机器学习—模型公平性
机器学习—模型公平性
目录
-
- 机器学习—模型公平性
-
- 零、前言
- 一、公平性评价指标
-
- 1.有哪些常见、常用的公平性指标?如何计算?
-
- 1.0 公平的定义
- 1.1 针对二分类模型、二值字段分群
- 1.2 针对二分类模型、多值字段分群
- 1.3 针对回归模型、二值字段分群
- 1.4 针对回归模型、多值字段分群
- 参考
零、前言
京东二面要求做一个机器学习-模型公平性相关的调研,所以整理一下更新在这里(之后有时间会继续更新一些缓解算法)
一、公平性评价指标
历史数据中存在偏差(例如肤色、种族等)或者有偏数据可能会导致人工智能和机器学习系统可能会表现出不公平的行为。 定义不公平行为的一种方法是按其损害或对人的影响来定义。损害大致有两种,一是可能会对特定群体提供或拒绝提供机会、资源或信息;二是存在对一个人群的工作质量没有针对另一个人群的工作质量好的情况。
1.有哪些常见、常用的公平性指标?如何计算?
1.0 公平的定义
- Fairness through unawareness
考虑到敏感特征和预测结果有关联,不把敏感属性作为分类器的输入,能获得一定程度的公平。当敏感特征 z z z与预测结果统计独立时:
P ( y ^ ∣ x ) = P ( y ^ ∣ x , z ) P(\hat{y}|x)=P(\hat{y}∣x,z) P(y^∣x)=P(y^∣x,z)
思考:这可以作为评价指标吗,比如对输入敏感特征和不输入敏感特征的预测结果计算差异性指标
即使敏感特征 z z z与预测结果统计独立,但是否会存在对 z z z的歧视已经融入其他特征的情况
最终是否会导向无论敏感特征如何,输出相同,这可能意味着”一刀切“? - Group fairness
即对于以敏感特征划分两个群体的个体来说,被分配到各个类别的比例是一样的,有 P ( y ^ = 1 ∣ A = 男 ) = P ( y ^ = 1 ∣ A = 女 ) P(\hat{y} = 1|A = 男)=P(\hat{y} = 1∣A = 女) P(y^=1∣A=男)=P(y^=1∣A=女)
敏感特征 A A A如果是个多值字段的话,也可以推广为
P ( y ^ = 1 ∣ A = 少年 ) = P ( y ^ = 1 ∣ A = 青年 ) = P ( y ^ = 1 ∣ A = 中年 ) = P ( y ^ = 1 ∣ A = 老年 ) P(\hat{y} = 1|A = 少年)=P(\hat{y} = 1∣A = 青年)=P(\hat{y} = 1∣A = 中年)=P(\hat{y} = 1∣A = 老年) P(y^=1∣A=少年)=P(y^=1∣A=青年)=P(y^=1∣A=中年)=P(y^=1∣A=老年)
或者有
P ( y ^ = 1 ∣ A ∈ [ 0 , 10 ) ) = P ( y ^ = 1 ∣ A ∈ [ 10 , 20 ) ) P(\hat{y} = 1|A \in [0, 10))=P(\hat{y} = 1|A \in [10, 20)) P(y^=1∣A∈[0,10))=P(y^=1∣A∈[10,20))
本质上是追求不同群体中的类型比例相同 - Individual fairness
Group fairness强调的是一种群体公平,在追求群体公平时往往会产生个体不公平的问题。而Individual fairness主要考虑的就是个体间的公平,其逻辑是假设样本 X 1 X_{1} X1和样本 X 2 X_{2} X2表现得比较接近,则分类得结果应该趋于一致。Dwork et al(2012)- Equalized odds
P ( Y ^ = 1 ∣ A = 1 , Y = y ) = P ( Y ^ = 1 ∣ A = 0 , Y = y ) P(\hat{Y} = 1|A = 1, Y = y)=P(\hat{Y} = 1∣A = 0, Y = y) P(Y^=1∣A=1,Y=y)=P(Y^=1∣A=0,Y=y),其中 y ∈ { 0 , 1 } y\in \{0,1\} y∈{0,1},与Group fairness的区别在于,这里强调的是整体中各个相同个体的比例相同Hardt et al(2016)
