NLP实验记录——事件编码表征方法探索
NLP实验记录——事件编码表征方法探索
- 1. 原有方案简介
- 2. 参考方案
- 3. 实验部分
-
- 3.1 基本结构
- 3.2 样本构建
- 3.3 模型选择
1. 原有方案简介
前段时间在做事件共指相关的工作,做了一部分实验简单的记录一下。本篇算是一个实验记录,没有确定性的结论,也不会放出完整的代码和模型,把它写下来只是为了给从事相关工作和研究的朋友们提供一点参考和思路。
事件共指,也就是判断几个事件是否指向同一个实际发生的真实事件。在我们所接触到的任务场景中,事件共指任务包括两种:
一是同一篇新闻上下文中所涉及到的事件的不同表述之间的共指,例如,前文中提到“土耳其发生7.8级地震”中的“地震”,与后文中所提到“此次地震造成了大量损失”中的“此次地震”,所指向的是同一事件;
二是在不同的新闻中,都报道了同一件事,例如两篇新闻都是针对土耳其地震的报道。
在我们原有的方案中,针对这两种任务场景有不同的处理方法。对于前者,实际上与实体共指任务(Entity Coreference)没有本质差别,所以直接采用实体共指的方案(mention表征+特征融合+判别分类)进行解决即可。对于后者,通过对事件触发词mention表征+上下文表征+论元相似度计算组合的方式进行综合打分。
在处理不同篇章的事件共指时,遇到一些问题导致最终的效果不太理想,可以大致归纳如下:
-
- 触发词mention的表征是通过篇章内指代消解任务的模型得出的,这里做应用场景的迁移,不能算是有监督的训练,所以只是起到一个参考价值;
-
- 上下文表征,即令[MASK]替换到触发词位置,再用预训练模型对替换后的原句进行编码,取[MASK]位置的切片作为上下文的表征结果,这一部分相当于利用了预训练模型在预训练中学习到的表征能力,也是无监督的。
-
- 论元的表征,这一步是做了实体链接的,如果实体id能够匹配,自然是好的,可以百分百确定两个实体是同一个,则此论元的相似度为1,但如果id不匹配,例如两个事件的地点论元分别是乌克兰和基辅,那么则需要引入实体的表征进行相似度计算,而这一步分的实体表征,一方面与触发词表征类似,是从另一个任务(实体识别)迁移过来的,另一方面与上下文表征存在一定的重合。
这样看来,这一方案的设计有诸多不合理的方面,尽管我们可以通过不停地加策略和设置各类超参数进行纠正,但是不可否认这不是一个完备的方案。
所以我设想采用一种类似端到端的方法,专门针对事件表征这一任务进行一些数据的构造以及训练,通过直接对事件所在句子进行编码,获取事件的编码。
2. 参考方案
其实对事件进行编码表示的方法,早就有很多人实践并应用到生产中去了,尤其是对于内容检索和推荐的场景,向量化表示是非常必要的。例如鹅厂某组,早在21年的时候做过的一次直播技术分享中,采用的就是这一技术方案(当时是对比学习大热的时期),但是作为小单位的小研究员,我们的人员和技术积累都十分有限,很多事情只能是从头开始一点点探索。
前段时间看到22年的一篇论文:Pairwise Representation Learning for Event Coreference,思来想去还是打算实验一下事件表征的想法。
首先简单介绍一下这篇论文所采用的思路:
简单来说,就是一个单塔的交互式模型,
将两个句子进行拼接后,一起经历预训练模型的编码,然后取触发词对应位置的token的表征,两个触发词位置分别进行sum pooling,再将得到的两个形状为[hidden_size]的表征进行element-wise的乘法,得到另一个[hidden_size]的表征,最后将这三者进行concat,得到的[3*hidden_size]的向量,就是触发词pair的表征。
类似的,可以计算每个论元pair对应的表征。对于事件i中存在,但是事件j中缺失的论元,缺少的 v j , r o l e v_{j, role} vj,role用全0向量补齐。
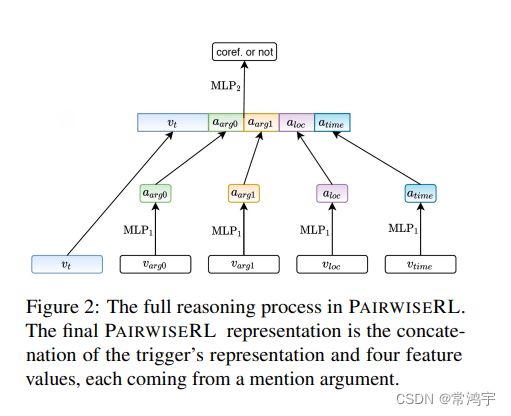
最后将所有触发词pair和论元pair的表征进行拼接,然后再判别分类,以是否为共指作为label进行有监督训练,这样一来经过训练之后的编码模型(也就是图一中的roberta),就是最终得到的事件表征模型。
这样做的好处在于,强行让对应位置的论元进行对比,例如,时间与时间进行对比,地点与地点进行对比。
但是这种单塔的模型,要想以句子对作为输入,在训练时期是可行的,但是在推理的时候,由于单塔模型的固有缺陷,需要将待共指的句子与全库进行拼接,全部实时编码,这样的计算量通常是不被接受的。
而如果以单句作为输入,直接利用训练好的模型对包含事件的句子进行编码,那又会造成训练与推理任务的不一致。
所以基于这种考虑,我没有采用这篇论文的思路,而是跟随自己的感觉,设计了双塔模型。
3. 实验部分
3.1 基本结构
我采用的方法很简单,首先为了方便后期的向量化检索,采用了双塔模型,不对两个输入句子(事件)进行拼接,而是各自编码。
