TensorFlow 深度学习第二版:1~5
原文:Deep Learning with TensorFlow Second Edition
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、人工神经网络
人工神经网络利用了 DL 的概念 。它们是人类神经系统的抽象表示,其中包含一组神经元,这些神经元通过称为轴突的连接相互通信。
Warren McCulloch 和 Walter Pitts 在 1943 年根据神经活动的计算模型提出了第一个人工神经元模型。这个模型之后是 John von Neumann,Marvin Minsky,Frank Rosenblatt(所谓的感知器)和其他许多人提出的另一个模型。
生物神经元
看一下大脑的架构灵感。大脑中的神经元称为生物神经元。它们是看起来不寻常的细胞,主要存在于动物大脑中,由皮质组成。皮质本身由细胞体组成,细胞体包含细胞核和细胞的大部分复杂成分。有许多称为树突的分支延伸,加上一个称为轴突的非常长的延伸。
在它的极端附近,轴突分裂成许多分支称为终树突,并且在这些分支的顶部是称为突触末端(或简单的突触)的微小结构,连接到其他神经元的树突。生物神经元接收称为来自其他神经元的信号的短电脉冲,作为回应,它们发出自己的信号:
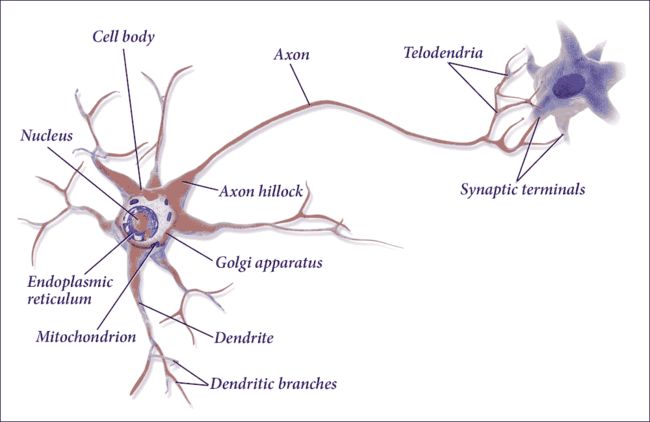
图 7:生物神经元的工作原理。
在生物学中,神经元由以下组成:
- 细胞体或体细胞
- 一个或多个树突,其职责是接收来自其他神经元的信号
- 轴突,反过来将同一神经元产生的信号传递给其他连接的神经元
神经元的活动在发送/接收来自其他神经元的信号(活动状态)和休息(非活动状态)之间交替。从一个相到另一个相的转变是由外部刺激引起的,由树枝状晶体拾取的信号表示。每个信号具有兴奋或抑制作用,在概念上由与刺激相关的权重表示。
处于空闲状态的神经元累积它收到的所有信号,直到达到某个激活阈值。
人工神经元
基于生物神经元的概念,出现了人工神经元的术语和思想,它们已被用于构建基于 DL 的预测分析的智能机器。这是启发人工神经网络的关键理念。与生物神经元类似,人工神经元由以下部分组成:
-
一个或多个传入连接,其任务是从其他神经元收集数字信号:为每个连接分配一个权重,用于考虑发送的每个信号
-
一个或多个输出连接,将信号传递给其他神经元
-
激活函数,基于一些信号确定输出信号的数值,信号从和其他神经元的输入连接接受,并从权重和神经元本身的激活阈值中适当地收集,权重与每个接收信号相关:

图 8:人工神经元模型。
通过将激活函数(也称为传递函数)应用于输入的加权和来计算输出,即神经元传输的信号。这些函数的动态范围介于 -1 和 1 之间,或介于 0 和 1 之间。许多激活函数在复杂性和输出方面有所不同。在这里,我们简要介绍三种最简单的形式:
- 阶跃函数:一旦我们确定阈值
x(例如,x = 10),如果输入之和高于阈值,该函数将返回 1,否则则返回 0。 - 线性组合:不管理阈值,而是从默认值中减去输入值的加权和。我们将得到二元结果,该结果将由减法的正(+b)或负(-b)输出表示。
- Sigmoid:这会产生 Sigmoid 曲线,这是一条具有 S 趋势的曲线。通常,sigmoid 函数指的是逻辑函数的特殊情况。
从第一个人工神经元原型制作中使用的最简单的形式,我们转向更复杂的形式,可以更好地表征神经元的功能:
-
双曲正切函数
-
径向基函数
-
圆锥截面函数
-
Softmax 函数

图 9:最常用的人工神经元模型传递函数。(a)阶梯函数(b)线性函数(c)sigmoid 函数,计算值介于 0 和 1 之间(d)sigmoid 函数,计算值介于 -1 和 1 之间。
选择适当的激活函数(也是权重初始化)是使网络发挥最佳表现并获得良好训练的关键。这些主题正在进行大量研究,如果训练阶段正确进行,研究表明在产出质量方面存在微小差异。
注意
在神经网络领域没有经验法则。这一切都取决于您的数据以及在通过激活函数后希望数据转换的形式。如果要选择特定的激活函数,则需要研究函数的图形,以查看结果如何根据给定的值进行更改。
ANN 如何学习?
神经网络的学习过程被配置为权重优化的迭代过程,因此是监督类型。由于网络在属于训练集的一组示例上的表现(即,您知道示例所属的类的集合),因此修改权重。
目的是最小化损失函数,其表示网络行为偏离期望行为的程度。然后在由除了训练集中的对象之外的对象(例如,图像分类问题中的图像)组成的测试集上验证网络的表现。
人工神经网络和反向传播算法
常用的监督学习算法是反向传播算法。训练程序的基本步骤如下:
- 用随机权重初始化网络
- 对于所有训练案例,请按照下列步骤操作:
-
正向传播:计算网络的误差,即所需输出与实际输出之间的差值
-
向后传递:对于所有层,从输出层回到输入层:
i:使用正确的输入显示网络层的输出(误差函数)。
ii:调整当前层中的权重以最小化误差函数。这是反向传播的优化步骤。
-
当验证集上的误差开始增加时,训练过程结束,因为这可能标志着阶段过拟合的开始,即网络倾向于以牺牲训练数据为代价来内插训练数据的阶段。普遍性。
权重优化
因此, 优化权重的有效算法的可用性构成了构建神经网络的必要工具。该问题可以通过称为梯度下降(GD)的迭代数值技术来解决。该技术根据以下算法工作:
- 随机选择模型参数的初始值
- 根据模型的每个参数计算误差函数的梯度 G.
- 更改模型的参数,使它们朝着减小误差的方向移动,即沿 -G 方向移动
- 重复步骤 2 和 3,直到 G 的值接近零
误差函数 E 的梯度(G)提供了误差函数与当前值具有更陡斜率的方向;所以为了减少 E,我们必须在相反的方向上做一些小步骤,-G。
通过以迭代方式多次重复此操作,我们向下移动到 E 的最小值,以达到G = 0的点,从而无法进一步进展:
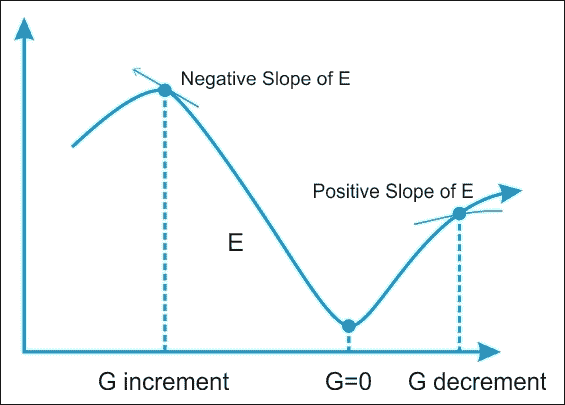
图 10:搜索误差函数 E 的最小值。我们沿着函数 E 的梯度 G 最小的方向移动。
随机梯度下降
在 GD 优化中,我们基于完整的训练集计算成本梯度,因此我们有时也将其称为批量 GD。在非常大的数据集的情况下,使用 GD 可能非常昂贵,因为我们在训练集上只进行一次传递。训练集越大,我们的算法更新权重的速度就越慢,并且在收敛到全局成本最小值之前可能需要的时间越长。
最快的梯度下降方法是随机梯度下降(SGD),因此,它被广泛应用于深度神经网络。在 SGD 中,我们仅使用来自训练集的一个训练样本来对特定迭代中的参数进行更新。
这里,术语随机来自这样的事实:基于单个训练样本的梯度是真实成本梯度的随机近似。由于其随机性,通向全局最小成本的路径并不像 GD 那样直接,但如果我们可视化 2D 空间中的成本表面,则可能会出现锯齿形:
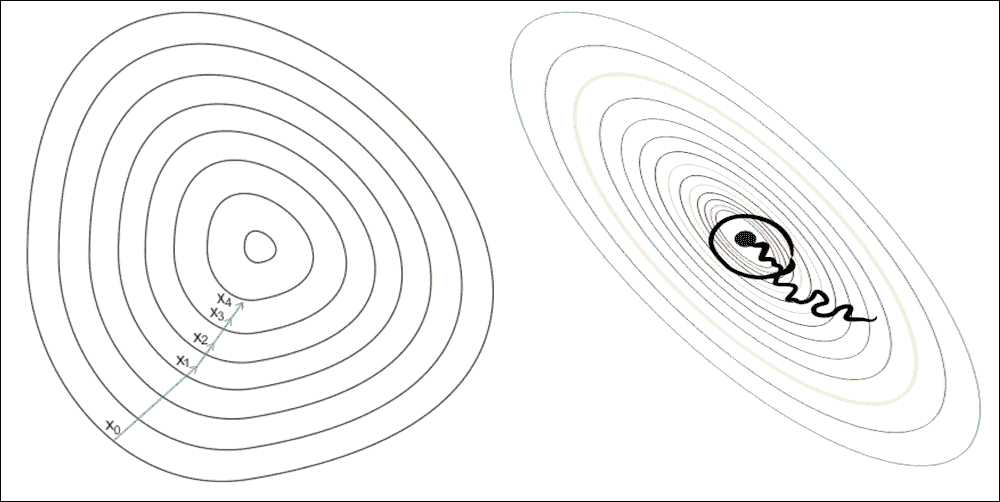
图 11:GD 与 SGD:梯度下降(左图)确保权重中的每次更新都在正确的方向上完成:最小化成本函数的方向。随着数据集大小的增长以及每个步骤中更复杂的计算,SGD(右图)在这些情况下是首选。这里,在处理每个样本时完成权重的更新,因此,后续计算已经使用了改进的权重。尽管如此,这个原因导致了在最小化误差函数方面的一些误导。
神经网络架构
我们连接节点的方式和存在的层数(即输入和输出之间的节点级别以及每层神经元的数量)定义了神经网络的架构。
神经网络中存在各种类型的架构。我们可以将 DL 架构,分为四组:深度神经网络(DNN),卷积神经网络(CNN),循环神经网络(RNN)和紧急架构(EA)。本章的以下部分将简要介绍这些架构。更多详细分析,以及应用实例,将成为本书后续章节的主题。
深度神经网络(DNN)
DNN 是人工神经网络,它们强烈地面向 DL。在正常分析程序不适用的情况下,由于要处理的数据的复杂性,因此这种网络是一种极好的建模工具。 DNN 是与我们讨论过的神经网络非常相似的神经网络,但它们必须实现更复杂的模型(更多的神经元,隐藏层和连接),尽管它们遵循适用于所有 ML 问题的学习原则(例如作为监督学习)。每层中的计算将下面层中的表示转换为稍微更抽象的表示。
我们将使用术语 DNN 将具体指代多层感知器(MLP),堆叠自编码器(SAE)和深度信任网络(DBN)。 SAE 和 DBN 使用自编码器(AEs)和 RBM 作为架构的块。它们与 MLP 之间的主要区别在于,训练分两个阶段执行:无监督的预训练和监督微调:
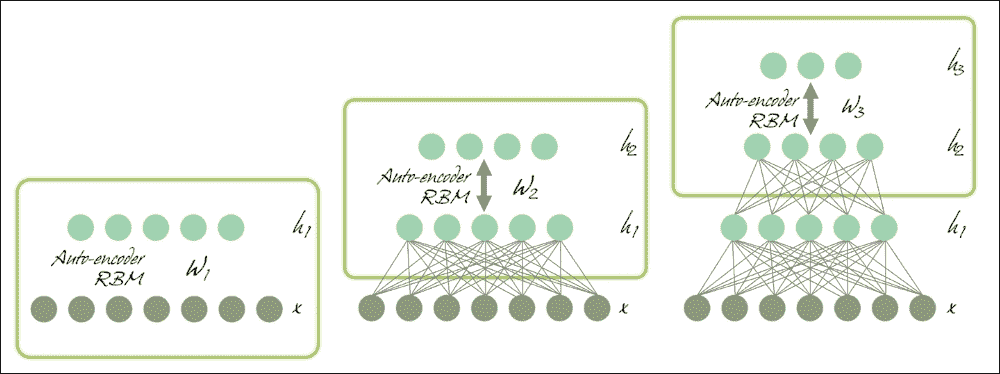
图 12:分别使用 AE 和 RBM 的 SAE 和 DBN。
在无监督预训练中,如上图所示,这些层按顺序堆叠并以分层方式进行训练,如使用未标记数据的 AE 或 RBM。然后,在有监督的微调中,堆叠输出分类器层,并通过用标记数据重新训练来优化完整的神经网络。
在本章中,我们不讨论 SAE(详见第 5 章,优化 TensorFlow 自编码器),但将坚持使用 MLP 和 DBN 并使用这两种 DNN 架构。我们将看到如何开发预测模型来处理高维数据集。
多层感知器
在多层网络中,可以识别层的人工神经元,以便每个神经元连接到下一层中的所有神经元,确保:
- 属于同一层的神经元之间没有连接
- 属于非相邻层的神经元之间没有连接
- 每层的层数和神经元数取决于要解决的问题
输入和输出层定义输入和输出,并且存在隐藏层,其复杂性实现网络的不同行为。最后,神经元之间的连接由与相邻层对相同的矩阵表示。
每个数组包含两个相邻层的节点对之间的连接的权重。前馈网络是层内没有环路的网络。
我们将在第 3 章,使用 TensorFlow 的前馈神经网络中更详细地描述前馈网络:
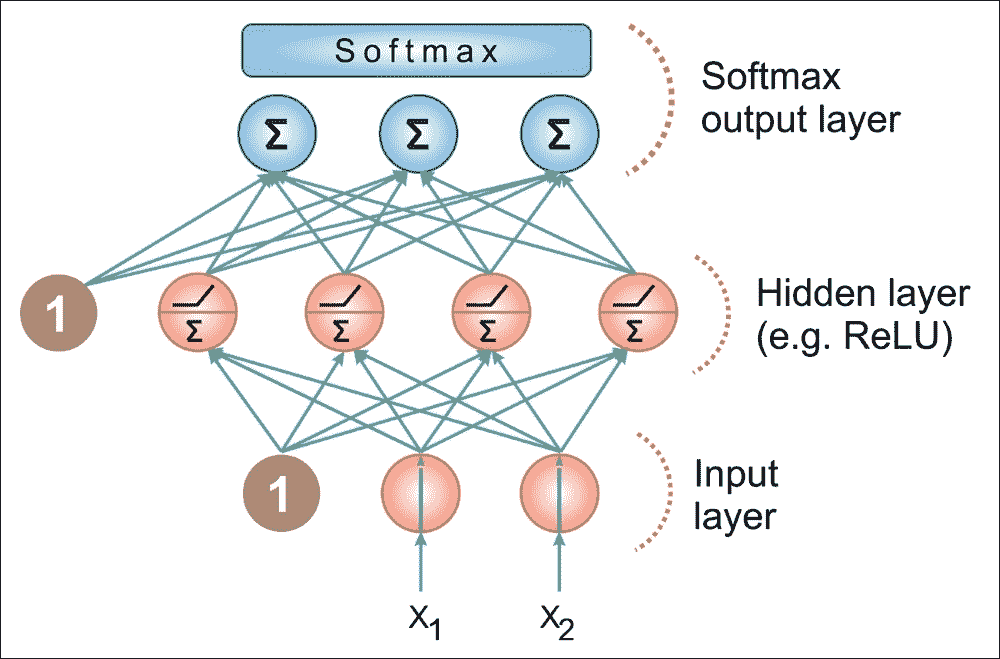
图 13:MLP 架构
深度信念网络(DBNs)
为了克服 MLP 中的过拟合问题,我们建立了一个 DBN,做了无监督预训练,为输入获得了一组不错的特征表示,然后微调训练集从网络获得实际预测。虽然 MLP 的权重是随机初始化的,但 DBN 使用贪婪的逐层预训练算法通过概率生成模型初始化网络权重。模型由可见层和多层随机和潜在变量组成,称为隐藏单元或特征检测器。
DBN 是深度生成模型,它们是神经网络模型,可以复制您提供的数据分布。这允许您从实际数据点生成“虚假但逼真”的数据点。
DBN 由可见层和多层随机潜在变量组成,这些变量称为隐藏单元或特征检测器。前两层在它们之间具有无向的对称连接并形成关联存储器,而较低层从前一层接收自上而下的有向连接。 DBN 的构建块是受限玻尔兹曼机(RBM)。如下图所示,几个 RBM 一个接一个地堆叠形成 DBN:
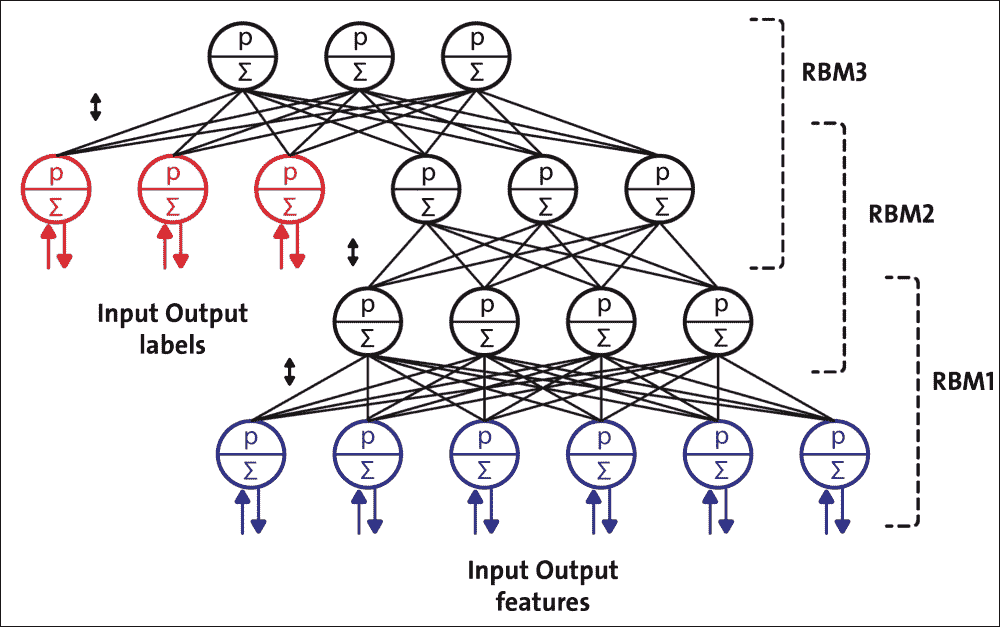
图 14:配置用于半监督学习的 DBN
单个 RBM 由两层组成。第一层由可见神经元组成,第二层由隐藏神经元组成。下图显示了简单 RBM 的结构。可见单元接受输入,隐藏单元是非线性特征检测器。每个可见神经元都连接到所有隐藏的神经元,但同一层中的神经元之间没有内部连接。
RBM 由可见层节点和隐藏层节点组成,但没有可见 - 隐藏和隐藏 - 隐藏连接,因此项受限制。它们允许更有效的网络训练,可以监督或监督。这种类型的神经网络能够表示输入的大量特征,然后隐藏的节点可以表示多达 2n 个特征。可以训练网络回答单个问题(例如,问题是或否:它是猫吗?),直到它能够(再次以二元的方式)响应总共 2n 个问题(它是猫吗? ,这是暹罗人?,它是白色的吗?)。
RBM 的架构如下,神经元根据对称的二分图排列:
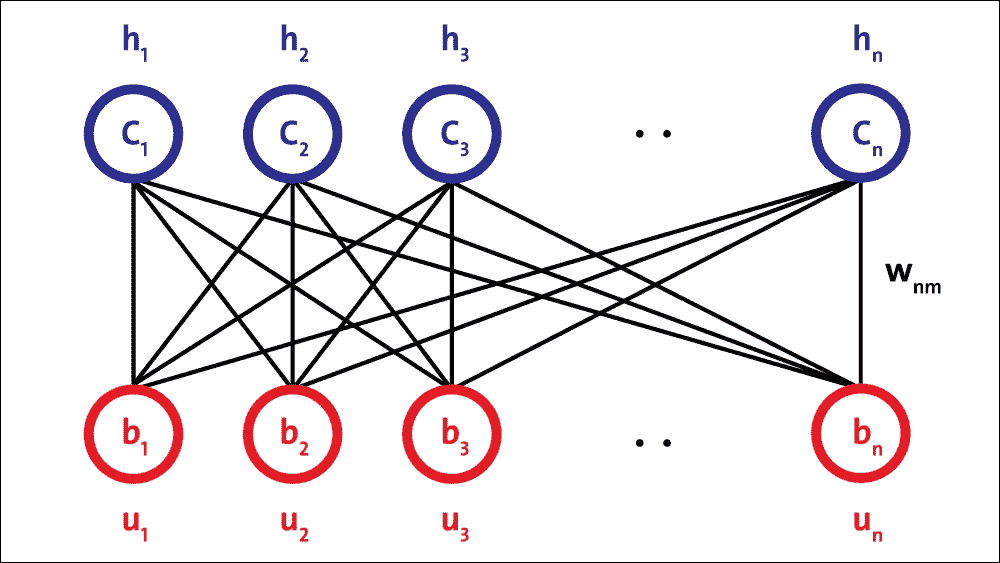
图 15:RBM 架构。
由于无法对变量之间的关系进行建模,因此单个隐藏层 RBM 无法从输入数据中提取所有特征。因此,一层接一层地使用多层 RBM 来提取非线性特征。在 DBN 中,首先使用输入数据训练 RBM,并且隐藏层表示使用贪婪学习方法学习的特征。这些第一 RBM 的学习特征,即第一 RBM 的隐藏层,被用作第二 RBM 的输入,作为 DBN 中的另一层。
类似地,第二层的学习特征用作另一层的输入。这样,DBN 可以从输入数据中提取深度和非线性特征。最后一个 RBM 的隐藏层代表整个网络的学习特征。
卷积神经网络(CNNs)
CNN 已经专门用于图像识别。学习中使用的每个图像被分成紧凑的拓扑部分,每个部分将由过滤器处理以搜索特定模式。形式上,每个图像被表示为像素的三维矩阵(宽度,高度和颜色),并且每个子部分可以与滤波器组卷积在一起。换句话说,沿着图像滚动每个滤镜计算相同滤镜和输入的内积。
此过程为各种过滤器生成一组特征图(激活图)。将各种特征图叠加到图像的相同部分上,我们得到输出量。这种类型的层称为卷积层。下图是 CNN 架构的示意图:
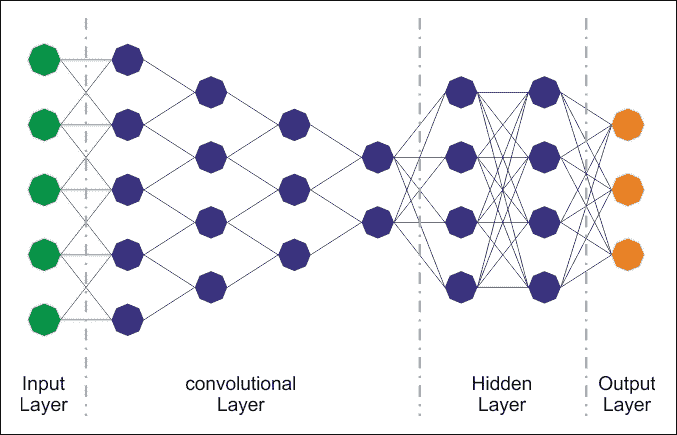
图 16:CNN 架构。
虽然常规 DNN 适用于小图像(例如,MNIST 和 CIFAR-10),但由于需要大量参数,它们会因较大的图像而崩溃。例如,100×100图像具有 10,000 个像素,并且如果第一层仅具有 1,000 个神经元(其已经严格限制传输到下一层的信息量),则这意味着 1000 万个连接。另外,这仅适用于第一层。
CNN 使用部分连接的层解决了这个问题。由于相邻层仅部分连接,并且因为它重复使用其权重,因此 CNN 的参数远远少于完全连接的 DNN,这使得训练速度更快。这降低了过拟合的风险,并且需要更少的训练数据。此外,当 CNN 已经学习了可以检测特定特征的内核时,它可以在图像上的任何地方检测到该特征。相反,当 DNN 在一个位置学习一个特征时,它只能在该特定位置检测到它。由于图像通常具有非常重复的特征,因此 CNN 在图像处理任务(例如分类)和使用较少的训练示例方面能够比 DNN 更好地推广。
重要的是,DNN 没有关于如何组织像素的先验知识;它不知道附近的像素是否接近。 CNN 的架构嵌入了这一先验知识。较低层通常识别图像的单元域中的特征,而较高层将较低层特征组合成较大特征。这适用于大多数自然图像,使 CNN 在 DNN 上具有决定性的先机:
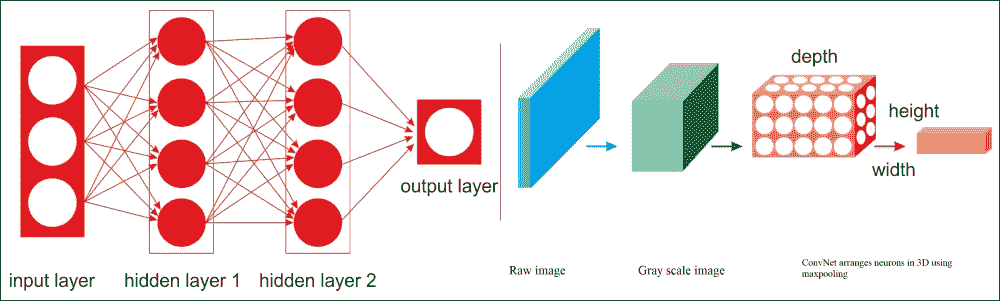
图 17:常规 DNN 与 CNN。
例如,在上图中,在左侧,您可以看到常规的三层神经网络。在右侧,CNN 以三维(宽度,高度和深度)排列其神经元,如在其中一个层中可视化。 CNN 的每一层都将 3D 输入音量转换为神经元激活的 3D 输出音量。红色输入层保持图像,因此其宽度和高度将是图像的尺寸,深度将是三个(红色,绿色和蓝色通道)。
因此,我们所看到的所有多层神经网络都有由长线神经元组成的层,我们不得不将输入图像或数据平铺到 1D,然后再将它们馈送到神经网络。但是,当您尝试直接为它们提供 2D 图像时会发生什么?答案是在 CNN 中,每个层都用 2D 表示,这样可以更容易地将神经元与其相应的输入进行匹配。我们将在接下来的部分中看到这方面的示例。
自编码器
AE 是具有三层或更多层的网络 ,其中输入层和输出具有相同数量的神经元,并且那些中间(隐藏层)具有较少数量的神经元。对网络进行训练,以便在输出中简单地为每条输入数据再现输入中相同的活动模式。
AE 是能够在没有任何监督的情况下学习输入数据的有效表示的 ANN(即,训练集是未标记的)。它们通常具有比输入数据低得多的维度,使得 AE 可用于降低维数。更重要的是,AE 作为强大的特征检测器,它们可用于 DNN 的无监督预训练。
该问题的显着方面在于,由于隐藏层中神经元的数量较少,如果网络可以从示例中学习并推广到可接受的程度,则它执行数据压缩;对于每个示例,隐藏神经元的状态为输入和输出公共状态的压缩版本提供。 AEs 的有用应用是数据可视化的数据去噪和降维。
