Python学习笔记 - 数据结构:元组、列表、集合和字典
前言
在计算机程序中会有很多数据,这些数据通常需要一个容器将它们管理起来,这就是数据结构,常见的有:数组(Array)、集合(Set)、列表(List)、队列(Queue)、链表(LinkedList)、树(Tree)、堆(Heap)、栈(Stack) 和 字典(Dict) 等数据结构。
在Python中内置的数据结构主要有:元组(tuple)、列表(list)、集合(set) 和 字典(dict)。这些数据结构都可用于保存多个数据项,这对于编程而言是非常重要的——因为程序不仅需要使用单个变量来保存数据,还需要使用多种数据结构来保存大量数据,而元组、列表、集合和字典就可以满足保存大量数据的需求。
注意:Python中并没有数组数据结构,因为数组要求元素类型是一致的。而Python作为动态类型语言,不强制声明变量的数据类型,也不强制检查元素的数据类型,不能保证元素的数据类型一致,所以Python中没有数组结构。
一、序列
所谓序列,指的是一种包含多项数据的数据结构,序列包含的多个数据项(也叫成员或元素)按顺序排列,可通过索引来访问成员。
序列的特点是:可迭代的、元素有序、可以重复出现。
1.1 Python的序列
Python 的常见序列类型包括字符串(str)、元组(tuple)、列表(list)、范围(range) 和 字节序列(bytes)。
序列可进行的操作有:索引、分片、加 和 乘。
1.2 序列操作
1、索引操作
序列中第一个元素的索引是0,其他元素的索引是第一个元素的偏移量。可以有正偏移量,称为正值索引;也可以有福偏移量,称为负值索引。正值索引的最后一个元素索引是 “序列长度 - 1”。负值索引最后一个元素索引是 “-1”。
例如,“Hello” 字符串,它的正值索引如下图1-1(a) 所示,负值索引如图1-1(b)所示。
 图1 正负索引示例
图1 正负索引示例
序列中的元素是通过索引下标访问的,即中括号 [index] 方式访问。在 Python Shell 中运行示例如下:
>>> a = 'Hello'
>>> a[0]
'H'
>>> a[1]
'e'
>>> a[4]
'o'
>>> a[-1]
'o'
>>> a[-2]
'l'
>>> a[5]
Traceback (most recent call last):
File "", line 1, in
IndexError: string index out of range
>>> max(a)
'o'
>>> min(a)
'H'
>>> len(a)
5 a[0] 是所访问序列的第一个元素,最后一个元素的索引可以是 4 或 -1。但是索引超过范围,则会发生 IndexError 错误。另外,获取序列的长度使用函数 len(),类似的序列还有 max() 和 min() 函数,max() 函数返回最后一个元素,min() 函数返回第一个元素。
2、序列的加和乘操作
Python 的 “+” 和 “*” 运算符可以应用于序列。+ 运算符可以将两个序列连接起来,* 运算符可以将序列重复多次。
在 Python Shell 中运行示例如下:
>>> a = 'Hello'
>>> a * 3
'HelloHelloHello'
>>> print(a)
Hello
>>> a += ' '
>>> a += 'World'
>>> print(a)
Hello World3、序列分片操作
序列的分片(Slicing) 就是从序列中切分出小的子序列。分片使用分片运算符,分片运算符有两种形式。
- [start : end] start 是开始索引,end 是结束索引。
- [start : end : step] start 是开始索引,end 是结束索引,step 是步长,步长是在分片时获取元素的间隔。步长可以是正整数,也可以是负整数。
《注意》切下的分片包括 start 索引位置元素,但不包括 end 索引位置元素,start 和 end 也都可以忽略。
在 Python Shell 中运行示例代码如下:
>>> a = 'Hello'
>>> a[1:3]
'el'
>>> a[:3]
'Hel'
>>> a[0:]
'Hello'
>>> a[:]
'Hello'
>>> a[1:-1]
'ell'(1)上述代码表达式 a[1:3] 是切出 1~3 的子字符串,注意不包括索引3的元素,所以结果是 "el"。
(2)表达式 a[:3] 省略了开始索引,则默认开始索引是 0,所以 a[:3] 与 a[0:3] 分片结果是一样的。
(3)表达式 a[0:] 省略了结束索引,默认结束索引是序列的长度,即 5,所以 a[0:] 与 a[0:5] 的分片结果是一样的。
(4)表达式 a[:] 同时省略了开始索引和结束索引,a[:] 与 a[0:5] 的结果是一样的。
(5)表达式 a[1:-1] 使用了负值索引,对照上图 1-1,不难计算出 a[1:-1] 的结果是 "ell"。
分片时使用 [start : end: step] 可以指定步长(step),步长与当次元素索引、下次元素索引之间的关系如下:
下次元素索引 = 当次元素索引 + 步长在 Python Shell 中运行示例代码如下:
>>> a = 'Hello'
>>> a[1:5]
'ello'
>>> a[1:5:2]
'el'
>>> a[0:3]
'Hel'
>>> a[0:3:2]
'Hl'
>>> a[0:3:3]
'H'
>>> a[::-1]
'olleH'(1)表达式 a[1:5] 省略了步长参数,步长默认值是1,结果是 "ello"。
(2)表达式 a[1:5:2] 步长为2,结果是 "el"。
(3)表达式 a[0:3] 分片后的子字符串是 "Hel",而 a[0:3:3] 步长为 3,分片结果为 "H" 字符。
(4)当步长为负数时比较麻烦,负数时是从右向左获取元素,所以表达式 a[::-1] 分片的结果是原始字符串的逆置,结果为 "olleH"。
二、元组
2.1 创建元组
元组(tuple) 是一种不可变序列,一旦创建就不能修改。创建元素可以使用 tuple([iterable]) 函数或者直接用逗号 “,” 将元素分隔。
