看叶子猿视频的jvm笔记
JVM
jdk包括jre和jvmjvm是按照运行时数据的存储结构来划分内存结构的,jvm在运行java程序时,将他们划分成几种不同格式的数据,分别存储在不同的区域,这些数据统一称为运行时数据。运行时数据包括java本身的数据信息和jvm运行java需要的额外数据信息。
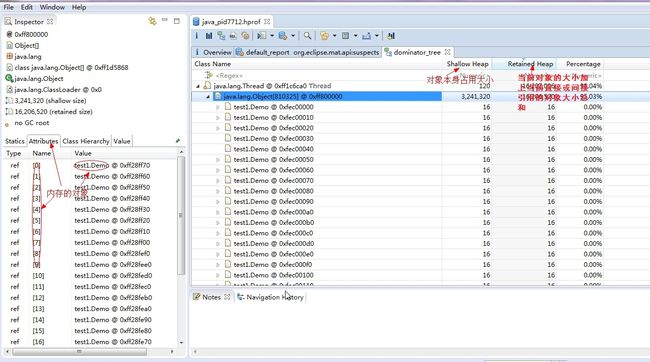
案例一 内存溢出
List
while(true) {
demoList.add(new Demo());
}
异常信息
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
可以通过configurations--》arguments--》VM arguments 来设置虚拟机参数 -XX:+HeapDumpOnOutOfMemoryError
运行后 在项目目录下会出来一个java_pid7712.hprof文件 可以用Memory Analyzer来分析 来定位
下载Memory Analyzer
http://www.eclipse.org/downloads/download.php?file=/mat/1.7/rcp/MemoryAnalyzer-1.7.0.20170613-win32.win32.x86_64.zip&mirror_id=1142
可以cmd里面输入jconsole来启动java监视和管理控制台
垃圾内存分为 eden(new 出来的对象的区域)和Survivor(存活下来的对象生活区域)区域

jdk 1.8 新加的 lanmbda 属于函数编程 减少了java原来的内部类 对map、reduce进行了优化
jb.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent arg0) {
System.out.println("旧方法");
}
});
jb.addActionListener(event -> System.out.println("我是lanmbda"));
同样的结果 lanmbda 实现起来更简洁
JRockit
BEA
世界上最快的java虚拟机
专注服务器应用(不注意程序的启动服务)
优势:
垃圾收集器
MissionControl服务套件
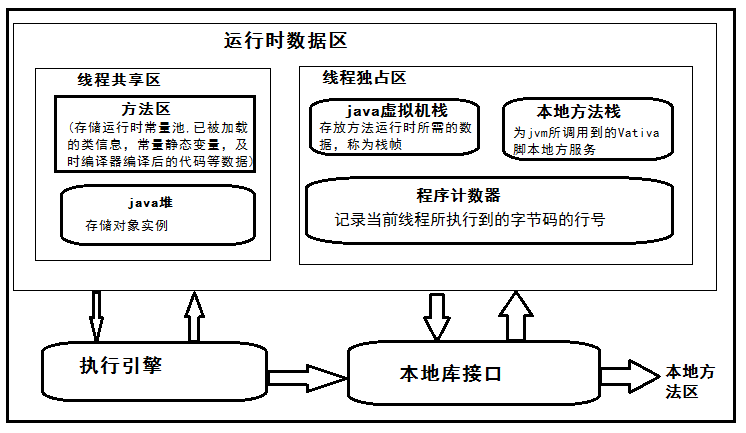
运行时数据区
程序计数器
程序计数器(处于线程独占区)是一块较小的内存空间,他可以看做是当前线程所执行的字节码的行号指示器。
如果线程执行的是java方法,这个计数器记录的是正在执行的虚拟字节码指令的地址。如果正在执行的是native方法,那么这个计数器的值为undefined
虚拟机栈为虚拟机执行java方法服务
本地方法栈为虚拟机执行native方法服务
java堆(java虚拟机最大的内存区域)
存放对象实例
垃圾收集器管理的主要区域
方法区
存储虚拟机加载的类信息,常量,静态常量,即编译后的代码等数据(类,字段,方法,接口)
方法区和永久代并不相同 他俩的出现只是为了更好的管理
方法区也在堆里面
运行时常量池
每一个运行时常量池都在java虚拟机的方法区中分配
String a1="abc";
String a2="abc";
println(a1 == a2);//true
因为a1 a2字符串指向的是一个常量池表 常量池表的数据结构是hashSet(无需不可重复) 所以他两指向的是同一个坐标 所以true
String a3 = new String("abc");
println("a1 == a3 );//false
因为a3创建的是一个对象在堆内存里面;
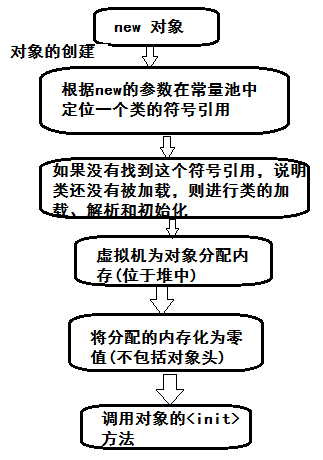
对象的创建
