【模型复现】densenet,增加残差结构连接,复用特征图的角度降低了计算量还提升了精度,transition_block压缩特征图
-
相比ResNet,DenseNet[1608.06993] Densely Connected Convolutional Networks (arxiv.org)提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。下图为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L 层的网络,DenseNet共包含 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1) 个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。【读点论文】Densely Connected Convolutional Networks用残差连接大力出奇迹,进一步叠加特征图,以牺牲显存为代价_残差连接论文_羞儿的博客-CSDN博客
-
众所周知,卷积神经网络提高效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而作者则是从特征图入手,通过对特征图的极致利用达到更好的效果和更少的参数。在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,目前很多论文都针对这个问题提出了解决方案,比如ResNet,Highway Networks,Stochastic depth,FractalNets等,尽管这些算法的网络结构有差别,但是核心都在于:在前面的层和后面的层之间创建短路连接。那么作者是怎么做呢?延续这个思路,那就是——在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来。为了能够保证前馈的特性,每一层将之前所有层的输入进行拼接,之后将输出的特征图传递给之后的所有层。
-
这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。每一层都可以直接利用损失函数的梯度以及最开始的输入信息,相当于是一种隐形的深度监督(implicit deep supervision),这有助于训练更深的网络。前面提到过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种密集连接相当于每一层都直接连接输入和损失,因此就可以减轻梯度消失现象,这样构建更深的网络不是问题。每层的输出特征图都是之后所有层的输入。
-
DenseNets的稠密连接模块dense block的一个优点是它比传统的卷积网络有更少的参数,因为它不需要再重新学习多余的特征图。传统的前馈结构可以被看成一种层与层之间状态传递的算法。每一层接收前一层的状态,然后将新的状态传递给下一层。它改变了状态,但也传递了需要保留的信息。ResNets将这种信息保留的更明显,因为它加入了恒等变换(identity transformations)。最近很多关于ResNets的研究都表明ResNets的很多层是几乎没有起作用的,可以在训练时随机的丢掉。DenseNet结构中,增加到网络中的信息与保留的信息有着明显的不同。DenseNet的dense block中每个卷积层都很窄(例如每一层有12个滤波器),仅仅增加小数量的特征图到网络的“集体知识”(collective knowledge),并且保持这些特征图不变——最后的分类器基于网络中的所有特征图进行预测。
-
-
DenseNet的网络结构主要由DenseBlock和Transition组成,如下图所示。下面具体介绍网络的具体实现细节。
-

- 在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H ( ⋅ ) H(·) H(⋅) 采用的是BN+ReLU+3x3 Conv的结构,如上图中block所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出 k 个特征图,即得到的特征图的channel数为 k,或者说采用 k 个卷积核。 在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的 k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 k 0 k_0 k0 ,那么 l l l 层输入的channel数为 k 0 + k ∗ ( l − 1 ) k_0+k*(l-1) k0+k∗(l−1) ,因此随着层数增加,尽管 k 设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有 k 个特征是自己独有的。
- CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图4给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。
-
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到 4 ∗ k 4*k 4∗k 个特征图它起到的作用是降低特征数量,从而提升计算效率。DenseNet:比ResNet更优的CNN模型 - 知乎 (zhihu.com)
-
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m ,Transition层可以产生 θ ∗ m \theta*m θ∗m 个特征(通过卷积层),其中 θ ∈ ( 0 , 1 ] \theta\in(0,1] θ∈(0,1] 是压缩系数(compression rate)。当 θ = 1 \theta=1 θ=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ = 0.5 \theta=0.5 θ=0.5 。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
-
在除了ImageNet外的所有数据集上,实验中使用的DenseNet都有三个dense block,每一个block都有相同的层数。在进入第一个dense block之前,输入图像先经过了16个(DenseNet-BC中是两倍的增长速率)卷积。对于3x3的卷积层,使用一个像素的零填充来保证特征图尺寸不变。在两个dense block之间的过渡层中,我们在2x2的平均池化层之后增加了1x1的卷积。在最后一个dense block之后,使用全局平均池化和softmax分类器。三个dense block的特征图的尺寸分别是32x32,16x16,8x8。
-
对于ImageNet数据集,图片输入大小为 224 ∗ 224 224*224 224∗224 ,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层(卷积核数为 2 ∗ k 2*k 2∗k),然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如下表所示:
-
