Nginx从初级到高级的玩法
青铜玩法
一、首先介绍下nginx
二、为什么要选择nginx
三、然后来聊下正向代理服务和反向代理服务
四、体验下nginx下载和阿里云快速安装
六、 安装好后现在介绍下Nginx目录文件
七、Nginx核心知识之默认配置文件解析
八、阿里云-Nginx配置虚拟主机,搭建前端静态资源服务器
九、nginx配置文件/图片服务器
十、你知道accessLog日志可以挖掘出来哪些信息吗?
十一、Nginx统计站点访问量、高频url统计
十二、自定义日志格式,统计接口响应耗时
黄金玩法
一、负载均衡环境准备
二、负载均衡的概念讲解/举例
三、负载均衡策略
四、Nginx后端节点可用性探测和配置
五、nginx全局异常兜底数据返回
六、nginx封禁恶意IP
七、nginx配置浏览器跨域
八、nginx的location规则-路径匹配
九、nginx配置WebSocket反向代理-实时通信
十、Nginx配置服务端缓存
10.1Nginx配置服务端缓存核心配置
10.2缓存命中率统计
十一、Nginx性能优化之静态资源压缩
钻石玩法
一、Nginx和Https的那些事
1.1 什么是Https,和http的区别
1.2、阿里云免费https证书申请和准备
1.3 阿里云 Nginx配置https证书配置实操
二、Nginx的第三方利器OpenResty+Lua介绍
2.1 什么是OpenResty, 为什么要用OpenResty?
2.2 Lua脚本介绍
2.3 什么是ngx_lua
2.4 OpenResty提供了常用的ngx_lua开发模块
2.5 OpenResty安装 linux centos7安装
2.6 讲解Nginx+OpenRestry开发第一个例子
2.7 Nginx+OpenRestry开发网络访问限制(黑名单)实操
2.8 Nginx+OpenRestry开发下载限速实操
2.9 下载限速实现原理
三、全链路高可用之Nginx基础架构问题分析
3.1 Nginx单点问题剖析
3.2 主流高可用方案Linux虚拟服务器 LVS
3.3 主流高可用方案keepalived
3.4 Keepalived核心配置介绍
3.5 准备Nginx+Lvs+KeepAlive相关验证
3.6 Nginx+Lvs+KeepAlive高可用方案实施
本博文主要介绍了Nginx从入门到熟悉的玩法,从Nginx快速安装-配置解读-文件服务器的配置-accesslog日志统计挖掘-站点访问量和高频url统计,到Nginx负载均衡玩法-兜底数据返回-浏览器跨域配置-服务端缓存配置-静态资源压缩,再到高级玩法之https认证-OpenResty下载限速-keepAlived高可用,全程实操配置+截图,通俗易懂~
青铜玩法
一、首先介绍下nginx
官网:http://nginx.org/
nginx是一个高性能的[HTTP]和[反向代理]web服务器, Nginx代码完全用[C语言]从头写成
支持系统:Mac/Windows/Linux
二、为什么要选择nginx
社区活跃高,高性能-支持单机千万级连接
强大的第三方库支持,功能强大:负载均衡、静态文件服务器、支持多种协议https、POP3等等

三、然后来聊下正向代理服务和反向代理服务
正向代理服务器
客户端和目标服务器之间的服务器,客户端向代理发送一个请求指定目标服务器,然后代理向目标服务器请求并获得内容,并返回给客户端,平时说的代理服务器一般是正向代理服务器
核心:用户知道自己访问的目标服务器
场景:跳板机、访问原来无法访问的网站, 比如国外的一些站点

反向代理服务器(Nginx)
客户端和目标服务器之间的服务器,客户端向代理发送一个请求,然后代理向目标服务器请求并获得内容,并返回给客户端。反向代理隐藏了真实的服务器
核心:客户端不知道要访问的目标服务器是哪台服务器,代理会根据一定的策略选择一个真实的服务器进行请求
场景:访问淘宝,知道访问的域名是taobao.com, 但是后面提供数据的具体是什么域名或ip我们是不知道的

四、体验下nginx下载和阿里云快速安装
先看下文字描述,然后下面还有操作步骤图,执行命令时,目录不要进错了
第一步:下载压缩包 并上传
http://nginx.org/en/download.html
第二步:安装依赖
yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel
第三步:创建一个文件夹,上传本地提供的nginx包
tar -zxvf nginx-1.18.0.tar.gz
./configure
make
make install./nginx

还是这个目录下 make 然后再make install

默认安装路径:/usr/local/nginx

./nginx 进行启动 ps -ef |grep "nginx"查看是否正常启动

防火墙开放端口,阿里云网络安全组配置80端口
浏览器访问:ip:80 ,出现下面这个就是安装成功啦
 六、 安装好后现在介绍下Nginx目录文件
六、 安装好后现在介绍下Nginx目录文件
源码编译安装后,默认目录:/usr/local/nginx
核心目录来波介绍:
conf #所有配置文件目录
nginx.conf #默认的主要的配置文件
nginx.conf.default #默认模板
html # 这是编译安装时Nginx的默认站点目录
50x.html #错误页面
index.html #默认首页
logs # nginx默认的日志路径,包括错误日志及访问日志
error.log #错误日志
nginx.pid #nginx启动后的进程id
access.log #nginx访问日志
sbin #nginx命令的目录
nginx #启动命令
常见很实用的命令(划重点 这要记住)
./nginx #默认配置文件启动
./nginx -s reload #重启,加载默认配置文件
./nginx -c /usr/local/nginx/conf/nginx.conf #启动指定某个配置文件
./nginx -s stop #停止
#关闭进程,nginx有master process 和worker process,关闭master即可
ps -ef | grep "nginx"
kill -9 PID
七、Nginx核心知识之默认配置文件解析
都是干货得配置讲解,仔细看看:
# 每个配置项由配置指令和指令参数 2 个部分构成
#user nobody; # 指定Nginx Worker进程运行以及用户组
worker_processes 4; # 推荐和CPU核数保持一致
#error_log logs/error.log; # 错误日志的存放路径 和错误日志
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid; # 进程PID存放路径
# 事件模块指令,用来指定Nginx的IO模型,Nginx支持的有select、poll、kqueue、epoll 等。
# 不同的是epoll用在Linux平台上,而kqueue用在BSD系统中,对于Linux系统,epoll工作模式是首选
events {
use epoll;#异步非阻塞模型
# 定义Nginx每个进程的最大连接数, 作为服务器来说: worker_connections * worker_processes,
# 作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/2。因为反向代理服务器,每个 并发会建立与客户端的连接和与后端服务的连接,会占用两个连接
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
# 自定义用户访问的日志 下面有模块单独讲解这$参数等的意思 。先看整个配置,有个宏观概念,然后再继续往下看细节
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
# 是否开启高效传输模式 on开启 off关闭
sendfile on;
#减少网络报文段的数量
#tcp_nopush on;
#keepalive_timeout 0;
# 客户端连接保持活动的超时时间,超过这个时间之后,服务器会关闭该连接
keepalive_timeout 65;
#压缩返回图片等,可节省带宽
#gzip on;
# 虚拟主机的配置
server {
listen 80; # 虚拟主机的服务端口
server_name localhost aaa.com bbb.com; #用来指定IP地址或域名,多个域名之间用空格分开
#charset koi8-r;
#access_log logs/host.access.log main;
#URL地址匹配
location / {
root html; # 服务默认启动目录
index index.html index.htm; #默认访问文件,按照顺序找
}
#error_page 404 /404.html; #错误状态码的显示页面
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
八、阿里云-Nginx配置虚拟主机,搭建前端静态资源服务器
搭建个前端静态资源服务器,对上面介绍的点加深理解
配置nginx.conf完成后 可通过域名直接访问到 conf中指定的惊天页面,实现前端静态资源展示。域名需要自己购买然后绑定IP地址

