数据结构——图——克鲁斯卡尔(Kruskal)算法
数据结构——图——克鲁斯卡尔(Kruskal)算法
同样的思路,我们也可以直接就以边为目标去构建,因为权值是在边上,直接去找最小权值的边来构建生成树也是很自然的想法,只不过构建时要考虑是否会形成环路而已。此时我们就用到了图的存储结构中的边集数组结构。以下是edge边集数组结构的定义代码:
typedef struct
{
int begin; /*起点下标*/
int end; /*终点下标*/
int weight; /*权值*/
} Edge;
我们将图7-6-3的邻接矩阵通过程序转化为图7-6-7的右图的边集数组,并且对它们按权值从小到大排序。

于是克鲁斯卡尔(Kruskal)算法代码如下,左侧数字为行号。其中 MAXEDGE为边数量的极大值,此处大于等于15即可,MAXVEX为顶点个数最大值,此处大于等于9即可。现在假设我们自己就是计算机,在调用MiniSpanTree_Kruskal函数,输入图7-6-3右图的邻接矩阵后,看看它是如何运行并打印出最小生成树的。
/*Kruskal算法生成最小生成树*/
#define MAXEDGE 100
#define MAXVEX 100
void MiniSpanTree_Kruskal(MGraph G)/*生成最小生成树*/
{
int i, n, m;
Edge edges[MAXEDGE];/*定义边集数组*/
int parent[MAXVEX]; /*定义一数组用来判断与边是否形成环路*/
/*此处省略将邻接矩阵G 转化为边集数组edges 并按权由小到大排序代码*/
for (i=0;i<G.numVertexes;i++)
{
parent[i] = 0; /*初始化数组值为0*/
}
for ( i = 0; i < G.numEdges; i++) /*循环每一条边*/
{
n = Find(parent, edges[i].begin);
m= Find(parent, edges[i].end);
if (n!=m)/*假如n与m不等,说明此边没有与现有生成树形成环路*/
{
parent[n] = m;/*将此边的结尾顶点放入下标为起点的parent中*/
/*表此顶点已经生成树集合中*/
printf("(%d,%d) %d",edges[i].begin, edges[i].end, edges[i].weight);
}
}
}
int Find(int* parent, int f)/*查找连线顶点的尾部下标*/
{
while (parent[f]>0)
{
f = parent[f];
}
return f;
}
1.程序开始运行,第5行之后,我们省略掉颇占篇幅但却很容易实现的将邻接矩阵转换为边集数组,并按权值从小到大排序的代码11,也就是说,在第5行开始,我们已经有了结构为edge,数据内容是图7-6-7 的右图的一维数组edges。
2.第5~7行,我们声明一个数组parent,并将它的值都初始化为0,它的作用我们后面慢慢说。
3.第8~17行,我们开始对边集数组做循环遍历,开始时,i=0。
4.第10行,我们调用了第19~25行的函数 Find,传入的参数是数组parent和当前权值最小边(v4,v7)的begin:4。因为parent中全都是О所以传出值使得n=4。
5.第11行,同样作法,传入(v4,v7z)的end: 7。传出值使得m=7。
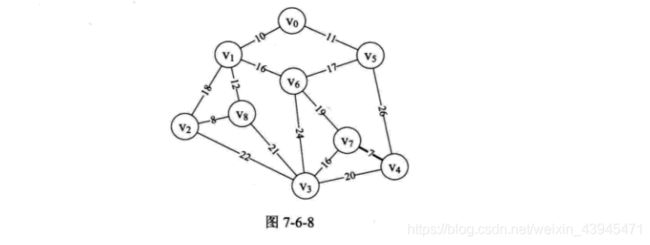
6.第12~16行,很显然n与m不相等,因此parent[4]=7。此时parent 数组值为{0,0,0,0,7,0,0,0,0},并且打印得到“(4,7) 7”。此时我们已经将边(v4,vz)纳入到最小生成树中,如图7-6-8所示。
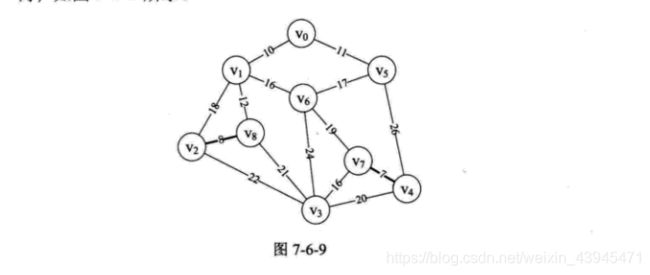
7.循环返回,执行10~16行,此时i=1,edge[1]得到边(v2v8),n=2,m=8,parent[2]=8,打印结果为“(2,8) 8”,此时 parent 数组值为{0,0,8,o,7,0,0,0,0},这也就表示边(v4,v7)和边(v2v8)已经纳入到最小生成树,如图7-6-9所示。
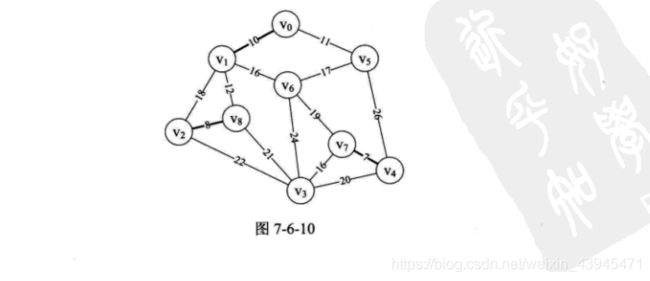
8.再次执行10~16 行,此时i=2,edge[2]得到边(vo,v1), n=0,m=1,parent[0]=1,打印结果为“(0,1) 10”,此时parent数组值为{(1,0,8,0,7,0,0,0,0},此时边(v4,V7)、(v2,v8)和(v0,v1)已经纳入到最小生成树,如图7-6-10所示。
9.当i=3、4、5、6时,分别将边(v0,v5)、( v1,v8)、( v3,v7)、(v1,v6)纳入到最小生成树中,如图7-6-11所示。此时 parent 数组值为{1,5,8,7,7,8,0,0,6},怎么去解读这个数组现在这些数字的意义呢?
