《Java8实战》第5章 使用流
上一章已经体验到流让你从外部迭代转向内部迭代。
5.1 筛选
看如何选择流中的元素:用谓词筛选,筛选出各不相同的元素。
5.1.1 用谓词筛选
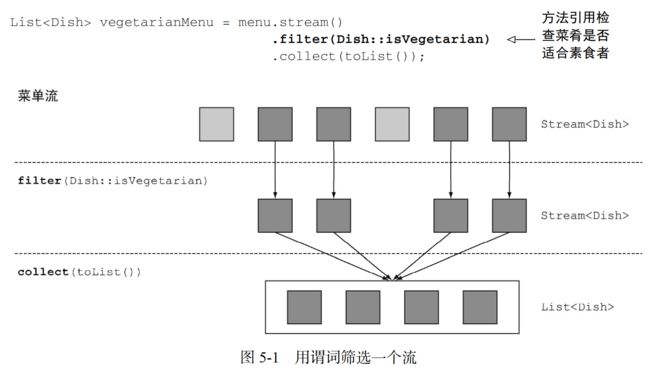
filter 方法,该操作会接受一个谓词(一个返回boolean 的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
List vegetarianMenu = menu.stream()
.filter(Dish::isVegetarian) // 方法引用检查菜肴是否适合素食者
.collect(toList());
5.1.2 筛选各异的元素
流还支持一个叫作 distinct 的方法,它会返回一个元素各异(根据流所生成元素的 hashCode和 equals 方法实现)的流。
以下代码会筛选出列表中所有的偶数,并确保没有重复.
List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct() // 去重
.forEach(System.out::println);

测验 5.1:筛选
你将如何利用流来筛选前两个荤菜呢?
答案:可以把 filter 和 limit 组合在一起来解决这个问题,并用 collect(toList())
将流转换成一个列表。
List dishes = menu.stream()
.filter(dish -> dish.getType() == Dish.Type.MEAT)
.limit(2) .collect(toList());
5.2 流的切片
5.2.1 使用谓词对流进行切片
Java 9 引入了两个新方法,可以高效地选择流中的元素,这两个方法分别是:takeWhile 和 dropWhile。
- 使用 takeWhile
举例来说,假设要在流中找到所有小于20的数字,可能会出现一下情况:在其顺序执行过程中,只能得到过滤条件触发之前输入的数字,后面的输入全部都会被舍弃。也就是说当第一次过滤条件被触发时,会忽略剩余的输入然后执行返回或退出命令。
public static void main(String[] args) {
List numberList= Arrays.asList(1,3,5,8,10,20,35,2,5,7);
numberList.stream().takeWhile(num->num<=20).forEach(System.out::println);
}
后面的35就不运行了
- 使用 dropWhile
Dropwhile方法:它与takewhile方法正相反。Dropwhile方法会丢弃过滤条件触发之前的所有输入,一旦过滤条件触发,就输出之后的所有数据。
5.2.2 截短流
流支持 limit(n)方法,该方法会返回另一个不超过给定长度的流。所需的长度作为参数传递给 limit。
选出热量超过 300 卡路里的头三道菜:
List dishes = specialMenu.stream()
.filter(dish -> dish.getCalories() > 300)
.limit(3).collect(toList())
图 5-3 展示了 filter 和 limit 的组合。你可以看到,该方法只选出了符合谓词的头三个元素,然后就立即返回了结果。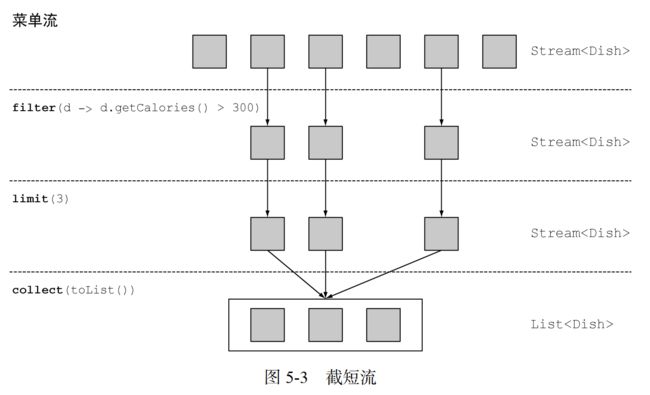
5.2.3 跳过元素
流还支持 skip(n)方法,返回一个扔掉了前 n 个元素的流。如果流中元素不足 n 个,则返回一个空流。
下面的代码将跳过热量超过 300卡路里的头两道菜,并返回剩下的
List dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.skip(2)
.collect(toList());

5.3 映射
一个非常常见的数据处理套路就是从某些对象中选择信息。
5.3.1 对流中每一个元素应用函数
流支持 map 方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”)。
下面的代码把方法引用 Dish::getName 传给了 map方法,来提取流中菜肴的名称:
List dishNames = menu.stream()
.map(Dish::getName)
.collect(toList());
因为 getName 方法返回一个 String,所以 map 方法输出的流的类型就是 Stream 。
例子:给定一个单词列表,你想要返回另一个列表,显示每个单词中有几个字母。怎么做呢?