阿里云中使用域名访问,需要购买域名然后进行备案。公司linux服务器或者mac,配置上Hosts对应域名即可。阿里云的话,要记得开放80安全端口。
/usr/local/nginx/html目录下创建wnn1.html
注意:
server {
listen 80;
server_name wnn2021.xxxxxx;
location / {
root /usr/local/nginx/html;
index wnn1.html;
}
}

九、nginx配置文件/图片服务器
图片服务器
很早之前学javaweb、node、或者其他基础web项目,基本都是图片上传到项目本身,这种方式生产环境很少用
公司一般会使用图片服务器或者云厂商提供的CDN
现在一般公司的文件/图片使用流程:前端提交图片->后端处理->存储到图片服务器->拼接好访问路径存储到数据库和范围前端
本地图片上传上去,配置专属访问路径
server {
listen 80;
server_name wnn2021.xxx;
location /app/img {
alias /usr/local/software/img/;
}
}
图片或者语音文件等查看方式都是一样的。地址拼接正确就可以。
这里需要注意2点:
在location / 中配置root目录
在location /path中配置alias虚拟目录, 目录后面的"/"符号一定要带上
十、你知道accessLog日志可以挖掘出来哪些信息吗?
先介绍下access.log日志用处
统计站点访问ip来源、某个时间段的访问频率
查看访问最频的页面、Http响应状态码、接口性能
接口秒级访问量、分钟访问量、小时和天访问量
conf中默认的配置解析
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
举例:
192.168.5.18 - - [20/January/2022:22:49:48 +0800] "GET /user/api/v1/product/order/query_state?product_id=1&token=JhbGciOJE HTTP/1.1" 200 48 "https://wnn2022.cn/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
解析:
$remote_addr 对应的是真实日志里的192.168.5.18,即客户端的IP。可以根据用户IP来统计网站用户的地域分布
$remote_user 对应的是第二个中杠“-”,没有远程用户,所以用“-”填充。
[ $time_local]对应的是 [20/January/2022:22:49:48 +0800] 。
“$request”对应的是"GET /user/api/v1/product/order/query_state?product_id=1&token=JhbGciOJE HTTP/1.1"。
$status对应的是200状态码,200表示正常访问。
$body_bytes_sent对应的是48字节,即响应body的大小。
“$http_referer” 对应的是”https://wnn2022.cn/“,若是直接打开域名浏览的时,referer就会没有值,为”-“。
“$http_user_agent” 对应的是”Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:56.0) Gecko/20100101 Firefox/56.0”。记录客户端的访问信息,部分爬虫爬取数据时,此信息是空的,可以用此来限制爬虫爬取
“$http_x_forwarded_for” 对应的是”-“或者空。
十一、Nginx统计站点访问量、高频url统计
准备了一批access.log日志,通过awk(文本处理工具)统计一下站点访问量 高频URL
 将日志放到logs目录下
将日志放到logs目录下

查看访问网站最频繁的前100个IP

命令解释:
{print $1} $1,取第一个IP地址
access_temp.log 分析日志的名称
sort -n 根据数值进行排序
uniq -c 去重统计
sort -rn 再根据以上结果按照数值倒序
head -n 100 取前100条
再统计下访问最多的url 前20名
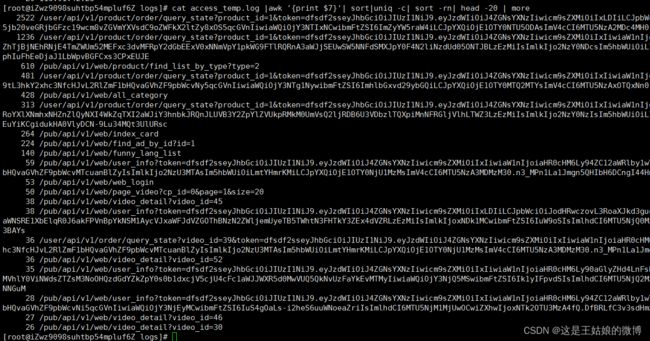
cat access_temp.log |awk '{print $7}'| sort|uniq -c| sort -rn| head -20 | more
{print $7} 空格分开后的第七位是URL信息
awk 是文本处理工具,默认按照空格切分,$N 是第切割后第N个,从1开始
sort命令用于将文本文件内容加以排序,-n 按照数值排,-r 按照倒序来排
案例的sort -n 是按照第一列的数值大小进行排序,从小到大,倒序就是 sort -rn
uniq 去除重复出现的行列, -c 在每列旁边显示该行重复出现的次数。
十二、自定义日志格式,统计接口响应耗时
看了上面几个其它网站的数据,下面来自定义日志格式,统计下每个接口响应的耗时
先更改下nginx.conf 增加 $request_time
$request_time
从接受用户请求的第一个字节到发送完响应数据的时间,即包括接收请求数据时间、程序响应时间、输出响应数据时间
$upstream_response_time:指从Nginx向后端建立连接开始到接受完数据然后关闭连接为止的时间
$request_time一般会比upstream_response_time大,因为用户网络较差,或者传递数据较大时,前者会耗时大很多