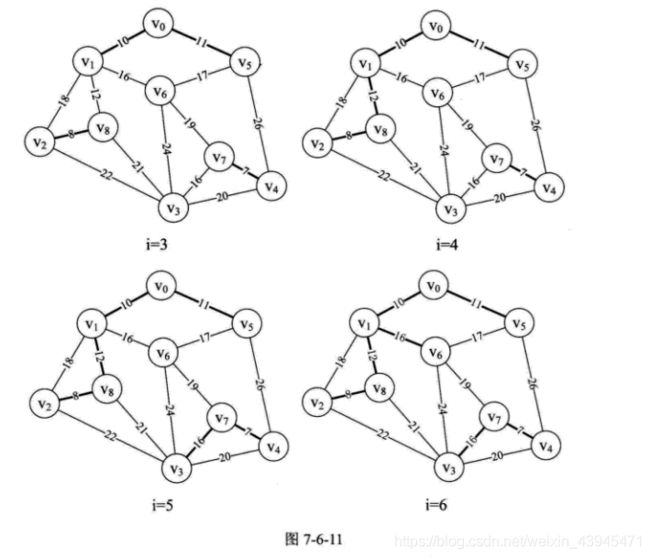
从图7-6-11的最右图i=6的粗线连线可以得到,我们其实是有两个连通的边集合A 与B中纳入到最小生成树中的,如图7-6-12所示。当parent[0]=1,表示v0和v1已经在生成树的边集合A 中。此时将parent[0]=1的1改为下标,由parent[1]=5,表示v1和v5在边集合A中,parent[5]=8表示v5与v8在边集合A中,parent[8]=6表示v8与v6在边集合A中,parent[6]=0表示集合A暂时到头,此时边集合A 有v0、V1、V5、v8、v6。我们查看parent中没有查看的值,parent[2]=8表示v2与v8在一个集合中,因此v2也在边集合A中。再由parent[3]=7、parent[4]=7和parent[7]=0可知v3、v4、vz在另一个边集合B中。
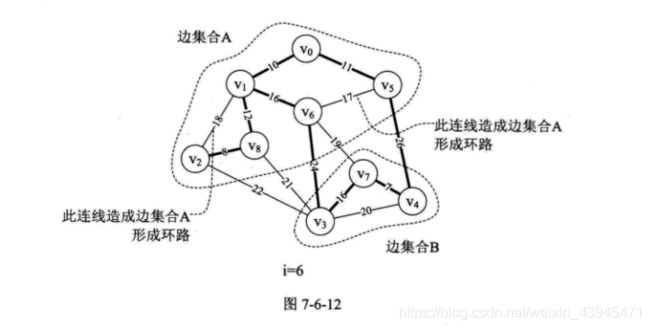
10.当i=7时,第10行,调用Find函数,会传入参数edges[7].begin=5。此时第21行,parent[5]=8>0,所以f=8,再循环得parent[8]=6。因parent[6]=0所以Find返回后第10行得到n=6。而此时第11行,传入参数edges[7].end=6得到m=6。此时n=m,不再打印,继续下一循环。这就告诉我们,因为边(vs,v6),使得边集合A形成了环路。因此不能将它纳入到最小生成树中,如图7-6-12所示。
11.当i=8时,与上面相同,由于边(v1,v2)使得边集合A 形成了环路。因此不能将它纳入到最小生成树中,如图7-6-12所示。
12.当i=9时,边(v6,v7),第10行得到n=6,第11 行得到m=7,因此parent[6]=7,打印“(6,7) 19”。此时 parent数组值为{1,5,8,7,7,8,7,0,6},如图7-6-13所示。
13.此后边的循环均造成环路,最终最小生成树即为图7-6-13所示。

假设N= (V,{B})是连通网,则令最小生成树的初始状态为只有n个顶点而无边的非连通图T={V,图中每个顶点自成一个连通分量。在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边。依次类推,直至T中所有顶点都在同一连通分量上为止。
此算法的Find函数由边数e决定,时间复杂度为0(loge),而外面有一个for 循环e次。所以克鲁斯卡尔算法的时间复杂度为O(eloge)。
克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势;