给 map 传递一个方法引用 String::length 来解决这个问题:
List words = Arrays.asList("Modern", "Java", "In", "Action");
List wordLengths = words.stream()
.map(String::length)
.collect(toList());
如果你要找出每道菜的名称有多长,该怎么做?可以像下面这样,再链接上一个 map:
List dishNameLengths = menu.stream()
.map(Dish::getName)
.map(String::length)
.collect(toList());
5.3.2 流的扁平化
让我们拓展一下:对于一张单词表,如何返回一张列表,列出里面 各不相同的字符 呢?例如,给定单词列表[“Hello”,“World”],你想要返回列表[“H”,“e”,“l”, “o”,“W”,“r”,“d”]。
你可以把每个单词映射成一张字符表,然后调用 distinct 来过滤重复的字符。第一个版本可能是这样的:
words.stream()
.map(word -> word.split(""))
.distinct()
.collect(toList());
这个方法的问题在于,传递给map方法的Lambda为每个单词返回了一个String[](String列表)。因此,map 返回的流实际上是 Stream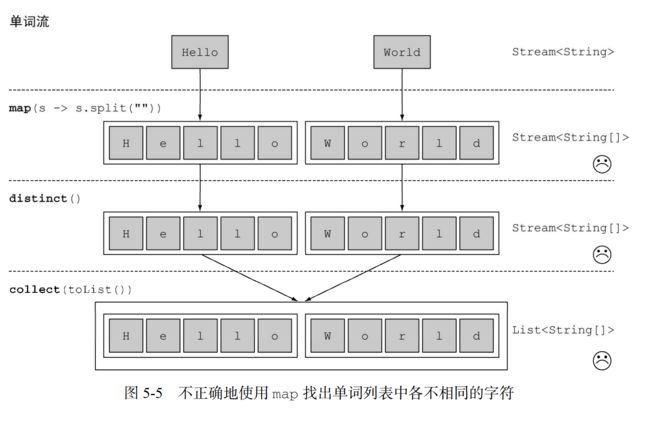
- 尝试使用 map 和 Arrays.stream()
首先,你需要一个字符流,而不是数组流。有一个叫作 Arrays.stream()的方法可以接受一个数组并产生一个流,例如:String[] arrayOfWords = {"Goodbye", "World"}; Stream
把它用在前面的那个流水线里,看看会发生什么:
words.stream()
.map(word -> word.split("")) // 将每个单词转换为由其字母构成的数组
.map(Arrays::stream) // 让每个数组变成一个单独的流
.distinct()
.collect(toList());
当前的解决方案仍然搞不定!这是因为,你现在得到的是一个流的列表(更准确地说是List
- 使用 flatMap
下面这样使用 flatMap 来解决这个问题:
List uniqueCharacters =
words.stream()
.map(word -> word.split("")) // 将每个单词转换为由其字母构成的数组
.flatMap(Arrays::stream) // 将各个生成流扁平化为单个流
.distinct()
.collect(toList());
使用 flatMap 方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。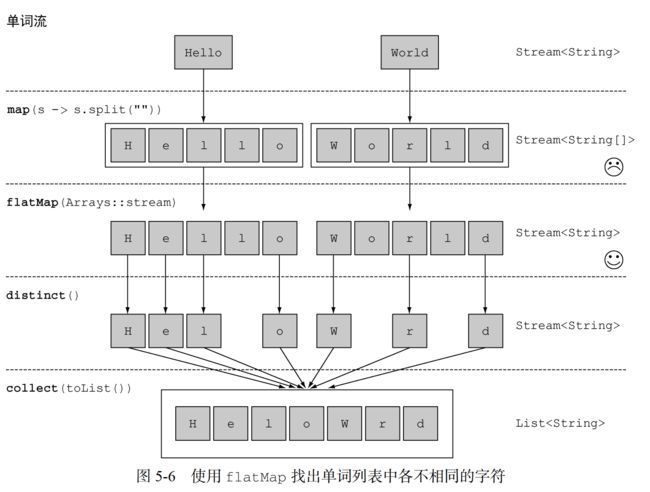
5.4 查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。Stream API通过 allMatch、anyMatch、noneMatch、findFirst 和 findAny 方法提供了这样的工具。
5.4.1 检查谓词是否至少匹配一个元素
anyMatch 方法可以回答“流中是否有一个元素能匹配给定的谓词”。比如,你可以用它来看看菜单里面是否有素食可选择:
if(menu.stream().anyMatch(Dish::isVegetarian)){
