MYSQL笔记01 数据库概述,SELECT语句,运算符,排序与分页,多表查询
数据库概述
为什么要使用数据库
持久化:把数据保存在可掉电式存储设备中以供之后使用。大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以"固化",而持久化的实现过程大多通过各种关系数据库来完成。
持久化的主要作用是将内存中的数据存储在关系型数据库中,当然也可以存储在磁盘文件,XML数据文件中。

数据库与数据库管理系统
数据库的相关概念
DB:数据库(Database)
即存储数据的"仓库",其本质是一个文件系统,它保存了一系列有组织的数据
DBMS:数据库管理系统(Database Management System)
是一种操作和管理数据库的大型软件,用于建立,使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据
SQL:结构化查询语言(Structured Query Language)
专门用来与数据库通信的语言
对三者的理解
MySQL服务器中安装了MySQL DBMS,使用MySQL DBMS来管理和操作DB,使用的是SQL语言
数据库与数据库管理系统的关系
数据库管理系统可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。为保存应用中实体的数据,一般会在数据库创建多个表,以保存程序中实体用户的数据。
数据库管理系统,数据库和表的关系如图所示:

目前常见数据库管理软件有Oracle,MySQL,MS SQL Server,DB2,PostgreSQL,Access,Sybase,informix……
关系型数据库
实质
这种类型的数据库是最古老的数据库类型,关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)

关系型数据库以行(row)和列(column)的形式存储数据,以便于用户理解。这一系列的行为和列被称为表,一组表组成了一个库(database)
表与表之间的数据记录有关系,现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。关系型数据库就是建立在关系模型基础上的数据库
SQL就是关系型数据库的查询语言
关系型数据库的优势
复杂查询:可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询
事务支持:使得对于要求安全性能很高的
非关系型数据库(了解)
键值型数据库:Redis
文档型数据库:MongoDB
搜索引擎数据库:ES、Solr
列式数据库:HBase
图形数据库:InfoGrid
关系型数据库设计原则
关系型数据库的典型数据结构就是数据表,这些表的组成都是结构化的
将数据放到表中,表再放到库中
一个数据库中可以有多张表,每个表都有一个名字,用来标识自己。表名具有唯一性
表具有一些特性,这些特性定义了数据在表中如何存储,类似Java中类的设计
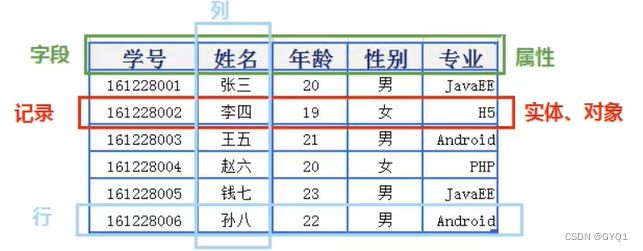
表、记录、字段
E-R(entity-relationship,实体-联系)模型中有三个主要概念是:实体集,属性,联系集
一个实体集对应于数据库中的一个表,一个实体则对应于数据库表中的一行,也称为一条记录,一个属性对应于数据库表的一列,也称为一个字段
表的关联关系
表与表之间的数据记录有关系,现实世界中的各种实体之间的各种联系均用关系模型来表示
一对一关联
在实际开发中应用不多,因为一对一可以创建成一张表
举例:
设计学生表:学号,姓名,手机号码,班级,系别,身份证号码,家庭住址,籍贯,紧急联系人
拆为两个表:基础信息表(常用信息),扩展信息表(不常见)
两种建表原则:
外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一
外键是主键:主表的主键和从表的主键,形成主外键关系
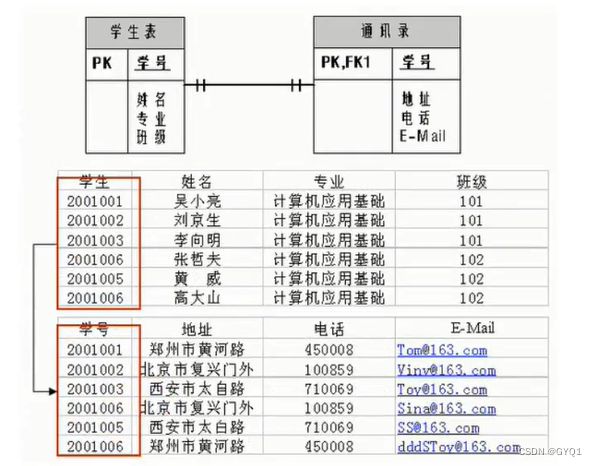
一对多关系
常见实例场景:客户表和订单表,分类表和商品表,部门表和员工表
一对多建表原则:在从表(多)创建一个字段,字段作为外键指向从表(一方)的主键

