PLG轻量日志监控系统(四)Loki之LogQL(一)Log queries
一 LogQL
中文解读
① 基本解读
一个'基本的日志查询'由两部分组成:日志流'选择器'、日志'管道'


了解支持的operators
LogQL: 'Log query language'
LogQL查询时分'两个'部分: '流选择器'(log stream selector)、查询'流水线'(log pipeline)![]()
② Log stream selector 流选择器
一个 Log Stream 代表了具有'相同元数据(Label 集)'的日志条目
++++++++++++ "语法特点" ++++++++++++
1) 对于'查询'表达式的'标签'部分,将其'包装'在花括号中'{}',标签值用"双引号"包括
2)然后使用'键值对的语法'来'选择标签',多个标签表达式用'逗号'分隔 -->'相当于and'
'流选择器'里面可以'使用label'作为'组合'选择, 并使用'匹配操作符'进行'筛选':
1) =: '精确'匹配
2)!=: '不'匹配
3)=~: 基于label的'正则'匹配 -->'PCRE'格式的
4)!~: 正则'不匹配'
注意: '=(表示精确)'、'感叹号!(取反)'、'~(表示正则)'
补充: 正则‘默认‘情况下,匹配是‘区分大小写‘的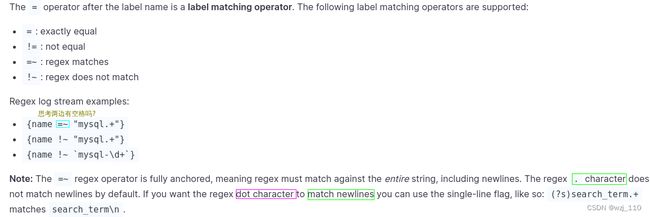
正则(?i)解读 (?P
(2)Log Pipeline
1)日志管道可以'附加到'日志流选择器后,以'进一步'处理和过滤日志流
2)它通常由'一个或多个'表达式组成,每个表达式针对每个日志'行依'次执行
3)如果一个表达式'过滤掉了'日志行,则管道将在此处'停止'并开始处理下一行
4)一些表达式可以'改变'日志内容和各自的标签,然后可用于'进一步'过滤和处理后续表达式或指标查询
++++++++++++ 一个'日志管道'可以由'以下部分'组成 ++++++++++++
[1]、'日志行'过滤表达式
[2]、'解析器(parse)'表达式
[3]、'标签(label)'过滤表达式
[4]、'日志行格式化'表达式
[5]、'标签格式化'表达式
[6]、Unwrap 表达式
备注: 其中 unwrap 表达式是一个'特殊'的表达式,只能在'度量查询'中使用① 日志行过滤表达式
过滤符: 'Line filter expression'
1)|=: 日志行'包含'字符串
2)!=: 日志行'不包含'字符串
3)|~: 日志行'匹配正则'表达式 -->'PCRE'格式的
4)!~: '日志行'与正则表达式'不'匹配
注意: '管道符|'、'感叹号!(取反)'、'字符匹配='
++++++++++++ "抽象" ++++++++++++
这种'工作方式'类似于find+grep;find'找'出文件,grep从文件中逐行'匹配':
find . -name "debug.log" | grep err
② 标签过滤表达式
说明: 顾名思义是获取对应特征'label'的日志行
1)String'字符串'用"双引号"或`反引号`引起来
例如: "200"或`us-central1`
2)Duration'时间'是一串'十进制'数字,每个数字都有'可选的数'和'单位'后缀
如: "300ms"、"1.5h" 或 "2h45m",
有效的时间单位是: "ns"、"us"(或 "µs")、"ms"、"s"、"m"、"h"
3)Number'数字'是浮点数(64 位)
如: 250、89.923
4)Bytes'字节'是一串'十进制'数字,每个数字都有'可选的数'和'单位'后缀
如: "42MB"、"1.5Kib" 或 "20b"
有效的'字节'单位:
"b"、"kib"、"kb"、"mib"、"mb"、"gib"、"gb"、"tib"、"tb"、"pib"、"bb"、"eb"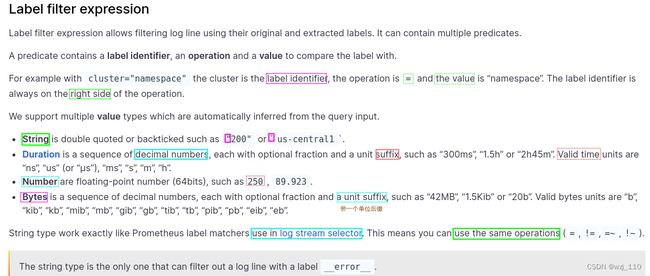

