Boosting算法预测银行客户流失率
Boosting算法预测银行客户流失率
描述
为了防止银行的客户流失,通过数据分析,识别并可视化哪些因素导致了客户流失,并通过建立一个预测模型,识别客户是否会流失,流失的概率有多大。以便银行的客户服务部门更加有针对性的去挽留这些流失的客户。
本任务的实践内容包括:
1、学习并熟悉Boosting算法原理。
2、使用AdaBoost、梯度提升算法、XGBoost算法创建模型,并且训练评估模型性能。
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
scikit-learn 1.0.2 numpy 1.19.3 pandas 1.3.5
分析
本任务涉及以下环节:
A)熟悉Boosting算法原理
B)加载并观察银行客户
C)创建AdaBoost模型,进行训练,评估其准确率和F1分数
D)创建梯度提升模型,进行训练,评估其准确率和F1分数
E)创建XGBoost模型,进行训练,评估其准确率和F1分数
实施
1、Boosting算法原理
Boosting集成分类器包含多个非常简单的成员分类器,这些成员分类器的性能仅好于随机猜想,常被称为弱学习机。典型的弱学习机的例子就是单层决策树。Boosting算法主要针对难以区分的样本,弱学习机通过在分类错误的样本上进行学习来提高继承分类器的分类性能。Boosting与Bagging不同,在Boosting的初始化阶段采用的是无返回抽样从训练样本中随机抽取一个子集,而Bagging采用的是有放回的抽取。Boosting的过程由四个步骤组成:
1、从训练集D中以无放回抽样方式随机抽取一个训练子集d1,用于弱学习机C1的训练
2、从训练集D中以无放回抽样方式随机抽取一个训练子集d2,并将C1中误分类样本的50%加入到训练集中,训练得到弱学习机C2
3、从训练集D中抽取C1和C2分类结果不一致的训练样本生成训练样本集d3,用d3来训练第三个弱学习机C3
4、通过多数投票来组合弱学习机C1、C2和C3。
Boosting与Bagging模型相比,Boosting可以同时降低偏差也方差,Bagging只能降低模型的方差。在实际应用中Boosting算法也还是存在明显的高方差问题,也就是过拟合。
1.1 AdaBoost算法
对于Boosting对应的两个问题,AdaBoost的策略为:
-
开始时分配同样权值,根据分类误差,提升弱分类器中分类错误的样本权值(对错误的更敏感),降低正确分类样本的权值。
-
采用加权表决法组合成强分类器,分类错误率小的分类器有更大的权值。
注:用到两种权值,一个是对样本的,一个是对分类器的。对样本的权值分类错的更大,对弱分类器的权值分类越好(错误率越小)的权值越大。
1.2 梯度提升(GBDT)算法
GBDT(梯度提升树)是以决策树(CART)为基学习器的Boosting类型的集成学习方法,与提升树在残差计算方面有所不同,提升树使用真正的残差,梯度提升树使用模型的负梯度拟合残差。
1.3 XGBoost算法
XGBoost是改进的梯度提升(GB)算法,XGBoost是GB算法的高效实现,XGBoost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。
2、加载分析银行客户数据集
import numpy as np # 基础线性代数扩展包
import pandas as pd # 数据处理工具箱
df_bank = pd.read_csv("../dataset/BankCustomer.csv") # 读取文件
df_bank.head() # 显示文件前5行
结果如下:
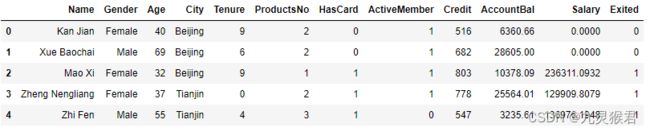
数据集特征说明:
-
name:客户姓名
-
Gender:客户性别
-
Age:客户年龄
-
City:城市
-
Tenure:用户时长
-
ProductsNo:使用产品数量
-
HasCard:是否拥有信用卡
-
ActiveMember:是否为活跃会员
-
Credit:信用评分
-
AccountBal:账户余额
-
Salary:薪资
-
Exited(标签):是否流失,1代表流失,0代表没有流失
3、数据处理
将二元数据文本化,创建数据集。
# 把二元类别文本数字化
df_bank['Gender'].replace("Female",0,inplace = True)
df_bank['Gender'].replace("Male",1,inplace=True)
# 显示数字类别
print("Gender unique values",df_bank['Gender'].unique())
# 把多元类别转换成多个二元哑变量,然后贴回原始数据集
d_city = pd.get_dummies(df_bank['City'], prefix = "City")
df_bank = [df_bank, d_city]
df_bank = pd.concat(df_bank, axis = 1)
# 构建特征和标签集合
y = df_bank['Exited']
X = df_bank.drop(['Name', 'Exited', 'City'], axis=1)
X.head() #显示新的特征集
结果如下:

4、拆分数据集
使用sklearn.model_selection.train_test_split()方法将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_split # 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
5、使用AdaBoost算法预测银行客户流失率
创建AdaBoost模型,对模型进行训练和预测,得出模型的准确率和F1分数。
