处理用户输入
shell脚本编程系列
传递参数
向shell脚本传递数据的最简单方法是使用命令行参数 比如
./add 10 30
- 读取参数
bash shell会将所有的命令行参数都指派给位置参数的特殊变量。其中$0对应脚本名、$1是第一个参数、$2是第二个参数,依次类推,直到$9
#!/bin/bash
# Using one command-line parameter
#
factorial=1
for (( number = 1; number <= $1; number++ ))
do
factorial=$[ $factorial * $number ]
done
echo The factorial of $1 is $factorial
exit
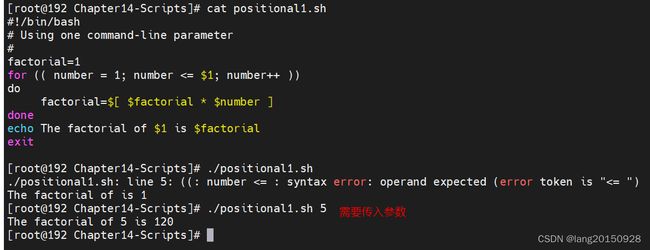
可以输入更多的命令行参数,但参数之间必须用空格分开.
命令行参数可以是数字,也可以是字符串,如果字符串包含有空格,则必须使用引号(单引号或双引号都可以).
如果命令行参数超过了9个,还是可以继续添加参数的,但是必须在变量名两侧添加花括号,比如${10}.
- 读取文件名
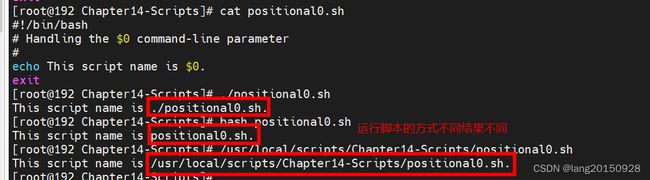
使用位置变量$0即可
这种方式受执行命令的影响
#!/bin/bash
# Handling the $0 command-line parameter
#
echo This script name is $0.
exit
使用basename命令返回不包含路径的脚本名 $(basename $0)
#!/bin/bash
# Using basename with the $0 command-line parameter
#
name=$(basename $0)
#
echo This script name is $name.
exit

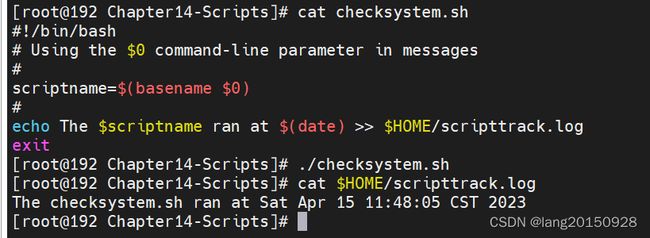
识别脚本名称并编写审计脚本
#!/bin/bash
# Using the $0 command-line parameter in messages
#
scriptname=$(basename $0)
#
echo The $scriptname ran at $(date) >> $HOME/scripttrack.log
exit
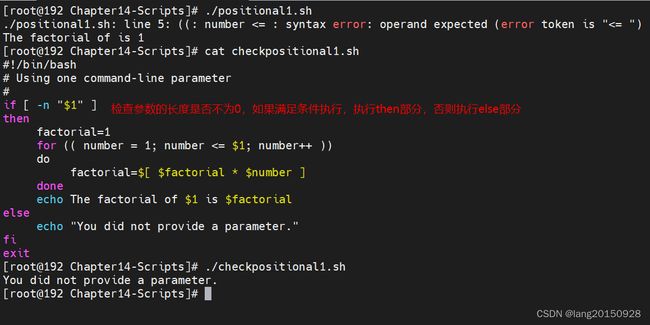
- 参数测试
使用位置变量之前一定要检查是否为空
#!/bin/bash
# Using one command-line parameter
#
if [ -n "$1" ]
then
factorial=1
for (( number = 1; number <= $1; number++ ))
do
factorial=$[ $factorial * $number ]
done
echo The factorial of $1 is $factorial
else
echo "You did not provide a parameter."
