基于mysql的淘宝用户、商品、平台价值分析
文章目录
- 一、项目背景和需求
-
- 1.项目背景及分析目的
- 二、数据集摸底并找出问题
-
- 2.1数据来源
- 2.2数据理解
- 2.3分析思路梳理
-
- 2.3.1 分析流程
- 2.3.2使用人货场拆解方式建立指标体系
- 2.3.3 确认问题
- 三、数据清洗
-
- 3.1 导入数据
- 3.2 选择子集
- 3.2 列名重命名
- 3.3 查找重复值并删除
- 3.4 处理错误值-以类别字段为主-‘行为类型’
- 3.5 查找缺失值
- 3.6 处理与时间相关的问题(一致化处理)
- 3.7 异常值处理(超出目标分析范围的数据)
- 3.8 最终数据范围(维度和数量)
- 四、指标体系建设及分析问题
-
- 4.1 用户指标体系
-
- 4.1.1 基础指标
-
- 4.1.1.1 UV、PV、浏览深度(PV/UV)的每日变化趋势
- 4.1.1.2 PV、UV每时变化趋势
- 4.1.1.3 复购率和跳失率
- 4.1.1.4用户留存率(按日)统计:
- 4.1.2 RFM模型分析
-
- 4.1.2.1 R维度分析
- 4.1.2.2 F维度分析(一定时间内的消费频率)
- 4.1.2.3整合结果:
- 4.1.3.4RFM模型整体分析结论:
- 4.2 商品相关指标分析
-
- 4.2.1 商品销售情况
- 4.2.2 商品销量与点击量、收藏量、加购量间的相关性分析
- 4.2.3 商品四象限划分图
- 4.2.4 “长尾效应”分析
- 五、平台指标体系
-
- 5.1 建立用户各行为转化漏斗模型
- 5.3 建立独立访客漏斗模型
- 六 结论
-
- 6.1 用户分析
- 6.2 用户精细化运营
- 6.3 商品分析
- 6.4 平台指标分析
一、项目背景和需求
1.项目背景及分析目的
随着互联网和大数据的发展,电商的数量已经呈现井喷式增长,到了一定的瓶颈期,那么通过数据分析挖掘消费者潜在需求、消费偏好成为平台运营过程中的重要环节。
所以本项目基于淘宝平台用户行为数据,在mysql关系型数据库,探索如何对用户行为规律,挖掘隐式反馈信息,寻找高价值用户、高贡献商品,并分析产品功能,优化产品路径。
关于隐式反馈:
推荐系统中用户对物品的反馈分为显式和隐式反馈。
显式反馈 (如评分、评级) 用户明确表示对物品喜好的行为。
隐式反馈 (如浏览、点击、加入购物车)不能明确反映用户喜好的行为。
显性反馈数值代表偏好程度,隐性反馈数值代表置信度。
二、数据集摸底并找出问题
2.1数据来源
阿里云天池
[https://tianchi.aliyun.com/dataset/dataDetail?dataId=649&userId=1]
2.2数据理解
User Behavior 是来自淘宝的用户行为数据集,用于隐式反馈的推荐问题。数据集由阿里巴巴提供。随机选取了大约 200 万用户在 2017 年 11 月 25 日至 12 月 3 日期间具有点击、购买、添加商品到购物车和商品偏好等行为。
数据集包含了2017年11月25日至2017年12月3日之间,有行为的约两百万随机用户的所有行为,包括点击、购买、加购、喜欢。
| 文件名称 | 说明 | 包含特征 |
|---|---|---|
| UserBehavior.csv | 包含所有的用户行为数据 | 用户ID,商品ID,商品类目ID,行为类型,时间戳 |
数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| 时间戳 | 行为发生的时间戳 |
用户行为类型共有四种,它们分别是:
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 商品加入购物车 |
| fav | 商品进行收藏 |
2.3分析思路梳理
2.3.1 分析流程
指标体系的构建设计应该提前设计,本案例指标体系的构建基于“人货场”理论
关于“人货场”三要素:
人货场,是指影响销售的三个重要因素(不是三个指标)
1.人:来自销售人员、顾客的因素
销售人员:人员是否足够,素质是否满意,执行是否到位?
顾客:是否有足够客户到来,是否有成交,成交消费力如何?
2.货:商品因素
商品质量:种类是否丰富、款式是否能够吸引、有没有爆款
商品数量:商品备货是否充足,畅销品是否短缺,滞销品有多少
3.场:卖场/门店/销售渠道因素
卖场数量:线下门店数量/位置,线上引流渠道数量/类型
卖场质量:线下门店装修、面积、陈列,线上引流渠道的转化路径,页面设计
2.3.2使用人货场拆解方式建立指标体系
最终结果:评价“用户、商品、平台”三者质量
人:(用户)是整个运营的核心,所有的举动都围绕着如何让更多的人有购买行为,让他们买的更多、买的更贵,所以对人的洞察是一切行为的基础。目前平台上的主力消费人群有哪些特征,他们对货物有哪些需求,他们活跃在哪一些平台,还有哪些消费力的人目前不在平台上,对这些问题的回答指向了接下来的行动。
| 指标 | 细化指标 | 说明 |
|---|---|---|
| 浏览 | PV | (pageview)是页面浏览量 |
| UV | (Unique Visitor)是一定时间内访问网页的人数,正式名称独立访客数(一个网站或者一个页面),也可以说是终端数 | |
| 流量质量 | PV/UV | 浏览深度 |
| ROI | 投资回报率(ROI)=年利润或年均利润/投资总额 *100% | |
| 成交用户 | 新客数 | (一般当天的算新用户,当日激活或者新增) |
| 老客数 | ||
| 客单价 | 当日消费总价/顾客数(新+老),客单价应该是稳的,突然多/少,购买力特别强的,疫情影响客单价下降 | |
| DAU | 日活跃用户 | |
| MAU | 月活跃用户 |
货: 对应供给,涉及到了货品分层,哪一些是红海(指的销量高、利润少、竞争多的商品,属于常规商品),哪一些是蓝海(销量少、利润高、竞争少的商品),如何进行动态调整,是要做自营还是平台,以满足消费者的需求