然后,在包含事件的句子中添加了特殊标记,例如等,把论元位置和触发词位置包裹起来,这样一来,原本的句子就变成了类似于:
,某某地点 发生了7.8级 的地震 。
这样一来,增加的特殊标记,可以对其包裹的论元内容进行表征,也相当于赋予了论元token一定的角色身份信息。
注意这里要把特殊标记添加到tokenizer里去,也就是说,每个特殊标记只占一个token。
# 实例化tokenizer,以span_bert为例
tokenizer = AutoTokenizer.from_pretrained('span_bert')
# 所有的特殊标记
special_tokens = [word.lower() for word in [
'' ,
'',
...,]
tokenizer.add_tokens(special_tokens)
并且相应的,要对模型的embedding层进行reshape,因为词表的大小发生了改变:
# 实例化模型
model = AutoModel.from_pretrained('span_bert')
# 改变形状
model.resize_token_embeddings(len(tokenizer))
然后对于训练任务的设置,有两个选择,其一把两个获取到的编码向量拼接,然后过一个分类器,判断是共指还是不共指,作为一个二分类任务;其二是当成回归任务来做,两个编码直接计算余弦相似度,正样本label是1,负样本label是0,直接用MSE损失。
这里选择了后者进行实验。
模型结构十分简单:
class TrainModel(torch.nn.Module):
def __init__(self, encoder, device='cpu'):
super(TrainModel, self).__init__()
self.encoder = encoder
self.classifier = torch.nn.Linear(768, 2)
self.loss_fct = MSELoss()
self.device = device
self.encoder.to(self.device)
def forward(self, inputs_1, inputs_2, label):
label = label.to(self.device)
emb_1 = self.encoder(input_ids=inputs_1['input_ids'].to(self.device),
token_type_ids=inputs_1['token_type_ids'].to(self.device),
attention_mask=inputs_1['attention_mask'].to(self.device))['pooler_output']
emb_2 = self.encoder(input_ids=inputs_2['input_ids'].to(self.device),
token_type_ids=inputs_2['token_type_ids'].to(self.device),
attention_mask=inputs_2['attention_mask'].to(self.device))['pooler_output']
sim = pytorch_cos_sim(emb_1, emb_2).squeeze()
loss = self.loss_fct(sim, label)
return loss
Dataset也比较简单,其中pos_pairs和neg_pairs中涉及到我自己写的一个非开源包里的数据格式,所以就不完整展示了,仅贴出框架供参考。
class TrainSet(Dataset):
def __init__(self, pos_pairs, neg_pairs, tokenizer):
self.pos_pairs = pos_pairs
self.neg_pairs = neg_pairs
self.tokenizer = tokenizer
self.examples = []
self.make_examples()
random.shuffle(self.examples)
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
return self.examples[idx]
def make_examples(self):
for pos_pair in self.pos_pairs:
inputs_1 = tokenizer(pos_pair[0].wrapped_text, return_tensors='pt', max_length=512, truncation=True)
inputs_2 = tokenizer(pos_pair[1].wrapped_text, return_tensors='pt', max_length=512, truncation=True)
label = torch.tensor(1.)