fi
跟踪参数
特殊变量$#包含脚本运行时携带的命令行参数的个数,这样对于多个命令行参数的检测工作变得简单
#!/bin/bash
# Adding command-line parameters
#
if [ $# -ne 2 ]
then
echo Usage: $(basename $0) parameter1 parameter2
else
total=$[ $1 + $2 ]
echo $1 + $2 is $total
fi
exit

虽然
$#代表命令行参数的个数,但是${$#}引用的并不是最后一个参数,${!#}才是,这个很奇怪
$*变量和$@变量可以访问所有参数,区别在于$*变量会将这些参数视为一个整体,$@会将这些参数视为多个独立的单词,以便你能遍历并处理全部单词
#!/bin/bash
# Exploring different methods for grabbing all the parameters
#
echo
echo "Using the \$* method: $*"
count=1
for param in "$*"
do
echo "\$* Parameter #$count = $param"
count=$[ $count + 1 ]
done
#
echo
echo "Using the \$@ method: $@"
count=1
for param in "$@"
do
echo "\$@ Parameter #$count = $param"
count=$[ $count + 1 ]
done
echo
exit

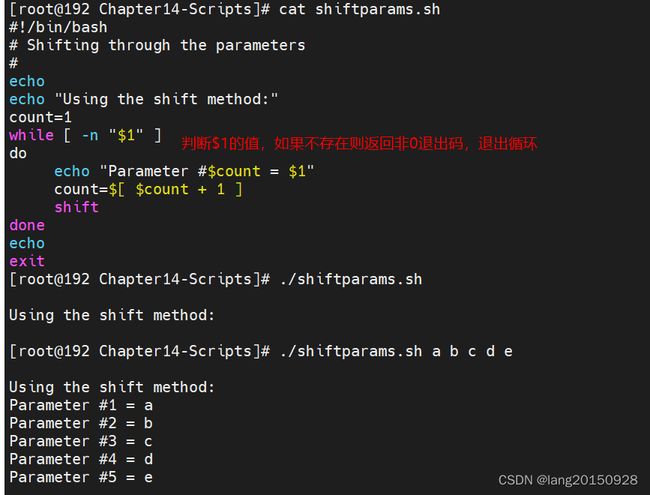
移动参数
shift命令会根据命令行参数的相对位置移动参数,使用shift命令默认情况下所有变量会向左移动一个位置。因此$3的值会移入$2,而$2的值会移入$1,$1的值则会被直接删除。$0是脚本名,不会变化
#!/bin/bash
# Shifting through the parameters
#
echo
echo "Using the shift method:"
count=1
while [ -n "$1" ]
do
echo "Parameter #$count = $1"
count=$[ $count + 1 ]
shift
done
echo
exit
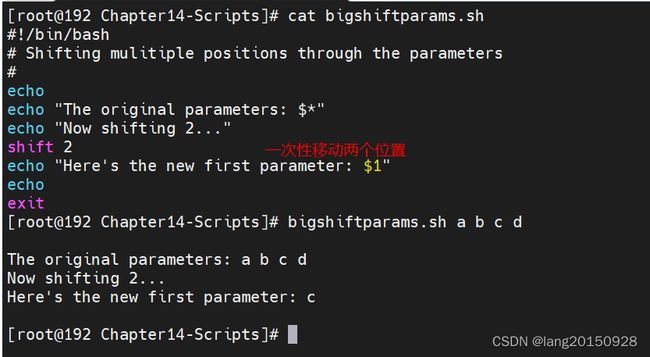
通过给shift命令传入参数可以一次性移动多个位置,比如shift 2
#!/bin/bash
# Shifting mulitiple positions through the parameters
#
echo
echo "The original parameters: $*"
echo "Now shifting 2..."