保存后,重启nginx 随机访问一些连接,查看日志如下:
最后一列就是统计到的时间,因为本地访问的很快,所以时间都是0秒,为了查看统计效果手动的改大了数值


($NF > 2) 最后一列超过2的。列表中看到的5个是接口响应超过2秒的前5个IP地址
黄金玩法
一、负载均衡环境准备
Linux服务器需要安装JDK8
准备两个一样的Jar包
demo-1.jar监听8080端口
demo-2.jar监听8081端口
接口说明
接口一
GET请求,返回json数据,控制输出日志
http://112.74.xxx.xxx:8080/api/v1/pub/info/check
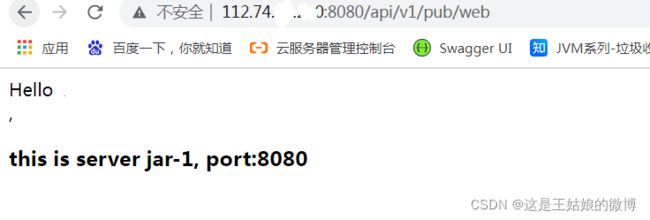
接口二返回HTML页面,两个jar返回的HTML内容不一样,方便区分访问的是哪个jar
http://112.74.xxx.xxx:8080/api/v1/pub/web

守护进程方式
nohup java -jar demo-1.jar &
nohup java -jar demo-2.jar &
二、负载均衡的概念讲解/举例
负载均衡(Load Balance)
分布式系统中一个非常重要的概念,当访问的服务具有多个实例时,需要根据某种“均衡”的策略决定请求发往哪个节点,这就是所谓的负载均衡,
原理是将数据流量分摊到多个服务器执行,减轻每台服务器的压力,从而提高了数据的吞吐量
负载均衡的种类
通过硬件来进行解决,常见的硬件有NetScaler、F5、Radware和Array等商用的负载均衡器,但比较昂贵的
通过软件来进行解决,常见的软件有LVS、Nginx等,它们是基于Linux系统并且开源的负载均衡策略
目前性能和成本来看,Nginx是目前多数公司选择使用的

具体配置:
upstream lbs {
server 112.74.xxx.xxx:8080;
server 112.74.xxx.xxx:8081;
}
server {
listen 80;
server_name wnn2021xx.xxx;
location /api/ {
proxy_pass http://lbs;
proxy_redirect default;
}
}
访问地址:http://wnn2021xxx.xxx/api/v1/pub/web
默认以轮询的方式访问

再刷新一下,变成了8080

三、负载均衡策略
节点轮询(默认)
简介:每个请求按顺序分配到不同的后端服务器
场景:会造成可靠性低和负载分配不均衡,适合静态文件服务器
weight 权重配置
简介:weight和访问比率成正比,数字越大,分配得到的流量越高
场景:服务器性能差异大的情况使用
nginx.conf
upstream lbs {
server 112.74.xxx.xxx:8080 weight=5;
server 112.74.xxx.xxx:8081 weight=10;
}
server {
listen 80;
server_name wnn2021xx.xxx;
location /api/ {
proxy_pass http://lbs;
proxy_redirect default;
}
}
重启后,查看接口访问日志
![]() http://wnn2021xx.xxxx/api/v1/pub/web 连续访问十几次
http://wnn2021xx.xxxx/api/v1/pub/web 连续访问十几次
8081日志打印输出明显多于8080
8081

8080

ip_hash(固定分发)
简介:根据请求按访问ip的hash结果分配,这样每个用户就可以固定访问一个后端服务器
场景:服务器业务分区、业务缓存、Session需要单点的情况
upstream lbs {
ip_hash;
server 112.74.xxx.xxx:8080 weight=5;
server 112.74.xxx.xxx:8081 weight=10;
}
server {
listen 80;
server_name wnn2021xx.xxx;
location /api/ {
proxy_pass http://lbs;
proxy_redirect default;
}
}
根据ip地址进行hash后,决定访问哪一个服务。
upstream还可以为每个节点设置状态值
down 表示当前的server暂时不参与负载
server 112.74.xxx.xxx:8080 down;
backup 其它所有的非backup机器down的时候,会请求backup机器,这台机器压力会最轻,配置也会相对低
server 112.74.xxx.xxx:8080 backup;
四、Nginx后端节点可用性探测和配置
某个应用挂了,请求不应该继续分发过去,这个需求要怎么做呢?
可以使用proxy_next_upstream+max_fails +fail_timeout
参数解释 :
max_fails=N 设定Nginx与后端节点通信的尝试失败的次数。
在fail_timeout参数定义的时间内,如果失败的次数达到此值,Nginx就这个节点不可用。
在下一个fail_timeout时间段到来前,服务器不会再被尝试。
失败的尝试次数默认是1,如果设为0就会停止统计尝试次数,认为服务器是一直可用的。
那么,具体什么是nginx认为的失败呢
可以通过指令proxy_next_upstream来配置什么是失败的尝试。
注意默认配置时,http_404状态不被认为是失败的尝试。
具体配置:
upstream lbs {
server 112.74.xxx.xxx:8080 max_fails=2 fail_timeout=60s ;
server 112.74.xxx.xxx:8081 max_fails=2 fail_timeout=60s;
}
location /api/ {
proxy_pass http://lbs;
proxy_next_upstream error timeout http_500 http_503 http_404;
}
达到的效果验证:
开启8080和8081端口,默认轮询状态。暂停8081节点,然后访问地址大于10次后,nginx会把这个8081端口剔除,不再访问。
重启8081节点,在fail_timeout周期里面不会再获取流量
继续超过fail_timeout周期后,8081开始重新获得流量
五、nginx全局异常兜底数据返回
任何接口都是可能出错,4xx、5xx等,如果业务没有做好统一的错误管理,直接暴露给用户,用户体验很差
所以假如后端某个业务出错,nginx层也需要进行转换,让前端知道Http响应是200,其实是将错误的状态码定向至200,返回了全局兜底数据
nginx.conf配置如下:
upstream lbs {
server 112.74.xxx.xxx:8080 weight=5;
server 112.74.xxx.xxx:8081 weight=10;
}
server {
listen 80;
server_name wnn2021xxx.xx;
access_log logs/wnn.access.log main;
location / {
proxy_pass http://lbs;
proxy_redirect default;
# 存放用户的真实ip
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream error timeout http_503 non_idempotent;#开启错误拦截配置,一定要开启
proxy_intercept_errors on;
}
error_page 404 500 502 503 504 =200 /default_api;
location = /default_api {
default_type application/json;#具体的返回状态码和信息,前后端可以提前定好
return 200 '{"code":"-1","msg":"invoke fail, not found "}';
}
}
正常情况下的参数和结果:

404 500 502 503 504这些状态码的请求和结果:


六、nginx封禁恶意IP
网络攻击时有发生,TCP洪水攻击、注入攻击、DOS等,比较难防的有DDOS等
封禁IP可以一定程度上保障数据安全,防止对手爬虫恶意爬取
封禁IP的一般做法:
1.linux server的层面封IP:iptables
2.nginx的层面封IP
nginx.conf配置。增加一个放黑名单的.conf文件。然后根据范围在对应大括号内引入这个黑名单.conf文件。
单个网站屏蔽IP的方法,把include xxx; 放到网址对应的在server{}语句块,虚拟主机
所有网站屏蔽IP的方法,把include xxx; 放到http {}语句块http{
# ....
include blacklist.conf;
}#conf目录下
#blacklist.conf目录下文件内容 下面是需要封禁的IP
deny 192.168.159.2;
deny 192.168.159.32;
./nginx -s reload #重新加载配置,不中断服务
自动化封禁思路:
编写shell脚本
AWK统计access.log,记录每秒访问超过60次的ip,然后配合nginx或者iptables进行封禁
crontab定时跑脚本
七、nginx配置浏览器跨域
什么样的算是跨域了?
浏览器同源策略 1995年,同源政策由 Netscape 公司引入浏览器。目前,所有浏览器都实行这个政策。
最初,它的含义是指,A网页设置的 Cookie,B网页不能打开,除非这两个网页"同源"。所谓"同源"指的是"三个相同"
协议相同 http https
域名相同 www.wnn2021.net
端口相同 80 81一句话:浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域
浏览器控制台跨域提示:
No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'null' is therefore not allowed access.
解决方法有JSONP(用的不多)、Http响应头配置允许跨域
Nginx开启跨域配,location下配置
location / {
add_header 'Access-Control-Allow-Origin' $http_origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Headers' 'DNT,web-token,app-token,Authorization,Accept,Origin,Keep-Alive,User-Agent,X-Mx-ReqToken,X-Data-Type,X-Auth-Token,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header Access-Control-Allow-Methods 'GET,POST,OPTIONS';
#如果预检请求则返回成功,不需要转发到后端
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 200;
}
} 更改之前:
配置重启之后:

配置层级截图:不要放错位置啦!
八、nginx的location规则-路径匹配
^ 以什么开始 $ 以什么结束
^/api/user$ 这个正则表达式表示字符串必须以/开始,以b $结束,中间必须是/api/pub
location 路径匹配 语法 location [ = | ~ | ~* | ^~ ] uri { ...... }
location = /uri = 表示精准匹配,只要完全匹配上才能生效
location /uri 不带任何修饰符,表示前缀匹配
location ^~ /uri/ 匹配任何已 /uri/ 开头的任何查询并且停止搜索
location / 通用匹配,任何未匹配到其他location的请求都会匹配到
正则匹配
区分大小写匹配(~)
不区分大小写匹配(~*)
优先级:精准匹配 > 字符串匹配(若有多个匹配项匹配成功,那么选择匹配长的并记录) > 正则匹配
优先级举例验证:
location ~^/usr/local/software/img/111.png$ {
return 1;
}location /usr/local/software/img/111.png {
return 2;
}location ^~/usr/local/software/img/ {
return 3;
}location = / {
return 4;
}location / {
return 5;
}
http://wnn20xxxx.xx//usr/local/software/img/111.png 返回结果1

http://wnn20xxx.xx//usr/local/software/img/aaaaa.png 随机png。返回了3 匹配任何已 /uri/ 开头的任何查询并且停止搜索

http://wnn20xxx.xx/ 命中了 =号 优先级高 返回了4

九、nginx配置WebSocket反向代理-实时通信
配置:
server {
listen 80;
server_name wnn.net;
location / {
proxy_pass http://lbs;
proxy_read_timeout 300s; //websocket空闲保持时长
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
}
}
核心是下面的配置 其他和普通反向代理没区别, 表示请求服务器升级协议为WebSocket
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
服务器处理完请求后,响应如下报文# 状态码为101
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: upgrade
十、Nginx配置服务端缓存
10.1Nginx配置服务端缓存核心配置
常见的开发人员控制的缓存分类:数据库缓存 应用程序缓存 Nginx网关缓存 前端缓存
放在Nginx网关缓存的好处就是让后端结果缓存离用户更进一步
核心配置:
proxy_cache_path /root/cache levels=1:2 keys_zone=wnn_cache:10m max_size=1g inactive=60m use_temp_path=off;
server {
location /{
...
proxy_cache wnn_cache;
proxy_cache_valid 200 304 10m;
proxy_cache_valid 404 1m;
proxy_cache_key $host$uri$is_args$args;
add_header Nginx-Cache "$upstream_cache_status";
}
}
分别介绍下配置的含义:
/root/cache
本地路径,用来设置Nginx缓存资源的存放地址
levels=1:2
缓存文件的层级,默认所有缓存文件都放在上面指定的根路径中,可能影响缓存的性能,
推荐指定为 2 级目录来存储缓存文件;1和2表示用1位和2位16进制来命名目录名称。第一级目录用1位16进制命名,如a;第二级目录用2位16进制命名,如3a。所以此例中一级目录有16个,二级目录有16*16=256个,总目录数为16 * 256=4096个。
当levels=1:1:1时,表示是三级目录,且每级目录数均为16个
key_zone
在共享内存中定义一块存储区域来存放缓存的 key 和 metadata
max_size
最大缓存空间, 如果不指定会使用掉所有磁盘空间。当达到 disk 上限后,会删除最少使用的 cache LRU算法
inactive
某个缓存在inactive指定的时间内如果不访问,将会从缓存中删除。优先级最高
use_temp_path
建议为 off,则 nginx 会将缓存文件直接写入指定的 cache 文件中。如果是On,会将缓存内容写到临时文件夹里面,然后再转移到指定文件夹。中间涉及文件的拷贝。所以建议为off
proxy_cache
启用proxy cache,并指定key_zone,如果proxy_cache off表示关闭掉缓存
add_header Nging-Cache "$upstream_cache_status"
用于前端判断是否是缓存,[miss、hit、expired(缓存过期)、updating(更新,使用旧的应答)]
proxy_cache_valid 200 304 10m
200或者304状态码的 缓存10分钟
nginx.conf配置演示结果:

第一次访问接口:

后台会有对应日志输出,60分钟内持续访问将无一条日志输出。

注意:
nginx缓存过期影响的优先级进行排序为:inactvie > 源服务器端Expires/max-age > proxy_cache_valid
如果出现 Permission denied 修改nginx.conf,将第一行修改为 user root
默认情况下GET请求及HEAD请求会被缓存,而POST请求不会被缓存,并非全部都要缓存,可以过滤部分路径不用缓存清空缓存的话:直接rm删除配置的资源路径/root/cache 或者 ngx_cache_purge
10.2缓存命中率统计
HIT表示命中了缓存。

有2种方式可以统计缓存命中率:
一:前端打点日志上报
二:nginx日志模板增加信息 $upstream_cache_status

重启后,日志如下

缓存命中率 = 命中次数 / 请求总次数
awk '{if($NF=="\"HIT\""){HIT++}}END{printf "%.2f",HIT/NR}' /usr/local/nginx/logs/wnn.211.host.access.log 统计出来缓存的命中率
$NF 表示的最后一个Field(列),即输出最后一个字段的内容
NF 表示的是浏览记录的域的个数
NR表示已经读取的记录数;
十一、Nginx性能优化之静态资源压缩
nginx.conf配置
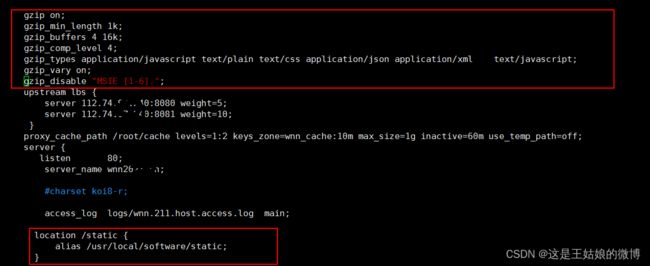
#开启gzip,减少我们发送的数据量
gzip on;
gzip_min_length 1k;
#4个单位为16k的内存作为压缩结果流缓存
gzip_buffers 4 16k;
#gzip压缩比,可在1~9中设置,1压缩比最小,速度最快,9压缩比最大,速度最慢,消耗CPU
gzip_comp_level 4;
#压缩的类型
gzip_types application/javascript text/plain text/css application/json application/xml text/javascript;
#给代理服务器用的,有的浏览器支持压缩,有的不支持,所以避免浪费不支持的也压缩,所以根据客户端的HTTP头来判断,是否需要压缩
gzip_vary on;
#禁用IE6以下的gzip压缩,IE某些版本对gzip的压缩支持很不好
gzip_disable "MSIE [1-6].";
wnn.js压缩前115k。

压缩后36k:节省了很多带宽

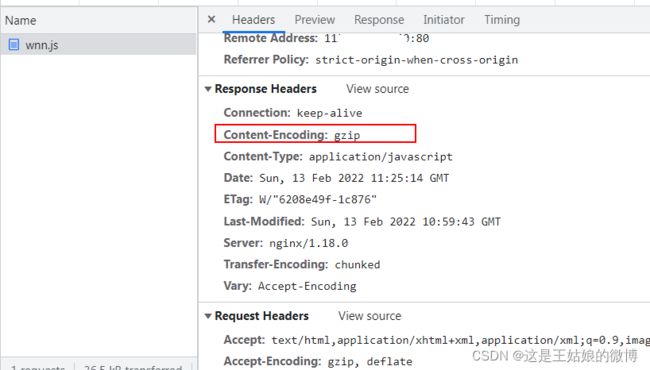
压缩是需要耗费CPU的,那么这种压缩是时间换空间还是空间换时间呢?
开启压缩后
在服务端是时间换空间的策略,服务端需要牺牲时间进行压缩以减小响应数据大小
压缩后的内容可以获得更快的网络传输速度,时间是得到了优化
所以是双向的
钻石玩法
一、Nginx和Https的那些事
1.1 什么是Https,和http的区别
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,是身披SSL外壳的HTTP
HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。
为什么要用呢
HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 HTTP 协议安全,可防止数据在传输过程中被窃取、改变,确保数据的完整性
流程
秘钥交换使用非对称加密,内容传输使用对称加密的方式

1.2、阿里云免费https证书申请和准备
证书申请->审核等待
https://common-buy.aliyun.com/?commodityCode=cas

点击购买-->支付-->进入申请证书页面 填入备案好的域名和联系人

申请后点击审核,预计1个多小时审核完成


审核通过就是已签发的状态
点击列表中的下载
将下载后的文件解压缩后,上传到指定目录中
1.3 阿里云 Nginx配置https证书配置实操
停止nginx.删除原先的nginx,新增ssl模块
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module
make
make install
#查看是否成功
/usr/local/nginx/sbin/nginx -V
新增ssl模块:![]()
配置如下:
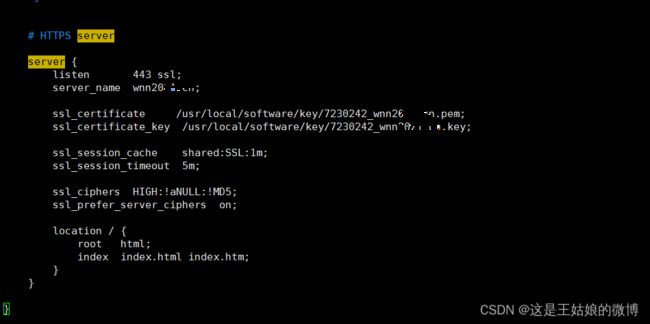

