论文阅读 第一篇:mutual context model
论文阅读第一篇:Recognizing Human-Object Interactions in Still Images by Modeling the Mutual Context of Objects and Human Poses
论文阅读的一般方法
- 多遍阅读
- 第一遍有个大概的认识
先看title,再看abstract,introduction,再看看conclusion,最后看看论文中图片,看看输入输出。能用三两句话总结归纳这篇论文在做什么工作。 - 第二遍看论文最核心的思想
在related work中可以看到这篇论文和其他论文的区别;重要的部分,作者一定会在论文中反复强调;要重点放在这篇论文的学术贡献点上 - 第三遍着眼于细节
最好的理解细节的方法就是去重现这篇论文中提出的方法
- 第一遍有个大概的认识
2.注意要点
打印版
尽管有PDF可以用,但使用打印版会让你注意力更集中,也更方便做笔记,关键点,不明白的学术词汇等都是刚开始阅读论文是需要认真标注的地方。参数
如果需要去重现论文的话,参数是需要特别留意的地方,作者的方法是否有隐藏的参数。关联论文的区别
前面已经发了一片相关领域的paper,为什么这一篇还可以发,这一篇paper做的工作(在前人的基础),是方法上的创新还是有什么其他方面的贡献,这是自己需要留意总结学习的地方。
批判思维
不要迷信权威
research paper难免都会有漏洞,但是作者不可能自己把漏洞写在paper里,limitation里写的也顶多是不痛不痒的小问题。并不是这篇论文的作者特别厉害,所以他的论文就无懈可击。认真研究,如果你发现了论文中的漏洞,你在作者的基础上去完善这个工作,那你也可以发一篇paper了。发现关键问题的基础
初期你会有各种各样的问题,但都不是关键的问题,也不是这篇paper的问题,而是你的问题。你还没有完全理解这篇paper,答案已经在其中,只是你还没有理解,或者是你的基础不够。你去认真踏实地解决你遇到的问题,不断地提升,慢慢你就能提出一些关键的,点子上的问题。
本篇论文
Recognizing Human-Object Interactions in Still Images by Modeling the Mutual Context of Objects and Human Poses
这是发表在2012年IEEE TPAMI,作者是大名鼎鼎的Feifei Li和她的学生,Bangpeng Yao。
原文链接在这里。这是我一门专题研讨课需要做presentation的paper,所以读得比较久,多少有点熟悉吧。
阅读的方法采用的是开头提到的多遍阅读法,因为自己对图像识别这块没有什么基础知识,所以看起来还是比较吃力的,刚开始尝试翻译了abstract和introduction。
然后将重点放在了model上,最后看了experiment。
因为时间比较紧张,还要准备presentation的slide和稿子,所以对paper的一些细节还是一知半解,这里简单地说一下这篇论文的主要思想和自己对paper 提出的mutual context model的理解。
摘要
在2D图像中,混乱场景中的物体检测和人体关节估计是计算机视觉领域的两大挑战。这个难点在包含人和物体的交互的活动(比如网球运动)中,就显得特别明显,在这样的活动中,相关的物体往往偏小或者只有部分可见,并且人的身体部分经常会有自遮挡(self-occluded)的部分(Occlusion means that there is something you want to see, but can’t due to some property of your sensor setup, or some event. )。然而,我们注意到物体和人的姿势可以相互充当相互场境(mutual context),识别其中一个有助于识别另外一个。在本文中,我们提出了一种相互场境模型来为一个人和物体交互活动中的物体和人的姿势共同建模。在我们的方法中,物体的检测为更好的人体姿势估计提供了很强的前提,而人体姿势的估计则又改善了和人交互的物体的检测的精确度。在一个六种运动的数据集和一个24种人和乐器交互的数据集下,我们展示了我们的相互场境模型在十分复杂的物体检测和人体姿势估计,以及人和物体交互活动的分类上,优胜于现有的最佳技术(state-of-the-art)。
