MySQL:基本常识介绍、操作数据库、操作数据库中的表、操作表中的数据(增删改查)、MySQL 函数
文章目录
- Day 02:
- 一、常见的 SQL 语句
- 二、基本常识
-
- 1. 数据库的列类型
- 2. 数据库的字段属性
- 三、操作数据库
-
- 1. 操作数据库
- 2. 操作数据库中的表
-
- (1)创建表:CREAT
- (2)修改表:ALTER
- (3)删除表:DROP
- 3. 操作数据库表中的数据
-
- (1)添加数据:INSERT
- (2)修改数据:UPDATE
- (3)删除数据:DELETE
- 四、查询数据:SELECT
-
- 1. 查询字段
- 2. 查询表达式
- 3. 依据条件查询
-
- (1)逻辑运算符
- (2)模糊查询:比较运算符
- 4. 联表查询
- 5. 自连接
- 6. 分页和排序
- 7. 子查询和嵌套查询
- 8. 练习
- 9. 分组过滤
- 10. 总结
- 五、MySQL 函数
-
- 1. 常用函数
- 2. 聚合函数(常用)
- 3. 数据库级别的 MD5 加密
- 注意:
Day 02:
一、常见的 SQL 语句
1、连接数据库
mysql -u root -p
2、修改密码
ALTER USER '用户名'@'主机或 IP' IDENTIFIED BY '密码';
3、刷新权限
flush privileges;
4、查看全部的数据库
show databases;
5、选择指定的数据库
use school; -- use + 数据库名称;
6、查看选中的数据库中所有的表
show tables;
7、查看某个表
desc student; -- desc + 表名;
8、创建数据库
create database factory; -- create database + 数据库名称;
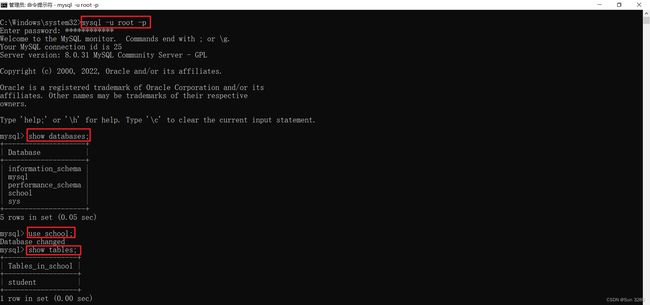
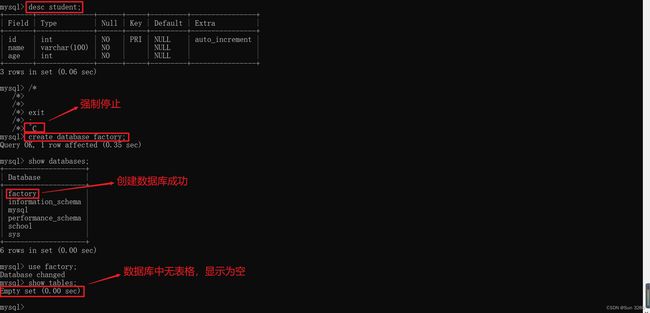
可以在 Navicat Premium 中看到操作的效果

数据库语言:
- 数据库定义语言 DDL:Data Definition Language
- 数据库操作语言 DML:Data Manipulation Language
- 数据库查询语言 DQL:Data Query Language
- 数据库控制语言 DCL:Data Control Language
二、基本常识
1. 数据库的列类型
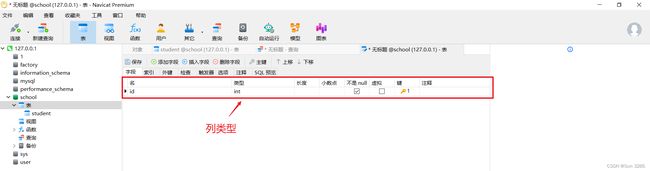
列类型分为数值类型、字符串类型、时间日期类型等。
| 数值类型 | 大小 | 备注 |
|---|---|---|
| tinyint | 1 个字节 | |
| smallint | 2 个字节 | |
| mediumint | 3 个字节 | |
| int | 4 个字节 | 标准的整数,常用 |
| bigint | 8 个字节 | |
| float | 4 个字节 | 存在精度问题 |
| double | 8 个字节 | 存在精度问题 |
| decimal | 字符串形式的浮点数,金融计算的时候一般用 |
| 字符串类型 | 大小 | 备注 |
|---|---|---|
| char | 255 | |
| varchar | 65535 | 可变字符串,常用 |
| tinytext | 2^8 - 1 | |
| text | 2^16 - 1 | 文本串,保存大文本,常用 |
| 时间日期类型 | 表示 | 备注 |
|---|---|---|
| date | yyyy-MM-dd | 日期格式 |
| time | HH:mm:ss | 时间格式 |
| datetime | yyyy-MM-dd HH:mm:ss | 常用 |
| timestamp | 时间戳,从 1970.01.01到现在的毫秒数 | 常用 |
| year | 年份格式 |
注意:
- datetime 类型中,HH 大写表示 24 小时制,hh 小写表示 12 小时制。
- 不要使用 NULL 进行运算,结果一定为 NULL。
2. 数据库的字段属性

对每个字段分别进行设置
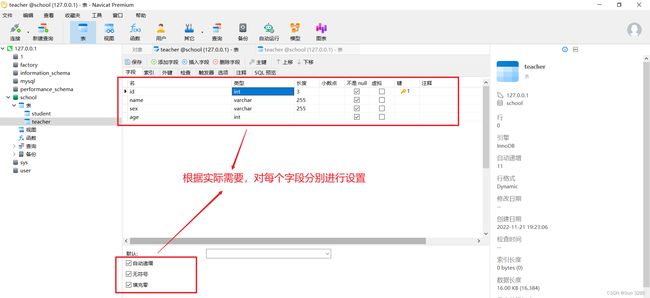
在表中填充数据
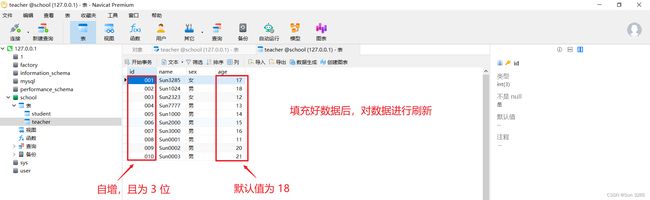
注意:规范中规定每一个表都必须存在以下五个字段。
字段 说明 id 主键 version 乐观锁 is_delete 伪删除 gmt_create 创建时间 gmt_update 修改时间
三、操作数据库
操作数据库 --> 操作数据库中的表 --> 操作数据库表中的数据
注意:sql 语言不区分大小写。
1. 操作数据库
操作数据库分为:创建数据库、删除数据库、使用数据库、查看数据库。
CREATE DATABASE IF NOT EXISTS room CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci; -- 创建数据库
DROP DATABASE IF EXISTS room; -- 删除数据库
CREATE DATABASE IF NOT EXISTS `user`;
USE `user`; -- 使用数据库
SHOW DATABASES; -- 查看数据库