System.out.println("The menu is (somewhat) vegetarian friendly!!");
}
anyMatch 方法返回一个 boolean,因此是一个终端操作。
5.4.2 检查谓词是否匹配所有元素
allMatch 方法的工作原理和 anyMatch 类似,但它会看看流中的元素是否都能匹配给定的谓词。
比如,你可以用它来看看菜品是否有利健康(即所有菜的热量都低于 1000 卡路里):boolean isHealthy = menu.stream().allMatch(dish -> dish.getCalories() < 1000);
noneMatch
和 allMatch 相对的是 noneMatch。它可以确保流中没有任何元素与给定的谓词匹配。
比如,你可以用 noneMatch 重写前面的例子:boolean isHealthy = menu.stream() .noneMatch(dish -> dish.getCalories() >= 1000);
anyMatch、allMatch 和 noneMatch 这三个操作都用到了所谓的短路,这就是大家熟悉的Java 中&&和||运算符短路在流中的版本。
5.4.3 查找元素
findAny 方法将返回当前流中的任意元素。它可以与其他流操作结合使用。
比如,你可能想找到一道素食菜肴。可以结合使用 filter 和 findAny 方法来实现这个查询:Optional
返回第一个符合的元素
Optional 简介
Optional类(java.util.Optional)是一个容器类,代表一个值存在或不存在。Optional 里面几种可以迫使你显式地检查值是否存在或处理值不存在的情形的方法
- isPresent()将在 Optional 包含值的时候返回 true, 否则返回 false。
- ifPresent(Consumer block)会在值存在的时候执行给定的代码块。第 3 章介绍过Consumer 函数式接口,它让你传递一个接受 T 类型参数,并返回 void 的 Lambda 表达式。
- T get()会在值存在时返回值,否则抛出一个 NoSuchElement 异常。
- T orElse(T other)会在值存在时返回值,否则返回一个默认值。
在前面的代码中你需要显式地检查Optional对象中是否存在一道菜可以访问其名称:
menu.stream()
.filter(Dish::isVegetarian)
.findAny() // 返回一个Optional
.ifPresent(dish -> System.out.println(dish.getName()); // 如果包含一个值就打印它,否则什么都不做
5.4.4 查找第一个元素
有些流由一个出现顺序(encounter order)来指定流中项目出现的逻辑顺序(比如由 List或排序好的数据列生成的流)。
如果我想找第一个元素,为此有一个 findFirst方法,它的工作方式类似于 findAny。
为此有一个 findFirst方法,它的工作方式类似于 findAny。
List someNumbers = Arrays.asList(1, 2, 3, 4, 5);
Optional firstSquareDivisibleByThree =
someNumbers.stream()
.map(n -> n * n)
.filter(n -> n % 3 == 0)
.findFirst(); // 9
何时使用 findFirst 和 findAny?
