C++:内存管理:C++内存管理详解
C++语言内存管理是指:对系统的分配、创建、使用这一系列操作。在内存管理中,由于是操作系统内存,使用不当会造成很麻烦的后果。本文将从系统内存的分配、创建出发,并且结合例子来说明内存管理不当会造成的结果以及解决方案。
一:内存
在计算机中,每个应用程序之间的内存是相互独立的,通常情况下应用程序A并不能访问应用程序B,当然我们可以使用一种特殊技术,让他们可以互相访问,但这个不是本文的重点。比如在计算机中,一个视频播放程序与一个浏览器程序,他们的内存并不能访问,每个程序所拥有的内存是分区进行管理的。
在计算机系统中,运行程序A将会在内存中开启程序A的内存区域1,运行程序B将会在内存中开辟程序B的内存区域2,内存1和内存2之间逻辑分离。

1.1 内存四个区
在程序A开辟的内存区域1会被分为几个区域,这就是内存四区,内存四区分为栈区、堆区、数据区和代码区。

栈区:指的是存储一些临时变量的区域,临时变量包括了局部变量、返回值、参数、返回地址等,当这些变量超出了当前作用域时将会自动弹出。该栈的最大存储是有大小的且固定的,超过该代销将会造成栈溢出。
堆区:是一个比较大的内存空间,主要用于对动态内存的分配,在程序开发中一般是开发人员进行分配和释放,若在程序结束时都还未释放,系统将自动进行回收。
数据区:主要存放全局变量、常量、静态变量,数据区又可以划分为:全局区和静态区,全局变量和静态变量将会存放到该区域。
代码区:比较简单,主要存储可执行代码,该区域的属性是只读的。
1.2 通过代码证实内存四区的底层结构
栈区
由于栈区和堆区的底层结构比较直观的表现,我们在此使用代码只演示这两个概念来查看代码观察栈区的内存地址分配情况。
// main.cpp
#include
int main() {
int a = 0;
int b = 0;
int c = 0;
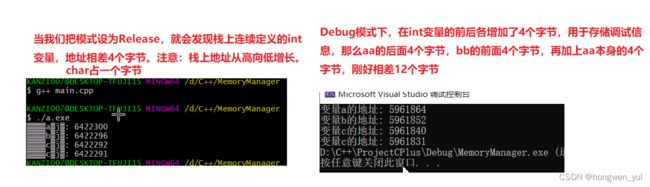
printf("变量a的地址: %d", &a);
printf("\n变量b的地址: %d", &b);
printf("\n变量c的地址: %d", &c);
// 打印结果
} 
为什么它们之间的地址不是增加而是减少呢?那是因为栈区的一种数据存储结构为先进后出,如图:
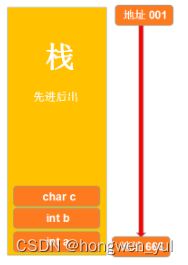
- 首先栈的顶部为地址的“最小”索引,随后往下依次增大,但是由于堆栈的特殊结果,我们将变量a先进行存储,那么它的一个索引地址将会是最大的,随后依次减少。(即 6422300)
- 第二次存储的变量时b,该值得地址索引比a小4个字节(因为int类型在32位系统中占4个字节),所以在a地址的基础上减少4个字节(即:6422296)
- 第三次存储变量c,该值得地址索引比b小4个字节(即:6422292)
- 第三次存储变量d,该值得地址索引比c小1个字节(即:6422291),因为char字符占一个字节
- 由于a、b、c、d这四个变量同属一一个栈内,所以他们地址的索引是连续性的,但是如果我们创建一个静态变量将会是怎样的了 ?
