ChatGPT + X = 更多可能性
ChatGPT具有多种先进性特征,一经发布备受瞩目,作为一个由OpenAI训练的大型自然语言处理模型,可实现自然语言生成、语言翻译、自然语言理解、语言摘要等一系列功能。发布两个月后月活用户突破1亿,成为史上用户增长速度最快的消费级应用程序。
事实上,ChatGPT的推出正式标志着生成式AI商用元年的到来。生成式AI是通过机器学习方法从数据中学习内容或对象,然后根据学习得到的模型生成全新、完全原创的新内容,目前已被广泛应用于各种领域,如自然语言处理、图像生成、音频生成等。
Gartner预计到2025年,生成式AI将占所有生成数据的10%,目前这一比例还不到1%,生成式AI商用前景广阔,其商业化应用方向主要有:
面向更智能的信息检索和处理。近日,微软宣布将推出整合了ChatGPT的新版Bing搜索引擎,ChatGPT可部分替代搜素引擎功能,根据用户的提问检索已有知识库,提供更直观的回答。未来ChatGPT有望接入Office全套工具,辅助用户对信息进行总结、提取、翻译等。
面向专业领域的垂直服务。生成式AI可广泛应用于电子商务、广告营销、编写代码等专业服务领域,替代部分初级的专业工作,成为人类的助手,帮助企业节约大量的人力成本,提高生产效率。
但是ChatGPT是如何与现有技术融合呢?我们先从ChatGPT+知识图谱、ChatGPT+办公自动化为例入手来看看:
1、ChatGPT+知识图谱
事实性错误是ChatGPT当前存在的一个比较大的问题,其在回答一些问题时候,不可避免的会给人一种"一本正经的胡说八道"的感觉,其解决方式就是如何干预它的方式,引入外部知识进行处理,
一种引入外部知识的方式是在回答过程中并给出链接,虽然回答中事实性存在错误,但通过链接可以进行人工核查,以解决事实性错误问题。
而另一种引入外部知识的方式,就是知识图谱了。知识图谱,是一种基于二元关系的知识库,用以描述现实世界中的实体或概念及其相互关系,基本组成单位是【实体-关系-实体】三元组(triplet),实体之间通过关系相互联结,构成网状结构。
从根本上讲,知识图谱本质上是一种知识表示方式,其通过定义领域本体,对某一业务领域的知识结构(概念、实体属性、实体关系、事件属性、事件之间的关系)进行了精确表示,使之成为某个特定领域的知识规范表示。随后,通过实体识别、关系抽取、事件抽取等方法从各类数据源中抽取结构化数据,进行知识填充,最终以属性图或RDF格式进行存储。
实际上,早年在针对PTM(还不算LLM)的时候,就说PTM(pretrained language model)就是Knowledge base,包含了大量如Knowledge probing等任务来分析和理解,LLM(chatgpt)是参数化的知识。KG优势还是在于方便debugging,人可理解,图结构表达能力强。
但这两点是可以进行结合的,尤其是在推理(常识和领域推理)、业务系统交互、超自动化、时效性内容的接入和更新等方面,有许多结合的实例。
例如,各种图谱任务的text generation映射,KG本身往更多适合符号来做的,包括数值计算,包括规则推理等方向去做深,因为这块对于LLM来说,其实是相对薄弱,或者说学习效率太低。将知识图谱融合到ChatGPT中可以通过多种方式实现。给它足够正确的知识,再引入知识图谱这类知识管理和信息注入技术,还要限定它的数据范围和应用场景,使得它生成的内容更为可靠。