shift 2
echo "Here's the new first parameter: $1"
echo
exit
处理选项
命令行参数是在命令/脚本名之后出现的各个单词,其中,以连字符或双连字符起始的参数,因其能够改变命令的行为,被称为命令行选项。所以,命令行选项也是一种特殊形式的命令行参数。
分离命令行和参数
在同时使用选项和参数的情况下,必须要用特殊字符将参数和选项进行分离,特殊字符是双连字符(–)
#!/bin/bash
# Extract command-line options and values
#
echo
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option" ;;
-b) param=$2
echo "Found the -b option with parameter value $param"
shift;;
-c) echo "Found the -c option" ;;
--) shift
break;;
*) echo "$1 is not an option" ;;
esac
shift
done
#
echo
count=1
for param in $@
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
exit
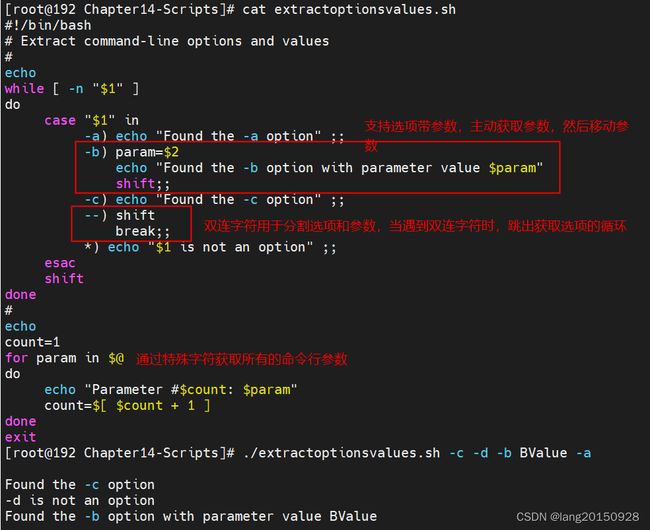
以上手工处理的方式,有很大的局限,比如不支持合并多个选项,而合并选项时一种很常见的用法

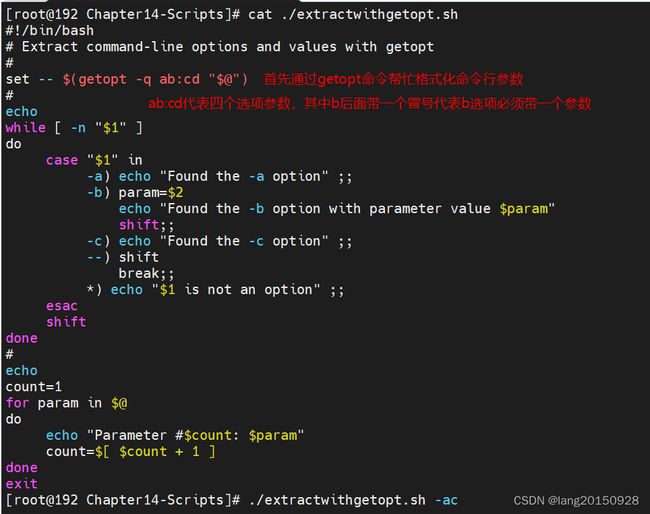
在脚本中使用getopt
格式为
getopt optstring parameters
optstring中列出要在脚本中用到的每个命令行选项字母,然后,在每个需要参数值的选项字母后面加一个冒号。
set命令有一个选项时双连字符–,可以将位置变量的值替换为set命令所指定的值。具体做法是将脚本的命令行参数传给getopt命令,然后再将getopt命令的输出传给set命令,用getopt格式化后的命令行参数来替换原始的命令行参数:
set -- $(getopt -q ab:cd "$@" )
#!/bin/bash
# Extract command-line options and values with getopt
#
set -- $(getopt -q ab:cd "$@")
#
echo
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option" ;;
-b) param=$2
echo "Found the -b option with parameter value $param"
shift;;
-c) echo "Found the -c option" ;;
--) shift
break;;
*) echo "$1 is not an option" ;;
esac
shift
done
#
echo
count=1
for param in $@
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
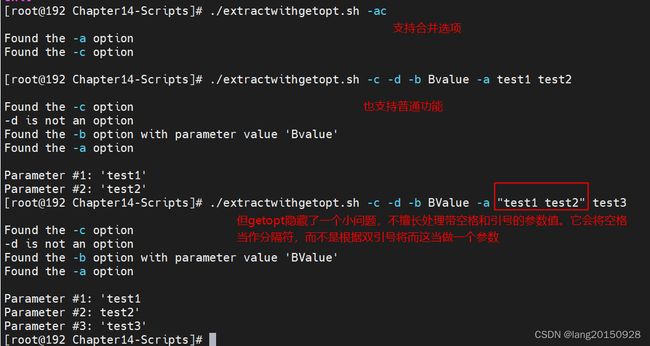
使用getopts命令
格式为
getopts optstring variable
getopts与getopt看起来很像,但多了一些扩展功能。另外,getopt在将命令行选项和参数处理后只生成一个输出,而后者能够和已有的shell位置变量配合默契。
有效的选项字母会在optstring中列出,如果选项字母要求有参数值,就在其后加一个冒号。
不想显示错误消息的话,可以在optstring之前加一个冒号。
getopts命令要用到两个环境变量,如果选项需要加带参数值,那么OPTARG环境变量保存的就是这个值。OPTIND环境变量保存着参数列表中getopts正在处理的参数位置。