场: 就是消费者在什么场景下,以什么样的方式接触了这个商品。早期导购比较简单,目前场就比较丰富,但也暴露了一些电商平台(eg:淘宝or京东)在导购方面的一些问题,比如内容营销,目前最好的可能是微博KOL生态和小红书,甚至微信,而不在电商自己的场。如何做一个全域的打通,和消费者进行多触点的接触,比如社交和电商的联动,来完成销售转化,这也就是所谓的「全域营销」
平台可以理解为电商网站,但是现在这个场的概念已经前后有所延伸说,往前延伸指的是引流,往后延伸指的是后期的售后、物流等。
2.3.3 确认问题
本次分析的目的是想对用户行为数据分析,为以下问题提供解释和改进建议:
- 从场的角度:基于漏斗模型的用户购买流程各环节分析指标,确定各个环节的转换率,便于找到需要改进的环节;
- 从商品角度:商品分析:找出热销商品,研究热销商品特点;
- 从用户的角度:基于RFM模型找出核心付费用户群,对这部分用户进行精准营销
三、数据清洗
3.1 导入数据
点开Mysql workbench
①新建一个库
DROP DATABASE IF EXISTS `用户行为分析`;
CREATE DATABASE `用户行为分析`;
USE `用户行为分析`;
②导入外部数据,使用Navicat连接Mysql,选择导入200万行数据。
ps:在开始分析一份数据的时候,第一时间先进行备份。(因为吃过一次数据不小心被删的亏,所以养成了拿到一份数据先备份):
CREATE TABLE USERBEHAVIOR_BACKUPS AS
SELECT *
FROM UserBehavior
③查看数据,对应2.2数据理解,第一列为用户ID,第二列为商品ID,第三列为商品类目ID,第四列为行为类型,第五列为时间戳,从数据面板发现列名和一些字段的数据类型需要修改。

3.2 选择子集
因为导入原始数据共有一亿多条,这里导入了200w条数据,为了查看数据是否已成功导入,查看表结构是否正确:
#查看数据是否为200w条
SELECT COUNT(*) FROM userbehavior;
#查看表结构,只看前20行即可
SELECT * FROM userbehavior LIMIT 20;
结果: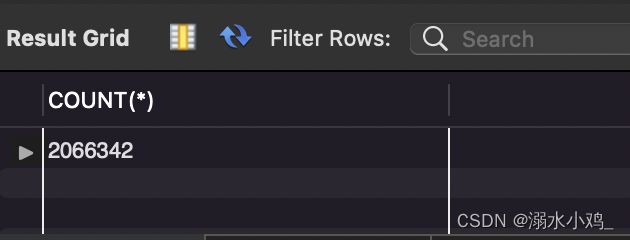
这里多出60w的数据,所以对200w以后的数据进行删除
但是发现导入的数据中第一个字段有重复值,所以增加一个ID标识列并设置为主键,便于删除:
ALTER TABLE userbehavior ADD COLUMN
id INT(8) PRIMARY KEY AUTO_INCREMENT;
处理后的表格如下: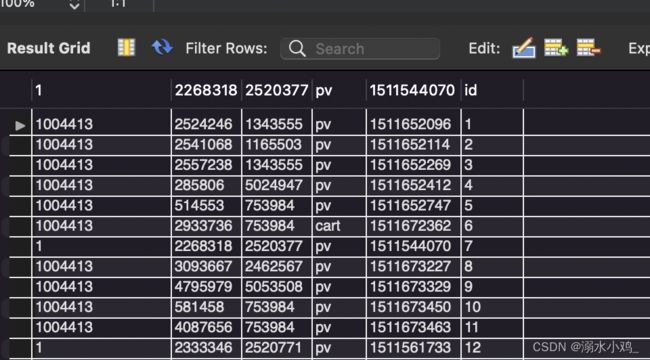
可以进行对200w以后的数据进行删除:
DELETE FROM userbehavior WHERE id > 2000000;
3.2 列名重命名
可以直接在类型面板上双击Column直接进行更改字段名
3.3 查找重复值并删除
①检查是否存在重复值
SELECT * FROM userbehavior
GROUP BY User_ID, Item_ID, Category_ID, Behavior_type, Time_date, id
HAVING COUNT(*)>1;
结果如下:
以上步骤完成后可以将表示id列删掉:
alter table userbehavior drop column id;
②修改数据类型:行为分析原来为枚举值,由于不再进行数据增加,因此设为VARCHAR。
3.4 处理错误值-以类别字段为主-‘行为类型’
select behavior_type, count(behavior_type)
from userbehavior
group by behavior_type with rollup
结果:行为数据和枚举出的四个类型保持一致,该列没有问题
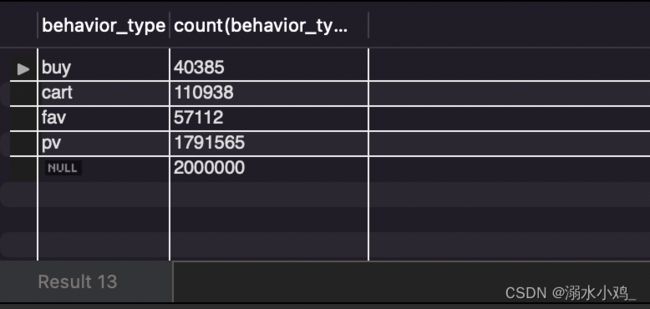
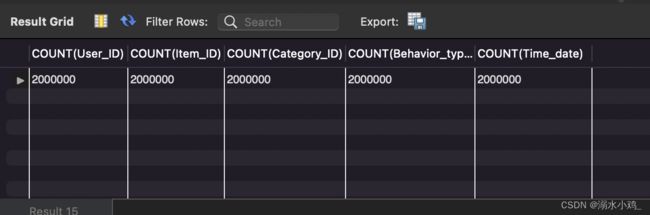
3.5 查找缺失值
SELECT
COUNT(User_ID),
COUNT(Item_ID),
COUNT(Category_ID),
COUNT(Behavior_type),
COUNT(Time_date)
FROM userbehavior;
结果各字段的数量相等,所以不存在缺失值:
3.6 处理与时间相关的问题(一致化处理)
目前时间列可读性较差,不利于我们要做的时间分析,所以需要进行转化,变成我们常见常用的时间格式。
专门处理时间戳的函数:From_unixtime;
作用:将MYSQL中以INT存储的时间以"YYYY-MM-DD"格式来显示。
语法:FROM_UNIXTIME(时间戳,时间格式)
常见的时间格式:
%Y年,%m月,%d日,eg:2022-01-01
%H时,%I分,%s秒,eg:11:59:30
因此需要将现有的时间列分为日期时间、日期、小时三列
①添加新列Date_time,根据Time_date返回日期时间(%Y年,%m月,%d日 %H时,%I分,%s秒 ):
ALTER TABLE userbehavior
add Date_time VARCHAR(255);
UPDATE userbehavior
set Date_time = from_unixtime(Time_date, '%Y-%m-%d %H:%i:%s')
②添加新列Date,根据Time_date返回日期
ALTER TABLE userbehavior
add Date VARCHAR(255);
UPDATE userbehavior
set Date = from_unixtime(Time_date, '%Y-%m-%d')
③添加新列Time,根据Time_date列返回时间
ALTER TABLE userbehavior
add Time VARCHAR(255);
UPDATE userbehavior
set Time = from_unixtime(Time_date, '%H:%i:%s')
根据以上得出的结果如下:

3.7 异常值处理(超出目标分析范围的数据)
需要检查日期是否都在需要分析的时间范围内,即2017年11月25日至2017年12月3日之间
select max(Date), min(Date)