注意事项:防火墙关闭或者开放443端口 service firewalld stop
二、Nginx的第三方利器OpenResty+Lua介绍
2.1 什么是OpenResty, 为什么要用OpenResty?
是基于Ngnix和Lua的高性能web平台,内部集成精良的LUa库、第三方模块、依赖, 开发者可以方便搭建能够处理高并发、扩展性极高的动态web应用、web服务、动态网关。
OpenResty将Nginx核心、LuaJIT、许多有用的Lua库和Nginx第三方模块打包在一起
Nginx是C语言开发,如果要二次扩展是很麻烦的,而基于OpenResty,开发人员可以使用 Lua 编程语言对 Nginx 核心模块进行二次开发拓展
性能强大,OpenResty可以快速构造出1万以上并发连接响应的超高性能Web应用系统
官网:http://openresty.org
让Web 服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL, Memcaches 以及 Redis 等都进行一致的高性能响应。
所以对于一些高性能的服务来说,可以直接使用 OpenResty 访问 Mysql或Redis等,而不需要通过第三方语言(PHP、Python、Ruby)等来访问数据库再返回,这大大提高了应用的性能
2.2 Lua脚本介绍
官网:http://www.lua.org/start.html
Lua 由标准 C 编写而成,没有提供强大的库,但可以很容易的被 C/C++ 代码调用,也可以反过来调用 C/C++ 的函数。
在应用程序中可以被广泛应用,不过Lua是一种脚本/动态语言,不适合业务逻辑比较重的场景,适合小巧的应用场景,代码行数保持在几十行到几千行。
LuaJIT 是采用 C 和汇编语言编写的 Lua 解释器与即时编译器
2.3 什么是ngx_lua
ngx_lua是Nginx的一个模块,将Lua嵌入到Nginx中,从而可以使用Lua来编写脚本,部署到Nginx中运行,
即Nginx变成了一个Web容器;开发人员就可以使用Lua语言开发高性能Web应用了。
2.4 OpenResty提供了常用的ngx_lua开发模块
lua-resty-memcached
lua-resty-mysql
lua-resty-redis
lua-resty-dns
lua-resty-limit-traffic
通过上述的模块,可以用来操作 mysql数据库、redis、memcached等,也可以自定义模块满足其他业务需求,
很多经典的应用,比如开发缓存前置、数据过滤、API请求聚合、AB测试、灰度发布、降级、监控、限流、防火墙、黑白名单等
2.5 OpenResty安装 linux centos7安装
# add the yum repo:
wget https://openresty.org/package/centos/openresty.repo
sudo mv openresty.repo /etc/yum.repos.d/
# update the yum index:
sudo yum check-update
sudo yum install openresty
#安装命令行工具
sudo yum install openresty-resty
# 列出所有 openresty 仓库里的软件包
sudo yum --disablerepo="*" --enablerepo="openresty" list available
#查看版本
resty -V
 2.6 讲解Nginx+OpenRestry开发第一个例子
2.6 讲解Nginx+OpenRestry开发第一个例子
Nginx+OpenRestry开发
编辑:/usr/local/openresty/nginx/conf/nginx.conf
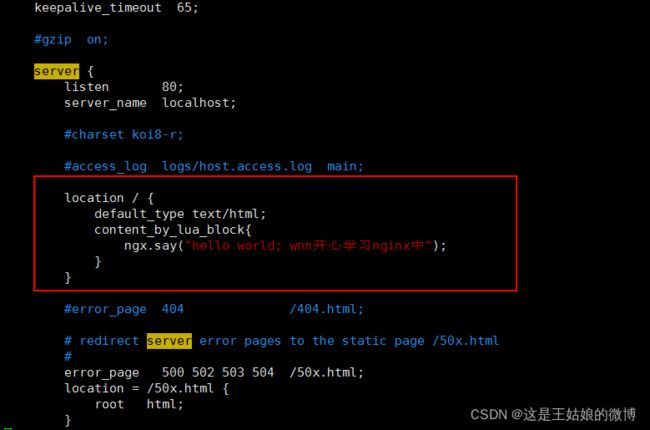
然后启动Nginx 访问 curl 127.0.0.1 就可以看到在nginx.conf里面用lua脚本写的文字

nginx对于请求的处理分多个阶段,Nginx , 从而让第三方模块通过挂载行为在不同的阶段来控制, 大致如下
初始化阶段(Initialization Phase)
init_by_lua_file
init_worker_by_lua_file
重写与访问阶段(Rewrite / Access Phase)
rewrite_by_lua_file
access_by_lua_file内容生成阶段(Content Phase)
content_by_lua_file日志记录阶段(Log Phase)
2.7 Nginx+OpenRestry开发网络访问限制(黑名单)实操
黑名单:生产环境-管理后台有的需要限制频繁访问的网段/ip等
下面使用Nginx+OpenRestry+Lua开发
http{
# 这里设置为 off,是为了避免每次修改之后都要重新 reload 的麻烦。
# 在生产环境上需要 lua_code_cache 设置成 on。
lua_code_cache off;
# lua_package_path可以配置openresty的文件寻址路径,$PREFIX 为openresty安装路径
# 文件名使用“?”作为通配符,多个路径使用“;”分隔,默认的查找路径用“;;”
# 设置纯 Lua 扩展库的搜寻路径
lua_package_path "$prefix/lualib/?.lua;;";
# 设置 C 编写的 Lua 扩展模块的搜寻路径(也可以用 ';;')
lua_package_cpath "$prefix/lualib/?.so;;";
server {
location / {
access_by_lua_file lua/black_ip_list.lua;
proxy_pass http://lbs;
}
}

lua/black_ip_list.lua

local black_ips = {["127.0.0.1"]=true} #local定义一个变量,数组里面是黑名单地址 多个可以逗号分隔开
local ip = ngx.var.remote_addr #获取业务请求的ip
if true == black_ips[ip] then #判断ip是否存在数组内
ngx.exit(ngx.HTTP_FORBIDDEN) #存在数组内,则为true,为黑名单列表 ,则终止请求,返回403页面
return;
end
./nginx -s reload 重启后访问地址:
 2.8 Nginx+OpenRestry开发下载限速实操
2.8 Nginx+OpenRestry开发下载限速实操
限速限流应用场景
下载限速:保护带宽及服务器的IO资源
请求限流:防止恶意攻击,保护服务器及资源安全
限制某个用户在一个给定时间段内能够产生的HTTP请求数
限流用在保护上游应用服务器不被在同一时刻的大量用户访问
openResty下载限速案例实操
Nginx 有一个 $limit_rate,这个反映的是当前请求每秒能响应的字节数, 该字节数默认为配置文件中 limit_rate 指令的设值