思考:在分配内存的时候,为什么 定义int 类型,内存大小相差4字节,而定义char类型内存相差1字节
要回答上面这个问题,我们首先要理解的就是:“跳跃力”。
对于一个指针 而言,如果前面规定了它的类型,那就相当于决定了它的“跳跃力”。“跳跃力”就比如说上图中 int类型跳了 4个字节,char类型跳了1字节,double类型跳了8字节。

数据区
我们定义一个全局变量和 静态变量看看效果
#include
int e = 0;
int main() {
static int f = 0;
printf("\n var e address: %d", &e);
printf("\nvar f address: %d", &f);
}
// 打印结果
var e address: 8430692
var f address: 8430696
从这个例子可以看出,数据区的地址不是栈结构,它是由低向高分配的,这里还是和栈区有点区别的。
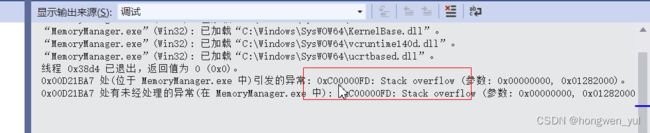
以上例子其实也说明了栈区的特性,就是容量具有固定大小,超过最大容量将会造成栈溢出
#include
int main() {
char char_arr[1024 * 1000000000];
char_arr[0] = 'a';
}
// 编译之后直接会报错
1.3 :为了解决上面这个问题(开辟大容量内存)
堆并没有栈一样的结构,也没有栈一样的先进后出。我们需要人为的对内存进行分配使用。
#include
#include
int main() {
//定义一个指针:指向一个大容量的内存地址
char* p1 = (char*)malloc(1024 * 1000);
// 把字符串"here is heap"赋值到指针 p1指向的空间中
std::string s = "here is heap";
strcpy_s(p1, 1024,s.c_str());
//打印内存空间的地址
printf("p1 storage address: %d", p1);
printf("\np1 storage: %s", p1);
}
//打印结果
p1 storage address: 19443776
p1 storage: here is heap 多说一点
char *p=new char[10];
p="hello";
delete p[];//此步释放时将报错❌这是因为:在C++中,字符串常量"hello"被保存在常量存储区,而p="hello"操作是改变了指针的指向,使得指针p指向了常量存储区的"hello",造成了初始在堆上开辟的内存泄露,而delete无法释放常量存储区的内存,导致出错。
二:malloc和free使用
在 C 语言(不是 C++)中,malloc 和 free 是系统提供的函数,成对使用,用于从堆中分配和释放内存。malloc 的全称是 memory allocation 译为“动态内存分配”。
2.1 malloc和free
在开辟堆空间时我们使用的函数为 malloc,malloc 在 C 语言中是用于申请内存空间,malloc 函数的原型如下:
void *malloc(size_t size);
- 在 malloc 函数中,size 是表示需要申请的内存空间大小,申请成功将会返回该内存空间的地址;申请失败则会返回 NULL,并且申请成功也不会自动进行初始化。
- 细心的同学可能会发现,该函数的返回值说明为 void *,在这里 void * 并不指代某一种特定的类型,而是说明该类型不确定,通过接收的指针变量从而进行类型的转换。
- 在分配内存时需要注意,即时在程序关闭时系统会自动回收该手动申请的内存 ,但也要进行手动的释放,保证内存能够在不需要时返回至堆空间,使内存能够合理的分配使用。
释放空间使用free函数原型如下:
void free(void *ptr);
free函数的返回值是void ,没有返回值,接收的参数为使用malloc分配的内存空间指针
下面看一下一个完整的堆内存申请与释放的例子:
// main.cpp
int main(){
// 下面是一个完整申请,释放内存的例子,可以参考一下。
int n, *p, i;
printf("请输入一个任意长度的数字来分配空间::");
scanf_s("%d", &n);
p = (int*)malloc(n * sizeof(int));
if (p ==NULL)
{
printf("内存申请失败");
return 0;
}
else
{
printf("内存申请成功");
}
// 使用 memset对内存空间进行填充
memset(p, 0, n * sizeof(int));
// 查看刚刚填充的内容
for (int i = 0; i < n; i++)
{
printf("\n%d", p[i]);
}
// 释放空间
free(p);
p = NULL;
return 0;
}分析上述代码可知:
- 使用malloc创建了一个由用户输入创建指定大小的内存,判断了内存地址是否创建成功,且使用 memset函数对该内存空间进行了填充,然后通过for循环来查看
- 最后使用 free()函数释放内存,并且将 p赋值为 NULL ,这一点要注意不能让指针指向未知的地址,要至于NULL(否则就是野指针)
2.2 内存泄漏与安全使用实例讲解
- 内存泄漏是指在动态分配的内存中,并没有释放内存或者一些其他原因造成了内存无法释放,轻则会造成系统内存资源浪费,严重会导致整个系统崩溃等情况的发生。
- 内存泄漏通常比较隐蔽,且少量的内存泄漏发生也不一定会有无法承受的后果,但由于该错误的积累将会造成整体系统的性能下降或系统崩溃,特别是在大型的系统中,如何有效的防止内存泄漏等问题的出现就变得尤其重要,例如一些长时间的程序,若在运行之初有少量的内存泄漏的问题产生可能并未呈现,但随着运行时间的增长、系统业务处理的增加将会累积出现内存泄漏这种情况;这时极大的会造成不可预知的后果,如整个系统的崩溃,造成的损失将会难以承受。由此防止内存泄漏对于底层开发人员来说尤为重要。
- C 程序员在开发过程中,不可避免的面对内存操作的问题,特别是频繁的申请动态内存时会及其容易造成内存泄漏事故的发生。如申请了一块内存空间后,未初始化便读其中的内容、间接申请动态内存但并没有进行释放、释放完一块动态申请的内存后继续引用该内存内容;如上所述这种问题都是出现内存泄漏的原因,往往这些原因由于过于隐蔽在测试时不一定会完全清楚,将会导致在项目上线后的长时间运行下,导致灾难性的后果发生。
// main.cpp
int main(){
char* p1;
p1 = (char *)malloc(100);
printf("内存开始被泄漏了");
return 0;
}
三:new 和delete
- C++中使用new 和delete从堆中分配和释放内存,new 和delete是运算符,不是函数,两者需要成对使用。
- new/delete 除了分配内存和释放内存 与malloc/free相比,还做了其他很多事情,所以在C++中不再使用malloc/free ,建议使用 new/delete。
3.1 new和delete使用
new 一般使用格式:
指针变量名 = new 类型标识符
指针变量名 = new 类型标识符(初始值)
指针变量名 = new类型标识符【内存单元个数】
// main.cpp
char * getMemory(unsigned long size) {
char *p = new char[size];
return p;
}
int main(){
try {
// 有可能会发生异常
char *p = getMemory(1000000);
// ...........
