HTTP/0.9 - HTTP/1.1的演进
HTTP是浏览器中服务器和浏览器之间的传输协议,是前后端开发人员都要掌握的知识点,无论是开发还是面试,都是绕不开的话题,今天一起来学习一下相关知识,演进历程差不多算是从HTTP/1到即将来临的HTTP/2,再到未来的HTTP/3
HTTP/0.9
1991年诞生了HTTP/0.9,当时主要是为了在服务器和浏览器之间传输HTML文件,也称之为超文本传输协议(HyperText Transfer Protocol), 实现比较简单,客户端发起请求,服务端返回数据
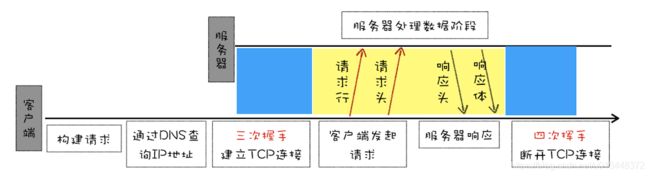
来看一下HTTP/0.9的一个完整的请求流程:
- HTTP是一种基于TCP协议的传输协议,客户端先要根据IP地址、端口跟服务器建立连接,建立连接的过程就是TCP的三次握手
- 建立连接之后,会发送一个GET请求来获取服务器上的资源
- 服务器接收到请求之后,会将资源(这里主要是HTML文件)以ASCII字符流的形式返回给客户端
- HTML文档传输完成之后,就会断开连接

当时的HTTP主要就是为了传输体积较小的HTML文件,并没有太复杂的需求,所以当时的HTTP\0.9比较简单,一个请求行就可以了,没有请求头和请求体,服务器也没有响应头,并且使用简单的ASCII字符流也能满足文件的传输
HTTP/1.0
随着万维网的飞速发展,0.9的策略已经不能再满足很多新的需求了,因为这时候不只是HTML文件了,随之而来的又有CSS文件,JavaScript脚本文件,图片,音频等等,这时候一种支持多种类型的文件传输协议就显得格外重要,并且传输形式也不能局限于ASCII字符流了,多种类型编码的文件也要支持
多种类型文件的下载
在0.9时代,请求只是HTML文件,没有更多的请求信息,比如文件编码以及类型等,服务器也不会返回更多的信息给浏览器,比如cookie,last-modified等,很显然这种交流传输的信息内容较少
在1.0时代,引入了请求头和响应头的概念,以key-value的形式存在,发送请求的时候带上请求头,服务器返回资源上带上响应头
通过请求头和响应头如何支持多种类型的数据
想要支持多种类型的文件,需要解决下面几个问题:
- 浏览器需要知道服务器返回数据的类型,根据类型来做相应处理
- 为了传输大文件,服务器会将文件压缩,而浏览器需要知道压缩格式
- 还需要知道返回资源的语言版本
- 需要知道资源的编码类型
基于上面的问题,1.0通过请求头和响应头来进行协商,发起请求的时候会通过HTTP请求头来告诉服务器期待什么类型的文件,压缩形式以及编码方式等,发送请求头如下所示:
accept: text/html
accept-encoding: gzip, deflate, br
accept-Charset: ISO-8859-1,utf-8
accept-language: zh-CN,zh
服务器接收到浏览器发送过来的请求头信息之后,会根据请求头的信息来准备相应数据,但是也会出现一些服务器资源压缩形式与请求形式不一致的情况,比如浏览器的请求压缩形式是gzip,而服务器上资源的压缩形式是br,那么这个时候浏览器会在响应头里通过content-encoding告诉浏览器,这个时候浏览器会根据最终的压缩形式来解析对应的资源,下面是一个例子:
content-encoding: br
content-type: text/html; charset=UTF-8
拿到了响应头信息之后,浏览器根据压缩方式br来解压文件,再按照编码格式UTF-8的形式来处理原始文件,最后按照HTML的方式来解析
除了上述几个功能之外,在1.0时代还额外增加了以下几个特性:
- 个别请求如果报错或者无法处理,服务器会返回状态码, 来告诉浏览器处理状态
- 1.0还增加cache机制,来减轻服务器的压力
- 服务器为了统计客户端的部分信息,还在请求头里加了用户代理(user-agent)字段
HTTP/1.1
需求一直在推动技术的进步,随着技术的发展,1.1又持续改进:
1. 持久连接
1.0时代,每次HTTP请求都会经历TCP连接,数据传输,TCP断开连接三个阶段
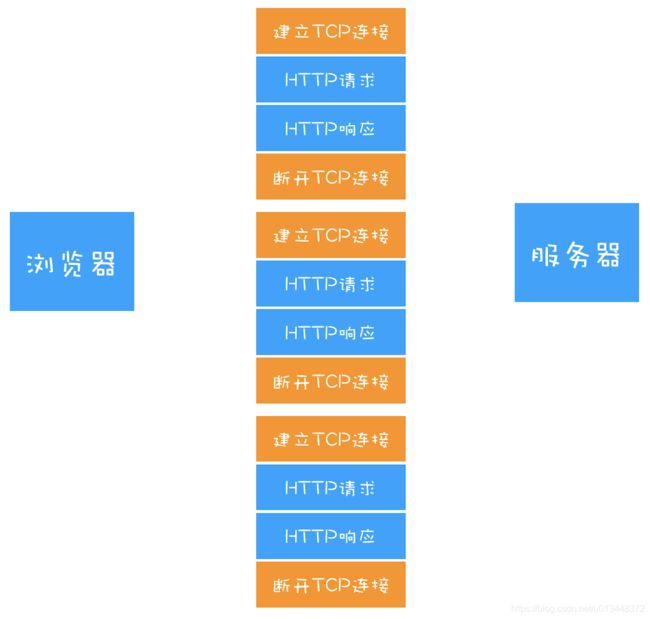
随着文件的增大,数量的增多,每次都要建立连接,断开连接,这样会增加很多额外的开销,所以在1.1时代,增加了持久连接的方法,即 一个TCP连接可以传输多个HTTP请求,只要浏览器或者服务器没有主动断开连接,那么该连接会一直处于激活状态
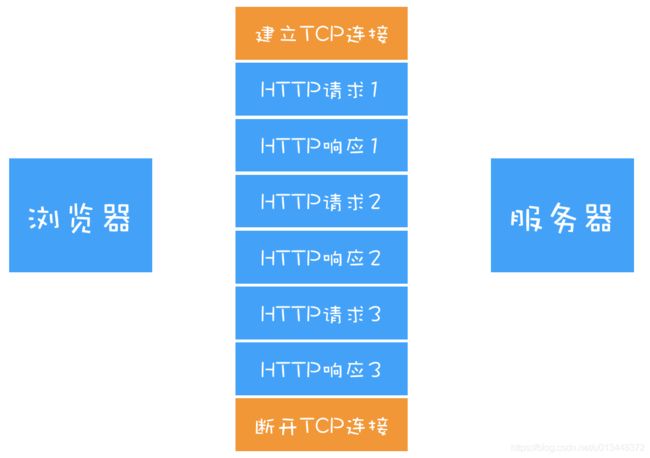
HTTP的持久连接会减少TCP的连接次数,减少了服务器的压力,提升了效率,在请求头和响应头中都有一个connection:keep-alive字段,如果想要关闭可以设置为connection:close。目前浏览器对同一域名,默认运行同时建立6个持久TCP连接
一个IP地址多个域名
1.0时代,一个主机对应一个IP,一个IP对应一个域名,随着虚拟机技术的进步,一个物理机可以绑定多个虚拟机,每个虚拟机又可以有自己单独的域名,这些域名都对应同一个IP地址。
在1.1时代,在请求头里还会有一个host字段,用来表明请求的域名地址,这样服务器就可以根据域名再找对应的虚拟机来做处理