论文阅读【15】Exploiting Local and Global Features in Transformer-based Extreme Multi-label Text Classific
论文十问十答:
Q1论文试图解决什么问题?
Q2这是否是一个新的问题?
Q3这篇文章要验证一个什么科学假设?
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
Q5论文中提到的解决方案之关键是什么?
Q6论文中的实验是如何设计的?
Q7用于定量评估的数据集是什么?代码有没有开源?
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
Q9这篇论文到底有什么贡献?
Q10下一步呢?有什么工作可以继续深入?
论文相关
- 论文标题:用基于Transformer的极端多标签文本分类中的局部和全局特征
- 发表时间:2022年
- 领域:自然语言处理
- 相关代码:http://manikvarma.org/downloads/XC/XMLRepository.html
摘要
极端多标签文本分类(XMTC)是用相关标签标记每个文档的任务,其中目标空间可能包含多达数千个类别标签。。最近,大的transformer预训练模型作为提升XMTC任务的一个重要模型。他通常嵌入特殊的CLS token表示全部文本中的语意作为全局向量,并且将这些token与候选标签进行匹配。然而,我们认为在这样的全局特征向量不足够表达文本中不同粒度级别的语义信息,如然而使用局部词级的特征填充可能会带来以下其他的问题。基于这一个问题,我门提出一个方法结合局部和全局特征来改进transformer模型预测类别的性能。我们的实验表明在benchmark数据集上,我们的模型的性能比现在的最优的模型的性能更好。
1.引言
极端多标签文本分类(XMTC)是用相关标签标记每个文档的任务,其中目标空间可能包含多达数千个类别标签。这些标签类型来自于一个语义层次,其中更高级别的标签相当于更抽象更宽泛的概念,而较低级别的标签指定细粒度的区别。XMTC有很多实际应用,例如给新闻和维基百科的文章分配一个主题,给在在线购物商品标记标签,为了税收目的给产品进行分类,等等。
XMTC的一个主要问题就是更高表示每个输入文本,并且更好的捕获标签所要表达的语义信息。传统的文本分类使用的是词袋(Bow)模型作为文本表示,它是一个使用了TF(文档中术语的频率)和IDF(文档集合中的反向文档频率) 的权重特征向量。因为依赖于文本的单词的位置,顺序和语义被忽略,因此词袋模型在捕捉输入文本的上下文语义信息还是稍微欠佳。这些限制已经被最近的可以学习上下文文本的emberdding的方法的神经网络解决,尤其是大的预训练模型,例如Bert,Roberta,XLNet.像这种使用神经网络XMTC的解决方案包括X-Transformer,APLC_XLNet和 LightXML,这些方法在基准数据集上获得了sota的表现。
在这些基于transform的模型中,在神经网络的每一层嵌入token[CLS],将输入文档的内容汇总到一个单个向量中。因为这些向量表示这所有文本的语义信息,在我们的paper中称之为全局特征。因为因为它们的全局语义是从多层的自我关注中丰富出来的,所以通常这个[CLS]嵌入在最后或者最后一层被用于标签预测。当然使用这些全局特征去预测标签是一个自然的选择,但是我们认为他们可能没有充分的挖掘出Transform模型的长处。尤其,这所有word的embedding能够直接参与标签预测。遵循这些直觉,我们研究如何利用单词嵌入(特别是从一个较低的层)变压器,除了在XMTC中的全局特征。因为相比于全局总结(我的理解是全局文本表示),这些word emberdding能反应更精确的语义信息。我们称之为局部特征。
我们认为在XMTC中不同的标签可以在各种粒度级别上反应的文本语义信息。例如一个直观的例子,在亚马逊的产品中写到“坠入爱河是美妙”就是老百汇的爱情二重唱。“音乐”这个类别可以从总结产品内容的全局特征中推断出来。另一方面,像"vocalist"和"soundtracks"就很容易直接从文本描述中的关键词"singer"和"recording"中预测出来。如果我们只关注“歌手”和“录音”的全局特征,那么它所带来的重要信号可能会在完整文件的全局摘要中被掩盖,即the [CLS] embeddings在最后或者最后一层。这导致了我们直接利用局部词级特征进行标签预测的关键思想,特别是那些来Transformer模型的底层的特征。具体来说,我们提供了一种方法,让每个标签仔细地选择文档文本中的关键字。该方法更加强调每个标签和文档单词之间的匹配,用上下文中的细节来补充全局特征。
为了建立一个稳健和高效的分类系统,我们提出了一个集成框架,该框架结合了预先训练好的变压器模型中的局部和全局特征,即 G L O C A L X M L G_{LOCA}LXML GLOCALXML。我们的实验证明了我们提出的方法的有效性,它优于或与SOTA模型的基准XMTC数据集。我们还进行了消融研究,以验证我们的模型在利用这两个特征方面的有效性。
2.建议的方法
2.1 准备工作
设x = {x1,x2,……,xT }是长度为T的输入文档,而相关的地面真实标签集是y∈ R L R^L RL与 y l y_l yl∈{0,1},其中L是标签的大小。分类器计算标签为真的概率 p l p_l pl。预测值p = { p 1 、 p 2 、 … … 、 p L p_1、p_2、……、p_L p1、p2、……、pL}和y之间的二叉交叉熵(BCE)损失的计算方法为:
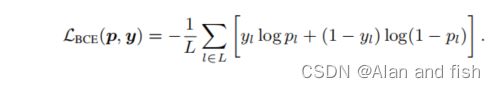
在输入transformer模型之前,文档x通常带有一个特殊的[CLS]标记。对于具有N层的transformer模型,第n层的隐藏表示表示为:

我们将分别介绍具有全局特征和局部特征的分类系统。
2.2 使用全局特征进行分类
全局特征表示[CLS]嵌入,总结了文档内容的高级和抽象表示。我们使用来自最后一层N的[CLS]嵌入,因为它包含了经过多层自我注意后最丰富的信息。在形式上,我们使用 h c l s ( N ) h^{(N)}_{cls} hcls(N)(或可选地传递给一个线性池处理器)作为全局特征。预测一个标签l的概率是由:

其中, e l g l o b a l e^{global}_l elglobal是全局特征的标签嵌入,<·,·>是点积。具有全局特征的分类器直接将文档表示与标签表示进行映射。
2.3 用局部特征进行分类
局部特征表示在某一Transformer层上的所有token embedding,它保留了感兴趣的标签所特有的多样化和细粒度的token信息。由于来transformer模型的第一层token嵌入大多属于token表层的含义(在上下文化时),我们选择它们作为局部特征。
类似于标签词注意力机制,我们的模型被设计为让每个标签仔细地从文档中选择关键token。尤其,我们将标签作为查询来检索文档中的显著标记( h c l s ( 1 ) h ^{(1)}_{cls} hcls(1)被写为 h 0 ( 1 ) ) h ^{(1)}_ 0) h0(1)):

其中:
- ψ K ψ_K ψK为一个线性函数
- e j l o c a l e^{local}_j ejlocal为局部特征的标签嵌入
- τ为温度。
τ控制着在单词上的注意力分布的平滑性。对于较小的τ < 1,注意力会在最显著的关键token上达到峰值.
公式2和4强调了全局和局部特征使用的区别:对于全局特征,计算标签嵌入和文档嵌入之间的相关性分数,而对于局部特征,相关性得分是直接计算在label emberding和token emberding之间的关键标记选择。检索到的关键标记根据相关性评分 α i j α_{ij} αij进行聚合:
 其中, ψ V ψ_V ψV是一个线性函数,而 φ M L P ( v j ) φ_{MLP}(vj) φMLP(vj)是一个多层感知器,它将聚合的标记嵌入到一个实值分数中。
其中, ψ V ψ_V ψV是一个线性函数,而 φ M L P ( v j ) φ_{MLP}(vj) φMLP(vj)是一个多层感知器,它将聚合的标记嵌入到一个实值分数中。
2.4 训练和推理
2.4.1 推理
我们的框架将分类与局部和全局特征相结合,对给定的输入文本和标签l的最终预测是:

2.4.2 训练目标
我们独立的优化 p g l o b a l p^{global} pglobaland p l o c a l p^{local} plocal的损失,而不是直接优化 p l f i n a l p^{final}_l plfinal:

分别优化这两个分类器会鼓励每个模块专注于它自己的特性.由于Transformer的主干是共享的,统一的框架允许我们建立一个快速和健壮的模型与更广泛的适用性。
3.实验
3.1 数据集
我们在3个基准数据集上进行了实验:
- EURLex-4K
- Wiki10-31K
- AmazonCat-13K
数据集的统计数据如表1所示。
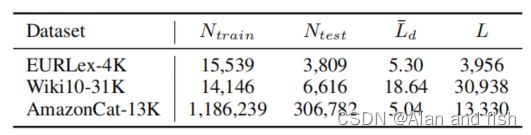
**表1:语料库统计: N t r a i n N^{train} Ntrain和 N t e s t N^{test} Ntest分别为训练实例数和测试实例数; L ‾ d \overline{ L}_d Ld为每个文档的平均标签数,L为唯一的标签数。**EURLex- 4K的未定义版本从APLC-XLNet github1中获得,另外两个来自极端分类库。EURLex-4K属于欧洲法律领域,Wiki10-31K属于一般领域,亚马逊cat-13K属于产品描述。
由于在大型XMTC数据集上适应我们提出的方法需要额外的基于树的技术,如X-transformers中的两阶段训练,我们将其留给未来的工作。
3.2 实验设置
3.2.1 实施细节
由于我们的方法可以应用于任何Transformer架构,我们对每个数据集使用三种不同的预先训练过的transformer基础模型:
- BERT
- Roberta
- XLNet
我们在之前的工作中根据实验设置来报告集合分数。
遵循APLC-XLNet,我们对预先训练过的transformer框架模块使用较小的学习率,因为它可能需要更少的调优。对于全局特征的分类器,我们的实现使用不同的学习率transformer 框架,池器(可选)和分类器,他们分别是Wiki10-31K数据集的学习率1e−5,1e−4,1e−3和其他两个数据集学习率5e−5,2e−4,2e−3。详细见下表格:
| 数据集 | transformer框架 | pooler | classifer |
|---|---|---|---|
| EURLex-4K | 1e−5 | 1e−4 | 1e−3 |
| Wiki10-31K | 5e−5 | 2e−4 | 2e−3 |
| AmazonCat-13K | 5e−5 | 2e−4 | 2e−3 |
对于具有局部特征的分类器,我们分别为attention模块和MLP设置2e−4、2e−3的学习率。我们使用fp16训练来减少内存使用和提高训练速度。我们在EURLex-4K和Wiki10-31K上使用BERT和Roberta的序列长度为512,AmazonCat-13K和XLNet模型的序列长度为256。
3.2.2 基线模型
我们将我们的模型结果神经网络基线模型的统计结果进行比较。统计的基线模型有一对多的DisMEC、PfastreXML、基于树的 Para-bel,eXtremeText。深度学习的方法有XML-CNN、AttentionXML、SOTA预训练的Transformer模型X-Transformer,APLCXLNet和 LightXML。
3.2.3 评价指标
遵循以前的工作,我们用微平均P@k来评估我们的方法,这是XMTC最常用的评价度量:

其中 p i p_i pi是排名列表p中的第i个标签, 1 y i + 1_{y_i ^+} 1yi+是指标函数。
3.3主要结果
表2报告了基于微平均P@k度量评估的模型的性能.我们的模型与统计模型和神经模型进行了比较,在粗体阶段表现最好,第二部分下划线。

表2:用微平均P@k度量评价了具有代表性分类系统的预测结果。粗体阶段和下划线突出了最佳和第二好的模型性能。
最具竞争力的基线是预先训练过的基于Transformer的模型。我们的模型在EURLex-4K和Wiki10-31K上的性能大大优于SOTA模型,比P@5提高了2%以上,并在AmazonCat-13K数据集上取得了具有竞争力的性能。我们将性能的提高归因于Transformer中局部特性的使用。当[CLS]嵌入不能捕获细粒度的细节时,具有更具体分类的标签可以直接受益于关注Transformer中的token Emberdding。至于获得亚马逊猫的原因只有边际,这可能是因为有更多的训练实例,所以其他神经模型有更好的机会编码更多有用的信息到全球嵌入,注入本地信息的优势在GLOCALXML不那么明显。
4. 分析局部和全局特征
4.1 单个模型的性能
表3报告了单个Roberta模型的性能。具有局部特征的分类器不可避免地会低于具有全局特征的分类器,这可能是因为局部分类器只共享一个较浅层的Transformer主干,所以它没有足够的表现力。尽管如此,当局部和全局特性组合时,GLOCALXML获得最好的性能,这可能来自于局部和全球特征的互补效应(下文分析)。
4.2 不同层次的局部特征
如图1所示,我们展示了将全局特征与不同的局部特征层相结合的性能。

