Python-梯度下降法实践
Python-梯度下降法实践
- 一、前言
- 二、梯度下降法
-
- 1.简介
- 2.关于线性回归梯度下降法实践
-
- 求y=x^2+2*x+5的最小值
-
- (1)通过图像观察
- (2)通过描点观察
- (3)标注点
- (4)改变步长观察
- 三、批量梯度下降算法[BGD]线性回归代码实现
-
- 1.介绍
- 2.代码实现
-
- (1)生成回归数据
- (2)拆分数据集和测试集
- (3)利用梯度下降法拟合直线y=wx+b
- (4)将迭代结果可视化查看,拟合线性回归图
- (5)计算训练集和测试集上均方误差
- 三、随机梯度下降法[SGD]
- 四、小批量梯度下降法[mini-batch梯度下降法]
一、前言
hello大家好这里是小L在这里想和大家一起学习一起进步。
这次笔记内容:学习梯度下降法python实现。以及讲解梯度下降法[GD],批量梯度下降法[BGD],随机梯度下降法[SGD],小批量梯度下降法[mini-batch梯度下降法].
二、梯度下降法

1.简介
梯度下降法用于不能用岭回归、Lasso回归求精确解(不存在逆矩阵)等情况。梯度下降法求迭代解,优化问题找到最优解。利用梯度下降法(没有逆矩阵,或者不好求的时候用)拟合直线y=wx+b,迭代算法需要赋一个初始值,n个特征有n+1个未知量。
梯度下降法最简步骤:
沿着负梯度方向不断迭代找到最优解

2.关于线性回归梯度下降法实践
当目标函数是凸函数时(目标函数对每一个变量具有一阶连续偏导数的函数),梯度下降法的解是全局最优解。一般情况下, 其解不保证是全局最优解。梯度下降法的收敛速度也未必是很快的。
而线性回归是凸函数,所以可以求得最优解。
求y=x^2+2*x+5的最小值
(1)通过图像观察
import numpy as np
import matplotlib.pyplot as plt
x=linspace(-6,4,100)
y=x**2+2*x+5
plt.plot(x,y)
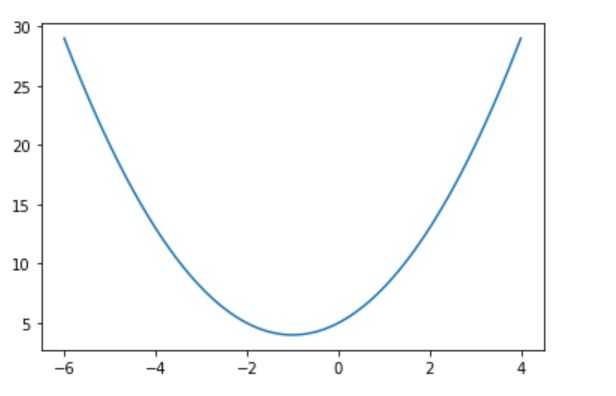
通过图像直接观察,在最小值点x为-1
#参数初始化
x_iter=3 #x的初始值
yita=0.06 #步长
y=2*x_iter+2
for i in range(0,100):
x_iter=x_inter-yita*y
print(x_iter)
-0.9999887713587551
迭代100次发现求出来的值很接近1.
(2)通过描点观察
#将迭代的点描绘出来更直观形象
x_iter=3#设置x的初始值
yita=0.06#步长
count=0#记录迭代次数
while True:
count+=1
y_last=x_iter**2+2*x_iter+5
x_iter=2*x_iter-yita*(2*x_iter+2)
y_next=x_iter**2+2*x_iter+5
plt.scatter(x_iter,y_last)
if abs(y_next-y_last)<1e-100:
break
print('最小值点x=',x_iter,'最小值y',y_next,'迭代次数n=',count)
x=linspace(-4,6,100)
y=x**2+2*x+5
plt.scatter(x,y)
最小值点x= -0.9999999594897632 最小值y= 4.000000000000002 迭代次数n= 144
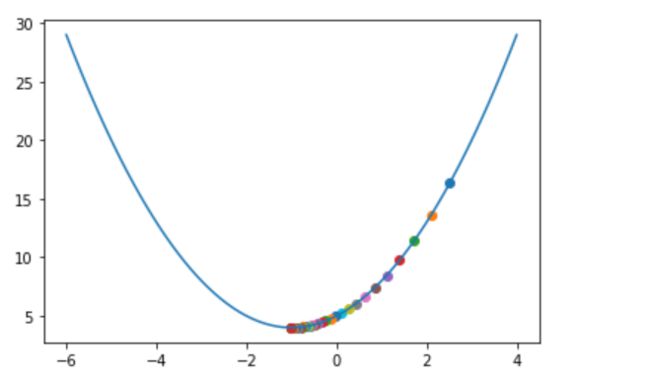
(3)标注点
#每年都考梯度下降
x_iter=3
yita=0.06 #步长
count=0 #迭代次数
while True:
count +=1
y_last =x_iter**2+x_iter*2+5
x_iter=x_iter-yita*(2*x_iter+2)
y_next=x_iter**2+x_iter*2+5
plt.scatter(x_iter,x_iter**2+x_iter*2+5)
plt.annotate(count,(x_iter,x_iter**2+x_iter*2+5))#标注各个点
if abs(y_next - y_last)<1e-100: #或者x变化不大或者y变化不大,或者导数接近0
break
print('最小值点x=',x_iter,'最小值y=',y_next,'迭代次数n=',count)
x=np.linspace(-6,4,100)
y=x**2+2*x+5
plt.plot(x,y)
最小值点x= -0.9999999594897632 最小值y= 4.000000000000002 迭代次数n= 144

