JAVA应用性能监控与调优
性能监控与调优
第一章 基于JDK命令行工具的监控
一.JVM的参数类型
1.标准参数
-help
-serve
-client
-version
2.X参数
非标准参数
3.XX参数
非标准化参数
相对不稳定
主要用于JVM调优和Debug
bool类型,+-号
kv类型
-Xmx最大内存
-Xms最小内存
二.运行时JVM参数查看
1.jvm性能调优工具jinfo
jinfo是jdk自带的命令,可以用来查看正在运行的java程序的扩展参数,支持在运行时修改部分参数
2.jinfo -help查看jinfo所有命令
3.jinfo -flags pid等等
4.用法详情:https://www.cnblogs.com/NetKillWill/archive/2017/10/28/jinfo.html
三.jstat查看虚拟机统计信息
1.类装载
jstat -class pid 1000 5
查看类加载,进程ID,间隔秒,几次
2.垃圾收集
jstat -gc pid 1000 3
查看gc详情
3.JIT编译
jstat -compiler 4578
四.jmap+MAT实战内存溢出
1.堆内存溢出:往List里添加对象撑满堆空间
2.非堆内存溢出:往List里添加类信息撑满非堆空间
3.如何导出内存映像文件
3.1内存溢出自动导出:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./
3.2使用jmap命令手动导出
jmap -help查看使用帮助
jmap -dump,format=b,file=heap.hprof pid 即可导出
jmap -heap 4578 等等命令
4.MAT分析内存溢出
五.jstack实战死循环和死锁
1.打印java进程内部所有的线程信息
2.jps -l查看有哪些java进程
3.jstack pid >pid.txt
4.线程状态和状态转换(待学习)
5.死循环排查
top查看消耗性能进程,结合jps -l,得到进程号
jstack pid > pid.txt导出进程中所有线程的堆栈信息
top -p pid -H查看进程下各线程信息
printf %x 4584 转换成十六进制的线程号
去jstack导出的pid.txt中搜索线程号查看信息
6.死锁排查
在pid.txt中搜索deadlock
第二章 基于JvisualVM的可视化监控
一.位置
C:\Program Files\Java\jdk1.8.0_181\bin下的jvisualvm.exe
二.远程jar应用
1.启动命令如下,然后添加JMX连接(查看CPU,堆,类加载,线程等)
nohup java -Xms512M -Xmx600M -Djava.rmi.server.hostname=101ycy.com -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar carloan-service-admin-0.0.1.jar > ./out &
2.添加jstat连接(查看Visual GC)
cd $JAVA_HOME/bin
touch jstatd.all.policy
vim jstatd.all.policy
jstatd.all.policy的内容如下:
grant codebase "file:${java.home}/../lib/tools.jar" {
permission java.security.AllPermission;
};
同级目录执行如下命令,注意设置hostname和端口,可加nohup后台启动
窗口运行:
./jstatd -J-Djava.security.policy=jstatd.all.policy -J-Djava.rmi.server.hostname=101ycy.com -p 2099 -J-Djava.rmi.server.logCalls=true
后台运行:
nohup ./jstatd -J-Djava.security.policy=jstatd.all.policy -J-Djava.rmi.server.hostname=101ycy.com -p 2099 -J-Djava.rmi.server.logCalls=true &
第三章 基于Btrace的监控调试
一.作用:
1.btrace可以动态地向目标应用的字节码注入追踪代码,做到调试的目的
2.可以拦截controller
3.拦截构造函数
4.拦截同名方法
5.返回值拦截
6.拦截异常
二.使用方式
1.创建脚本,命令行执行btrance pid 脚本.java
2.visualVM中安装btrace插件
三.注意事项
1.默认只能在本地运行
2.生产环境可以使用,但是修改后的字节码不会被还原,需要重启应用
3.要在本地先测好了,再在生产环境运行
第四章 tomcat性能监控与调优
