paddleserving模型部署,工业级落地部署,高可用、高并发、高吞吐、低延时
完整参考链接:
https://www.paddlepaddle.org.cn/tutorials/projectdetail/1555945
https://github.com/PaddlePaddle/Serving/blob/v0.6.0/README_CN.md
获取模型的方式
训练过程直接保存可部署的模型
”通常训练过程是使用的save_inference_model接口保存模型的,但是这样保存的模型文件中缺少Paddle Serving部署所需要的配置文件。当前Paddle Serving提供了一个save_model的API接口,用于帮助用户在训练过程中保存模型,即将Paddle Serving在部署阶段需要用到的参数与配置文件统一保存打包。相关API接口的应用示例代码如下所示,只要参考下面两行代码将训练程序中的save_inference_model替换为save_model,就可以训练出供Paddle Serving使用的模型文件了。示例中,{“words”: data}和{“prediction”: prediction}分别指定了模型的输入和输出,"words"和"prediction"输入和输出变量的别名,设计别名的目的是为了便于开发者能够记忆自己训练模型的输入输出对应的字段。
静态图
import paddle_serving_client.io as serving_io
serving_io.save_model("serving_model", "client_conf",
{"words": data}, {"prediction": prediction},
paddle.static.default_main_program())
动态图
import paddle_serving_client.io as serving_io
serving_io.save_dygraph_model("serving_model", "client_conf", model)
训练完后进行转换
如果用户已使用paddlejit.save(动态图) 或者 save_inference_model接口(静态图)保存出可用于推理的模型,Paddle Serving为大家提供了paddle_serving_client.convert接口,该接口可以把已保存的模型转换成可用于Paddle Serving使用的模型文件。相关API接口的应用示例代码如下所示,
python -m paddle_serving_client.convert --dirname $MODEL_DIR --model_filename $MODEL_FILENAME --params_filename PARAMS_FILENAME --serving_server $SERVING_SERVER_DIR --serving_client $SERVING_CLIENT_D
其中各个参数解释如下所示:
dirname (str) – 需要转换的模型文件存储路径,Program结构文件和参数文件均保存在此目录。
serving_server (str, 可选) - 转换后的模型文件和配置文件的存储路径。默认值为serving_server。
serving_client (str, 可选) - 转换后的客户端配置文件存储路径。默认值为serving_client。
model_filename (str,可选) – 存储需要转换的模型Inference Program结构的文件名称。如果设置为None,则使用 model 作为默认的文件名。默认值为None。
params_filename (str,可选) – 存储需要转换的模型所有参数的文件名称。当且仅当所有模型参数被保存在一个单独的二进制文件中,它才需要被指定。如果模型参数是存储在各自分离的文件中,设置它的值为None。默认值为None。
上面介绍了两种获取可用于部署在线服务的模型的方法,根据上面的两个例子,新模型保存成功后,飞桨都会按照用户指定的"serving_model和"client_conf""生成两个目录,如下所示:
.
├── client_conf
│ ├── serving_client_conf.prototxt
│ └── serving_client_conf.stream.prototxt
└── serving_model
├── params
├── model
├── serving_server_conf.prototxt
└── serving_server_conf.stream.prototxt
其中,"serving_client_conf.prototxt"和"serving_server_conf.prototxt"是Paddle Serving的客户端和服务端需要加载的配置,"serving_client_conf.stream.prototxt"和"serving_server_conf.stream.prototxt"是配置文件的二进制形式。"serving_model"下保存的其它内容和原先的save_inference_model接口保存的模型文件是一致的。未来我们会考虑在Paddle框架中直接保存可服务的配置,实现配置保存对用户无感,提升用户体验。
四种部署应用方式
常见的深度学习模型开发流程需要经过问题定义、数据准备、特征提取、建模、训练过程,以及最后一个环——将训练出来的模型部署应用到实际业务中。如图1所示,当前用户在训练出一个可用的模型后,可以选择如下四种部署应用方式:
服务器端高性能部署:将模型部署在服务器上,利用服务器的高性能帮助用户处理推理业务。
就是吧静态图的前向推理,从本地搬到服务器上而已,模型本身没有服务化,没有体现分布式部署
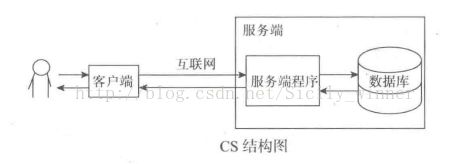
模型服务化部署:将模型以线上服务的形式部署在服务器或者云端,用户通过客户端请求发送需要推理的输入内容,服务器或者云通过响应报文将推理结果返回给用户。


这种方式与其它方式相比,对于使用者来说,最大的特点就是“独乐乐不如众乐乐”。也就是说,在模型部署成功后,不同用户都可以通过客户端以发送网络请求的方式获得推理服务。如图2所示,通过建模、训练获得的模型在部署到云端后形成云服务,例如百度云,百度云会和负载均衡的模块连接,其中负载均衡模块的作用是防止访问流量过大。用户可以通过手机、电脑等设备访问云上的推理服务。
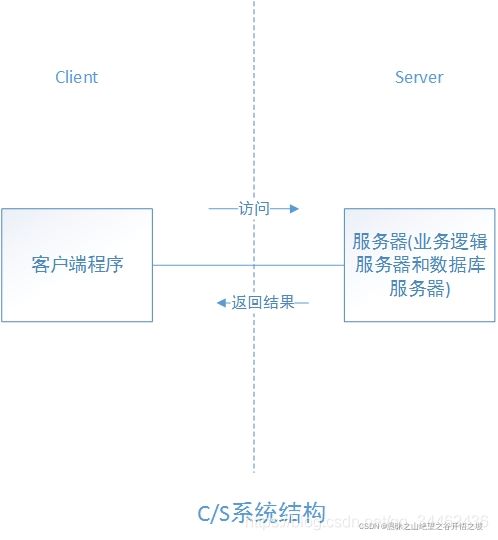
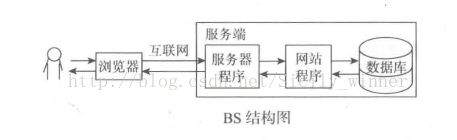
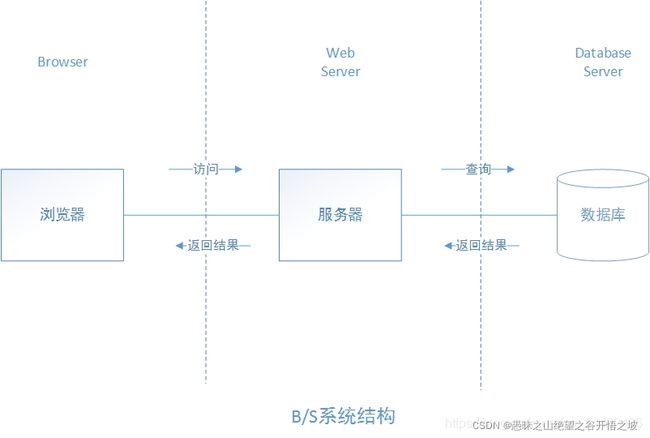
B/S和C/S架构理解
BS:(Browser/Server,浏览器/服务器模式),web应用 可以实现跨平台,客户端零维护,但是个性化能力低,响应速度较慢。
CS:(Client/Server,客户端/服务器模式),桌面级应用 响应速度快,安全性强,个性化能力强,响应数据较快
RPC服务(C/S结构)(c/c++,客户端类似app)
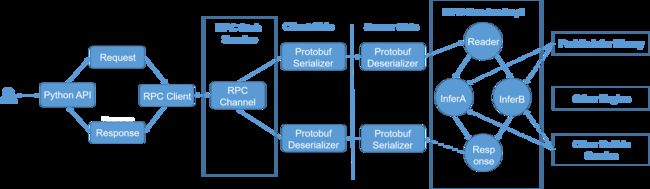
一行命令启动RPC方式的推理服务的原理是什么呢?如下图所示,该图为RPC推理服务的流程图。Paddle Serving使用了百度开源的PRC通信库,该通信库使用可兼容多种语言的Protobuf格式的报文来封装请求或响应字段。
在推理过程中,Client端把用户的输入数据,例如一条或多条电影评论打包到Protobuf报文中并发送给服务端。服务端内部有多个算子,通过这些算子服务端在收到Protobuf报文后,可以从Protobuf报文中解析出飞桨推理库可以读取的输入数据格式,然后由推理库做推理,推理结果将被重新封装为Protobuf格式返回给客户端。显而易见,通过使用Paddle Serving,用户将不需要去了解飞桨的推理库的输入输出格式,整个从读取输入数据到返回推理结果都将由Paddle Serving服务端内部的算子完成。Paddle Serving通过paddle_serving_server_gpu.serve(paddle_serving_server.serve)这个服务模块将这些算子串联到一起,完成整个在线推理的服务流程。因此用户仅需要一条命令调用这个服务模块,并设定好推理使用的模型以及服务端口等信息,即可完成在线推理服务启动工作。
服务端没有逻辑,客户端编写预处理和后处理逻辑
RPC服务是CS架构,用户使用客户端来访问服务端获取推理结果,客户端和服务端之间的通信使用的是百度开源的一款RPC通信库来完成的。RPC具有高并发、低延时等特点,已经支持了包括百度在内上百万在线推理实例、上千个在线推理服务,稳定可靠,其整体性能要优于HTTP,但是只能适用于Linux操作系统,而且需要编写Client端的代码。如果用户的推理业务需要数据前后处理,例如训练图片的归一化,文本的ID化等等,这部分代码也需要包含在客户端中。
用户还可以使用paddle_serving_server.serve启动RPC服务。 尽管用户需要基于Paddle Serving的python客户端API进行一些开发,但是RPC服务通常比HTTP服务更快。需要指出的是这里我们没有指定–name。
HTTP服务(Web服务)(B/S架构)
服务端直接包含了逻辑处理部分
用户可以将数据格式处理逻辑放在服务器端进行,这样就可以直接用curl去访问服务
Web服务是BS架构,用户可以使用浏览器或其它Web应用通过HTTP协议访问服务端。与RPC相比其优势在于可以适用于包括Linux操作系统在内的不同系统环境。此外还省去了编写客户端代码的工作量,仅需要使用服务端设定的URL就可以发送推理请求,获取推理结果。但是如果需要做预处理操作,则需要在服务端上做二次开发,由服务段使用Paddle Serving的内置预处理模块完成数据预处理操作。
Pipeline服务
RRC的服务非常简单易用,但是在具体的生产环境中会有如下的问题
难以处理多个模型以流水线的方式串联。例如推荐系统中有召回、排序等服务。这种情况RPC服务做多模型管理复杂且易错,需要更高级的模型串联管理框架。
难以精确管理每个模型的资源开销,精确调控每个模型的使用设备,进程数量,部署方式等等
难以同时提供rpc协议和rest接口,难以支持多语言和多操作系统。
为此Pipeline做了如下操作。
设计pipeline server可以通过DAG有向无环图的方式定义多模型串联。
模型服务以Op的形式呈现,通过config文件配置每个Op的资源使用。
通过grpc-gateway,利用自动生成的Go程序转发HTTP请求,实现同时暴露rest和rpc服务的目的。
Pipeline 客户端和 RPC客户端的异同
相同点: 都需要初始化一个Client/PipelineClient的对象,然后连接一个或者多个endpoint,通过数据读取组装feed dict,调用predict函数。
