MongoDB入门与实战-第三章-数据操作增删改查索引
目录
- 参考
- 官方文档
- 表结构
-
- 新增字段
- 修改表字段重命名
- 删除字段
- 基础操作
- 插入数据
-
- insert
- insertOne
- insertMany
- 查询数据
-
- 1、基础查询
-
- find()
- findOne()
- count()
- 2.查询运算符的使用
- 3.分页查询
- 4.排序
- 5、聚合distinct
- 6、逻辑与或非
- 7、成员运算
- 8、类型$type
- 9、正则
- 10、投影(类似于查询指定列)
- 11、数组
- 12、查询某一天
- 修改数据
-
- 1.替换整个文档
- 2.修改对应的属性,需要用到修改操作符,比如 s e t , set, set,unset, p u s h , push, push,addToSet
- 3.updateMany()可以用来更改匹配到的所有文档
- 4.向数组中添加数据
- 5.自增自减操作符$inc
- 删除数据
-
- 1. db.collectionName.remove()
- 2. db.collectionName.deleteOne()
- 3. db.collectionName.deleteMany()
- 4. 删除所有数据:db.students.remove({})----性格较差,内部是在一条一条的删除文档。
- 5.删除集合
- 6.删除数据库
- 7.注意:删除某一个文档的属性,应该用update。 remove以及delete系列删除的是整个文档
- 8.当删除的条件为内嵌的属性时:
- 9.删除重复
- 参数解释
- 文档关系
-
- 一对一
- 一对多
- 多对多
- 聚合查询
-
- 演示数据
- Aggregate语法
- $match和 $group
-
- 取最大值和最小值
- 取分组里面最大的id和最小的id
- 求每个岗位的总工资并排序
- 求每个岗位的人数
- 查询岗位名以及岗位内的员工姓名:select post,group_concat(name) from db1.emp group by post;
- $project
- $sort 和 $limit 和 $skip
-
- 取平均工资最高的两个岗位
- 去平均工资最高的第二个岗位
- $simple
- $concat 和 $substr 和 $toLower 和 $toUpper
-
- 截取字符串,不展示_id
- 拼接
- 将性别转换为大写
- 索引
-
- 创建索引
- 查询索引
- explain输出
- 配置修改
-
- 忘记密码
参考
https://github.com/Vacricticy/mongodb_practice
MongoDB之索引
官方文档
https://docs.mongodb.com/docs/manual/reference/update-methods/
表结构
新增字段
db.collection.update(criteria,objNew,upsert,multi)
# demo
db.device.update({}, {$set: {projectId:"1584383990662078466"}}, {multi: 1})
# 1 、添加一个字段. table 代表表名 , 添加字段 content,字符串类型。
db.table.update({}, {$set: {content:""}}, {multi: 1})
参数说明:
- criteria:查询条件
- objNew:update对象和一些更新操作符
- upsert:如果不存在update的记录,是否插入objNew这个新的文档,true为插入,默认为false,不插入。
- multi:默认是false,只更新找到的第一条记录。如果为true,把按条件查询出来的记录全部更新。
修改表字段重命名
db.getCollection("device").update({}, {$rename : {"code":"deviceCode", "name":"deviceName"}}, false, true)
xx版本之后使用update和updateOne只能更新满足条件的一条文档。
例子,将原来的字段名raw_field修改成新的字段名new_field。
db.Test.update({}, {'$rename': {'raw_field': 'new_field}}, false, true)
# 或者
db.Test.updateOne({}, {'$rename': {'raw_field': 'new_field}}, false)
其实上面的update语句中:
- {}:是过滤条件。(更新哪些文档);
- {’$rename’: {‘raw_field’: 'new_field}}:是更新操作;
- false:若根据该过滤条件无法找到匹配的文档时,不插入该文档。
- true:更新多条(但是我在用这个的时候不太好使,还是用的updateMany来更新的多条)。
删除字段
db.url.update({}, {$unset:{'content':''}},false, true)
基础操作
# 查看所有的数据库
show dbs 或show databases