注意:如果表名或者字段是一个特殊字符,就需要带 ``。
2. 操作数据库中的表
操作数据库中的表分为:创建表(增)、修改表(改)、删除表(删)。
(1)创建表:CREAT
格式:
CREATE TABLE IF NOT EXISTS `表名` (
`字段名` 列类型(长度) NOT NULL AUTO_INCREMENT COMMENT "注释",
`字段名` 列类型(长度) NOT NULL DEFAULT "默认值" COMMENT "注释",
...
`字段名` 列类型(长度) DEFAULT NULL COMMENT "注释",
PRIMARY KEY(`字段名`)
)ENGINE=INNODB DEFAULT charset=utf8mb4 -- 引擎和字符集设置
需求:创建一个名为 “person” 的表,字段有:id、登陆密码、姓名、性别、出生日期、家庭住址、邮箱。
CREATE TABLE IF NOT EXISTS `person` (
`id` INT(5) NOT NULL AUTO_INCREMENT COMMENT "学号",
`name` VARCHAR(10) NOT NULL DEFAULT "Sun3285" COMMENT "姓名",
`password` VARCHAR(10) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT "男" COMMENT "性别",
`birth` DATETIME DEFAULT NULL COMMENT "出生日期",
`address` VARCHAR(20) DEFAULT NULL COMMENT "地址",
`email` VARCHAR(12) DEFAULT NULL COMMENT "邮箱",
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT charset=utf8mb4

结果
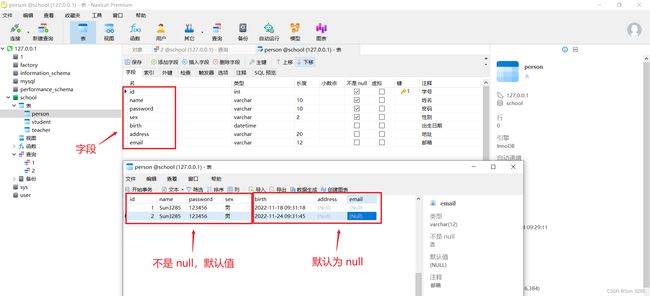
注意:
- 主键一般设置为自动递增。
- 将字段设置为 “不是 null”,则一般要设定默认值,否则,将字段设置为默认为 null。
- 创建表时注意用英文括号
(),表和字段的名称最好用 `` 括起来。- 字符串使用单引号
''或双引号""括起来。- 所有的字段语句后加英文逗号
,,最后一个不用加(如果最后一行不是设置主键的话)。- 主键是
PRIMARY KEY,一般一个表只能有一个主键。- 数据库引擎常见的有
InnoDB和MyISAM。- 所有的数据库文件都存在 data 目录下,一个文件夹就对应了一个数据库,本质还是文件的存储。
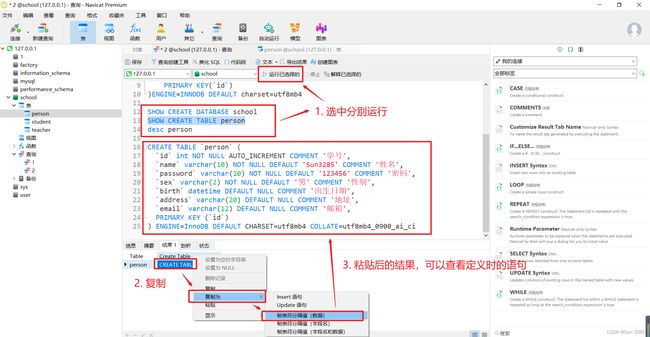
逆向操作:常用的三个命令
SHOW CREATE DATABASE `school` -- 查看创建数据库 school 的语句
SHOW CREATE TABLE `person` -- 查看表 person 的定义语句
desc `person` -- 显示表 person 的结构
注意:这三个命令在创建完表之后用,可以看到对应的 sql 语句。
(2)修改表:ALTER
格式:
ALTER TABLE `原表名` RENAME `新表名` -- 修改表名
ALTER TABLE `表名` ADD `字段` 字段属性 -- 增加表的字段
ALTER TABLE `表名` CHANGE `原字段名` `新字段名` 字段属性 -- 修改表的字段
ALTER TABLE `表名` MODIFY `字段名` 字段属性 -- 修改表的字段
ALTER TABLE `表名` DROP `字段名` -- 删除表的字段
需求:
- 修改表名
- 增加表的字段
- 修改表的字段(给字段重命名、修改字段的约束)
- 删除表的字段
ALTER TABLE `person` RENAME `person1` -- 修改表名
ALTER TABLE `person1` ADD `age` INT(3) NOT NULL DEFAULT '18' COMMENT '年龄' -- 增加表的字段
ALTER TABLE `person1` CHANGE `age` `age1` INT(5) DEFAULT null COMMENT 'age1' -- 修改表的字段
ALTER TABLE `person1` MODIFY `age1` INT(5) NOT NULL DEFAULT '20' COMMENT '年龄' -- 修改表的字段
ALTER TABLE `person1` DROP `age1` -- 删除表的字段
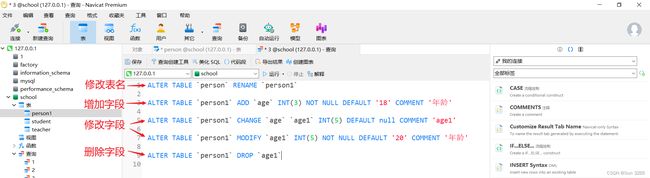
注意:
change既可以给字段重命名,并且必须同时定义字段的约束;而modify只可以修改字段的约束。
(3)删除表:DROP
格式:
DROP TABLE IF EXISTS `表名`
需求:删除表
person9。
DROP TABLE IF EXISTS `person9`
注意:所有的创建和删除操作尽量加上判断,以免报错。
3. 操作数据库表中的数据
数据库操作语言 DML:Data Manipulation Language
操作数据库表中的数据分为:添加数据(增)、修改数据(改)、删除数据(删)。
(1)添加数据:INSERT
格式:
INSERT INTO `表名` (`字段1`, `字段2`, `字段3`) VALUES ('值1', '值2', '值3'), ('值1', '值2', '值3')
需求:在表中插入数据。
INSERT INTO `example` (`address`) VALUES ('山西')
INSERT INTO `example` (`address`) VALUES ('江西')
INSERT INTO `example` (`id`, `name`, `address`) VALUES ('3', 'Sun3285', '北京')
INSERT INTO `example` VALUES ('4', 'Sun1111', '山东')
INSERT INTO `example` (`name`, `address`) VALUES ('Sun2222', '河北'), ('Sun3333', '河南'), ('Sun7777', '四川')
注意:
- 由于主键自增,在插入时可以省略主键的字段,如上面第 5 条语句。
- 如果不写表的字段,会一一匹配值,如上面第 4 条语句。
- 在写插入语句时,一定要保证字段和数据一一对应。
- 可以同时插入多条记录,插入多条记录时,每个记录之间用逗号
,隔开,如上面第 5 条语句。
(2)修改数据:UPDATE
格式:
UPDATE `表名` SET `字段1`='值1', `字段2`='值2' WHERE 约束条件
where 子句约束条件的操作符如下
| 操作符 | 说明 |
|---|---|
| <、>、=、<=、>= | 小于、大于、等于、小于等于、大于等于 |
| !=、<> | 不等于 |
| BETWEEN x AND y | 在 [x, y] 范围内,注意是闭区间 |
| AND | 与 |
| OR | 或 |
| Not | 非,如 Not a |
需求:在表中修改数据。
UPDATE `example` SET `name`='Sun1024' WHERE id = 7
UPDATE `example` SET `name`='Sun7891', `address`='安徽' WHERE id = 6 -- 修改多个属性
UPDATE `example` SET `name`='太阳1024' WHERE id >= 5
UPDATE `example` SET `name`='太阳3285' WHERE id <> 3
UPDATE `example` SET `address`='辽宁' WHERE id BETWEEN 4 AND 6
UPDATE `example` SET `address`='河北' WHERE id = 2 AND `name`='Sun3285'
UPDATE `example` SET `address`='天津' WHERE id <= 2 OR `address`='陕西'
注意:
- 修改多个字段时,用逗号隔开。
- 一般在修改字段时,应该带条件
where,否则会修改所有的记录。- 修改数据时,值可以是一个具体的值,也可以是一个变量(一般只有时间会用)。