图1:对全局特征(最后一层嵌入)与不同层局部特征结合的有效性进行消融测试。横轴为局部层数,纵轴为P@5性能。第0层对应于原始的token embeddings
我们的全局特征使用[CLS]embedding作为Roberta的最后一层,然而局部特征是来自transformer 0-12层的token embedding。第0层对应原始的token emberdding,而没有传递给任何Transformer块。
我们观察到,具有全局特征的分类性能相对稳定,优于具有局部特征的分类性能。我们的GLOCALXML模型结合了这两个特性,获得了最好的性能。对于Wiki10-31K数据集,当特性来自3层以下时,GLOCALXML获得了更好的性能,即使在第0层嵌入了原始的token。原因是,由于这个数据集有一个很大的标签空间,并且每个文档平均有19个标签,所以[CLS]嵌入更难用标签所特有的独特的单词级特征来总结文本。因此,允许标签直接查询文档中的关键字的本地分类器可以获取缺失的信息。将这两者结合起来可以得到更好的结果。
4.2 在不同层的局部特征
图1中,我们展示了将全局特征与不同的局部特征层相结合的性能。为了效率考虑,我们将实验的序列长度减少到256。在Roberta中的最后一层,全局特征使用[CLS]嵌入,而局部特征是来自Transformer层的0−12的令牌嵌入。第0层对应于原始的令牌嵌入,而没有被传递给任何Transformer块。
我们观察到,具有全局特征的分类性能相对稳定,优于具有局部特征的分类性能。我们的 G L O C A L X M L G_{LOCAL}XML GLOCALXML模型结合了这两个特性,获得了最好的性能。对于Wiki10-31K数据集,当 G L O C A L X M L G_{LOCA}LXML GLOCALXML的特征小于3层,即是在第0层都能获得更好的性能。原因是,由于这个数据集有一个很大的标签空间,并且每个文档平均有19个标签,[CLS]embedding更难用标签所特有的独特的词级特征来总结文本。因此,允许标签直接查询文档中的关键字的局部分类器可以获取缺失的信息。将这两者结合起来可以得到更好的结果。在这两个数据集上,我们观察到,当 G L O C A L X M L G_{LOCAL}XML GLOCALXML与来自较高层的局部特征结合时,其性能也会变得更差,即使来自更高层的局部特征在EURLex-4K中表现得更好。当局部特征位于(接近)第1层时, G L O C A L X M L G_{LOCAL}XML GLOCALXML的性能达到峰值。

图2:(EURLex-4K) G L O C A L X M L G_{LOCAL}XML GLOCALXML的分类相对于全局特征的相对改进,以及具有全局和局部特征的预测标签分布之间的JSD,以及具有全局和局部特征的预测标签分布之间的JSD。我们修复了全局分类器,并使用了来自不同层的局部特征。
我们的假设是:即使在更高层次的标记保留了标记的含义,经过多层的自我注意后,它变得更加情境化。因此,从更多的上下文化的嵌入中进行查询会使标签更难获取显著的关键字信息。在图2中,我们研究了 G L O C A L X M L G_{LOCAL}XML GLOCALXML相对于全局分类器的相对改进(红色曲线)与局部和全局分类器预测的标签分布的JSD(绿色曲线)之间的相关性。
它显示:
1)当使用更高层次的单词嵌入时,局部和全局分类器的分布更相似。
2)分布相似性越高, G L O C A L X M L G_{LOCAL}XML GLOCALXML的改善程度越低。
这表明,从更多的情境化的单词嵌入中查询可能会降低到查询全局嵌入(正如全局分类器也一样),并导致更少的信息增益。
5.总结
在本文中,我们提出了 G L O C A L X M L G_{LOCAL}XML GLOCALXML,一个集成了预先训练过的Transformer的全局和局部特征的分类系统。全局分类器使用[CLS]embedding作为文档的摘要,局部分类器使用标签词的注意力直接选择文本的显著部分进行分类。我们的模型结合了这两者来捕获不同粒度的文档语义,这在基准数据集上实现了优于SOTA方法或可比较的性能。