from userbehavior
结果:
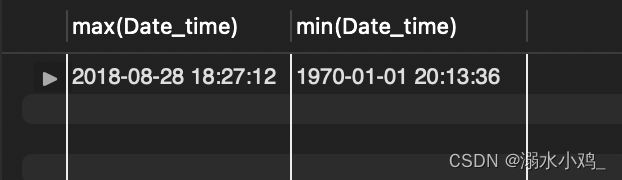
最大值日期超过2017-12-3,最小日期超过2017-11-25,因此需要删除2017年11月25日至2017年12月3日之外的数据
DELETE FROM USERBEHAVIOR
WHERE DATE < '2017-11-25' OR DATE > '2017-12-03';
共删除了991条时间异常数据
3.8 最终数据范围(维度和数量)
| 维度 | 数量 |
|---|---|
| 用户数量 | 19544 |
| 商品数量 | 628886 |
| 商品类目数量 | 6492 |
| PV | 1790224 |
| Buy | 40243 |
| Cart | 111015 |
| Fav | 57526 |
| 所有行为数量 | 1999008 |
四、指标体系建设及分析问题
基于人-货-场指标体系
使用MySQL进行分析,Excel进行可视化展示
4.1 用户指标体系
基础指标体系(UV/PV/留存率)+RFM模型分析
4.1.1 基础指标
4.1.1.1 UV、PV、浏览深度(PV/UV)的每日变化趋势
UV:独立访客数,统计distinct user_id的数量,需要按日统计(分组);
PV:页面流量次数,统计behavior_type = 1的记录数,需要按日统计(分组);
PV/UV:平均一个独立访问者所浏览的页面访问量
代码如下:
select date, count(distinct user_id) 'uv',
count(if(behavior_type = 'pv', 1, null)) 'pv',
count(if(behavior_type = 'pv', 1, null))/count(distinct user_id) 'pv/uv'
from userbehavior
group by date
结果如下:
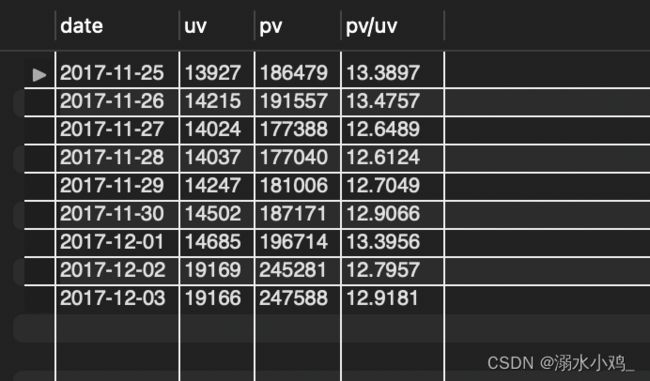
将以上数据导入excel中,绘制PV、UV每日变化趋势图。
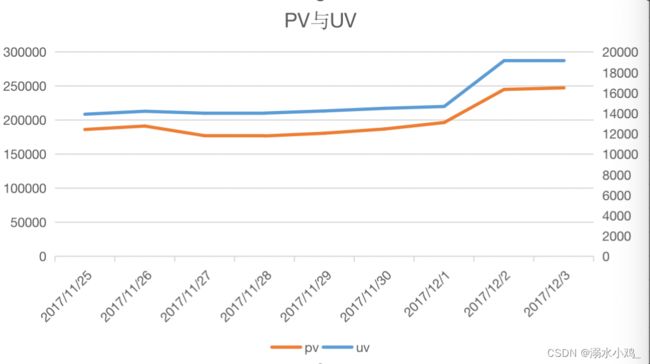
发现在2017年11月25日-2017年12月3日期间,PV与UV随日期的变化趋势相似,11月25日-12月1日较平稳,12月2日开始有明显增长,增长率约为28%,查询日历可以发现这两天为周末,但11.25 ~26同为周末,所以第二个周末的增幅与周末的相关度较小,与淘宝的双十二预热有关,全平台的预热会使的打开淘宝与访客数出现增长。
4.1.1.2 PV、UV每时变化趋势
select substring_index(Time,':', 1) '小时',
count(distinct user_id) '每时的用户数',
count(if(behavior_type = 'pv', 1, null)) '点击',
count(if(behavior_type = 'cart', 1, null)) '加购',
count(if(behavior_type = 'fav', 1, null)) '收藏',
count(if(behavior_type = 'buy', 1, null)) '购买'
from userbehavior
group by substring_index(Time,':', 1)
结果如下:
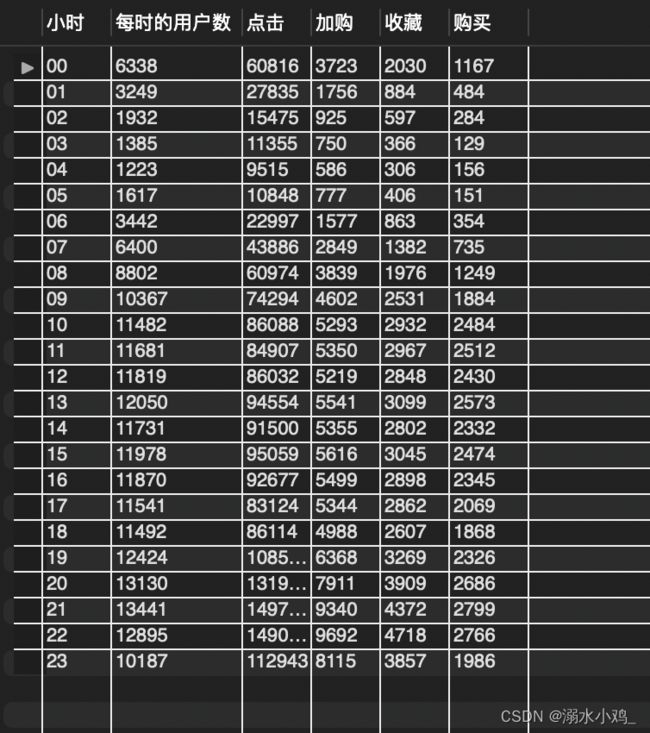
将计算出的数据导入Excel中进行可视化分析:

从上图可以看出:
(1)四种行为的分布趋势基本一致。
(2)每天的0点到3点,各项指标都会快速降低,在4点左右降到一天内的最低值,从5点开始用户活跃度快速上升,从10点至18点用户活跃度平稳但是在12点和17点有小幅度下降(符合上班、上学人群作息规律),用户在晚上18点到23点会频繁点击浏览网页,收藏与加入购物车数量也随之增加。
(3)其中购买曲线与收藏曲线趋势更为接近,在一定程度上说明客户对于收藏商品更为偏爱,然而在购物环节中收藏和加入购物车都是确定购物意向的行为,没有先后之分,所以将这两个环节合并为购物环节中的一步,可以关注客户购物车和收藏的商品进行精准推送。
4.1.1.3 复购率和跳失率
- 复购率 = 购买次数两次及其以上的人数/有购买行为的用户总数
- 跳失率 = 只有浏览行为的用户数/总用户数
因为后面计算跳失率还会用到以user_id分组的用户行为数据,所以在这里先创建一个视图方便后续查询
CREATE VIEW 用户行为数据汇总 AS
SELECT user_id,
COUNT(Behavior_type) AS 用户行为总数,
SUM(CASE WHEN `Behavior_type` = 'pv' THEN 1 ELSE 0 END) AS '点击',
SUM(CASE WHEN `Behavior_type` = 'buy' THEN 1 ELSE 0 END) AS '购买',
SUM(CASE WHEN `Behavior_type` = 'cart' THEN 1 ELSE 0 END) AS '加购',
SUM(CASE WHEN `Behavior_type` = 'fav' THEN 1 ELSE 0 END) AS '收藏'
FROM USERBEHAVIOR_BACKUPsecond
GROUP BY User_ID
ORDER BY COUNT(Behavior_type) DESC;
结果如下:

①复购率计算
在某时间窗口内重复消费用户(消费两次及以上的用户)在总消费用户中占比
select count(if (购买 > 1, 1, null)) as '复购',
count(if (购买 > 0, 1, null)) as '总消费',
concat(round(count(if(购买 > 1, 1, null)) * 100/count(if(购买 > 0, 1, null)),2),'%') as '复购率'
from 用户行为数据汇总

可看到复购率高达65.98%,得出结论:淘宝用户忠诚度较高
②跳失率计算