一.tomcat远程debug
1.jdwp,定义了调试器和被调试的jvm之间的通信协议
2.使用方式:run/debug中配置remote
tomcat上配置,然后idea中
3.普通jar进程也可以,启动命令添加配置即可
二.tomcat-manager监控,自带的
1.低版本默认开启,高版本为了安全默认不开启
2.配置:
conf/tomcat-users..xml中添加用户
conf/Catalina/localhost/manager.xml配置允许的远程连接,需要新建
重启
3.浏览器中打开查看
三.psi-probe监控
1.github:psi-probe,下载maven打包,mvn clean package
2.也需要配置两个文件
3.浏览器中打开查看
4.作用
应用的统计信息;
jsp预编译,加快应用访问
查看日志
监控线程,堆栈信息
连接信息
请求数量;请求处理时间;请求响应字节数
四.tomcat调优
1.内存优化(后边讲)
2.线程优化
maxConnections:最大连接数,8之后默认NIO多路复用,默认值看文档,默认NIO/NIO2是10000,APR8192
acceptCount:超出最大连接数,进入队列,队列数量
maxThreads:最大线程数,每一次http请求到达web服务,tomcat都会创建一个线程来处理,同时并发处理得数量,默认200,跟机器CPU内存配置相关,监控里看工作线程数工作状态,就可以知道开多少合适
minSpareThreads:最小空闲的工作线程,不建议太小免得请求多造成等待
3.配置优化
autoDeploy:tomcat要不要周期性检查部署新的应用,会影响性能,conf/server.xml中,生产环境要关闭
enableLookups:改成false,消耗性能,默认禁用,开启会走DNS查询
reloadable:改成false,发现classes,web-inf变化重新载入,默认也不开启,context.html文档
protocol: http/1.1,默认使用NIO旧版本代表BIO,server.html文档
APR模式:调用native方法,从操作系统级别解决异步IO问题,大幅提高处理相应能力,tomcat高并发应用的首选模式,需要安装依赖库
sesson优化:如果是jsp,如果没用原生session,可以在页面上禁用session,<% page session="false" %>
说明文档:docs/config/http.html
第五章 Nginx性能监控与调优
一.niginx安装
1.修改yum源
2.yum install nginx
3./etc/nginx
4.配置反向代理需要配置selinux,关闭:setenforce 0,查看状态getenforce,需要关闭
二.ngx_http_stub_status监控连接信息
1.先查看这个模块是否编译进来nginx -V查看编译参数,查找--with-http_stub_status_module,有则编译进来了
2.active connections:当前活动连接数;reading:读取客户端请求头,writing:响应头数,waiting:等待的请求头数
三.ngxtop监控请求信息
1.安装 python-pip
yum install epel-release
yum install python-pip
2.安装ngxtop
pip install ngxtop
3.官方文档
https://github.com/lebinh/ngxtop
4.一些命令
默认监控:ngxtop
顶流Ip和请求:ngxtop top remote_addr request
四.nginx-rrd图形化监控
1.图形化监控
五.nginx优化
1.增加工作线程数和并发连接数
worker_processes 2;#进程数,一般跟cpu个数一致
events {
worker_connections 10240;#每个进程打开最大连接数
multi_accept on;#可以一次建立多个连接
use epoll;#使用epoll(linux2.6的高性能方式)
}
2.启用长连接
反向代理调用服务也可以启用长连接
3.启用缓存,压缩
gzip on;
4.操作系统优化
/etc/sysctl.conf内核参数优化
5.参考
可以看其他nginx专门讲解的课程
第六章 JVM层GC调优
应该设置多大内存,应该设置什么回收机制
一.JVM的内存结构
1.运行时数据区(规范)
规范如下图:

2.程序计数器:JVM支持多线程同时执行,每个线程都有自己的程序计数器,线程正在执行的方法叫做当前方法,如果是Java代码,程序计数器里存放的就是当前正在执行的指令的地址,如果是C代码,则为空
3.虚拟机栈:是线程私有的,生命周期跟线程相同,虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法出口等信息,每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出站的过程