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.model_selection import GridSearchCV # 导入网格搜索工具
from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost模型
from sklearn.metrics import (f1_score, confusion_matrix) # 导入评估标准
dt = DecisionTreeClassifier() # 选择决策树分类器作为AdaBoost的基准算法
ada = AdaBoostClassifier(dt) # AdaBoost模型
# 使用网格搜索优化参数
ada_param_grid = {"base_estimator__criterion" : ["gini", "entropy"],
"base_estimator__splitter" : ["best", "random"],
"base_estimator__random_state" : [7,9,10,12,15],
"algorithm" : ["SAMME","SAMME.R"],
"n_estimators" :[1,2,5,10],
"learning_rate": [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3,1.5]}
ada_gs = GridSearchCV(ada,param_grid = ada_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
ada_gs.fit(X_train,y_train) # 拟合模型
ada_gs = ada_gs.best_estimator_ # 最佳模型
y_pred = ada_gs.predict(X_test) # 进行预测
print("Adaboost测试准确率: {:.2f}%".format(ada_gs.score(X_test, y_test)*100))
print("Adaboost测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
结果如下:
Adaboost测试准确率: 79.00%
Adaboost测试F1分数: 51.16%
6、使用梯度提升算法预测银行客户流失率
创建梯度提升算法模型,对模型进行训练和预测,得出模型的准确率和F1分数。
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升分类器
gb = GradientBoostingClassifier() # 梯度提升分类器
# 使用网格搜索优化参数
gb_param_grid = {'loss' : ["deviance"],
'n_estimators' : [100,200,300],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [4, 8],
'min_samples_leaf': [100,150],
'max_features': [0.3, 0.1]}
gb_gs = GridSearchCV(gb,param_grid = gb_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
gb_gs.fit(X_train,y_train) # 拟合模型
gb_gs = gb_gs.best_estimator_ # 最佳模型
y_pred = gb_gs.predict(X_test) # 进行预测
print("梯度提升测试准确率: {:.2f}%".format(gb_gs.score(X_test, y_test)*100))
print("梯度提升测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
结果如下:
梯度提升测试准确率: 86.45%
梯度提升测试F1分数: 61.12%
输出结果显示,梯度提升算法的效果果然很好,F1分数达到61%以上。
7、使用XGBoost算法预测银行客户流失率
创建XGBoost算法模型,对模型进行训练和预测,得出模型的准确率和F1分数。
from xgboost import XGBClassifier # 导入XGB分类器
xgb = XGBClassifier() # XGB分类器
# 使用网格搜索优化参数
xgb_param_grid = {'min_child_weight': [1, 5, 10],
'gamma': [0.5, 1, 1.5, 2, 5],
'subsample': [0.6, 0.8, 1.0],
'colsample_bytree': [0.6, 0.8, 1.0],
'max_depth': [3, 4, 5]}
xgb_gs = GridSearchCV(xgb,param_grid = xgb_param_grid,
scoring="f1", n_jobs= 10, verbose = 1)
xgb_gs.fit(X_train,y_train) # 拟合模型
xgb_gs = xgb_gs.best_estimator_ # 最佳模型
y_pred = xgb_gs.predict(X_test) # 进行预测
print("XGB测试准确率: {:.2f}%".format(xgb_gs.score(X_test, y_test)*100))
print("XGB测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
结果如下:
XGB测试准确率: 86.25%
XGB测试F1分数: 60.09%
实验发现,XGBoost算法效果也不错。