Hadoop 笔记(一) HDFS 和 MapReduce 体系结构
Hadoop 1.x 由 Common、HDFS、MapReduce 组成。Hadoop 2.x 由 Common、HDFS、YARN、MapReduce 组成。两者的 Common 和 HDFS 部分相同,前者主要为其它模块提供服务,起到辅助作用,后者是 Hadoop 的文件系统。
两个版本的主要区别在于 MapReduce 和 YARN。1.x 版本 MapReduce 负责计算和资源调度,耦合性较大;而 2.x 将这两个功能拆开,MapReduce 负责计算,而 YARN 负责资源调度。
本问主要讲解 HDFS 和 MapReduce 结构,下一篇文章讲解 YARN 结构。
目录
- Common
- HDFS
-
- 特点
- 体系架构
- MapReduce
-
- 特点
- 体系架构
Common
Common 是其它模块的公共接口,提供公用 API。它还提供了 mini 集群、本地库、超级用户、服务器认证和 HTTP 认证等功能。
HDFS
HDFS 是 Hadoop 文件系统,提供了高容错、高扩展、高可靠的分布式存储服务,并提供服务访问接口。
特点
- 可以自动快速检测应对硬件错误;
- 适用于批处理数据场景,更多地追求数据吞吐量,这采用了最高效的数据访问——流式数据访问;
- 还能减少数据传输,转移计算比移动数据更划算;
- 采用一次性模型,一次写入,多次读取,文件一旦写入后就不再修改;
- 考虑到平台的可一支性。
体系架构
HDFS 采用 master/slave 架构来构建分布式存储集群,可以任意添加或删除 slave 节点。master 主机运行主进程 namenode,slave 都运行从属进程 datanode。客户端连接 namenode 以获取文件的元数据,而真正的文件 I/O 操作时客户端直接和 datanode 交互。
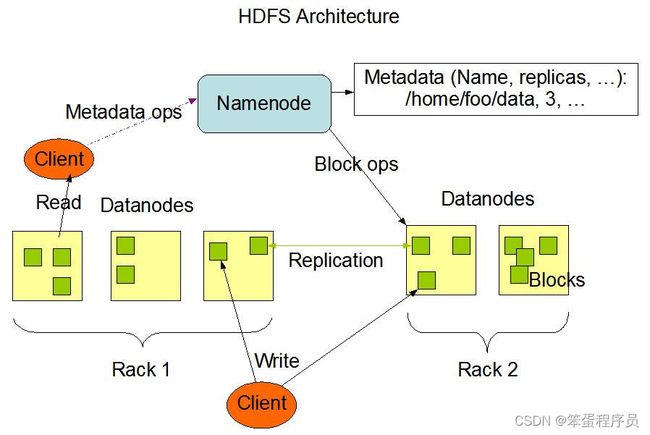
NameNode(nn) 就是主控制服务器,负责维护文件系统的命名空间并协调客户端对文件的访问,记录命名空间内的任何改动或命名空间本身的属性改动。存储元数据信息,如文件名、目录结构、文件属性等信息,以及每个文件的块列表和块所在的 DataNode 等。
DataNode(dn) 负责它们所在的物理节点上的存储管理,HDFS 开放文件系统的命名空间以便让用户以文件的形式存储数据。在本地文件系统存储文件块数据,以及校验和。
**Secondary NameNode(2nm)**用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据快照。
HDFS 的文件切分成不同的数据块(block),默认大小 128 M,也可自行设置。HDFS 的数据都是一次写入,多次读取。每个数据块有多个副本,尽可能地分布存储在不同的 DataNode 中。
NameNode 使用**事务日志(EditLog)记录 HDFS 元数据的变化,使用映像文件(FsImage)**存储文件系统的命名空间,包含文件的映射、属性等信息。事务日志和映像文件都存储在 NameNode 的本低文件系统中。
主从节点通过 TCP 协议进行通信,DataNode 每 3 秒钟向 NameNode 发送一个心跳,报告自己处于存活状态,每 10 次心跳之后,发送一次数据块报告,告知其所存储的数据块信息。NameNode 可以通过这些信息重建元数据,并确保每个数据块有足够的副本。
客服端要访问一个文件。首先,客户端从 NameNode 获得组成文件的数据块的位置列表,也就知道数据块被存储在哪些 DataNode 上。其次,客户端直接从 DataNode 上读取文件。NameNode 不参与文件的传输。
MapReduce
MapReduce 是一种处理海量数据的并行编程模式,用于大规模数据集的并行计算。它封装了并行处理、容错处理、本地化计算、负载均衡等细节,还提供了一个简单而强大的接口。
特点
- 分布式编程架构;
- 以数据为中心;
- 分而治之;
- Map 将一个任务分解为多个子任务;
- Reduce 将分解后多任务分别处理,并将结果汇总为最终结果。
体系架构
MapReduce 包括两个处理步骤:
- Map 阶段:输入数据被分割成离散块,以便可以单独处理;
- Reduce 阶段:汇总 Map 阶段输出生成预期结果。
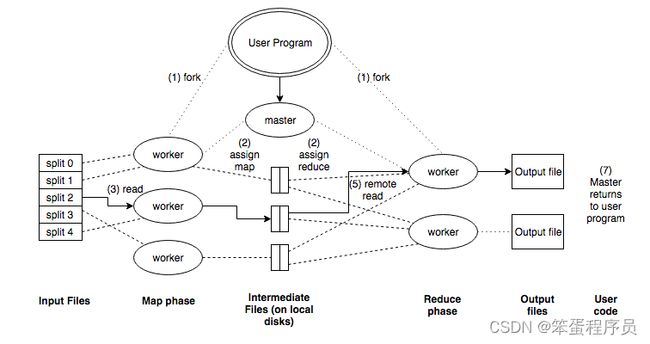
首先,输入文件被分为 M 块,接着在集群的机器上执行分派的处理程序。分派的执行程序中有一个程序比较特别,就是主控程序 master,剩下的执行程序都是作为 Master 分派工作的 Worker(工作机)。Master 会选择空闲的 Worker 来分配任务。
被分配了 Map 任务的 Worker 读取并处理相关的输入块。它处理输入数据,并将分析的结果以
Reduce Worker 从本地硬盘上读取中间数据,使用 key 进行排序,这是因为相同的 key 可能被映射到不同的 Map Worker 上。排序后,把 key 相关的中间结果值集合传递给用户定义的 Reduce 函数,最终写到一个输出文件。
所有 Map 和 Reduce 任务完成后,Master 激活用户程序,返回用户程序的调用点。
本文讲解了 HDFS 和 MapReduce 的体系架构,下一篇文章讲解 YARN 的体系结构。
参考资料
【1】https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html;
【2】云计算(第三版),刘鹏;