Equalized odds考虑靠了不同Label里面sensitive组的情况,要求 Y ^ ⊥ S ∣ Y \hat{Y} \perp S | Y Y^⊥S∣Y - Equal opportunity
中文理解为机会均等
P ( Y ^ = 1 ∣ A = 1 , Y = y ) = P ( Y ^ = 0 ∣ A = 1 , Y = y ) P(\hat{Y} = 1|A = 1, Y = y)=P(\hat{Y} = 0∣A = 1, Y = y) P(Y^=1∣A=1,Y=y)=P(Y^=0∣A=1,Y=y),其中 y ∈ { 0 , 1 } y\in \{0,1\} y∈{0,1} - Disparate mistreatment
强调不同群体上错误率相同,包括相同的FPR、FNR等:
Zafar et al(2017)
- Equalized odds
1.1 针对二分类模型、二值字段分群
-
Demographic Parity
1 − ∣ P ( Y ^ = 1 ∣ S = 1 ) − P ( Y ˆ = 1 ∣ S = 0 ) ∣ 1 − |P(\hat{Y} = 1|S = 1) − P(Yˆ = 1|S = 0)| 1−∣P(Y^=1∣S=1)−P(Yˆ=1∣S=0)∣ 记作 D P DP DP -
Equality of Odds
- Equality of Opportunity(w.r.t y = 1)
1 − ∣ P ( Y ^ = 1 ∣ Y = 1 , S = 1 ) − P ( Y ˆ = 1 ∣ Y = 1 , S = 0 ) ∣ 1 − |P(\hat{Y} = 1|Y = 1, S = 1) − P(Yˆ = 1|Y = 1, S = 0)| 1−∣P(Y^=1∣Y=1,S=1)−P(Yˆ=1∣Y=1,S=0)∣
记作 E q O p p 1 EqOpp1 EqOpp1 - Equality of Opportunity (w.r.t y = 0)
1 − ∣ p ( Y ˆ = 1 ∣ Y = 0 , S = 1 ) − p ( Y ˆ = 1 ∣ Y = 0 , S = 0 ) ∣ 1 − |p(Yˆ = 1|Y = 0, S = 1) − p(Yˆ = 1|Y = 0, S = 0)| 1−∣p(Yˆ=1∣Y=0,S=1)−p(Yˆ=1∣Y=0,S=0)∣
记作 E q O p p 0 EqOpp0 EqOpp0
0.5 × [ E q O p p 0 + E q O p p 1 ] 0.5 × [EqOpp0 + EqOpp1] 0.5×[EqOpp0+EqOpp1]记作 E q O d d EqOdd EqOdd
- Equality of Opportunity(w.r.t y = 1)
-
Accuracy
P ( Y ^ = y ∣ Y = y , S = 1 ) P(\hat{Y} = y|Y = y, S = 1) P(Y^=y∣Y=y,S=1)记作 s 1 − a c c s1-acc s1−acc
P ( Y ^ = y ∣ Y = y , S = 0 ) P(\hat{Y} = y|Y = y, S = 0) P(Y^=y∣Y=y,S=0)记作 s 0 − a c c s0-acc s0−acc
$accuracy = 0.5 × [s1-acc + s0-acc] 记作 记作 记作acc$ -
Disparity in selection rate
此指标包含不同子群体之间的选择率差异。 此差异的一个示例是贷款批准率差异。 选择率是指每个分类中归类为 1 的数据点所占的比例(在二元分类中)。
Tabel from Charan Reddy et al(2021)
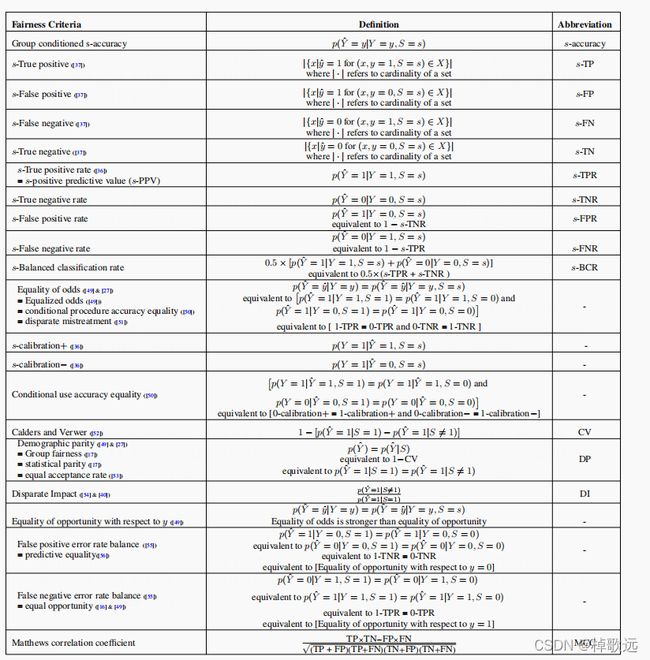
1.2 针对二分类模型、多值字段分群