# 切换到指定的数据库
use xxx
# 查看当前操作的数据库
db
# 查看当前数据库中所有的集合
show collections
插入数据
insert
db.collectionName.insert( {name:'liu5'} )
db.collectionName.insert( [ {name:'liu5'} , {name:'liu6'} ] )
db.user insert({
"_id": "11",
"name":"zhangsan",
"age":18,
"hobbies":["music","read"],
"addr":{
"country":"China",
"city":"BJ"
}
})
insertOne
当我们向集合插入一个或多个文档时,如果没有指定_id,则mongodb会自动生成,该属性用来作为文档的唯一标识
# 插入一条数据
db.collectionName.insertOne( {name:'liu'} )
# db表示的是当前操作的数据库
collectionName表示操作的集合,若没有,则会自动创建
# 插入的文档如果没有手动提供_id属性,则会自动创建一个
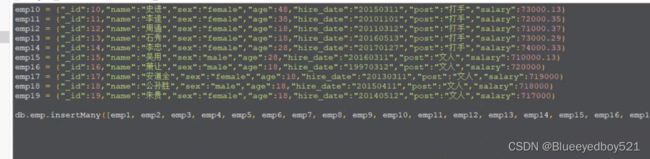
insertMany
## 插入多条数据
db.collectionName.insertMany( [ {name:'liu5'} , {name:'liu6'} ] )
db.collectionName.insert( [ {name:'liu5'} , {name:'liu6'} ] )
需要用数组包起来
万能API:db.collectionName.insert()
#添加两万条数据
for(var i=0;i<20000;i++){
db.users.insert({username:'liu'+i}) #需要执行20000次数据库的添加操作
}
db.users.find().count()//20000
通过数组批量插入
# 优化:
var arr=[];
for(var i=0;i<20000;i++){
arr.push({username:'liu'+i})
}
db.user.insert(arr) #只需执行1次数据库的添加操作,可以节约很多时间
指定自定义id
db.collectionName.insertOne( {_id:"xxxx",name:'liu'} )
查询数据
1、基础查询
find()
db.collectionName.find() 或db.collectionName.find({})
查询集合所有的文档,即所有的数据。
查询到的是整个数组对象。在最外层是有一个对象包裹起来的。
db.collectionName.find({_id:222})
findOne()
条件查询。注意:结果返回的是一个数组
db.collectionName.findOne() 返回的是查询到的对象数组中的第一个对象
注意:
db.students.find({_id:222}).name //错误
db.students.findOne({_id:222}).name //正确
# 1.mongodb支持直接通过内嵌文档的属性值进行查询
# 什么是内嵌文档:hobby就属于内嵌文档
{
name:'liu',
hobby:{
movies:['movie1','movie2'],
cities:['zhuhai','chengdu']
}
}
db.users.find({hobby.movies:'movie1'}) //错误
db.users.find({"hobby.movies":'movie1'})//此时查询的属性名必须加上引号
count()
db.collectionName.count()或db.collectionName.length() 统计文档个数
2.查询运算符的使用
#比较操作符
$gt 大于
$gte 大于等于
$lt 小于
$lte 小于等于
$ne 不等于
$eq 等于的另一种写法
db.users.find({num:{$gt:200}}) #大于200
db.users.find({num:{$gt:200,$lt:300}}) #大于200小于300
$or 或者
db.users.find(
{
$or:[
{num:{$gt:300}},
{num:{$lt:200}}
]
}
) #大于300或小于200
3.分页查询
db.users.find().skip(页码-1 * 每页显示的条数).limit(每页显示的条数)
db.users.find().skip(pageIndex-1 * pageSize).limit(pageSize)
db.users.find().limit(10) #前10条数据
db.users.find().skip(50).limit(10) #跳过前50条数据,即查询的是第61-70条数据,即第6页的数据
4.排序
db.emp.find().sort({sal:1}) #1表示升序排列,-1表示降序排列
db.emp.find().sort({sal:1,empno:-1}) #先按照sal升序排列,如果遇到相同的sal,则按empno降序排列
