视觉学习(四) --- 基于yolov5进行数据集制作和模型训练
环境信息
Jetson Xavier NX:Jetpack 4.4.1
Ubuntu:18.04
CUDA: 10.2.89
OpenCV: 4.5.1
cuDNN:8.0.0.180
一.yolov5 项目代码整体架构介绍
1. yolov5官网下载地址:
GitHub: https://github.com/ultralytics/yolov5/tree/v5.0
2. 代码架构
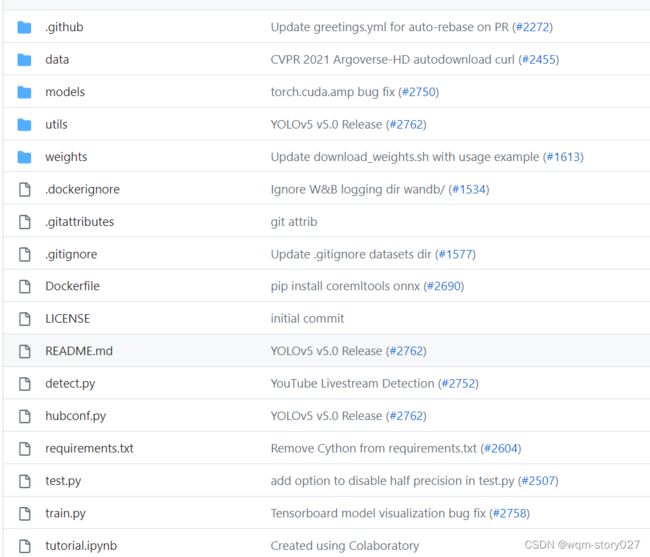
data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
weights:放置训练好的权重参数。
detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
train.py:训练自己的数据集的函数。
test.py:测试训练的结果的函数。
requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
二.数据集制作和预训练权重(yolov5s.pt)
1. 直接运行detect.py文件
直接运行detect.py文件,会在默认检测/data/images 下的两张图片,检测结果在runs/detect/exp文件夹下。
运行过程中产生的问题查阅>>>>四、遇到的问题及解决
2. 下载预训练权重文件yolov5s.pt
https://github.com/ultralytics/yolov5/releases

3. 自制数据集
3.1新建文件夹存储数据集和标签
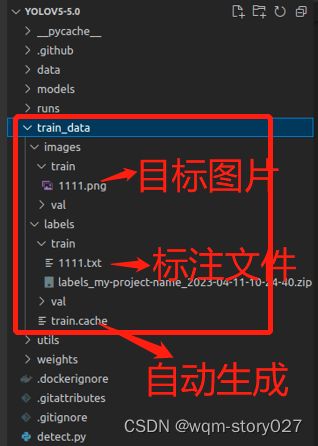
在yolov5项目的同级目录下面建立文件夹train_data,将采集的图片(即将训练或检测的图片)放入 train_data/images/train 文件夹下,此时 train_data/labels/train 文件夹是空的,文件夹结构如下图
3.2 图片标注
(1) 图片标注可以使用Labelme,教程可以参考http://t.csdn.cn/vQj2u
(2) 图片标注也可以使用在线标注工具
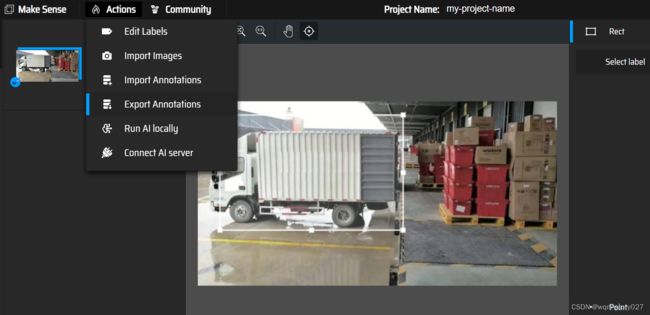
Get Started —> Click here to select them —>Object detection —>点击“+”,Insert label —> Start Project —> 标记目标 —> Actions —> Export Annotations —> A.zip xxxx in YOLO format —> Export
将导出的文件上传至train_data/labels/train/文件夹下,并解压
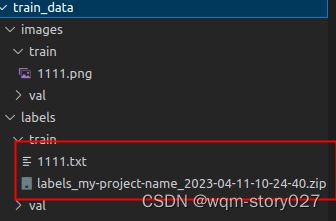
至此数据标注完成。
三、模型训练
1.修改数据配置文件和模型配置文件
训练目标检测模型需要修改两个yaml文件中的参数。一个是data目录下的相应的yaml文件,一个是models目录文件下的相应的yaml文件。
(1) 修改data文件夹下yaml文件
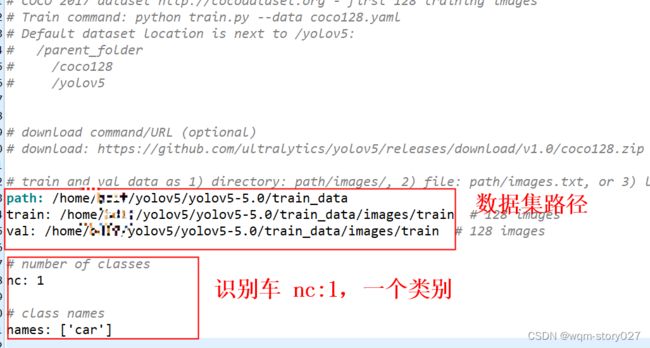
复制一份coco.yaml,并另存为test_car.yaml,以对车辆的识别为例,修改内容:
# COCO 2017 dataset http://cocodataset.org - first 128 training images
# Train command: python train.py --data coco128.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /coco128
# /yolov5
# download command/URL (optional)
# download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
path: /home/bdlf/yolov5/yolov5-5.0/train_data
train: /home/bdlf/yolov5/yolov5-5.0/train_data/images/train # 128 images
val: /home/bdlf/yolov5/yolov5-5.0/train_data/images/train # 128 images
# number of classes
nc: 1
# class names
names: ['car']
(2) 修改models文件夹下yaml文件
复制一份yolov5s.yaml文件,另存为yolov5s_car.yaml, 修改 nc 值

2. 修改并运行 train.py 文件
一般需要修改主函数中:预训练权重文件"–weights",训练模型"–cfg",训练集路径 “–data”