(4)改变步长观察
x_iter=3
yita=0.8 #将步长增大
count=0 #迭代次数
while True:
count +=1
y_last =x_iter**2+x_iter*2+5
x_iter=x_iter-yita*(2*x_iter+2)
y_next=x_iter**2+x_iter*2+5
plt.scatter(x_iter,x_iter**2+x_iter*2+5)
if abs(y_next - y_last)<1e-100: #或者x变化不大或者y变化不大,或者导数接近0
break
print('最小值点x=',x_iter,'最小值y=',y_next,'迭代次数n=',count)
x=np.linspace(-6,4,100)
y=x**2+2*x+5
plt.plot(x,y)
最小值点x= -1.000000008911663 最小值y= 4.0 迭代次数n= 39

可以发现步长改变后,虽然点会震荡,但不会影响最终结果。
三、批量梯度下降算法[BGD]线性回归代码实现
1.介绍
批量梯度下降法(BGD)求解,一次性把所有数据放进去(求和符号),更新一次参数,很耗时,但是表现比较稳定(平稳)

2.代码实现
(1)生成回归数据
#生成回归数据
from sklearn.datasets import make_regression
X,y=make_regression(n_sample=100,n_features=1,noise=50,random_state=8)
plt.scatter(X,y)
(2)拆分数据集和测试集
#拆分数据集与测试集
#数据量特别大时,用不了网格搜索,用梯度下降法
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=8)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(1,2,1)#分布图
plt.scatter(X_train,y_train,c='g')
plt.title('训练集散点图')
plt.subplot(1,2,2)
plt.scatter(X_test,y_test,c='orange')
plt.title('测试集散点图')