你可能会想,为什么会同时有 findFirst 和 findAny 呢?答案是并行。找到第一个元素在并行上限制更多。如果你不关心返回的元素是哪个,请使用 findAny,因为它在使用并行流时限制较少。
5.5 归约
如何把一个流中的元素组合起来,使用 reduce 操作来表达更复杂的查询,比如“计算菜单中的总卡路里”或“菜单中卡路里最高的菜是哪一个”。此类查询需要将流中所有元素反复结合起来,得到一个值。这样的查询可以被归类为归约操作(将流归约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
5.5.1 元素求和
使用 for-each 循环来对数字列表中的元素求和:
int sum = 0;
for (int x : numbers) {
sum += x;
}
反复相加,列表归约成一个数字,这段代码中有两个参数:总和变量的初始值,在这里是 0;将列表中所有元素结合在一起的操作,在这里是+。
如果需要所有数字相乘呢?又得复制吗?
所以就使用了reduce操作。int sum = numbers.stream().reduce(0, (a, b) -> a + b);
reduce 接受两个参数:
- 一个初始值,这里是 0;
- 一个BinaryOperator来将两个元素结合起来产生一个新值,这里用的是lambda (a, b) -> a + b。
相乘的话,也是把行为传递进去就可以了int product = numbers.stream().reduce(1, (a, b) -> a * b);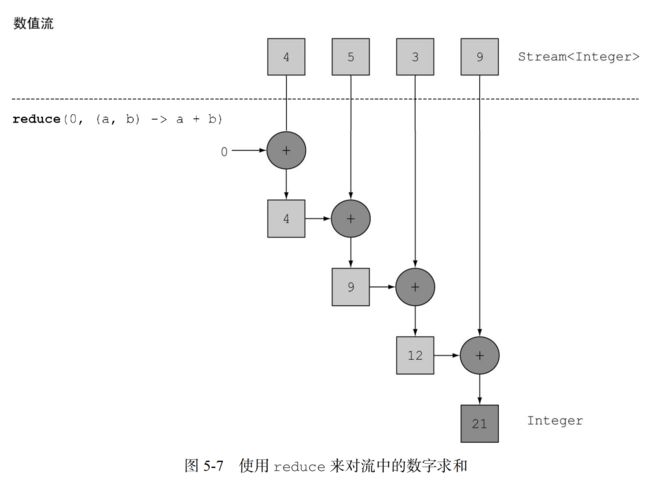
无初始值
reduce 还有一个重载的变体,它不接受初始值,但是会返回一个 Optional 对象:Optional
5.5.2 最大值和最小值
Optional
测验 5.3:归约
怎样用 map 和 reduce 方法数一数流中有多少个菜呢?
答案:要解决这个问题,你可以把流中每个元素都映射成数字 1,然后用 reduce 求和。这相当于按顺序数流中的元素个数。
**int count = menu.stream().map(d -> 1).reduce(0, (a, b) -> a + b); **
map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名,因为它很容易并行化。请注意,在第 4 章中我们也看到了内置 count 方法可用来计算流中元素的个数:
long count = menu.stream().count();

5.6 付诸实践
练习:
(1) 找出 2011 年发生的所有交易,并按交易额排序(从低到高)。
(2) 交易员都在哪些不同的城市工作过?
(3) 查找所有来自于剑桥的交易员,并按姓名排序。
(4) 返回所有交易员的姓名字符串,按字母顺序排序。
(5) 有没有交易员是在米兰工作的?
(6) 打印生活在剑桥的交易员的所有交易额。
(7) 所有交易中,最高的交易额是多少?