(3)删除数据:DELETE
格式:
DELETE FROM `表名` WHERE 约束条件 -- 删除符合条件的数据
TRUNCATE `表名` -- 删除表中的所有数据(截断表)
需求:删除表中的数据。
DELETE FROM `example` WHERE `id` = 6 -- 删除符合条件的数据
INSERT INTO `example2` (`name`) VALUES ('123'), ('456'), ('789')
TRUNCATE `example2` -- 截断表
DELETE FROM `example2` -- 清空表
注意:
删除表中的所有数据用
TRUNCATE命令,作用是完全清空一个数据库表的数据,表的结构和索引约束不会变。不加约束条件的
DELETE命令也可以清空一个数据库表的数据,同样表的结构和索引约束不会变,但不同点是TRUNCATE命令会重新设置自增列,此时计数器归零,不会影响事务,而DELETE命令不会使计数器归零,在表中再添加数据时,自增列会在之前基础上自增。删除表、清空表、截断表三者的区别如下。

四、查询数据:SELECT
数据库查询语言 DQL:Data Query Language
DQL 是数据库最核心的语言,是最重要的语句,也是使用频率最高的语句。
创建一个数据库 school1,在数据库中创建四个表(学生表 student、年级表 grade、科目表 subject、成绩表 result)并插入数据。
-- 创建一个 school1 数据库
create database if not exists `school1`;
use `school1`;
-- 创建学生表
drop table if exists `student`;
create table `student`(
`studentno` int(4) not null comment '学号',
`loginpwd` varchar(20) default null,
`studentname` varchar(20) default null comment '学生姓名',
`sex` tinyint(1) default null comment '性别,0或1',
`gradeid` int(11) default null comment '年级编号',
`phone` varchar(50) not null comment '联系电话',
`address` varchar(255) not null comment '地址',
`borndate` datetime default null comment '出生时间',
`email` varchar (50) not null comment '邮箱账号',
`identitycard` varchar(18) default null comment '身份证号',
primary key (`studentno`),
unique key `identitycard`(`identitycard`),
key `email` (`email`)
)engine=myisam default charset = utf8mb4;
-- 创建年级表
drop table if exists `grade`;
create table `grade`(
`gradeid` int(11) not null auto_increment comment '年级编号',
`gradename` varchar(50) not null comment '年级名称',
primary key (`gradeid`)
)engine=innodb auto_increment = 6 default charset = utf8mb4;
-- 创建科目表
drop table if exists `subject`;
create table `subject`(
`subjectno` int(11) not null auto_increment comment '课程编号',
`subjectname` varchar(50) default null comment '课程名称',
`classhour` int(4) default null comment '学时',
`gradeid` int(4) default null comment '年级编号',
primary key (`subjectno`)
)engine = innodb auto_increment = 19 default charset = utf8mb4;
-- 创建成绩表
drop table if exists `result`;
create table `result`(
`studentno` int(4) not null comment '学号',
`subjectno` int(4) not null comment '课程编号',
`examdate` datetime not null comment '考试日期',
`studentresult` int(4) not null comment '考试成绩',
key `subjectno` (`subjectno`)
)engine = innodb default charset = utf8mb4;
-- 插入学生数据
insert into `student` (`studentno`, `loginpwd`, `studentname`, `sex`, `gradeid`, `phone`, `address`, `borndate`, `email`, `identitycard`) values
(1000, '123456', '张伟', 0, 2, '13800001234', '北京朝阳', '1980-1-1', '[email protected]', '123456198001011234'),
(1001, '123456', '赵强', 1, 3, '12341259422', '广东深圳', '1997-3-2', '[email protected]', '123999199703024894'),
(1002, '123456', '王五', 0, 1, '14725896541', '山西太原', '1991-10-19', '[email protected]', '654456199110191233'),