下图显示了 AE 通常如何工作;它通过两个阶段重建接收的输入:编码阶段,其对应于原始输入的尺寸减小;以及解码阶段,其能够从编码(压缩)表示重建原始输入:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kNiZcHjM-1681565849691)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_01_19.jpg)]
图 18:自编码器的编码和解码阶段。
作为无监督神经网络,自编码器的主要特征是其对称结构。 自编码器有两个组件:将输入转换为内部表示的编码器,然后是将内部表示转换为输出的解码器。
换句话说, 自编码器可以看作是编码器的组合,其中我们将一些输入编码为代码,以及解码器,其中我们将代码解码/重建为其原始输入作为输出。因此,MLP 通常具有与自编码器相同的架构,除了输出层中的神经元的数量必须等于输入的数量。
如前所述,训练自编码器的方法不止一种。第一种方法是一次训练整个层,类似于 MLP。但是,在计算成本函数时,不像在监督学习中使用某些标记输出,我们使用输入本身。因此,成本函数显示实际输入和重建输入之间的差异。
循环神经网络(RNNs)
RNN 的基本特征是网络包含至少一个反馈连接,因此激活可以在循环中流动。它使网络能够进行时间处理和学习序列,例如执行序列识别/再现或时间关联/预测。
RNN 架构可以有许多不同的形式。一种常见类型包括标准 MLP 加上添加的循环。这些可以利用 MLP 强大的非线性映射功能,并具有某种形式的内存。其他人具有更均匀的结构,可能与每个神经元连接到所有其他神经元,并且可能具有随机激活函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9bwsXdl8-1681565849691)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_01_20.jpg)]
图 19:RNN 架构。
对于简单的架构和确定性激活函数,可以使用类似的 GD 过程来实现学习,这些过程导致用于前馈网络的反向传播算法。
上图查看了 RNN 的一些最重要的类型和功能。 RNN 被设计成利用输入数据的顺序信息,与诸如感知器,长短期存储器单元(LSTM)或门控循环单元(GRU)之类的构件块之间的循环连接。后两者用于消除常规 RNN 的缺点,例如梯度消失/爆炸问题和长短期依赖性。我们将在后面的章节中讨论这些架构。
前沿架构
已经提出了许多其他前沿 DL 架构 ,例如深度时空神经网络(DST-NN),多维循环神经网络(MD-RNN),和卷积自编码器(CAE)。
然而,人们正在谈论和使用其他新兴网络,例如 CapsNets(CNN 的改进版本,旨在消除常规 CNN 的缺点),用于个性化的分解机和深度强化学习。
深度学习框架
在本节中,我们介绍了一些最流行的 DL 框架。简而言之,几乎所有的库都提供了使用图形处理器加速学习过程的可能性,在开放许可下发布,并且是大学研究小组的结果。
TensorFlow 是数学软件,是一个开源软件库,用 Python 和 C++ 编写,用于机器智能。 Google Brain 团队在 2011 年开发了它,它可以用来帮助我们分析数据,预测有效的业务成果。构建神经网络模型后,在必要的特征工程之后,您可以使用绘图或 TensorBoard 以交互方式执行训练。
最新版 TensorFlow 提供的主要功能包括更快的计算,灵活性,可移植性,易于调试,统一的 API,GPU 计算的透明使用,易用性和可扩展性。其他好处包括它被广泛使用,支持,并且可以大规模生产。
Keras 是一个深度学习库,位于 TensorFlow 和 Theano 之上,提供了一个直观的 API,受到了 Torch(可能是现有的最佳 Python API)的启发。 Deeplearning4j 依赖于 Keras 作为其 Python API,并从 Keras 和 Keras,Theano 和 TensorFlow 导入模型。
Google 的软件工程师 FrançoisChollet 创建了 Keras。它可以在 CPU 和 GPU 上无缝运行。这样可以通过用户友好性,模块化和可扩展性轻松快速地进行原型设计。 Keras 可能是增长最快的框架之一,因为构建 NN 层太容易了。因此,Keras 很可能成为 NN 的标准 Python API。
Theano 可能是最常见的库。 Theano 是用 Python 编写的,它是 ML 领域中使用最广泛的语言之一(Python 也用于 TensorFlow)。此外,Theano 允许使用 GPU,比单 CPU 快 24 倍。 Theano 允许您有效地定义,优化和求值复杂的数学表达式,例如多维数组。不幸的是,Yoshua Bengio 于 2017 年 9 月 28 日宣布,Theano 的发展将停止。这意味着 Theano 实际上已经死了。
Neon 是由 Nirvana 开发的基于 Python 的深度学习框架。 Neon 的语法类似于 Theano 的高级框架(例如,Keras)。目前,Neon 被认为是基于 GPU 的最快工具,特别是对于 CNN。虽然它的基于 CPU 的实现比大多数其他库相对更差。
Torch 是 ML 的巨大生态系统,提供大量算法和函数,包括 DL 和处理各种类型的多媒体数据,特别关注并行计算。它为 C 语言提供了出色的接口, 拥有庞大的用户社区。 Torch 是一个扩展脚本语言 Lua 的库,旨在为设计和训练 ML 系统提供灵活的环境。 Torch 是各种平台(Windows,Mac,Linux 和 Android)上的独立且高度可移植的框架,脚本可以在这些平台上运行而无需修改。 Torch 为不同的应用提供了许多用途。
Caffe,主要由伯克利远景和学习中心(BVLC)开发 ,是一个框架 ,因其表达,速度和模块性而脱颖而出。其独特的架构鼓励应用和创新,使计算更容易从 CPU 转换到 GPU。庞大的用户群意味着最近发生了相当大的发展。它是用 Python 编写的,但由于需要编译的众多支持库,安装过程可能很长。
MXNet 是一个支持多种语言的 DL 框架,例如 R,Python,C++ 和 Julia。这很有帮助,因为如果你知道这些语言中的任何一种,你根本不需要走出自己的舒适区来训练你的 DL 模型。它的后端用 C++ 和 CUDA 编写,它能够以与 Theano 类似的方式管理自己的内存。
MXNet 也很受欢迎,因为它可以很好地扩展,并且可以与多个 GPU 和计算机一起使用,这使它对企业非常有用。这就是为什么亚马逊将 MXNet 作为 DL 的参考库。 2017 年 11 月,AWS 宣布推出 ONNX-MXNet,这是一个开源 Python 包,用于将开放式神经网络交换(ONNX) DL 模型导入 Apache MXNet。
Microsoft Cognitive Toolkit(CNTK)是 Microsoft Research 的统一 DL 工具包,可以轻松训练, 将多种 GPU 和服务器中的流行模型类型组合在一起。 CNTK 为语音,图像和文本数据实现高效的 CNN 和 RNN 训练。它支持 cuDNN v5.1 进行 GPU 加速。 CNTK 还支持 Python,C++ ,C#和命令行接口。
这是一个总结这些框架的表:
| 框架 | 支持的编程语言 | 训练教材和社区 | CNN 建模能力 | RNN 建模能力 | 可用性 | 多 GPU 支持 |
|---|---|---|---|---|---|---|
| Theano | Python,C++ | ++ | 丰富的 CNN 教程和预建模型 | 丰富的 RNN 教程和预建模型 | 模块化架构 | 否 |
| Neon | Python, | + | CNN 最快的工具 | 资源最少 | 模块化架构 | 否 |
| Torch | Lua,Python | + | 资源最少 | 丰富的 RNN 教程和预建模型 | 模块化架构 | 是 |
| Caffe | C++ | ++ | 丰富的 CNN 教程和预建模型 | 资源最少 | 创建层需要时间 | 是 |
| MXNet | R,Python,Julia,Scala | ++ | 丰富的 CNN 教程和预建模型 | 资源最少 | 模块化架构 | 是 |
| CNTK | C++ | + | 丰富的 CNN 教程和预建模型 | 丰富的 RNN 教程和预建模型 | 模块化架构 | 是 |
| TensorFlow | Python,C++ | +++ | 丰富的 RNN 教程和预建模型 | 丰富的 RNN 教程和预建模型 | 模块化架构 | 是 |
| DeepLearning4j | Java,Scala | +++ | 丰富的 RNN 教程和预建模型 | 丰富的 RNN 教程和预建模型 | 模块化架构 | 是 |
| Keras | Python | +++ | 丰富的 RNN 教程和预建模型 | 丰富的 RNN 教程和预建模型 | 模块化架构 | 是 |
除了前面的库之外,最近还有一些关于云计算的 DL 项目。这个想法是将 DL 功能带到大数据,拥有数十亿个数据点和高维数据。例如,Amazon Web Services(AWS),Microsoft Azure,Google Cloud Platform 和 NVIDIA GPU Cloud(NGC)都提供机器和深度学习服务,它们是公共云的原生。
2017 年 10 月,AWS 针对 Amazon Elastic Compute Cloud(EC2)P3 实例发布了深度学习 AMI(亚马逊机器映像) 。这些 AMI 预装了深度学习框架,如 TensorFlow,Gluon 和 Apache MXNet,这些框架针对 Amazon EC2 P3 实例中的 NVIDIA Volta V100 GPU 进行了优化。深度学习服务目前提供三种类型的 AMI:Conda AMI,Base AMI 和带源代码的 AMI。
Microsoft Cognitive Toolkit 是 Azure 的开源深度学习服务。与 AWS 的产品类似,它侧重于可以帮助开发人员构建和部署深度学习应用的工具。该工具包安装在 Python 2.7 的根环境中。 Azure 还提供了一个模型库,其中包含代码示例等资源,以帮助企业开始使用该服务。
另一方面,NGC 为 AI 科学家和研究人员提供 GPU 加速容器。 NGC 采用容器化的深度学习框架,如 TensorFlow,PyTorch 和 MXNet,经过 NVIDIA 的调整,测试和认证,可在参与的云服务提供商的最新 NVIDIA GPU 上运行。尽管如此,还有通过各自市场提供的第三方服务。
总结
在本章中,我们介绍了 DL 的一些基本主题。 DL 由一组方法组成,这些方法允许 ML 系统获得多个级别上的数据的分层表示。这是通过组合简单单元来实现的,每个简单单元从输入级别开始,以更高和抽象级别的表示,在其自己的级别上转换表示。
最近,这些技术提供了许多应用中从未见过的结果,例如图像识别和语音识别。这些技术普及的主要原因之一是 GPU 架构的发展,这大大减少了 DNN 的训练时间。
有不同的 DNN 架构,每个架构都是针对特定问题而开发的。我们将在后面的章节中更多地讨论这些架构,并展示使用 TensorFlow 框架创建的应用示例。本章最后简要介绍了最重要的 DL 框架。
在下一章中,我们将开始我们的 DL 之旅,介绍 TensorFlow 软件库。我们将介绍 TensorFlow 的主要功能,并了解如何安装它并设置我们的第一个工作再营销数据集。
二、TensorFlow v1.6 的新功能是什么?
2015 年,Google 开源了 TensorFlow,包括其所有参考实现。所有源代码都是在 Apache 2.0 许可下在 GitHub 上提供的。从那以后,TensorFlow 已经在学术界和工业研究中被广泛采用,最稳定的版本 1.6 最近已经发布了统一的 API。
值得注意的是,TensorFlow 1.6(及更高版本)中的 API 并非都与 v1.5 之前的代码完全向后兼容。这意味着一些在 v1.5 之前工作的程序不一定适用于 TensorFlow 1.6。
现在让我们看看 TensorFlow v1.6 具有的新功能和令人兴奋的功能。
Nvidia GPU 支持的优化
从 TensorFlow v1.5 开始,预构建的二进制文件现在针对 CUDA 9.0 和 cuDNN 7 构建。但是,从 v1.6 版本开始,TensorFlow 预构建的二进制文件使用 AVX 指令,这可能会破坏旧 CPU 上的 TensorFlow。尽管如此,自 v1.5 以来,已经可以在 NVIDIA Tegra 设备上增加对 CUDA 的支持。
TensorFlow Lite
TensorFlow Lite 是 TensorFlow 针对移动和嵌入式设备的轻量级解决方案。它支持具有小二进制大小和支持硬件加速的快速表现的设备上机器学习模型的低延迟推理。
TensorFlow Lite 使用许多技术来实现低延迟,例如优化特定移动应用的内核,预融合激活,允许更小和更快(定点数学)模型的量化内核,以及将来利用杠杆专用机器学习硬件在特定设备上获得特定模型的最佳表现。
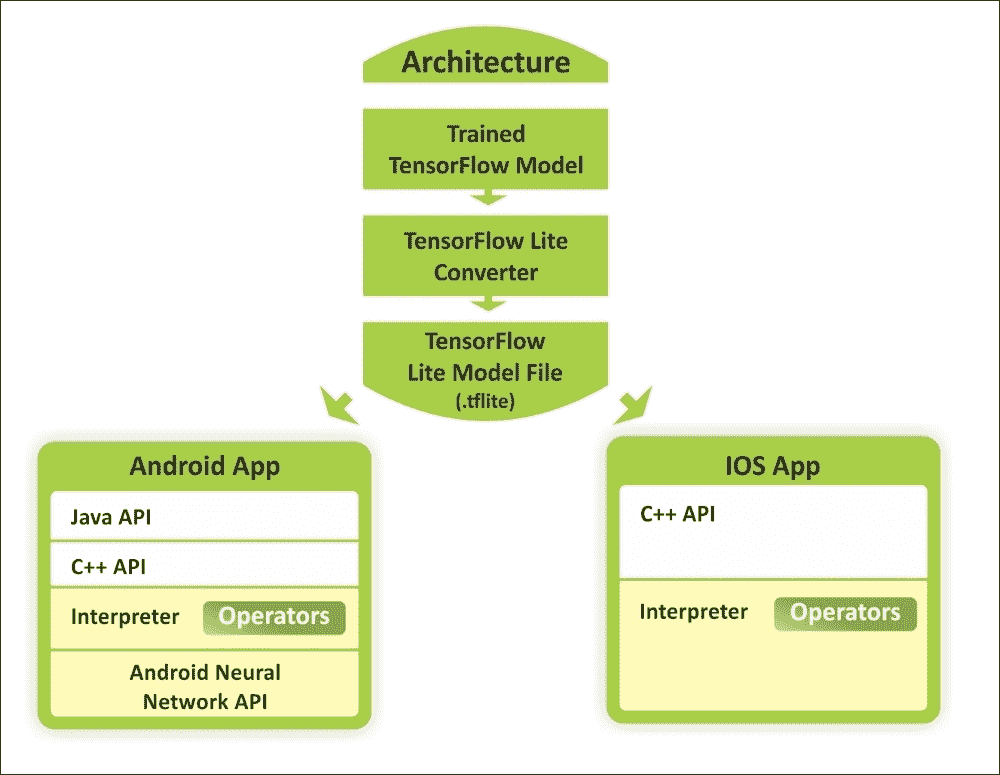
图 1:使用 TensorFlow Lite 在 Android 和 iOS 设备上使用训练模型的概念视图
机器学习正在改变计算范式,我们看到了移动和嵌入式设备上新用例的新趋势。在相机和语音交互模型的推动下,消费者的期望也趋向于与其设备进行自然的,类似人的交互。
因此,用户的期望不再局限于计算机,并且移动设备的计算能力也因硬件加速以及诸如 Android 神经网络 API 和 iOS 的 C++ API 之类的框架而呈指数级增长。如上图所示,预训练模型可以转换为较轻的版本,以便作为 Android 或 iOS 应用运行。
因此,广泛使用的智能设备为设备智能创造了新的可能性。这些允许我们使用我们的智能手机来执行实时计算机视觉和自然语言处理(NLP)。
急切执行
急切执行是 TensorFlow 的一个接口,它提供了一种命令式编程风格。启用预先执行时,TensorFlow 操作(在程序中定义)立即执行。
需要注意的是,从 TensorFlow v1.7 开始,急切执行将被移出contrib。这意味着建议使用tf.enable_eager_execution()。我们将在后面的部分中看到一个例子。
优化加速线性代数(XLA)
v1.5 之前的 XLA 不稳定并且具有非常有限的特性。但是,v1.6 对 XLA 的支持更多。这包括以下内容:
- 添加了对 XLA 编译器的 Complex64 支持
- 现在为 CPU 和 GPU 添加了快速傅里叶变换(FFT)支持
bfloat支持现已添加到 XLA 基础结构中- 已启用 ClusterSpec 传播与 XLA 设备的工作
- Android TF 现在可以在兼容的 Tegra 设备上使用 CUDA 加速构建
- 已启用对添加确定性执行器以生成 XLA 图的支持
开源社区报告的大量错误已得到修复,并且此版本已集成了大量 API 级别的更改。
但是,由于我们尚未使用 TensorFlow 进行任何研究,我们将在后面看到如何利用这些功能开发真实的深度学习应用。在此之前,让我们看看如何准备您的编程环境。
安装和配置 TensorFlow
您可以在许多平台上安装和使用 TensorFlow,例如 Linux, macOS 和 Windows。此外,您还可以从 TensorFlow 的最新 GitHub 源构建和安装 TensorFlow。此外,如果您有 Windows 机器,您可以通过原生点或 Anacondas 安装 TensorFlow。 TensorFlow 在 Windows 上支持 Python 3.5.x 和 3.6.x.
