Redis——狂神
1 什么是NoSQL?
1.1为什么要用NoSQL?
先从历史开始讲吧
1、单机数据库时代
90年代,一个基本的网站访问量较小,单个数据库可以顶住当时的访问量
在那个时候,都会去使用静态网页html,因为服务器压力不会太大
缺点:
- 数据量太大,一台机子放不下了
- 当数据量达到300万以上,就需要建立索引,MySQL索引,B+树。数据量一大,电脑内存也放不下了
- 在当时的数据库单机时代,读写一体,服务器承受不了
如果说以上三个条件满足了至少一个,那么就需要做出改变了

2、Memcached(缓存)+ MySQL + 垂直拆分(读写分离)
网站在大部分情况下都是在读,当用户在界面中按下一个button,就会对数据库发送一个查询请求,如果说,当一个或者多个用户都在发送一个相同的请求,而这个请求每次都要查询数据库,这很耗费性能,这时候就需要减轻数据库的压力,可以使用缓存来保证效率
发展:优化数据结构和索引----->文件缓存(IO操作)----->Memcached(当时的热门技术)
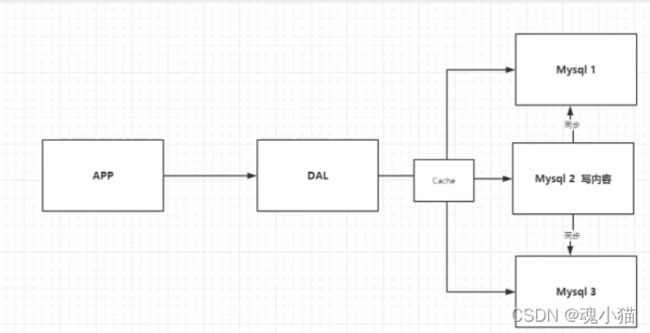
3、分库分表 + 水平拆分 + MySQL集群
技术与业务在发展的同时对人开始有越来越高的要求
本质都是在解决数据库的读和写问题
以MySQL的存储引擎为例
- MyISAM:这个存储引擎支持表锁,并且不支持事务的ACID,影响操作,在高并发下会出现严重的锁问题
- InnoDB:行锁+表锁,支持事务的ACID
慢慢的由于数据量的增大,慢慢的开始使用分库分表解决写压力!在当时MySQL还推出了一个 表分区 的概念,但是并没有多少的公司愿意去使用
MySQL集群的解决方案,已经在当时解决了大部分的需求
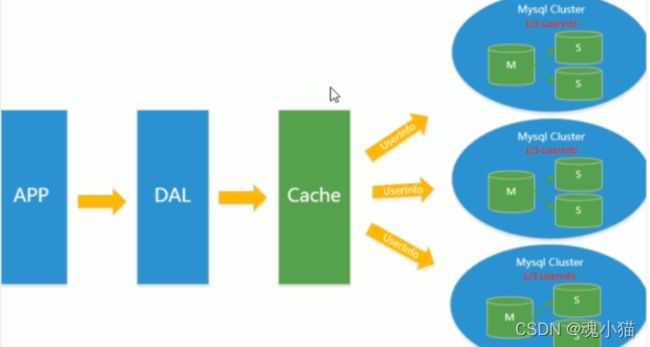
4、如今最近的年代
2010-2020,过了十年,世界发生了巨大变化,从按键手机到智能手机,定位,也成为了一种数据
MySQL等关系型数据库开始出现性能瓶颈!大数据,数据量很多,变化很快
MySQL可以用来存储一些比较大的文件,博客,图片!数据库表很大,执行IO操作的效率就会很低下,如果有一种数据库专门用来处理这种数据,就可以用来缓解MySQL的压力(如何处理这些问题)
为什么要用NoSQL
用户个人信息,社交网络,地理位置,用户自己产生的信息数据,等等一系列的弹性数据爆发式增长,关系型数据的传统的表结构已经承载不了了,这时候就需要使用NoSQL数据库来解决,NoSQL可以很好处理以上情况
1.2NoSQL简介
什么是NoSQL
NoSQL翻译为Not Only SQL,译为不仅仅是SQL,意指非关系型数据库
web2.0的诞生,传统的关系型数据库已经很难对付web2.0时代!特别是指大规模高并发社区!会出现很多问题,NoSQL在大数据时代发展的十分迅速,尤其是Redis