- 多值字段分区可以考虑将1.1的中的指标进行扩展,例如Disparate Impact在二值字段中定义为 D I = min ( P ( Y ^ = 1 ∣ S = 0 ) P ( Y ^ = 1 ∣ S = 1 ) , P ( Y ^ = 1 ∣ S = 1 ) P ( Y ^ = 1 ∣ S = 0 ) ) DI = \min(\frac{P(\hat{Y} = 1|S=0)}{P(\hat{Y} = 1|S=1)},\frac{P(\hat{Y} = 1|S=1)}{P(\hat{Y} = 1|S=0)}) DI=min(P(Y^=1∣S=1)P(Y^=1∣S=0),P(Y^=1∣S=0)P(Y^=1∣S=1)),在多值字段中计算 D I i j = min ( P ( Y ^ = 1 ∣ S = s i ) P ( Y ^ = 1 ∣ S = s j ) , P ( Y ^ = 1 ∣ S = s j ) P ( Y ^ = 1 ∣ S = s i ) ) DI_{ij} = \min(\frac{P(\hat{Y} = 1|S=s_{i})}{P(\hat{Y} = 1|S=s_{j})},\frac{P(\hat{Y} = 1|S=s_{j})}{P(\hat{Y} = 1|S=s_{i})}) DIij=min(P(Y^=1∣S=sj)P(Y^=1∣S=si),P(Y^=1∣S=si)P(Y^=1∣S=sj)), i , j = 1 , . . . , n i,j=1,...,n i,j=1,...,n,定义 D I = ∑ i ≠ j D I i j n ( n − 1 ) DI = \frac{\sum_{i\ne j} DI_{ij}}{n(n-1)} DI=n(n−1)∑i=jDIij衡量平均水平,或者 D I = max D I i j DI = \max DI_{ij} DI=maxDIij
- 在一些情况下,被保护的敏感特征 S S S是连续的或者有序的,比如收入等。可以人为根据敏感特征 S S S进行分箱。
1.3 针对回归模型、二值字段分群
-
Individual Fairness
U n f a i r = 1 n 1 n 2 ∑ ( x i , y i ) ∈ S 1 , ( x j , y j ) ∈ S 2 d ( y i , y j ) ( w ⋅ x i − w ⋅ x j ) 2 Unfair = \frac{1}{n_{1}n_{2}} \sum_{(x_{i},y_{i})\in S_{1},(x_{j},y_{j})\in S_{2}}d(y_{i},y_{j})(w\cdot x_{i}-w\cdot x_{j})^{2} Unfair=n1n21∑(xi,yi)∈S1,(xj,yj)∈S2d(yi,yj)(w⋅xi−w⋅xj)2
其中 d d d是一个随着 ∣ y i − y j ∣ |y_{i}-y_{j}| ∣yi−yj∣增大而增大的非负函数, S 1 S_{1} S1和 S 2 S_{2} S2是由敏感特征 S S S划分的两组, w w w是由包含敏感特征的全部数据训练出来的线性模型系数。
这里的Unfair相当于是用 ∣ y i − y j ∣ |y_{i}-y_{j}| ∣yi−yj∣作为权重衡量 w w w对于 S 1 S_{1} S1和 S 2 S_{2} S2两组数据的不同影响,且高估某一组的因变量不能通过高估另一个组的因变量来消除影响。 -
Group Fairness
U n f a i r 2 = ( 1 n 1 n 2 ∑ ( x i , y i ) ∈ S 1 , ( x j , y j ) ∈ S 2 d ( y i , y j ) ( w ⋅ x i − w ⋅ x j ) ) 2 Unfair_{2} = (\frac{1}{n_{1}n_{2}} \sum_{(x_{i},y_{i})\in S_{1},(x_{j},y_{j})\in S_{2}}d(y_{i},y_{j})(w\cdot x_{i}-w\cdot x_{j}))^{2} Unfair2=(n1n21∑(xi,yi)∈S1,(xj,yj)∈S2d(yi,yj)(w⋅xi−w⋅xj))2
U n f a i r 2 Unfair_{2} Unfair2和 U n f a i r Unfair Unfair的区别在于 U n f a i r 2 Unfair_{2} Unfair2允许这样一种情况,如果模型高估了一组的因变量,可以通过高估另一个组的因变量来消除。 -
Statistical Parity
预测函数 f f f如果独立于某个受保护的属性 S S S,我们就说该函数满足 SP 要求。即当 f ( X ) ∈ [ 0 , 1 ] f(X)\in [0,1] f(X)∈[0,1]时,有 P [ f ( X ) ≤ z ∣ S = s ] = P [ f ( x ) ≤ z ] P[f(X)\le z|S=s]=P[f(x)\le z] P[f(X)≤z∣S=s]=P[f(x)≤z]