此外,Python 3 附带了 PIP3 包管理器,它是用于安装 TensorFlow 的程序。因此,如果您使用此 Python 版本,则无需安装 PIP。根据我们的经验,即使您的计算机上集成了 NVIDIA GPU 硬件,也值得安装并首先尝试仅使用 CPU 的版本,如果您没有获得良好的表现,那么您应该切换到 GPU 支持。
支持 GPU 的 TensorFlow 版本有几个要求,例如 64 位 Linux,Python 2.7(或 Python 3 的 3.3+),NVIDIACUDA®7.5 或更高版本(Pascal GPU 需要 CUDA 8.0)和 NVIDIA cuDNN(这是 GPU 加速深度学习)v5.1(建议使用更高版本)。有关详情,请参阅此链接。
更具体地说,TensorFlow 的当前开发仅支持使用 NVIDIA 工具包和软件的 GPU 计算。因此,必须在您的计算机上安装以下软件才能获得预测分析应用的 GPU 支持:
- NVIDIA 驱动程序
- 具有计算能力的
CUDA >= 3.0 - CudNN
NVIDIA CUDA 工具包包括(详见此链接):
- GPU 加速库,例如用于 FFT 的 cuFFT
- 基本线性代数子程序(BLAS)的 cuBLAS
- cuSPARSE 用于稀疏矩阵例程
- cuSOLVER 用于密集和稀疏的直接求解器
- 随机数生成的 cuRAND,图像的 NPP 和视频处理原语
- 适用于 NVIDIA Graph Analytics 库的 nvGRAPH
- 对模板化并行算法和数据结构以及专用 CUDA 数学库的推动
但是,我们不会介绍 TensorFlow 的安装和配置,因为 TensorFlow 上提供的文档非常丰富,可以遵循并采取相应的措施。另一个原因是该版本将定期更改。因此,使用 TensorFlow 网站保持自己更新将是一个更好的主意。
如果您已经安装并配置了编程环境,那么让我们深入了解 TensorFlow 计算图。
TensorFlow 计算图
在考虑执行 TensorFlow 程序时,我们应该熟悉图创建和会话执行的概念。基本上,第一个用于构建模型,第二个用于提供数据并获得结果。
有趣的是,TensorFlow 在 C++ 引擎上执行所有操作,这意味着在 Python 中甚至不会执行一些乘法或添加操作。 Python 只是一个包装器。从根本上说,TensorFlow C++ 引擎包含以下两件事:
- 有效的操作实现,例如 CNN 的卷积,最大池化和 sigmoid
- 前馈模式操作的衍生物
TensorFlow 库在编码方面是一个非凡的库,它不像传统的 Python 代码(例如,你可以编写语句并执行它们)。 TensorFlow 代码由不同的操作组成。甚至变量初始化在 TensorFlow 中也很特殊。当您使用 TensorFlow 执行复杂操作(例如训练线性回归)时,TensorFlow 会在内部使用数据流图表示其计算。该图称为计算图,它是由以下组成的有向图:
- 一组节点,每个节点代表一个操作
- 一组有向弧,每个弧代表执行操作的数据
TensorFlow 有两种类型的边:
- 正常:它们携带节点之间的数据结构。一个操作的输出,即来自一个节点的输出,成为另一个操作的输入。连接两个节点的边缘带有值。
- 特殊:此边不携带值,但仅表示两个节点之间的控制依赖关系,例如 X 和 Y。这意味着只有在 X 中的操作已经执行时才会执行节点 Y,但之前关于数据的操作之间的关系。
TensorFlow 实现定义控制依赖性,以强制规定执行其他独立操作的顺序,作为控制峰值内存使用的方式。
计算图基本上类似于数据流图。图 2 显示了简单计算的计算图,如z = d × c = (a + b) × c:
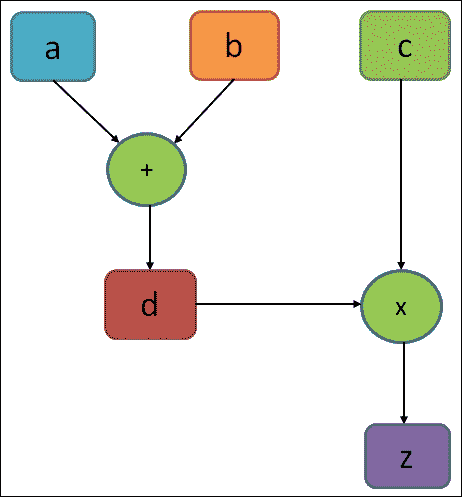
图 2:一个计算简单方程的非常简单的执行图
在上图中,图中的圆圈表示操作,而矩形表示计算图。如前所述,TensorFlow 图包含以下内容:
tf.Operation对象:这些是图中的节点。这些通常简称为操作。 操作仅为 TITO(张量 - 张量 - 张量)。一个或多个张量输入和一个或多个张量输出。tf.Tensor对象:这些是图的边缘。这些通常简称为张量。
张量对象在图中的各种操作之间流动。在上图中,d也是操作。它可以是“常量”操作,其输出是张量,包含分配给d的实际值。
也可以使用 TensorFlow 执行延迟执行。简而言之,一旦您在计算图的构建阶段中编写了高度复合的表达式,您仍然可以在运行会话阶段对其进行求值。从技术上讲,TensorFlow 安排工作并以有效的方式按时执行。
例如,使用 GPU 并行执行代码的独立部分如下图所示:
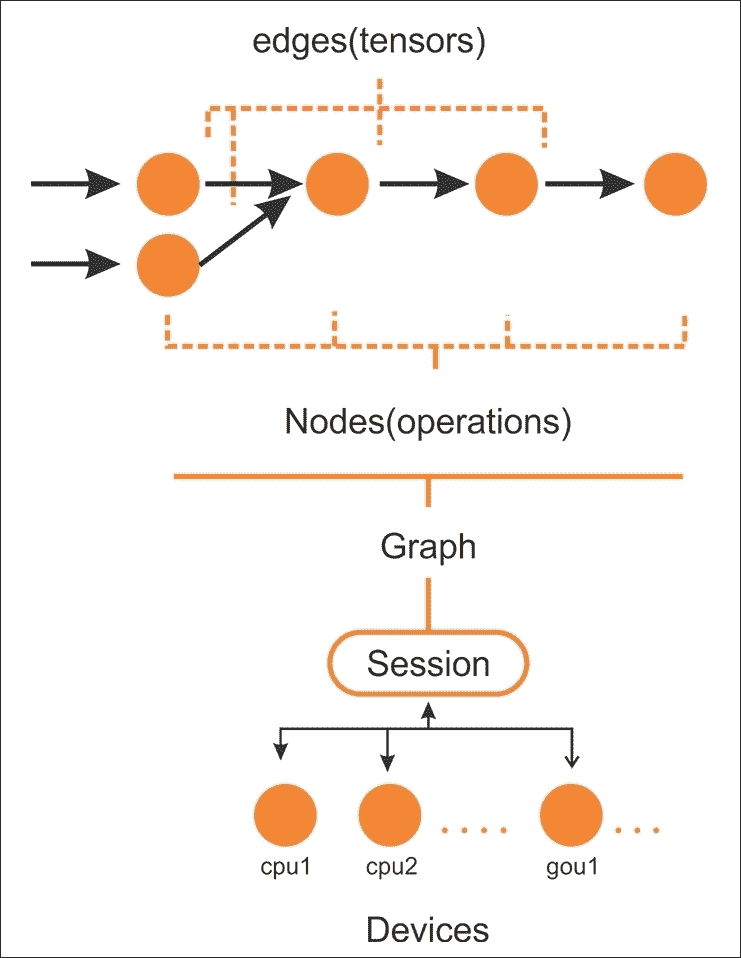
图 3:要在 CPU 或 GPU 等设备上的会话上执行的 TensorFlow 图中的边和节点
在创建计算图之后,TensorFlow 需要具有以分布式方式由多个 CPU(以及 GPU,如果可用)执行的活动会话。通常,您实际上不需要明确指定是使用 CPU 还是 GPU,因为 TensorFlow 可以选择使用哪一个。
默认情况下,将选择 GPU 以进行尽可能多的操作;否则,将使用 CPU。然而,通常,它会分配所有 GPU 内存,即使它不消耗它。
以下是 TensorFlow 图的主要组成部分:
- 变量:用于 TensorFlow 会话之间的值,包含权重和偏置。
- 张量:一组值,在节点之间传递以执行操作(也称为操作)。
- 占位符:用于在程序和 TensorFlow 图之间发送数据。
- 会话:当会话启动时,TensorFlow 会自动计算图中所有操作的梯度,并在链式规则中使用它们。实际上,在执行图时会调用会话。
不用担心,前面这些组件中的每一个都将在后面的章节中讨论。从技术上讲,您将要编写的程序可以被视为客户。然后,客户端用于以符号方式在 C/C++ 或 Python 中创建执行图,然后您的代码可以请求 TensorFlow 执行此图。整个概念从下图中变得更加清晰:
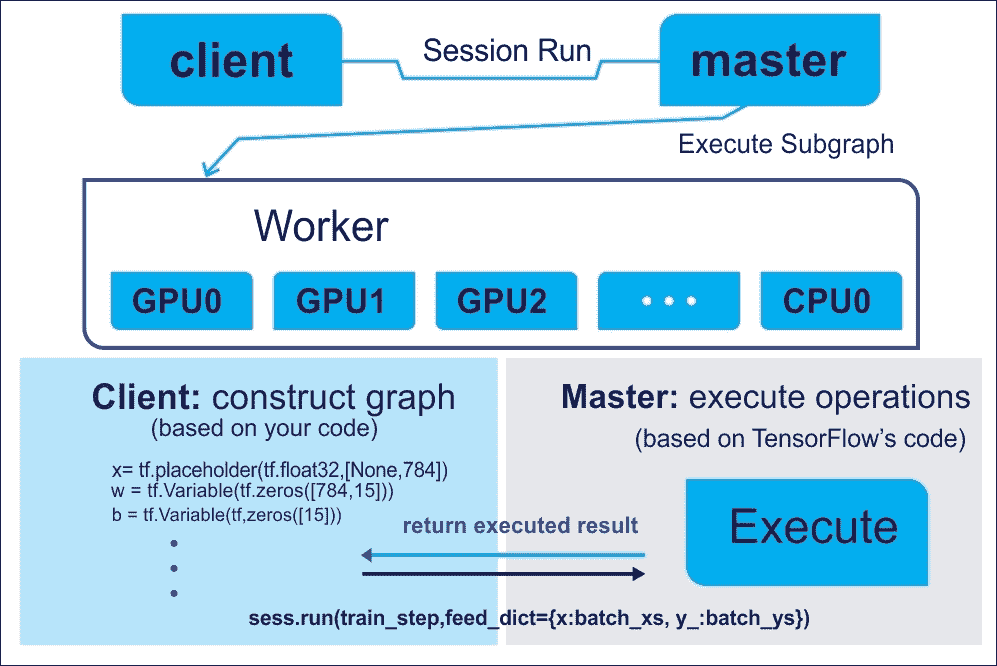
图 4:使用客户端主架构来执行 TensorFlow 图
计算图有助于使用 CPU 或 GPU 在多个计算节点上分配工作负载。这样,神经网络可以等同于复合函数,其中每个层(输入,隐藏或输出层)可以表示为函数。要了解在张量上执行的操作,需要了解 TensorFlow 编程模型的良好解决方法。
TensorFlow 代码结构
TensorFlow 编程模型表示如何构建预测模型。导入 TensorFlow 库时, TensorFlow 程序通常分为四个阶段:
- 构建涉及张量运算的计算图(我们将很快看到张量)
- 创建会话
- 运行会话;执行图中定义的操作
- 执行数据收集和分析
这些主要阶段定义了 TensorFlow 中的编程模型。请考虑以下示例,其中我们要将两个数相乘:
import tensorflow as tf # Import TensorFlow
x = tf.constant(8) # X op
y = tf.constant(9) # Y op
z = tf.multiply(x, y) # New op Z
sess = tf.Session() # Create TensorFlow session
out_z = sess.run(z) # execute Z op
sess.close() # Close TensorFlow session
print('The multiplication of x and y: %d' % out_z)# print result
前面的代码段可以用下图表示:
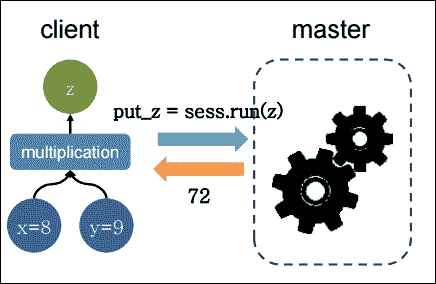
图 5:在客户端主架构上执行并返回的简单乘法
为了使前面的程序更有效,TensorFlow 还允许通过占位符交换图变量中的数据(稍后讨论)。现在想象一下代码段之后的可以做同样的事情,但效率更高:
import tensorflow as tf
# Build a graph and create session passing the graph
with tf.Session() as sess:
x = tf.placeholder(tf.float32, name="x")
y = tf.placeholder(tf.float32, name="y")
z = tf.multiply(x,y)
# Put the values 8,9 on the placeholders x,y and execute the graph
z_output = sess.run(z,feed_dict={x: 8, y:9})
print(z_output)
TensorFlow 不是乘以两个数字所必需的。此外,这个简单的操作有很多行代码。该示例的目的是阐明如何构造代码,从最简单的(如在本例中)到最复杂的。此外,该示例还包含一些基本指令,我们将在本书中给出的所有其他示例中找到这些指令。
第一行中的单个导入为您的命令导入 TensorFlow;如前所述,它可以用tf实例化。然后,TensorFlow 运算符将由tf和要使用的运算符的名称表示。在下一行中,我们通过tf.Session()指令构造session对象:
with tf.Session() as sess:
提示
会话对象(即sess)封装了 TensorFlow 的环境,以便执行所有操作对象,并求值Tensor对象。我们将在接下来的部分中看到它们。
该对象包含计算图,如前所述,它包含要执行的计算。以下两行使用placeholder定义变量x和y。通过placeholder,您可以定义输入(例如我们示例的变量x)和输出变量(例如变量y):
x = tf.placeholder(tf.float32, name="x")
y = tf.placeholder(tf.float32, name="y")
提示
占位符提供图元素和问题计算数据之间的接口。它们允许我们创建我们的操作并构建我们的计算图而不需要数据,而不是使用它的引用。
要通过placeholder函数定义数据或张量(我们将很快向您介绍张量的概念),需要三个参数:
- 数据类型是要定义的张量中的元素类型。
- 占位符的形状是要进给的张量的形状(可选)。如果未指定形状,则可以提供任何形状的张量。
- 名称对于调试和代码分析非常有用,但它是可选的。
注意
有关张量的更多信息,请参阅此链接。
因此,我们可以使用先前定义的两个参数(占位符和常量)来引入我们想要计算的模型。接下来,我们定义计算模型。
会话内的以下语句构建x和y的乘积的数据结构,并随后将操作结果分配给张量z。然后它如下:
z = tf.multiply(x, y)
由于结果已由占位符z保存,我们通过sess.run语句执行图。在这里,我们提供两个值来将张量修补为图节点。它暂时用张量值替换操作的输出:
z_output = sess.run(z,feed_dict={x: 8, y:9})
在最后的指令中,我们打印结果:
print(z_output)
这打印输出72.0。
用 TensorFlow 急切执行
如前所述,在启用 TensorFlow 的急切执行时,我们可以立即执行 TensorFlow 操作,因为它们是以命令方式从 Python 调用的。
启用急切执行后,TensorFlow 函数会立即执行操作并返回具体值。这与tf.Session相反,函数添加到图并创建计算图中的节点的符号引用。
TensorFlow 通过tf.enable_eager_execution提供急切执行的功能,其中包含以下别名:
tf.contrib.eager.enable_eager_executiontf.enable_eager_execution
tf.enable_eager_execution具有以下签名:
tf.enable_eager_execution(
config=None,
device_policy=None
)
在上面的签名中,config是tf.ConfigProto,用于配置执行操作的环境,但这是一个可选参数。另一方面,device_policy也是一个可选参数,用于控制关于特定设备(例如 GPU0)上需要输入的操作如何处理不同设备(例如,GPU1 或 CPU)上的输入的策略。
现在调用前面的代码将启用程序生命周期的急切执行。例如,以下代码在 TensorFlow 中执行简单的乘法运算:
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=[1, 1]) # a placeholder for variable x
y = tf.placeholder(tf.float32, shape=[1, 1]) # a placeholder for variable y
m = tf.matmul(x, y)
with tf.Session() as sess:
print(sess.run(m, feed_dict={x: [[2.]], y: [[4.]]}))
以下是上述代码的输出:
>>>
8.
然而,使用急切执行,整体代码看起来更简单:
import tensorflow as tf
# Eager execution (from TF v1.7 onwards):
tf.eager.enable_eager_execution()
x = [[2.]]
y = [[4.]]
m = tf.matmul(x, y)
print(m)
以下是上述代码的输出:
>>>
tf.Tensor([[8.]], shape=(1, 1), dtype=float32)
你能理解在执行前面的代码块时会发生什么吗?好了,在启用了执行后,操作在定义时执行,Tensor对象保存具体值,可以通过numpy()方法作为numpy.ndarray访问。
请注意,在使用 TensorFlow API 创建或执行图后,无法启用急切执行。通常建议在程序启动时调用此函数,而不是在库中调用。虽然这听起来很吸引人,但我们不会在即将到来的章节中使用此功能,因为这是一个新功能,尚未得到很好的探索。
TensorFlow 中的数据模型
TensorFlow 中的数据模型由张量表示。在不使用复杂的数学定义的情况下,我们可以说张量(在 TensorFlow 中)识别多维数值数组。我们将在下一小节中看到有关张量的更多细节。
张量
让我们看一下来自维基百科:张量的形式定义:
“张量是描述几何向量,标量和其他张量之间线性关系的几何对象。这种关系的基本例子包括点积,叉积和线性映射。几何向量,通常用于物理和工程应用,以及标量他们自己也是张量。“
该数据结构的特征在于三个参数:秩,形状和类型,如下图所示:
图 6:张量只是具有形状,阶数和类型的几何对象,用于保存多维数组
因此,张量可以被认为是指定具有任意数量的索引的元素的矩阵的推广。张量的语法与嵌套向量大致相同。
提示
张量只定义此值的类型以及在会话期间应计算此值的方法。因此,它们不代表或保留操作产生的任何值。
有些人喜欢比较 NumPy 和 TensorFlow。然而,实际上,TensorFlow 和 NumPy 在两者都是 Nd 数组库的意义上非常相似!