多对多关系
要表示多对多关系,必须创建第三个表,该表通常称为联接表,它将多对多关系划分为两个一对多关系,将这两个表的主键都插入第三个表中
举例:学生-课程
学生信息表:一行代表一个学生的信息(学号,姓名....)
课程信息表:一行代表一个课程的信息(课程编号,授课老师...)
选课信息表:一个学生可以选多课,一门课可以被多个学生选择
 自我引用
自我引用

SQL
SQL分类
SQL语言在功能上主要分为如下3大类:
DDL(Data Definiton Languages,数据定义语言),这些语句定义不同的数据库,表,视图,索引等数据库,还可以用来创建,删除,修改数据库和数据表的结构。
主要语句关键字包括CREATE,DROP,ALTER等
DML(Data Manipulation Language,数据操作语言),用于添加,删除,更新和查询数据库记录,并检查数据完整性。
主要语句关键字包括INSERT,DELETE,UPDATE,SELECT等
SELECT是SQL语言的基础,最为重要
DCL(Data Control Language,数据控制语言),用于定义数据库,表,字段,用户访问权限和安全级别。
主要的语句关键字包括GRANT,REVOKE,COMMIT,ROLLBACK,SAVEPOINT等
因为查询语句使用的非常的频繁,所以很多人把查询语句单独算做DQL(数据查询语言)
还有单独将COMMIT,ROLLBACK取出来称为TCL(Transaction Control Language,事务控制语言)
SQL语言规范
SQL可以写在一行或者多行,为了提供可读性,各子句分行写,必要时使用缩进
每条命令以 ; 或 \g 或 \G 结尾
关键字不能被缩写也不能分行
关于标点符号
必须保证保证所有的括号,单引号,双引号是成对结束的
必须使用英文状态下的半角输入方式
字符类型和日期时间类型的数据可以使用单引号表示
列的别名,尽量使用双引号,而且不建议省略as
MySQL在Windows环境下是大小写不敏感的
MySQL在Linux环境下是大小写敏感的
数据库名,表名,表的别名,变量名是严格区分大小写的
关键字,函数名,列(字段)名,列(字段)的别名是忽略大小写的
建议书写规范:
数据库名,表名,表的别名,字段名,字段的别名等都小写
SQL关键字,函数名,绑定变量都大写
注释
单行注释:
#xxx(MySQL特有)
-- xxx
多行注释:
/*xxx*/
基本SELECT语句
-- 查询表中所有字段
SELECT * FROM t_emp;
-- 查询表中指定字段
SELECT eid,emp_name,age,sex FROM t_emp;
-- 表中字段指定别名
SELECT eid AS id,emp_name AS ename FROM t_emp;
-- 指定别名省略写法
SELECT eid id,emp_name ename FROM t_emp;
-- 双引号指定别名(别名有空格分割的情况)
SELECT eid "emp id",emp_name "e name" FROM t_emp;
-- 去除重复行
SELECT DISTINCT emp_name FROM t_emp;
-- 多个字段时,将多个字段作为一个整体判断
SELECT DISTINCT emp_name,sex FROM t_emp;
-- 空值参与运算结果还是null(0,'','null'不属于空值)
SELECT emp_name "name",age "年龄",age+1 "明年年龄" FROM t_emp;
-- IFNULL函数,IFNULL(xxx,0)如果xxx的值为null用0替换
SELECT emp_name "name",IFNULL(age,0) "年龄",IFNULL(age,0)+1 "明年年龄" FROM t_emp;
-- 着重号:``当字段或表名等和关键字相同时使用它去区分
SELECT emp_name AS `name` FROM t_emp;
SELECT oid FROM `order`;
-- 查询常数:给结果集加一个常数字段
SELECT '常数',eid id,emp_name ename FROM t_emp;
-- 显示表结构
DESCRIBE t_emp;
DESC t_dept;
-- 过滤数据
SELECT * FROM t_emp WHERE age>18;
SELECT * FROM t_emp WHERE age>18 AND did=1;运算符
算数运算符
算法运算符主要用于数学运算,其可以连接运算符前后的两个数值或表达式,对数值或表达式进行加,减,乘,除和取模运算。


A/B:如果B为0,则结果为null;
A%B:结果的符号和A相同;
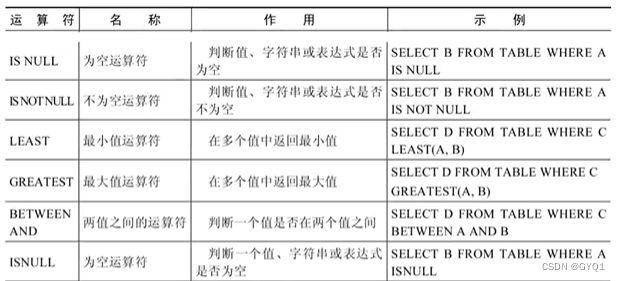
比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较结果为假则返回0,其他情况则返回NULL。
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。