可以用 P [ f ( X ) ≤ z ∣ S = s ] − P [ f ( X ) ≤ z ] P[f(X) \le z | S = s] -P[f(X)\le z] P[f(X)≤z∣S=s]−P[f(X)≤z]进行度量 -
Bounded group loss
对于每个受保护的属性S来说,预测损失都低于某一预先确定的值,即衡量的是 E [ l ( Y , f ( X ) ) ∣ S = s ] E[l(Y,f(X))|S=s] E[l(Y,f(X))∣S=s]。 -
Disparity in selection rate
与分类模型的定义相似,只不过在回归模型中,选择率是指预测值的分布。可以考虑KL散度等衡量分布差异性的指标 -
Pairwise Fairness
假设回归模型输出的分数越高越好(比如大学录取率,放贷率),那么每个组都希望自己的到更高的分数,我们要控制的就是每个组得到更高的分数的比率。- Group-dependent Pairwise Accuracy
假设有一个样本空间 X X X, 由敏感特征 S S S划分为 G i , . . . , G n G_{i}, ..., G_{n} Gi,...,Gn这 n n n个组(二值字段时, n = 2 n=2 n=2),对于一个函数 f : X → R f:\mathcal{X}\rightarrow\mathbb{R} f:X→R我们可以定义基于组的成对准确度:
A G i > G j : = P ( f ( x ) > f ( x ′ ) ∣ y > y ′ , ( x , y ) ∈ G i , ( x ′ , y ′ ) ∈ G j ) A_{G_{i}>G_{j}} := P(f(x) > f(x') | y > y',(x, y) \in G_{i},(x', y') \in G_{j} ) AGi>Gj:=P(f(x)>f(x′)∣y>y′,(x,y)∈Gi,(x′,y′)∈Gj)
这个定义考虑了单个组与单个组之间,回归模型中因变量大小关系的平均准确度。进一步,对于单个组与其他任意组的成对准确性可以定义为:
A G i > : : = P ( f ( x ) > f ( x ′ ) ∣ y > y ′ , ( x , y ) ∈ G i ) A_{G_{i}>:} := P(f(x) > f(x') | y > y',(x, y) \in G_{i}) AGi>::=P(f(x)>f(x′)∣y>y′,(x,y)∈Gi)
A : > G i : = P ( f ( x ) > f ( x ′ ) ∣ y > y ′ , ( x ′ , y ′ ) ∈ G i ) A_{:>G_{i}} := P(f(x) > f(x') | y > y',(x', y') \in G_{i}) A:>Gi:=P(f(x)>f(x′)∣y>y′,(x′,y′)∈Gi) - Pairwise Equal Opportunity
定义为 A G i > G j = κ A_{G_{i}>G_{j}} = \kappa AGi>Gj=κ, for some κ ∈ [ 0 , 1 ] \kappa \in [0, 1] κ∈[0,1], for all i , j i, j i,j (Hardt et al(2016))
二分类器的机会相等要求无论敏感特征如何positively-labeled examples能够公平地预测为positive label。而在回归模型中则是要求任意一个组被认为比任意一个其他组因变量大的概率是相等的。Narasimhan et al(2020)在文中提到,考虑到优化时的鲁棒性,可以将这一定义松弛为
- max i ≠ j A G i > G j − min i ≠ j A G i > G j ≤ τ \max_{i\neq j} A_{G_{i}>G_{j}} - \min_{i\neq j} A_{G_{i}>G_{j}}\leq\tau maxi=jAGi>Gj−mini=jAGi>Gj≤τ (要求组间的成对精确度在一定范围内)