嗯,NumPy 确实有 n 维数组支持,但它不提供方法来创建张量函数并自动计算导数(并且它没有 GPU 支持)。下图是 NumPy 和 TensorFlow 的简短一对一比较:

图 7:NumPy 与 TensorFlow:一对一比较
现在让我们看一下在 TensorFlow 图之前创建张量的替代方法(我们将在后面看到其他的进给机制):
>>> X = [[2.0, 4.0],
[6.0, 8.0]] # X is a list of lists
>>> Y = np.array([[2.0, 4.0],
[6.0, 6.0]], dtype=np.float32)#Y is a Numpy array
>>> Z = tf.constant([[2.0, 4.0],
[6.0, 8.0]]) # Z is a tensor
这里,X是列表,Y是来自 NumPy 库的 n 维数组,Z是 TensorFlow 张量对象。现在让我们看看他们的类型:
>>> print(type(X))
>>> print(type(Y))
>>> print(type(Z))
#Output
<class 'list'>
<class 'numpy.ndarray'>
<class 'tensorflow.python.framework.ops.Tensor'>
好吧,他们的类型打印正确。但是,与其他类型相比,我们正式处理张量的更方便的函数是tf.convert_to_tensor()函数如下:
t1 = tf.convert_to_tensor(X, dtype=tf.float32)
t2 = tf.convert_to_tensor(Z, dtype=tf.float32)
现在让我们使用以下代码查看它们的类型:
>>> print(type(t1))
>>> print(type(t2))
#Output:
<class 'tensorflow.python.framework.ops.Tensor'>
<class 'tensorflow.python.framework.ops.Tensor'>
太棒了!关于张量的讨论已经足够了。因此,我们可以考虑以术语秩为特征的结构。
秩和形状
称为秩的维度单位描述每个张量。它识别张量的维数。因此,秩被称为张量的阶数或维度。阶数零张量是标量,阶数 1 张量是向量,阶数 2 张量是矩阵。
以下代码定义了 TensorFlow scalar,vector,matrix和cube_matrix。在下一个示例中,我们将展示秩如何工作:
import tensorflow as tf
scalar = tf.constant(100)
vector = tf.constant([1,2,3,4,5])
matrix = tf.constant([[1,2,3],[4,5,6]])
cube_matrix = tf.constant([[[1],[2],[3]],[[4],[5],[6]],[[7],[8],[9]]])
print(scalar.get_shape())
print(vector.get_shape())
print(matrix.get_shape())
print(cube_matrix.get_shape())
结果打印在这里:
>>>
()
(5,)
(2, 3)
(3, 3, 1)
>>>
张量的形状是它具有的行数和列数。现在我们将看看如何将张量的形状与其阶数联系起来:
>>scalar.get_shape()
TensorShape([])
>>vector.get_shape()
TensorShape([Dimension(5)])
>>matrix.get_shape()
TensorShape([Dimension(2), Dimension(3)])
>>cube.get_shape()
TensorShape([Dimension(3), Dimension(3), Dimension(1)])
数据类型
除了阶数和形状,张量具有数据类型。以下是数据类型列表:
| 数据类型 | Python 类型 | 描述 |
|---|---|---|
DT_FLOAT |
tf.float32 |
32 位浮点 |
DT_DOUBLE |
tf.float64 |
64 位浮点 |
DT_INT8 |
tf.int8 |
8 位有符号整数 |
DT_INT16 |
tf.int16 |
16 位有符号整数 |
DT_INT32 |
tf.int32 |
32 位有符号整数 |
DT_INT64 |
tf.int64 |
64 位有符号整数 |
DT_UINT8 |
tf.uint8 |
8 位无符号整数 |
DT_STRING |
tf.string |
可变长度字节数组。张量的每个元素都是一个字节数组 |
DT_BOOL |
tf.bool |
布尔 |
DT_COMPLEX64 |
tf.complex64 |
由两个 32 位浮点组成的复数:实部和虚部 |
DT_COMPLEX128 |
tf.complex128 |
由两个 64 位浮点组成的复数:实部和虚部 |
DT_QINT8 |
tf.qint8 |
量化操作中使用的 8 位有符号整数 |
DT_QINT32 |
tf.qint32 |
量化操作中使用的 32 位有符号整数 |
DT_QUINT8 |
tf.quint8 |
量化操作中使用的 8 位无符号整数 |
上表是不言自明的,因此我们没有提供有关数据类型的详细讨论。 TensorFlow API 用于管理与 NumPy 数组之间的数据。
因此,要构建具有常量值的张量,将 NumPy 数组传递给tf.constant()运算符,结果将是具有该值的张量:
import tensorflow as tf
import numpy as np
array_1d = np.array([1,2,3,4,5,6,7,8,9,10])
tensor_1d = tf.constant(array_1d)
with tf.Session() as sess:
print(tensor_1d.get_shape())
print(sess.run(tensor_1d))
运行该示例,我们获得以下内容:
>>>
(10,)
[ 1 2 3 4 5 6 7 8 9 10]
要构建具有变量值的张量,请使用 NumPy 数组并将其传递给tf.Variable构造器。结果将是具有该初始值的变量张量:
import tensorflow as tf
import numpy as np
# Create a sample NumPy array
array_2d = np.array([(1,2,3),(4,5,6),(7,8,9)])
# Now pass the preceding array to tf.Variable()
tensor_2d = tf.Variable(array_2d)
# Execute the preceding op under an active session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(tensor_2d.get_shape())
print sess.run(tensor_2d)
# Finally, close the TensorFlow session when you're done
sess.close()
在前面的代码块中,tf.global_variables_initializer()用于初始化我们之前创建的所有操作。如果需要创建一个初始值取决于另一个变量的变量,请使用另一个变量的initialized_value()。这可确保以正确的顺序初始化变量。
结果如下:
>>>
(3, 3)
[[1 2 3]
[4 5 6]
[7 8 9]]
为了便于在交互式 Python 环境中使用,我们可以使用InteractiveSession类,然后将该会话用于所有Tensor.eval()和Operation.run()调用:
import tensorflow as tf # Import TensorFlow
import numpy as np # Import numpy
# Create an interactive TensorFlow session
interactive_session = tf.InteractiveSession()
# Create a 1d NumPy array
array1 = np.array([1,2,3,4,5]) # An array
# Then convert the preceding array into a tensor
tensor = tf.constant(array1) # convert to tensor
print(tensor.eval()) # evaluate the tensor op
interactive_session.close() # close the session
提示
tf.InteractiveSession()只是方便的语法糖,用于在 IPython 中保持默认会话打开。
结果如下:
>>>
[1 2 3 4 5]
在交互式设置中,例如 shell 或 IPython 笔记本,这可能会更容易,因为在任何地方传递会话对象都很繁琐。
注意
IPython 笔记本现在称为 Jupyter 笔记本。它是一个交互式计算环境,您可以在其中组合代码执行,富文本,数学,绘图和富媒体。有关更多信息,感兴趣的读者请参阅此链接。
定义张量的另一种方法是使用tf.convert_to_tensor语句:
import tensorflow as tf
import numpy as np
tensor_3d = np.array([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],
[[9, 10, 11], [12, 13, 14], [15, 16, 17]],
[[18, 19, 20], [21, 22, 23], [24, 25, 26]]])
tensor_3d = tf.convert_to_tensor(tensor_3d, dtype=tf.float64)
with tf.Session() as sess:
print(tensor_3d.get_shape())
print(sess.run(tensor_3d))
# Finally, close the TensorFlow session when you're done
sess.close()
以下是上述代码的输出:
>>>
(3, 3, 3)
[[[ 0\. 1\. 2.]
[ 3\. 4\. 5.]
[ 6\. 7\. 8.]]
[[ 9\. 10\. 11.]
[ 12\. 13\. 14.]
[ 15\. 16\. 17.]]
[[ 18\. 19\. 20.]
[ 21\. 22\. 23.]
[ 24\. 25\. 26.]]]
变量
变量是用于保存和更新参数的 TensorFlow 对象。必须初始化变量,以便您可以保存并恢复它以便稍后分析代码。使用tf.Variable()或tf.get_variable()语句创建变量。而tf.get_varaiable()被推荐但tf.Variable()是低标签抽象。
在下面的示例中,我们要计算从 1 到 10 的数字,但让我们先导入 TensorFlow:
import tensorflow as tf
我们创建了一个将初始化为标量值 0 的变量:
value = tf.get_variable("value", shape=[], dtype=tf.int32, initializer=None, regularizer=None, trainable=True, collections=None)
assign()和add()运算符只是计算图的节点,因此在会话运行之前它们不会执行赋值:
one = tf.constant(1)
update_value = tf.assign_add(value, one)
initialize_var = tf.global_variables_initializer()
我们可以实例化计算图:
with tf.Session() as sess:
sess.run(initialize_var)
print(sess.run(value))
for _ in range(5):
sess.run(update_value)
print(sess.run(value))
# Close the session
让我们回想一下,张量对象是操作结果的符号句柄,但它实际上并不保存操作输出的值:
>>>
0
1
2
3
4
5
运行
要获取操作的输出,可以通过调用会话对象上的run()并传入张量来执行图。除了获取单个张量节点,您还可以获取多个张量。
在下面的示例中,使用run()调用一起提取sum和multiply张量:
import tensorflow as tf
constant_A = tf.constant([100.0])
constant_B = tf.constant([300.0])
constant_C = tf.constant([3.0])
sum_ = tf.add(constant_A,constant_B)
mul_ = tf.multiply(constant_A,constant_C)
with tf.Session() as sess:
result = sess.run([sum_,mul_])# _ means throw away afterwards
print(result)
输出如下:
>>>
[array(400.],dtype=float32),array([ 300.],dtype=float32)]
应该注意的是,所有需要执行的操作(即,为了产生张量值)都运行一次(每个请求的张量不是一次)。
馈送和占位符
有四种方法将数据输入 TensorFlow 程序(更多信息,请参阅此链接):
- 数据集 API:这使您能够从简单和可重用的分布式文件系统构建复杂的输入管道,并执行复杂的操作。如果您要处理不同数据格式的大量数据,建议使用数据集 API。数据集 API 为 TensorFlow 引入了两个新的抽象,用于创建可馈送数据集:
tf.contrib.data.Dataset(通过创建源或应用转换操作)和tf.contrib.data.Iterator。 - 馈送:这允许我们将数据注入计算图中的任何张量。
- 从文件中读取:这允许我们使用 Python 的内置机制开发输入管道,用于从图开头的数据文件中读取数据。
- 预加载数据:对于小数据集,我们可以使用 TensorFlow 图中的常量或变量来保存所有数据。
在本节中,我们将看到馈送机制的例子。我们将在接下来的章节中看到其他方法。 TensorFlow 提供了一种馈送机制,允许我们将数据注入计算图中的任何张量。您可以通过feed_dict参数将源数据提供给启动计算的run()或eval()调用。
提示
使用feed_dict参数进行馈送是将数据提供到 TensorFlow 执行图中的最低效方法,并且仅应用于需要小数据集的小型实验。它也可以用于调试。
我们还可以用馈送数据(即变量和常量)替换任何张量。最佳做法是使用tf.placeholder()使用 TensorFlow 占位符节点。占位符专门用作馈送的目标。空占位符未初始化,因此不包含任何数据。
因此,如果在没有馈送的情况下执行它,它将始终生成错误,因此您不会忘记提供它。以下示例显示如何提供数据以构建随机2×3矩阵:
import tensorflow as tf
import numpy as np
a = 3
b = 2
x = tf.placeholder(tf.float32,shape=(a,b))
y = tf.add(x,x)
data = np.random.rand(a,b)
sess = tf.Session()
print(sess.run(y,feed_dict={x:data}))
sess.close()# close the session
输出如下:
>>>
[[ 1.78602004 1.64606333]
[ 1.03966308 0.99269408]
[ 0.98822606 1.50157797]]
>>>
通过 TensorBoard 可视化计算
TensorFlow 包含函数 ,允许您在名为 TensorBoard 的可视化工具中调试和优化程序。使用 TensorBoard,您可以以图形方式观察有关图任何部分的参数和详细信息的不同类型的统计数据。
此外,在使用复杂的 DNN 进行预测建模时,图可能很复杂且令人困惑。为了更容易理解,调试和优化 TensorFlow 程序,您可以使用 TensorBoard 可视化 TensorFlow 图,绘制有关图执行的量化指标,并显示其他数据,例如通过它的图像。
因此,TensorBoard 可以被认为是一个用于分析和调试预测模型的框架。 TensorBoard 使用所谓的摘要来查看模型的参数:一旦执行了 TensorFlow 代码,我们就可以调用 TensorBoard 来查看 GUI 中的摘要。
TensorBoard 如何运作?
TensorFlow 使用计算图来执行应用。在计算图中,节点表示操作,弧是操作之间的数据。
TensorBoard 的主要思想是将摘要与图上的节点(操作)相关联。代码运行时,摘要操作将序列化节点的数据并将数据输出到文件中。稍后,TensorBoard 将可视化汇总操作。有关更详细的讨论,读者可以参考此链接。
简而言之,TensorBoard 是一套 Web 应用,用于检查和理解您的 TensorFlow 运行和图。使用 TensorBoard 时的工作流程如下:
-
构建计算图/代码
-
将摘要操作附加到您要检查的节点
-
像往常一样开始运行图
-
运行摘要操作
-
执行完成后,运行 TensorBoard 以显示摘要输出
file_writer = tf.summary.FileWriter('/path/to/logs', sess.graph)
对于步骤 2(即,在运行 TensorBoard 之前),请确保通过创建摘要编写器在日志目录中生成摘要数据:
#sess.graph包含图定义;启用图可视化工具
现在,如果你在终端中键入$ which tensorboard,如果你用 pip 安装它,它应该存在:
root@ubuntu:~$ which tensorboard
/usr/local/bin/tensorboard
你需要给它一个日志目录。当您在运行图的目录中时,可以使用以下内容从终端启动它:
tensorboard --logdir path/to/logs
当 TensorBoard 配置完全时,可以通过发出以下命令来访问它:
# Make sure there's no space before or after '="
$ tensorboard –logdir=<trace_file_name>
现在您只需输入http://localhost:6006/即可从浏览器访问localhost:6006。然后它应该是这样的:
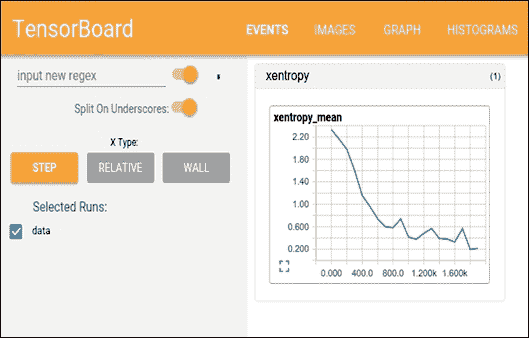
图 8:在浏览器上使用 TensorBoard
注意
TensorBoard 可用于谷歌浏览器或 Firefox。其他浏览器可能有效,但可能存在错误或表现问题。
这已经太过分了吗?不要担心,在上一节中,我们将结合前面解释的所有想法构建单个输入神经元模型并使用 TensorBoard 进行分析。
线性回归及更多
在本节中,我们将仔细研究 TensorFlow 和 TensorBoard 的主要概念,并尝试做一些基本操作来帮助您入门。我们想要实现的模型模拟线性回归。
在统计和 ML 中,线性回归是一种经常用于衡量变量之间关系的技术。这是一种非常简单但有效的算法,也可用于预测建模。
线性回归模拟因变量y[i],自变量x[i],和随机项b。这可以看作如下:
![]()
使用 TensorFlow 的典型线性回归问题具有以下工作流程,该工作流程更新参数以最小化给定成本函数(参见下图):
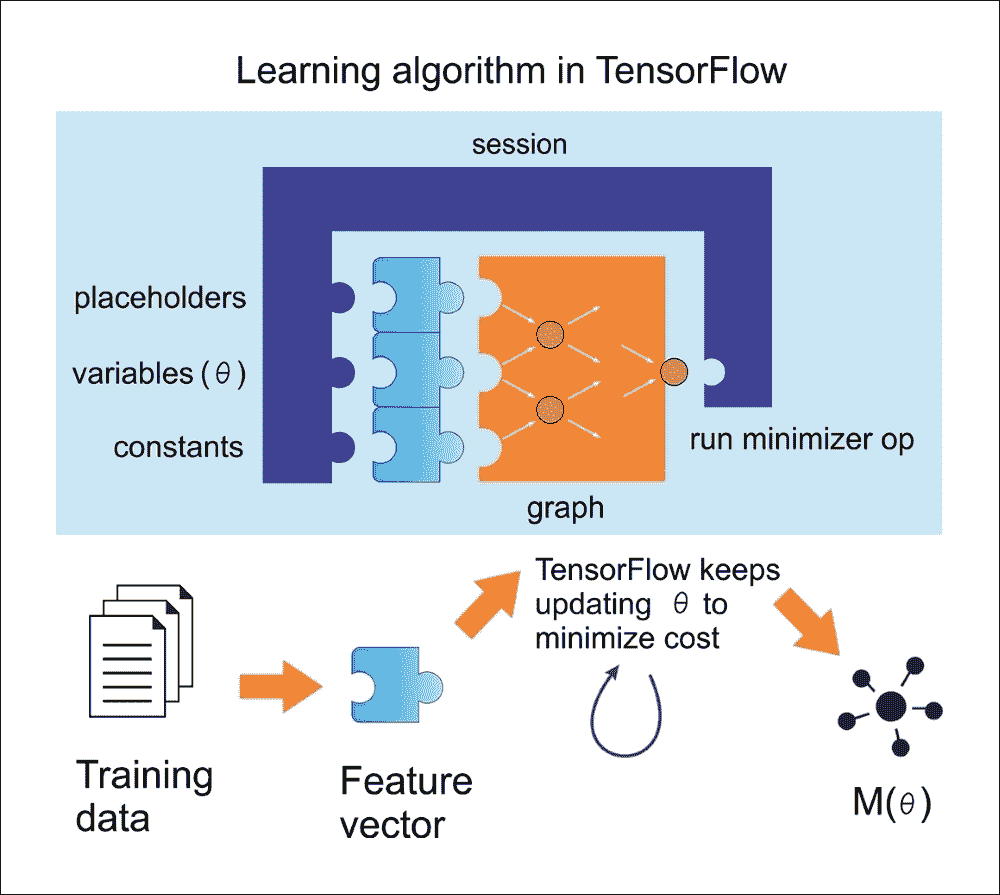
图 9:在 TensorFlow 中使用线性回归的学习算法
现在,让我们尝试按照前面的图,通过概念化前面的等式将其重现为线性回归。为此,我们将编写一个简单的 Python 程序,用于在 2D 空间中创建数据。然后我们将使用 TensorFlow 来寻找最适合数据点的线(如下图所示):
# Import libraries (Numpy, matplotlib)
import numpy as np
import matplotlib.pyplot as plot
# Create 1000 points following a function y=0.1 * x + 0.4z
(i.e. # y = W * x + b) with some normal random distribution:
num_points = 1000
vectors_set = []
# Create a few random data points
for i in range(num_points):
W = 0.1 # W
b = 0.4 # b
x1 = np.random.normal(0.0, 1.0)#in: mean, standard deviation
nd = np.random.normal(0.0, 0.05)#in:mean,standard deviation
y1 = W * x1 + b
# Add some impurity with normal distribution -i.e. nd
y1 = y1 + nd
# Append them and create a combined vector set:
vectors_set.append([x1, y1])
# Separate the data point across axises:
x_data = [v[0] for v in vectors_set]
y_data = [v[1] for v in vectors_set]
# Plot and show the data points in a 2D space
plot.plot(x_data, y_data, 'ro', label='Original data')
plot.legend()
plot.show()
如果您的编译器没有报错,您应该得到以下图表:
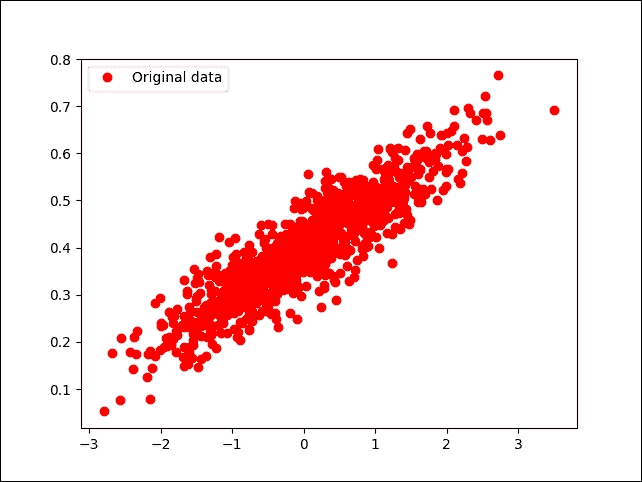
图 10:随机生成(但原始)数据
好吧,到目前为止,我们刚刚创建了一些数据点而没有可以通过 TensorFlow 执行的相关模型。因此,下一步是创建一个线性回归模型,该模型可以获得从输入数据点估计的输出值y,即x_data。在这种情况下,我们只有两个相关参数,W和b。