在Python Shell 中运行示例代码如下:
>>> 21,32,43,45 # --1
(21, 32, 43, 45)
>>> (21,32,43,45) # --2
(21, 32, 43, 45)
>>> a = (21,32,43,45)
>>> print(a)
(21, 32, 43, 45)
>>> ('Hello', 'World') # --3
('Hello', 'World')
>>> ('Hello', 'World', 1, 2, 3) # --4
('Hello', 'World', 1, 2, 3)
>>> tuple([21,32,43,45]) # --5
(21, 32, 43, 45)
(1)代码第1处创建了一个有 4 个元素的元组,创建元组时使用小括号把元素括起来不是必须的,但是还是建议带上。
(2)代码第2处使用小括号将元素括起来,这只是为了提高程序的可读性。
(3)代码第3处创建了一个字符串元组
(4)代码第4处创建了字符串和整数混合的元组。Python 中没有强制声明数据类型,因此元组中的元素可以是任何数据类型。
另外,元组还可以通过 tuple() 函数创建,参数 iterable 可以是任何可迭代对象。
(5)代码第5处使用了 tuple() 函数创建元组对象,实参 [21, 32, 43, 45] 是一个列表,列表是可迭代对象,可以作为 tuple() 函数参数创建元组对象。
创建元组还需要注意如下极端情况:
>>> a = (21)
>>> type(a)
>>> a = (21,)
>>> type(a)
>>> a = ()
>>> type(a)
从上述代码可见,当一个元组只有一个元素时,后面的逗号(,) 是不能省略的,即 (21, ) 表示的是只有一个元素的元组,而 (21) 表示的是一个整数。另外,() 可以创建空元组对象。
2.2 访问元组
元组作为序列,可以通过下标索引的方式访问其中的元素,也可以对其进行分片。
在Python Shell 中运行示例代码如下:
>>> a = ('Hello', 'World', 1, 2, 3) # --1
>>> a[1]
'World'
>>> a[1:3]
('World', 1)
>>> a[2:]
(1, 2, 3)
>>> a[:2]
('Hello', 'World')(1)上述代码第1处是元组 a,a[1] 是访问元组下标索引为 1 的元素,即元组的第二个元素。表达式 a[1:3]、a[2:] 和 a[:2] 都是分片操作。
元组还可以进行拆包(Unpack)操作,就是将元组的元素取出赋值给不同的变量。
在 Python Shell 中运行示例代码如下:
>>> a = ('Hello', 'World', 1, 2, 3)
>>> str1, str2, n1, n2, n3 = a # --1
>>> str1
'Hello'
>>> str2
'World'
>>> n1
1
>>> n2
2
>>> n3
3
>>> str1, str2, *n = a # --2
>>> str1
'Hello'
>>> str2
'World'
>>> n
[1, 2, 3]
>>> str1, _, n1, n2, _ = a # --3
>>> str1
'Hello'
>>> n1
1
>>> n2
2(1)上述代码第1处是将元组 a 进行拆包操作,接收拆包元素的变量个数应等于元组中的元素个数。接收变量个数可以少于元组的元素个数。
(2)代码第2处接收变量只有 3 个,最后一个很特殊,变量 n 前面有星号,表示将剩下的元素作为一个列表赋值给变量 n。
(3)另外,还可以使用下划线指定不取值哪些元素,代码第3处表示不取第二个和第五个元素。
2.3 遍历元组
一般使用 for 循环遍历元组,示例代码如下:程序清单:traverse_tuple.py
# coding=utf-8
# 代码文件: 元组/traverse_tuple.py
# 使用for循环遍历元组
a = (21, 32, 43, 45)
for item in a: # --1
print(item)
print('--------------')
for i, item in enumerate(a): # --2
print('{0} -- {1}'.format(i, item))
# print('%d -- %d' %(i, item))运行结果:
>python traverse_tuple.py
21
32
43
45
--------------
0 -- 21
1 -- 32
2 -- 43
3 -- 45一般情况下,遍历的目的只是取出每一个元素值,见代码第1处的 for 循环。但有时候需要在遍历过程中同时获取索引,这时可以使用代码第2处的 for 循环,其中 enumerate(a) 函数可以获得一个元组对象,该元组对象有两个成员,第一个成员是索引,第二个成员是数值。所以 (i, item) 是元组拆包过程,其中变量 i 是元组 a 的当前索引,item 是元组 a 的当前元素值。
《注意》本节所介绍的元组遍历方式适合于所有序列,如字符串、范围 和 列表等。
三、列表
列表(list) 也是一种数据结构,与元组不同的是,列表具有可变性,可以追加、插入、删除和替换列表中的元素。
3.1 创建列表
创建列表可以使用 list([iterable]) 函数,或者用中括号 [ ] 将元素括起来,元素之间用逗号分隔。
在Python Shell 中运行示例代码如下:
>>> [20, 10, 50, 40, 30] # --1
[20, 10, 50, 40, 30]
>>> []
[]
>>> ['Hello', 'World', 1, 2, 3] # --2
['Hello', 'World', 1, 2, 3]
>>> a = [10] # --3
>>> type(a)
>>> a = [10,] # --4
>>> type(a)
>>> list((20, 10, 50 ,40, 30)) # --5