#注意:skip,limit,sort可以以任意的顺序调用,最终的结果都是先调sort,再调skip,最后调limit
#5.设置查询结果的投影,即只过滤出自己想要的字段
db.emp.find({},{ename:1,_id:0}) #在匹配到的文档中只显示ename字段
5、聚合distinct
# 查询所有的name
db.user.distinct("name")

6、逻辑与或非
$and,$or,$not
# 1)、select * from user where id>=3 and id<=4
db.user.find({"_id":{"$gte":3, "$lte":4}})
# 2)、select * from user where id >= 3 and id <= 4 and age >= 4
db.user.find({
"_id":{"$gte":3, "$lte":4}},
"age":{"$gte":4}
)
# 另一种写法
db.user.find({
"$and":[
{"_id":{"$gte":3, "$lte":4}},
{"age":{"$gte":4}}
]
})
# 3)、select * from user where id >= 0 and id <= 1 or id >= 4 or name = 'tianqi'
db.user.find({
"$or":[
{"_id":{"$gte":0, "$lte":1}},
{"_id":{"$gte":4}},
{"name":"tainqi"}
]
})
# 另一种写法
db.user.find({
"$or":[
"$and":[
{"_id":{"$gte":0}},
{"_id":{"$lte":1}}
],
{"_id":{"$gte":4}},
{"name":"tainqi"}
]
})
# 4)、select * from user where id % 2 = 1
db.user.find({"_id":{"$mod":[2,1]}})
# 5)、上一条取反
db.user.find({"_id":{"$not":{"$mod":[2,1]}}})
7、成员运算
$in $nin
# 1)、select * from user where age in (1,2,3)
db.user.find("age":{"$in":[1,2,3]});
# 1)、select * from user where name not in ('zhangsan', 'lisi')
db.user.find("age":{"$nin":["zhangsan", "lisi"]});
8、类型$type
mongoDB可以使用的类型如下表所示:
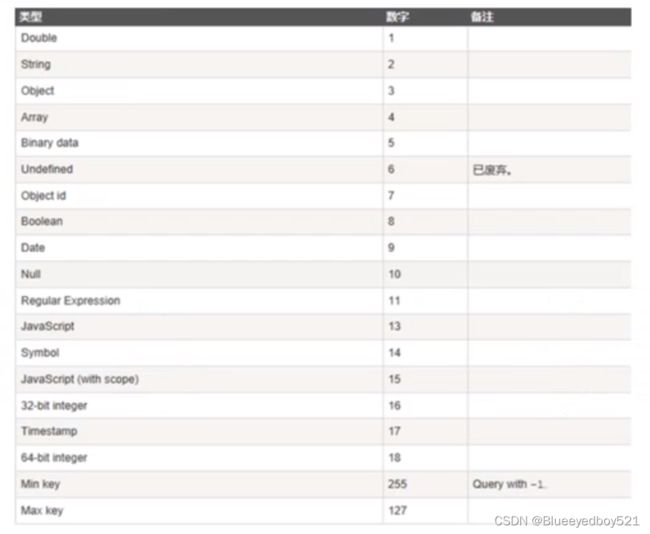
# 查询name是字符串类型的数据
db.user.find({name:{$type:2}})
9、正则
正则定义在/ / 内
# 匹配规则:z开头、n或者u结尾,不区分大小写
# select * from user where name regexp '^z.*?(n|u)$'
db.user.find({"name": /^z.*?(n|u)$/i})
10、投影(类似于查询指定列)
# 查询时,可以在第二个参数的位置来设置查询结果的投影
# 如下语句只查询ename字段,但是会查出_id, ename两个字段,_id是默认
db.emp.find({}, {ename:1});
# 也可以指定不显示_id
db.emp.find({}, {_id:0, ename:1});
11、数组
# 查hobbies中有dancing的人
db.user.find({"hobbies":"dancing"})
# 查看机油dancing爱好又有tea爱好的人
db.user.find({"hobbies":{"$all":["dancing", "tea"]}})
# 查看索引第二个爱好为dancing的人(索引从0开始计算)
db.user.find({"hobbies.1":"dancing"})
# 查看所有人的第1到第2个爱好,第一个{}表示查询条件为所有,第二个显示条件(左闭右开)
db.user.find({},{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":[0,2]}
})
# 查询所有人最后两个爱好,第一个{}表示查询条件为所有,第二个是显示条件
db.user.find({},{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":-2}
})
# 查询子文档有"country":"china"的人
db.user.find({"addr.country":"china"})```
12、查询某一天
方法一、
db.集合名.find({con_date:new Date("2018-08-13")})
db.集合名.find({con_date:ISODate("2018-08-13")})
方法二、
db.集合名.find({con_date:{'$gte':ISODate("2010-12-21"),'$lt':ISODate("2010-12-22")}})
注意:使用gte和lt形式