(1003, '123456', '刘昊', 1, 5, '12332459874', '山东济南', '2001-11-26', '[email protected]', '245856200111261233'),
(1004, '123456', '孙旺', 1, 4, '16985257453', '江西南昌', '1995-6-2', '[email protected]', '339682199506021233'),
(1005, '123456', '赵小明', 1, 2, '13800001234', '山东烟台', '1982-1-1', '[email protected]', '123456198201011234'),
(1006, '123456', '王小强', 1, 2, '13800001234', '辽宁沈阳', '1998-8-1', '[email protected]', '123456199808011234'),
(1007, '123456', '赵皓空', 0, 5, '13800001234', '安徽合肥', '1997-7-2', '[email protected]', '123456199707021264');
-- 插入年级数据
insert into `grade` (`gradeid`, `gradename`) values
(1, '大一'),
(2, '大二'),
(3, '大三'),
(4, '大四'),
(5, '预科班');
-- 插入科目数据
insert into `subject` (`subjectno`, `subjectname`, `classhour`, `gradeid`) values
(1, '高等数学-1', 110, 1),
(2, '高等数学-2', 110, 2),
(3, '高等数学-3', 100, 3),
(4, '高等数学-4', 130, 4),
(5, 'C语言-1', 110, 1),
(6, 'C语言-2', 110, 2),
(7, 'C语言-3', 100, 3),
(8, 'C语言-4', 130, 4),
(9, 'Java程序设计-1', 110, 1),
(10, 'Java程序设计-2', 110, 2),
(11, 'Java程序设计-3', 100, 3),
(12, 'Java程序设计-4', 130, 4),
(13, '数据库结构-1', 110, 1),
(14, '数据库结构-2', 110, 2),
(15, '数据库结构-3', 100, 3),
(16, '数据库结构-4', 130, 4),
(17, 'C#基础', 130, 1);
-- 插入成绩数据
insert into `result` (`studentno`, `subjectno`, `examdate`, `studentresult`) values
(1000, 1, '2013-11-11 16:00:00', 85),
(1000, 2, '2013-11-12 16:00:00', 70),
(1000, 3, '2013-11-11 09:00:00', 68),
(1000, 4, '2013-11-13 16:00:00', 98),
(1000, 5, '2013-11-14 16:00:00', 58),
(1001, 1, '2013-11-11 16:00:00', 99),
(1001, 2, '2013-11-12 16:00:00', 90),
(1001, 3, '2013-11-11 09:00:00', 91),
(1001, 4, '2013-11-13 16:00:00', 95),
(1001, 5, '2013-11-14 16:00:00', 97),
(1002, 1, '2013-11-11 16:00:00', 82),
(1002, 2, '2013-11-12 16:00:00', 95),
(1002, 3, '2013-11-11 09:00:00', 99),
(1002, 4, '2013-11-13 16:00:00', 100),
(1002, 5, '2013-11-14 16:00:00', 96);
1. 查询字段
格式:
SELECT `字段1`, `字段2`, `字段3` FROM `表名`;
需求:
- 查询全部的学生信息;
- 查询指定字段的学生信息;
- 给查询到的结果起别名(字段、表);
- 给查询到的结果用函数进行操作;
- 去重复数据。
SELECT * FROM `student`; -- 查询全部的学生信息
SELECT `studentname`, `address`, `email` FROM `student`; -- 查询指定字段的学生信息
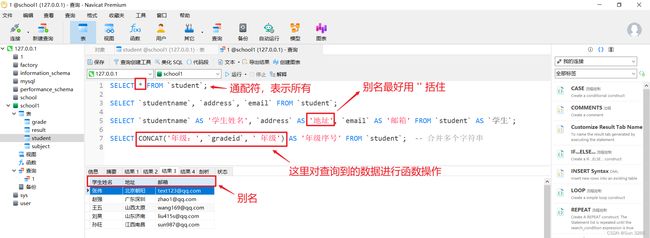
SELECT `studentname` AS '学生姓名', `address` AS '地址', `email` AS '邮箱' FROM `student` AS `学生`; -- 起别名
SELECT CONCAT('年级:', `gradeid`, ' 年级') AS '年级序号' FROM `student`; -- 给查询到的结果合并多个字符串
SELECT DISTINCT `studentno` AS '学号' FROM `result`;
注意:
*是通配符,表示全部。- 起别名用关键字
AS,也可以省略不写,中文别名最好用''括住,英文别名可以不用括住。- 函数是对查询到的数据进行操作,如
CONCAT函数表示合并多个字符串。- 去重复用关键字
DISTINCT。
2. 查询表达式
格式:
SELECT 表达式;
这里的表达式可以为:文本值、列(字段)、Null、函数、计算表达式、系统变量等等。
需求:
- 查询系统版本;
- 用来计算;
- 查询自增的步长;
- 学生成绩乘以 1.25。
SELECT VERSION() AS '版本'; -- 查询系统版本(函数)
SELECT 2*300 + 23 AS '计算结果'; -- 用来计算(表达式)
SELECT @@auto_increment_increment AS '自增的步长'; -- 查询自增的步长(变量)
SELECT `studentno` AS '学号', `studentresult` * 1.25 AS '成绩' FROM `result`; -- 成绩乘以 1.25