./nginx -s reload 重启后wget访问jar地址进行下载 下载的大小控制在300kb上下浮动,这样就完成了下载的限速
wget "127.0.0.1/download/demo-1.jar"

2.9 下载限速实现原理
下载限速实现原理
目的:限制下载速度
常用的是漏桶原理和令牌桶原理
什么是漏桶算法
备注:如果是请求限流,请求先进入到漏桶里,漏桶以固定的速度出水,也就是处理请求,当水加的过快也就是请求过多,
桶就会直接溢出,也就是请求被丢弃拒绝了,所以漏桶算法能强行限制数据的传输速率或请求数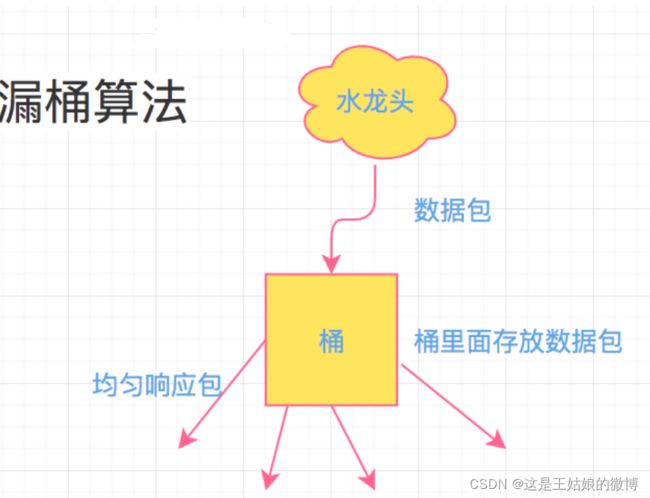
什么是令牌桶算法
备注:只要突发并发量不高于桶里面存储的令牌数据,就可以充分利用好机器网络资源。
如果桶内令牌数量小于被消耗的量,则产生的令牌的速度就是均匀处理请求的速度

三、全链路高可用之Nginx基础架构问题分析
3.1 Nginx单点问题剖析
Nginx反向代理单点故障分析
dns轮训多个ip,假如某个nginx挂了,怎么办

Nginx集群架构(vip 虚拟IP)
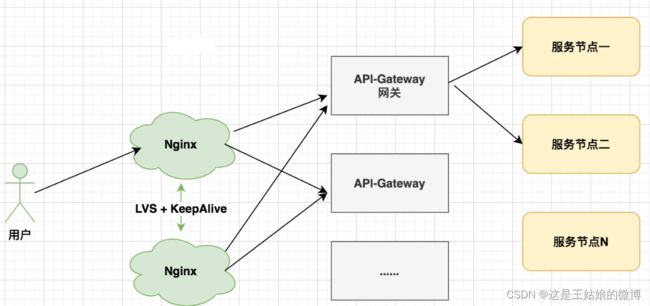
Nginx高可用解决方案-基础
国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系。
从低到高分别是:物理层、数据链路层、网络层、传输层、会话层、表示层和应用层
四层工作在第四层 也就是传输层 七层工作在最高层,也就是应用层
F5、LVS(四层负载 tcp)
用虚拟ip+port接收请求,再转发到对应的真实机器
HAproxy、Nginx(七层负载)
用虚拟的url或主机名接收请求,再转向相应的处理服务器
3.2 主流高可用方案Linux虚拟服务器 LVS
什么是LVS
官网 www.linuxvirtualserver.org
LVS是Linux Virtual Server,Linux虚拟服务器,是一个虚拟的服务器集群系统
Linux2.4 内核以后,LVS 已经是 Linux 标准内核的一部分
软件负载解决的两个核心问题是:选谁、转发

提供了10多种调度算法: 轮询、加权轮询、最小连接、目标地址散列、源地址散列等
三种负载均衡转发技术
NAT:数据进出都通过 LVS, 前端的Master既要处理客户端发起的请求,又要处理后台RealServer的响应信息,将RealServer响应的信息再转发给客户端, 容易成为整个集群系统性能的瓶颈; (支持任意系统且可以实现端口映射)
DR: 移花接木,最高效的负载均衡规则,前端的Master只处理客户端的请求,将请求转发给RealServer,由后台的RealServer直接响应客户端,不再经过Master, 性能要优于LVS-NAT; 需要LVS和RS集群绑定同一个VIP(支持多数系统,不可以实现端口映射)
TUNL(用的比较少):隧道技术,前端的Master只处理客户端的请求,将请求转发给RealServer,然后由后台的RealServer直接响应客户端,不再经过Master;(支持少数系统,不可以实现端口映射))
3.3 主流高可用方案keepalived
什么是keepalived
核心:监控并管理 LVS 集群系统中各个服务节点的状态
keepalived是一个类似于交换机制的软件,核心作用是检测服务器的状态,如果有一台web服务器工作出现故障,Keepalived将检测到并将有故障的服务器从系统中剔除,使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成。
后来加入了vrrp(虚拟路由器冗余协议),除了为lvs提供高可用还可以为其他服务器比如Mysql、Haproxy等软件提供高可用方案
#安装keepalived
yum install -y keepalived
#默认路径
cd /etc/keepalived
192.168.159.146 是从backup节点 192.168.159.145是master节点