简单地说,就是访客只访问一个页面就离开了。一个较高的跳失率是不利于店铺转化率提升以及店铺的发展的,在这里若是‘用户行为总数’的数据是1说明用户只有一个行为,也可以说用户只点击了一个页面就离开了。
select sum(case when 用户行为总数 = 1 then 1 else 0 end) '一个行为',
sum(case when 用户行为总数 > 0 then 1 else 0 end) '总行为人数',
concat
(round(sum(case when 用户行为总数 = 1 then 1 else 0 end)*100/ sum(case when 用户行为总数 > 0 then 1 else 0 end),2),'%') '跳失率'
from 用户行为数据汇总

查询可得在统计区间内(9天)仅访问APP一次的用户数量为1,跳失率为0.01%,说明商品内容、推荐机制等对用户有比较强的吸引力
综合复购率和跳失率来看,淘宝APP的用户忠诚度较高,且内容质量高,可以吸引用户持续使用APP,可以重视用户关系,进一步培养用户忠诚度。
p.s:根据《精益数据分析》中对电子商务模式的总结,用户复购率以90天为统计区间的可靠性更高,当然这次分析根据淘宝APP的用户复购率可以得出淘宝APP目前处于“忠诚度模式”中,所以不要将精力放在获取如何获取更多新用户上,要维护老用户的忠诚度,如提高客服素质,尽可能简化购买流程,鼓励用户使用收藏、撰写评论等。
4.1.1.4用户留存率(按日)统计:
用户留存率即为活跃用户留存率(eg:某天100个用户活跃,过了3天剩下50个,即活跃留存率为50%)
首先先建立一个新表用来计算留存率,并得出以2017-11-25作为第一天的用户总数
--第一天用户数
create table retention_rate
as select count(distinct user_id) as 第一天新用户数
from userbehavior
where dates = '2017-11-25';
n日后留存率=(注册后的n日后还登录的用户数)/第一天新增总用户数
这里以2017-11-25作为第一天,计算次日、3日、5日、7日留存率。
先计算第二天留存用户数:
-- 第二天留存用户数
alter table retention_rate add column 第二天留存用户 INT;
update retention_rate set 第二天留存用户=
(select count(distinct user_id) from userbehavior
where date = '2017-11-26'
and user_id in (SELECT user_id FROM userbehavior WHERE date = '2017-11-25'));
--- 第三天留存用户数
alter table retention_rate add column 第三天留存用户 int;
update retention_rate set 第三天留存用户=
(select count(distinct user_id) from userbehavior
where date = '2017-11-27'
and user_id in (SELECT user_id FROM userbehavior WHERE date = '2017-11-25'));
--- 第五天留存用户数
alter table retention_rate add column 第五天留存用户 int;
update retention_rate set 第五天留存用户=
(select count(distinct user_id) from userbehavior
where date = '2017-11-29'
and user_id in (SELECT user_id FROM userbehavior WHERE date = '2017-11-25'));
--- 第七天留存用户数
alter table retention_rate add column 第七天留存用户 int;
update retention_rate set 第七天留存用户=
(select count(distinct user_id) from userbehavior
where date = '2017-12-01'
and user_id in (SELECT user_id FROM userbehavior WHERE date = '2017-11-25'));
结果如下:
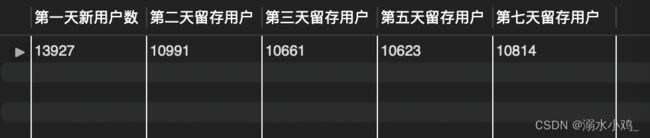
转换成留存率:
SELECT CONCAT(ROUND(第二天留存用户/第一天新用户数*100,2),'%')AS 次日留存率,
CONCAT(ROUND(第三天留存用户/第一天新用户数*100,2),'%')AS 三日留存率,
CONCAT(ROUND(第五天留存用户/第一天新用户数*100,2),'%')AS 五日留存率,
CONCAT(ROUND(第七天留存用户/第一天新用户数*100,2),'%')AS 七日留存率
from retention_rate;
结果如下:

由上表数据,次日、3日、5日、7日留存率均维持在76%左右,数据作为周留存率来看,表现还是非常优秀的,但作为次日留存来看,就不是很理想了,可以结合产品设计和新用户转化路径来分析用户的流失原因,通过不断的修改和调整来降低用户流失,提升次日留存率;另外,12月1日的留存率相较之前有1%-2%的上涨,可能是因为当天12月1日是星期五,正好是客户活跃度上升的一个转折点,也可能是有购物优惠活动,可以考虑促销活动能为提升留存带来一定正向的影响。
4.1.2 RFM模型分析
RFM模型是衡量客户价值和客户创利能力的重要工具和手段,其中由3个要素构成了数据分析最好的指标,分别是:
- R-Recency(最近一次购买时间)
- F-Frequency(消费频率)
- M-Money(消费金额)
由于原数据源没有相关的金额数据,暂且通过 R 和 F 的数据对客户价值进行打分,最终按照综合分数对用户分层。
4.1.2.1 R维度分析
