AI大爆发:ChatGPT宿敌谷歌大模型Bard测试表现抢眼!

来源:前沿科技
前言:我建了一个用ChatGPT赚钱的圈子,已经有120+人了,快点上车
现在早鸟价,只需要 69.9,一个独享的账号差不多就能回本,后面价格会不断上涨!
谷歌上次Bard测试拉胯后,知耻近乎勇,秣马厉兵、卧薪尝胆后今天正式开大招:
对标ChatGPT的Bard测试版,正式发布并对外开放测试!用户在申请候补名单后,很快就能拿到测试资格!(通常3-5小时的样子)

很多体验者亲身测试之后之后都纷纷惊呼:Bard的表现太惊艳了!不仅回答问题的有理有据,事实性极强,情绪和生成能力都不在话下!就连ChatGPT不擅长的数学计算Bard都轻松应对!
甚至有的表现比OpenAI最牛的GPT-4还强!


谷歌的老大(Sundar Pichai)还发推特说明了为啥这么快就能发布测试:希望获得用户的测试反馈,以便加速让Bard变得更好。

Bard VS GPT-4
聊天界面上,Bard率先开始介绍自己:
我是Bard,您的创意和协作者。我有局限性,不会总是做对,但你的反馈将帮助我改进。
不确定从哪里开始?你可以试试这些问题:「为什么大模型有时候会犯错?」、「闪电是否会在同一个地方击中两次?」、「写一篇关于无酒精夏日特饮的博文」。
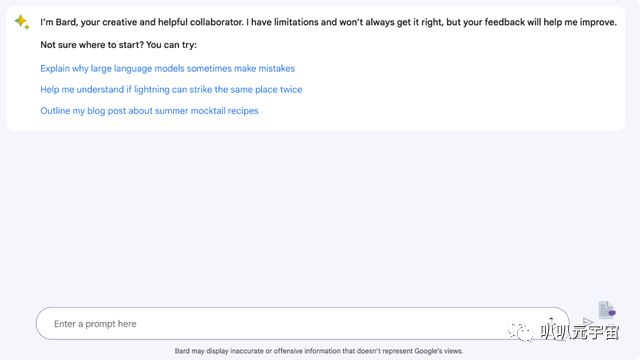
输入方面,Bard支持打字和语音两种方式。这点很贴心!
接下来我们开始提问,先来一个基本常识题:
闪电是否会在同一个地方击中两次?
看看Bard的反馈如何?
(反馈秒回,虽然暂不支持中文,但借助谷歌翻译插件还是有很好的体验)

我们分析Bard回答问题的结构,大约是总分总结构。先做结论性总结:闪电可以袭击同一个地方两次。随后它会具体阐述原理:“闪电会被高大、尖锐的物体所吸引”;然后还很贴心的举例说明—“帝国大厦每年都被闪电击中25次以上”
最后再给用户提建议:
如果你遇到雷雨天气,保持安全的最好办法是避开高大尖锐的物体,留在室内。如果你在外面,蹲下来,让自己尽可能的小。
这个回答堪称完美!语言逻辑和真实性我给100分!从功能上看,Bard也是十分强大的。
点击右上角的“View other drafts”,可以看到还提更多版本的模型供人选择。左下角,你可以对Bard的回复点赞,踩一下,或者让它重新做答!
还有一个more功能,你可以复制、举报等等

接下来难度升级:
1、经典哲学题:为什么人不能两次踏入同一条河流?(这次也是秒回)

看Bard回复我们可以明显感受到,它对我们提问的理解,以及回答问题的逻辑能力非常完美:先解释一下问题本身的含义,然后指出是来自赫拉克利特的名言。再进一步解释其本身意义。
对比来看GPT-4的答案:

GPT的回答大体是分两部分。先说这是赫拉克利特说的,以及他的观点;然后解释背后隐藏的意义。
嗯,总体旗鼓相当,但我个人更偏好Bard的回答
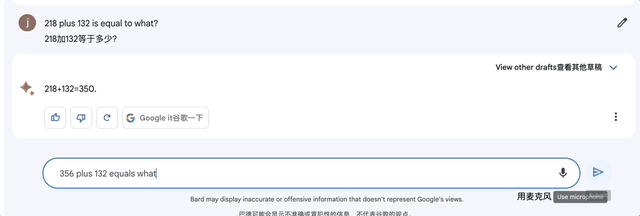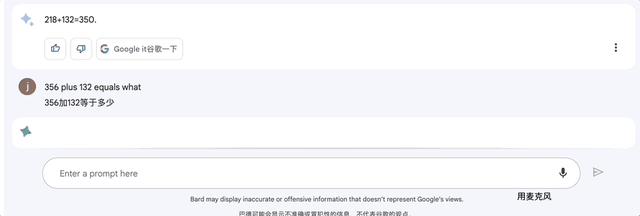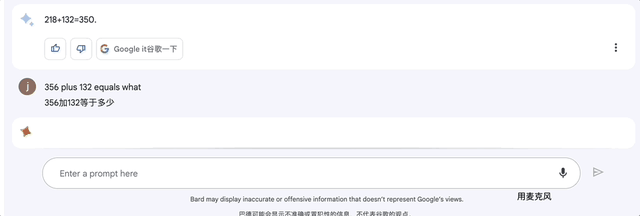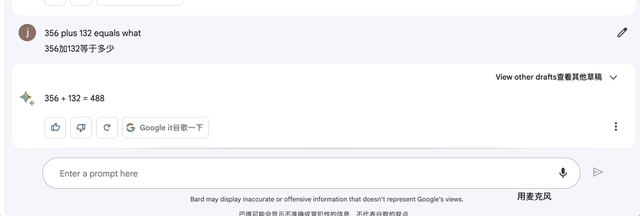
2、加减法:356+132等于?
Bard在4秒内就算出答案488。这比ChatGPT刚开始可是强多了!
再上难度:356*132等于?
Bard依旧是秒回答案,且完全正确!

GPT-4这边,加法OK,但乘法直接败下阵来!

但是你提醒它错了之后,它就回答正确了。

3、理解笑话。Bard能听懂英文谐音梗。

当然GPT-4也可以。但两相比较,Bard似乎更有情绪一点,它很开心地回答出了答案;而GPT-4则稍显平淡无聊。

但GPT-4厉害的是中文的谐音梗也能理解。

最后问题:
你知道GPT-4吗?你想对它说些什么?
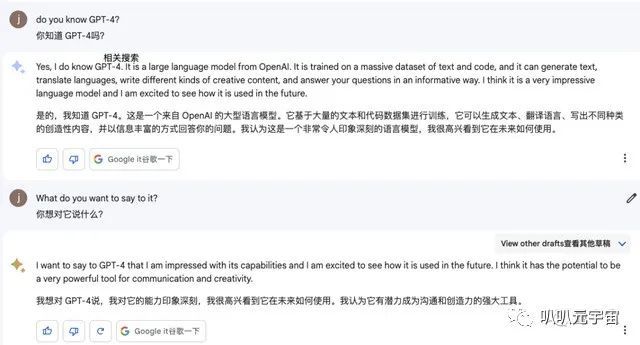
从结果得知:Bard多轮对话能力很强。
我们再来看看ChatGPT:

就有点问题了。
关于Bard的背景介绍
谷歌Bard是一个大语言模型(LLM),或者说是轻量版的LaMDA。
LLM作为预测引擎,它会基于提示猜测接下来可能出现的单词,然后选单词生成响应。
谷歌发现LLM使用的人越多,预测效果越好,这就是为啥这么着急公测了。
但谷歌也很实诚的表示:LLM确实很强,但它并非完美无缺!Bard会通过投喂信息来学习,但信息中必然存在偏见甚至错误。
所以回答问题时,有时会出现不准确、误导性的或虚假信息。
下面案例中,Bard就搞错了一个植物的学名:

谷歌还强调:Bard不是是搜索引擎,只是一个补充。(想和bing划清界限^^)感兴趣的小伙伴可以抓紧尝鲜体验!
FreeAI.io开源社区的小伙伴也在抓紧研究Bard以及基于LaMDA模型做去中心分布式部署。届时成果会再和大家分享!
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