很多的数据类型用户的个人信息,社交网络,地理位置,这些数据类型的存储不需要一个固定的格式,不需要太多操作就可以实现横向拓展,就比如Redis,它是使用类似于Java的Map
NoSQL 特点
一切为了解耦
- 方便扩展(数据之间没有联系可以快速拓展)
- 大数据量高性能,Redis可以支持8w的并发量(写操作),11w访问量(读操作),NoSQL的缓存记录级,是一种细粒度的缓存,性能比较高
- 数据类型多样性(不需要事先设计数据库,随取随用,数据量过大就无法设计)
传统的关系数据库管理系统(Relational Database Management System:RDBMS)和NoSQL的区别
传统的RDBMS
- 结构化
- SQL
- 数据和关系存在于单独的表中 row(行) column(列)
- 数据操作,数据定义语言
- 严格的一致性
- 基础的事务
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性
- CAP定律和BASE理论
大数据时代的3V + 3高
大数据时代的3V
海量Volume
多样Variety
实时Velocity
大数据时代的3高
高并发
高可用(随时水平拆分,机器不够了,随时扩展)
高性能(保证用户体验和性能)
1.3NoSQL的四大分类
KV键值对
- 新浪:Redis
- 美团:Redis + Tair
- 阿里,百度:Redis + Memcached
文档型数据库(Bson,Binary Json,二进制Json)
-
MongoDB,需要掌握,它是一种基于分布式文件存储的数据库,由C++编写,主要用来处理大量的文档
它是一种介于关系型数据库和非关系型数据库之间的一种中间产品,功能丰富,而且MongoDB是NoSQL中最像关系型数据库的产品 -
ConthDB
列存储数据库
- HBASE
- 分布式文件系统
图形关系数据库
- 它不是存图片的!它存放的是关系,就好比一个人的社交圈,可以动态扩充
- Neo4j,InfoGrid
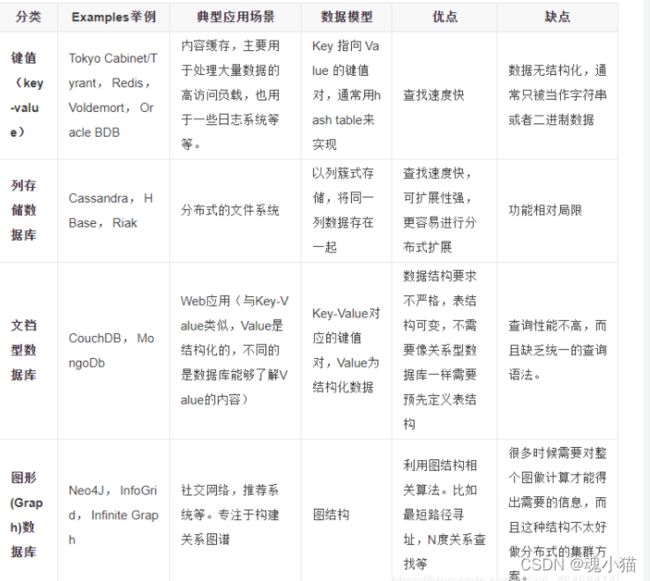
4种分类的对比
2 Redis入门
2.1Redis简介
什么是Redis?
Redis(Remote Directory Server),中文译为远程字典服务,免费开源,由C语言编写,支持网络,可基于内存也可持久化的日志型,KV键值对数据库,并且提供多种语言的API,是当下NoSQL中最热门的技术之一!被人们称之为结构化数据库!
并且Redis支持多种语言(如下图)

redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步
Redis能干嘛?