1)'字符串'类型的工作方式和'日志流选择器中'使用的方式'完全'一样
常见:可以使用'同样的操作符'(=、!=、=~、!~)
2)使用 Duration、Number 和 Bytes 将在'比较前'转换'标签值',并支持'以下'比较器
== 或 = '相等'比较
!= '不等于'比较
> 和 >= 用于'大于'或'大于等于'比较
< 和 <= 用于'小于'或'小于等于'比较 
③ Parse 解析器
1)解析器表达式可以'解析和提取'日志内容中的标签
2)这些提取的标签可以用于'标签过滤表达式'进行过滤或者用于指标聚合。
3)提取的标签键将由解析器进行'自动格式化',以遵循 Prometheus 指标名称的约定
特点:它们只能包含 'ASCII 字母和数字',以及下划线和冒号,'不能'以数字开头
4)其中解析器可以'解析日志'内容, 并通过管道实现灵活的'条件查询',可用的'解析器'有如下几种:
Loki supports 'JSON', 'logfmt', 'pattern', 'regexp' and 'unpack' parsers.各种解析器性能对比
细节点: '解析器'相当于自定义'数据展示'
1)JSON

前提: 日志行是'json'格式的数据
补充: 如果该日志行'不是预期的格式',该日志行'不会'被过滤,而会被添加一个新的'__error__'标签
++++++++++++++ '无参的场景' ++++++++++++++
说明: 有'参'数

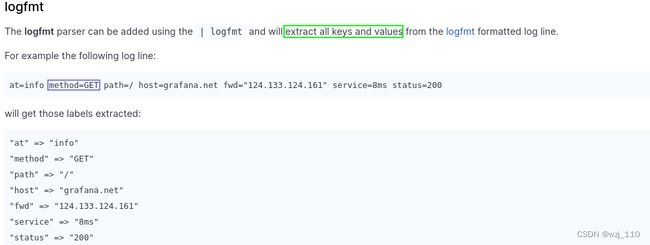
2)logfmt
3)Pattern
说明: '了解'即可,'自定义格式'进行'日志行的匹配'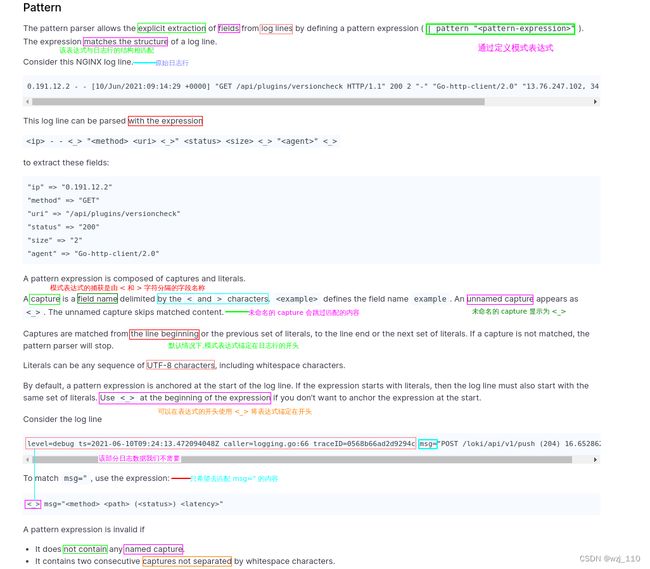
4)Regular expression
RE2 synatax
思考: 如何使用'正则中补获的'变量?
{job="regex_test"} | regexp "(?P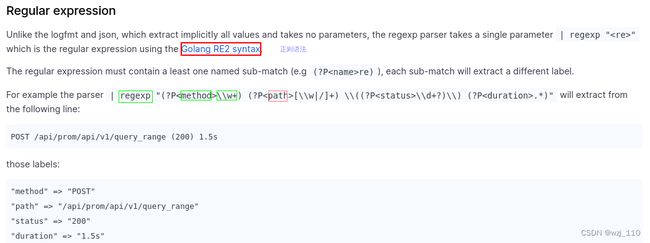
正则案例
5)unpack

6)Line format expression
| line_format : '行格式'表达式 --> '了解'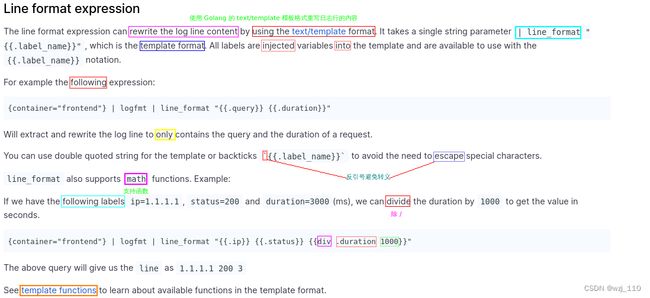
++++++++++++++ "案例讲解" ++++++++++++++
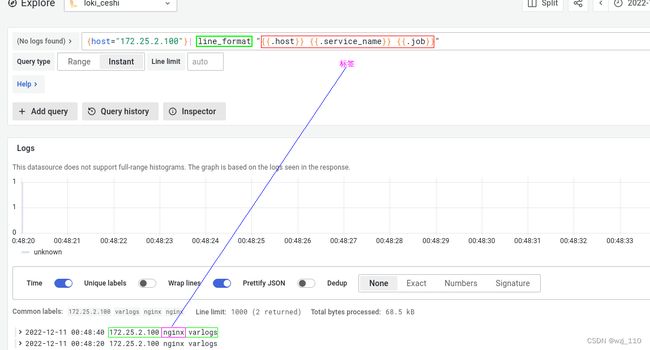
7)Labels format expression
| label_format: '标签'格式表达式 --> '了解'