现在的目标是创建一个图,允许我们根据输入数据x_data,通过将它们调整为y_data来找到这两个参数的值。因此,我们的目标函数如下:
![]()
如果你还记得,我们在 2D 空间中创建数据点时定义了W = 0.1和b = 0.4。 TensorFlow 必须优化这两个值,使W趋于 0.1 和b为 0.4。
解决此类优化问题的标准方法是迭代数据点的每个值并调整W和b的值,以便为每次迭代获得更精确的答案。要查看值是否确实在改善,我们需要定义一个成本函数来衡量某条线的优质程度。
在我们的例子中,成本函数是均方误差,这有助于我们根据实际数据点与每次迭代的估计距离函数之间的距离函数找出误差的平均值。我们首先导入 TensorFlow 库:
import tensorflow as tf
W = tf.Variable(tf.zeros([1]))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
在前面的代码段中,我们使用不同的策略生成一个随机点并将其存储在变量W中。现在,让我们定义一个损失函数loss = mean[(y - y_data)^2],这将返回一个标量值,其中包含我们之间所有距离的均值。数据和模型预测。就 TensorFlow 约定而言,损失函数可表示如下:
loss = tf.reduce_mean(tf.square(y - y_data))
前一行实际上计算均方误差(MSE)。在不进一步详述的情况下,我们可以使用一些广泛使用的优化算法,例如 GD。在最低级别,GD 是一种算法,它对我们已经拥有的一组给定参数起作用。
它以一组初始参数值开始,并迭代地移向一组值,这些值通过采用另一个称为学习率的参数来最小化函数。通过在梯度函数的负方向上采取步骤来实现这种迭代最小化:
optimizer = tf.train.GradientDescentOptimizer(0.6)
train = optimizer.minimize(loss)
在运行此优化函数之前,我们需要初始化到目前为止所有的变量。让我们使用传统的 TensorFlow 技术,如下所示:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
由于我们已经创建了 TensorFlow 会话,我们已准备好进行迭代过程,帮助我们找到W和b的最佳值:
for i in range(6):
sess.run(train)
print(i, sess.run(W), sess.run(b), sess.run(loss))
您应该观察以下输出:
>>>
0 [ 0.18418592] [ 0.47198644] 0.0152888
1 [ 0.08373772] [ 0.38146532] 0.00311204
2 [ 0.10470386] [ 0.39876288] 0.00262051
3 [ 0.10031486] [ 0.39547175] 0.00260051
4 [ 0.10123629] [ 0.39609471] 0.00259969
5 [ 0.1010423] [ 0.39597753] 0.00259966
6 [ 0.10108326] [ 0.3959994] 0.00259966
7 [ 0.10107458] [ 0.39599535] 0.00259966
你可以看到算法从W = 0.18418592和b = 0.47198644的初始值开始,损失非常高。然后,算法通过最小化成本函数来迭代地调整值。在第八次迭代中,所有值都倾向于我们期望的值。
现在,如果我们可以绘制它们怎么办?让我们通过在for循环下添加绘图线来实现 ,如下所示:
for i in range(6):
sess.run(train)
print(i, sess.run(W), sess.run(b), sess.run(loss))
plot.plot(x_data, y_data, 'ro', label='Original data')
plot.plot(x_data, sess.run(W)*x_data + sess.run(b))
plot.xlabel('X')
plot.xlim(-2, 2)
plot.ylim(0.1, 0.6)
plot.ylabel('Y')
plot.legend()
plot.show()
前面的代码块应该生成下图(虽然合并在一起):
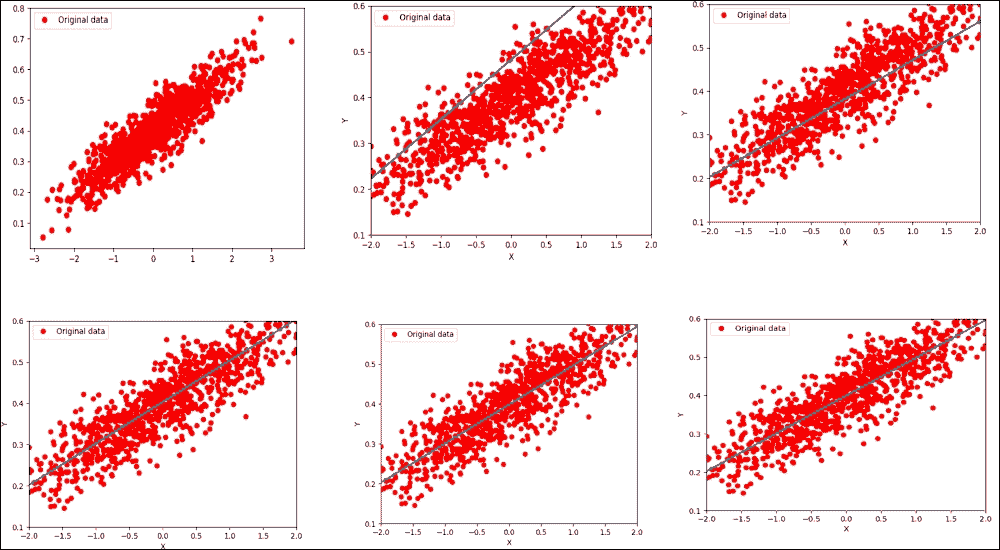
图 11:在第六次迭代后优化损失函数的线性回归
现在让我们进入第 16 次迭代:
>>>
0 [ 0.23306453] [ 0.47967502] 0.0259004
1 [ 0.08183448] [ 0.38200468] 0.00311023
2 [ 0.10253634] [ 0.40177572] 0.00254209
3 [ 0.09969243] [ 0.39778906] 0.0025257
4 [ 0.10008509] [ 0.39859086] 0.00252516
5 [ 0.10003048] [ 0.39842987] 0.00252514
6 [ 0.10003816] [ 0.39846218] 0.00252514
7 [ 0.10003706] [ 0.39845571] 0.00252514
8 [ 0.10003722] [ 0.39845699] 0.00252514
9 [ 0.10003719] [ 0.39845672] 0.00252514
10 [ 0.1000372] [ 0.39845678] 0.00252514
11 [ 0.1000372] [ 0.39845678] 0.00252514
12 [ 0.1000372] [ 0.39845678] 0.00252514
13 [ 0.1000372] [ 0.39845678] 0.00252514
14 [ 0.1000372] [ 0.39845678] 0.00252514
15 [ 0.1000372] [ 0.39845678] 0.00252514
好多了,我们更接近优化的值,对吧?现在,如果我们通过 TensorFlow 进一步改进我们的可视化分析,以帮助可视化这些图中发生的事情,该怎么办? TensorBoard 提供了一个网页,用于调试图并检查变量,节点,边缘及其相应的连接。
此外,我们需要使用变量标注前面的图,例如损失函数,W,b,y_data,x_data等。然后,您需要通过调用tf.summary.merge_all()函数生成所有摘要。
现在,我们需要对前面的代码进行如下更改。但是,最好使用tf.name_scope()函数对图上的相关节点进行分组。因此,我们可以使用tf.name_scope()来组织 TensorBoard 图表视图中的内容,但让我们给它一个更好的名称:
with tf.name_scope("LinearRegression") as scope:
W = tf.Variable(tf.zeros([1]))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
然后,让我们以类似的方式标注损失函数,但使用合适的名称,例如LossFunction:
with tf.name_scope("LossFunction") as scope:
loss = tf.reduce_mean(tf.square(y - y_data))
让我们标注 TensorBoard 所需的损失,权重和偏置:
loss_summary = tf.summary.scalar("loss", loss)
w_ = tf.summary.histogram("W", W)
b_ = tf.summary.histogram("b", b)
一旦您标注了图,就可以通过合并来配置摘要了:
merged_op = tf.summary.merge_all()
在运行训练之前(初始化之后),使用tf.summary.FileWriter() API 编写摘要,如下所示:
writer_tensorboard = tf.summary.FileWriter('logs/', tf.get_default_graph())
然后按如下方式启动 TensorBoard:
$ tensorboard –logdir=<trace_dir_name>
在我们的例子中,它可能类似于以下内容:
$ tensorboard --logdir=/home/root/LR/
现在让我们转到http://localhost:6006并单击 GRAPH 选项卡。您应该看到以下图表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qe42IjO0-1681565849695)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_02_11.jpg)]
图 12:TensorBoard 上的主图和辅助节点
提示
请注意,Ubuntu 可能会要求您安装python-tk包。您可以通过在 Ubuntu 上执行以下命令来执行此操作:
$ sudo apt-get install python-tk
# For Python 3.x, use the following
$ sudo apt-get install python3-tk
真实数据集的线性回归回顾
在上一节中,我们看到线性回归的一个例子。我们看到了如何将 TensorFlow 与随机生成的数据集一起使用,即假数据。我们已经看到回归是一种用于预测连续(而非离散)输出的监督机器学习。
然而,对假数据进行线性回归就像买一辆新车但从不开车。这个令人敬畏的机器需要在现实世界中使用!幸运的是,许多数据集可在线获取,以测试您新发现的回归知识。
其中一个是波士顿住房数据集,可以从 UCI 机器学习库下载。它也可以作为 scikit-learn 的预处理数据集使用。
所以,让我们开始导入所有必需的库,包括 TensorFlow,NumPy,Matplotlib 和 scikit-learn:
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from numpy import genfromtxt
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
接下来,我们需要准备由波士顿住房数据集中的特征和标签组成的训练集。read_boston_data ()方法从 scikit-learn 读取并分别返回特征和标签:
def read_boston_data():
boston = load_boston()
features = np.array(boston.data)
labels = np.array(boston.target)
return features, labels
现在我们已经拥有特征和标签,我们还需要使用normalizer()方法对特征进行标准化。这是方法的签名:
def normalizer(dataset):
mu = np.mean(dataset,axis=0)
sigma = np.std(dataset,axis=0)
return(dataset - mu)/sigma
bias_vector()用于将偏差项(即全 1)附加到我们在前一步骤中准备的标准化特征。它对应于前一个例子中直线方程中的b项:
def bias_vector(features,labels):
n_training_samples = features.shape[0]
n_dim = features.shape[1]
f = np.reshape(np.c_[np.ones(n_training_samples),features],[n_training_samples,n_dim + 1])
l = np.reshape(labels,[n_training_samples,1])
return f, l
我们现在将调用这些方法并将数据集拆分为训练和测试,75% 用于训练和休息用于测试:
features,labels = read_boston_data()
normalized_features = normalizer(features)
data, label = bias_vector(normalized_features,labels)
n_dim = data.shape[1]
# Train-test split
train_x, test_x, train_y, test_y = train_test_split(data,label,test_size = 0.25,random_state = 100)
现在让我们使用 TensorFlow 的数据结构(例如占位符,标签和权重):
learning_rate = 0.01
training_epochs = 100000
log_loss = np.empty(shape=[1],dtype=float)
X = tf.placeholder(tf.float32,[None,n_dim]) #takes any number of rows but n_dim columns
Y = tf.placeholder(tf.float32,[None,1]) # #takes any number of rows but only 1 continuous column
W = tf.Variable(tf.ones([n_dim,1])) # W weight vector
做得好!我们已经准备好构建 TensorFlow 图所需的数据结构。现在是构建线性回归的时候了,这非常简单:
y_ = tf.matmul(X, W)
cost_op = tf.reduce_mean(tf.square(y_ - Y))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_op)
在前面的代码段中,第一行将特征矩阵乘以可用于预测的权重矩阵。第二行计算损失,即回归线的平方误差。最后,第三行执行 GD 优化的一步以最小化平方误差。
提示
使用哪种优化器:使用优化器的主要目的是最小化成本;因此,我们必须定义一个优化器。使用最常见的优化器(如 SGD),学习率必须以1 / T进行缩放才能获得收敛,其中T是迭代次数。
Adam 或 RMSProp 尝试通过调整步长来自动克服此限制,以使步长与梯度具有相同的比例。此外,在前面的示例中,我们使用了 Adam 优化器,它在大多数情况下都表现良好。
然而,如果您正在训练神经网络计算梯度是必须的,使用实现 RMSProp 算法的RMSPropOptimizer函数是一个更好的主意,因为它是在小批量设置中学习的更快的方式。研究人员还建议在训练深度 CNN 或 DNN 时使用 Momentum 优化器。
从技术上讲,RMSPropOptimizer 是一种先进的梯度下降形式,它将学习率除以指数衰减的平方梯度平均值。衰减参数的建议设置值为 0.9,而学习率的良好默认值为 0.001。
例如在 TensorFlow 中,tf.train.RMSPropOptimizer()帮助我们轻松使用它:
optimizer = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost_op)
现在,在我们开始训练模型之前,我们需要使用initialize_all_variables()方法初始化所有变量,如下所示:
init = tf.initialize_all_variables()
太棒了!现在我们已经设法准备好所有组件,我们已经准备好训练实际的训练了。我们首先创建 TensorFlow 会话,如下所示:
sess = tf.Session()
sess.run(init_op)
for epoch in range(training_epochs):
sess.run(training_step,feed_dict={X:train_x,Y:train_y})
log_loss = np.append(log_loss,sess.run(cost_op,feed_dict={X: train_x,Y: train_y}))
训练完成后,我们就可以对看不见的数据进行预测。然而,看到完成训练的直观表示会更令人兴奋。因此,让我们使用 Matplotlib 将成本绘制为迭代次数的函数:
plt.plot(range(len(log_loss)),log_loss)
plt.axis([0,training_epochs,0,np.max(log_loss)])
plt.show()
以下是上述代码的输出:
>>>
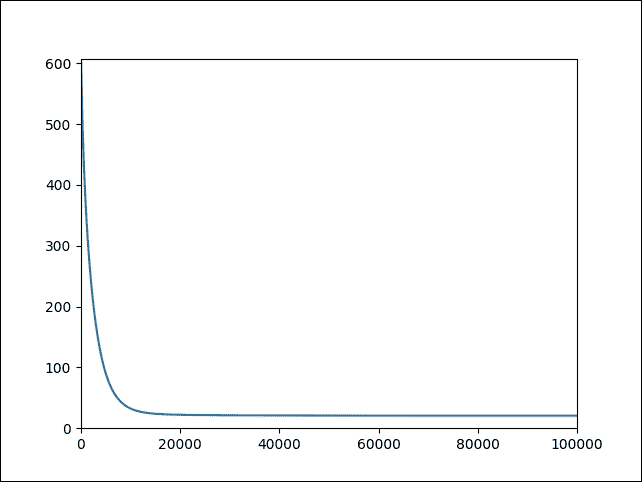
图 13:作为迭代次数函数的成本
对测试数据集做一些预测并计算均方误差:
pred_y = sess.run(y_, feed_dict={X: test_x})
mse = tf.reduce_mean(tf.square(pred_y - test_y))
print("MSE: %.4f" % sess.run(mse))
以下是上述代码的输出:
>>>
MSE: 27.3749
最后,让我们展示最佳拟合线:
fig, ax = plt.subplots()
ax.scatter(test_y, pred_y)
ax.plot([test_y.min(), test_y.max()], [test_y.min(), test_y.max()], 'k--', lw=3)
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
plt.show()
以下是上述代码的输出:
>>>
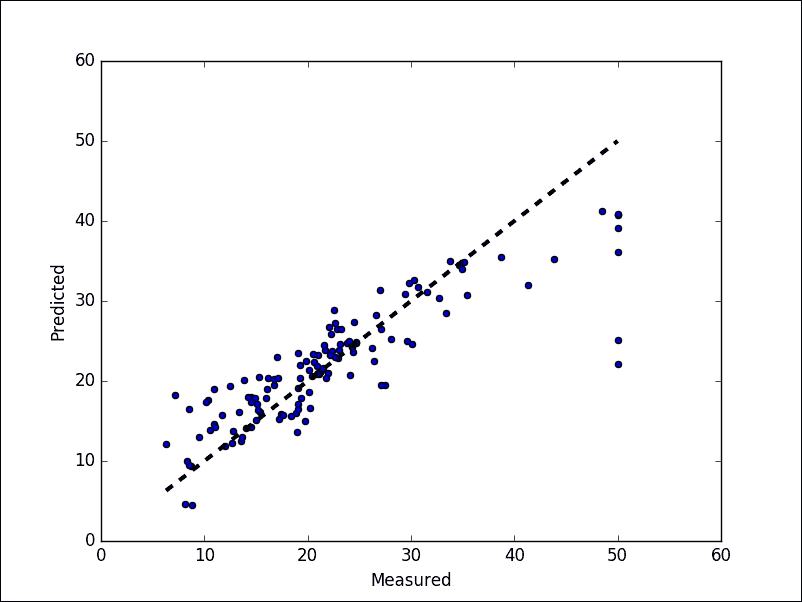
图 14:预测值与实际值
总结
TensorFlow 旨在通过 ML 和 DL 轻松地为每个人进行预测分析,但使用它确实需要对一些通用原则和算法有一个正确的理解。 TensorFlow 的最新版本带有许多令人兴奋的新功能,所以我们试图覆盖它们,以便您可以轻松使用它们。总之,这里简要回顾一下本章已经解释过的 TensorFlow 的关键概念:
- 图:每个 TensorFlow 计算可以表示为数据流图,其中每个图构建为一组操作对象。有三种核心图数据结构:
tf.Graph,tf.Operation和tf.Tensor)。 - 操作:图节点将一个或多个张量作为输入,并产生一个或多个张量作为输出。节点可以由操作对象表示,用于执行诸如加法,乘法,除法,减法或更复杂操作的计算单元。
- 张量:它们就像高维数组对象。换句话说,它们可以表示为数据流图的边缘,并且是不同操作的输出。
- 会话:会话对象是一个实体,它封装了执行操作对象的环境,以便在数据流图上运行计算。结果,在
run()或eval()调用内部求值张量对象。
在本章的后面部分,我们介绍了 TensorBoard,它是分析和调试神经网络模型的强大工具。最后,我们看到了如何在假数据集和真实数据集上实现最简单的基于 TensorFlow 的线性回归模型之一。
在下一章中,我们将讨论不同 FFNN 架构的理论背景,如深度信念网络(DBN)和多层感知器(MLP)。
然后,我们将展示如何训练和分析评估模型所需的表现指标,然后通过一些方法调整 FFNN 的超参数以优化表现。最后,我们将提供两个使用 MLP 和 DBN 的示例,说明如何为银行营销数据集建立非常强大和准确的预测分析模型。
三、实现前馈神经网络
自动识别手写数字是一个重要的问题,可以在许多实际应用中找到。在本节中,我们将实现一个前馈网络来解决这个问题。

图 3:从 MNIST 数据库中提取的数据示例
为了训练和测试已实现的模型,我们将使用一个名为 MNIST 的手写数字最着名的数据集。 MNIST 数据集是一个包含 60,000 个示例的训练集和一个包含 10,000 个示例的测试集。存储在示例文件中的数据示例如上图所示。
源图像最初是黑白的。之后,为了将它们标准化为20×20像素的大小,由于抗混叠滤波器用于调整大小的效果,引入了中间亮度级别。随后,在28×28像素的区域中将图像聚焦在像素的质心中,以便改善学习过程。整个数据库存储在四个文件中:
train-images-idx3-ubyte.gz:训练集图像(9912422 字节)train-labels-idx1-ubyte.gz:训练集标签(28881 字节)t10k-images-idx3-ubyte.gz:测试集图像(1648877 字节)t10k-labels-idx1-ubyte.gz:测试集标签(4542 字节)
每个数据库包含两个文件的 ;第一个包含图像,而第二个包含相应的标签。
探索 MNIST 数据集
让我们看一下如何访问 MNIST 数据的简短示例,以及如何显示所选图像。为此,只需执行Explore_MNIST.py脚本。首先,我们必须导入 numpy,因为我们必须进行一些图像处理:
import numpy as np
Matplotlib 中的pyplot函数用于绘制图像:
import matplotlib.pyplot as plt
我们将使用tensorflow.examples.tutorials.mnist中的input_data类,它允许我们下载 MNIST 数据库并构建数据集:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
然后我们使用read_data_sets方法加载数据集:
import os
dataPath = "temp/"
if not os.path.exists(dataPath):
os.makedirs(dataPath)
input = input_data.read_data_sets(dataPath, one_hot=True)
图像将保存在temp/目录中。现在让我们看看图像和标签的形状:
print(input.train.images.shape)
print(input.train.labels.shape)
print(input.test.images.shape)
print(input.test.labels.shape)
以下是上述代码的输出:
>>>
(55000, 784)
(55000, 10)
(10000, 784)
(10000, 10)
使用 Python 库matplotlib,我们想要可视化一个数字:
image_0 = input.train.images[0]
image_0 = np.resize(image_0,(28,28))
label_0 = input.train.labels[0]
print(label_0)
以下是上述代码的输出:
>>>
[ 0\. 0\. 0\. 0\. 0\. 0\. 0\. 1\. 0\. 0.]