[20, 10, 50, 40, 30] (1)上述代码第1处创建了一个有5个元素的列表,注意中括号不能省略,如果省略了中括号,那就变成元组了。
(2)创建空列表是 [ ] 表达式,列表中可以放入任何对象,代码第2处是创建一个字符串和整数混合的列表。
(3)代码第3处是创建只有一个元素的列表,中括号不能省略。
(4)另外,无论是元组还是列表,每一个元素后面都跟着一个逗号,只是最后一个元素的逗号经常是省略的,代码第4处最后一个元素没有省略逗号。
(5)另外,列表还可以通过 list([iterable]) 函数创建,参数 iterable 是任何可迭代对象。代码第5处使用 list() 函数创建列表对象,实参 (20, 10, 50, 40, 30) 是一个元组,元组是可迭代对象,可以作为 list() 函数参数创建列表对象。
3.2 追加元素
列表中追加单个元素可以使用 append() 方法。如果想追加另一个列表,可以使用 + 运算符或 extend() 方法。
append() 方法语法:list.append(x)
其中,参数 x 是要追加的单个元素值。
extend() 方法语法:list.extend(t)
其中,参数 t 是要追加的另外一个列表。
在 Python Shell 中运行示例代码如下:
>>> student_list = ['张三', '李四', '王五']
>>> student_list.append('董六') # --1
>>> student_list
['张三', '李四', '王五', '董六']
>>> student_list
['张三', '李四', '王五', '董六']
>>> student_list += ['刘备', '关羽'] # --2
>>> student_list
['张三', '李四', '王五', '董六', '刘备', '关羽']
>>> student_list.extend(['张飞', '赵云']) # --3
>>> student_list
['张三', '李四', '王五', '董六', '刘备', '关羽', '张飞', '赵云'](1)上述代码中第1处使用了 append() 方法,在列表后面追加了一个元素,append() 方法不能同时追加多个元素。
(2)代码第2处利用 += 运算符追加多个元素,能够支持 += 运算是因为列表支持 + 运算。
(3)代码第3处使用了 extend() 方法追加多个元素,以列表作为函数实参。
3.3 插入元素
插入元素可以使用列表的 insert() 方法,该方法可以在指定索引位置插入一个元素。
insert() 方法语法:list.insert(i, x)
其中参数 i 是要插入的索引位置,参数 x 是要插入的元素数值。
在 Python Shell 中运行示例代码如下:
>>> student_list = ['张三', '李四', '王五']
>>> student_list.insert(2, '刘备')
>>> student_list
['张三', '李四', '刘备', '王五']上述代码中,student_list 调用 insert() 方法,在索引 2 位置插入一个元素,新元素的索引为2。
3.4 替换元素
列表具体可变性,其中的元素替换很简单,通过列表下标将索引元素放在赋值符号 “=” 左边,进行赋值即可替换。
在Python Shell 中运行示例代码如下:
>>> student_list = ['张三', '李四', '王五']
>>> student_list[0] = '诸葛亮'
>>> student_list
['诸葛亮', '李四', '王五']其中,student_list[0] = "诸葛亮" 替换了列表 student_list 中的第一个元素。
3.5 删除元素
列表中实现删除元素有两种方式,一种是使用列表的 remove() 方法,另一种是使用列表的 pop() 方法。
1)remove() 方法
remove() 方法从左到右查找列表中的元素,如果找到匹配元素则删除,注意如果找到多个匹配元素,只是删除第一个,如果没有找到则会抛出错误。
remove() 方法语法:list.remove(x)
其中,参数 x 是要找的元素值。
使用 remove() 方法删除元素,示例代码如下:
>>> student_list = ['张三', '李四', '王五', '王五']
>>> student_list.remove('王五')
>>> student_list
['张三', '李四', '王五']
>>> student_list.remove('王五')
>>> student_list
['张三', '李四']2)pop() 方法
pop() 方法也会删除列表中的元素,但它会将成功删除的元素返回。
pop() 方法语法:item = list.pop([i])
其中,参数 i 是指定删除元素的索引,i 可以省略,表示删除最后一个元素。返回值 item 是删除的元素。
在 Python Shell 中,使用 pop() 方法删除元素示例代码如下:
>>> student_list = ['张三', '李四', '王五']
>>> student_list.pop()
'王五'
>>> student_list
['张三', '李四']
>>> student_list.pop(0)
'张三'
>>> student_list
['李四']3.6 其他常用方法
前面介绍列表追加、插入和删除时,已经介绍了一些方法。事实上列表还有很多方法,本节再介绍几个常用方法。
- reverse():逆置列表。
- copy():复制列表。
- clear():清除列表中的所有元素。
- index(x[, i[, j]]):返回查找 x 第一次出现的索引,i 是开始查找索引,j 是结束查找索引,该方法继承自序列,元组和字符串也可以使用该方法。
- count(x):返回 x 出现的次数,该方法继承自序列,元组和字符串也可以使用该方法。
- sort():用于对列表元素进行排序。
在 Python Shell 中运行示例代码如下:
>>> a = [21, 32, 43, 45] # --1
>>> a.reverse()
>>> a
[45, 43, 32, 21]
>>> b = a.copy() # --2
>>> b
[45, 43, 32, 21]
>>> a.clear() # --3
>>> a
[]
>>> b
[45, 43, 32, 21]
>>> a = [45, 43, 32, 21, 32]
>>> a.count(32) # --4
2
>>> student_list = ['张三', '李四', '王五']
>>> student_list.index('王五') # --5
2
>>> student_tuple = ('张三', '李四', '王五')
>>> student_tuple.index('王五') # --6
2
>>> student_tuple.index('李四', 1, 2)
1
>>> a_list = [3, 4, -2, -30, 14, 9.3, 3.4]
>>> a_list
[3, 4, -2, -30, 14, 9.3, 3.4]
>>> a_list.sort() # --7
>>> a_list
[-30, -2, 3, 3.4, 4, 9.3, 14](1)上述代码第1处调用了 reverse() 方法将列表 a 逆置。
(2)代码第2处调用 copy() 方法复制列表 a,并赋值给列表 b。
(3)代码第3处是清楚列表 a 中的元素。
(4)代码第4处是返回列表 a 中元素值为 32 的元素个数。
(5)代码第5处是返回元素 '王五' 在 student_list 列表中的索引位置。
(6)代码第6处是返回元素 '王五' 在 student_list 元组中的索引位置。也就是说,元组对象也有 index() 方法。
(7)代码第7处是对列表 a_list 进行排序,默认是升序排序。
3.7 列表推导式
Python 中有一种特殊表达式——推导式,它可以将一种数据结构作为输入,经过过滤、计算处理后,最后输出另一种数据结构。
工具数据结构的不同,可分为列表推导式、集合推导式和字典推导式。本节先介绍列表推导式。
如果想获得 0~9 中偶数的平方数列,可以通过 for 循环实现。代码如下:list_for.py
# coding=utf-8
# 代码文件: 列表/list_for.py
# 获得 0~9 中偶数的平方数列列表,通过for循环实现
n_list = [] # 初始化一个空列表
for x in range(10):
if x % 2 == 0:
n_list.append(x ** 2)
print(n_list)运行结果如下:
[0, 4, 16, 36, 64]0~9 中偶数的平方数列也可以通过列表推导式实现,代码如下:list_derivation.py
# coding=utf-8
# 代码文件: 列表/list_derivation.py
# 获得 0~9 中偶数的平方数列列表,通过列表推导式循环实现
n_list2 = [(x ** 2) for x in range(10) if (x % 2 == 0)] # --1
print(n_list2)运行结果如下:
[0, 4, 16, 36, 64](1)上述代码第1处就是列表推导式,可知输出的结果与 for 循环是一样的。下图2 所示是列表推导式语法结构,其中,in 后面的表达式是“输入序列”;for 前面的表达式是“输出表达式”,它的运算结果会保存到一个新列表中;if 条件语句用来过滤输入序列,符合条件的才传递输出表达式,“条件语句” 是可以省略的,所有元素都传递给输出表达式。
 图2 列表推导式语法结构
图2 列表推导式语法结构
条件语句还可以包含多个条件,例如找出 0~99 可以被 5 整除的偶数数列,实现代码如下:
# 列表推导式后面还可以包含多个if条件语句,这些条件语句是逻辑与的关系
# 例如找出0~99可以被5整除的偶数数列
# n_list3 = [x for x in range(100) if (x % 2 == 0) if (x % 5 == 0)] # --1
n_list3 = [x for x in range(100) if (x % 2 == 0) and (x % 5 == 0)] # --2
print(n_list3)运行结果:
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90](1)代码第1处和代码第2处的处理方式是等效的,在代码第1处中,多个 if 条件语句之间是没有使用逻辑运算符连接的,个人建议使用代码第2处的写法更好一些,更加简明清晰。
四、集合
集合(set)是一种可迭代的、无序的、不能包含重复元素的数据结构。下图3 是一个班级的集合,其中包含一些学生,这些学生是无序的,不能通过序号访问,而且不能重复。集合又分为可变集合(set)和不可变集合(frozenset)。
【提示】与序列比较,序列中的元素时有序的,可以重复出现,而集合中的元素时无序的,且不能有重复的元素。序列强调的是有序,集合强调的是不重复。当不考虑顺序,而且没有重复的元素时,序列和集合可以相互替换。
 图3 班级的集合
图3 班级的集合
4.1 创建可变集合
可变集合类型是 set,创建可变集合可以使用 set([iterable]) 函数,或者用大括号 { } 将元素括起来,元素之间用逗号分隔。
在 Python Shell 中运行示例代码如下:
>>> a = {'张三', '李四', '王五'} # --1
>>> a
{'王五', '李四', '张三'}
>>> a = {'张三', '李四', '王五', '王五'} # --2
>>> len(a)
3
>>> a
{'王五', '李四', '张三'}
>>> set((20, 10, 50, 40, 30)) # --3
{40, 10, 50, 20, 30}
>>> b = {} # --4
>>> type(b)
>>> b = set() # --5
>>> type(b)
(1)上述代码第1处是使用大括号{ } 创建集合,如果元素有重复的会怎样呢?