上面是自己刚开始读时写的翻译,有很多不准确的地方,但大致能了解这篇paper的主要工作。在图像识别的两个主要任务,human pose estimation 和 object detection中,存在着自遮挡这样的难题,传统的方法不能很好地解决这些问题。本文提出了一种mutual context的模型,它充分利用了human pose 和 object两者的相互关系,让它们可以在识别时互为context,从而使得这两者的识别工作都得到了改善。
介绍
使用场境(context)来增加视觉识别近来受到了越来越多的关注。心理试验表明场境(context)在人类视觉系统识别中有很重要的作用。在计算机视觉中,场境(context)已经被用在诸如物体的识别和检测,场景的识别,动作分类以及图像分割等方面。尽管很清楚的,使用场境(context)(来进行视觉识别)的想法是很好的,但是观察显示绝大多数的场境(context)信息对于增强识别任务的效果没有多大的贡献。在最近的Pascal VOC(pattern analysis,statistical modelling and computational learning visual object classes)挑战赛中,基于场境(context)和基于滑动窗口的方法在物体检测(比如检测自行车)上的差别仅仅在一个很小的3%-4%的差额内。我们认为,一个可以解释这种如此小的差额的原因是,强场境(strong context)的缺失。尽管去检测一辆公路上的车子是容易的,不管车子是否在路上,汽车的强检测子都可以很高准确度地对汽车进行检测。实际上,对于人的视觉系统来说,检测场景中视觉上的反常之处对于生存和社会活动都是至关重要的(比如检测一只在冰箱中的猫和一个机场里无人看管的包裹)。所以场景(的重要性,作用)是不是被夸大了呢?我们的答案是否定的。许多重要的视觉识别任务都都很依赖于场景。一个这样的情况是,人和物体交互(HOI)的活动中人体姿势的估计和物体的检测。正如图一中所展示的,这两大难题(的解决)可以通过互相充当场景来获得极大的收益。如果不知道(图一中)这个人正在用板球拍进行防御性击球的话,就不太容易准确地估计这个运动员的姿势;如果不是看到这个运动员的姿势的话,也很难去检测一个甚至对于人眼来说都是几乎不可见的运动员手中的小球。在本文中,我们提出为HOI活动中的物体和人体姿势之间的相互环境建模,如此其中一个可以帮助另一个的识别。特别地,在我们地相互场景模型中,两个场景的信息也被考虑到。同现场景为每个活动中物体和特定类型的人体姿势之间的同现统计建模。图六中的人体姿势类型被称为“原子姿势”,(图六中的人体姿势)可以理解为是人体姿势的字典,其中人体姿势被符合身体部分相似形态的相同的原子姿态所表示。我们也注意到空间场景,它为物体和不同的人体部分的空间关系建模。我们展示了我们的算法在一个六类运动和一个二十四种人和乐器交互(PPMI)的数据集下,极大地改善了物体检测和人体姿势估计两方面的性能。此外,将物体检测和人体姿势估计放到一起,我们的方法在HOI运动分类上也达到了较高的准确度。物体和人体姿势地相互环境建模有其心理学的理论基础。在参考文献17和18中,展示了当物体被显示时,人对于人体姿势有更好的洞察。在参考文献19中,作者进一步确认了在HOI活动中物体和人体姿势的空间和功能性关系。在我们的工作中,我们明确地为这些关系建模,使得物体和人体姿势的识别可以相互获益。这使得我们的方法和之前大多数活动识别方法都不同,比如在参考文献20,21,22,23中,活动识别被视作单纯的图像或者视频分类问题,而没有具体地分析这些活动中涉及到的物体和人体姿势。文章剩余部分的按照下面的方式进行组织。第二部分描述了相关工作,第三,四,五部分分别详细地说明了我们模型的细节,模型的学习以及结论。第六部分给出了实验结果。第七部分做了文章总结。
introduction 部分主要介绍这篇论文的整体组织,以及mutual context model更详细的内容,阅读完此部分,基本上应该对这篇paper有个大概地认识。
下面的内容将根据我的presentation顺序来介绍一下这篇paper
background
interaction
You can conceive a lot of examples of interaction if you want,because the interaction is really common in our life.