数字1是数组的第八个位置。这意味着我们图像的数字是数字 7。最后,我们必须验证数字是否真的是 7。我们可以使用导入的plt函数来绘制image_0张量:
plt.imshow(image_0, cmap='Greys_r')
plt.show()
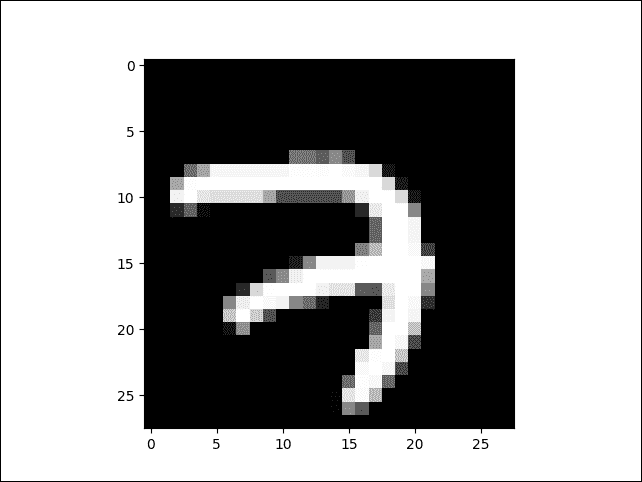
图 4:从 MNIST 数据集中提取的图像
Softmax 分类器
在上一节中,我们展示了如何访问和操作 MNIST 数据集。在本节中,我们将看到如何使用前面的数据集来解决 TensorFlow 手写数字的分类问题。我们将应用所学的概念来构建更多神经网络模型,以便评估和比较所采用的不同方法的结果。
将要实现的第一个前馈网络架构如下图所示:
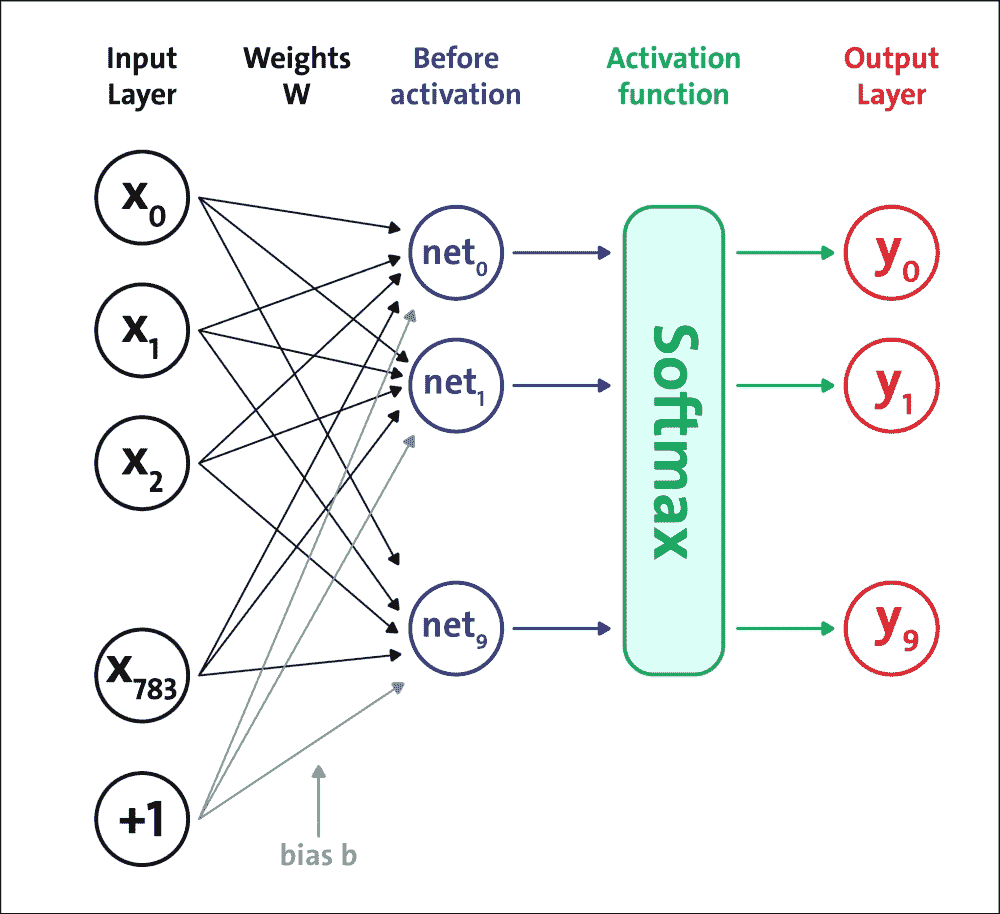
图 5:softmax 神经网络架构
我们将构建一个五层网络:第一层到第四层是 Sigmoid 结构,第五层是 softmax 激活函数。请记住,定义此网络是为了激活它是一组正值,总和等于 1。这意味着输出的第j个值是与网络输入对应的类j的概率。让我们看看如何实现我们的神经网络模型。
为了确定网络的适当大小(即,层中的神经元或单元的数量),即隐藏层的数量和每层神经元的数量,通常我们依赖于一般的经验标准,个人经验或适当的测试。这些是需要调整的一些超参数。在本章的后面,我们将看到一些超参数优化的例子。
下表总结了已实现的网络架构。它显示了每层神经元的数量,以及相应的激活函数:
| 层 | 神经元数量 | 激活函数 |
|---|---|---|
| 1 | L = 200 |
Sigmoid |
| 2 | M = 100 |
Sigmoid |
| 3 | N = 60 |
Sigmoid |
| 4 | O = 30 |
Sigmoid |
| 5 | 10 |
Softmax |
前四层的激活函数是 Sigmoid 函数。激活函数的最后一层始终是 softmax,因为网络的输出必须表示输入数字的概率。通常,中间层的数量和大小会极大地影响的网络表现:
- 以积极的方式,因为在这些层上是基于网络推广的能力,并检测输入的特殊特征
- 以负面的方式,因为如果网络是冗余的,那么它会不必要地减轻学习阶段的负担
为此,只需执行five_layers_sigmoid.py脚本。首先,我们将通过导入以下库来开始实现网络:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import math
from tensorflow.python.framework import ops
import random
import os
接下来,我们将设置以下配置参数:
logs_path = 'log_sigmoid/' # logging path
batch_size = 100 # batch size while performing training
learning_rate = 0.003 # Learning rate
training_epochs = 10 # training epoch
display_epoch = 1
然后,我们将下载图像和标签,并准备数据集:
dataPath = "temp/"
if not os.path.exists(dataPath):
os.makedirs(dataPath)
mnist = input_data.read_data_sets(dataPath, one_hot=True) # MNIST to be downloaded
从输入层开始,我们现在将看看如何构建网络架构。输入层现在是形状[1×784]的张量 - 即[1,28 * 28],它代表要分类的图像:
X = tf.placeholder(tf.float32, [None, 784], name='InputData') # image shape 28*28=784
XX = tf.reshape(X, [-1, 784]) # reshape input
Y_ = tf.placeholder(tf.float32, [None, 10], name='LabelData') # 0-9 digits => 10 classes
第一层接收要分类的输入图像的像素,与W1权重连接组合,并添加到B1偏差张量的相应值:
W1 = tf.Variable(tf.truncated_normal([784, L], stddev=0.1)) # Initialize random weights for the hidden layer 1
B1 = tf.Variable(tf.zeros([L])) # Bias vector for layer 1
第一层通过 sigmoid 激活函数将其输出发送到第二层:
Y1 = tf.nn.sigmoid(tf.matmul(XX, W1) + B1) # Output from layer 1
第二层从第一层接收Y1输出,将其与W2权重连接组合,并将其添加到B2偏差张量的相应值:
W2 = tf.Variable(tf.truncated_normal([L, M], stddev=0.1)) # Initialize random weights for the hidden layer 2
B2 = tf.Variable(tf.ones([M])) # Bias vector for layer 2
第二层通过 sigmoid 激活函数将其输出发送到第三层:
Y2 = tf.nn.sigmoid(tf.matmul(Y1, W2) + B2) # Output from layer 2
第三层接收来自第二层的Y2输出,将其与W3权重连接组合,并将其添加到B3偏差张量的相应值:
W3 = tf.Variable(tf.truncated_normal([M, N], stddev=0.1)) # Initialize random weights for the hidden layer 3
B3 = tf.Variable(tf.ones([N])) # Bias vector for layer 3
第三层通过 sigmoid 激活函数将其输出发送到第四层:
Y3 = tf.nn.sigmoid(tf.matmul(Y2, W3) + B3) # Output from layer 3
第四层接收来自第三层的Y3输出,将其与W4权重连接组合,并将其添加到B4偏差张量的相应值:
W4 = tf.Variable(tf.truncated_normal([N, O], stddev=0.1)) # Initialize random weights for the hidden layer 4
B4 = tf.Variable(tf.ones([O])) # Bias vector for layer 4
然后通过 Sigmoid 激活函数将第四层的输出传播到第五层:
Y4 = tf.nn.sigmoid(tf.matmul(Y3, W4) + B4) # Output from layer 4
第五层将在输入中接收来自第四层的激活O = 30,该激活将通过softmax激活函数,转换为每个数字的相应概率类别:
W5 = tf.Variable(tf.truncated_normal([O, 10], stddev=0.1)) # Initialize random weights for the hidden layer 5
B5 = tf.Variable(tf.ones([10])) # Bias vector for layer 5
Ylogits = tf.matmul(Y4, W5) + B5 # computing the logits
Y = tf.nn.softmax(Ylogits)# output from layer 5
这里,我们的损失函数是目标和softmax激活函数之间的交叉熵,应用于模型的预测:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=Ylogits, labels=Y) # final outcome using softmax cross entropy
cost_op = tf.reduce_mean(cross_entropy)*100
另外,我们定义correct_prediction和模型的准确率:
correct_prediction = tf.equal(tf.argmax(Y, 1), tf.argmax(Y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
现在我们需要使用优化器来减少训练误差。与简单的GradientDescentOptimizer相比,AdamOptimizer具有几个优点。实际上,它使用更大的有效步长,算法将收敛到此步长而不进行微调:
# Optimization op (backprop)
train_op = tf.train.AdamOptimizer(learning_rate).minimize(cost_op)
Optimizer基类提供了计算损失梯度的方法,并将梯度应用于变量。子类集合实现了经典的优化算法,例如GradientDescent和Adagrad。在 TensorFlow 中训练 NN 模型时,我们从不实例化Optimizer类本身,而是实例化以下子类之一
tf.train.Optimizertf.train.GradientDescentOptimizertf.train.AdadeltaOptimizertf.train.AdagradOptimizertf.train.AdagradDAOptimizertf.train.MomentumOptimizertf.train.AdamOptimizertf.train.FtrlOptimizertf.train.ProximalGradientDescentOptimizertf.train.ProximalAdagradOptimizertf.train.RMSPropOptimizer
见此链接和tf.contrib.opt用于更多优化器。
然后让我们构建一个将所有操作封装到范围中的模型,使 TensorBoard 的图可视化更加方便:
# Create a summary to monitor cost tensor
tf.summary.scalar("cost", cost_op)
# Create a summary to monitor accuracy tensor
tf.summary.scalar("accuracy", accuracy)
# Merge all summaries into a single op
summary_op = tf.summary.merge_all()
最后,我们将开始训练:
with tf.Session() as sess:
# Run the initializer
sess.run(init_op)
# op to write logs to TensorBoard
writer = tf.summary.FileWriter(logs_path, graph=tf.get_default_graph())
for epoch in range(training_epochs):
batch_count = int(mnist.train.num_examples/batch_size)
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
_,summary = sess.run([train_op, summary_op], feed_dict={X: batch_x, Y_: batch_y})
writer.add_summary(summary, epoch * batch_count + i)
print("Epoch: ", epoch)
print("Optimization Finished!")
print("Accuracy: ", accuracy.eval(feed_dict={X: mnist.test.images, Y_: mnist.test.labels}))
定义摘要和会话运行的源代码几乎与前一个相同。我们可以直接转向评估实现的模型。运行模型时,我们有以下输出:
运行此代码后的最终测试设置准确率应约为 97%:
Extracting temp/train-images-idx3-ubyte.gz
Extracting temp/train-labels-idx1-ubyte.gz
Extracting temp/t10k-images-idx3-ubyte.gz
Extracting temp/t10k-labels-idx1-ubyte.gz
Epoch: 0
Epoch: 1
Epoch: 2
Epoch: 3
Epoch: 4
Epoch: 5
Epoch: 6
Epoch: 7
Epoch: 8
Epoch: 9
Optimization Finished!
Accuracy: 0.9
715
现在我们可以通过在运行文件夹中打开终端然后执行以下命令来移动到 TensorBoard:
$> tensorboard --logdir='log_sigmoid/' # if required, provide absolute path
然后我们在localhost上打开浏览器。在下图中,我们显示了成本函数的趋势,作为示例数量的函数,在训练集上,以及测试集的准确率:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yJptXo1w-1681565849696)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_03_06.jpg)]
图 6:测试集上的准确率函数,以及训练集上的成本函数
成本函数随着迭代次数的增加而减少。如果没有发生这种情况,则意味着出现了问题。在最好的情况下,这可能只是因为某些参数未正确设置。在最坏的情况下,构建的数据集中可能存在问题,例如,信息太少或图像质量差。如果发生这种情况,我们必须直接修复数据集。
到目前为止,我们已经看到了 FFNN 的实现。但是,使用真实数据集探索更有用的 FFNN 实现会很棒。我们将从 MLP 开始。
实现多层感知器(MLP)
感知器单层 LTU 组成,每个神经元连接到所有输入。这些连接通常使用称为输入神经元的特殊传递神经元来表示:它们只输出它们被输入的任何输入。此外,通常添加额外的偏置特征(x0 = 1)。
这种偏置特征通常使用称为偏置神经元的特殊类型的神经元来表示,一直输出 1。具有两个输入和三个输出的感知器在图 7 中表示。该感知器可以同时将实例分类为三个不同的二元类,这使其成为多输出分类器:
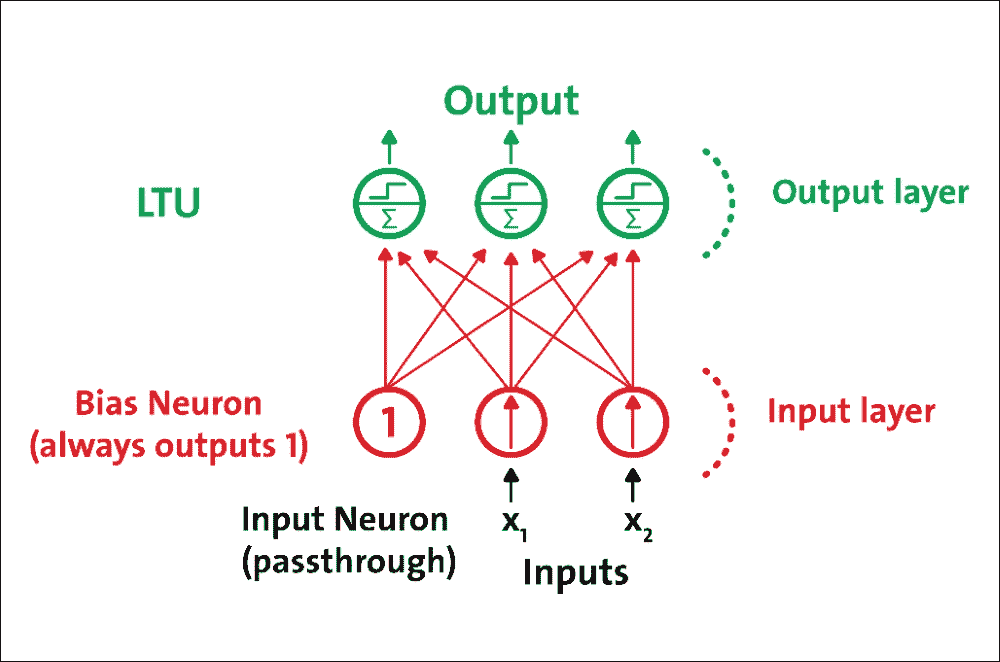
图 7:具有两个输入和三个输出的感知器
由于每个输出神经元的决策边界是线性的,因此感知器无法学习复杂模式。然而,如果训练实例是线性可分的,研究表明该算法将收敛于称为“感知器收敛定理”的解决方案。
MLP 是 FFNN,这意味着它是来自不同层的神经元之间的唯一连接。更具体地,MLP 由一个(通过)输入层,一个或多个 LTU 层(称为隐藏层)和一个称为输出层的 LTU 的最后一层组成。除输出层外,每一层都包含一个偏置神经元,并作为完全连接的二分图连接到下一层:
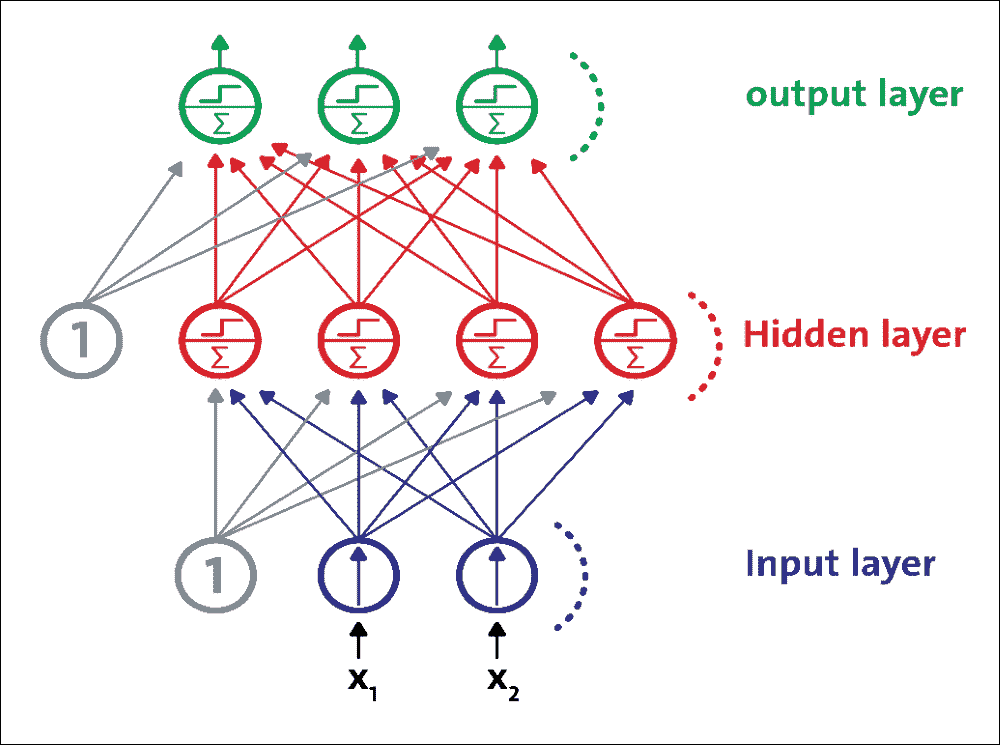
图 8:MLP 由一个输入层,一个隐藏层和一个输出层组成
训练 MLP
MLP 在 1986 年首次使用反向传播训练算法成功训练。然而,现在这种算法的优化版本被称为梯度下降。在训练阶段期间,对于每个训练实例,算法将其馈送到网络并计算每个连续层中的每个神经元的输出。
训练算法测量网络的输出误差(即,期望输出和网络的实际输出之间的差异),并计算最后隐藏层中每个神经元对每个输出神经元误差的贡献程度。然后,它继续测量这些误差贡献中有多少来自先前隐藏层中的每个神经元,依此类推,直到算法到达输入层。通过在网络中向后传播误差梯度,该反向传递有效地测量网络中所有连接权重的误差梯度。
在技术上,通过反向传播方法计算每层的成本函数的梯度。梯度下降的想法是有一个成本函数,显示某些神经网络的预测输出与实际输出之间的差异:
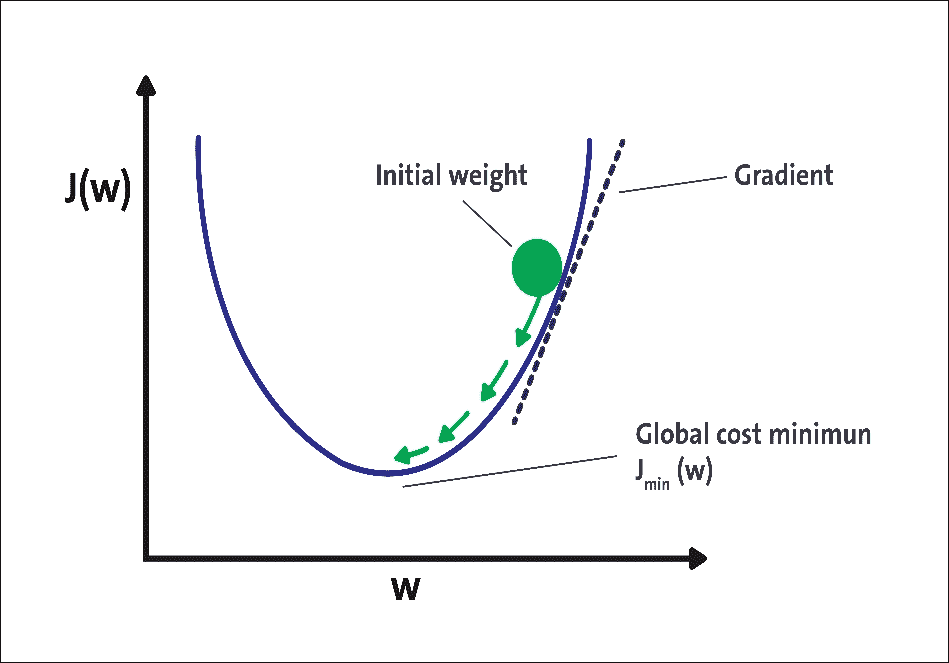
图 9:用于无监督学习的 ANN 的示例实现
有几种已知类型的代价函数,例如平方误差函数和对数似然函数。该成本函数的选择可以基于许多因素。梯度下降法通过最小化此成本函数来优化网络的权重。步骤如下:
- 权重初始化
- 计算神经网络的预测输出,通常称为转发传播步骤
- 计算成本/损失函数。一些常见的成本/损失函数包括对数似然函数和平方误差函数
- 计算成本/损失函数的梯度。对于大多数 DNN 架构,最常见的方法是反向传播
- 基于当前权重的权重更新,以及成本/损失函数的梯度
- 步骤 2 到 5 的迭代,直到成本函数,达到某个阈值或经过一定量的迭代
图 9 中可以看到梯度下降的图示。该图显示了基于网络权重的神经网络的成本函数。在梯度下降的第一次迭代中,我们将成本函数应用于一些随机初始权重。对于每次迭代,我们在梯度方向上更新权重,这对应于图 9 中的箭头。重复更新直到一定次数的迭代或直到成本函数达到某个阈值。
使用 MLP
多层感知器通常用于以监督方式解决分类和回归问题。尽管 CNN 逐渐取代了它们在图像和视频数据中的实现,但仍然可以有效地使用低维和数字特征 MLP:可以解决二元和多类分类问题。
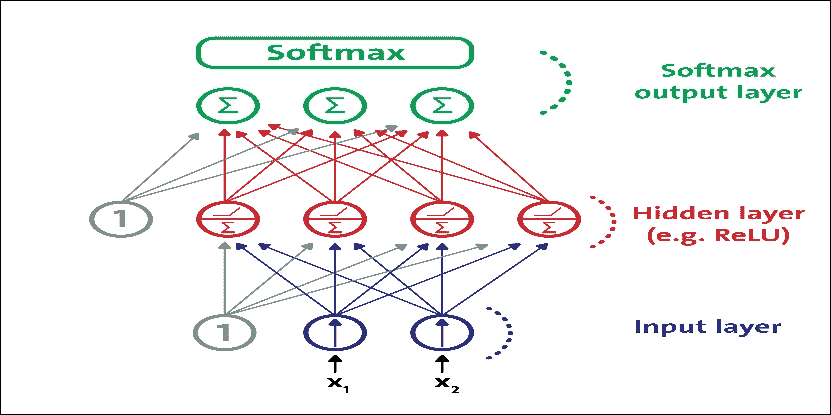
图 10:用于分类的现代 MLP(包括 ReLU 和 softmax)
然而,对于多类分类任务和训练,通常通过用共享 softmax 函数替换各个激活函数来修改输出层。每个神经元的输出对应于相应类的估计概率。请注意,信号仅在一个方向上从输入流向输出,因此该架构是 FFNN 的示例。
作为案例研究,我们将使用银行营销数据集。这些数据与葡萄牙银行机构的直接营销活动有关。营销活动基于电话。通常,不止一次联系同一个客户,以评估产品(银行定期存款)是(是)还是不(否)订阅。 目标是使用 MLP 来预测客户是否会订阅定期存款(变量 y),即二元分类问题。
数据集描述
我想在此承认有两个来源。这个数据集被用于 Moro 和其他人发表的一篇研究论文中:一种数据驱动的方法来预测银行电话营销的成功,决策支持系统,Elsevier,2014 年 6 月。后来,它被捐赠给了 UCI 机器学习库,可以从此链接下载。
根据数据集描述,有四个数据集:
bank-additional-full.csv:这包括所有示例(41,188)和 20 个输入,按日期排序(从 2008 年 5 月到 2010 年 11 月)。这些数据非常接近 Moro 和其他人分析的数据bank-additional.csv:这包括 10% 的例子(4119),从 1 和 20 个输入中随机选择bank-full.csv:这包括按日期排序的所有示例和 17 个输入(此数据集的较旧版本,输入较少)bank.csv:这包括 10% 的示例和 17 个输入,从 3 中随机选择(此数据集的较旧版本,输入较少)
数据集中有 21 个属性。独立变量可以进一步分类为与客户相关的数据(属性 1 到 7),与当前活动的最后一次联系(属性 8 到 11)相关。其他属性(属性 12 至 15)以及社会和经济背景属性(属性 16 至 20)被分类。因变量由 y 指定,最后一个属性(21):
| ID | 属性 | 说明 |
|---|---|---|
| 1 | age |
年龄数字。 |
| 2 | job |
这是类别格式的职业类型,具有可能的值:admin,blue-collar,entrepreneur,housemaid,management,retired,self-employed,services,student,technician,unemployed和unknown。 |
| 3 | marital |
这是类别格式的婚姻状态,具有可能的值:divorced(或widowed),married,single和unknown。 |
| 4 | education |
这是类别格式的教育背景,具有如下可能的值:basic.4y,basic.6y,basic.9y,high.school,illiterate,professional.course,university.degree和unknown。 |
| 五 | default |
这是类别格式的信用,默认情况下可能包含:no,yes和unknown。 |
| 6 | housing |
客户是否有住房贷款? |
| 7 | loan |
类别格式的个人贷款,具有可能的值:no,yes和unknown。 |
| 8 | contact |
这是类别格式的通信类型,具有可能的值:cellular或telephone。 |
| 9 | month |
这是类别格式的一年中最后一个通话月份,具有可能的值:jan,feb,mar,… nov和dec。 |
| 10 | day_of_week |
这是类别格式的一周中的最后一个通话日,具有可能的值:mon,tue,wed,thu和fri。 |
| 11 | duration |
这是以秒为单位的最后一次通话持续时间(数值)。此属性高度影响输出目标(例如,如果duration = 0,则y = no)。然而,在通话之前不知道持续时间。另外,在通话结束后,y显然是已知的。因此,此输入仅应包括在基准目的中,如果打算采用现实的预测模型,则应将其丢弃。 |
| 12 | campaign |
这是活动期间此客户的通话数量。 |
| 13 | pdays |
这是上一个广告系列和客户的上次通话之后经过的天数(数字 -999 表示之前未联系过客户)。 |
| 14 | previous |
这是之前此广告系列和此客户的通话数量(数字)。 |
| 15 | poutcome |
上一次营销活动的结果(类别:failure,nonexistent和success)。 |
| 16 | emp.var.rate |
这是就业变化率的季度指标(数字)。 |
| 17 | cons.price.idx |
这是消费者价格指数的月度指标(数字)。 |
| 18 | cons.conf.idx |
这是消费者信心指数的月度指标(数字)。 |
| 19 | euribor3m |
这是 3 个月的 euribor 费率的每日指标(数字)。 |
| 20 | nr.employed |
这是员工数的季度指标(数字)。 |
| 21 | y |
表示客户是否拥有定期存款,可能值是二元:yes和no。 |