例如,我们可以将知识图谱中的实体和关系表示为嵌入向量,将其作为额外的特征融入到模型中,以提高模型的性能。这种方法可以将知识图谱的结构信息和语义信息都融合到模型中,使得模型能够更好地理解和生成自然语言文本。
在对话中,知识图谱可以帮助模型理解对话的上下文,为回答问题提供更准确的信息。在LaMDA论文中,就使用了知识图谱来提供对话的上下文信息。通过结合知识图谱的信息,可以自动生成问题,从而帮助用户更好地理解实体和关系之间的语义和上下文。
百度在日前正式发布了生成式大语言模型“文心一言”,以及其底层的“文心大模型”(Ernie 3.0)就结合了知识图谱。在文心之前,大部分LLM大模型使用纯文本数据。例如1750亿个参数的GPT-3的语料库中有570GB来自普通爬网的过滤文本。这些原始文本缺乏语言知识和世界知识等知识的明确表达。此外,大多数大型模型都是以自回归的方式进行训练的,在适应下游语言理解任务时,此类模型在传统微调的情况下表现出较差的性能。
从理论上讲,引入知识图谱,将极大增强文心在下游应用上理解问题、解决实际问题的表现。因此文心3.0使用了纯文本加上大规模知识图谱组成的4TB语料库作为训练数据,同时采用各种类型的预训练任务,使模型能够更有效地学习由有价值的词汇、句法和语义信息组成的不同层次的知识。其中预训练任务传播了三种任务范式,即自然语言理解、自然语言生成和知识提取。文心3.0在few-shot和zero-shot任务中表现出相较之前大模型的优势,使其各项指标超过了当时的SOTA模型,在Super GLUE基准测试中获得第一名。
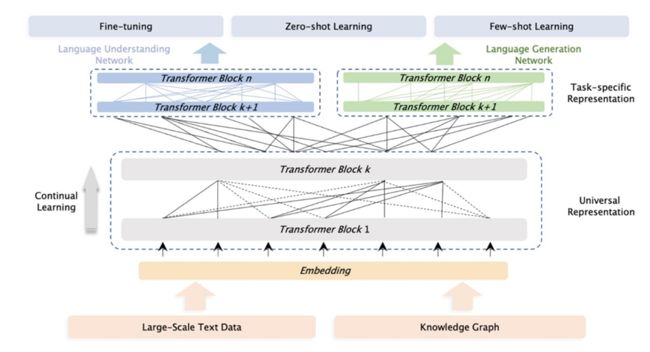
另一方面,ChatGPT在zero-shot/few-shot上面的优秀表现,实际上也可以反馈到知识图谱构建的整个流程当中,例如利用ChatGPT进行实体识别、关系抽取以及事件抽取,这可以在一定程度上缓解知识图谱在落地过程中的高成本难题。
不过,ChatGPT遇到的事实性错误和时效性问题,知识图谱同样存在。知识图谱也需要解决知识更新的问题。而且知识图谱如果不能保证非结构化数据源的正确性,到后面也注定会发生事实性错误,这无疑需要引起重视。
2、ChatGPT+办公自动化
在办公自动化场景,目前已经有多种ChatGPT结合的现象级的应用出现,例如:
ChatPDF,可以先对上传的PDF进行分析,为文件中每个段落创建语义索引。当用户提出一个问题后,工具就会把关联语段发送给ChatGPT,然后让它结合问题进行解读;
ResearchGPT,可以直接上传要看的论文PDF或者链接之后,就可以显示论文原文,右侧可以直接问它问题。
DocsGPT,这一工具简化了在项目文档中查找信息的过程。通过集成强大的GPT模型,开发人员可以轻松地提出关于项目的问题并得到准确的答案。
ChatExcel,这一新应用可以直接使用自然语言对表格中的数据信息进行查询、修改等操作,就像是一个精通Excel的助手。
不过,我们可以清晰的看到,在这些“ChatGPT+办公自动化“工具的背后,实际上有一个文档标准化和规范化处理的模块在进行支撑,有效的处理当前复杂格式的文档,如word/pdf/doc/excel等进行规范化处理,扫描版pdf等的处理,并以此作为输入。与ChatGPT进行结合,可以极大的提升其产品性能和用户体验。
好啦,今天就说到这。我们预计,业界将会紧跟ChatGPT这个技术点,结合各类相关技术和最终应用场景,探索出更多可能。