Given a image contains human-object interaction,we may want to know what the human-object interaction activity is. Namely we want to do recognition for the image.Is it depicts A man is playing basket ball or a man is playing the musical instrument…That is what we called “activity classification”. Besides the classification,for a deeper understanding for a image,we also want to know some details.By classification,we know it’s a class of tennis forehand activity.We would like to know the different parts of the body as well as the location of these body parts.This is the work,”human pose estimation”.we also want to know the object that the person is interacting with.And this is the work,”object detection”.
Although the human pose estimation and the object detection has been widely studied for so many years in computer vision,they are still very changing problems due to the following reasons.

human pose estimation
When we do the human pose estimation,sometime,the unusual part appearance,the self-occlusion and the image region which looks like very similar to a body part can make our work become changing.As you can see in this image,a typical state-of-the-art pose analysis algorithm may give the inaccurate or even the wrong results to you.
But suppose we already know the man is playing baseball and the location of the bat,it should facilitate the human pose estimation because of the strong prior for the pose.It is easy to explain.For instance,if the bat is here,intuitively, it may be a baseball forehand pose ,but not other.
object detection
It is the same to the object detection,which some problems may hinder our work just like in estimation of human pose.Sometimes the object in the image can be very small,low-resolution,partially occluded and some regions of the image background are very similar to the detection target.
A typical object detection approach is the scanning window.For such scenario in this image(indicate in the image),this approach may give you a lot of wrong result.But if we already know it is a pose of casting a ball.With the help of the pose,especially the location of the upper arm,we can locate the detection target easier.That is,the human pose estimation facilitates the detection of object.
Human pose estimation and object detection,this two difficult tasks can benefit greatly from serving as context for each other,which is the intuition that we use the mutual context in this paper.
approach in this paper
In this paper,by introducing a set of “atomic pose”,which can be thought of as a dictionary of human poses,where the same atomic pose describes those human poses which have the same layouts of body parts just as the picture shown,we learn an overall relationship between different activities,objects and human poses,rather than modeling the human-object interactions for each activity. And the model in this paper can deal with the situations where human interacts with any number of objects.So by allowing human pose estimation and object detection server as context for each other,the recognition performance of both tasks are improved.Two contexts,the co-occurrence context which models the co-occurrence statistics between objects and specific types of human poses within each activity and the spatial context which models the spatial relationship between objects and different human body parts, are considered in the mutual context model.Besides,it also incorporates a discriminative action classification component and the state-of-the-art object and body part detectors,which further improves the recognition performance.
mutual context model

A graphical illustration of the model is shown in this picture(indicate it in the image).First the activity,such as tennis forehand and volleyball smash,is represented by A;the object,like tennis racket and volleyball,is represented by O;H indicates the atomic pose label that the human pose belongs to.For each overall human pose,we decompose it into the spatial layout of a number of body parts denoted by P,which like head,torso ,upper-left-arm and so on;
model representation
Putting everything together,the model can be represented as the formulation.
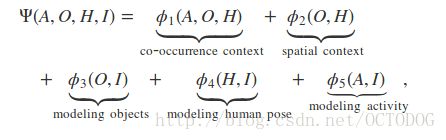
This is a conditional random field model and the term,CRF,here is a kind of statistical modeling method often applied in pattern recognition.As you can see from the formulation, ϕ1 models the co-occurrence compatibility between A ,O and H ,ϕ2 considers the spatial relationship between O and H,and ϕ3 to ϕ5 models the image evidence based on state-of-the-art object detection,human pose estimation and activity classification approaches.So this is overview of the mutual model and I am going to introduce the potentials of this model.