(8) 找到交易额最小的交易。
5.6.1 领域:交易员和交易
以下是你要处理的领域,一个 Traders 和 Transactions 的列表:
Trader raoul = new Trader("Raoul", "Cambridge");
Trader mario = new Trader("Mario","Milan");
Trader alan = new Trader("Alan","Cambridge");
Trader brian = new Trader("Brian","Cambridge");
List transactions = Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
Trader 和 Transaction 类的定义如下:
public class Trader{
private final String name;
private final String city;
public Trader(String n, String c){
this.name = n;
this.city = c;
}
public String getName(){
return this.name;
}
public String getCity(){
return this.city;
}
public String toString(){
return "Trader:"+this.name + " in " + this.city;
}
}
public class Transaction{
private final Trader trader;
private final int year;
private final int value;
public Transaction(Trader trader, int year, int value){
this.trader = trader;
this.year = year;
this.value = value;
}
public Trader getTrader(){
return this.trader;
}
public int getYear(){
return this.year;
}
public int getValue(){
return this.value;
}
public String toString(){
return "{" + this.trader + ", " +
"year: "+this.year+", " +
"value:" + this.value +"}";
}
}
5.6.2 解答
找出 2011 年发生的所有交易,并按交易额排序(从低到高)
List tr2011 =
transactions.stream()
.filter(transaction -> transaction.getYear() == 2011) // 给 filter 传递一个谓词来选择 2011 年的交易
.sorted(comparing(Transaction::getValue)) // 按照交易额进行排序
.collect(toList());
交易员都在哪些不同的城市工作过
List cities =
transactions.stream()
.map(transaction -> transaction.getTrader().getCity()) // 提取与交易相关的每位交易员的所在城市
.distinct() // 只选择互不相同的城市
.collect(toList()); // 这里的toList改成toSet,这样就不需要distinct()处理了
查找所有来自于剑桥的交易员,并按姓名排序
List traders =
transactions.stream()
.map(Transaction::getTrader) //从交易中提取所有交易员
.filter(trader -> trader.getCity().equals("Cambridge")) // 仅选择位于剑桥的交易员
.distinct()
.sorted(comparing(Trader::getName)) // 对生成的交易员流按照姓名进行排序
.collect(toList());
返回所有交易员的姓名字符串,按字母顺序排序
String traderStr =
transactions.stream()
.map(transaction -> transaction.getTrader().getName()) // 提取所有交易员姓名,生成一个Strings 构成的 Stream
.distinct()
.sorted() // 对姓名按字母顺序排序
// .collect(joining()); 可以改成这样,效率高一点
.reduce("", (n1, n2) -> n1 + n2);// 逐个拼接每个名字,得到一个将所有名字连接起来的 String
有没有交易员是在米兰工作的
boolean milanBased =
transactions.stream()
.anyMatch(transaction -> transaction.getTrader()
.getCity()
.equals("Milan")); // 把一个谓词传递给 anyMatch,检查是否有交易员在米兰工作
打印生活在剑桥的交易员的所有交易额
transactions.stream()
.filter(t -> "Cambridge".equals(t.getTrader().getCity())) // 选择住在剑桥的交易员所进行的交易
.map(Transaction::getValue) // 提取这些交易的交易额
.forEach(System.out::println);
所有交易中,最高的交易额是多少
Optional highestValue =
transactions.stream()
.map(Transaction::getValue) // 提取每项交易的交易额
.reduce(Integer::max); // 计算生成的流中的最大值
找到交易额最小的交易
Optional smallestTransaction =
transactions.stream()
// 通过反复比较每个交易的交易额,找出最小的交易
.reduce((t1, t2) -> t1.getValue() < t2.getValue() ? t1 : t2);
Optional smallestTransaction =
transactions.stream()
.min(comparing(Transaction::getValue));
5.7 数值流
用 reduce 方法计算流中元素的总和
int calories = menu.stream()
.map(Dish::getCalories)
.reduce(0, Integer::sum);
这段代码的问题是,它有一个暗含的装箱成本。每个 Integer 都必须拆箱成一个原始类型,再进行求和。要是可以直接像下面这样调用 sum 方法,岂不是更好?