堆heap:是JVM中内存最大的一块,被所有线程共享,在虚拟机启动时创建,此内存唯一的目的就是存放对象,可以是连续的,也可以是不连续的,逻辑上连续就可以
4.方法区methodarea:在java8中叫metaspace,在6,7是PermGen永久代,方法区别名叫非堆
常量池是方法区的一部分
5.本地方法栈:本地方法栈为虚拟机使用到native方法服务
6.jvm内存结构
metaspace=class,package,method,field,字节码,常量池,符号引用等
ccs:32位指针的class
codecache:JIT编译后的本地代码,jni使用的C代码

-XX:NewSize -XX:MaxNewSize 新生代大小,最大大小
-XX:NewRatio -XX:SurvivorRatio 新旧比例,Eden和S区比例
-XX:MetaspaceSize -XX:MaxMetaspaceSize 方法区大小
-XX:+UseCompressedClassPointers 是否启用CCS压缩类指针,,默认1G
等等
二.垃圾回收算法
1.创建的对象一直被应用程序持有,释放不掉就会内存泄露
2.回收思想:枚举根节点,做可达性分析
3.根节点:类加载器,thread,虚拟机栈的本地变量表,static成员,常量引用,本地方法栈的变量等
4.垃圾回收算法
标记清除:标记处需要回收的对象,然后统一清除
缺点:效率不高,两个过程效率都不高,产生碎片,导致提前GC
5.复制
两个容量相等的块,一次只使用一个块,块满了就把存活的复制到另外一块上面
缺点:运行高效,空间利用率低
6.标记整理
标记,然后整理存活的对象向一端移动,然后清理掉边界以外的内存
优缺点:没有碎片,但是整理内存比较耗时
7.分带垃圾回收(JVM)
Young区采用复制算法
Old区用标记清除或标记整理算法
7.对象分配
对象优先在Eden区
大对象直接进入老年代:-XX:PretenureSizeThreshold,多大的对象定位为大对象,这个参数配置
长期存活对象进入老年代:
-XX:MaxTenuringThreshold:年轻代年龄,多大进入老年代
-XX:+PrintTenuringDistribution:发生YGC打印存活对象年龄信息
-XX:TargetSurvivorRatio:S区回收后存活比例,80%的平均年龄跟年龄取最小值,达到这个值也会进Old
三.垃圾收集器
1.串行收集器Serial(web不用)
单线程,发现内存不够,暂停应用执行,起垃圾回收线程回收,再运行应用
开启串行:-XX:+UseSerialGC,启用这个默认启用下边这个
-XX:+UseSerialOldGC
2.并行收集器(适合后台处理)
吞吐量优先
-XX:+UseParallelGC,启用这个默认启用下边这个
-XX:+UseParallelOldGC
Server模式下的默认收集器,双核2G以上就是Server模式
概念:内存不够暂停应用,启动多个GC线程进行GC,然后启动应用
-XX:ParallelGCThreads=
CPU>8 N=5/8
CPU<8 N=CPU
有自适应特性,确定停顿时间和吞吐量自适应大小,一般不用
3.并发收集器(适合web应用)
响应时间优先
CMS:
-XX:+UseConcMarkSweepGC 老年代设置,默认年轻代如下
-XX:+UseParNewGC
低停顿,低延迟
收集过程:初始标记stw,停止应用;并发标记,并发预清理,重新标记stw,并发清除,并发重置
缺点:CPU敏感,当GC时,占用一个核心;产生浮动垃圾;空间碎片;
ICMS:
适用于单核或双核,分几次收集,jdk8中废弃了
G1:-XX:+UseG1GC jdk7开始使用,jdk8推荐G1
是否需要切换到G1
50%以上的堆被存活对象占用
对象分配和晋升的速度变化非常大
垃圾回收时间特别长,超过了1s
4.并行VS并发
并行:指多条垃圾收集器并行工作,但用户线程处于等待状态,适合科学计算,后台处理等若交互场景
并发:执行GC时同时运行用户线程,不会停顿用户程序运行,适合对响应时间有要求的场景,比如web
5.停顿时间VS吞吐量
GC时终端应用执行的时间,-XX:MaxGCPauseMillis
吞吐量:花在GC的时间和应用时间的占比,-XX:GCTimeRatio=
6.理想情况
吞吐量大的时候,停顿时间变小,一般是花在应用时间越长,停顿越长
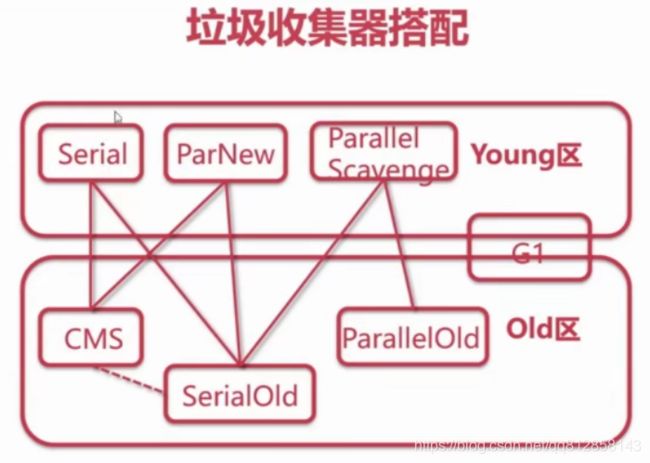
7.如何选择垃圾收集器
1.优先调整堆大小让服务器自己来选择
2.如果内存小于100M,使用串行
3.如果是单核,并且没有停顿时间要求,串行或JVM自己选
4.允许停顿超过1s,并行或JVM自己选
5.如果响应时间重要,不能超过1s,则选择并发类型