等号运算符

安全等于运算符
![]()
非符号类型运算符

-- 查询姓名中包含G的员工(%代表不确定个数的任意字符)
SELECT * FROM t_emp WHERE emp_name LIKE '%g%';
-- 查询姓名中包含G和Y的员工
SELECT * FROM t_emp WHERE emp_name LIKE '%g%' AND emp_name LIKE '%y%';
-- 查询下姓名第二个字符为Y的员工( _ 代表一个任意字符)
SELECT * FROM t_emp WHERE emp_name LIKE '_y%';
-- 查询名为 _y 的员工,使用 \ 转义字符
SELECT * FROM t_emp WHERE emp_name LIKE '_\_y';REGEXP运算符

-- 查找姓名以G开头的行
SELECT * FROM t_emp WHERE emp_name REGEXP '^g';
-- 查找姓名以Q结尾的行
SELECT * FROM t_emp WHERE emp_name REGEXP 'q$';
-- 查找姓名包含Y的行
SELECT * FROM t_emp WHERE emp_name REGEXP 'y';
-- 查找姓名为G某Q的行
SELECT * FROM t_emp WHERE emp_name REGEXP 'g.q';
-- 查找姓名包含G或Y的行
SELECT * FROM t_emp WHERE emp_name REGEXP '[g,y]';逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1,0或者NULL。
MySQL中支持4种逻辑运算符如下:

注意:
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
位运算符
与或非
SELECT 12 & 5 , 12 | 5 ,12 ^ 5 FROM DUAL;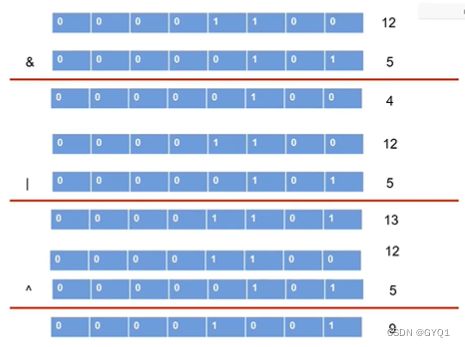
按位取反