self.examples.append((inputs_1, inputs_2, label))
for neg_pair in self.neg_pairs:
inputs_1 = tokenizer(neg_pair[0].wrapped_text, return_tensors='pt', max_length=512, truncation=True)
inputs_2 = tokenizer(neg_pair[1].wrapped_text, return_tensors='pt', max_length=512, truncation=True)
label = torch.tensor(0.)
self.examples.append((inputs_1, inputs_2, label))
3.2 样本构建
比起模型结构,样本构建是更重要的部分。
正样本:
对于正样本,直接筛选了线上系统中按照原有方法提取出的,同一篇文章内的共指事件对。这样做主要是考虑到篇章内的共指事件对,准确性要高于跨篇章的共指事件对,避免在训练样本中,掺杂过多的假阳性。
此外,并不是所有的共指事件对,都可以用作正样本,只有论元要素相对齐全,且指示明确的,才可以用作训练样本。
例如,一个事件表述为,“某某强烈谴责了这一行动”,对于其中的“行动”这一事件,仅仅是对前文的指代,在这一表述中,其未包含任何事件论元,仅有一个触发词,那么句话对这个事件的表征一定是糟糕的,实际使用中,我们也不会用模型取生成这句话中“行动”这一事件的表征。
负样本:
负样本构建的质量会直接关系到最终的效果,在此我创建负样本采用了以下集中方法:
- 在同一篇文本中,随机选择不构成共指的、且论元信息相对充足样本对(判断不构成共指,用的是原有的事件共指模型)
- 在数据库中,检索时间跨度较大的、相同事件类型的事件,因为一般来讲,某个事件的报道会集中在一个时间段,所以时间相差很大时,两个事件大概率不构成共指。
- 论元替换。为了增强表征的结果对论元位置的敏感性,把事件的某些论元替换成另一个无关论元,例如,将土耳其替换成阿富汗,再将替换后的句子与原句构成负样本对。
此外还对样本对进行了部分人工检查。受限于精力和时间,最终只生成类1651对正样本和1655对负样本。
3.3 模型选择
在编码模型的选择上,首先想到了span bert,因为添加特殊token的方法跟span bert的预训练任务是很一致的,并且它本就是用于做片段共指的。
此外还尝试了sentence transformer的模型,值得注意的是,sentence transformer模型的基础编码器是roberta,需要在建模和预测的时候把token_type_id去掉。
从效果上讲,经过训练之后,span bert表征的准确性,尤其是在测试集上的表现,要远远优于sentence transformer的mpnet-v2,这倒是令我感到很意外。
但是受限于我的数据量和数据质量,最终训练出来的模型也没有达到特别好的效果,对于一些相似度0.4到0.6的事件对,很难通过得分来判断它们是否构成共指,判断的阈值很难划定,最终的结果只能是起到一个参考作用。
经过这个实验,事件编码的可信性基本上是得到了论证,但是距离直接使用,还有一点差距。或许,如果有大量的高质量数据的话,这个方法的效果会能够达到可以直接应用的级别。
以上便是本文的全部内容,希望这个实验能够给从事类似研究的你带来一定的启发。