由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的[1409.5185] Deeply-Supervised Nets (arxiv.org);
-
参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;由于特征复用,最后的分类器使用了低级特征。
-
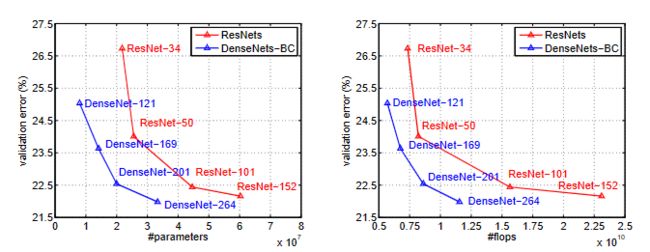
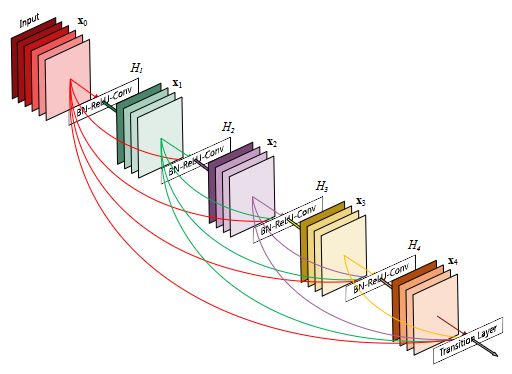
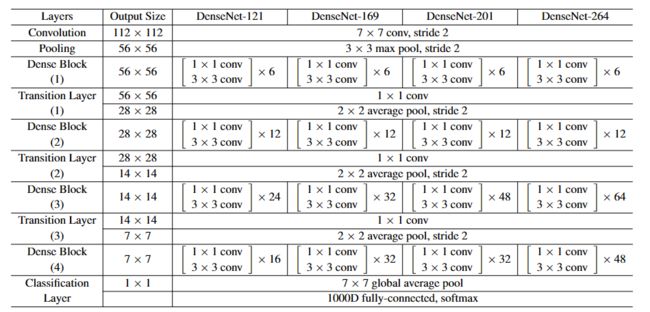
pytorch实现densenet
-
导包,查看配置信息
-
import time import torch from torch import nn, optim import torch.nn.functional as F import torchvision import sys device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') print(torch.__version__) print(device) -
1.13.1 cpu -
构建模块和搭建模型
-
def conv_block(in_channels, out_channels): blk = nn.Sequential(nn.BatchNorm2d(in_channels), # 先归一化,然后激活,然后再卷积 nn.ReLU(), nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) return blk class DenseBlock(nn.Module): def __init__(self, num_convs, in_channels, out_channels): super(DenseBlock, self).__init__() net = [] for i in range(num_convs): in_c = in_channels + i * out_channels # 根据这一层的输入和前几层的输出计算下一层的输入通道,很耗显存(尽管本次实验不在GPU上跑,耗内存) net.append(conv_block(in_c, out_channels)) self.net = nn.ModuleList(net) self.out_channels = in_channels + num_convs * out_channels # 计算输出通道数 def forward(self, X): for blk in self.net: Y = blk(X) X = torch.cat((X, Y), dim=1) # 在通道维上将输入和输出连结 return X blk = DenseBlock(2, 3, 10) X = torch.rand(4, 3, 8, 8) Y = blk(X) print("密集模块测试:",Y.shape) def transition_block(in_channels, out_channels): blk = nn.Sequential( nn.BatchNorm2d(in_channels), nn.ReLU(), nn.Conv2d(in_channels, out_channels, kernel_size=1), nn.AvgPool2d(kernel_size=2, stride=2)) return blk blk = transition_block(23, 10) print("过渡层测试",blk(Y).shape) net = nn.Sequential( nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) num_channels, growth_rate = 64, 32 # num_channels为当前的通道数 num_convs_in_dense_blocks = [4, 4, 4, 4] class GlobalAvgPool2d(nn.Module): # 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现 def __init__(self): super(GlobalAvgPool2d, self).__init__() def forward(self, x): return F.avg_pool2d(x, kernel_size=x.size()[2:]) class FlattenLayer(torch.nn.Module): def __init__(self): super(FlattenLayer, self).__init__() def forward(self, x): # x shape: (batch, *, *, ...) return x.view(x.shape[0], -1) for i, num_convs in enumerate(num_convs_in_dense_blocks): DB = DenseBlock(num_convs, num_channels, growth_rate) net.add_module("DenseBlosk_%d" % i, DB) # 上一个稠密块的输出通道数 num_channels = DB.out_channels # 在稠密块之间加入通道数减半的过渡层 if i != len(num_convs_in_dense_blocks) - 1: net.add_module("transition_block_%d" % i, transition_block(num_channels, num_channels // 2)) num_channels = num_channels // 2 net.add_module("BN", nn.BatchNorm2d(num_channels)) net.add_module("relu", nn.ReLU()) net.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, num_channels, 1, 1) net.add_module("fc", nn.Sequential(FlattenLayer(), nn.Linear(num_channels, 10))) X = torch.rand((1, 1, 96, 96)) for name, layer in net.named_children(): X = layer(X) print(name, ' output shape:\t', X.shape) -
