异配图神经网络——Graph Transformer Networks
一.论文概述
作者提出了Graph Transformer Network (GTN)用来在异配图(heterogeneous graph)上学习节点表示。通过Graph Transformer层,模型能将异构图转换为由meta-path定义的多个新图,这些meta-paths具有任意的边类型和长度,通过在学得的meta-path对应的新图上进行卷积能获取更有效的节点表示。在几个异配图数据集上的实验结果也验证了GTN的有效性。
二.预备知识
假设 T v \mathcal{T}^v Tv和 T e \mathcal{T}^e Te 分别表示节点类型和边类型,对于给定图 G = ( V , E ) G=(V,E) G=(V,E),其中 V V V是节点集, E E E是边集,节点类型映射函数为 f v : V → T v f_v: V \rightarrow \mathcal{T}^v fv:V→Tv,边类型映射函数为 f e : E → T e f_e: E \rightarrow \mathcal{T}^e fe:E→Te。当 ∣ T e ∣ = 1 \left|\mathcal{T}^e\right|=1 ∣Te∣=1 且 ∣ T v ∣ = 1 \left|\mathcal{T}^v\right|=1 ∣Tv∣=1时,图为同配图,否则为异配图。在本文中作者考虑 ∣ T e ∣ > 1 \left|\mathcal{T}^e\right|>1 ∣Te∣>1的情况。异配图可以被表示为一个邻接矩阵 { A k } k = 1 K \left\{A_k\right\}_{k=1}^K {Ak}k=1K 的集合,其中 K = ∣ T e ∣ K=\left|\mathcal{T}^e\right| K=∣Te∣, A k ∈ R N × N A_k \in \mathbf{R}^{N \times N} Ak∈RN×N 是一个邻接矩阵,当 A k [ i , j ] A_k[i, j] Ak[i,j] 非零时,表示节点 j j j到节点 i i i间存在第 k k k中类型的边。邻接矩阵的集合可以写为 A ∈ R N × N × K \mathbb{A} \in \mathbf{R}^{N \times N \times K} A∈RN×N×K, X ∈ R N × D X \in \mathbf{R}^{N \times D} X∈RN×D 表示节点的 D D D维特征组成的矩阵。
Meta-Path:异配图 G G G上的连接异配边的路径 p p p,如 v 1 ⟶ t 1 v 2 ⟶ t 2 … ⟶ t l v l + 1 v_1 \stackrel{t_1}{\longrightarrow} v_2 \stackrel{t_2}{\longrightarrow} \ldots \stackrel{t_l}{\longrightarrow} v_{l+1} v1⟶t1v2⟶t2…⟶tlvl+1,其中 t l ∈ T e t_l \in \mathcal{T}^{e} tl∈Te表示meta-path的第 l l l类边。Meta-path定义了节点 v 1 v_1 v1到 v l + 1 v_{l+1} vl+1复合关系 R = t 1 ∘ t 2 … ∘ t l R=t_1 \circ t_2 \ldots \circ t_l R=t1∘t2…∘tl,其中 R 1 ∘ R 2 R_1 \circ R_2 R1∘R2表示关系由 R 1 R_1 R1和 R 2 R_2 R2组成。给定复合关系 R R R或边类型序列 ( t 1 , t 2 , … , t l ) \left(t_1, t_2, \ldots, t_l\right) (t1,t2,…,tl),meta-path P P P对应的邻接矩阵 A P A_{\mathcal{P}} AP可以通过邻接矩阵乘法来获取:
A P = A t l … A t 2 A t 1 A_{\mathcal{P}}=A_{t_l} \ldots A_{t_2} A_{t_1} AP=Atl…At2At1