(2)代码第2处包含有重复的元素,创建时会剔除多余的重复元素,只保留一份。
(3)代码第3处是使用 set() 函数创建集合对象,
(4)如果需要创建一个空的集合对象,不能使用大括号{ } 表示,见代码第4处,b 并不是集合而是字典。
(5)创建空集合要使用空参数的 set() 函数,见代码第5处。
【提示】要获得集合中元素的个数,可以使用 len() 函数,注意 len() 是函数不是方法,本例中 len(a) 表达式返回集合 a 的元素个数,可以发现对于多余的重复元素并没有计算在内,所以 len(a) 返回的结果是 3,而不是 4。
4.2 修改可变集合
可变集合类似于列表,可变集合的内容可以被修改,可以向其中插入和删除元素。修改可变集合有几个常用的方法。
- add(elem):添加元素,如果元素已经存在,则不能添加,不会抛出错误。
- remove(elem):删除元素,如果元素不存在,则抛出错误。
- discard(elem):删除元素,如果元素不存在,不会抛出错误。
- pop():删除返回集合中任意一个元素,返回值是删除的元素。
- clear():清除集合。
在 Python Shell 中运行示例代码如下:
>>> student_set = {'张三', '李四', '王五'}
>>> student_set.add('董六')
>>> student_set
{'王五', '李四', '董六', '张三'}
>>> student_set.remove('李四')
>>> student_set
{'王五', '董六', '张三'}
>>> student_set.remove('李四') # --1
Traceback (most recent call last):
File "", line 1, in
KeyError: '李四'
>>> student_set.discard('李四') # --2
>>> student_set
{'王五', '董六', '张三'}
>>> student_set.discard('王五')
>>> student_set
{'董六', '张三'}
>>> student_set.pop()
'董六'
>>> student_set
{'张三'}
>>> student_set.clear()
>>> student_set
set() (1)上述代码第1处使用 remove() 方法删除元素时,由于要删除的元素 "李四" 已经不在集合中,所以会抛出错误。
(2)同样是删除集合中不存在的元素,discard() 方法不会抛出错误,见代码第2处。
4.3 遍历集合
集合是无序的,没有索引,不能通过下标访问单个元素。但可以遍历集合,访问集合的每一个元素。
一般使用 for 循环遍历集合,示例代码如下:traverse_set.py
# coding=utf-8
# 代码文件: 集合/traverse_set.py
# 遍历集合,一般通过for循环实现
student_set = {'张三', '李四', '王五'}
for item in student_set:
print(item)
print('---------------')
for i, item in enumerate(student_set): # --1
print('{0} - {1}'.format(i, item))运行结果:
李四
王五
张三
---------------
0 - 李四
1 - 王五
2 - 张三(1)代码第1处 for 循环中使用了 enumerate() 函数,该函数在上文的 2.3节—遍历元组中介绍过了,但需要注意的是,此时遍历 i 不是索引,只是遍历集合的次数。
4.4 不可变集合
不可变集合类型是 frozenset,创建不可变集合应使用 frozenset([iterable]) 函数,不能使用大括号 { }。
在 Python Shell 中运行示例程序如下:
>>> student_set = frozenset({'张三', '李四', '王五'}) # --1
>>> student_set
frozenset({'王五', '李四', '张三'})
>>> type(student_set)
>>> student_set.add('董六') # --2
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'frozenset' object has no attribute 'add'
>>> a = (21, 32, 43, 45)
>>> seta = frozenset(a) # --3
>>> seta
frozenset({32, 45, 43, 21}) (1)上述代码第1处是创建不可变集合,frozenset() 函数的参数 {'张三', '李四', '王五'} 是另一个集合对象,可以作为 frozenset() 函数的参数。
(2)代码第3处使用了一个元组对象 a 作为 frozenset() 的参数。
(3)由于创建的是不可变集合,集合内容不能被修改,所以试图修改会发生错误,见代码第2处,使用 add() 方法发生了错误。
4.5 集合推导式
集合推导式与列表推导式类似,区别只是输出结果是集合。修改 3.7节—列表推导式中的 list_derivation.py 代码,给出集合推导式的代码如下:
代码清单:set_derivation.py
# coding=utf-8
# 代码文件: 集合/set_derivation.py
# 集合推导式的运用
n_set = {x for x in range(100) if x % 2 == 0 if x % 5 == 0}
print(n_set)运行结果:
{0, 70, 40, 10, 80, 50, 20, 90, 60, 30}由于集合是不能有重复元素的,集合推导式输出的结果会过滤掉重复的元素,示例代码如下:
input_list = [2, 3, 2, 4, 5, 6, 6, 6]
n_list = [(x ** 2) for x in input_list] # 列表推导式 --1
print(n_list)
n_set2 = {(x ** 2) for x in input_list} # 集合推导式 --2
print(n_set2)输出结果:
[4, 9, 4, 16, 25, 36, 36, 36]
{4, 36, 9, 16, 25}(1)上述代码第1处是列表推导式,代码第2处是集合推导式,从输出结果可以看出集合推导式是没有重复的元素出现的。
五、字典
字典(dict)是可迭代的、可变的数据结构,通过键来访问元素。字典结构比较复杂,它是由两部分视图构成的,一个是键(key)视图,另一个是值(value)视图。键视图不能包含重复元素,而值集合可以,键和值是成对出现的。
【说明】字典(dict)这种类型的数据结构在有些编程语言中也叫 map(映射)。
下图4 所示是字典结构的“国家代号”。键是国家代号,值是国家名称。
 图4 字典结构的国家代号
图4 字典结构的国家代号
【提示】字典更适合通过键来快速访问值,就像查英文字典一样,键就是要查找的英文单词,而值是英文单词的翻译和解释等内容。有的时候,一个英文单词会对应多个翻译和解释,这也是与字典集合特性像对应的。
5.1 创建字典
字典类型是 dict,创建字典可以使用 dict() 函数,或者用大括号 { } 将 “键 : 值” 对括起来,“键 : 值” 对之间用冒号分隔。
在 Python Shell 中运行示例代码如下:
>>> dict1 = {102: '张三', 105: '李四', 109: '王五'} # --1
>>> len(dict1)
3