- 内存存储,持久化,因为内存断电即失,并且Redis支持两种持久化方式,RDB / AOF
- 效率高,可用于高速缓存
- 消息发布订阅(消息队列)
- 地图信息分析
- 计数器(eg:微博浏览量)
特性
- 数据类型多样
- 持久化
- Redis集群
- 事务
2.2Linux安装Redis
安装Redis的第一种,官网下载安装包
下载安装包,redis-5.0.10.tar.gz
下载到Windows之后,用Xftp工具上传至Linux
解压安装包并将其解压到opt目录下
tar -zxvf redis-5.0.10.tar.gz -C /opt
并且解压之后可以看见Redis的配置文件redis.conf
同时还需要基本的环境搭建
# 保证Redis的正常运行,gcc的安装也是必要的
yum install gcc-c++
# 安装Redis所需要的环境
make
# 此命令只是为了确认当前所有环境全部安装完毕,可以选择不执行
make install
Redis的安装,默认在/usr/local/bin下

之后,需要将Redis的配置文件复制到bin目录下,可以提前准备好一个目录,然后在复制到新创建好的目录中

然后修改复制之后的配置文件,修改一条信息,修改的信息就是图中划红线的位置,它的意思是指守护进程模式启动,即可以在后台运行Redis

随后就可以开始启动Redis服务(通过指定的配置文件启动服务)
redis-server /usr/local/bin/myconfig/redis.conf

使用Redis客户端连接指定的端口号
redis-cli -p 6379
2.3redis-benchmark性能测试工具
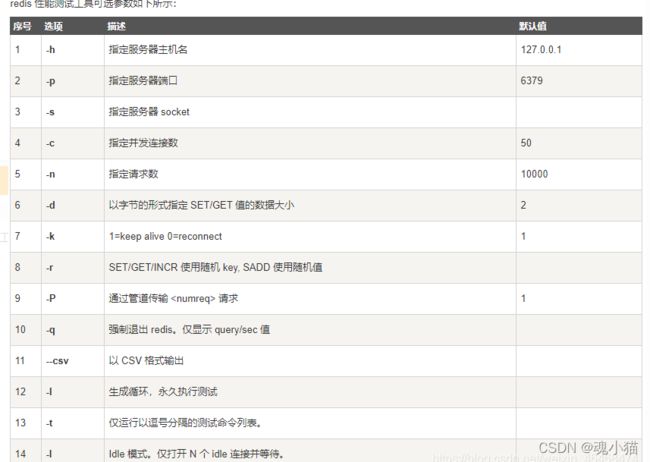
# 当前命令表示,性能测试,在本机,端口号6379,并发连接数100,每个连接10w个请求数量
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
# 测试结果如下,以Redis的set命令为例
====== SET ======
100000 requests completed in 1.85 seconds # 十万个请求在1.85秒之内被处理
100 parallel clients # 每次请求都有100个客户端在执行
3 bytes payload # 一次处理3个字节的数据
keep alive: 1 # 每次都保持一个服务器的连接,只用一台服务器处理这些请求
28.68% <= 1 milliseconds
97.99% <= 2 milliseconds
99.47% <= 3 milliseconds
99.59% <= 4 milliseconds
99.62% <= 5 milliseconds
99.68% <= 6 milliseconds
99.79% <= 7 milliseconds
99.90% <= 22 milliseconds
99.97% <= 23 milliseconds
100.00% <= 23 milliseconds # 所有的请求在23秒之内完成
54054.05 requests per second # 平均每秒处理54054.05个请求
2.4Redis基础知识
备注:在Redis中,关键字语法不区分大小写!
Redis有16个数据库支持,为啥嘞,可以查看redis.conf配置文件

并且初始数据库默认使用0号数据库(16个数据库对应索引0到15)
可以使用select命令切换数据库:select n(0-15)
127.0.0.1:6379> SELECT 12
OK
127.0.0.1:6379[12]> SELECT 0
OK
127.0.0.1:6379> DBSIZE # 查看当前库的key数量
(integer) 0
删除数据库信息
127.0.0.1:6379> keys *
1) "mylist"
2) "myset:__rand_int__"
3) "counter:__rand_int__"
4) "key:__rand_int__"
127.0.0.1:6379> FLUSHDB # 删除当前数据库
OK
127.0.0.1:6379> keys *
(empty list or set)
# 还有一个删除的命令,叫做FLUSHALL,它的意思是删除16个数据库中的全部信息。
# 不管在那种数据库中,删库一直都是需要慎重操作的
题外话:为什么Redis选用6379作为默认端口号?
6379在是手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字。MERZ长期以来被Redis作者antirez及其朋友当作愚蠢的代名词。后来Redis作者在开发Redis时就选用了这个端口。(摘自知乎)
————————————————
版权声明:本文为CSDN博主「你给我把被子盖好了,别再踢了」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46468474/article/details/109807495
Redis是单线程的(从Redis6.0.1开始支持多线程)
Redis的读写速度很快,官方表示,Redis基于内存操作,CPU不是Redis的性能瓶颈,Redis的性能瓶颈是根据机器的内存和带宽
Redis是C语言编写,官方提供的数据为10万+的QPS(Queries-Per-Second,每秒内的查询次数)
Redis单线程为什么速度还是这么快?