new类名--》 根据new的参数在常量池中定位一个类的符号引用 --> 如果没有找到这个符号引用,说明类还没有被加载,则进行类的加载、解析和初始化
--> 虚拟机为对象分配内存(位于堆中) -->将分配的内存化为零值(不包括对象头) --> 调用对象的
创建对象,在堆中开辟内存时是如何分配内存的?
两种方式:指针碰撞和空闲列表。我们具体使用的哪一种,就要看我们虚拟机中使用的是什么了。
指针碰撞:假设Java堆中内存是绝对规整的,所有用过的内存度放一边,空闲的内存放另一边,中间放着一个指针作为分界点的指示器,所分配内存就仅仅是把哪个指针向空闲空间那边挪动一段与对象大小相等的举例,这种分配方案就叫指针碰撞
空闲列表:有一个列表,其中记录中哪些内存块有用,在分配的时候从列表中找到一块足够大的空间划分给对象实例,然后更新列表中的记录。这就叫做空闲列表
对象的结构
Header(对象头)
自身运行时的数据(Mark Word)
哈希值、GC分代年龄、锁状态标志、线程持有锁、偏向线程ID、偏向时间
类型指针
对象引用是如何找到我们在堆中的对象实例的?
这个问题也可以称为对象的访问定位问题,也有两种方式。句柄访问和直接指针访问。
句柄访问:Java堆中会划分出一块内存来作为句柄池,引用变量中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息
在栈中有一个引用变量指向句柄池中一个句柄的地址,这个句柄又包含了两个地址,一个对象实例数据,一个是对象类型数据(这个在方法区中,因为类字节码文件就放在方法区中),
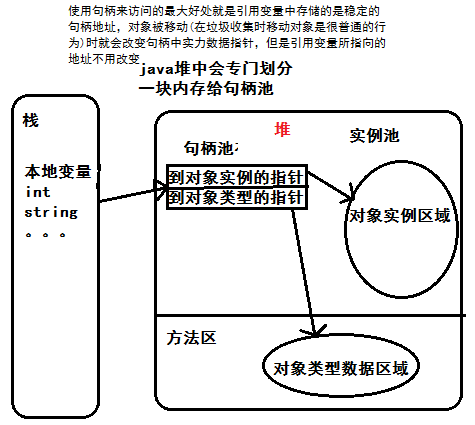
直接指针访问:引用变量中存储的就直接是对象地址了
在堆中就不会分句柄池了,直接指向了对象的地址,对象中包含了对象类型数据的地址
垃圾回收(重点)
如何判定对象为垃圾对象
引用计数发
可达性分析法
如何回收
回收策略
标记-清除算发
复制算法
标记整理算法
分代手机算法
垃圾回收器
serial
parnew
cms
G1
引用计数法
在对象中添加一个引用计数器,当有地方引用这个对象的时候,引用计数器的值就加1,当引用失效的时候,计数器的值就减1;
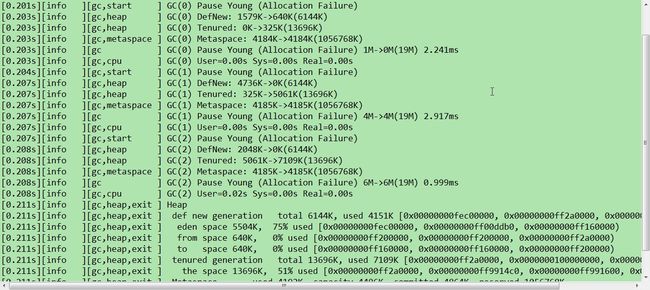
gc内存输出 命令
-verbose:gc -XX:+PrintGCDetails
-verbose:gc -Xlog:gc* jdk 1.9
GC日志打印信息:
-XX:+PrintGCTimeStamps输出格式:
289.556: [GC [PSYoungGen: 314113K->15937K(300928K)] 405513K->107901K(407680K), 0.0178568 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
293.271: [GC [PSYoungGen: 300865K->6577K(310720K)] 392829K->108873K(417472K), 0.0176464 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
详解:
293.271是从jvm启动直到垃圾收集发生所经历的时间,GC表示这是一次Minor GC(新生代垃圾收集);[PSYoungGen: 300865K->6577K(310720K)] 提供了新生代空间的信息,PSYoungGen,表示新生代使用的是多线程垃圾收集器Parallel Scavenge。300865K表示垃圾收集之前新生代占用空间,6577K表示垃圾收集之后新生代的空间。新生代又细分为一个Eden区和两个Survivor区,Minor GC之后Eden区为空,6577K就是Survivor占用的空间。
括号里的310720K表示整个年轻代的大小。