>>> dict1
{102: '张三', 105: '李四', 109: '王五'}
>>> type(dict1)
>>>
>>> dict1 = {}
>>> dict1
{}
>>> dict({102: '张三', 105: '李四', 109: '王五'}) # --2
{102: '张三', 105: '李四', 109: '王五'}
>>> dict(((102, '张三'), (105, '李四'), (109, '王五'))) # --3
{102: '张三', 105: '李四', 109: '王五'}
>>> dict([(102, '张三'), (105, '李四'), (109, '王五')]) # --4
{102: '张三', 105: '李四', 109: '王五'}
>>> t1 = (102, '张三')
>>> t2 = (105, '李四')
>>> t3 = (109, '王五')
>>> t = (t1, t2, t3)
>>> dict(t) # --5
{102: '张三', 105: '李四', 109: '王五'}
>>> list1 = [t1, t2, t3]
>>> dict(list1) # --6
{102: '张三', 105: '李四', 109: '王五'}
>>> dict(zip([102, 105, 109], ['张三', '李四', '王五'])) # --7
{102: '张三', 105: '李四', 109: '王五'} (1)上述代码第1处是使用大括号 "键 : 值" 对创建字典,这是最简单的创建字典方式。创建一个空字典的表达式是 { }。获得字典长度(即键值对个数)也是使用 len() 函数。
(2)代码第2处、第3处、第4处、第5处都是使用 dict() 函数创建字典。代码第2处 dict() 函数参数是另一个字典 {102: '张三', 105: '李四', 109: '王五'},使用这种方式创建字典不如直接使用大括号 "键 : 值" 对方式。
(3)代码第3处和第5处的 dict() 函数参数是一个元组,这个元组中要包含三个只有两个元素的元组,创建过程参考下图5所示。
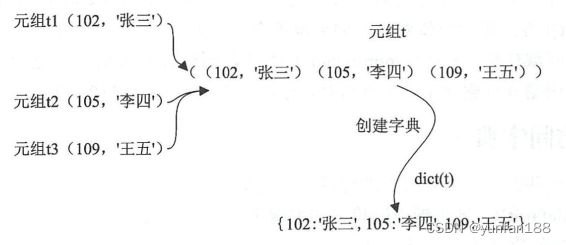 图5 使用元组对象创建字典过程
图5 使用元组对象创建字典过程
(4)代码第4处和第6处 dict() 函数参数是一个列表,这个列表中包含三个只有两个元素的元组。
(5)代码第7处使用了 zip() 函数,zip() 函数将两个可迭代列表对象打包成元组,在创建字典时,可迭代对象元组需要两个可迭代对象,第一个对象是键 ([102, 105, 109]),第二个是值 (['张三', '李四', '王五']),它们包含的元素个数相同,并且一 一对应。
【注意】使用 dict() 函数创建字典时还可以使用一种 key == value 形式参数,语法如下:
dict(key1=value1, key2=value2, key3=value3 ...)
key = value 形式只能创建键是字符串类型的字典,使用时需要省略包裹字符串的引号(包括双引号或单引号)。
在 Python Shell 中运行示例代码如下:
>>> dict(102 = '张三', 105 = '李四', 109 = '王五') # --1 File "", line 1 dict(102 = '张三', 105 = '李四', 109 = '王五') ^^^^^ SyntaxError: expression cannot contain assignment, perhaps you meant "=="? >>> dict('102' = '张三', '105' = '李四', '109' = '王五') # --2 File " ", line 1 dict('102' = '张三', '105' = '李四', '109' = '王五') ^^^^^^^ SyntaxError: expression cannot contain assignment, perhaps you meant "=="? >>> dict(S102 = '张三', S105 = '李四', S109 = '王五') # --3 {'S102': '张三', 'S105': '李四', 'S109': '王五'} (1)代码第1处试图通过上述 dict() 函数创建键是整数类型的字典,结果发生了错误。
(2)代码第2处试图使用字符串作为键创建字典,但是该 dict() 函数需要省略字符串的引号,因此会发生错误。
需要注意的是,本例中键是由数字构成的字符串,它们很特殊,如果省略包裹它们的引号,那么它们会被认为是数字,使用该 dict() 函数是不允许的。
(3)代码第3处的键在数字前面加了字母 S,这样会被识别为字符串类型,因此能正确创建字典对象。
5.2 修改字典
字典可以被修改,但都是针对键和值同时修改,修改字典操作包括添加、替换和删除键值对。
在Python Shell 中运行示例代码如下:
>>> dict1 = {102: '张三', 105: '李四', 109: '王五'}
>>> dict1[109] # --1
'王五'
>>> dict1[110] = '董六' # --2
>>> dict1
{102: '张三', 105: '李四', 109: '王五', 110: '董六'}
>>> dict1[109] = '张三' # --3
>>> dict1
{102: '张三', 105: '李四', 109: '张三', 110: '董六'}
>>> del dict1[109] # --4
>>> dict1
{102: '张三', 105: '李四', 110: '董六'}
>>> dict1.pop(105)
'李四'
>>> dict1
{102: '张三', 110: '董六'}
>>> del dict1[105]
Traceback (most recent call last):
File "", line 1, in
KeyError: 105
>>> dict1.pop(105, '董六') # --5
'董六'
>>> dict1.popitem() # --6
(110, '董六')
>>> dict1
{102: '张三'} (1)访问字典中元素可通过下标实现,下标参数是键,返回对应的值,代码第1处中 dict1[109] 是取出字典 dict1 中键为 109 的值:'王五'。
(2)字典下标访问的元素也可以在赋值符号 “=” 左边,代码第2处是给字典 110 键赋值,注意此时字典对象 dict1 中并没有 110 键,那么这样的操作会添加 110: '董六' 键值对这一元素。
(3)如果键已存在那么会替换对应的值,如代码第3处会将键 109 对应的值替换为 '张三',虽然此时值视图中已经有 '张三' 了,但仍然可以添加,这说明字典中的值是可以重复的,这里需要再次说明以下,键是不可以重复的。
(4)代码第4处是删除 109 键对应的值,注意 del 是语句不是函数。使用 del 语句删除键值对时,如果键不存在会抛出错误。
(5)还可以使用字典中的 pop(key[, default]) 和 popitem() 方法删除键值对元素。使用 pop() 方法删除键值对时,如果键不存在则返回默认值(即方法参数 default),见代码第5处。键 105 不存在,所以 dict.pop(105, '董六') 返回了设置的默认值 '董六'。
(6)popitem() 方法可以删除任意键值对,返回删除的键值对构成元组,上述代码第6处删除了一个键值对,返回一个元组对象 (110, '董六')。