启动和查看命令
#启动
service keepalived start
#停止
service keepalived stop
#查看状态
service keepalived status
#重启
service keepalived restart
#停止防火墙
systemctl stop firewalld.service
注意: 如果有缺少依赖可以执行下面的命令
yum install -y gcc
yum install -y openssl-devel
yum install -y libnl libnl-devel
yum install -y libnfnetlink-devel
yum install -y net-tools
yum install -y vim wget
3.4 Keepalived核心配置介绍
master配置如下:
注意:括号里面红色的标注是backup配置
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL # 设置lvs的id,在一个网络内应该是唯一的
enable_script_security #允许执行外部脚本
}
#配置vrrp_script,主要用于健康检查及检查失败后执行的动作。
vrrp_script chk_real_server {
#健康检查脚本,当脚本返回值不为0时认为失败
script "/usr/local/software/conf/chk_server.sh"
#检查频率,以下配置每2秒检查1次
interval 2
#当检查失败后,将vrrp_instance的priority减小5
weight -5
#连续监测失败3次,才认为真的健康检查失败。并调整优先级
fall 3
#连续监测2次成功,就认为成功。但不调整优先级
rise 2user root
}#配置对外提供服务的VIP vrrp_instance配置
vrrp_instance VI_1 {
#指定vrrp_instance的状态,是MASTER还是BACKUP主要还是看优先级。
state MASTER(BACKUP)#指定vrrp_instance绑定的网卡,最终通过指定的网卡绑定VIP
interface ens33#相当于VRID,用于在一个网内区分组播,需要组播域内内唯一。
virtual_router_id 51#本机的优先级,VRID相同的机器中,优先级最高的会被选举为MASTER
priority 100(50)#心跳间隔检查,默认为1s,MASTER会每隔1秒发送一个报文告知组内其他机器自己还活着。
advert_int 1#密码 鉴权,密码不超过8位数,配置了同样密码的 才加入keepalived的服务
authentication {
auth_type PASS
auth_pass 1111
}#定义虚拟IP(VIP)为192.168.159.100,可多设,每行一个
virtual_ipaddress {
192.168.159.100
}#本vrrp_instance所引用的脚本配置,名称就是vrrp_script 定义的容器名
track_script {
chk_real_server
}
}# 定义对外提供服务的LVS的VIP以及port
virtual_server 192.168.159.100 80 {
# 设置健康检查时间,单位是秒
delay_loop 6# 设置负载调度的算法为rr
lb_algo rr# 设置LVS实现负载的机制,有NAT、TUN、DR三个模式
lb_kind NAT# 会话保持时间
persistence_timeout 50#指定转发协议类型(TCP、UDP)
protocol TCP# 指定real server1的IP地址
real_server 192.168.159.145(192.168.159.146) 80 {
# 配置节点权值,数字越大权重越高
weight 1# 健康检查方式
TCP_CHECK { # 健康检查方式
connect_timeout 10 # 连接超时
retry 3 # 重试次数
delay_before_retry 3 # 重试间隔
connect_port 80 # 检查时连接的端口
}}
}
3.5 准备Nginx+Lvs+KeepAlive相关验证
演示验证结果:
如果其中keepalived挂了,那就会vip就会分发到另外一个keepalived节点,响应正常
更改192.168.159.146 backup index.html

192.168.159.146 backup nginx.conf 是从nginx.conf.default中复制出来的,没有额外的配置。改完后直接重启nginx即可
 访问 192.168.159.146页面:
访问 192.168.159.146页面:

同样操作更改192.168.159.145 master index.html改成如下

192.168.159.145 nginx.conf 是从nginx.conf.default中复制出来的,没有额外的配置。改完后直接重启nginx即可 
访问 192.168.159.145 页面:
#启动 keepalived
service keepalived start
#查看状态
service keepalived status
现在是有2个IP 原先就只有一个 192.168.159.145。192.168.159.100是虚拟IP

正常情况下通过 192.168.159.100访问的是master 192.168.159.145 节点

当master节点挂了的时候,192.168.159.100会漂移到192.168.159.146 backup节点上(此时backup会暂时变成master)。当master节点重新恢复启动的时候,依然会是master节点。

如果某个realServer挂了,比如是Nginx挂了,那对应keepalived节点存活依旧可以转发过去,但是响应失败
先将master 里面的nginx 停掉。即使LVS节点存活,但是realServer挂了 也还是会访问出错。这种情况应该怎么办?

3.6 Nginx+Lvs+KeepAlive高可用方案实施
解决的问题:如果某个realServer挂了,比如是Nginx挂了,那对应keepalived节点存活依旧可以转发过去,但是响应失败
脚本监听:
2个节点都做如下操作 master backup

chk_server.sh脚本内容(需要 chmod +x chk_server.sh)
#!/bin/bash
#检查nginx进程是否存在
counter=$(ps -C nginx --no-heading|wc -l)
if [ "${counter}" -eq "0" ]; then
service keepalived stop
echo 'nginx server is died.......'
fi

ps -C nginx --no-heading|wc -l 查看当前nginx的进程有几个是活的,当进程数是0的时候,则认定nginx死亡,就将本机的keepalived stop。keepalived stop后,虚拟IP将会漂移到另外一个服务器上。
#配置vrrp_script,主要用于健康检查及检查失败后执行的动作。
vrrp_script chk_real_server {
#健康检查脚本,当脚本返回值不为0时认为失败
script "/usr/local/software/conf/chk_server.sh"
#检查频率,以下配置每2秒检查1次
interval 2
#当检查失败后,将vrrp_instance的priority减小5
weight -5
#连续监测失败3次,才认为真的健康检查失败。并调整优先级
fall 3
#连续监测2次成功,就认为成功。但不调整优先级
rise 2
user root
}
上面这段配置要放在每个nginx所在服务 部署的keepalived的配置文件中

注意!注意!注意!
常见问题:
vip能ping通,vip监听的端口不通: 第一个原因:nginx1和nginx2两台服务器的服务没有正常启动
vip ping不通: 核对是否出现裂脑,常见原因为防火墙配置所致导致多播心跳失败,核对keepalived的配置是否正确
特别注意: 需要关闭selinux,不然sh脚本可能不生效getenforce 查看
setenforce 0 关闭
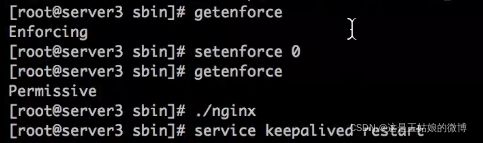
关闭后再重新启动nginx sh脚本就可以生效了。
总结篇
master 进程负责管理 Nginx 本身和其他 worker 进程

高性能原理
nginx 通过 多进程 + io多路复用(epoll) 实现了高并发
采用多个worker 进程实现对 多cpu 的利用 通过eopll 对 多个文件描述符 事件回调机制

linux I/O多路复用有select,poll,epoll
I/O模式一般分为同步IO和异步IO。
同步IO会阻塞进程,异步IO不会阻塞进程。
目前linux上大部分用的是同步IO,异步IO在linux上还不太成熟(有部分)
同步IO又分为阻塞IO,非阻塞IO,IO多路复用, 很多人对这个就有疑问了????
同步IO会阻塞进程,为什么也包括非阻塞IO? 因为非阻塞IO虽然在请求数据时不阻塞,但真正数据来临时,也就是内核数据拷贝到用户数据时,此时进程是阻塞的。