3. 依据条件查询
加入 where 子句约束条件,格式:
SELECT `字段1`, `字段2`, `字段3` FROM `表名` WHERE 约束条件;
依据约束条件的不同分为逻辑运算符和比较运算符,返回的结果都是布尔值。
(1)逻辑运算符
逻辑运算符:与 AND、或 OR、非 NOT。
需求:
- 查询考试成绩在 80 - 90 分之间的数据;
- 查询学号在 1000 号以外的学生成绩。
-- 查询考试成绩在 80 - 90 分之间的数据
SELECT `studentno` AS '学号', `studentresult` AS '考试成绩' FROM `result`
WHERE `studentresult` >= 80 AND `studentresult` <= 90;
SELECT `studentno` AS '学号', `studentresult` AS '考试成绩' FROM `result`
WHERE `studentresult` BETWEEN 80 AND 90;
-- 查询学号在 1000 号以外的学生成绩
SELECT `studentno` AS '学号', `studentresult` AS '考试成绩' FROM `result`
WHERE `studentno` != 1000;
SELECT `studentno` AS '学号', `studentresult` AS '考试成绩' FROM `result`
WHERE `studentno` <> 1000;
SELECT `studentno` AS '学号', `studentresult` AS '考试成绩' FROM `result`
WHERE NOT `studentno` = 1000;

注意:
where子句约束条件中判断等于是=,而不是==。
(2)模糊查询:比较运算符
比较运算符:除了小于、大于、等于、小于等于、大于等于、不等于,常见的还有以下几种。
| 操作符 | 说明 |
|---|---|
| BETWEEN x AND y | 在 [x, y] 范围内,注意是闭区间 |
| LIKE | 匹配,和 %(代表 0 到任意个字符)以及 _(代表一个字符)连用 |
| IN | 如果是其中某一个值,结果为 true |
| IS NULL | 判断操作符是否是 NULL |
| IS NOT NULL | 判断操作符是否不是 NULL |
需求:表的信息如图所示

- 查询姓赵的同学;
- 查询姓赵的同学,且姓后只有一个字;
- 查询姓赵的同学,且姓后有两个字;
- 查询名字中有“小”字的同学;
- 查询学号为 1002、1005、1007 的学生信息;
- 查询在山东的学生;
- 查询邮箱不为 NULL 的同学。
-- 查询姓赵的同学
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `studentname` LIKE '赵%';
-- 查询姓赵的同学,且姓后只有一个字
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `studentname` LIKE '赵_';
-- 查询姓赵的同学,且姓后有两个字
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `studentname` LIKE '赵__';
-- 查询名字中有“小”字的同学
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `studentname` LIKE '%小%';
-- 查询学号为 1002、1005、1007 的学生信息
SELECT * FROM `student`
WHERE `studentno` in (1002, 1005, 1007);
SELECT * FROM `student`
WHERE `studentno` = 1002 OR `studentno` = 1005 OR `studentno` = 1007;
-- 查询在山东的学生
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `address` LIKE '山东%';
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `address` IN ('山东济南', '山东烟台', '山东淄博', '山东济宁', '山东泰安');
-- 查询邮箱不为 NULL 的同学
SELECT `studentno` AS '学号', `studentname` AS '学生姓名', `address` AS '地址' FROM `student`
WHERE `email` IS NOT NULL;
注意:
- 通配符
%和_是在 LIKE 中使用,IN 中是具体的一个或多个值。- 若比较完全相等用
=;若只是匹配用LIKE。
4. 联表查询
格式:
SELECT `字段1`, `字段2`, `字段3`, `字段4`, `字段5`
FROM `左表` AS 左表别名
INNER(LEFT/RIGHT) JOIN `右表` AS 右表别名
ON 左表.`交叉字段` = 右表.`交叉字段`
WHERE 约束条件;
思路:
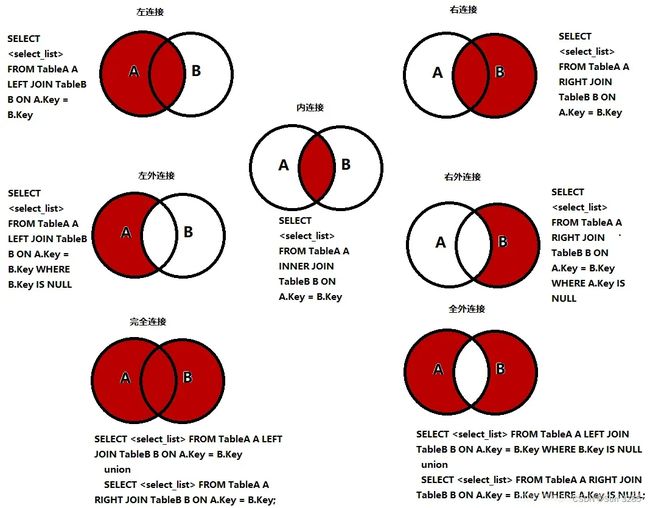
- 分析需求,分析查询的字段来源于哪些表;
- 确定使用哪种连接查询,七种 JOIN 如下图所示;
- 确定交叉点,即两个表中的哪个数据是相同的。
| 连接查询 | 说明 |
|---|---|
| INNER JOIN | 取交叉点的交集,并合并两者相交的数据 |
| LEFT JOIN | 以左表为基准,与右表建立连接,对左表进行扩展 |
| RIGHT JOIN | 以右表为基准,与左表建立连接,对右表进行扩展 |
需求:查询参加了考试的同学的信息,包括学号、姓名、科目编号、成绩、邮箱。
-- 内连接
SELECT s.`studentno`, `studentname`, `subjectno`, `studentresult`, `email`
FROM `student` AS s
INNER JOIN `result` AS r
ON s.`studentno` = r.`studentno`;
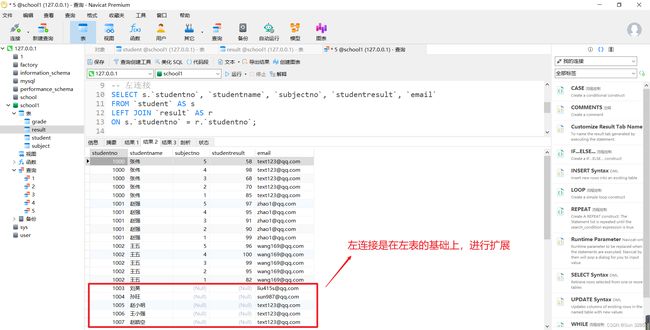
-- 左连接
SELECT s.`studentno`, `studentname`, `subjectno`, `studentresult`, `email`
FROM `student` AS s
LEFT JOIN `result` AS r
ON s.`studentno` = r.`studentno`;
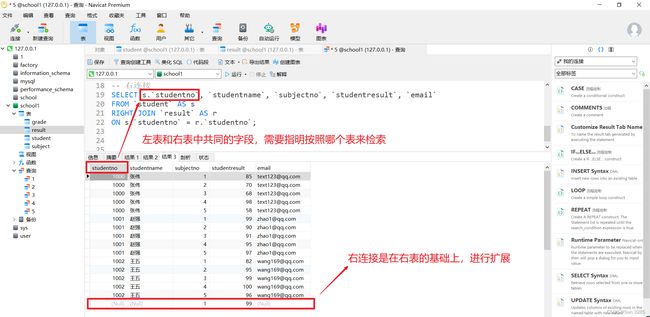
-- 右连接
SELECT s.`studentno`, `studentname`, `subjectno`, `studentresult`, `email`
FROM `student` AS s
RIGHT JOIN `result` AS r
ON s.`studentno` = r.`studentno`;
注意:
这里的
ON是在建立连接,WHERE是对结果进行筛选。两个表中共同的字段,需要指明按照哪个表来检索,如:
s.studentno。内连接时,只保留满足
ON条件的数据,然后剔除不匹配的数据。联表查询的过程为,先根据
ON联表,然后再选择相应的字段。联表查询可以先用通配符
*看到联表后的全部字段,然后再选择所需的字段。