5.3 访问字典
字典还需要一些方法用来访问它的键或值,这些方法如下:
get(key[, default]) # 通过键返回值,如果键不存在则返回默认值default
items() # 返回字典的所有键值对
keys() # 返回字典键视图
values() # 返回字典值视图在 Python Shell 中运行示例代码如下:
>>> dict1 = {102: '张三', 105: '李四', 109: '王五'}
>>> dict1.get(105) # --1
'李四'
>>> dict1.get(101) # --2
>>> dict1.get(101, '董六') # --3
'董六'
>>> dict1.items() # --4
dict_items([(102, '张三'), (105, '李四'), (109, '王五')])
>>> dict1.keys() # --5
dict_keys([102, 105, 109])
>>> dict1.values() # --6
dict_values(['张三', '李四', '王五'])(1)上述代码第1处通过 get() 方法返回 105 键对应的值,如果没有键对应的值,而且还没有为 get() 方法提供默认值,则不会有返回值,见代码第2处。代码第3处提供了返回值。
(2)代码第4处通过 items() 方法返回字典对象 dict1 所有的键值对。
(3)代码第5处通过 keys() 方法返回字典对象 dict1 所有的键信息,并以列表的形式出现;代码第6处通过 values() 方法返回字典对象 dict1 所有的值信息,也是以列表的形式出现。
在访问字典时,也可以使用 in 和 not in 运算符,但需要注意的是,in 和 not in 运算符一般只是在测试键视图中进行。
在 Python Shell 中运行示例代码如下:
>>> student_dict = {102: '张三', 105: '李四', 109: '王五'}
>>> 102 in dict1
True
>>> '李四' in dict1
False
>>> '李四' not in dict1
True
>>> 101 not in dict15.4 遍历字典
字典遍历也是字典的主要操作。与集合不同,字典有两个视图,因此遍历过程可以只遍历值视图,也可以只遍历键视图,也可以键值同时遍历。这些遍历过程都是通过 for 循环实现的。
示例代码如下:traverse_dict.py
# coding=utf-8
# 代码文件: 字典/traverse_dict.py
# 遍历字典,通过for循环实现
student_dict = {102: '张三', 105: '李四', 109: '王五'}
print('--- 遍历键 ---')
for student_id in student_dict.keys(): # --1
print('学号: ' + str(student_id))
print('--- 遍历值 ---')
for student_name in student_dict.values(): # --2
print('学生: ' + student_name)
print('--- 遍历键:值 ---')
for student_id, student_name in student_dict.items(): # --3
print('学号: {0} -> 学生: {1}'.format(student_id, student_name))运行结果如下:
--- 遍历键 ---
学号: 102
学号: 105
学号: 109
--- 遍历值 ---
学生: 张三
学生: 李四
学生: 王五
--- 遍历键:值 ---
学号: 102 -> 学生: 张三
学号: 105 -> 学生: 李四
学号: 109 -> 学生: 王五(1)上述代码第3处遍历字典的键值对,items() 方法返回键值对元组序列,student_id,student_name 是从元组拆包出来的两个变量。
5.5 字典推导式
因为字典包含了键和值两个不同的结构,因此字典推导式结果可以非常灵活。
字典推导式示例代码如下:dict_derivation.py
# coding=utf-8
# 代码文件: 字典/dict_derivation.py
# 字典推导式的运用
input_dict = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
output_dict = {k: v for k, v in input_dict.items() if v % 2 == 0} # --1
print(output_dict)
keys = [k for k, v in input_dict.items() if v % 2 == 0] # --2
print(keys)运行结果:
{'two': 2, 'four': 4}
['two', 'four'](1)上述代码第1处是字典推导式,注意输入结构不是直接使用字典,因为字典不是序列,可以通过字典的 items() 方法返回字典中键值对序列。
(2)代码第2处也是字典推导式,但只返回键结构。
5.6 字典的其他常用方法
我们使用 dir() 函数来查看 dict 类类型包含哪些方法。在 Python Shell 中输入命令:dir(dict)
>>> dir(dict)
['__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__',
'__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__ior__', '__iter__', '__le__', '__len__',
'__lt__', '__ne__', '__new__', '__or__', '__reduce__', '__reduce_ex__', '__repr__',
'__reversed__', '__ror__', '__setattr__', '__setitem__',
'__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items',
'keys', 'pop', 'popitem', 'setdefault', 'update',
'values']1、clear()方法
clear() 方法用来清空字典中所有的 key-value 对,对一个字典执行 clear() 方法后,该字典就会变成一个空字典。
示例代码如下:
>>> cars = {'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars
{'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars.clear()
>>> cars
{}2、update() 方法
update() 方法可使用一个字典所包含的 key-value 对来更新已有的字典。在执行 update() 方法时,如果被更新的字典中已包含对应的 key-value 对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的 key-value 对,则该 key-value 对会被添加进去。
示例代码如下:
>>> cars = {'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars.update({'BMW': 4.5, 'Porsche': 9.3})
>>> cars