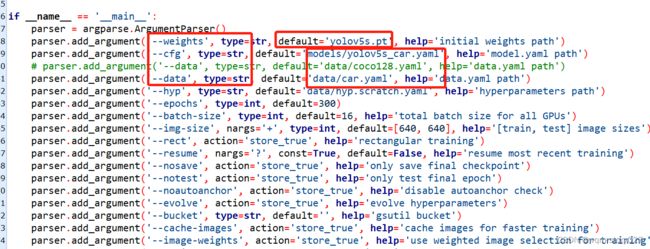
还有一些参数可以根据自己需求修改:
#模型的训练轮次,这里是训练的300轮
parser.add_argument('--epochs', type=int, default=300)
#根据电脑配置 ,cpu的核心数是8核
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
更多参数详解:
http://t.csdn.cn/zLPrt
parser = argparse.ArgumentParser()
# 预训练权重文件
parser.add_argument('--weights', type=str, default=ROOT / 'pretrained/yolov5s.pt', help='initial weights path')
# 训练模型
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
# 训练路径,包括训练集,验证集,测试集的路径,类别总数等
parser.add_argument('--data', type=str, default=ROOT / 'data/fire_data.yaml', help='dataset.yaml path')
# hpy超参数设置文件(lr/sgd/mixup)./data/hyps/下面有5个超参数设置文件,每个文件的超参数初始值有细微区别,用户可以根据自己的需求选择其中一个
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
# epochs: 训练轮次, 默认轮次为300次
parser.add_argument('--epochs', type=int, default=300)
# batchsize: 训练批次, 默认bs=16
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs, -1 for autobatch')
# imagesize: 设置图片大小, 默认640*640
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
# rect: 是否采用矩形训练,默认为False
parser.add_argument('--rect', action='store_true', help='rectangular training')
# resume: 是否接着上次的训练结果,继续训练
# 矩形训练:将比例相近的图片放在一个batch(由于batch里面的图片shape是一样的)
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
# nosave: 不保存模型 默认False(保存) 在./runs/exp*/train/weights/保存两个模型 一个是最后一次的模型 一个是最好的模型
# best.pt/ last.pt 不建议运行代码添加 --nosave
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
# noval: 最后进行测试, 设置了之后就是训练结束都测试一下, 不设置每轮都计算mAP, 建议不设置
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
# noautoanchor: 不自动调整anchor, 默认False, 自动调整anchor
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
# evolve: 参数进化, 遗传算法调参
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
# bucket: 谷歌优盘 / 一般用不到
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
# cache: 是否提前缓存图片到内存,以加快训练速度,默认False
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
# mage-weights: 使用图片采样策略,默认不使用
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
# device: 设备选择
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
# multi-scale 是否进行多尺度训练
parser.add_argument('--multi-scale', default=True, help='vary img-size +/- 50%%')
# single-cls: 数据集是否多类/默认True
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