拓展需求(三表查询):查询参加了考试的同学的信息,包括学号、姓名、科目编号、科目名、成绩。
-- 拓展需求:查询参加了考试的同学的信息,包括学号、姓名、科目编号、科目名、成绩。
SELECT s.`studentno`, `studentname`, sub.`subjectno`, `subjectname`, `studentresult`
FROM `student` AS s
INNER JOIN `result` AS r
ON s.`studentno` = r.`studentno`
INNER JOIN `subject` AS sub
ON r.`subjectno` = sub.`subjectno`;

总结:假设存在多表查询,慢慢来,先查询两张表,然后再逐个增加。
5. 自连接
自己的表和自己的表连接,核心是:一张表拆为两张一样的表。

由上面的表可以看出,“数学”、“通信”、“政治”和“计算机基础”的 pid 为 1,是父类,而其他分别属于这四类的子类。
需求:查询父类对应的子类关系。
SELECT a.`subjectname` AS '父类', b.`subjectname` AS '子类'
FROM `subject1` AS a, `subject1` AS b
WHERE a.`order` = b.`pid`;

6. 分页和排序
格式:
ORDER BY `字段` DESC; -- 根据字段降序排序(从大到小)
ORDER BY `字段` ASC; -- 根据字段升序排序(从小到大)
LIMIT a, b -- 从第 a 条数据开始(起始值),一页显示 b 条数据(页面大小)
注意:
- 排序必须在分页上面,分页必须在最后一行。
- 降序为
DESC,升序为ASC。- 分页时第一条数据的起始值为 0。
- 第 n 页的起始值为:
a = (n-1) * b。
需求:查询参加了考试的同学的信息,包括学号、姓名、科目编号、科目名、成绩,对结果进行降序排序,并分页。
-- 查询参加了考试的同学的信息,包括学号、姓名、科目编号、科目名、成绩,对结果进行降序排序,并分页
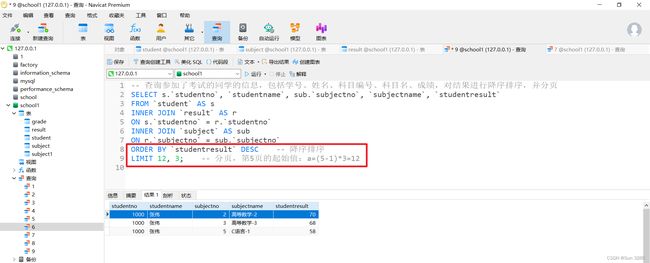
SELECT s.`studentno`, `studentname`, sub.`subjectno`, `subjectname`, `studentresult`
FROM `student` AS s
INNER JOIN `result` AS r
ON s.`studentno` = r.`studentno`
INNER JOIN `subject` AS sub
ON r.`subjectno` = sub.`subjectno`
ORDER BY `studentresult` DESC -- 降序排序
LIMIT 12, 3; -- 分页,第5页的起始值:a=(5-1)*3=12
7. 子查询和嵌套查询
子查询:在 WHERE 子句中加入查询语句。
需求:查询课程为“高等数学-2”且分数不小于87的同学信息,包括学号,姓名,要求:
- 使用联表查询;
- 使用子查询。
-- 查询课程为“高等数学-2”且分数不小于87的同学信息,包括学号,姓名
-- 方式一:联表查询
SELECT s.`studentno`, `studentname`
FROM `student` AS s
LEFT JOIN `result` AS r
ON s.`studentno` = r.`studentno`
LEFT JOIN `subject` AS sub
ON r.`subjectno` = sub.`subjectno`
WHERE `subjectname` = '高等数学-2' AND `studentresult` >= 87;
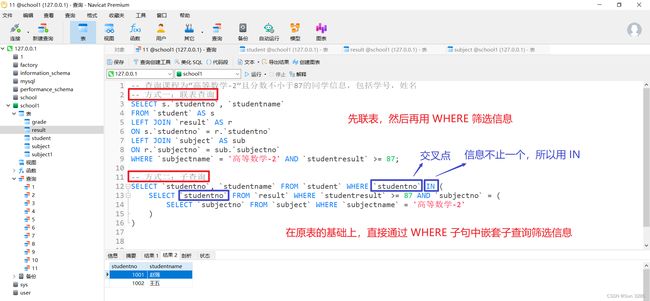
-- 方式二:子查询
SELECT `studentno`, `studentname` FROM `student` WHERE `studentno` IN (
SELECT `studentno` FROM `result` WHERE `studentresult` >= 87 AND `subjectno` = (
SELECT `subjectno` FROM `subject` WHERE `subjectname` = '高等数学-2'
)
)
注意:
子查询执行的过程:由里及外。
用子查询时,查询的字段只能为原表中有的,如:
studentno、studentname都是student中的字段。联表查询是联完表再查,而子查询是根据条件来筛选原表中的信息。
8. 练习
练习:查询年级为大一、课程为“C语言-1”且分数不小于95分的同学信息,包括学号,姓名。
- 联表查询;
- 子查询。
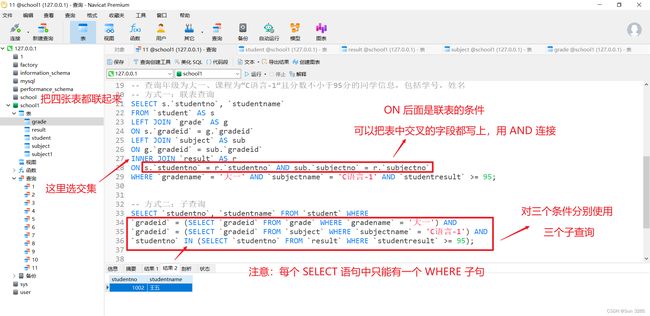
-- 查询年级为大一、课程为“C语言-1”且分数不小于95分的同学信息,包括学号,姓名。
-- 方式一:联表查询
SELECT s.`studentno`, `studentname`
FROM `student` AS s
LEFT JOIN `grade` AS g
ON s.`gradeid` = g.`gradeid`
LEFT JOIN `subject` AS sub
ON g.`gradeid` = sub.`gradeid`
INNER JOIN `result` AS r
ON s.`studentno` = r.`studentno` AND sub.`subjectno` = r.`subjectno`
WHERE `gradename` = '大一' AND `subjectname` = 'C语言-1' AND `studentresult` >= 95;
-- 方式二:子查询
SELECT `studentno` AS '学号', `studentname` AS '姓名' FROM `student` WHERE `gradeid` = (
SELECT `gradeid` FROM `grade` WHERE `gradename` = '大一'
) AND `studentno` IN (
SELECT `studentno` FROM `result` WHERE `studentresult` >= 95 AND `subjectno` = (
SELECT `subjectno` FROM `subject` WHERE `subjectname` = 'C语言-1'
)
);
总结:
- 联表查询中,
ON后面是联表的条件,最好把表中交叉的字段都写上,用AND连接。 - 在联表查询中,先联两个表,观察结果,然后再依次联第三个、第四个、第五个等等,灵活使用内连接、左连接。
- 子查询中可以对每一个条件都使用一个子查询。
- 每个
SELECT语句中只能有一个WHERE子句。 - 判断是否相等(一对一)用
=,判断是否属于某个范围内的一个值(一对多)用IN。
9. 分组过滤
格式:
GROUP BY 字段 -- 通过什么字段来分组
HAVING 条件 -- 对分组后的结果进行过滤
需求:查询不同课程的平均分、最高分以及最低分,且最低分大于 80 分。
-- 查询不同课程的平均分、最高分以及最低分,且最低分大于 80 分
SELECT `subjectname` AS '科目', AVG(`studentresult`) AS '平均分',
MAX(`studentresult`) AS '最高分', MIN(`studentresult`) AS '最低分'
FROM `result` AS r
INNER JOIN `subject` AS sub
ON r.`subjectno` = sub.`subjectno`
GROUP BY sub.`subjectname` -- GROUP BY r.`subjectno`
HAVING 最低分 > 80;