由于数据集包含的时间是2017年11月25日至2017年12月3日之间,这里选取2017年12月4日作为计算日期,统计客户最近发生购买行为的日期距离2017年12月4日间隔几天,由于整个数据集区间为9天,每2天为一个区间:
0~2天设置为3
3~5天设置为2
6~8天设置为1
-- r指标分析:建立r视图,将用户最近一次购买时间,给出相应分数
-- 获取每个用户最近购买时间(创建试图方便后续查询)
drop view if exists user_recency;
create view user_recency as
select user_id, max(date) 'recent_buy_time'
from userbehavior
where behavior_type = 'buy'
group by user_id;
-- 计算每个用户最近购买时间的距离,根据相差的天数给予一定的分数,创建试图,后续会用到 r_value。
drop view if exists r_level;
create view r_level as
select user_id, recent_buy_time, datediff('2017-12-04', recent_buy_time) '间隔',
(case when datediff('2017-12-04', recent_buy_time) <=2 then 3
when datediff('2017-12-04', recent_buy_time) between 3 and 5 then 2
else 1 end) 'r_value'
from user_recency;
--计算分值分布情况
select a.r_value,COUNT(.r_value)
from (select user_id, recent_buy_time, datediff('2017-12-04', recent_buy_time) '间隔',
(case when datediff('2017-12-04', recent_buy_time) <=2 then 3
when datediff('2017-12-04', recent_buy_time) between 3 and 5 then 2
else 1 end) 'r_value'
from user_recency) a
group by a.r_value
结果如下:
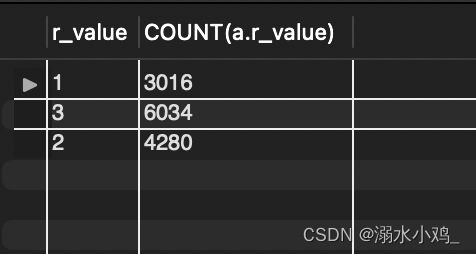
使用Excel进行可视化以后如图所示:

r_value = 3 表示有超过半数的客户会在购买第二天后就再进行购买,说明淘宝APP现在已经有比较好的用户粘性。
4.1.2.2 F维度分析(一定时间内的消费频率)
F指标计算就是求出每个用户消费次数,拿到具体消费次数以后对消费情况进行评分
-- f指标分析:建立f视图
drop view if exists user_buy_fre;
create view user_buy_fre as
select user_id, count(behavior_type) 'buy_frequency'
from userbehavior
where behavior_type = 'buy'
group by user_id
order by buy_frequency desc;

可以看到最大值为72,将其分为6个区间
1 ~ 9:1分 10 ~ 19:2分 20 ~ 29:3分
30 ~ 39:4分 40 ~ 49:5分 50分以上:6分
-- 进行区间划分,建立视图,后续整合需要用到
drop view if exists f_level;
create view f_level as
select user_id, buy_frequency, (
case when buy_frequency between 1 and 9 then 1
when buy_frequency between 10 and 19 then 2
when buy_frequency between 20 and 29 then 3
when buy_frequency between 30 and 39 then 4
when buy_frequency between 40 and 49 then 5
else 6 end) 'f_value'
from user_buy_fre;
-- 进行计算分值分布情况
select b.f_value, count(b.f_value)
from (select user_id, buy_frequency, (
case when buy_frequency between 1 and 9 then 1
when buy_frequency between 10 and 19 then 2
when buy_frequency between 20 and 29 then 3
when buy_frequency between 30 and 39 then 4
when buy_frequency between 40 and 49 then 5
else 6 end) 'f_value'
from user_buy_fre) b
group by b.f_value
结果如下: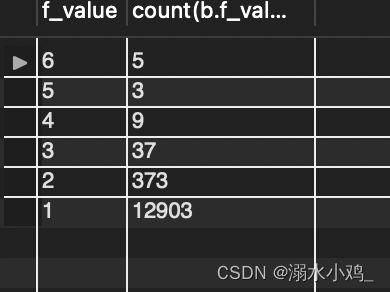
将数据导入Excel中进行可视化:
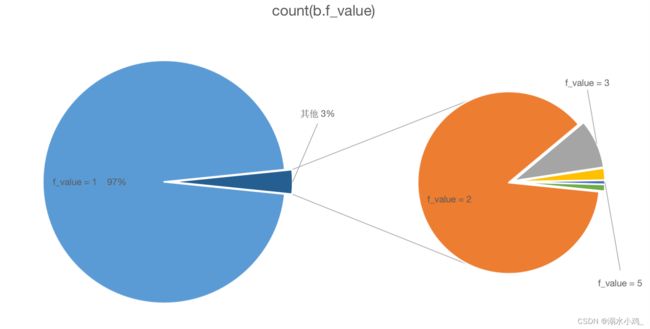
由此可见,消费1-9次的人占97%
4.1.2.3整合结果:
根据r、f的均值对用户进行分层:
求出R维度的均值(前面已经建立好了视图‘r_level’,在这里可以直接使用):
select avg(r_value) as 'r_avg' from r_level
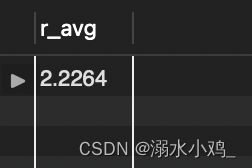
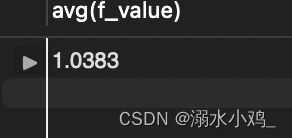
求出F维度的均值:
select avg(f_value) from f_levle
结果如下:
本数据通过最近消费(R)和消费频率(F)建立RFM模型,根据用户八大类等级划分,由于数据没有M值,故只建立四个等级,并且按照最近一次消费的均值和消费频率的均值定高低界限:
- 重要高价值客户:指最近一次消费较近且消费频率较高的客户
- 重要唤回客户:指最近一次消费较远且消费频率较高的客户
- 重要深耕客户:指最近一次消费较近且消费频率较低的客户
- 重要挽留客户:指最近一次消费较远且消费频率较低的客户
代码如下:
--- 拿到每个人的r值和f值(两表关联r_level,f_level),与均值对比
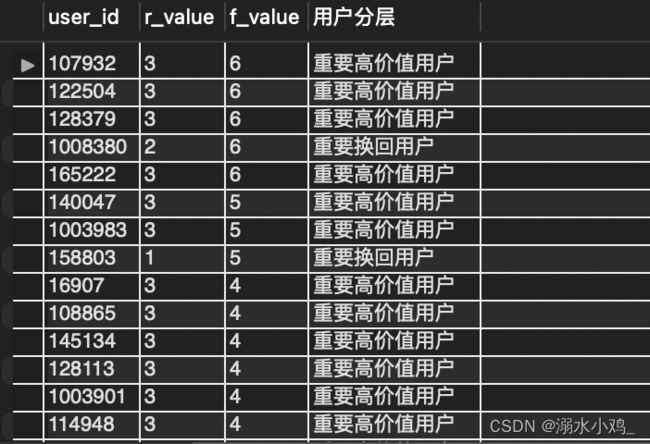
select r.user_id, r.r_value, f.f_value,
(case when r.r_value > 2.2265 and f.f_value > 1.0383 then '重要高价值用户'
when r.r_value < 2.2265 and f.f_value > 1.0383 then '重要唤回用户'
when r.r_value > 2.2265 and f.f_value < 1.0383 then '重要深耕客户'
when r.r_value < 2.2265 and f.f_value < 1.0383 then '重要挽留客户'
end
) as 用户分层
from r_level r join f_level f on r.user_id = f.user_id
结果如下:
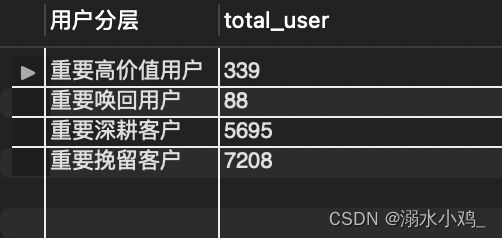
对用户分层进行统计结果如下:
4.1.3.4RFM模型整体分析结论:
通过用户分层可以了解每位顾客的特性,从而实现差异化营销。比如对于 user_id = 107932 的用户,为重点用户需要关注;对于重要深耕客户这类忠诚度高而购买能力不足的,可以适当给点折扣或捆绑销售来增加用户的购买频率。对于 user_value = 1008380 这类忠诚度不高而购买能力强的,需要关注他们的购物习性做精准化营销,制定专属的运营策略来进行维护,如专属优惠、专属客服等,保证其较高的用户粘性;而对于重要挽留客户这类忠诚度不高且购买能力不足的,可能是找到了同类的竞品APP或是产品体验不佳,可以对该部分用户进行调研找到其流失原因,及时进行新活动心有会推送,对用户进行召回。
4.2 商品相关指标分析
可以从点击量、收藏量、加购量、浏览量等四个指标来对商品受欢迎程度进行分析。
4.2.1 商品销售情况
统计所有商品的点击量、收藏量、加购量、购买次数以及购买转化(已购买用户占所有用户的比值),同时找到购买次数、浏览次数、收藏次数和加入购物车次数最多的商品
SELECT COUNT(DISTINCT item_id) FROM userbehavior;
SELECT COUNT(DISTINCT item_id) FROM userbehavior
WHERE behavior_type = 'buy';
select item_id,
sum(case when behavior_type = 'pv' then 1 else 0 end) as '点击',
sum(case when behavior_type = 'fav' then 1 else 0 end) as '收藏',
sum(case when behavior_type = 'cart' then 1 else 0 end) as '加购',
sum(case when behavior_type = 'buy' then 1 else 0 end) as '购买',
round(count(distinct case when behavior_type = 'buy' then user_id else null end)/count(distinct user_id)*100,2) as '购买转化率' --null值不计入count计算
from userbehavior
group by item_id
order by sum(case when behavior_type = 'buy' then 1 else 0 end) desc
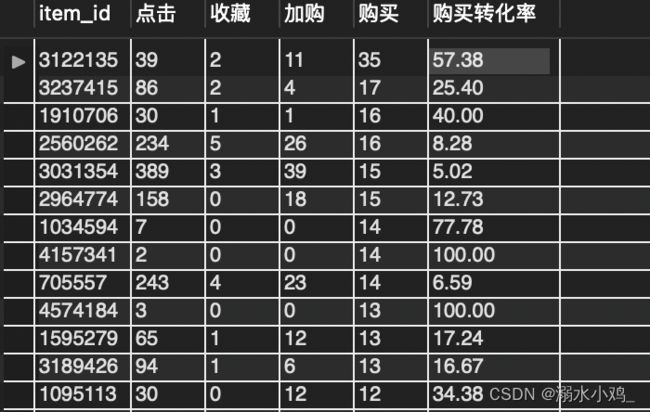
1⃣️ 以购买量排序,得到排名前十的商品编号及其销量:
2⃣️ 以点击量排序,得到排名前十的商品编号及其销量:
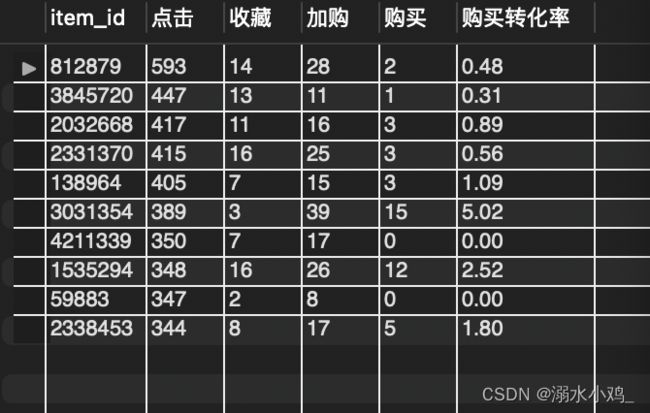
3⃣️ 以收藏率排序,得到排名前十的商品编号及其销量:
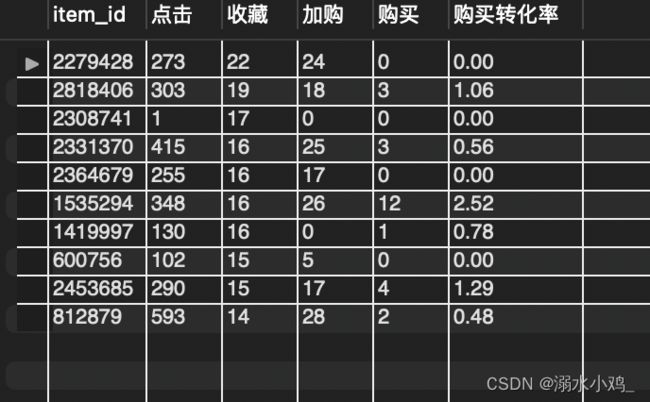
4⃣️ 以加购量排序,得到排名前十的商品编号及其销量:

4.2.2 商品销量与点击量、收藏量、加购量间的相关性分析
用户从浏览->加购/收藏->购买,在购物环节中收藏和加入购物车都是确定购物意向的行为,没有先后之分,所以将这两个环节合并为购物环节中的一步,是否浏览量影响着加购/收藏呢?所以对加购量和浏览量两个表进行连接查看相关性。
1⃣️ 加购量与浏览量间的相关性分析
select a.item_id,a.浏览量, b.加购量
from
(SELECT item_id,COUNT(behavior_type) AS 浏览量
FROM userbehavior
WHERE behavior_type = 'pv'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 10) a
left join
(SELECT item_id,COUNT(behavior_type) AS 加购量
FROM userbehavior
WHERE behavior_type = 'cart'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 10) b on a.item_id = b.item_id
结果:
可以看到在加入浏览量次数最多的前10个商品中,有4个加入了购物车, 说明浏览量与加购量的关系更为直接。
2⃣️ 加购量与销售量间的相关性分析
从收藏/加购再到购买,是否可以认为销量与加购有关呢?
