Segment Anything Model代码讲解(二)之image_encoder
image_encoder代码解析
在transformer的结构中,编码是非常重要的部分。接下来看image_encoder的代码部分目录
- class ImageEncoderViT
- def init
- def forward
- class Block
- def init
- def forward
- class Attention
- def init
- def forward
- def window_partition
- def window_unpartition
- def get_rel_pos
- def add_decomposed_rel_pos
- class PatchEmbed
- def init
- def forward
transformer结构
image_encoder代码结构是按照transformer的encoder部分进行设计的。因此看transformer的结构可以了解代码的实现目标。
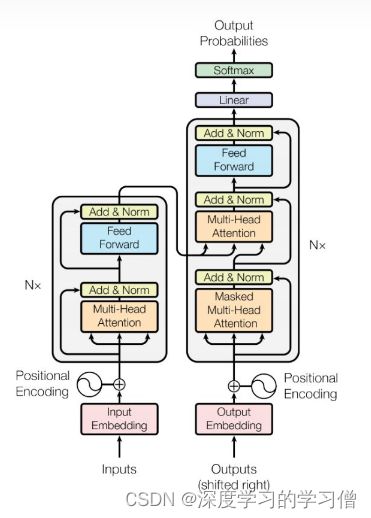
各部分代码详解
class ImageEncoderViT是对图片编码的整体处理过程,其backbone借鉴了vit的算法
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Optional, Tuple, Type
from .common import LayerNorm2d, MLPBlock
# This class and its supporting functions below lightly adapted from the ViTDet backbone available at: https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/vit.py # noqa
class ImageEncoderViT(nn.Module):
def __init__(
self,
img_size: int = 1024,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 12,
mlp_ratio: float = 4.0,
out_chans: int = 256,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_abs_pos: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
global_attn_indexes: Tuple[int, ...] = (),
) -> None:
"""
Args:
img_size (int): Input image size.
patch_size (int): Patch size.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
depth (int): Depth of ViT.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_abs_pos (bool): If True, use absolute positional embeddings.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks.
global_attn_indexes (list): Indexes for blocks using global attention.
"""
super().__init__()
self.img_size = img_size
#进行切分处理
self.patch_embed = PatchEmbed(
kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size),
in_chans=in_chans,
embed_dim=embed_dim,
)
#位置编码处理
self.pos_embed: Optional[nn.Parameter] = None
if use_abs_pos:
# Initialize absolute positional embedding with pretrain image size.
self.pos_embed = nn.Parameter(
torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim)
)
#设置blocks的深度和每层结构
self.blocks = nn.ModuleList()
for i in range(depth):
block = Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
norm_layer=norm_layer,
act_layer=act_layer,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
window_size=window_size if i not in global_attn_indexes else 0,
input_size=(img_size // patch_size, img_size // patch_size),
)
self.blocks.append(block)
#设置neck的结构Conv2d+LayerNorm2d+Conv2d
self.neck = nn.Sequential(
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
bias=False,
),
LayerNorm2d(out_chans),
nn.Conv2d(
out_chans,
out_chans,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(out_chans),
)
#对数据进行前向传播
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
if self.pos_embed is not None:
x = x + self.pos_embed
for blk in self.blocks:
x = blk(x)
x = self.neck(x.permute(0, 3, 1, 2))
return x
Block是构建image_encoder的特征提取的backbone过程。其backbone借鉴了vit的算法
class Block(nn.Module):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then
use global attention.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
#归一化
self.norm1 = norm_layer(dim)
实例化attn方法
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.norm2 = norm_layer(dim)
#多层感知机
self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
#窗口尺度
self.window_size = window_size
def forward(self, x: torch.Tensor) -> torch.Tensor:
shortcut = x
x = self.norm1(x)
# Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x)
# Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + x
x = x + self.mlp(self.norm2(x))
return x
自注意力机制
class Attention(nn.Module):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int):输入通道的数量.
num_heads (int): Number of attention heads.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos
if self.use_rel_pos:
assert (
input_size is not None
), "Input size must be provided if using relative positional encoding."
# initialize relative positional embeddings
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, _ = x.shape
# qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
# q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
attn = (q * self.scale) @ k.transpose(-2, -1)
if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = attn.softmax(dim=-1)
x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
x = self.proj(x)
return x
def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]:
"""
Partition into non-overlapping windows with padding if needed.
Args:
x (tensor): input tokens with [B, H, W, C].
window_size (int): window size.
Returns:
windows: windows after partition with [B * num_windows, window_size, window_size, C].
(Hp, Wp): padded height and width before partition
"""
B, H, W, C = x.shape
pad_h = (window_size - H % window_size) % window_size
pad_w = (window_size - W % window_size) % window_size
if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
Hp, Wp = H + pad_h, W + pad_w
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows, (Hp, Wp)
def window_unpartition(
windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int]
) -> torch.Tensor:
"""
Window unpartition into original sequences and removing padding.
Args:
windows (tensor): input tokens with [B * num_windows, window_size, window_size, C].
window_size (int): window size.
pad_hw (Tuple): padded height and width (Hp, Wp).
hw (Tuple): original height and width (H, W) before padding.
Returns:
x: unpartitioned sequences with [B, H, W, C].
"""
Hp, Wp = pad_hw
H, W = hw
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
if Hp > H or Wp > W:
x = x[:, :H, :W, :].contiguous()
return x
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
"""
Get relative positional embeddings according to the relative positions of
query and key sizes.
Args:
q_size (int): size of query q.
k_size (int): size of key k.
rel_pos (Tensor): relative position embeddings (L, C).
Returns:
Extracted positional embeddings according to relative positions.
"""
max_rel_dist = int(2 * max(q_size, k_size) - 1)
# Interpolate rel pos if needed.
if rel_pos.shape[0] != max_rel_dist:
# Interpolate rel pos.
rel_pos_resized = F.interpolate(
rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
size=max_rel_dist,
mode="linear",
)
rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
else:
rel_pos_resized = rel_pos
# Scale the coords with short length if shapes for q and k are different.
q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
return rel_pos_resized[relative_coords.long()]
def add_decomposed_rel_pos(
attn: torch.Tensor,
q: torch.Tensor,
rel_pos_h: torch.Tensor,
rel_pos_w: torch.Tensor,
q_size: Tuple[int, int],
k_size: Tuple[int, int],
) -> torch.Tensor:
"""
Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950
Args:
attn (Tensor): attention map.
q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C).
rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis.
rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis.
q_size (Tuple): spatial sequence size of query q with (q_h, q_w).
k_size (Tuple): spatial sequence size of key k with (k_h, k_w).
Returns:
attn (Tensor): attention map with added relative positional embeddings.
"""
q_h, q_w = q_size
k_h, k_w = k_size
Rh = get_rel_pos(q_h, k_h, rel_pos_h)
Rw = get_rel_pos(q_w, k_w, rel_pos_w)
B, _, dim = q.shape
r_q = q.reshape(B, q_h, q_w, dim)
rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
attn = (
attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
).view(B, q_h * q_w, k_h * k_w)
return attn
class PatchEmbed(nn.Module):
"""
Image to Patch Embedding.
"""
def __init__(
self,
kernel_size: Tuple[int, int] = (16, 16),
stride: Tuple[int, int] = (16, 16),
padding: Tuple[int, int] = (0, 0),
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
kernel_size (Tuple): kernel size of the projection layer.
stride (Tuple): stride of the projection layer.
padding (Tuple): padding size of the projection layer.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
"""
super().__init__()
self.proj = nn.Conv2d(
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.proj(x)
# B C H W -> B H W C
x = x.permute(0, 2, 3, 1)
return x