10. 总结
SELECT 完整语法:
SELECT DISTINCT `字段1`, `字段2`, 函数(`字段3`), 函数(`字段4`)
FROM `表1` AS '别名' -- 表和字段都可以取别名
INNER/LEFT/RIGHT JOIN `表2` AS '别名' -- 联表查询
ON 表1.`交叉字段` = 表2.`交叉字段`
WHERE 约束条件 -- 约束条件中可以为逻辑运算符、模糊查询或子查询
GROUP BY `字段` -- 通过什么字段来分组
HAVING 条件 -- 对分组后的结果进行过滤,条件和 WHERE 一样,只是位置不同
ORDER BY `字段` DESC/ASC; -- 根据字段降序或升序排序
LIMIT a, b -- 从第 a 条数据开始(起始值),一页显示 b 条数据(页面大小)
特别注意:顺序很重要,不能乱。
五、MySQL 函数
MySQL 8.0 参考手册中函数和运算符官网:点此进入。
1. 常用函数
数学运算
SELECT ABS(-10); -- 绝对值
SELECT CEIL(1.01); -- 向上取整
SELECT FLOOR(1.98); -- 向下取整
SELECT RAND(); -- 0-1 的随机数
SELECT SIGN(2); -- 判断一个数的符号:正数 -> 1、负数 -> -1、0 -> 0
字符串函数
SELECT CHAR_LENGTH('越努力越幸运'); -- 字符串长度
SELECT CONCAT('今天', '星期六', '!'); -- 拼接字符串
SELECT LOWER('Sun3285'); -- 全部字母小写
SELECT UPPER('Sun3285'); -- 全部字母大写
SELECT INSTR('Today is Saturaday!', 't'); -- 返回第一次出现的字符的索引
SELECT REVERSE('Sun3285加油!'); -- 反转字符串
SELECT REPLACE('今天很开心!', '今天', '每天都一定要'); -- 将指定字符串替换为新的字符串
SELECT INSERT('今天是星期日', 1, 3, '明天'); -- 从索引为1的字符开始,将长度为3的字符串替换为指定字符串
SELECT SUBSTR('天道酬勤,加油~', 1, 4); -- 从索引为1的字符开始,截取长度为4的字符串
-- 查询姓“赵”的同学,改为“周”
SELECT INSERT(studentname, 1, 1, '周') FROM `student` WHERE `studentname` LIKE '赵%'; -- 第一种方式
SELECT REPLACE(studentname, '赵', '周') FROM `student` WHERE `studentname` LIKE '赵%'; -- 第二种方式
注意:
- sql 语言不区分大小写,如第五行输出结果为 1。
- 起始索引为:1。
时间和日期函数
SELECT CURRENT_DATE(); -- 获取当前日期
SELECT CURDATE(); -- 同上
SELECT NOW(); -- 获取当前日期时间
SELECT LOCALTIME(); -- 获取当前本地日期时间,结果同上
SELECT SYSDATE(); -- 获取当前系统日期时间,结果同上
SELECT YEAR(NOW()); -- 获取当前日期时间:年
SELECT MONTH(NOW()); -- 获取当前日期时间:月
SELECT DAY(NOW()); -- 获取当前日期时间:日
SELECT HOUR(NOW()); -- 获取当前日期时间:时
SELECT MINUTE(NOW()); -- 获取当前日期时间:分
SELECT SECOND(NOW()); -- 获取当前日期时间:秒
系统信息
SELECT SYSTEM_USER(); -- 获取用户名
SELECT USER(); -- 同上
SELECT VERSION(); -- 获取 MySQL 版本
2. 聚合函数(常用)
| 函数名称 | 说明 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| MD5() | MD5 加密 |
注意:COUNT(字段)、COUNT(*) 和 COUNT(1) 三者的区别:
- COUNT(字段):只统计所选字段的那一列,且会忽略空值(这里的空不是空字符串或者 0,而是表示 NULL)。
- COUNT(*):不会忽略 NULL,统计了所有的列,相当于行数。