# optimizer: 优化器选择 / 提供了三种优化器
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
# sync-bn: 是否使用跨卡同步BN,在DDP模式使用
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
# dataloader的最大worker数量 (使用多线程加载图片)
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
# 训练结果的保存路径
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
# 训练结果的文件名称
parser.add_argument('--name', default='exp', help='save to project/name')
# 项目位置是否存在 / 默认是都不存在
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
# 四元数据加载器: 允许在较低 --img 尺寸下进行更高 --img 尺寸训练的一些好处。
parser.add_argument('--quad', action='store_true', help='quad dataloader')
# cos-lr: 余弦学习率
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
# 标签平滑 / 默认不增强, 用户可以根据自己标签的实际情况设置这个参数,建议设置小一点 0.1 / 0.05
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
# 早停止耐心次数 / 100次不更新就停止训练
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
# --freeze冻结训练 可以设置 default = [0] 数据量大的情况下,建议不设置这个参数
parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
# --save-period 多少个epoch保存一下checkpoint
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
# --local_rank 进程编号 / 多卡使用
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
# 在线可视化工具,类似于tensorboard工具
parser.add_argument('--entity', default=None, help='W&B: Entity')
# upload_dataset: 是否上传dataset到wandb tabel(将数据集作为交互式 dsviz表 在浏览器中查看、查询、筛选和分析数据集) 默认False
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
# bbox_interval: 设置界框图像记录间隔 Set bounding-box image logging interval for W&B 默认-1 opt.epochs // 10
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
# 使用数据的版本
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
3. train.py 运行结果
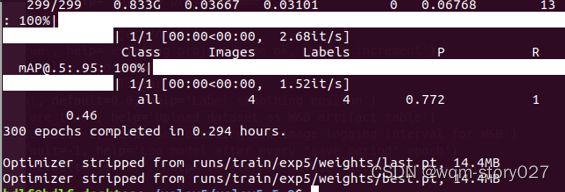
python3 train.py
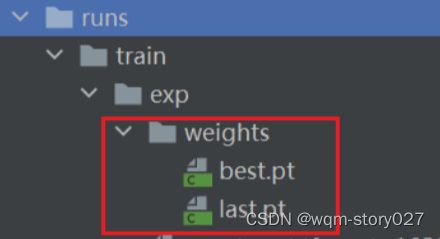
等到数据训练好了以后,就会在runs/train/exp/weights目录下会产生两个权重文件,一个是最后一轮的权重文件,一个是最好的权重文件。我们要利用这个最好的权重文件来做推理测试。
4. 修改运行 detect.py 文件
主要修改权重文件 “–weights” 和 测试数据路径 “–source”

更多参数解释:
https://blog.csdn.net/weixin_43334693/article/details/129349094
--weights: 训练的权重路径,可以使用自己训练的权重,也可以使用官网提供的权重。默认官网的权重yolov5s.pt(yolov5n.pt/yolov5s.pt/yolov5m.pt/yolov5l.pt/yolov5x.pt/区别在于网络的宽度和深度以此增加)
--source: 测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流, 默认data/images