对于Redis,有两个误区:
- 高性能的服务器一定是多线程的?
- 多线程一定比单线程效率高?
Redis将所有的数据全部放在内存中,使用单线程去操作效率比较高,对于多线程,CPU有一种东西叫做上下文切换,这种操作耗时,对于内存系统来说,没有上下文切换,效率一定是最高的。
Redis使用单进程的模式来处理客户端的请求,对大部分事件的响应都是通过epoll函数的加强封装,Redis的实际处理速度依靠主进程的执行效率,epoll可以显著提高程序在大量并发连接中系统的CPU利用率
2.5Redis五大数据类型
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
2.5.1Redis-key
# 基础语法:
# SET key value 设置一个key
# GET key 获取一个key对应value
# EXISTS key 查询key是否存在
# MOVE key n(数字) 将当前key移动到指定的几号数据库中
# KEYS * 查询当前数据库中全部的key
# EXPIRE key time 设置当前key的过期时间
# TTL key 查询当前key的存活时间
# TYPE key 查看key的数据类型
127.0.0.1:6379> set name xiaohuang # 设置key-value
OK
127.0.0.1:6379> get name # 查询key指定的value
"xiaohuang"
127.0.0.1:6379> EXISTS name # 查看当前key是否存在
(integer) 1
127.0.0.1:6379> EXISTS name1
(integer) 0
127.0.0.1:6379> MOVE name 1 # 将当前key移动到1号数据库
(integer) 1
127.0.0.1:6379> KEYS *
(empty list or set)
127.0.0.1:6379> SELECT 1 # 选择数据库
OK
127.0.0.1:6379[1]> KEYS *
1) "name"
127.0.0.1:6379[1]> EXPIRE name 10 # 设置当前key的过期时间,单位是秒
(integer) 1
127.0.0.1:6379[1]> KEYS *
1) "name"
127.0.0.1:6379[1]> KEYS *
1) "name"
127.0.0.1:6379[1]> KEYS *
1) "name"
127.0.0.1:6379[1]> KEYS *
1) "name"
127.0.0.1:6379[1]> ttl name # 查看指定key的存活时间,
(integer) -2 # 返回-2表示当前key已经过期,如果为-1,表示永不过期
127.0.0.1:6379[1]> KEYS *
(empty list or set)
127.0.0.1:6379> set name xiaojiejie
OK
127.0.0.1:6379> set age 26
OK
127.0.0.1:6379> KEYS *
1) "age"
2) "name"
127.0.0.1:6379> TYPE name # 查看指定key的value的数据类型
string
127.0.0.1:6379> TYPE age
string
127.0.0.1:6379>
2.5.2String(字符串)
# 语法:
# APPEND key appendValue 对指定key实现字符串拼接,如果key不存在,等同于set
# STRLEN key 查看指定key的长度
# INCR key 对指定key进行自增,类似于Java中的i++
# DECR key 自减,类似于Java的i--
# INCRBY key n 对指定key按照指定的步长值进行自增
# DECRBY key n 按照指定的步长值自减
# SETRANGE key index value 从指定key的索引开始,插入指定的value值。
# 如果key不存在且索引>1,那么当前的索引之前的数据,会用\x00代替并占用一个索引位置,相当于ASCII码中的null
# GETRANGE key startIndex endIndex 将指定key按照索引的开始和结束范围进行截取,成为一个新的key
# SETEX key time value 设置一个有存活时间的key
# SETNX key value 如果这个key不存在,即创建
# MSET key value ... 设置多个key value
# MGET key ... 获取多个key指定的value
# GETSET key value 先获取指定的key,然后再设置指定的value
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> KEYS * # 获取当前数据库中所有的key
1) "k1"
127.0.0.1:6379> APPEND k1 hello #给k1再继续追加value值
(integer) 7
127.0.0.1:6379> get k1
"v1hello"
127.0.0.1:6379> APPEND k1 ,xiaohuang
(integer) 17
127.0.0.1:6379> STRLEN k1 # 查看当前k1的长度
(integer) 17
127.0.0.1:6379> get k1
"v1hello,xiaohuang"
127.0.0.1:6379> KEYS *
1) "k1"
127.0.0.1:6379> APPEND name xiaohuang
(integer) 9
127.0.0.1:6379> get name
"xiaohuang"
127.0.0.1:6379> KEYS *
1) "k1"
2) "name"
###################实现自增自减效果################
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> get views
0