co-occurrence context

ϕ1() models the compatibility between activity ,object and human poses in terms of co-occurrence frequency. For instance ,”tennis ball”and “tennis racket” always appear in the same activity,like “tennis serve”,and people usually serve the tennis in several specific poses.In the formulation,Nh is the total number of atomic poses(Namely the letter N means “the Number of something”,so,you should already know the meaning of the No and Na),and hi here represents the i−th atomic pose.The 1 here is a indicator function,which 'returns' 1 if H equals hi otherwise 'returns' 0.And the ζi,j,k represents the strength of the co-occurrence between hi , oj and ak ,that is to say,the larger ζi,j,k is,the more likely for hi , oj and ak to co-occur.
spatial context
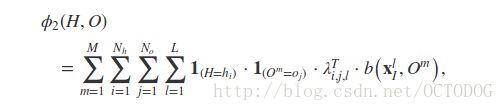
The next is ϕ2() which considers the spatial relationship between object and different parts of human.M is the number of object bounding boxes in image.the bounding box is a term in geometry,which is the box with the smallest measure(area,volume and so on) to enclose all the points of a set.So the object bounding box can be interpreted as the smallest box which can enclose the object.For example,M is 2 here. λi,j,l here encodes the set of weights for the relationship when the object class of Om is oj.While the b(xlI,Om) here denotes the spatial relationship between xlI , the location of the center of the human’s l-th body part,and Om . b(xlI,Om) can be represented by a binary feature.
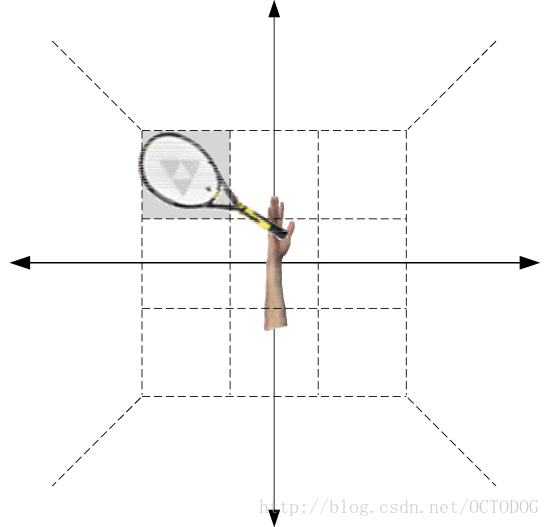
The picture is a visualization of the binary feature b() .The space is divided into 13 disjoint regions based on a coordinate frame defined by the xlI . Because the b(xlI,Om) is a sparse binary vector with only one 1 for the element that corresponds to the relative location of Om with respect to xlI ,the b(xlI,Om) here is a 13 dimensional binary vector with a 1 in the region that filled by gray color,namely the spatial relationship between the arm and the tennis racket can be denoted by this 13 dimensional binary vector.
other
Maybe a little tedious,right?But this it is and we also have the ϕ3() ,
modeling object, ϕ4() ,modeling human pose, and ϕ5() ,modeling activities, next.While,after we talk about the co-occurrence context and the spatial context,you may have a sense of doubt,where is the mutual context that we emphasize all the time?
Okay,imprecisely,just,imprecisely,the mutual context means the human pose can be the context to the object detection,as well as object detection.So the mutual context can be parameterized as the the model we give.Activity,object,human pose and interaction,each of them is indispensable for the mutual context.However,in consideration of our limited time tonight,so we have to focus on some parts of the model while overlook others.And I am going to go through very quickly for the next three parts of the mutual context model.
ϕ3() model objects in the image using object detection scores in all the object bounding boxes and the spatial relationship between these boxes and ϕ4() models the atomic pose that H belongs to and the Likelihood of observing image I given the atomic pose hi.The last one, ϕ5() ,takes the global image as features and train an activity classifier to model the HOI.It serves as the activity context to understand the interactions between humans and objects.
conclusion for the mutual context
The mutual context model have the following properties.The remarkable of these is the third.Compared to the original method where the objects and human poses in each HOI activity are modeled separately,this model is easier to extend to larger scale data set and other activities because it jointly all the objects and atomic poses in all the HOI activities.So this model has universality and it is valuable.
model learning
I am going to introduce the model learning briefly.
