Hive窗口函数
概述
窗口函数(window functions)也叫开窗函数、OLAP函数。
- 如果函数具有over子句,则它是窗口函数
- 窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过group by 子句组合的 常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的 各个行,并且可以将这些行中的某些属性添加到结果集中
实例
数据
cookie1,2021-05-10,1
cookie1,2021-05-11,5
cookie1,2021-05-12,7
cookie1,2021-05-13,3
cookie1,2021-05-14,2
cookie1,2021-05-15,4
cookie1,2021-05-16,4
cookie2,2021-05-10,2
cookie2,2021-05-11,3
cookie2,2021-05-12,5
cookie2,2021-05-13,6
cookie2,2021-05-14,3
cookie2,2021-05-15,9
cookie2,2021-05-16,7
建表语句
create table if not exists website_pv ( cookieid string, createtime string, pv int ) row format delimited fields terminated by ',';--插入数据
load data inpath '/website_pv.txt' into table website_pv;
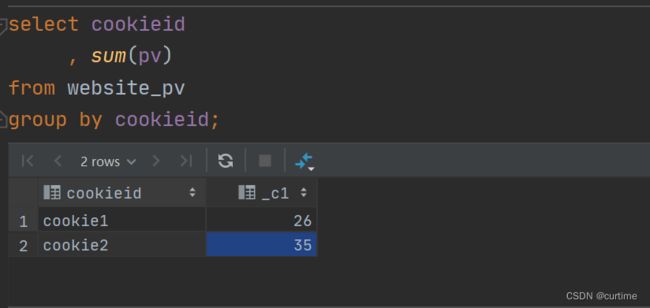
sum+group by 常规聚合操作
sum+窗口函数聚合操作

窗口表达式
在 sum(pv) over (partition by cookieid order by createtime) 语法完整的情况下,进行累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行
window expression 窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行,语法如下:
关键字是 rows between... and ... ,包括下面这几个选项
- PRECEDING:往前
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点
- UNBOUNDED PRECEDING 表示从前面的起点
- UNBOUNDED FOLLOWING:表示到后面的终点
 窗口排序函数
窗口排序函数
row_number()、rank()、dense_rank()
适用场景: 适合topN业务分析
row_number():在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;rank():在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;dense_rank():在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;

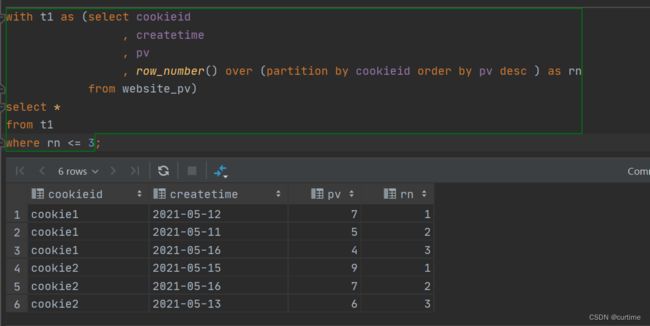
需求:找出每个用户访问pv最多的Top3重复并列的不考虑
ntile()
将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1

窗口分析函数
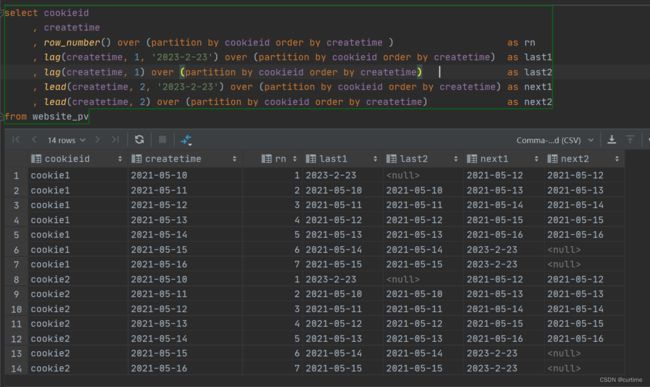
lag(col,n,default):用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为null时,取默认值,如果不指定,则为null)
lead(col,n,default):用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为null时,取默认值,如果不指定,则为null)
first_value:取分组内排序后,截止到当前行,第一个值
last_value:取分组内排序后,截止到当前行,最后一个值