392829K->108873K(417472K),表示垃圾收集之前(392829K)与之后(108873K)Java堆的大小(总堆417472K,堆大小包括新生代和年老代)
由新生代和Java堆占用大小可以算出年老代占用空间,如,Java堆大小417472K,新生代大小310720K那么年老代占用空间是417472K-310720K=106752k;垃圾收集之前老年代占用的空间为392829K-300865K=91964k 垃圾收集之后老年代占用空间108873K-6577K=102296k.
0.0176464 secs表示垃圾收集过程所消耗的时间。
[Times: user=0.06 sys=0.00, real=0.01 secs] 提供cpu使用及时间消耗,user是用户模式垃圾收集消耗的cpu时间,实例中垃圾收集器消耗了0.06秒用户态cpu时间,sys是消耗系统态cpu时间,real是指垃圾收集器消耗的实际时间。
可达性分析算法
引用链
作为GCRoot的对象
虚拟机栈(栈帧中的局部变量表)
方法区的类属性所引用的对象
方法区中常量所引用的对象
本地方法中引用的对象
标记-清除算法
先标记出要回收的对象(一般使用可达性分析算法),再清除
会有效率问题
空间问题:标记的空间被清除后,会造成我的内存中出现越来越多的不连续空间,
当要分配一个大对象的时候,在进行询址的要花费很多时间。
复制算法
堆
新生代
Eden
Survivor 存活区
Tenured Gen
老年代
方法区
栈 本地方法栈 程序计数器
复制算法:把内存分成两块,先在第一块进行对象的分配,然后先对要回收的对象内存进行标记,然后对未标记的内存连续第放在
另一块内存中,再对标记的内存进行清除。
主要缺点:内存缩小为原来的一半。
(HotSpot JVM把年轻代分为了三部分:1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1,为啥默认会是这个比例,接下来我们会聊到。
一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区。
对象在Survivor区中每熬过一次Minor GC,年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中。
因为年轻代中的对象基本都是朝生夕死的(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产生内存碎片。
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。
紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。
年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。
经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。
不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。)
标记-整理-清除算法
标记操作和“标记-清除”算法一致,后续操作不只是直接清理对象,而是在清理无用对象完成后让所有存活的对象都向一端移动,并更新引用其对象的指针。
主要缺点:在标记-清除的基础上还需进行对象的移动,成本相对较高,好处则是不会产生内存碎片
分代收集算法
针对不同的年代进行不同算法的垃圾回收
针对新生代 现在复制算法 对老年代 标记整理算法
Serial收集器
单线程垃圾收集器、最基本、发展最悠久
parnew收集器
多线程
Parallel Scavenge 收集器
复制算法
多线程收集器
达到可控制的吞吐量:
-XX:MaxGCPauseMillis 垃圾收集器最大停顿的时间1
-XX:CGTIMERatio 吞吐量大小(0-99)