预处理
您可以看到数据集尚未准备好直接输入 MLP 或 DBN 分类器,因为该特征与数值和分类值混合在一起。此外,结果变量具有分类值。因此,我们需要将分类值转换为数值,以便特征和结果变量以数字形式。下一步显示了此过程。有关此预处理,请参阅preprocessing_b.py文件。
首先,我们必须加载预处理所需的所需包和库:
import pandas as pd
import numpy as np
from sklearn import preprocessing
然后从上述 URL 下载数据文件并将其放在方便的位置 - 比如说input:
然后,我们加载并解析数据集:
data = pd.read_csv('input/bank-additional-full.csv', sep = ";")
接下来,我们将提取变量名称:
var_names = data.columns.tolist()
现在,基于表 1 中的数据集描述,我们将提取分类变量:
categs = ['job','marital','education','default','housing','loan','contact','month','day_of_week','duration','poutcome','y']
然后,我们将提取定量变量:
# Quantitative vars
quantit = [i for i in var_names if i not in categs]
然后让我们得到分类变量的虚拟变量:
job = pd.get_dummies(data['job'])
marital = pd.get_dummies(data['marital'])
education = pd.get_dummies(data['education'])
default = pd.get_dummies(data['default'])
housing = pd.get_dummies(data['housing'])
loan = pd.get_dummies(data['loan'])
contact = pd.get_dummies(data['contact'])
month = pd.get_dummies(data['month'])
day = pd.get_dummies(data['day_of_week'])
duration = pd.get_dummies(data['duration'])
poutcome = pd.get_dummies(data['poutcome'])
现在,是时候映射变量来预测:
dict_map = dict()
y_map = {'yes':1,'no':0}
dict_map['y'] = y_map
data = data.replace(dict_map)
label = data['y']
df_numerical = data[quantit]
df_names = df_numerical .keys().tolist()
一旦我们将分类变量转换为数值变量,下一个任务就是正则化数值变量。因此,使用归一化,我们将单个样本缩放为具有单元规范。如果您计划使用二次形式(如点积或任何其他内核)来量化任何样本对的相似性,则此过程非常有用。该假设是在文本分类和聚类上下文中经常使用的向量空间模型的基础。
那么,让我们来衡量量化变量:
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(df_numerical)
df_temp = pd.DataFrame(x_scaled)
df_temp.columns = df_names
现在我们有(原始)数值变量的临时数据帧,下一个任务是将所有数据帧组合在一起并生成正则化数据帧。我们将使用熊猫:
normalized_df = pd.concat([df_temp,
job,
marital,
education,
default,
housing,
loan,
contact,
month,
day,
poutcome,
duration,
label], axis=1)
最后,我们需要将结果数据帧保存在 CSV 文件中,如下所示:
normalized_df.to_csv('bank_normalized.csv', index = False)
用于客户订阅评估的 TensorFlow 中的 MLP 实现
对于这个例子,我们将使用我们在前面的例子中正则化的银行营销数据集。有几个步骤可以遵循。首先,我们需要导入 TensorFlow,以及其他必要的包和模块:
import tensorflow as tf
import pandas as pd
import numpy as np
import os
from sklearn.cross_validation import train_test_split # for random split of train/test
现在,我们需要加载正则化的银行营销数据集,其中所有特征和标签都是数字。为此,我们使用 pandas 库中的read_csv()方法:
FILE_PATH = 'bank_normalized.csv' # Path to .csv dataset
raw_data = pd.read_csv(FILE_PATH) # Open raw .csv
print("Raw data loaded successfully...\n")
以下是上述代码的输出:
>>>
Raw data loaded successfully...
如前一节所述,调整 DNN 的超参数并不简单。但是,它通常取决于您正在处理的数据集。对于某些数据集,可能的解决方法是根据与数据集相关的统计信息设置这些值,例如,训练实例的数量,输入大小和类的数量。
DNN 不适用于小型和低维数据集。在这些情况下,更好的选择是使用线性模型。首先,让我们放置一个指向标签列本身的指针,计算实例数和类数,并定义训练/测试分流比,如下所示:
Y_LABEL = 'y' # Name of the variable to be predicted
KEYS = [i for i in raw_data.keys().tolist() if i != Y_LABEL]# Name of predictors
N_INSTANCES = raw_data.shape[0] # Number of instances
N_INPUT = raw_data.shape[1] - 1 # Input size
N_CLASSES = raw_data[Y_LABEL].unique().shape[0] # Number of classes
TEST_SIZE = 0.25 # Test set size (% of dataset)
TRAIN_SIZE = int(N_INSTANCES * (1 - TEST_SIZE)) # Train size
现在,让我们看一下我们将用于训练 MLP 模型的数据集的统计数据:
print("Variables loaded successfully...\n")
print("Number of predictors \t%s" %(N_INPUT))
print("Number of classes \t%s" %(N_CLASSES))
print("Number of instances \t%s" %(N_INSTANCES))
print("\n")
以下是上述代码的输出:
>>>
Variables loaded successfully...
Number of predictors 1606
Number of classes 2
Number of instances 41188
下一个任务是定义其他参数,例如学习率,训练周期,批量大小和权重的标准偏差。通常,较低的训练率会帮助您的 DNN 学习更慢,但需要集中精力。请注意,我们需要定义更多参数,例如隐藏层数和激活函数。
LEARNING_RATE = 0.001 # learning rate
TRAINING_EPOCHS = 1000 # number of training epoch for the forward pass
BATCH_SIZE = 100 # batch size to be used during training
DISPLAY_STEP = 20 # print the error etc. at each 20 step
HIDDEN_SIZE = 256 # number of neurons in each hidden layer
# We use tanh as the activation function, but you can try using ReLU as well
ACTIVATION_FUNCTION_OUT = tf.nn.tanh
STDDEV = 0.1 # Standard Deviations
RANDOM_STATE = 100
前面的初始化是基于反复试验设置的 。因此,根据您的用例和数据类型,明智地设置它们,但我们将在本章后面提供一些指导。此外,对于前面的代码,RANDOM_STATE用于表示训练的随机状态和测试分割。首先,我们将原始特征和标签分开:
data = raw_data[KEYS].get_values() # X data
labels = raw_data[Y_LABEL].get_values() # y data
现在我们有标签,他们必须编码:
labels_ = np.zeros((N_INSTANCES, N_CLASSES))
labels_[np.arange(N_INSTANCES), labels] = 1
最后,我们必须拆分训练和测试集。如前所述,我们将保留 75% 的训练输入,剩下的 25% 用于测试集:
data_train, data_test, labels_train, labels_test = train_test_split(data,labels_,test_size = TEST_SIZE,random_state = RANDOM_STATE)
print("Data loaded and splitted successfully...\n")
以下是上述代码的输出:
>>>
Data loaded and splitted successfully
由于这是一个监督分类问题,我们应该有特征和标签的占位符:
如前所述,MLP 由一个输入层,几个隐藏层和一个称为输出层的最终 LTU 层组成。对于这个例子,我将把训练与四个隐藏层结合起来。因此,我们将分类器称为深度前馈 MLP。请注意,我们还需要在每个层中使用权重(输入层除外),以及每个层中的偏差(输出层除外)。通常,每个隐藏层包括偏置神经元,并且作为从一个隐藏层到另一个隐藏层的完全连接的二分图(前馈)完全连接到下一层。那么,让我们定义隐藏层的大小:
n_input = N_INPUT # input n labels
n_hidden_1 = HIDDEN_SIZE # 1st layer
n_hidden_2 = HIDDEN_SIZE # 2nd layer
n_hidden_3 = HIDDEN_SIZE # 3rd layer
n_hidden_4 = HIDDEN_SIZE # 4th layer
n_classes = N_CLASSES # output m classes
由于这是一个监督分类问题,我们应该有特征和标签的占位符:
# input shape is None * number of input
X = tf.placeholder(tf.float32, [None, n_input])
占位符的第一个维度是None,这意味着我们可以有任意数量的行。第二个维度固定在多个特征上,这意味着每行需要具有该列数量的特征。
# label shape is None * number of classes
y = tf.placeholder(tf.float32, [None, n_classes])
另外,我们需要另一个占位符用于丢弃,这是通过仅以某种可能性保持神经元活动(例如p < 1.0,或者将其设置为零来实现)来实现的。请注意,这也是要调整的超参数和训练时间,而不是测试时间:
dropout_keep_prob = tf.placeholder(tf.float32)
使用此处给出的缩放,可以将相同的网络用于训练(使用dropout_keep_prob < 1.0)和评估(使用dropout_keep_prob == 1.0)。现在,我们可以定义一个实现 MLP 分类器的方法。为此,我们将提供四个参数,如输入,权重,偏置和丢弃概率,如下所示:
def DeepMLPClassifier(_X, _weights, _biases, dropout_keep_prob):
layer1 = tf.nn.dropout(tf.nn.tanh(tf.add(tf.matmul(_X, _weights['h1']), _biases['b1'])), dropout_keep_prob)
layer2 = tf.nn.dropout(tf.nn.tanh(tf.add(tf.matmul(layer1, _weights['h2']), _biases['b2'])), dropout_keep_prob)
layer3 = tf.nn.dropout(tf.nn.tanh(tf.add(tf.matmul(layer2, _weights['h3']), _biases['b3'])), dropout_keep_prob)
layer4 = tf.nn.dropout(tf.nn.tanh(tf.add(tf.matmul(layer3, _weights['h4']), _biases['b4'])), dropout_keep_prob)
out = ACTIVATION_FUNCTION_OUT(tf.add(tf.matmul(layer4, _weights['out']), _biases['out']))
return out
上述方法的返回值是激活函数的输出。前面的方法是一个存根实现,它没有告诉任何关于权重和偏置的具体内容,所以在我们开始训练之前,我们应该定义它们:
weights = {
'w1': tf.Variable(tf.random_normal([n_input, n_hidden_1],stddev=STDDEV)),
'w2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2],stddev=STDDEV)),
'w3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_3],stddev=STDDEV)),
'w4': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_4],stddev=STDDEV)),
'out': tf.Variable(tf.random_normal([n_hidden_4, n_classes],stddev=STDDEV)),
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'b3': tf.Variable(tf.random_normal([n_hidden_3])),
'b4': tf.Variable(tf.random_normal([n_hidden_4])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
现在我们可以使用真实参数(输入层,权重,偏置和退出)调用前面的 MLP 实现,保持概率如下:
pred = DeepMLPClassifier(X, weights, biases, dropout_keep_prob)
我们建立了 MLP 模型,是时候训练网络了。首先,我们需要定义成本操作,然后我们将使用 Adam 优化器,它将慢慢学习并尝试尽可能减少训练损失:
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=pred, labels=y))
# Optimization op (backprop)
optimizer = tf.train.AdamOptimizer(learning_rate = LEARNING_RATE).minimize(cost_op)
接下来,我们需要定义用于计算分类准确率的其他参数:
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Deep MLP networks has been built successfully...")
print("Starting training...")
之后,我们需要在启动 TensorFlow 会话之前初始化所有变量和占位符:
init_op = tf.global_variables_initializer()
现在,我们非常接近开始训练,但在此之前,最后一步是创建 TensorFlow 会话并按如下方式启动它:
sess = tf.Session()
sess.run(init_op)
最后,我们准备开始在训练集上训练我们的 MLP。我们遍历所有批次并使用批量数据拟合以计算平均训练成本。然而,显示每个周期的训练成本和准确率会很棒:
for epoch in range(TRAINING_EPOCHS):
avg_cost = 0.0
total_batch = int(data_train.shape[0] / BATCH_SIZE)
# Loop over all batches
for i in range(total_batch):
randidx = np.random.randint(int(TRAIN_SIZE), size = BATCH_SIZE)
batch_xs = data_train[randidx, :]
batch_ys = labels_train[randidx, :]
# Fit using batched data
sess.run(optimizer, feed_dict={X: batch_xs, y: batch_ys, dropout_keep_prob: 0.9})
# Calculate average cost
avg_cost += sess.run(cost, feed_dict={X: batch_xs, y: batch_ys, dropout_keep_prob:1.})/total_batch
# Display progress
if epoch % DISPLAY_STEP == 0:
print("Epoch: %3d/%3d cost: %.9f" % (epoch, TRAINING_EPOCHS, avg_cost))
train_acc = sess.run(accuracy, feed_dict={X: batch_xs, y: batch_ys, dropout_keep_prob:1.})
print("Training accuracy: %.3f" % (train_acc))
print("Your MLP model has been trained successfully.")
以下是上述代码的输出:
>>>
Starting training...
Epoch: 0/1000 cost: 0.356494816
Training accuracy: 0.920
…
Epoch: 180/1000 cost: 0.350044933
Training accuracy: 0.860
….
Epoch: 980/1000 cost: 0.358226758
Training accuracy: 0.910
干得好,我们的 MLP 模型已经成功训练!现在,如果我们以图形方式看到成本和准确率怎么办?我们来试试吧:
# Plot loss over time
plt.subplot(221)
plt.plot(i_data, cost_list, 'k--', label='Training loss', linewidth=1.0)
plt.title('Cross entropy loss per iteration')
plt.xlabel('Iteration')
plt.ylabel('Cross entropy loss')
plt.legend(loc='upper right')
plt.grid(True)
以下是上述代码的输出 :
>>>
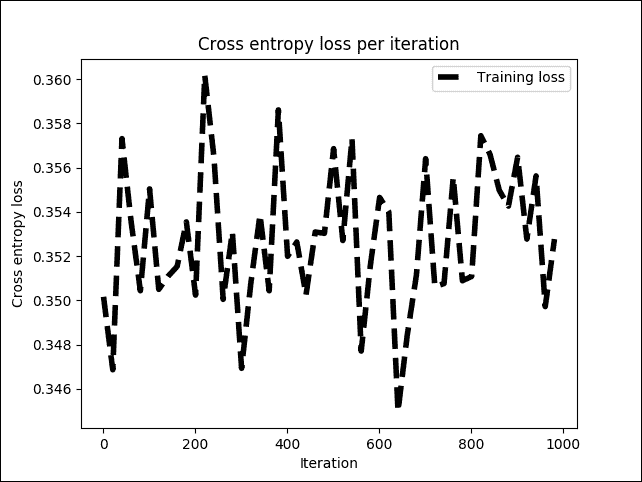
图 11:训练阶段每次迭代的交叉熵损失
上图显示交叉熵损失在 0.34 和 0.36 之间或多或少稳定,但波动很小。现在,让我们看看这对整体训练准确率有何影响:
# Plot train and test accuracy
plt.subplot(222)
plt.plot(i_data, acc_list, 'r--', label='Accuracy on the training set', linewidth=1.0)
plt.title('Accuracy on the training set')
plt.xlabel('Iteration')
plt.ylabel('Accuracy')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
以下是前面代码的输出:
>>>
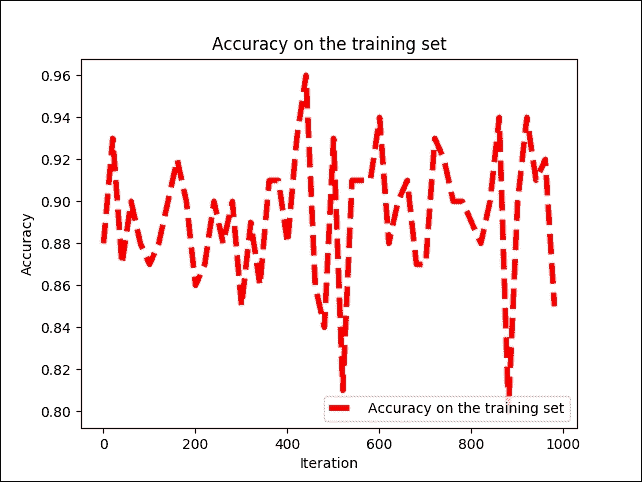
图 12:每次迭代时训练集的准确率
我们可以看到训练准确率在 79% 和 96% 之间波动,但不会均匀地增加或减少。解决此问题的一种可能方法是添加更多隐藏层并使用不同的优化器,例如本章前面讨论的梯度下降。我们将丢弃概率提高到 100%,即 1.0。原因是也有相同的网络用于测试:
print("Evaluating MLP on the test set...")
test_acc = sess.run(accuracy, feed_dict={X: data_test, y: labels_test, dropout_keep_prob:1.})
print ("Prediction/classification accuracy: %.3f" % (test_acc))
以下是上述代码的输出:
>>>
Evaluating MLP on the test set...
Prediction/classification accuracy: 0.889
Session closed!