(3)利用梯度下降法拟合直线y=wx+b
#利用梯度下降法(没有逆矩阵,或者不好求的时候用)拟合直线y=wx+b,迭代算法需要赋一个初始值,n个特征有n+1个未知量
#利用梯度下降法拟合直线y=wx+b
#参数初始化
w=1 #直线斜率
b=-100 #直线截距
lr=0.001 #学习率leqarning rate(步长)
#训练集70
#求和
sum_w=0
sum_b=0
for i in range(len(X_train)):
y_hat =w*X_train[i]+b
sum_w+=(y_train[i]-y_hat)*X_train[i]
sum_b+=y_train[i]-y_hat #最后乘以1
#更新w和b的值,更新一次
w+=lr*sum_w
b+=lr*sum_b
w,b
参数更新一次,输出结果为:
(array([8.47987404]), array([-92.20644646]))
增加epochs参数,调整训练次数,理论上训练次数越多,损失函数越小准确度越高
#利用梯度下降法(没有逆矩阵,或者不好求的时候用)拟合直线y=wx+b,迭代算法需要赋一个初始值,n个特征有n+1个未知量
#利用梯度下降法拟合直线y=wx+b
#参数初始化
epochs=1000#更新很多次,优化训练次数
#理论上训练次数越多,损失函数越小准确度越高
w=1#直线斜率
b=0#直线截距
lr=0.001#学习率leqarning rate(步长)
for i in range(epochs):
#训练集70
#求和
sum_w=0
sum_b=0
for i in range(len(X_train)):
y_hat=w*X_train[i]+b
sum_w=(y_train[i]-y_hat)*x_train[i]
sum_b=y_train[i]-y_hat #最后乘以1
#更新w和b的值,更新一次
w +=lr*sum_w
b +=lr*sum_b
w,b
迭代1000次,输出结果为:
(array([67.2160481]), array([4.81391939]))
可以看出训练次数不一样,参数还是有很大改变。
(4)将迭代结果可视化查看,拟合线性回归图
xx=np.linspace(-4,4,100)
yy=w*xx+b
plt.scatter(X_train,y_train,c='g')
plt.plot(xx,yy)
plt.title('线性回归拟合图')
plt.legend(('拟合直线','训练集散点图'))
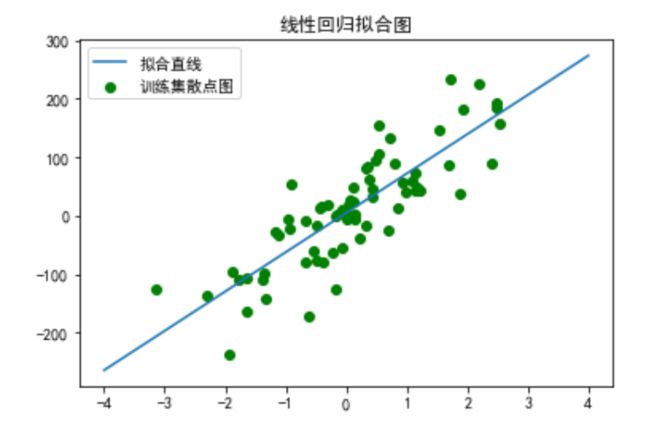
可以看出最后直线拟合效果不错,散点均匀分布在直线两端
(5)计算训练集和测试集上均方误差
#计算在训练集和测试集上的均方误差
total_loss_train=0
for i in range(len(X_train)):
y_hat=X_train[i]*w+b
total_loss_train+=(y_hat-y_train[i])**2
total_loss_test=0
for i in range(len(X_test)):
y_hat=X_test[i]*w+b
total_loss_test+=(y_hat-y_test[i])**2
print(total_loss_train/len(X_train),total_loss_train/len(X_test))
输出结果如下:
[2759.01406036] [6437.69947417]
三、随机梯度下降法[SGD]

中间没有求和号了,i是随机的,一条数据改一次,来一条数据更新一次参数,有的数据有噪声,震荡型较强,局部最优,有时候也需要需要跳出那个坑找到全局最优
四、小批量梯度下降法[mini-batch梯度下降法]
关于批量梯度下降法和随机批量梯度下降法的结合折中,少量数据一起多次的进行梯度下降算法(少量多次)