方法三、
db.集合名.find({con_date:{'$gte':new Date('2018/08/21 00:00:00'),'$lte':new Date('2018/08/21 23:59:59')}})
db.集合名.find({con_date:{'$gte':new Date('2018-08-21 00:00:00'),'$lte':new Date('2018-08-21 23:59:59')}})
注意:使用 $gte与$lte
方法四、
db.集合名.find({con_date:ISODate("2018-02-13T16:00:00.000Z")})
db.集合名.find({con_date:ISODate("2018-08-13")})
java代码参考:查询mongodb当天数据
/*
相差8个时区
24 = 16 + 8
db.getCollection("elevator_alarm").find({deviceCode:"1589581864182480897",timestamp:{"$gte":ISODate("2022-11-07T16:00:00.000Z")}}).sort({timestamp:-1})
*/
//mongodb查询条件
Query query = new Query();
query.addCriteria(Criteria.where(IotConstant.FIELD_DEVICE_CODE).is(param.getDeviceCode()));
String todayStr = DateUtil.yesterday().toDateStr();
Date today = DateUtil.parseDateTime(todayStr+" 00:00:00");
query.addCriteria(Criteria.where(IotConstant.FIELD_TIMESTAMP).gte(today));
long count = mongoTemplate.count(query,Dto.class);
修改数据
1.替换整个文档
# db.collectionName.update(condiction,newDocument)
db.students.update({_id:'222'},{name:'kang'})
这种操作会用新对象完全替换旧对象,而不是修改指定属性
2.修改对应的属性,需要用到修改操作符,比如 s e t , set, set,unset, p u s h , push, push,addToSet
db.collectionName.update(
# 查询条件
{_id:222},
{
#修改对应的属性
$set:{
name:'kang2',
age:21
}
#删除对应的属性
$unset:{
gender:1 //这里的1可以随便改为其他的值,无影响
}
}
)
update默认与updateOne()等效,即对于匹配到的文档只更改其中的第一个
3.updateMany()可以用来更改匹配到的所有文档
db.students.updateMany(
{name:'liu'},
{
$set:{
age:21,
gender:222
}
}
)
# 使用update也可以实现修改多个
db.collectionName.update(
# 查询条件
{_id:222},
{
#修改对应的属性
$set:{
name:'kang2',
age:21
}
#删除对应的属性
$unset:{
gender:1 //这里的1可以随便改为其他的值,无影响
},{
multi: true // 表示修改多个
}
}
)
4.向数组中添加数据
db.users.update({username:'liu'},{$push:{"hobby.movies":'movie4'}})
#如果数据已经存在,则不会添加
db.users.update({username:'liu'},{$addToSet:{"hobby.movies":'movie4'}})
5.自增自减操作符$inc
{$inc:{num:100}} #让num自增100
{$inc:{num:-100}} #让num自减100
db.emp.updateMany({sal:{$lt:1000}},{$inc:{sal:400}}) #给工资低于1000的员工增加400的工资
删除数据
1. db.collectionName.remove()
# remove默认会删除所有匹配的文档。相当于deleteMany()
# remove可以加第二个参数,表示只删除匹配到的第一个文档。此时相当于deleteOne()
db.students.remove({name:'liu',true})
# 删除集合所有数据,性能较差,先匹配在删除
db.students.remove({})
2. db.collectionName.deleteOne()
db.students.deleteOne({name:'liu'})
3. db.collectionName.deleteMany()
db.students.deleteMany({name:'liu'})
4. 删除所有数据:db.students.remove({})----性格较差,内部是在一条一条的删除文档。