delete[] p;
}
catch(const std::bad_alloc &ex) {
cout << ex.what();
}
}
plain new 在分配失败的情况下,抛出异常 std::bad_alloc 而不是返回 NULL,
因此通过判断返回值是否为 NULL 是徒劳的。3.2 delete和delete[]的区别
C++中对new申请的内存的释放方式有 delete和delete[]两种方式,那么这两种方式有什么区别了 ?
- delete 释放new分配的单个对象指针指向的内存。
- delete[] 释放new分配的对象数组指针指向的内存
-
为基本数据类型分配和回收空间;
-
为自定义类型分配和回收空间;
现在我们针对基本数据类型分析 delete/delete[]
int *a = new int[10];
delete a;
delete[] a;
- 此种情况中的释放效果是相同的,原因在于:分配基本数据类型内存时,内存大小已经确定,系统可以记忆并且进行管理,在析构时,系统并不会调用析构函数。
- 它直接通过指针可以获取实际分配的内存空间,哪怕是一个数组内存空间(注意:在分配过程中系统会记录分配内存的大小信息,此信息保存在结构体 _CrtMemBlockHeader中,具体情况可以参考VC安装目录下CRTSRCDBGDEL.cpp)
针对Class类型,他们的差异体现在
class A
{
private:
char *m_cBuffer;
int m_nLen;
public:
A(){m_cBuffer = new char[m_nLen];}
~A{ delete []m_cBuffer ;}
}
A *a = new A[100];
// 仅释放了a指针指向的全部内存空间 但是只调用了a[0]对象的析构函数 剩下的从a[1]到a[9]这9个用户自行分配的m_cBuffer对应内存空间将不能释放 从而造成内存泄漏.
delete a;
//调用使用类对象的析构函数释放用户自己分配内存空间并且 释放了a指针指向的全部内存空间
delete a[]总结:
如果ptr代表一个用new 申请的内存返回的内存空间地址,即所谓的指针,那么:
delete ptr 代表用来释放内存,且只用来释放ptr指向的内存。
delete[] ptr 用来释放ptr指向内存,同时还逐一调用数组每个对象的 destructor 。
对于像 int/ char/ long/int */ struct 等简单的数据类型,由于对象没有 析构函数(destructor)所以使用 delete或者 delete[] 是一样的,但是如果是C++对象数组就不同了。
下面我们来证看一个例子:学习delete 和 delete[] 使用方法
#include
#include
class Babe
{
public:
Babe()
{
std::cout<< "Create a Babe" < 可以看到:
- 只使用delete的时候只出现了一个 Babe was desstructor ,而使用delete[] 的时候出现了10 个 Babe was desstructor,。
- 不过不管是delete 还是delete[] ,他们的对象在内存中均被删除,存储位置均标记为可写。
- 但是使用delete的时候 只调用了 pbabe[0] 的析构函数,使用delete[] 则调用了10个 Babe对象的析构函数,那么调用多少个析构函数有什么区别了 ?
析构函数特点:
- 如果没有使用操作系统的系统资源(比如:Socket、File、Thread等),不会造成明显恶果。
- 如果使用了操作系统的系统资源,如果单纯只是把类的对象从内存中删除是不妥当的,因为没有调用对象的析构函数会导致系统资源部被释放,这些资源的释放必须依靠这些类的析构函数,所以在这些类生成对象数组的时候,最好使用 delete[]来释放
未完待续:看完这篇你还能不懂C语言/C++内存管理?
把内存管理理解好,C语言真的不难学。今天带你“攻破”内存管理