select a.item_id,a.购买量,b.浏览量, c.加购量, d.收藏量
from (SELECT item_id,COUNT(behavior_type) AS 购买量
FROM userbehavior
WHERE behavior_type = 'buy'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 10) a left join
(SELECT item_id,COUNT(behavior_type) AS 浏览量
FROM userbehavior
WHERE behavior_type = 'pv'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 10) b
on a.item_id = b.item_id
left join
(SELECT item_id,COUNT(behavior_type) AS 加购量
FROM userbehavior
WHERE behavior_type = 'cart'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 10) c on a.item_id = c.item_id
left join (SELECT item_id,COUNT(behavior_type) AS 收藏量
FROM userbehavior
WHERE behavior_type = 'fav'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 10) d on a.item_id = d.item_id
结果如下:

四个表连接可以更直观看到在加入购物车次数最多的前10个商品中,第1、3、7位的商品在销量中排第6、3、9, 说明购买量与加购的关系更为直接。
4.2.3 商品四象限划分图
销量与加购关系更直接,加购与浏览量关系更直接,那么基于浏览量->加购/收藏->销量,可以说明浏览量间接影响购买量,对此以浏览量和销量作为分析维度来对商品进行四象限划分,从而得出更具体的优化方案。因为原始数据有200w,因此各取500行
根据浏览量新建一个浏览量前500的表,代码如下
CREATE TABLE 浏览量表 as
SELECT item_id, COUNT(behavior_type) AS 浏览量
FROM userbehavior
WHERE behavior_type = 'pv'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC
LIMIT 500;
然后使用子查询对购买量表进行连接,查询浏览量排行榜前500的商品的销量
SELECT a.item_id, a.浏览量, b.购买量
FROM 浏览量表 a left join (select item_id, COUNT(behavior_type) AS 购买量
FROM usebehavior
WHERE behavior_type = 'buy'
group by item_id) b
on a.item_id = b.item_id
ORDER BY b.购买量 DESC
;
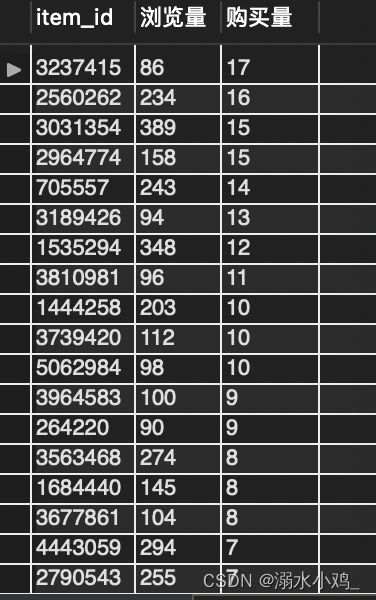
将上述数据导入Excel后,有些商品的购买量为NULL,利用查找替换,将Excel中的null值替换成0,X轴是浏览量,Y轴是购买量,使用Excel散点图可视化后如图:
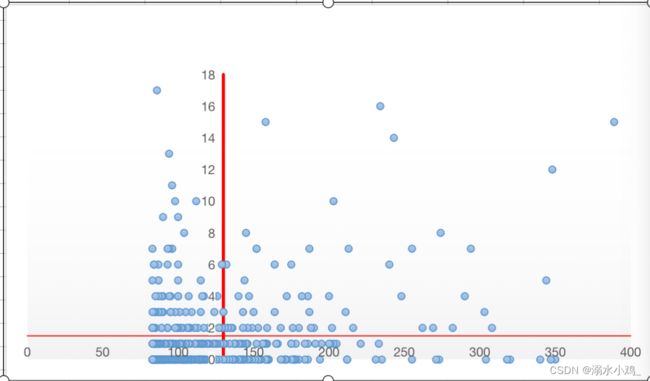
①处于第Ⅰ象限的商品:此类商品的浏览量与销量都处于较高的水平,属于比较受用户欢迎的商品,可能会成为热销产品。
②处于第Ⅱ象限的商品:此类商品的销量高,但是浏览量低,说明该类商品
③处于第Ⅲ象限的商品:浏览量和销量都比较低,说明用户对商品不感兴趣。
④处于第Ⅳ象限的商品:商品浏览量高,但是销量低,说明商品整体的转化率很低。
4.2.4 “长尾效应”分析
互联网的长尾效应:不在传统需求曲线的头部,而在于需求曲线中那条无穷长的尾巴。
按照商品销量对商品进行分类统计:
#查询商品件数及购买次数
SELECT a.购买次数,COUNT(item_id) AS 商品量
FROM (
SELECT item_id,COUNT(behavior_type) AS 购买次数
FROM `userbehavior`
WHERE behavior_type = 'buy'
GROUP BY item_id
ORDER BY COUNT(behavior_type) DESC) a
GROUP BY a.购买次数
ORDER BY a.购买次数;
结果如下:
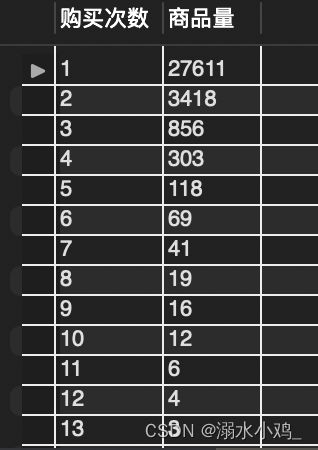
使用Excel的转化图表可视化如下图(X轴为购买次数, Y轴为商品量):

发现购买一件商品的比例占用户购买商品数的85%,说明商品售卖主要依靠长尾商品的累积效应,而非爆款商品的带动。
五、平台指标体系
5.1 建立用户各行为转化漏斗模型
行为指标:点击次数、收藏次数、加购次数、购买次数、购买转化率
- 电商行业常用漏斗模型:APP/网站首页 - 商品详情页 - 添加购物车 - 购物车结算 - 核对订单 - 提交订单 - 选择支付方式 - 支付
- 但是此次数据集只有商品详情页(pv)、加入购物车(cart)和支付(buy),在购物环节中收藏和加入购物车两个环节没有先后之分,所以将这两个环节可以放在一起作为购物环节的一步。最终得到用户购物行为各环节转化率,如下
# 首先创建用户行为视图,因为在4.1.1.3中已经建立了用户行为总数的视图,这里就不需要再重新建立,直接使用即可
SELECT * FROM 用户行为数据汇总;
# 再计算转化率
SELECT CONCAT(ROUND(SUM(点击)/SUM(点击)*100,2),'%') AS 'pv',
CONCAT(ROUND((SUM(加购)+SUM(收藏))/SUM(点击)*100,2),'%') AS 'pv_to_favcart',
CONCAT(ROUND(SUM(购买)/SUM(点击)*100,2),'%') AS 'pv_to_buy'
FROM 用户行为数据汇总;
结果如下:

将数据导入Excel中形成可视化:

由下图可以看到,点击加购或者收藏的百分比在9.4%左右,最后支付的百分比为2.25%左右,第二步到第三部剩余四分之一左右,但第一步到第二步仅剩9.4%,从浏览到确定购买意向只有9.4%左右的转化率,夹点出现在点击-收藏或加购这一过程中,可能原因是用户花了大量时间寻找合适的产品,可以针对性的优化平台的筛选功能,让用户能够更容易的找到合适产品,并将流程指标再细化后进行分析,找出影响用户流失的关键问题点。
5.3 建立独立访客漏斗模型
-- 用户行为数据汇总是之前创建的以user_id分组的行为数据视图
SELECT * FROM 用户行为数据汇总;
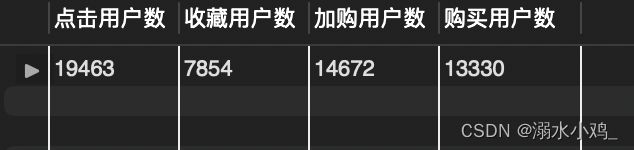
SELECT SUM(CASE WHEN 点击 > 0 THEN 1 ELSE 0 END)AS 点击用户数,
SUM(CASE WHEN 收藏 > 0 THEN 1 ELSE 0 END)AS 收藏用户数,
SUM(CASE WHEN 加购 > 0 THEN 1 ELSE 0 END)AS 加购用户数,
SUM(CASE WHEN 购买 > 0 THEN 1 ELSE 0 END)AS 购买用户数
from 用户行为数据汇总
结果如下
使用Excel进行可视化以后的图表如下:
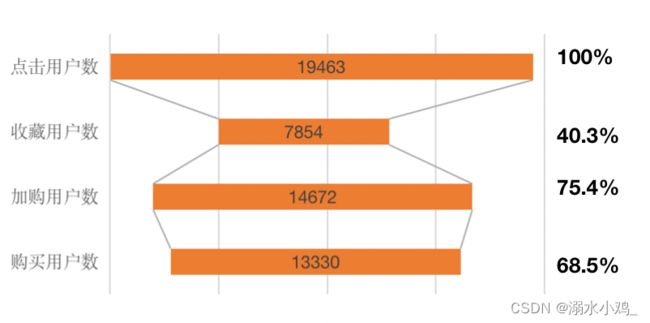
可以看出以独立用户为分析维度,用户并没有在点击以后大量流失,有75%的用户选择了加购,40%的用户选择了收藏,且到最后有68.5%的用户最后选择了支付,整体的购买转化率较高,说明APP整体生态健康,可以满足大多数用户的需求。
综合上面两个分析来看,造成总体从PV到有购买意向只有9.4%的原因是:用户在产生购买意向之前会对商品进行大量的比对,在进行比对后才会产生购买意向,最后进行购买。所以比对环节是提升重点,APP可以从推荐机制入手,以用户日常行为为依据,尽量精准推荐,并且需要匹配相关度更高的关键词,完善商品关键词设置制度和搜索算法,减少用户寻找商品的时间成本。
六 结论
本文分析了淘宝APP用户行为数据共200万条,从三个不同角度提出业务问题,使用RFM模型和漏斗分析数据给出如下结论和建议。
6.1 用户分析
- 从日期维度来看,用户的各种行为数据在周末或者周中的差异不是很大,但是会收到购物节活动的影响,如第二个周欧模就双十二的影响导致用户点击和加购的行为数量明显增加,可以进一步扩大分析范畴,如以整年为单位进行环比分析,标注出各个比较大的购物节,重点关心购物节前后的用户行为数量变化,同时对每周末进行比较,分析购物节推广活动安排在周末/非周末对用户行为的影响;在一年中对各个月进行同比对比购买行为的趋势,找出整个月中是否有购买行为上升的规律(结合用户年龄数据进行分析,购买行为上升可能与发工资的时段也有关)
- 从时间维度上来看,用户的各种行为活跃高峰期都在晚间的21点左右,说明安排在这个时间段的活动对用户的触达率是最好的,可以考虑在这个时间做一些力度较大的优惠活动,也可以将转化行为的时间安排在这个时间段,如直播带货等来进行用户的活跃度提升及转化。并且发现用户在晚间的行为更偏向于浏览商品,白天10点左右购买行为的比率较高,可以根据这个特性在晚间对商品进行宣传,然后在白天进行转化。
- 根据跳失率和复购率来看,淘宝APP中的商品对用户具有足够的吸引力,可以得出淘宝APP目前处于“忠诚度模式”中,重点为维系老用户的忠诚度。**优化方法有:**①提高成交转化率,优化用户推荐系统,或者邀请明星做测评推广;②用户复购率为65.98%,说明这些用户对该平台较为满意,可以通过奖励积分或者优惠券等方式鼓励用户重复购买;③通过分析找出价值用户的购买偏好,产品和类目等,给价值用户制定个性化的产品推荐,从而提高用户体验,进而提高购买率。
- 在本项目中用户留存率相对稳定,七日留存率略有回升,可能是因为当天12月1日是星期五,正好是客户活跃度上升的一个转折点,可能是有购物优惠活动。为了提高留存,可以让用户养成习惯,在一定程度上增加用户对产品的依赖性。①每日给用户推送可能感兴趣的商品;②一些签到的小游戏或者签到领积分活动,增加用户登录的频率,进而增加用户浏览时长;③对于年购买量比较大的用户,为了增加这些用户的粘性,可以推出vip服务,让这些用户享受折扣和优惠券,进而提高高价值用户的留存率和对平台的忠诚度;④大力推广直播跟用户互动,计算亲密指数并进行排行,可以让用户与店主之间建立信任,进而增加客户的忠诚度。
6.2 用户精细化运营
通过RFM模型中的用户最近一次购买时间、用户消费频次分析,分拆得到以下重要用户。可以在后续精细化运营场景中直接使用细分用户,做差异化运营:
- 对高价值客户做VIP服务设计,增加用户粘性同时通过设计优惠券提升客户消费;
- 对深耕客户做广告推送,刺激用户提升消费频次;
- 对挽留客户做优惠券、签到送礼策略,增加挽留用户粘性;
- 对唤回客户做定向广告、短信召回策略,尝试召回用户。
对于重要价值用户,消费频率高且最近消费距离现在时间短,需要给其提供VIP服务;
对于占比较大的重要发展用户,其消费频率低,但最近消费距离现在时间较短,想办法提高其消费频率;
对于重要保持用户,最近消费距离现在时间较远,也就是R值低,但是消费频次高,这样的用户,是一段时间没来的忠实客户,可以采取邮件推送、APP推送提醒、促销活动时短信提醒等方式主动和他们保持联系,提高复购率;
对于占比较大的重要挽留用户,最近消费时间距离现在较远、消费频率低,这种用户有即将流失的危险,需要主动联系用户,调查清楚哪里出了问题,并想办法挽回
6.3 商品分析
商品的浏览量和销量的相关性不是很高,所以没有必要一味提高浏览量, 销量并不会随之增加。根据四象限划分图的分析,应重点提升第二象限及第三象限的商品,针对第二象限的商品应提高其曝光率,找出它的用户画像,尽量做到精准推送或建立专属社群,提供用户交流平台,提升用户粘性及转化率;第三象限应尝试提升商品的流量,分析销量是否会随之提升。
通过分析发现,商品的销量主要靠的是“长尾效应”而非某款爆款商品,但是这是站在APP的角度来看,对于B端商家来说,也可以打造爆款商品来减少商品种类繁多的运营及库存成本。
针对销量排行榜前面的商品可以增加其曝光率推荐率,在用户搜索时进行优先展现。
6.4 平台指标分析
总体转化率只有 2.25%,用户点击后收藏和加购物车的转化率在 9.4% ,需要提高用户的购买意愿,要考虑为什么用户浏览了那么多商品却只有9.4%的用户加入购物或收藏,可能这中间用户花了太多的时间却没有挑选到满意的商品,那么有一些客户就流失掉了。**优化方法:**建议通过活动、优惠券、产品详情页的改进等提高转化;可以采取问卷调查的方式分析用户行为推送用户可能感兴趣的商品、优化购物界面使界面布局更加人性化等方式更好的满足用户需求,激活更多用户。