左移右移
SELECT 8 >> 2 , 8 << 2 FROM DUAL;排序与分页
排序
使用ORDER BY子句排序
ASC:升序;DESC:降序
ORDER BY子句在SELECT语句的结尾
单列排序
-- 不使用排序操作,默认按照记录添加顺序展示
SELECT * FROM t_emp;
-- 查询员工按年龄排序,没有指定升降序(默认自然排序)
SELECT age , emp_name FROM t_emp ORDER BY age;
-- 先条件查询再排序
SELECT age , emp_name FROM t_emp
WHERE age BETWEEN 18 AND 100
ORDER BY age DESC;
多列排序
-- 先按性别,再按年龄
SELECT * FROM t_emp ORDER BY sex DESC,age ASC;分页
每页pageSize条数据,第pageNum页
LIMIT (pageNum - 1) * pageSize , pageSize;
-- 每页5条,第1页
SELECT * FROM t_emp LIMIT 5;
-- 偏移量,行数
SELECT * FROM t_emp LIMIT 0,5;
-- 每页5条,第2页
SELECT * FROM t_emp LIMIT 5,5;
-- 8.0新特性
SELECT * FROM t_emp LIMIT 5 OFFSET 5;
多表查询
也称为关联查询,指两个或更多个表一起完成查询操作。
前提条件:这些一起查询的表之间是有关系的(一对一,一对多),它们之间一定有关联字段,这个字段可能建立了外键,也可能没有建立外键。
笛卡尔积
-- 多表查询
SELECT goods_name '商品名称',shop_name '店铺名称',username '店铺拥有者' FROM goods,shop,`user`;此时查询结果条数是三张表记录数的乘积。
假如我们有两个集合X,Y。那么X和Y的笛卡尔积就是X和Y的所有可能组合。
笛卡尔积也称为交叉连接,使用CROSS JOIN表示。它的作用就是可以把任意表进行连接,即使这两张表不相关。
-- CROSS JOIN
SELECT goods_name '商品名称',shop_name '店铺名称',username '店铺拥有者'
FROM goods CROSS JOIN shop CROSS JOIN `user`;此时的多表查询缺少了多表之间的连接条件。
正确的多表查询
SELECT goods_name '商品名称',shop_name '店铺名称',username '店铺拥有者'
FROM goods, shop, `user`
WHERE goods.`shop_id`=shop.`id` AND shop.`owner_id`=user.`id`;添加表的连接条件
建议:
如果查询语句中出现多个表都存在的字段,则必须指明此字段所在的表
如果给表起了别名,一旦在SELECT或WHERE中使用表名的话,则必须使用表的别名
-- 获取商品名称为'飞跃篮球鞋'的相关信息
SELECT g.goods_name '商品名称',c.category_desc '分类',s.shop_name '店铺名称',u.username '店铺拥有者'
FROM goods g,goods_category c,shop s,`user` u
WHERE g.`goods_name`='飞跃篮球鞋' AND g.`shop_id`=s.`id` AND s.`owner_id`=u.`id` AND (g.`category_id_one`=c.`id` OR g.`category_id_two` =c.`id`);自连接
SELECT c1.`category_desc` '一级分类',c2.`category_desc` '二级分类'
FROM goods_category c1,goods_category c2
WHERE c2.`parent_id`=c1.`id`;内连接
合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行
-- 内连接(SQL92)
SELECT username,shop_name
FROM `user` u,shop s
WHERE u.`id`=s.`owner_id`;
-- 内连接(SQL99) INNER JOIN INNER可以省略
SELECT username,shop_name,goods_name
FROM `user` u JOIN shop s
ON u.`id`=s.`owner_id`
JOIN goods g
ON s.`id`=g.`shop_id`;外连接
合并具有同一列的两个以上的表的行,结果集中除了包含一个表与另一个表匹配的行之外还查询到了左表或右表中不匹配的行
外连接又分为左外连接,右外连接,满外连接
区别在于在包含匹配的行的基础上,左外连接包含左表不匹配的行,右外连接包含右表不匹配的行,满外连接包含左右两表不匹配的行
-- SQL99语法外连接
-- 左外连接 LEFT OUTER JOIN OUTER可以省略
SELECT username,shop_name
FROM `user` u LEFT JOIN shop s
ON u.`id`=s.`owner_id`;
-- 右外连接 RIGHT OUTER JOIN
SELECT username,shop_name
FROM `user` u RIGHT JOIN shop s
ON u.`id`=s.`owner_id`;
-- 满外连接(MYSQL不支持)
SELECT username,shop_name
FROM `user` u FULL OUTER JOIN shop s
ON u.`id`=s.`owner_id`;七种SQL JOINS的实现
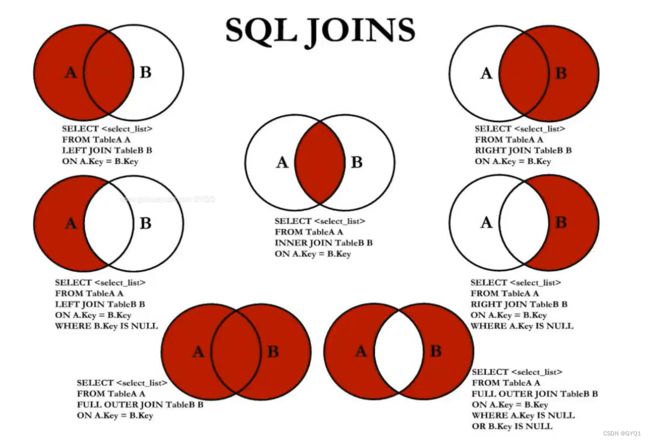
UNION
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。

-- UNION 去重
SELECT username FROM `user`
WHERE username LIKE '贵%'
UNION
SELECT username FROM `user`
WHERE id = 1;
-- UNION ALL 不去重
SELECT username FROM `user`
WHERE username LIKE '贵%'
UNION ALL
SELECT username FROM `user`
WHERE id = 1;
-- 满外连接
SELECT u.username,s.shop_name
FROM `user` u LEFT JOIN shop s
ON u.`id`=s.`owner_id`
UNION
SELECT u.username,s.shop_name
FROM `user` u RIGHT JOIN shop s
ON u.`id`=s.`owner_id`NATURAL JOIN 自然连接
SQL99在SQL92的基础上提供了一些特殊的语法,比如NATURAL JOIN用来表示自然连接。我们可以把自然连接理解为SQL92中的等值连接,他会自动查询表中所有相同的字段,然后进行等值连接。
-- 自然连接
SELECT *
FROM `user` u NATURAL JOIN shop s;USING
-- 原来的写法
SELECT *
FROM `user` u JOIN shop s
ON u.`id`=s.`id`;
-- USING 当on后面的字段相同时可以使用USING
SELECT *
FROM `user` u JOIN shop s
USING(id);表连接的约束条件可以有三种方式:WHERE,ON,USING
WHERE:适用于所有关联查询
ON:只能和JOIN一起使用,只能写关联条件,虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
USING:只能和JOIN一起使用,而且要求两个关联字段在关联表中名称一致,而且只能表示关联字段值相等
注意:我们要控制连接表的数量,多表连接就相当于嵌套for循环一样,非常消耗资源,会让SQL查询性能下降的很严重,因此不要连接不必要的表。在许多DBMS中,也会有最大连接表的限制