Just as we talked before,the atomic poses can be thought of as a dictionary of human poses.And it plays a very important role in modeling human and object interactions.We can do the human poses estimation much easier if we know which atomic pose which the image corresponds to.
In this paper,we obtain the atomic poses by clustering the configurations of human body parts,which is based on the annotation of human body parts.And compared to those clusters obtained within each activity class separately,atomic poses here are shared by all the activities,so it easier to extend to more activity class.
This picture shows all the atomic poses which obtained from the sport data set.
Thicker lines indicate stronger connections.For instance,there is a thicker line for the “tennis forehand” and the forth atomic pose.Namely there is a strong connection between them.
I am not intend to introduce the detectors and classifiers’ training and the model parameters estimating.However,we should note that the mutual context model is a standard conditional random field with no hidden variables.
model inference
Now let me briefly goes to the model inference and then dive to the experiments.
We initialize the model inference with the spatial pyramid matching(SPM) action classification result,object bounding boxes obtained from independent object detectors,and initial pose estimation results from a pictorial structure model.In order to reduce false negatives in object detection,we kept those bounding boxes if score which gets by the object detectors are larger than 0.9.
We use pictorial structure with Gaussian distribution to update the pose estimation results here.And we use a greedy forward search method to update the object detection results.Last,we optimize the mutual context model by enumerating all possible combination of A and H labels.
experiment
So now let’s go through the experiments.
This paper use two known data sets of HOI activities,the sports data set and the PPMI data set.I will focus on the first one.

The sport data set contains six classes and each class contains thirty training images and twenty testing images.let’s look at the object detection first.
Here we evaluate the performance of detecting each object in all the testing images.We use average precision to measure the performance.We can observe that our detection approach achieves the best performance compared to the contrast approaches.Whether the baseline,deformable part model,or the object context and person context.For example,in the case of cricket ball and croquet ball ,which are very similar and are very difficultly to detect by traditional methods,the deformable part model gives performance of 24\% and 50\%,while our method yields 32\% and 58\%.

Next is the human poses estimation.Similarly to object detection,our method performance better than the state-of-the-art method,the pictorial structure method.”PS” in this table stands for “pictorial structure” and “class-based PS” means training one pictorial structure using image of each class.Note that our methods even shows a 3\% average improvement over a class-based pictorial structure model where use the ground truth activity class label.
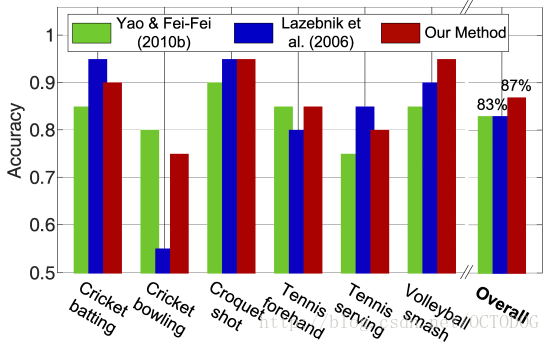
Last is the activity classification.our model gives a prediction of the class label of the HOI activity.We observe that our method outperforms the other approaches here.
conclusion
The major contribution of this paper’s work is to demonstrate the importance of context in visual recognition,Specifically we found that the mutual context between object and human pose can significantly improve the recognition.
The limitation of our work is we need to annotate the human body parts and objects in each training image.
One direction of our future work is to study weakly supervised or unsupervised approaches to understand human-object interaction activities.
感谢本次研讨课的老师,Ruizhen Hu,给了我们特别多关于论文阅读的方法。当然也感谢这篇论文的作者!
Reference
http://videolectures.net/cvpr2010_fei_fei_mmco/
http://ieeexplore.ieee.org/document/6165303/
presentation ppt: https://pan.baidu.com/s/1c1BfgMc 密码: 9ega
presentation script: https://pan.baidu.com/s/1o8v1WuA 密码: vbvy