Focal Loss损失函数
Focal Loss损失函数
损失函数
损失:在机器学习模型训练中,对于每一个样本的预测值与真实值的差称为损失。
损失函数:用来计算损失的函数就是损失函数,是一个非负实值函数,通常用L(Y, f(x))来表示。
作用:衡量一个模型推理预测的好坏(通过预测值与真实值的差距程度),一般来说,差距越小,损失越小,模型在相应数据集上效果越好。
使用:损失函数主要是在模型训练阶段,在每一个batch的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值与真实值的差异值,即损失值。得到损失值后,模型通过反向传播去更新模型参数,来降低真实值与预测值之间的损失(距离),使得模型生成的预测值向真实值靠拢,从而达到学习的目的。
在训练完该模型后,此时模型通过n次反向传播后,使得模型每个参数达到最优,即该模型预测得到的结果最接近真实结果。
常见损失函数
- 1、分类损失函数:
0-1 loss、熵与交叉熵loss、softmax loss及其变种、KL散度、Hinge loss、Exponential loss、Logistic loss、Focal Loss - 2、回归损失函数:
L1 loss、L2 loss、perceptual loss、生成对抗网络损失、GAN的基本损失、-log D trick、Wasserstein GAN、LS-GAN、Loss-sensitive-GAN
Focal Loss损失函数简介
解决问题:解决one-stage目标检测中的正负样本数量极其不平衡的问题。
正负样本不平衡:为了提高召回率,在一张图像中能够匹配到目标的候选框(正样本)个数一般只有十几个或者几十个,而没有匹配到的候选框(负样本)则有1000-100000个,很直观的想法是“宁肯错杀一千,绝不放过一个”,因此在目标检测中,模型往往会提出远高于实际数量的区域提议(Region Proposal,SSD等one-stage的Anchor也可以看作一种区域提议),这么多的负样本不仅对训练网络起不到什么作用,反而会淹没掉少量但有助于训练的样本。
根据Focal Loss论文的统计,通常包含少量信息的“easy examples”(通常是负例),与包含有用信息的“hard examples”(正例+难负例)之比为100000:100!这导致这些简单例的损失函数值将是难例损失函数的40倍!

二阶段目标检测:一般不需要解决样本不平衡问题,因为在二阶段目标检测中分了两步,第一步同样会生成许多负样本以及很少的正样本,但到第二步时,会在第一步的基础上选取特定数量的正负样本去检测,所以正负样本一般不会特别不平衡。
Focal Loss基本理论
Focal loss是基于二分类交叉熵CE(Cross Entropy)的。它是一个动态缩放的交叉熵损失,通过一个动态缩放因子,可以动态降低训练过程中易区分样本的权重,从而将重心快速聚焦在那些难区分的样本(有可能是正样本,也有可能是负样本,但都是对训练网络有帮助的样本)。
Cross Entropy Loss:基于二分类的交叉熵损失,它的形式如下
C E ( p , y ) = { − log ( p ) if y = 1 − log ( 1 − p ) otherwise \mathrm{CE}(p, y)= \begin{cases}-\log (p) & \text { if } y=1 \\ -\log (1-p) & \text { otherwise }\end{cases} CE(p,y)={−log(p)−log(1−p) if y=1 otherwise
上式中,y 的取值为1和-1,分别代表前景和背景。p 的取值范围为0~1,是模型预测属于前景的概率。接下来定义一个关于P的函数:
p t = { p if y = 1 1 − p otherwise p_{\mathrm{t}}= \begin{cases}p & \text { if } y=1 \\ 1-p & \text { otherwise }\end{cases} pt={p1−p if y=1 otherwise
结合上式,可得到简化公式:
C E ( p , y ) = C E ( p t ) = − log ( p t ) C E(p, y)=C E(p t)=-\log (p t) CE(p,y)=CE(pt)=−log(pt)
Balanced Cross Entropy:常见的解决类不平衡方法。引入了一个权重因子α ∈ [ 0 , 1 ] ,当为正样本时,权重因子就是α,当为负样本时,权重因子为1-α。所以,损失函数也可以改写为
CE ( p t ) = − α t log ( p t ) \operatorname{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right) CE(pt)=−αtlog(pt)
这里给出一张图,可以看出当权重因子为0.75时,效果最好。
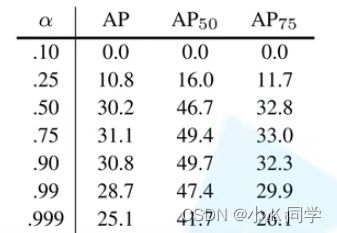
Focal Loss:虽然BCE解决了正负样本不平衡问题,但并没有区分简单还是难分样本。当易区分负样本超级多时,整个训练过程将会围绕着易区分负样本进行,进而淹没正样本,造成大损失。所以这里引入了一个调制因子 ,用来聚焦难分样本,公式如下
FL ( p t ) = − ( 1 − p t ) γ log ( p t ) \operatorname{FL}\left(p_t\right)=-\left(1-p_t\right)^\gamma \log \left(p_t\right) FL(pt)=−(1−pt)γlog(pt)
γ为一个参数,范围在 [0,5], 当 γ为0时,就变为了最开始的CE损失函数。
( 1 − p t ) γ \left(1-p_t\right)^\gamma (1−pt)γ 可以降低易分样本的损失贡献,从而增加难分样本的损失比例,解释如下:当 p t p_t pt 趋向于1,即说明该样本是易区分样本,此时调制因子 ( 1 − p t ) γ \left(1-p_t\right)^\gamma (1−pt)γ 是趋向于0,说明对损失的贡献较小,即减低了易区分样本的损失比例。当 p t p_t pt 很小,也就是假如某个样本被分到正样本,但是该样本为前景的概率特别小,即被错分到正样本了,此时调制因子 ( 1 − p t ) γ \left(1-p_t\right)^\gamma (1−pt)γ 是趋向于1,对loss也没有太大的影响。
对于 γ \gamma γ 的不同取值,得到的loss效果如图所示

可以看出,当 p t p_t pt 越大,即易区分的样本分配的非常好,其所对于的loss就越小。
通过以上针对正负样本以及难易样本平衡,可以得到应该最终的Focal loss形式:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) F L\left(p_t\right)=-\alpha_t\left(1-p_t\right)^\gamma \log \left(p_t\right) FL(pt)=−αt(1−pt)γlog(pt)
即通过 α t \alpha_t αt 可以抑制正负样本的数量失衡,通过 γ \gamma γ 可以控制简单/难区分样本数量失衡。
总结
- 1、调制因子 ( 1 − p t ) γ \left(1-p_t\right)^\gamma (1−pt)γ 是用来降低易分样本的损失贡献(比重),无论是前景类还是背景类, p t p_t pt 越大,就说明该样本越容易被区分,调制因子也就越小。
- 2、 α t \alpha_t αt 用于调节正负样本损失之间的比例,前景类别使用 αt 时,对应的背景类别使用 1 − α t 1-\alpha_t 1−αt 。
- 3、 γ \gamma γ 和 α t \alpha_t αt 都有相应的取值范围,他们的取值相互间也是有影响的,在实际使用过程中应组合使用。
参考:
https://www.zhihu.com/question/46292829
https://blog.csdn.net/chenaxin/article/details/109218772
https://blog.csdn.net/BIgHAo1/article/details/121783011