- m a x i m i z e min i ≠ j A G i > G j maximize \min_{i\neq j} A_{G_{i}>G_{j}} maximizemini=jAGi>Gj(最小成对精确度尽可能大)
- Within-Group vs. Cross-Group Comparison
相当于是Pairwise Equal Opportunity的一个延申,考虑一个特殊的场景需要分别约束组间和组内的准确度,则有
A G i > G j = κ A_{G_{i}>G_{j}} = \kappa AGi>Gj=κ, for some κ ∈ [ 0 , 1 ] \kappa \in [0, 1] κ∈[0,1], for all i ≠ j i\neq j i=j(不同组间)
A G i > G j = κ ′ A_{G_{i}>G_{j}} = \kappa' AGi>Gj=κ′, for some κ ′ ∈ [ 0 , 1 ] \kappa' \in [0, 1] κ′∈[0,1], for all i i i(同一组内) - Marginal Equal Opportunity
上面成对等机会公平(Pairwise Equal Opportunity)的定义是一个比较细粒度的,考虑了 m 2 m^{2} m2个基于组的成对准确度,所以出于统计显着性原因和细粒度约束的考虑,Narasimhan et al(2020)提出了边际等机会的定义,约束一个组与其他所有组的平均准确度:
A G i > : = κ A_{G_{i}>:} = \kappa AGi>:=κ, for some κ ∈ [ 0 , 1 ] \kappa \in [0, 1] κ∈[0,1], for i = 1 , . . , m i = 1,.., m i=1,..,m - Regression Symmetric Equal Accuracy
如果回归问题输出的是不分高下的标签,那么我们希望输出值能够在组内尽可能的准确。此时可以定义 G i G_{i} Gi组的系统成对准确度为 A G i > : + A : > G i A_{Gi>:} + A_{:>Gi} AGi>:+A:>Gi,
- Group-dependent Pairwise Accuracy
1.4 针对回归模型、多值字段分群
- 可以考虑将1.3的成对准确度中,敏感特征 S S S划分的组数扩展到 n ( n > 2 ) n(n>2) n(n>2)组
- 在一些情况下,被保护的敏感特征 S S S是连续的或者有序的,比如收入等。此时可以对1.3中的成对精确度进行拓展:
A > : : = P ( f ( x ) > f ( x ′ ) ∣ y > y ′ , s > s ′ ) A_{>:} := P(f(x) > f(x') | y > y', s>s') A>::=P(f(x)>f(x′)∣y>y′,s>s′)
A : > : = P ( f ( x ) > f ( x ′ ) ∣ y > y ′ , s < s ′ ) A_{:>} := P(f(x) > f(x') | y > y',s
其中 s s s是 ( x , y ) (x, y) (x,y)的敏感特征值,而 s ′ s' s′是 ( x ′ , y ′ ) (x',y') (x′,y′)的敏感特征值
参考
- [1] Fairness through awareness
- [2] Equality of Opportunity in Supervised Learning
- [3] Fairness Beyond Disparate Treatment & Disparate Impact: Learning Classification without Disparate Mistreatment
- [4] Benchmarking Bias Mitigation Algorithms in Representation Learning through Fairness Metrics
- [5] Pairwise Fairness for Ranking and Regression
- [6] Azure_Machine learning fairness (preview)