meta-path的概念包含多跳连接,作者的框架中新图结构由邻接矩阵表示。
Graph Convolutional Network (GCN):假设 H ( l ) H^{(l)} H(l)为GCN第 l l l层的特征表示,则GCN的传播规则为:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中 A ~ = A + I ∈ R N × N \tilde{A}=A+I \in \mathbf{R}^{N \times N} A~=A+I∈RN×N是添加了自环的邻接矩阵, D ~ \tilde{D} D~是与之对应的度矩阵。在GCN中图上的卷积操作由图结构来确定(图结构不可学习),只有节点的层特征表示包含一个线性变换 H ( l ) W ( l ) H^{(l)} W^{(l)} H(l)W(l)。在作者的框架中,图结构是可以学习的,这使得可以从不同的卷积中获益。
对于有向图,作者采用入度对角矩阵来对 A ~ \tilde{A} A~进行正则化,即 D ~ − 1 2 A ~ \tilde{D}^{-\frac{1}{2}} \tilde{A} D~−21A~。
三.Meta-Path的生成
先前的工作中meta-paths需要人工构造,而Graph Transformer Networks却可以通过给定的数据和任务来学习meta-paths,然后对学到的meta-paths进行图卷积。
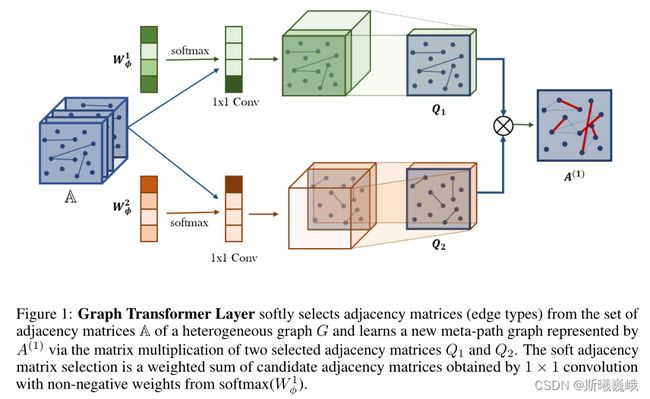
Graph Transformer (GT)层中meta-path的生成由两个组件。首先GT层从候选邻接矩阵 A \mathbb{A} A中软选择两个图结构 Q 1 Q_1 Q1和 Q 2 Q_2 Q2,然后复合两种关系来学得一个新图结构( Q 1 Q_1 Q1和 Q 2 Q_2 Q2间的矩阵乘法)。
软选择的具体过程:通过 1 × 1 1 \times 1 1×1卷积获取候选邻接矩阵的加权和,正式计算公式为:
Q = F ( A ; W ϕ ) = ϕ ( A ; softmax ( W ϕ ) ) Q=F\left(\mathbb{A} ; W_\phi\right)=\phi\left(\mathbb{A} ; \operatorname{softmax}\left(W_\phi\right)\right) Q=F(A;Wϕ)=ϕ(A;softmax(Wϕ))
其中 ϕ \phi ϕ是卷积层, W ϕ ∈ R 1 × 1 × K W_\phi \in \mathbf{R}^{1 \times 1 \times K} Wϕ∈R1×1×K是 ϕ \phi ϕ的参数。加上 softmax \text{softmax} softmax能获取类似channel attention的效果。
另外,在生成meta-path邻接矩阵时为了数值稳定,作者还使用度矩阵来对其进行正则化,即 A ( l ) = D − 1 Q 1 Q 2 A^{(l)}=D^{-1} Q_1 Q_2 A(l)=D−1Q1Q2。
理论证明:GTN是否可以学到关于边类型和路径长度的任意meta-path
任意长度为 l l l的元路径对应的邻接矩阵 A P A_P AP可以通过如下公式计算得到:
A P = ( ∑ t 1 ∈ T e α t 1 ( 1 ) A t 1 ) ( ∑ t 2 ∈ T e α t 2 ( 2 ) A t 2 ) ⋯ ( ∑ t l ∈ T e α t l ( l ) A t l ) A_P=\left(\sum_{t_1 \in \mathcal{T}^e} \alpha_{t_1}^{(1)} A_{t_1}\right)\left(\sum_{t_2 \in \mathcal{T}^e} \alpha_{t_2}^{(2)} A_{t_2}\right) \cdots\left(\sum_{t_l \in \mathcal{T}^e} \alpha_{t_l}^{(l)} A_{t_l}\right) AP=(t1∈Te∑αt1(1)At1)(t2∈Te∑αt2(2)At2)⋯(tl∈Te∑αtl(l)Atl)