可以看官方文档,GC调优
四.可视化GC日志分析工具
1.每种垃圾回收器的吞吐量和最大响应时间
2.gceasy:在线工具,上传GC日志文件进行分析
3.GCViewer:
github下载,maven编译
4.如何打印GC日志
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps
-Xloggc:$CATALINA_HOME/logs/gc.log 日志输出到哪里
-XX:+PrintHeapAtGC 发生GC时打印堆信息
不同类型的收集器格式稍有不同
5.主要看的指标
吞吐量,最大最小平均响应时间,发生GC的原因
五.tomcat的GC调优
1.步骤:
打印GC日志;根据日志得到关键性能指标;分析GC原因,调优JVM参数,反复调试;
2.参数:
-XX:+DisableExplicitGC 不打印手动GC
-XX:+HeapDumpOnOutOfMemoryError 发生内存溢出时打印内存映像
-XX:HeapDumpPath=$CATALINA_HOME/logs/ 打印堆栈信息
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
Xloggc:$CATALINA_HOME/logs/gc.log 打印GC日志
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
一.parallel GC调优的指导原则
1.除非确定,否则不要设置最大堆内存
2.优先设置吞吐量目标
3.如果吞吐量目标达不到,调大最大内存,不能让OS使用swap,如果仍然达不到,降低目标
4.如果吞吐量能达到,GC时间太长,设置停顿时间的目标
5.如果是metaspaceGC可以调大小
-XX:MetaspaceSize=100M
-XX:MaxMetaspaceSize=100M
如果YGC频繁可以调
-XX:YoungGenerationSizeIncrement=30
二.G1调优最佳实践
1.年轻代大小:避免使用-Xmn年轻代大小,-XX:NewRatio年轻代和老年代比例等显示设置Young区大小,会覆盖暂停时间目标
2.暂停时间目标:暂停时间不要太苛刻,其吞吐量目标是90%的应用程序时间和10%的垃圾回收时间,太苛刻会直接影响到吞吐量
3.演示的调试
-XX:MetaspaceSize=64M metaspace大小
-Xms128M -Xmx128M 整个堆大小
-XX:+UseG1GC 使用G1垃圾收集器
-MaxGCPauseMillis=100 设置每次年轻代垃圾回收的最长时间 G1的应该优先设置这个
三.总结
1.JVM的各种垃圾收集器
2.评价垃圾收集器性能的两个关键指标:吞吐量和最大停顿时间
第七章 JVM字节码与java代码层优化
一.jvm字节码指令与javap
因为在源码层面看不出代码区别,深入到字节码层面就可以看出区别
i++与++i,字符串拼接+原理
其它代码优化方法
二.jdk自带的javap
1.javap -help
2.javap -verbose xxx.class > xxx.txt 输出字节码文件的反解析文件
三.基于栈的架构
JVM的执行指令基于栈的架构,电脑常见的都是基于寄存器的
四.i++与++1
iconst压操作数栈
istore放本地变量表
iload从本地变量表压栈
五.常用代码的优化方法
1.尽量重用对象,不要创建对象
2.容器类初始化的时候指定长度
3.ArrayList随机遍历快,LinkedList添加删除快
4.集合遍历尽量减少重复计算
5.使用Entry遍历Map
6.大数组复制用System.arraycopy,调用的native方法
7.尽量使用基本类型而不是包装类型,int而不是integer,integer -128到127会缓存
8.不要手动调用System.gc(),生产环境一般参数禁用
9.及时消除过期对象的引用,防止内存泄露
10.尽量使用局部变量,减小变量的作用域,作用域越小出了作用域变量就可以被回收了
11.尽量使用非同步容易,ArrayList,而不是Vector
12.尽量减小同步作用的范围
synchronized在普通方法上加锁等价于在this上加锁,
在静态方法上加锁,等价于在类上加锁
13.threadlocal缓存线程不安全的对象,simpledataformat构造成本比较高
14.尽量使用延迟加载
15.尽量减少使用反射,加缓存
16.尽量使用连接池,线程池,对象池,缓存
17.及时释放资源,I/O流,Socket,数据库连接
18.慎用异常,不要用抛弃异常来表示正常的业务逻辑
19.String操作尽量少用正则表达式
replaceVs replaceAll,少用第二个
20.日志输出注意使用不同的级别
21.日志中参数拼接使用占位符
log.info("xxx{}",orderid)//这样性能高