--data: 配置数据文件路径,包括image/label/classes等信息,训练自己的文件,需要作相应更改,可以不用管
--imgsz: 预测时网络输入图片的尺寸,默认值为 [640]
--conf-thres: 置信度阈值,默认为 0.50
--iou-thres: 非极大抑制时的 IoU 阈值,默认为 0.45
--max-det: 保留的最大检测框数量,每张图片中检测目标的个数最多为1000类
--device: 使用的设备,可以是 cuda 设备的 ID(例如 0、0,1,2,3)或者是 'cpu',默认为 '0'
--view-img: 是否展示预测之后的图片/视频,默认False
--save-txt: 是否将预测的框坐标以txt文件形式保存,默认False,使用--save-txt 在路径runs/detect/exp*/labels/*.txt下生成每张图片预测的txt文件
--save-conf: 是否保存检测结果的置信度到 txt文件,默认为 False
--save-crop: 是否保存裁剪预测框图片,默认为False,使用--save-crop 在runs/detect/exp*/crop/剪切类别文件夹/ 路径下会保存每个接下来的目标
--nosave: 不保存图片、视频,要保存图片,不设置--nosave 在runs/detect/exp*/会出现预测的结果
--classes: 仅检测指定类别,默认为 None
--agnostic-nms: 是否使用类别不敏感的非极大抑制(即不考虑类别信息),默认为 False
--augment: 是否使用数据增强进行推理,默认为 False
--visualize: 是否可视化特征图,默认为 False
--update: 如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
--project: 结果保存的项目目录路径,默认为 'ROOT/runs/detect'
--name: 结果保存的子目录名称,默认为 'exp'
--exist-ok: 是否覆盖已有结果,默认为 False
--line-thickness: 画 bounding box 时的线条宽度,默认为 3
--hide-labels: 是否隐藏标签信息,默认为 False
--hide-conf: 是否隐藏置信度信息,默认为 False
--half: 是否使用 FP16 半精度进行推理,默认为 False
--dnn: 是否使用 OpenCV DNN 进行 ONNX 推理,默认为 False
运行结果
python3 detect.py
会在runs/detect/exp文件夹下生成结果文件

四、遇到的问题及解决
问题1:
Can't get attribute ‘SPPF' on 解决:
去…/yolov5-5.0/models/文件夹下将以下代码复制到common.py文件:
import warnings
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
问题2:
RuntimeError: The size of tensor a (80) must match the size of tensor b (56) at....
解决:
下载新的yolov5s.pt 替换原来的文件
https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt
问题3:
更换了数据集位置,导致报错:
AssertionError: Image Not Found YOLOv5-5.0/VOCdevkit/images/train/0.jpg
解决:
只需将之前在本机或服务器端训练生成的.cache文件删除,重新在电脑或服务器上运行train.py即可
问题4
AssertionError: train: No labels in autodl-tmp/PyQt5-YOLOv5-5.0/VOC2007/dataSet_path/train.cache. Can not train without labels. See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
这个是因为文件名命名原因,原图片命名不知道是中文的原因还是因为没有和标记文件一致的原因
解决:
原图片命名和标记文件名一致,避免中文命名,如train_data/images/train/1111.png 与 train_data/labels/train/1111.txt
总结:训练数据集如果采集的图片数据不够时,容易导致训练结果不理想,进而使用训练后的权重文件检测时,容易检测失败
参考链接:
[1] https://blog.csdn.net/weixin_41258131/article/details/127562734
[2] https://blog.csdn.net/qq_45022743/article/details/125663524