{'BMW': 4.5, 'Benz': 8.3, 'Audi': 7.9, 'Porsche': 9.3}(1)从运行结果可以看出,由于被更新的字典对象 cars 中已包含 key 为 'Audi' 的key-value 对,因此更新时该 key-value 对的 value 将被改写;但被更新的字典 cars 中不包含 key 为 'Porsche' 的 key-value 对,那么更新时就会为原字典增加一个 key-value 对。
3、pop()、popitem() 方法
- pop() 方法用于获取指定 key 对应的 value,并删除这个 key-value 对。
示例代码如下:
>>> cars = {'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars.pop('Audi') # --1
7.9
>>> cars
{'BMW': 8.5, 'Benz': 8.3}(1)上述代码第1处获取键为 'Audi' 对应的值,并删除该键值对。
- popitem() 方法用于随机弹出字典中的一个 key-value 对。
【提示】此处的随机弹出其实是假的,正如列表的 pop() 方法总是弹出列表中最后一个元素,实际上字典的 popitem() 方法其实也是弹出字典中最后一个 key-value 对。由于字典存储 key-value 对的顺序是不可知的,因此开发者感觉字典的 popitem() 方法是“随机”弹出的,但实际上字典的 popitem() 方法总是弹出底层存储的最后一个 key-value 对。
示例代码如下:
>>> cars = {'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars
{'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars.popitem()
('Audi', 7.9)
>>> cars
{'BMW': 8.5, 'Benz': 8.3}从上面的运行结果可以看出,popitem() 方法弹出的是一个元组,因此程序完全可以通过序列解包的方式用两个变量分别接收 key 和 value。
示例代码如下:
>>> cars = {'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> k, v = cars.popitem()
>>> print(k, v)
Audi 7.94、setdefault() 方法
setdefault() 方法也用于根据 key 来获取对应 value 的值。但该方法有一个额外的功能:当程序要获取的 key 在字典中不存在时,该方法会先为这个不存在的 key 设置一个默认的 value,然后再返回该 key 对应的 value。总之,setdefault() 方法总能返回指定 key 对应的 value:如果该 key-value 对存在,则直接返回该 key 对应的 value;如果该 key-value 对不存在,则先为该 key 设置默认的 value,然后再返回该 key 对应的 value。
示例代码如下:
>>> cars = {'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9}
>>> cars.setdefault('Porsche', 9.2) # --1
9.2
>>> cars
{'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9, 'Porsche': 9.2}
>>> cars.setdefault('BMW', 3.4) # --2
8.5
>>> cars
{'BMW': 8.5, 'Benz': 8.3, 'Audi': 7.9, 'Porsche': 9.2}(1)上述第1处调用 setfault() 方法,设置默认值,该 key 在 dict 中不存在,所以新增该 key-value 对。
(2)代码第2处调用 setdefault() 方法,设置默认值,但该 key 在 dict 中已存在,不会修改 dict 的内容。
5、fromkeys() 方法
fromkeys() 方法使用给定的多个 key 创建字典,这些 key 对应的 value 默认都是 None,也可以额外传入一个参数作为默认的 value。该方法一般不会使用字典对象调用(没什么意义),通常会使用 dict 类直接调用。
例如如下示例代码:
>>> a_dict = dict.fromkeys(['a', 'b']) # --1
>>> a_dict
{'a': None, 'b': None}
>>> b_dict = dict.fromkeys((13, 17)) # --2
>>> b_dict
{13: None, 17: None}
>>> c_dict = dict.fromkeys((13, 17), 'Good') # --3
>>> c_dict
{13: 'Good', 17: 'Good'}(1)上述代码第1处,使用类名 dict 直接调用 fromkeys() 方法,列表作为参数,创建包含两个 key 的字典对象 a_dict,value 的默认值为 None。
(2)代码第2处,使用类名 dict 直接调用 fromkeys() 方法,元组作为参数,创建包含两个 key 的字典对象 b_dict,value 的默认值也是 None。
(3)代码第3处,使用类名 dict 直接调用 fromkeys() 方法,元组作为第1个参数,并指定了 value 的默认值:"Good",创建包括两个 key 的字典对象 c_dict,value 的值为 "Good"。
5.7 使用字典格式化字符串
在格式化字符串时,如果要格式化的字符串模板中包含多个变量,后面就需要按顺序给出多个变量,这种方式对于字符串模板中包含少量变量的情形是合适的,但如果字符串模板中包含大量变量,这种按顺序提供变量的方式则有些不合适。可改为在字符串模板中按 key 指定变量,然后通过字典作为字符串模板中的 key 设置值。
例如如下程序:dict_format_str.py
# coding=utf-8
# 代码文件: 字典/dict_format_str.py
# 使用字典格式化字符串
# 在字符串模板中使用key
str_template = 'bookName: %(name)s, bookPrice: %(price).2f, bookAuthor: %(author)s'
book1 = {'name': 'Python Programming Language', 'price': 88.9, 'author': 'Jack'}
# 使用字典为字符串模板中的key传入值
print(str_template %book1)
book2 = {'name': 'Java Programming Language', 'price': 78.9, 'author': 'Mike'}
print(str_template %book2)运行结果:
>python dict_format_str.py
bookName: Python Programming Language, bookPrice: 88.90, bookAuthor: Jack
bookName: Java Programming Language, bookPrice: 78.90, bookAuthor: Mike参考
《Python从小白到大牛(第1版-2018).pdf》第9章 - 数据结构
《疯狂Python讲义(2018.12).pdf》第3章 - 列表、元组和字典