吞吐量 = (执行用户代码的时间)/(执行用户代码的时间+垃圾回收所占用的时间)
CMS收集器(Concurrent Mark Sweep)
收集老年代
工作过程
初始标记
并发标记
重新标记
并发清理
优点
并发收集
低停顿
缺点
占用大量的cpu资源
无法处理浮点垃圾
出现Concurrent MarkFailure
空间碎片
G1收集器 jdk1.9
优势
并行与并发
分代收集(新生代和老年代区分不明显)
空间整合
可预测的停顿
步骤
初始标记
并发标记
最终标记
筛选回收
内存分别策略
优先分配到eden
大对象直接分配到老年代
长期存活的对象分配到老年代
空间分配担保
动态年龄判断
-XX:+UseSerialGC 指定垃圾收集器
-Xms20M -Xmx20M 设置内存最大最小
-Xmn10M 指定新生代为10M
-XX:SurvivorRatio=8 设置eden 与survuvor 的比值大小 8:1
-XX:PretenureSizeThreshold=6M 指定大对象为6M
age 可以设置老年代值
-XX:+HandlePromotionFailure 空间分配担保
-verbose:gc -XX:+PrintGCDetails -XX:+UseSerialGC -Xms20M -Xmx20M
-verbose:gc -XX:+PrintGCDetails -XX:+UseSerialGC -Xms20M -Xmx20M -Xmn10M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=6M
逃逸分析与栈上分配
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。
甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
上述代码如果想要StringBuffer sb不逃出方法,可以这样写:return sb.toString();
jps(java process status)
java 的进程资源监控器
本地虚拟机唯一id lvmid local virtual machine id
jps -m 运行时传入主类的参数
jps -v 虚拟机参数
jps -l 运行的主类全名 或者jar包名称
也可以一块使用 jsp -mlv
Jstat(监视虚拟机运行时的状态信息)
可以监视 类装载、内存、垃圾回收、jit编译信息
可以百度其操作命令(官网 https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html)
jstat -gcutil 3344 1000 10 每隔1000毫秒执行一次 10次
元空间的本质和永久代类似,都是对jvm规范中的方法区的实现。不过元空间与永久代之间最大的区别是:元空间并不在虚拟机中,而是使用本地内存。
因此在默认情况下,元空间的大小仅受本地内存限制。
jinfo
实时查看和调整虚拟机的各项参数
jmap
-XX:+HeapDumpOnOutOfMemoryError
Jhat(jvm heap Analysis Tool)
用处不大
jstack
线程快照
-f
-m
-l
jstack -l 3344
JConsole
内存监控
线程监控
死锁
VisualVM
https://visualvm.github.io/download.html
性能调优
小案例
问题:经常有用户反映长时间出现卡顿现象
处理思路:
优化SQL
监控cpu
监控内存
Full GC 20-30S
解决方案
部署多个web容器,每个web容器的堆内存指定为4g
案例二
不定期内存溢出,把堆内存加大,也无济于事。导出堆转储快照信息,没有任何信息。内存监控正常。
处理思路
是堆外内存的问题 byte字节内存溢出 把堆外内存调大