# 可直接通过db.students.drop()删除整个集合来提高效率。
5.删除集合
# 清空集合,并把集合也删除
db.collection.drop()
6.删除数据库
db.dropDatabase()
7.注意:删除某一个文档的属性,应该用update。 remove以及delete系列删除的是整个文档
8.当删除的条件为内嵌的属性时:
db.users.remove({"hobby.movies":'movie3'})
9.删除重复
参考:Mongodb操作(二):批量查重及去重
# 先查询重复 对应sql
select deviceCode,timestamp,count(*) as count from data where deviceCode = '22122121' group by deviceCode,timestamp having count>1;
# mongodb
db.data.aggregate([ {$match: {deviceCode: '22122121'}},{$group: { _id : {deviceCode:"$deviceCode",timestamp:"$timestamp" }, count: {$sum: 1}}}, {$match: {count: {$gt: 1}}}], {allowDiskUse: true})
## 删除
db.data.aggregate([ {$match: {deviceCode: '22122121'}},{$group: { _id : {deviceCode:"$deviceCode",timestamp:"$timestamp" }, count: {$sum: 1},'dups':{'$addToSet':'$_id'}}}, {$match: {count: {$gt: 1}}}], {allowDiskUse: true}).forEach(function(doc){
doc.dups.shift();
db.data.remove({_id:{$in:doc.dups}});
})
参数解释
(1)根据author_name、tid等分组并统计数量, g r o u p 只会返回参与分组的字段,使用 group只会返回参与分组的字段,使用 group只会返回参与分组的字段,使用addToSet在返回结果数组中增加_id字段
(2)使用 m a t c h 匹配数量大于 1 的数据( 3 ) d o c . d u p s . s h i f t ( ) ; 作用是剔除重复数据其中一 个 i d ,让后面的删除语句不会删除所有数据( 4 )使用 f o r E a c h 循环根 据 i d 删除数据( 5 ) match匹配数量大于1的数据 (3)doc.dups.shift();作用是剔除重复数据其中一个_id,让后面的删除语句不会删除所有数据 (4)使用forEach循环根据_id删除数据 (5) match匹配数量大于1的数据(3)doc.dups.shift();作用是剔除重复数据其中一个id,让后面的删除语句不会删除所有数据(4)使用forEach循环根据id删除数据(5)addToSet 操作符只有在值没有存在于数组中时才会向数组中添加一个值。如果值已经存在于数组中,$addToSet返回,不会修改数组。
(6)allowDiskUse: true
数据过大会报内存错误:Exceeded memory limit for g r o u p , b u t d i d n ′ t a l l o w e x t e r n a l s o r t . P a s s a l l o w D i s k U s e : t r u e t o o p t i n 可以在后面添加上这个属性就不会了。数据不大的情况下,可以不用试一下注意: f o r E a c h 和 group, but didn't allow external sort. Pass allowDiskUse:true to opt in 可以在后面添加上这个属性就不会了。数据不大的情况下,可以不用试一下 注意:forEach和 group,butdidn′tallowexternalsort.PassallowDiskUse:truetooptin可以在后面添加上这个属性就不会了。数据不大的情况下,可以不用试一下注意:forEach和addToSet的驼峰写法不能全部写成小写,因为mongodb严格区分大小写。
文档关系
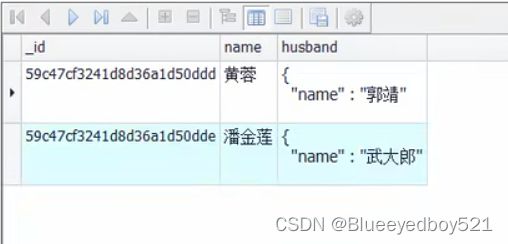
一对一
db.wifeAndHusband.insert([
{
name:'黄蓉',
husband:{
name:'郭靖'
}
},
{
name:'潘金莲',
husband:{
name:'武大郎'
}
}
])
查询db.wifyAndHusband.find()
一对多
#用户与订单:
db.users.insert([
{_id:100,username:'liu1'},
{_id:101,username:'liu2'}
])
db.orders.insert([
{list:['apple','banana'],user_id:100},