127.0.0.1:6379> INCR views # 设置value的自增效果
(integer) 1
127.0.0.1:6379> INCR views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379> DECR views # 设置value的自减效果
(integer) 1
127.0.0.1:6379> DECR views
(integer) 0
127.0.0.1:6379> get views
"0"
############可以在自增自减时设置步长##############
127.0.0.1:6379> INCRBY views 2 # 自增,设置步长为2
(integer) 2
127.0.0.1:6379> INCRBY views 2
(integer) 4
127.0.0.1:6379> get views
"4"
127.0.0.1:6379> DECRBY views 3 # 自减,设置步长为3
(integer) 1
127.0.0.1:6379> DECRBY views 3
(integer) -2
127.0.0.1:6379> get views
"-2"
# 注意:value的自增和自减只适用于Integer类型
127.0.0.1:6379> incr name
(error) ERR value is not an integer or out of range
#################实现字符串截取效果#################
127.0.0.1:6379> set k1 hello,xiaohuang
OK
127.0.0.1:6379> get k1
"hello,xiaohuang"
127.0.0.1:6379> GETRANGE k1 0 3 # 实现字符串截取,有起始索引和结束索引,相当于Java中的subString()
"hell"
# 如果结束索引为-1,则表示当前截取的字符串为全部
127.0.0.1:6379> GETRANGE k1 0 -1
"hello,xiaohuang"
###############实现字符串的替换效果#################
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> SETRANGE key2 2 hello # 实现字符串的替换效果,命令中的数字“2”表示从索引2的位置开始将其替换为指定字符串
(integer) 7
127.0.0.1:6379> get key2
"abhello"
##################################################
# setex(set with expire) # 设置过期时间
# setnx(set with not exist) # 如果key不存在,创建(分布式锁中常用)
127.0.0.1:6379> setex k3 10 v3 # 设置一个k3,过期时间为10秒
OK
127.0.0.1:6379> keys *
1) "k1"
2) "key2"
3) "name"
4) "views"
5) "k3"
# 10秒之后会自动删除
127.0.0.1:6379> keys *
1) "k1"
2) "key2"
3) "name"
4) "views"
127.0.0.1:6379> setnx lan redis # 如果key不存在,即创建
(integer) 1
127.0.0.1:6379> setnx lan mongodb
(integer) 0 # 0表示没有设置成功,也可理解为“有0行受到影响”
127.0.0.1:6379> get lan
"redis"
######################一次性设置(获取)多个键值对#####################
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # 同时设置多个值
OK
127.0.0.1:6379> KEYS *
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> mget k1 k2 k3 # 同时获取多个值
1) "v1"
2) "v2"
3) "v3"
# 也可以在这边的语法前面加上一个m,代表设置多个
127.0.0.1:6379> msetnx k1 vv1 k4 v4
(integer) 0
# 但是这边同时设置多个值,如果有一个key已经存在,那么这一条设置语句便不会执行成功,
# 因为Redis单条语句是原子操作,要么同时成功,要么同时失败
127.0.0.1:6379> keys *
1) "k2"
2) "k1"
3) "k3"
# 在Redis中,还推荐了一个比较有意思的东西
# 这是Redis中关于key的命名,可以用“:”来代表层次结构,可以对指定的key进行分类存储
127.0.0.1:6379> mset user:1:name xiaohuang user:1:age 21
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "xiaohuang"
2) "21"
127.0.0.1:6379> getset sqlan redis # 先获取当前key指定的value,如果不存在,会返回nil(null),然后设置新值
(nil)
127.0.0.1:6379> get sqlan
"redis"
127.0.0.1:6379> getset sqlan hbase
"redis"
127.0.0.1:6379> get sqlan
"hbase"
####################################################################
类似于Redis中String这样的使用场景,value值可以是字符串,也可以是其他类型
String的存储的字符串长度最大可以达到512M
主要用途
- 计数器
- 统计多单位的数量
- 一个用户的粉丝数
- 一个有过期时间的验证码