int calories = menu.stream()
.map(Dish::getCalories)
.sum();
但是这样是不行的,问题在于 map 方法会生成一个 Stream。虽然流中的元素是 Integer类型,但 Stream 接口没有定义 sum 方法,所以Stream API 还提供了原始类型流特化,专门支持处理数值流的方法。
5.7.1 原始类型流特化
Java 8 引入了三个原始类型特化流接口来解决这个问题:IntStream、DoubleStream 和LongStream,分别将流中的元素特化为 int、long 和 double,从而避免了暗含的装箱成本。
- 映射到数值流
将流转换为特化版本的常用方法是 mapToInt、mapToDouble 和 mapToLong。这些方法和前面说的 map 方法的工作方式一样,只是它们返回的是一个特化流,而不是 Stream。
int calories = menu.stream() // 返回一个 Stream
.mapToInt(Dish::getCalories) // 返回一个 IntStream
.sum();
- 转换回对象流
一旦有了数值流,你可能会想把它转换回非特化流。
IntStream intStream = menu.stream().mapToInt(Dish::getCalories); // 将 Stream 转换为数值流
Stream stream = intStream.boxed(); // 将数值流转换为 Stream
- 默认值 OptionalInt
求和的那个例子很容易,因为它有一个默认值:0。但是,如果你要计算 IntStream 中的最大元素,就得换个法子了,因为 0 是错误的结果。
要找到 IntStream 中的最大元素,可以调用 max 方法,它会返回一个 OptionalInt:
OptionalInt maxCalories = menu.stream()
.mapToInt(Dish::getCalories)
.max();
现在,如果没有最大值的话,你就可以显式处理 OptionalInt 去定义一个默认值了:
如果没有最大值的话,显式提供一个默认最大值int max = maxCalories.orElse(1);
5.7.2 数值范围
和数字打交道时,有一个常用的东西就是数值范围,比如,假设你想要生成 1 和 100 之间的所有数字。Java 8 引入了两个可以用于 IntStream 和 LongStream 的静态方法,帮助生成这种范围:range 和 rangeClosed。这两个方法都是第一个参数接受起始值,第二个参数接受结束值。但 range 是不包含结束值的,rangeClosed 则包含结束值。来看一个例子:
// 表示范围[1, 100] , 一个从 1 到 100的偶数流IntStream evenNumbers = IntStream.rangeClosed(1, 100) .filter(n -> n % 2 == 0); System.out.println(evenNumbers.count()); // 从 1 到 100 有50 个偶数
5.7.3 数值流应用:勾股数
- 勾股数
其实就算勾股定理。公式 a * a + b * b = c * c
- 表示三元数
new int[]{3, 4, 5},来表示勾股数(3, 4, 5)。
- 筛选成立的组合
判断它是否能形成一组勾股数呢?你需要测试 a * a + b * b 的平方根是不是整数。这个思想在 Java 中可以这么表述:Math.sqrt(aa + bb) % 1 == 0filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
- 生成三元组
stream.filter(b -> Math.sqrt(aa + bb) % 1 == 0) .map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});
- 生成 b 值
IntStream.rangeClosed(1, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.boxed()
.map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});
你在 filter 之后调用 boxed,从 rangeClosed 返回的 IntStream 生成一个Stream。这是因为你的 map 会为流中的每个元素返回一个 int 数组。而 IntStream中的 map 方法只能为流中的每个元素返回另一个 int,这可不是你想要的!你可以用 IntStream的 mapToObj 方法改写它,这个方法会返回一个对象值流:
IntStream.rangeClosed(1, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.mapToObj(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});
- 生成值
假设:给出了 a 的值。现在,只要已知 a 的值,你就有了一个可以生成勾股数的流。如何解决这个问题呢?就像 b 一样,你需要为 a 生成数值!最终的解决方案如下所示:
Stream pythagoreanTriples =
IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.mapToObj(b ->
new int[]{a, b, (int)Math.sqrt(a * a + b * b)})
);
- 运行代码
现在可以运行解决方案,并且可以利用前面看到的 limit 命令,明确限定从生成的流中要返回多少组勾股数了:
pythagoreanTriples.limit(5).forEach(t -> System.out.println(t[0] + ", " + t[1] + ", " + t[2]));
打印
3, 4, 5
5, 12, 13
6, 8, 10
7, 24, 25
8, 15, 17
- 你还能做得更好吗