{list:['apple','banana2'],user_id:100},
{list:['apple'],user_id:101}
])
查询liu1的所有订单:
首先获取liu1的id: var user_id=db.users.findOne({name:‘liu1’})._id;
根据id从订单集合中查询对应的订单: db.orders.find({user_id:user_id})
多对多
#老师与学生
db.teachers.insert([
{
_id:100,
name:'liu1'
},
{
_id:101,
name:'liu2'
},
{
_id:102,
name:'liu3'
}
])
db.students.insert([
{
_id:1000,
name:'xiao',
tech_ids:[100,101]
},
{
_id:1001,
name:'xiao2',
tech_ids:[102]
}
])
聚合查询
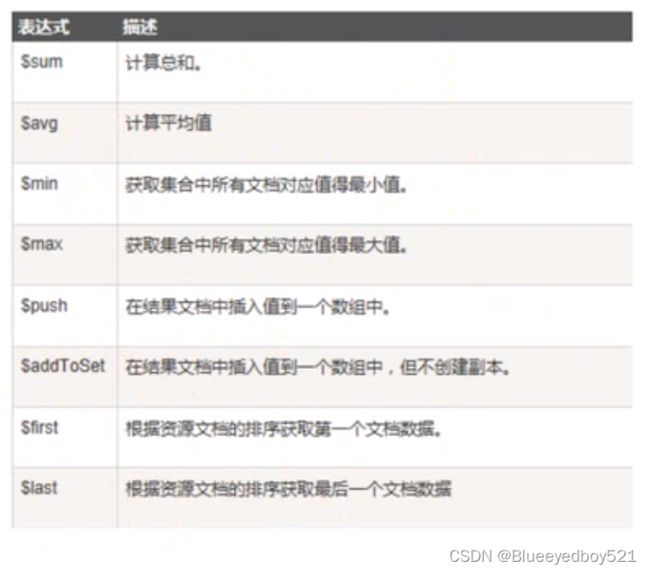
我们在查询时肯定会用到聚合,在MongoDB中聚合为aggregate,
聚合函数主要用到$match,$group, $avg, $project, $concat
演示数据
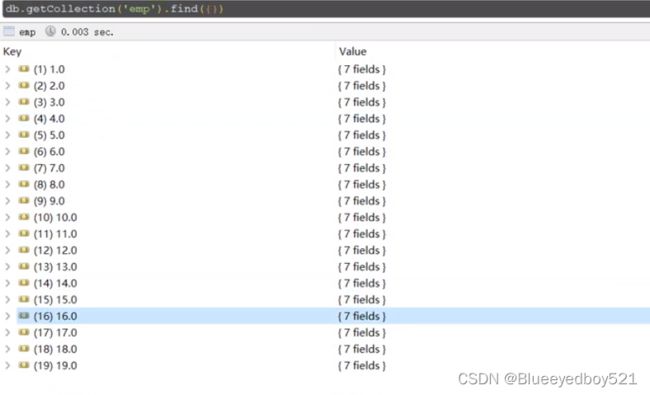
Aggregate语法
基本格式:
db.collection.aggregate(pipeline,options)
- pipeline
一系列数据聚合操作或阶段。在版本2.6中更改:该方法仍然可以将流水线阶段作为单独的参数
接受,而不是作为数组中的元素;但是,如果不将管道指定为数组,则不能指定options参数。目前所使用的4.0.4版本必须使用数组。 - options
可选。aggregate()传递给聚合命令的其他选项。2.6版中的新增功能:仅当将管道指定为数组时
才可用。
注意:使用db.collection.aggregate()直接查询会提示错误,但是传一个空数组如db.collection.aggregate([])则不会报错,且会和find一样返回所有文档。
$match和 $group
相当于sq语句中的where和group by
{"$match": {"字段": "条件"}}},可以使用任何常用查询操作符$gt,$lt $in等
# select * from db1.emp where post='公务员'
db.emp.aggregate([{"$match":{"post":"公务员"}}])
# select* from db1.emp where id > 3 group by post;
db.emp.aggregate([
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post":'avg.salary':{"$avg":"$salary"}}}
])
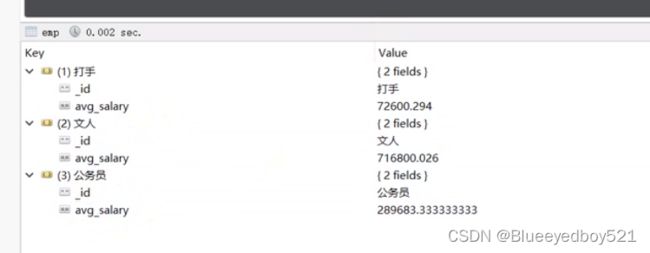
# select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate([
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post":'avg.salary':{"$avg":"$salary"}}},
{"$match":{"avg.salary":{"$gt":10000}}},
])
# "$group":("_id:分组字段,"新的字段名":聚合操作符}}
# 1)、将分组字段传给$group函数的_id字段即可
{"$group":{"_id":"$sex"}} # 按照性别分组
{"$group":{"_id":"$post"}} # 按照职位分组
{"$group":{"_id":{"state":"$state","city":"$city"}}} # 按照多个字段分组,比如按照州市分组

取最大值和最小值

取分组里面最大的id和最小的id

求每个岗位的总工资并排序

求每个岗位的人数
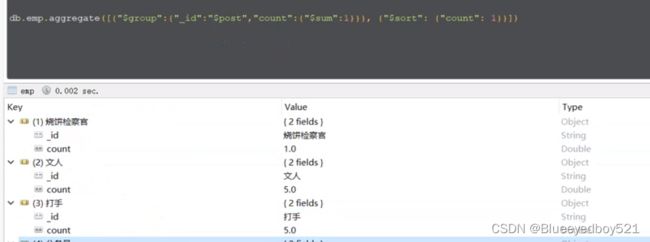
数组操作符(重复/不重复)求每个岗位中的所有人名
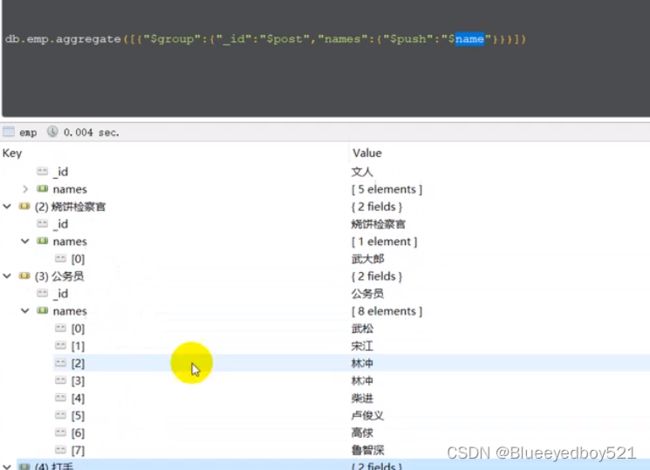
查询岗位名以及岗位内的员工姓名:select post,group_concat(name) from db1.emp group by post;
重复的也查出来
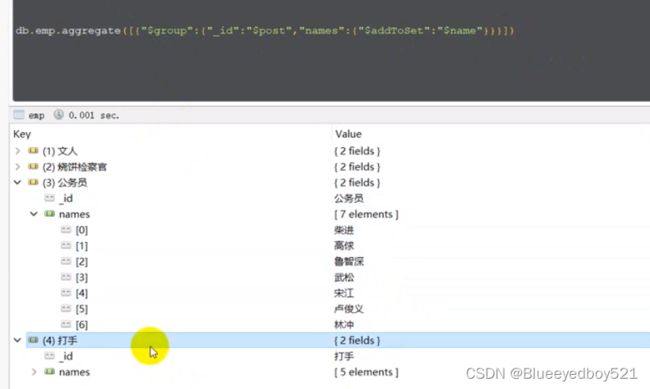
查询不重复的,如果有重复的保留一个
$project
用于投射,及设定该键值对是否保留。1为保留,0为不保留,可对原有键值对做操作后,增加自定义表达式(查询哪些要显示的列)
{"$project": {"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}}
# select name,post,(age+1) as new_age from db1.emp;
db.emp.aggregate([
{
$project:{
"name":1,
"post":1.
