scrapy框架学习总结
目录
一、scrapy是什么?
二、scrapy工作原理
三、scrapy安装
四、scrapy的基本使用(爬虫项目创建->爬虫文件创建->运行 + 爬虫项目结构 + response的属性和方法)
五、Pipeline管道的封装
六、pipelines多条管道下载
七、scrapy多页下载
八、链接提取器CrawlSpider
九、数据入库
十、scrapy日志配置
十一、使用post请求爬取
双手奉上尚硅谷scrapy课程: https://www.bilibili.com/video/BV1Db4y1m7Ho/?p=90&spm_id_from=333.999.top_right_bar_window_history.content.click&vd_source=a3264716fe097cbd43e5dbc235c0e426
一、scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
*结构性数据:即同一类型的数据
如:某一网页上的同一类型的标签
二、scrapy工作原理
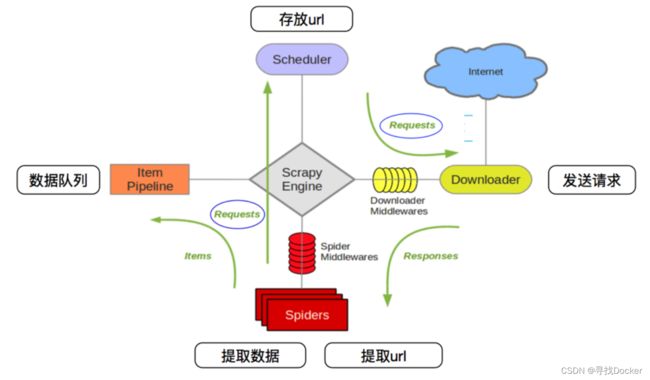
scrapy框架的执行过程:
1、引擎向spiders要url
2、引擎将要爬取的url给调度器
3、调度器会将url件成请求对象放入到指定的队列中
4、从队列中出队—个请求
5、引擎将请求交给下载器进行处理
6、下载器发送请求获取互联网数据
7、下载器将数据返回给引擎
8、引擎将数据再次给到spiders
9、spiders通过xpath解析该数据,得到数据或者url
10、spiders将数据或者url给到引擎
11、引擎判断是数据还是url, 是数据,交给管道(item pipeline )处理进行存储, 是url交给调度器处理

三、scrapy安装
pip install scrapy出错提示to update pip,请升级pip
python -m pip install --upgrade pip
四、scrapy的基本使用(爬虫项目创建->爬虫文件创建->运行 + 爬虫项目结构 + response的属性和方法)
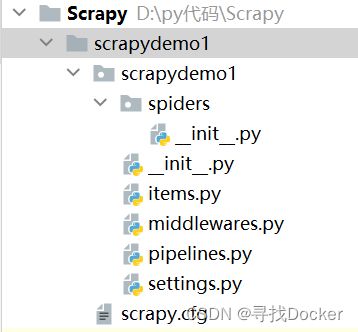
(1) scrapy项目的创建与运行
pycharm命令行终端中:
scrapy startproject 项目名执行后出现:
(2) 创建爬虫文件
要在spiders文件夹中去创建爬虫文件,pycharm命令行终端:
cd 路径\spiders创建爬虫文件:
scrapy genspider 爬虫文件名 要爬取的网页如:

spiders文件夹下会生成对应的爬虫文件。
生成的爬虫文件内容详解:
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫时使用
name = 'baidu'
#允许访问的域名
allowed_domains = ['www.baidu.com']
#起始的url地址 第一次访问的域名
start_urls = ['http://www.baidu.com/']
#该方法中response相当于response = request.get()
def parse(self, response):
pass(3) scrapy项目的结构

(4) 运行爬虫文件
scrapy crawl 爬虫文件名如:scrapy crawl baidu
注释:在settings.py文件中,注释掉ROBOTSTXT_OBEY = True,才能爬取拥有反爬协议的网页
(5) response的属性和方法(爬虫的处理主要是对response进行操作,从这里开始主要对生成的爬虫文件进行操作)
#该方法中response相当于response = request.get()
response.text () 用于获取响应的内容
response.body () 用于获取响应的二进制数据
response.xpath() 可以直接使用xpath方法来解析response中的内容
response.xpath().extract() 提取全部seletor对象的data属性值,返回字符串列表
response.xpath().extract_first() 提取seletor列表的第一个数据,返回字符串
(6) 实战案例
58同城案例:
import scrapy
#58同城案例
class TcSpider(scrapy.Spider):
name = 'tc'
allowed_domains = ['sq.58.com']
start_urls = ['https://sq.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
def parse(self, response):
#print("58同城爬取成功!")
#字符串数据,response.text用于获取响应的内容
content = response.text
print(content)
#二进制数据
content = response.body
print(content)
print(response)
#xpath解析,
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
#提取标签的data属性值
print(span.extract)汽车之家案例:
import scrapy
#汽车之家案例
class CarhomeSpider(scrapy.Spider):
name = 'carhome'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['http://car.autohome.com.cn/pic/brand-15.html']
def parse(self, response):
print("汽车之家爬取成功!")
car_list = response.xpath('//div[@class="uibox-con carpic-list02"]/ul/li/div/span/a/text()')
img_list = response.xpath('//div[@class="uibox-con carpic-list02"]/ul/li/a/img/@src')
for i in range(len(car_list)):
print(car_list[i].extract())
print(img_list[i].extract())xpath表达式 '//div[@id="filter"]/div[@class="tabs"]/a/span'对应58同城页面:

注,xpath详解
五、Pipeline管道的封装
爬虫文件、items文件、pipelines文件三者关系:
1.首先,spider 爬取了数据,过滤后 写入到items中
(item是scrapy中,连结spider和pipeline的桥梁,即items是 定义数据结构)
2.其次,再通过yield返回爬取数据给核心引擎并 交付给pipeline
3.最后,pipeline通过 调用items获取数据,再 写入指定文件或通过数据库连接存入数据库
(1) 爬虫文件(爬取数据)
#当当网案例
class DangdangSpider(scrapy.Spider):
name = 'dangdang'
allowed_domains = ['http://category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
# piplines 保存数据
# items 定义数据结构
print("当当网爬取成功!")
#xpath
title = response.xpath('//a[@class="pic"]/@title')
img = response.xpath('//img//@data-original')
price = response.xpath('//p[@class="price"]/span[1]/text()')
for i in range(len(title)):
#print(title[i].extract(),img[i].extract(),price[i].extract())
book = Scrapydemo4Item(img=img[i].extract(),title=title[i].extract(),price=price[i].extract())
# 在这里,yield可以实现获取一个book就将book交给pipelines即管道
yield book
(2) items文件(定义数据结构)
import scrapy
# 通俗的说就是你要爬取的数据都是什么样的
class Scrapydemo4Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#图片
img = scrapy.Field()
#名字
title = scrapy.Field()
#价格
price = scrapy.Field()
(3) Pipelines文件(保存数据)
开启管道,需要在setting文件中,去除pipelines的注释
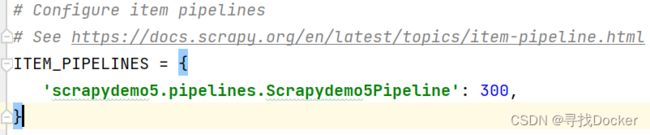
(item_pipelines为管道优先级)
from itemadapter import ItemAdapter
# 如果想使用管道,就必须在setting里开启
class Scrapydemo4Pipeline:
# 在爬虫执行完之前,执行的方法
def open_spider(self,spider):
self.fp = open('book.json','a',encoding='utf-8')
# items就是yield后面的book对象
def process_item(self, item, spider):
#单个w会覆写,使用a,
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.write(str(item))
return item
# 在爬虫执行完之后,执行的方法
def close_spider(self,spider):
self.fp.close()注:注意,在Pipelines文件中,我们对方法是进行重写,上面三个方法名和形参名不能更改
六、pipelines多条管道下载
(1) 定义管道类
在pipelines文件中:
#多条管道开启
#(1)定义管道类
#(2)在setting中添加优先级
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('img')
filename = './books/' + item.get('title') + '.jpg'
urllib.request.urlretrieve(url = url,filename = filename)(2) 在setting中添加优先级
在settings文件中item_pipelines下添加一条:

七、scrapy多页下载
多页下载分两种情况:一是多个页面爬取的业务逻辑基本一致,只需重复调用同一个parse方法即可;二是多个页面的爬取的业务逻辑不一致,这时需要定义多个不同的“parse”方法进行下载,如parse_first(self, response),parse_second(self, response),注意,这里使用meta,可以实现多个不同方法爬取数据汇集一处,最后写入item。
这里使用scrapy.Request(url=url,callback=self.parse)进行页面请求,也就是在更换页面爬取时使用,url就是请求地址,callback就是要调用的函数。
情况一(多个页面爬取的业务逻辑基本一致)(更便捷的方式使用CrawlSpider)
import scrapy
from scrapydemo4.items import Scrapydemo4Item
#当当网案例
class DangdangSpider(scrapy.Spider):
name = 'dangdang'
#多页时必须调整allowed_domains的范围
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_urls = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# piplines 下载数据
# items 定义数据结构
print("当当网爬取成功!")
#xpath
li_list = response.xpath('//ul[@id="component_59"]//li')
for li in li_list:
title = li.xpath('.//a[@class="pic"]/@title').extract_first()
img = response.xpath('.//a[@class="pic"]/img/@src').extract_first()
if img:
img = img
else:
img = response.xpath('.//a[@class="pic"]/img/@src').extract_first()
price = response.xpath('//p[@class="price"]/span[1]/text()').extract_first()
#print(title[i].extract(),img[i].extract(),price[i].extract())
book = Scrapydemo4Item(img=img,title=title,price=price)
# 在这里,yield可以实现获取一个book就将book交给pipelines即管道
yield book
#多页爬取
#每一页的爬取的业务逻辑都是一样的,所以我们只需要将执行的那个页面的请求再次调用parse方法即可
# http://category.dangdang.com/cp02.01.02.00.00.00.html
if self.page < 100:
self.page = self.page + 1
url = self.base_urls + str(self.page) + '-cp01.01.02.00.00.00.html'
print(url)
#怎么调用parse方法?
#scrapy.Request就是scrapy的get请求
#url就是请求地址,callback就是要调用的函数
yield scrapy.Request(url=url,callback=self.parse)情况二(多个页面爬取的业务逻辑不一致)
import scrapy
from scrapydemo5.items import Scrapydemo5Item
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.ygdy8.net']
start_urls = ['https://www.ygdy8.net/html/gndy/china/index.html']
def parse_first(self, response):
print("电影天堂爬取成功!")
#xpath
a_list = response.xpath('//table[@class="tbspan"]')
for i in a_list:
name = i.xpath('.//td[2]//a[2]/text()').extract_first()
href = i.xpath('.//td[2]//a[2]/@href').extract_first()
#print(name,href)
#跳转
url = "https://www.ygdy8.net" + href
#对第二页链接发起访问
#这里使用meta,可以实现多个爬取数据汇集一处,最后写入item
yield scrapy.Request(url=url,callback=self.parser_second,meta={'name':name})
def parser_second(self,response):
src = response.xpath('//div[@class="co_content8"]//img/@src').extract_first()
name = response.meta['name']
#item
moive =Scrapydemo5Item(name=name,src=src)
#piplines
yield moive八、链接提取器CrawlSpider
scrapy 框架中分两类爬虫:Spider 类和CrawlSpider 类。在 CrawlSpider 中,我们可以利用正则表达式或者正则方法 指定一些爬取规则来实现页面的请求,这些规则放在一个特定的数据结构 Rule 中表示。 可以用来爬取同一个网站爬取业务逻辑基本一致的网页。
参数介绍:
allow = () #正则表达式提取符合正则的链接
restrict_xpaths = () # 提取符合xpath规则的链接
restrict_css = () #提取符合选择器规则的链接)
(1) 创建爬虫文件
scrapy genspider -t crawl 爬虫文件名 爬取的域名
(2) 编辑rules
rules = (
Rule(LinkExtractor(allow=r'正则表达式'), callback='parse_item', follow=False),
)
follow为True时,连省略的页面链接也能获取
注:获取请求链接,正则内容一般是页面链接,如
(3) 实战案例
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapydemo6.items import Scrapydemo6Item
#读书网案例
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188.html']
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\d+\.html'), callback='parse_item', follow=False),
)
def parse_item(self, response):
#xpath
img_list = response.xpath('//ul/li/div[@class="book-info"]/div/a')
for i in img_list:
src = i.xpath('./img/@data-original').extract_first()
name = i.xpath('./img/@alt').extract_first()
#item
books = Scrapydemo6Item(src=src,name=name)
yield books九、数据入库
(1) 安装pymysql
pip install pymysql -i https://pypi.douban.com/simple
(2) 在settings文件中添加数据库配置
DB_HOST = '127.0.0.1'
#端口号
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '123456'
#database名
DB_NAME = 'spider01'
DB_CHARSET = 'utf8'
(3)创建数据库和表
create database spider01 charset=utf8;
use spider01;
create table book(
id int primary key auto_increament,
name varchar(128),
src varchar(128);
)
(4)数据库相关方法
pymysql.connect(host,post,user,password,db,charset) 连接数据库,创建连接对象
connect对象.cursor() 创建一个游标
cursor对象.execute() 执行sql语句
connect对象.commit() 提交sql语句
connect对象.close() 关闭连接
(5)实战案例
pipelines文件:
from itemadapter import ItemAdapter
class Scrapydemo6Pipeline:
#重写
#开始
def open_spider(self,spider):
self.fp = open("./books.json","w",encoding="utf-8")
#写入
def process_item(self, item, spider):
self.fp.write(str(item))
return item
#结束
def close_spider(self,spider):
self.fp.close()
#加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql
#数据库
class MysqlPipeline:
# 开始
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
#游标
self.cursor = self.conn.cursor()
# 写入
def process_item(self, item, spider):
#sql
sql = 'insert into book(name,src) values ("{}","{}")'.format(item['name'],item['src'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
# 结束
def close_spider(self, spider):
# 关闭
self.cursor.close()
self.conn.close()十、scrapy日志配置
(1)日志级别
CRITICAL:严重错误
ERROR:一般错误
WARNING:警告
INFO:一般信息
DEBUG:调试信息
默认的日志等级是DEBUG
(2) settings.py文件设置
在settings.py文件中
LOG_FILE = XX.log 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL = 日志级别 设置日志显示的等级,就是显示哪些,不显示哪些
十一、使用post请求爬取
之前的所有爬取不上传数据,使用post方式进行爬取
(1)实战案例
在爬虫文件中:
import json
import scrapy
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['fanyi.baidu.com']
#start_urls = ['http://fanyi.baidu.com/langdetect']
# post请求必须使用start_requests方法进行请求
def start_requests(self):
url = 'http://fanyi.baidu.com/sug/'
#上传数据
data = {
"kw" : "domain"
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
#爬取
def parse_second(self,response):
content = response.text
# html语句转字符串
obj = json.loads(content,encoding='utf-8')
print(obj)