不同点:RPC客户端的feed字典严格按照 client端配置的prototxt文件定义的feed和fetch。RPC在Pipeline中以一个Op的形式出现,在Op的preprocess返回部分需要传入feed和fetch,在底层调用RPC服务。Pipeline client的feed字典只需要和Server端的第一个Op的输入和最后一个Op的输出相匹配就可以,具体的key值可以自行定义。例如OCR的例子当中,发送的feed字典的key为image,与此同时,在Pipeline Server端的第一个DetOp的preprocess函数,我们就可以看到对feed字典的解包,中间用到了image这个key;相似的,在RecOp当中,最后的返回值是res,也和pipeline client predict函数的fetch参数相吻合。
通过这个样例,我们可以感受到Pipeline的以下优势
多模型串联易用性,只需要定义op的串联关系,和op之间feed dict匹配,就可以用config yaml管理各个模型的资源使用和端口管理。
多语言多平台支持,同时暴露grpc和http服务,满足市面上想象得到的所有平台。
前后处理的易用性,与其他框架相比,pipeline在前后处理部分全部用python封装,用户可以直接从套件库或训练代码直接移植前后处理,不会出现在跨语言时重新实现一遍前后处理的难题。
Paddle Serving提供业界领先的多模型串联服务,强力支持各大公司实际运行的业务场景
我们先获取两个模型
python3 -m paddle_serving_app.package --get_model ocr_rec
tar -xzvf ocr_rec.tar.gz
python3 -m paddle_serving_app.package --get_model ocr_det
tar -xzvf ocr_det.tar.gz
然后启动服务端程序,将两个串联的模型作为一个整体的服务。
python3 web_service.py
最终使用http的方式请求
python3 pipeline_http_client.py
也支持rpc的方式
python3 pipeline_rpc_client.py
输出
{‘err_no’: 0, ‘err_msg’: ‘’, ‘key’: [‘res’], ‘value’: ["[‘土地整治与土壤修复研究中心’, ‘华南农业大学1素图’]"]}
移动端部署:将模型部署在移动端上,例如手机或者物联网的嵌入式端。
Web端部署(前端部署):将模型部署在网页上,用户通过网页完成推理业务。
服务端模型服务化部署,具体指令
rpc
python -m paddle_serving_server_gpu.serve --model imdb_lstm_model/ --port 9292 --gpu_id 0
参数 取值类型 缺省值 描述
thread int 4 当前服务的并发数量
port int 292 向用户公开的服务端口
name str “” 服务名,可用于生成HTTP请求url,配置了该参数则表示启动的是HTTP服务,否则启动的是RPC服务
model str “” 待服务的飞桨模型所在目录
mem_optim bool True 启用内存优化
ir_optim bool False 启用计算图的分析和优化
use_trt(Only for gpu version) bool False 启用tensor RT(仅限GPU)
multilang bool False 启用grpc服务端(否则启用brpc服务端)
use_mkl (Only for cpu version) bool False 用MKL进行推理
use_lite bool False 用ARM设备推理
use_xpu bool False 用昆仑芯片推理
Pipeline
完整版参数配置文档说明
https://hub.fastgit.org/PaddlePaddle/Serving/blob/v0.7.0/doc/Serving_Configure_CN.md#python-pipeline
Python Pipeline提供了用户友好的多模型组合服务编程框架,适用于多模型组合应用的场景。 其配置文件为YAML格式,一般默认为config.yaml。示例如下:
#rpc端口, rpc_port和http_port不允许同时为空。当rpc_port为空且http_port不为空时,会自动将rpc_port设置为http_port+1
rpc_port: 18090
#http端口, rpc_port和http_port不允许同时为空。当rpc_port可用且http_port为空时,不自动生成http_port
http_port: 9999
#worker_num, 最大并发数。当build_dag_each_worker=True时, 框架会创建worker_num个进程,每个进程内构建grpcSever和DAG
##当build_dag_each_worker=False时,框架会设置主线程grpc线程池的max_workers=worker_num
worker_num: 20
#build_dag_each_worker, False,框架在进程内创建一条DAG;True,框架会每个进程内创建多个独立的DAG
build_dag_each_worker: false
dag:
#op资源类型, True, 为线程模型;False,为进程模型