"new_age":{"$add":["$age",1]}
}
}
])
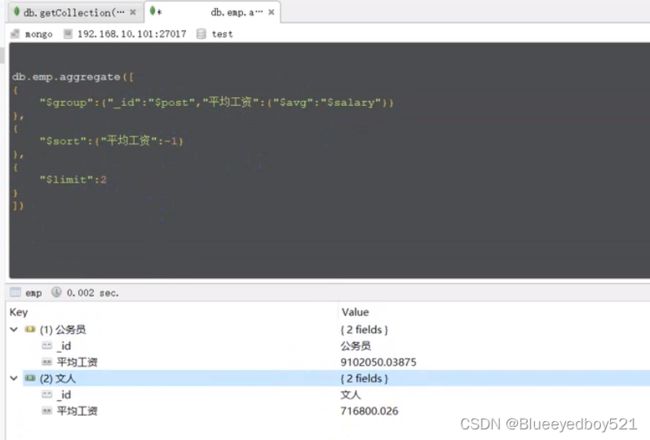
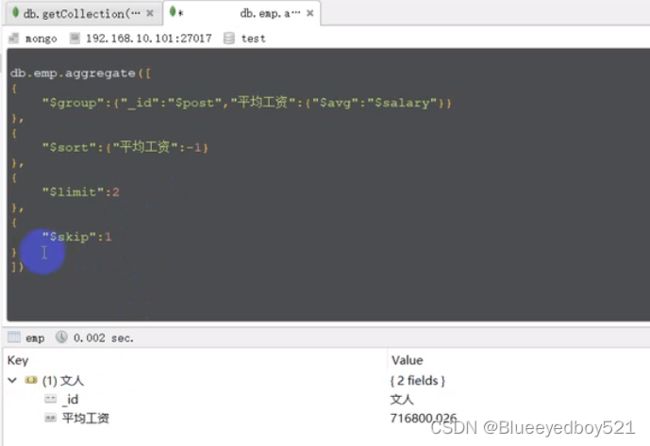
$sort 和 $limit 和 $skip
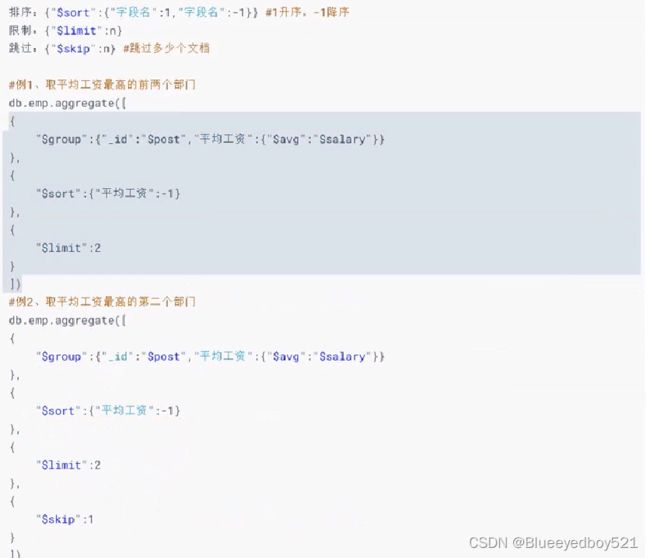
取平均工资最高的两个岗位
去平均工资最高的第二个岗位
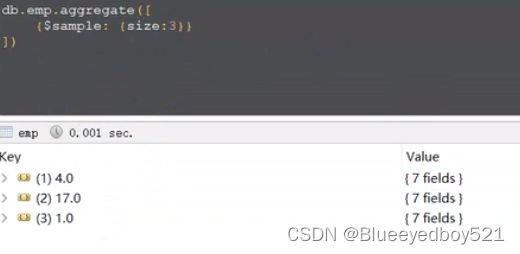
$simple
随机获取3个文档
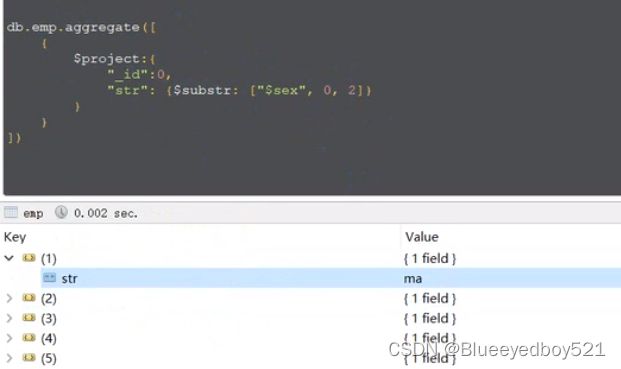
$concat 和 $substr 和 $toLower 和 $toUpper

截取字符串,不展示_id
拼接
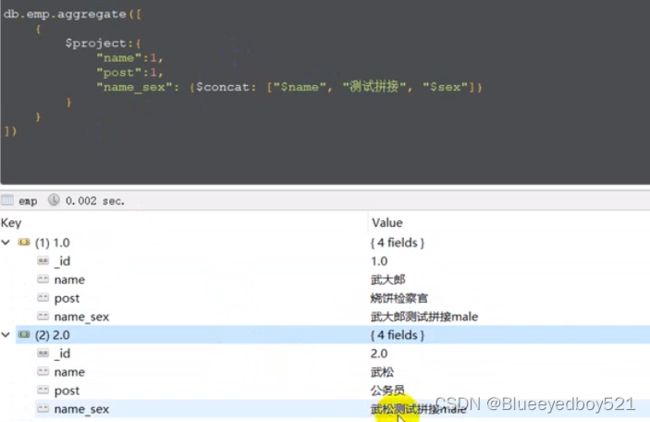
将性别转换为大写

索引
创建索引
索引通常能够极大的提供查询的效率,MongoDB使用createIndex()方法来创建索引,其基本语法格式如下所示:
db.tower_crane_data.createIndex({"deviceCode":1,"timestamp":-1});
key:创建的索引字段,1为指定升序创建索引,-1则按照降序来创建索引
db.user.createIndex({"name":-1})
# 指定所建立索引的名字
db.user.createIndex({"name":1},{"name":"nameIndex"})
ensureIndex()接收可选参数,可选参数列表如下:
查询索引
db.collection_name.getIndexes()
explain输出
explain 可以为查询提供大量的信息。对于慢查询来说,它是最重要的诊断工具之一。通过查看一个查询的 explain输出,可以了解查询都使用了哪些索引以及是如何使用的。对于任何查询,都可以在末尾添加一个 explain 调用(就像添加sort 或 limit 一样,但是 explain 必须是最后一个调用)。