目前的解决办法并不是最优的,因为你要求两次平方根。让代码更为紧凑的一种可能的方法是,先生成所有的三元数(aa, bb, aa+bb),然后再筛选符合条件的:
Stream pythagoreanTriples2 =
IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.mapToObj(
b -> new double[]{a, b, Math.sqrt(a*a + b*b)}) // 产生三元数
.filter(t -> t[2] % 1 == 0)); // 元组中的第三个元素必须是整数
5.8 构建流
5.8.1 由值创建流
使用静态方法 Stream.of,通过显式值创建一个流。它可以接受任意数量的参数。
Stream stream = Stream.of("Modern ", "Java ", "In ", “Action”);
stream.map(String::toUpperCase).forEach(System.out::println);
你可以使用 empty 得到一个空流,如下所示:
Stream emptyStream = Stream.empty();
5.8.2 由可空对象创建流
Java 9 提供了一个新方法可以由一个可空对象创建流。使用流的过程中,你可能也碰到过这种情况,即你处理的对象有可能为空,而你又需要把它们转换成流(或者由 null 构成的空的流)进行处理。
String homeValue = System.getProperty("home");
Stream homeValueStream = homeValue == null ? Stream.empty() : Stream.of(value);
借助于 Stream.ofNullable,这段代码可以改写得更加简洁:
Stream homeValueStream = Stream.ofNullable(System.getProperty("home"));
这种模式搭配 flatMap 处理由可空对象构成的流时尤其方便:
Stream values =
Stream.of("config", "home", "user")
.flatMap(key -> Stream.ofNullable(System.getProperty(key)));
5.8.3 由数组创建流
使用静态方法 Arrays.stream 从数组创建一个流。它接受一个数组作为参数。
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();
5.8.4 由文件生成流
Java 中用于处理文件等 I/O 操作的 NIO API(非阻塞 I/O)已更新,以便利用 Stream API。
long uniqueWords = 0;
try(Stream lines =
Files.lines(Paths.get("data.txt"), Charset.defaultCharset())){ // 流会自动关闭,因此不需要执行额外的 try-finally 操作
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" "))) // 生成单词流
.distinct() // 去重
.count(); // 数一数有多少个不同的单词
}
catch(IOException e){ // 如果打开文件时出现异常则加以处理
}
5.8.5 由函数生成流:创建无限流
Stream API提供了两个静态方法来从函数生成流:Stream.iterate 和 Stream.generate。这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。
- 迭代
我们先来看一个 iterate 的简单例子,然后再解释:
Stream.iterate(0, n -> n + 2) .limit(10).forEach(System.out::println);
iterate 方法接受一个初始值(在这里是 0),还有一个依次应用在每个产生的新值上的Lambda(UnaryOperator类型)。这里,使用 Lambda n -> n + 2,返回的是前一个元素加上 2。此操作将生成一个无限流——这个流没有结尾,所以使用了limit来限制流的大小。
- 生成
与 iterate 方法类似,generate 方法也可让你按需生成一个无限流。但 generate 不是依次对每个新生成的值应用函数的。它接受一个 Supplier类型的 Lambda 提供新的值。
**Stream.generate(Math::random) **
.limit(5) .forEach(System.out::println);
5.10 小结
- 可以使用 filter、distinct、takeWhile (Java 9)、dropWhile (Java 9)、skip 和limit 对流做筛选和切片。
- 如果明确地知道数据源是排序的,那么用 takeWhile 和 dropWhile 方法通常比filter 高效得多。
- 可以使用 map 和 flatMap 提取或转换流中的元素。
- 可以使用 findFirst 和 findAny 方法查找流中的元素。你可以用 allMatch、noneMatch 和 anyMatch 方法让流匹配给定的谓词。
- 这些方法都利用了短路:找到结果就立即停止计算;没有必要处理整个流。
- 可以利用 reduce 方法将流中所有的元素迭代合并成一个结果,例如求和或查找最大元素。
- filter 和 map 等操作是无状态的,它们并不存储任何状态。reduce 等操作要存储状态才能计算出一个值。sorted 和 distinct 等操作也要存储状态,因为它们需要把流中的所有元素缓存起来才能返回一个新的流。这种操作称为有状态操作。
- 流有三种基本的原始类型特化:IntStream、DoubleStream 和 LongStream。它们的操作也有相应的特化。
- 流不仅可以从集合创建,也可从值、数组、文件以及 iterate 与 generate 等特定方法创建。
- 无限流所包含的元素数量是无限的(想象一下所有可能的字符串构成的流)。这种情况是有可能的,因为流中的元素大多数都是即时产生的。使用 limit 方法,你可以由一个无限流创建一个有限流。