- COUNT(1):不会忽略 NULL,忽略所有列,然后用 1 代表代码行。
可以想成表中有这么一个字段,这个字段的所有值是固定值 1,COUNT(1) 就是计算一共有多少个 1。COUNT(*) 执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。这两个执行结果相同。
使用聚合函数进行查询
需求:
统计学生的年级种类数;
计算学生成绩的总和、平均值、最大值、最小值。
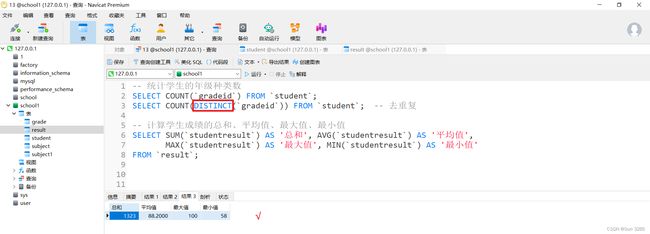
-- 统计学生的年级种类数
SELECT COUNT(`gradeid`) FROM `student`;
SELECT COUNT(DISTINCT(`gradeid`)) FROM `student`; -- 去重复
-- 计算学生成绩的总和、平均值、最大值、最小值
SELECT SUM(`studentresult`) AS '总和', AVG(`studentresult`) AS '平均值',
MAX(`studentresult`) AS '最大值', MIN(`studentresult`) AS '最小值'
FROM `result`;
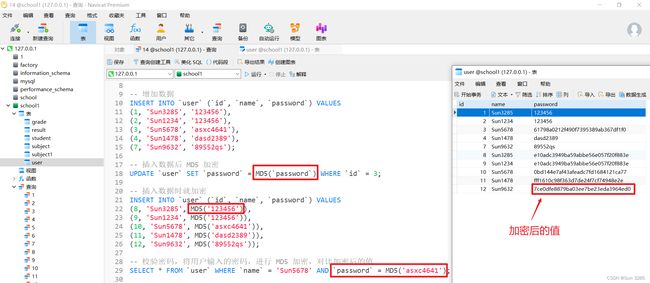
3. 数据库级别的 MD5 加密
MD5:一种加密算法,主要增强算法复杂度和不可逆性,相同数据经过 MD5 加密后的结果是一样的。
校验密码:将用户输入的密码,进行 MD5 加密,对比(正确密码与输入密码)加密后的值。
测试 MD5 加密
-- 创建表 user
CREATE TABLE IF NOT EXISTS `user` (
`id` INT(3) NOT NULL auto_increment COMMENT '序号',
`name` VARCHAR(10) NOT NULL DEFAULT 'Sun3285' COMMENT '姓名',
`password` VARCHAR(50) NOT NULL DEFAULT '123456' COMMENT '密码',
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT charset=utf8mb4
-- 增加数据
INSERT INTO `user` (`id`, `name`, `password`) VALUES
(1, 'Sun3285', '123456'),
(2, 'Sun1234', '123456'),
(3, 'Sun5678', 'asxc4641'),
(4, 'Sun1478', 'dasd2389'),
(7, 'Sun9632', '89552qs');
-- 插入数据后 MD5 加密
UPDATE `user` SET `password` = MD5(`password`) WHERE `id` = 3;
-- 插入数据时就加密
INSERT INTO `user` (`id`, `name`, `password`) VALUES
(8, 'Sun3285', MD5('123456')),
(9, 'Sun1234', MD5('123456')),
(10, 'Sun5678', MD5('asxc4641')),
(11, 'Sun1478', MD5('dasd2389')),
(12, 'Sun9632', MD5('89552qs'));
-- 校验密码,将用户输入的密码,进行 MD5 加密,对比加密后的值
SELECT * FROM `user` WHERE `name` = 'Sun5678' AND `password` = MD5('asxc4641');
注意:
- sql 语句后都要加分号结尾。
- 输错 sql 语句可以强行终止:
Ctrl + C。 - sql 语句的注释是:
--(空格)。 - 学习方法:对照 Navicat Premium 可视化历史日志查看 sql 语句;固定的语法或者关键字必须要记住。
- 出现的错误
- 错误一:注释应该为
comment

- 错误二:注意规定的类型大小与默认值的大小

- 最佳操作:
- 数据库就是单纯的表,只用来存数据,只有行(数据)和列(字段)。
- 如果想用多张表的数据,想用外键,则用程序去实现。
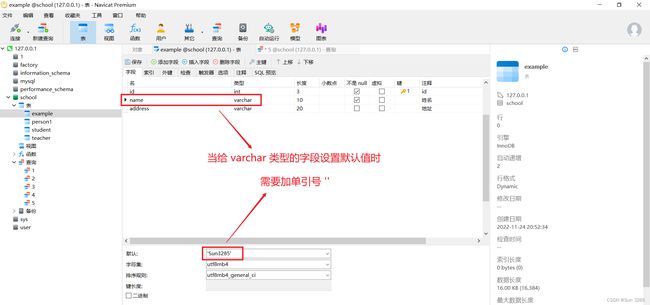
- 当给
varchar类型的字段设置默认值时,需要加单引号''。
- 出现的错误:应该是
where

where子句约束条件中判断等于是=,而不是==。