其中 α t l ( l ) \alpha_{t_l}^{(l)} αtl(l)表示第 l l l个GT层中边类型 t l t_l tl对应的权重, A P A_P AP可以看作所有长度为 l l l的元路径邻接矩阵的加权和,因此堆叠 l l l个GT层能够学习任意长度为 l l l的meta-path结构(参见图2)。
这也存在一个问题,添加GT层会增加meta-path的长度,这将使得原始边被忽略。在一些应用中,长meta-path和短meta-path都很重要,为了学习短和长元路径(包括原始边),作者在候选邻接矩阵中添加了单位阵。该trick使得当堆叠 l l l个GT层时,允许GTN学习任意长度的meta-path,最长可达 l + 1 l+1 l+1。
四.Graph Transformer Networks
同普通的图像卷积类似,可以使用多个卷积核(作者设置为 C C C)来同时考虑多种类型的meta-path,然后生成一个meta-paths集,中间邻接矩阵 Q 1 Q_1 Q1和 Q 2 Q_2 Q2则变成邻接张量 Q 1 \mathbb{Q}_1 Q1 和 Q 2 ∈ R N × N × C \mathbb{Q}_2 \in \mathbf{R}^{N \times N \times C} Q2∈RN×N×C(参见图2)。通过多个不同的图结构学习不同的节点表示是有益的。作者在堆叠了 l l l个GT层之后,在meta-path张量的每个channel上应用相同的GCN,然后将多个节点特征进行拼接:
Z = ∥ i = 1 C σ ( D ~ i − 1 A ~ i ( l ) X W ) Z=\|_{i=1}^C \sigma\left(\tilde{D}_i^{-1} \tilde{A}_i^{(l)} X W\right) Z=∥i=1Cσ(D~i−1A~i(l)XW)
从上式可知, Z Z Z包含了来自 C C C个不同meta-path图的节点表示,然后将其应用于下游的分类任务。

五.实验部分
作者采用三个异配数据集来进行实验,数据集的统计特征如下表所示:

实验一:节点分类实验

结论:
- 从GTN的性能比所有的baseline要好可以看出,GTN学得的新图结构包含用于学习更有效节点表示的有用meta-path。此外,与baseline中具有常数的简单meta-path邻接矩阵相比,GTN能为边分配可变权重。
- 在表2中 GTN − I \text{GTN}_{-I} GTN−I表示候选邻接矩阵中没有 I I I,从结果可以看出其性能比包含 I I I的要差,证明了添加单位阵的有效性。
实验二:GTN的解释实验
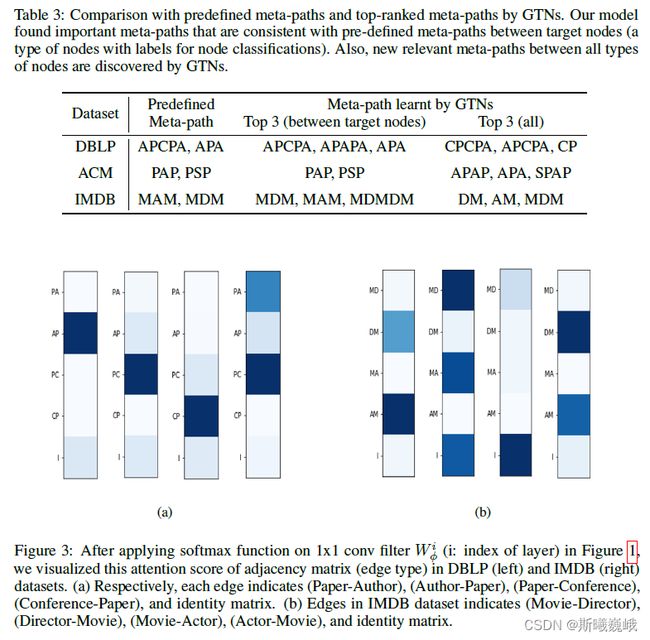
作者经过公式推导得出,一条meta-path t l , t l − 1 , . . . , t 0 t_l, t_{l-1},...,t_0 tl,tl−1,...,t0的贡献度能通过 ∏ i = 0 l α t i ( i ) \prod_{i=0}^{l}\alpha_{t_i}^{(i)} ∏i=0lαti(i)进行获取,它表明了meta-path在预测任务上的重要程度。表3展示了文献中广泛使用的预定义meta-paths,以及GTN学习的具有高注意力分数的meta-paths。
结论:
- 从表3可以看出,通过领域知识预定义的meta-paths与GTN中学得的排名靠前的meta-paths一致。这表明GTN能学习任务meta-path的重要性。此外,GTN还挖掘了不包含在预定义meta-path集的meta-paths。
- 图3展示了每个GT层的邻接矩阵的注意力分数,(a)为DBLP,(b)为IMDB。与DBLP相比,单位阵在IMDB中有更高的注意力分数。通过给单位阵分配更高的注意力分数,GTN试图坚持更短的meta-paths,即使在更深的层。这表明GTN更根据数据集自适应学习最有效的meta-path的能力。