is_thread_op: False
#重试次数
retry: 1
#使用性能分析, True,生成Timeline性能数据,对性能有一定影响;False为不使用
use_profile: false
tracer:
interval_s: 10
op:
det:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 6
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf:
#client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测
client_type: local_predictor
#det模型路径
model_config: ocr_det_model
#Fetch结果列表,以client_config中fetch_var的alias_name为准
fetch_list: ["concat_1.tmp_0"]
# device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type: 0
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices: ""
#use_mkldnn, 开启mkldnn时,必须同时设置ir_optim=True,否则无效
#use_mkldnn: True
#ir_optim,开启TensorRT时,必须同时设置ir_optim=True,否则无效
ir_optim: True
#precsion, 预测精度,降低预测精度可提升预测速度
#GPU 支持: "fp32"(default), "fp16", "int8";
#CPU 支持: "fp32"(default), "fp16", "bf16"(mkldnn); 不支持: "int8"
precision: "fp32"
rec:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 3
#超时时间, 单位ms
timeout: -1
#Serving交互重试次数,默认不重试
retry: 1
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf:
#client类型,包括brpc, grpc和local_predictor。local_predictor不启动Serving服务,进程内预测
client_type: local_predictor
#rec模型路径
model_config: ocr_rec_model
#Fetch结果列表,以client_config中fetch_var的alias_name为准
fetch_list: ["ctc_greedy_decoder_0.tmp_0", "softmax_0.tmp_0"]
# device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type: 0
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices: ""
#use_mkldnn, 开启mkldnn时,必须同时设置ir_optim=True,否则无效
#use_mkldnn: True
#ir_optim,开启TensorRT时,必须同时设置ir_optim=True,否则无效
ir_optim: True
#precsion, 预测精度,降低预测精度可提升预测速度
#GPU 支持: "fp32"(default), "fp16", "int8";
#CPU 支持: "fp32"(default), "fp16", "bf16"(mkldnn); 不支持: "int8"
precision: "fp32"
#worker_num, 最大并发数。当build_dag_each_worker=True时, 框架会创建worker_num个进程,每个进程内构建grpcSever和DAG
##当build_dag_each_worker=False时,框架会设置主线程grpc线程池的max_workers=worker_num
worker_num: 1
#http端口, rpc_port和http_port不允许同时为空。当rpc_port可用且http_port为空时,不自动生成http_port
rpc_port: 9998
http_port: 18082
dag:
#op资源类型, True, 为线程模型;False,为进程模型
is_thread_op: False
op:
uci:
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 2
#uci模型路径
model_config: uci_housing_model
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices: "" # "0,1"
#client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测
client_type: local_predictor
#Fetch结果列表,以client_config中fetch_var的alias_name为准
fetch_list: ["price"]