密集模块测试: torch.Size([4, 23, 8, 8]) 过渡层测试 torch.Size([4, 10, 4, 4]) 0 output shape: torch.Size([1, 64, 48, 48]) 1 output shape: torch.Size([1, 64, 48, 48]) 2 output shape: torch.Size([1, 64, 48, 48]) 3 output shape: torch.Size([1, 64, 24, 24]) DenseBlosk_0 output shape: torch.Size([1, 192, 24, 24]) transition_block_0 output shape: torch.Size([1, 96, 12, 12]) DenseBlosk_1 output shape: torch.Size([1, 224, 12, 12]) transition_block_1 output shape: torch.Size([1, 112, 6, 6]) DenseBlosk_2 output shape: torch.Size([1, 240, 6, 6]) transition_block_2 output shape: torch.Size([1, 120, 3, 3]) DenseBlosk_3 output shape: torch.Size([1, 248, 3, 3]) BN output shape: torch.Size([1, 248, 3, 3]) relu output shape: torch.Size([1, 248, 3, 3]) global_avg_pool output shape: torch.Size([1, 248, 1, 1]) fc output shape: torch.Size([1, 10]) -
加载模型并训练
-
def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'): """Download the fashion mnist dataset and then load into memory.""" trans = [] if resize: trans.append(torchvision.transforms.Resize(size=resize)) trans.append(torchvision.transforms.ToTensor()) transform = torchvision.transforms.Compose(trans) mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform) mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform) if sys.platform.startswith('win'): num_workers = 0 # 0表示不用额外的进程来加速读取数据 else: num_workers = 4 train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers) return train_iter, test_iter def evaluate_accuracy(data_iter, net, device=None): if device is None and isinstance(net, torch.nn.Module): # 如果没指定device就使用net的device device = list(net.parameters())[0].device acc_sum, n = 0.0, 0 with torch.no_grad(): for X, y in data_iter: if isinstance(net, torch.nn.Module): net.eval() # 评估模式, 这会关闭dropout acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item() net.train() # 改回训练模式 else: # 自定义的模型, 3.13节之后不会用到, 不考虑GPU if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数 # 将is_training设置成False acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item() else: acc_sum += (net(X).argmax(dim=1) == y).float().sum().item() n += y.shape[0] return acc_sum / n def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs): net = net.to(device) print("training on ", device) loss = torch.nn.CrossEntropyLoss() for epoch in range(num_epochs): train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time() for X, y in train_iter: X = X.to(device) y = y.to(device) y_hat = net(X) l = loss(y_hat, y) optimizer.zero_grad() l.backward() optimizer.step() train_l_sum += l.cpu().item() train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item() n += y.shape[0] batch_count += 1 test_acc = evaluate_accuracy(test_iter, net) print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec' % (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start)) batch_size = 256 # 如出现“out of memory”的报错信息,可减小batch_size或resize train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=96) lr, num_epochs = 0.001, 5 optimizer = torch.optim.Adam(net.parameters(), lr=lr) train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs) -
training on cpu epoch 1, loss 0.4546, train acc 0.839, test acc 0.855, time 891.0 sec epoch 2, loss 0.2718, train acc 0.900, test acc 0.903, time 876.2 sec epoch 3, loss 0.2341, train acc 0.913, test acc 0.907, time 863.5 sec epoch 4, loss 0.2114, train acc 0.923, test acc 0.915, time 857.3 sec epoch 5, loss 0.1943, train acc 0.928, test acc 0.868, time 860.1 sec