重要字段的详细介绍:
“isMultiKey” : false
本次查询是否使用了多键索引
“nReturned” : 8449
本次查询返回的文档数量。
“totalDocsExamined” : 8449
MongoDB 按照索引指针在磁盘上查找实际文档的次数。如果查询中包含的查询条件不是索引的一部分,或者请求的字段没有包含在索引中,MongoDB 就必须查找每个索引项所指向的文档。
“totalKeysExamined” : 8449
如果使用了索引,那么这个数字就是查找过的索引条目数量。如果本次查询是一次全表扫描,那么这个数字就表示检查过的文档数量。
“stage” : “IXSCAN”
MongoDB 是否可以使用索引完成本次查询。如果不可以,那么会使用 “COLLSCAN” 表示必须执行集合扫描来完成查询。
“needYield” : 0
为了让写请求顺利进行,本次查询所让步(暂停)的次数。如果有写操作在等待执行,那么查询将定期释放它们的锁以允许写操作执行。在本次查询中,由于并没有写操作在等待,因此查询永远不会进行让步。
“executionTimeMillis” : 15
数据库执行本次查询所花费的毫秒数。这个数字越小越好。“executionTimeMillis” 报告了查询的执行速度,即从服务器接收请求到发出响应的时间。然而,这可能并不总是你希望看到的值。如果 MongoDB 尝试了多个查询计划,那么"executionTimeMillis" 反映的是所有查询计划花费的总运行时间,而不是所选的最优查询计划所花费的时间。
“indexBounds” : {…}
这描述了索引是如何被使用的,并给出了索引的遍历范围。
如果发现 MongoDB 正在使用的索引与自己希望的不一致,则可以用 hint 强制其使用特定的索引。
注:如果查询没有使用你希望其使用的索引,而你使用了 hint强制进行更改,那么应该在部署之前对这个查询执行 explain。如果强制 MongoDB 在它不知道如何使用索引的查询上使用索引,则可能会导致查询效率比不使用索引时还要低。
配置修改
忘记密码
mongodb忘记密码处理步骤