getopts支持在参数中加入空格,比如 -b “Bv1 Bv2” -a。
将选项字母和参数值写在一起,两者之间也不需要加空格 比如-abBValue。
getopts命令能将所有未定义的选项统一输出成问号。

选项标准化
-a 显示所有对象
-c 生成计数
-d 指定目录
-e 扩展对象
-f 指定读入数据的文件
-h 显示命令的帮助信息
-i 忽略文本大小写
-l 产生长格式输出
-n 使用非交互模式(批处理)
-o 将所有输出重定向至指定的文件
-q 以静默模式运行
-r 递归处理目录和文件
-s 以静默模式运行
-v 生成详细输出
-x 排除某个对象
-y 对所有问题回答yes
read获取用户输入
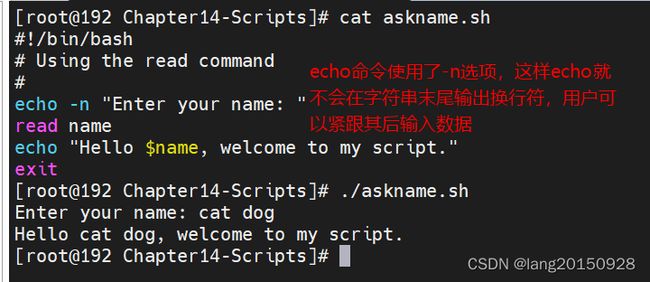
基本的读取,read命令从标准输入(键盘)或另一个文件描述符中接受输入。获取输入后,read命令会将数据存入变量
#!/bin/bash
# Using the read command
#
echo -n "Enter your name: "
read name
echo "Hello $name, welcome to my script."
exit
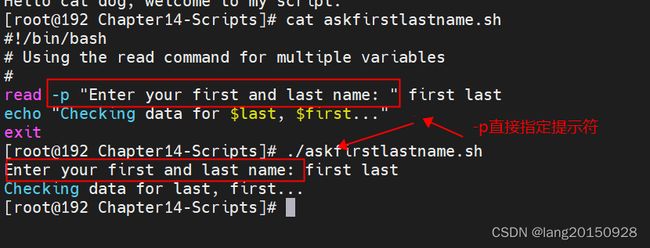
使用-p选项,允许直接指定提示符
#!/bin/bash
# Using the read command for multiple variables
#
read -p "Enter your first and last name: " first last
echo "Checking data for $last, $first..."
exit
使用-t选项指定一个计时器,如果计时器超时,则read命令会返回非0退出状态码
#!/bin/bash
# Using the read command with a timer
#
if read -t 5 -p "Enter your name: " name
then
echo "Hello $name, welcome to my script."
else
echo
echo "Sorry, no longer waiting for name."
fi
exit

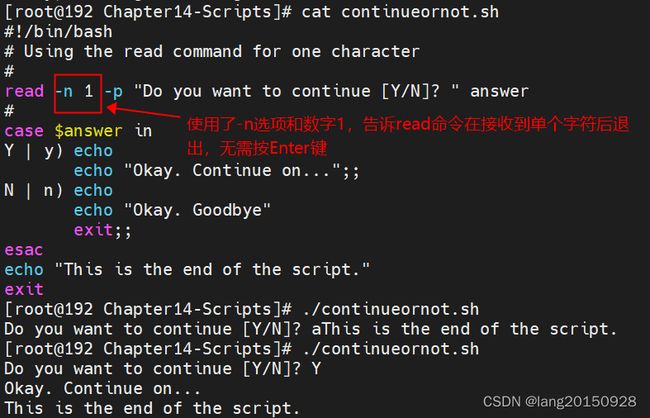
使用-n选项指定read命令读取的字符数,当字符数达到预设值时,就会自动退出,将已填入的数据赋给变量
#!/bin/bash
# Using the read command for one character
#
read -n 1 -p "Do you want to continue [Y/N]? " answer
#
case $answer in
Y | y) echo
echo "Okay. Continue on...";;
N | n) echo
echo "Okay. Goodbye"
exit;;
esac
echo "This is the end of the script."
exit
使用read命令读取文件,每次调用read命令都会从指定文件中读取一行文本。当文件中没有内容可读时,read命令会退出并返回非0退出状态码。但是将文件数据传给read命令比较麻烦,通常是对文件使用cat命令,将结果通过管道直接传给含有read命令的while命令
#!/bin/bash
# Using the read command to read a file
#
count=1
cat $HOME/scripts/test.txt | while read line
do
echo "Line $count: $line"
count=$[ $count + 1 ]
done
echo "Finished processing the file."
exit