因此,分类准确率约为 89%。一点也不差!现在,如果需要更高的精度,我们可以使用称为深度信任网络(DBN)的另一种 DNN 架构,可以以有监督或无监督的方式进行训练。
这是在其应用中作为分类器观察 DBN 的最简单方法。如果我们有一个 DBN 分类器,那么预训练方法是以类似于自编码器的无监督方式完成的,这将在第 5 章中描述,优化 TensorFlow 自编码器,分类器以受监督的方式训练(微调),就像 MLP 中的那样。
深度信念网络(DBNs)
为了克服 MLP 中的过拟合问题,我们建立了一个 DBN,进行无监督的预训练,为输入获得一组不错的特征表示,然后对训练集进行微调以获得预测。网络。
虽然 MLP 的权重是随机初始化的,但 DBN 使用贪婪的逐层预训练算法通过概率生成模型初始化网络权重。这些模型由可见层和多层随机潜在变量组成,这些变量称为隐藏单元或特征检测器。
堆叠 DBN 中的 RBM,形成无向概率图模型,类似于马尔可夫随机场(MRF):两层由可见神经元和隐藏神经元组成。
堆叠 RBM 中的顶部两层在它们之间具有无向的对称连接并形成关联存储器,而较低层从上面的层接收自上而下的定向连接:
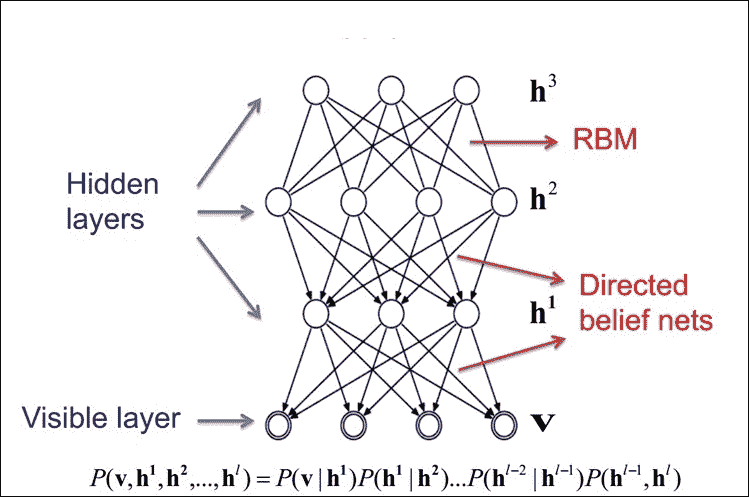
图 13:RBM 作为构建块的 DBN 的高级视图
顶部两层在它们之间具有无向的对称连接并形成关联存储器,而较低层从前面的层接收自上而下的定向连接。几个 RBM 一个接一个地堆叠以形成 DBN。
受限玻尔兹曼机(RBMs)
RBM 是无向概率图模型,称为马尔科夫随机场。它由两层组成。第一层由可见神经元组成,第二层由隐藏神经元组成。图 14 显示了简单 RBM 的结构。可见单元接受输入,隐藏单元是非线性特征检测器。每个可见神经元都连接到所有隐藏的神经元,但同一层中的神经元之间没有内部连接:
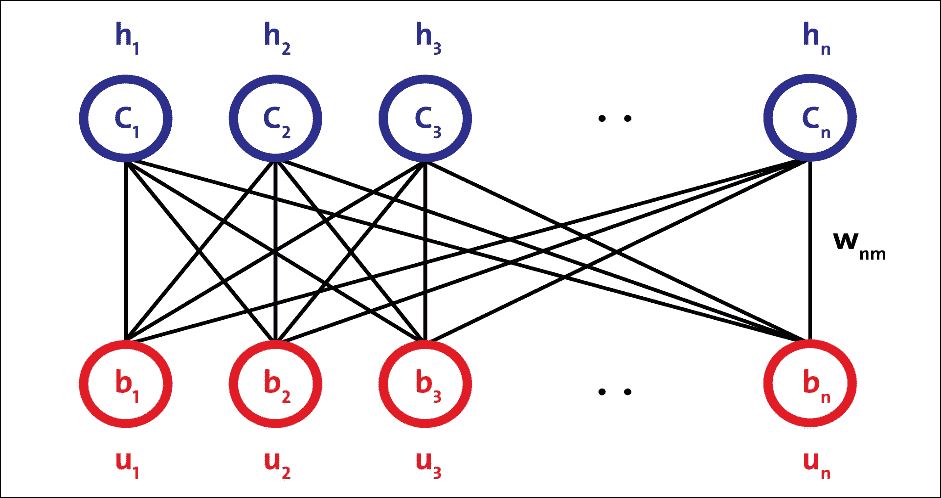
图 14:简单 RBM 的结构
图 14 中的 RBM 由m个可见单元组成,V = (v[1] ... v[m])和n个隐藏单元,H = (h[1] ... h[n])。可见单元接受 0 到 1 之间的值,隐藏单元的生成值介于 0 和 1 之间。模型的联合概率是由以下等式给出的能量函数:
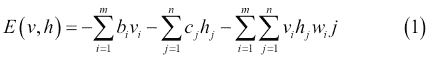
在前面的等式中,i = 1 ... m,j = 1 ... n,bi和cj分别是可见和隐藏单元的偏差,并且w[ij]是v[i]和h[j]之间的权重。模型分配给可见向量v的概率由下式给出:
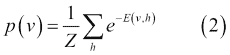
在第二个等式中,Z是分区函数,定义如下:
![]()
权重的学习可以通过以下等式获得:
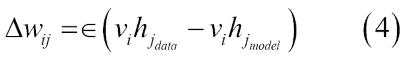
在等式 4 中,学习率由eps定义。通常,较小的eps值可确保训练更加密集。但是,如果您希望网络快速学习,可以将此值设置得更高。
由于同一层中的单元之间没有连接,因此很容易计算第一项。p(h | v)和p(v | h)的条件分布是阶乘的,并且由以下等式中的逻辑函数给出:

因此,样本v[i] h[j]是无偏的。然而,计算第二项的对数似然的计算成本是指数级的。虽然有可能得到第二项的无偏样本,但使用马尔可夫链蒙特卡罗(MCMC)的吉布斯采样,这个过程也不具有成本效益。相反,RBM 使用称为对比发散的有效近似方法。
通常,MCMC 需要许多采样步骤才能达到静止的收敛。运行吉布斯采样几步(通常是一步)足以训练一个模型,这称为对比分歧学习。对比分歧的第一步是用训练向量初始化可见单元。
下一步是使用等式 5 计算所有隐藏单元,同时使用可见单元,然后使用等式 4 从隐藏单元重建可见单元。最后,隐藏单元用重建的可见单元更新。因此,代替方程式 4,我们最终得到以下的权重学习模型:
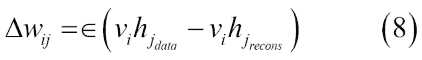
简而言之,该过程试图减少输入数据和重建数据之间的重建误差。算法收敛需要多次参数更新迭代。迭代称为周期。输入数据被分成小批量,并且在每个小批量之后更新参数,具有参数的平均值。
最后,如前所述,RBM 最大化可见单元p(v)的概率,其由模式和整体训练数据定义。它相当于最小化模型分布和经验数据分布之间的 KL 散度。
对比分歧只是这个目标函数的粗略近似,但它在实践中非常有效。虽然方便,但重建误差实际上是衡量学习进度的一个非常差的指标。考虑到这些方面,RBM 需要一些时间来收敛,但是如果你看到重建是不错的,那么你的算法效果很好。
构建一个简单的 DBN
单个隐藏层 RBM 无法从输入数据中提取所有特征,因为它无法对变量之间的关系进行建模。因此,一层接一个地使用多层 RBM 来提取非线性特征。在 DBN 中,首先使用输入数据训练 RBM,并且隐藏层以贪婪学习方法表示学习的特征。
第一 RBM 的这些学习特征用作第二 RBM 的输入,作为 DBN 中的另一层,如图 15 所示。类似地,第二层的学习特征用作另一层的输入。
这样,DBN 可以从输入数据中提取深度和非线性特征。最后一个 RBM 的隐藏层代表整个网络的学习特征。前面针对所有 RBM 层描述的学习特征的过程称为预训练。
无监督的预训练
假设您要处理复杂任务,您没有多少标记的训练数据。很难找到合适的 DNN 实现或架构来进行训练并用于预测分析。然而,如果您有大量未标记的训练数据,您可以尝试逐层训练层,从最低层开始,然后使用无监督的特征检测器算法向上移动。这就是 RBM(图 15)或自编码器(图 16)的工作原理。
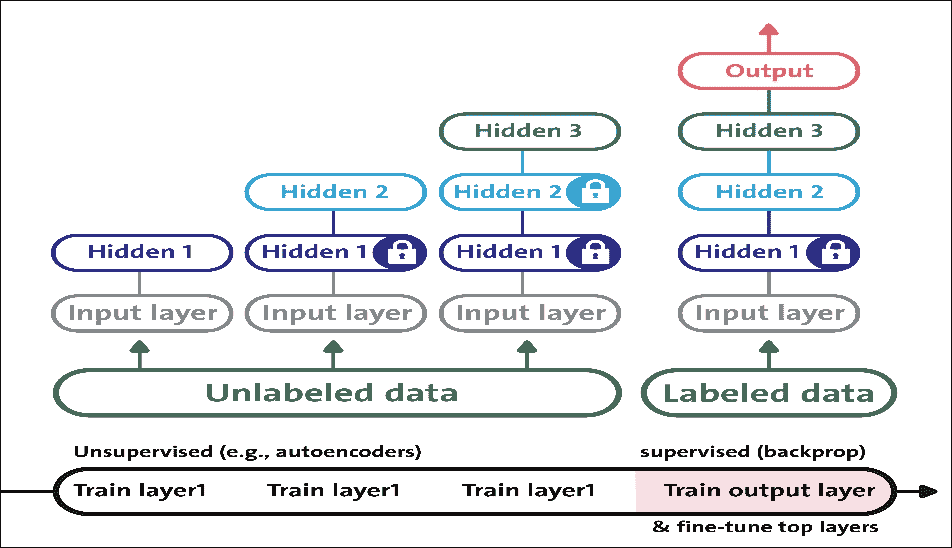
图 15:使用自编码器在 DBN 中进行无监督的预训练
当您有一个复杂的任务需要解决时,无监督的预训练仍然是一个不错的选择,没有类似的模型可以重复使用,并且标记很少的训练数据,但是大量未标记的训练数据。目前的趋势是使用自编码器而不是 RBM;但是,对于下一节中的示例,RBM 将用于简化。读者也可以尝试使用自编码器而不是 RBM。
预训练是一种无监督的学习过程。在预训练之后,通过在最后一个 RBM 层的顶部添加标记层来执行网络的微调。此步骤是受监督的学习过程。无监督的预训练步骤尝试查找网络权重:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mfg130wX-1681565849700)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_03_16.jpg)]
图 16:通过构建具有 RBM 栈的简单 DBN 在 DBN 中进行无监督预训练
监督的微调
在监督学习阶段(也称为监督微调)中,不是随机初始化网络权重,而是使用在预训练步骤中计算的权重来初始化它们。这样,当使用监督梯度下降时,DBN 可以避免收敛到局部最小值。
如前所述,使用 RBM 栈,DBN 可以构造如下:
- 使用参数
W[1]训练底部 RBM(第一个 RBM) - 将第二层权重初始化为
W[2] = W[1]^T,这可确保 DBN 至少与我们的基础 RBM 一样好
因此,将这些步骤放在一起,图 17 显示了由三个 RBM 组成的简单 DBN 的构造:
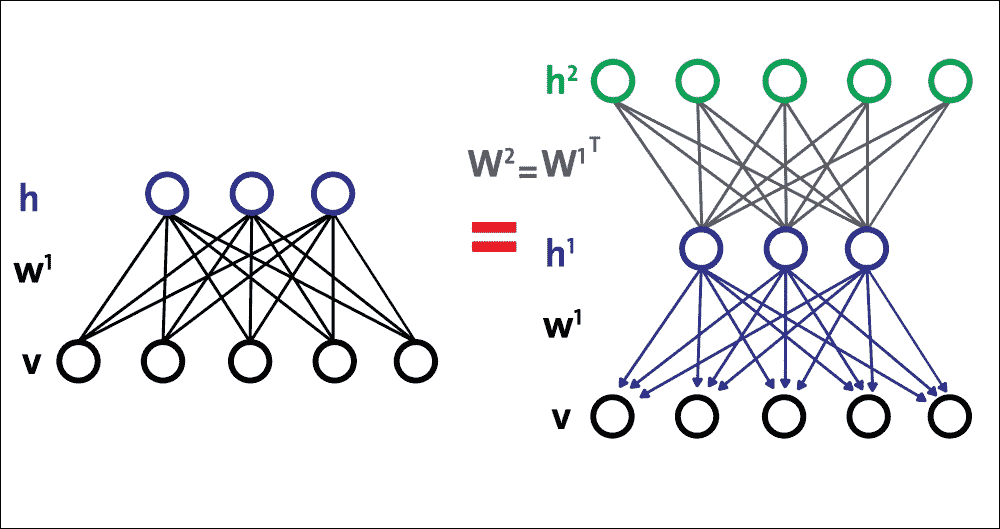
图 17:使用多个 RBM 构建简单的 DBN
现在,当调整 DBN 以获得更好的预测准确率时,我们应该调整几个超参数,以便 DBN 通过解开和改进W[2]来拟合训练数据。综上所述,我们有了创建基于 DBN 的分类器或回归器的概念工作流程。
现在我们已经有足够的理论背景来介绍如何使用几个 RBM 构建 DBN,现在是时候将我们的理论应用于实践中了。在下一节中,我们将了解如何开发用于预测分析的监督 DBN 分类器。
用于客户订阅评估的 TensorFlow 中的 DBN 实现
在银行营销数据集的前一个示例中,我们使用 MLP 观察到大约 89% 的分类准确率。我们还将原始数据集标准化,然后将其提供给 MLP。在本节中,我们将了解如何为基于 DBN 的预测模型使用相同的数据集。
我们将使用 Md.Rezaul Karim 最近出版的书籍 Predictive Analytics with TensorFlow 的 DBN 实现,可以从 GitHub 下载。
前面提到的实现是基于 RBM 的简单,干净,快速的 DBN 实现,并且基于 NumPy 和 TensorFlow 库,以便利用 GPU 计算。该库基于以下两篇研究论文实现:
- Geoffrey E. Hinton,Simon Osindero 和 Yee-Whye Teh 的深度信念网快速学习算法。 Neural Computation 18.7(2006):1527-1554。
- 训练受限制的玻尔兹曼机:简介,Asja Fischer 和 Christian Igel。模式识别 47.1(2014):25-39。
我们将看到如何以无监督的方式训练 RBM,然后我们将以有监督的方式训练网络。简而言之,有几个步骤需要遵循。主分类器是classification_demo.py。
提示
虽然在以监督和无监督的方式训练 DBN 时数据集不是那么大或高维度,但是在训练时间中会有如此多的计算,这需要巨大的资源。然而,RBM 需要大量时间来收敛。因此,我建议读者在 GPU 上进行训练,至少拥有 32 GB 的 RAM 和一个 Corei7 处理器。
我们将从加载所需的模块和库开始:
import numpy as np
import pandas as pd
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics.classification import accuracy_score
from sklearn.metrics import precision_recall_fscore_support
from sklearn.metrics import confusion_matrix
import itertools
from tf_models import SupervisedDBNClassification
import matplotlib.pyplot as plt
然后,我们加载前一个 MLP 示例中使用的已经正则化的数据集:
FILE_PATH = '../input/bank_normalized.csv'
raw_data = pd.read_csv(FILE_PATH)
在前面的代码中,我们使用了 pandas read_csv()方法并创建了一个DataFrame。现在,下一个任务是按如下方式扩展特征和标签:
Y_LABEL = 'y'
KEYS = [i for i in raw_data.keys().tolist() if i != Y_LABEL]
X = raw_data[KEYS].get_values()
Y = raw_data[Y_LABEL].get_values()
class_names = list(raw_data.columns.values)
print(class_names)
在前面的行中,我们已经分离了特征和标签。这些特征存储在X中,标签位于Y中。接下来的任务是将它们分成训练(75%)和测试集(25%),如下所示:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=100)
现在我们已经有了训练和测试集,我们可以直接进入 DBN 训练步骤。但是,首先我们需要实例化 DBN。我们将以受监督的方式进行分类,但我们需要为此 DNN 架构提供超参数:
classifier = SupervisedDBNClassification(hidden_layers_structure=[64, 64],learning_rate_rbm=0.05,learning_rate=0.01,n_epochs_rbm=10,n_iter_backprop=100,batch_size=32,activation_function='relu',dropout_p=0.2)
在前面的代码段中,n_epochs_rbm是预训练(无监督)和n_iter_backprop用于监督微调的周期数。尽管如此,我们已经为这两个阶段定义了两个单独的学习率,分别使用learning_rate_rbm和learning_rate。
不过,我们将在本节后面描述SupervisedDBNClassification的这个类实现。
该库具有支持 sigmoid,ReLU 和 tanh 激活函数的实现。此外,它利用 l2 正则化来避免过拟合。我们将按如下方式进行实际拟合:
classifier.fit(X_train, Y_train)
如果一切顺利,你应该在控制台上观察到以下进展:
[START] Pre-training step:
>> Epoch 1 finished RBM Reconstruction error 1.681226
….
>> Epoch 3 finished RBM Reconstruction error 4.926415
>> Epoch 5 finished RBM Reconstruction error 7.185334
…
>> Epoch 7 finished RBM Reconstruction error 37.734962
>> Epoch 8 finished RBM Reconstruction error 467.182892
….
>> Epoch 10 finished RBM Reconstruction error 938.583801
[END] Pre-training step
[START] Fine tuning step:
>> Epoch 0 finished ANN training loss 0.316619
>> Epoch 1 finished ANN training loss 0.311203
>> Epoch 2 finished ANN training loss 0.308707
….
>> Epoch 98 finished ANN training loss 0.288299
>> Epoch 99 finished ANN training loss 0.288900
由于 RBM 的权重是随机初始化的,因此重建和原始输入之间的差异通常很大。
从技术上讲,我们可以将重建误差视为重建值与输入值之间的差异。然后,在迭代学习过程中,将该误差反向传播 RBM 的权重几次,直到达到最小误差。
然而,在我们的情况下,重建达到 938,这不是那么大(即,不是无限),所以我们仍然可以期望良好的准确率。无论如何,经过 100 次迭代后,显示每个周期训练光泽的微调图如下:
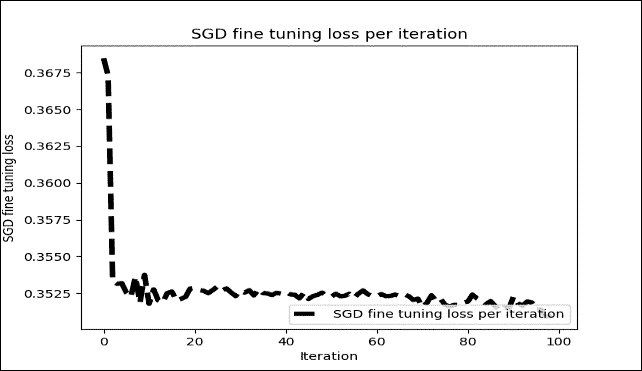
图 18:每次迭代的 SGD 微调损失(仅 100 次迭代)
然而,当我重复前面的训练并微调 1000 个周期时,我没有看到训练损失有任何显着改善:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zHpigbKd-1681565849700)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_03_19.jpg)]
图 19:每次迭代的 SGD 微调损失(1000 次迭代)
这是监督的 DBN 分类器的实现。此类为分类问题实现 DBN。它将网络输出转换为原始标签。在对标签映射执行索引之后,它还需要网络参数并返回列表。
然后,该类预测给定数据中每个样本的类的概率分布,并返回字典列表(每个样本一个)。最后,它附加了 softmax 线性分类器作为输出层:
class SupervisedDBNClassification(TensorFlowAbstractSupervisedDBN, ClassifierMixin):
def _build_model(self, weights=None):
super(SupervisedDBNClassification, self)._build_model(weights)
self.output = tf.nn.softmax(self.y)
self.cost_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=self.y, labels=self.y_))
self.train_step = self.optimizer.minimize(self.cost_function)
@classmethod
def _get_param_names(cls):
return super(SupervisedDBNClassification, cls)._get_param_names() + ['label_to_idx_map', 'idx_to_label_map']
@classmethod
def from_dict(cls, dct_to_load):
label_to_idx_map = dct_to_load.pop('label_to_idx_map')
idx_to_label_map = dct_to_load.pop('idx_to_label_map')
instance = super(SupervisedDBNClassification, cls).from_dict(dct_to_load)
setattr(instance, 'label_to_idx_map', label_to_idx_map)
setattr(instance, 'idx_to_label_map', idx_to_label_map)
return instance
def _transform_labels_to_network_format(self, labels):
"""
Converts network output to original labels.
:param indexes: array-like, shape = (n_samples, )
:return:
"""
new_labels, label_to_idx_map, idx_to_label_map = to_categorical(labels, self.num_classes)
self.label_to_idx_map = label_to_idx_map
self.idx_to_label_map = idx_to_label_map
return new_labels
def _transform_network_format_to_labels(self, indexes):
return list(map(lambda idx: self.idx_to_label_map[idx], indexes))
def predict(self, X):
probs = self.predict_proba(X)
indexes = np.argmax(probs, axis=1)
return self._transform_network_format_to_labels(indexes)
def predict_proba(self, X):
"""
Predicts probability distribution of classes for each sample in the given data.
:param X: array-like, shape = (n_samples, n_features)
:return:
"""
return super(SupervisedDBNClassification, self)._compute_output_units_matrix(X)
def predict_proba_dict(self, X):
"""
Predicts probability distribution of classes for each sample in the given data.
Returns a list of dictionaries, one per sample. Each dict contains {label_1: prob_1, ..., label_j: prob_j}
:param X: array-like, shape = (n_samples, n_features)
:return:
"""
if len(X.shape) == 1: # It is a single sample
X = np.expand_dims(X, 0)
predicted_probs = self.predict_proba(X)
result = []
num_of_data, num_of_labels = predicted_probs.shape
for i in range(num_of_data):
# key : label
# value : predicted probability
dict_prob = {}
for j in range(num_of_labels):
dict_prob[self.idx_to_label_map[j]] = predicted_probs[i][j]
result.append(dict_prob)
return result
def _determine_num_output_neurons(self, labels):
return len(np.unique(labels))
正如我们在前面的例子和运行部分中提到的那样,微调神经网络的参数是一个棘手的过程。有很多不同的方法,但我的知识并没有一刀切的方法。然而,通过前面的组合,我收到了更好的分类结果。另一个要选择的重要参数是学习率。根据您的模型调整学习率是一种可以采取的方法,以减少训练时间,同时避免局部最小化。在这里,我想讨论一些能够帮助我提高预测准确率的技巧,不仅适用于此应用,也适用于其他应用。
现在我们已经建立了模型,现在是评估其表现的时候了。为了评估分类准确率,我们将使用几个表现指标,如precision,recall和f1 score。此外,我们将绘制混淆矩阵,以观察与真实标签相对应的预测标签。首先,让我们计算预测精度如下:
Y_pred = classifier.predict(X_test)
print('Accuracy: %f' % accuracy_score(Y_test, Y_pred))
接下来,我们需要计算分类的precision,recall和f1 score:
p, r, f, s = precision_recall_fscore_support(Y_test, Y_pred, average='weighted')
print('Precision:', p)
print('Recall:', r)
print('F1-score:', f)
以下是上述代码的输出:
>>>
Accuracy: 0.900554
Precision: 0.8824140209830381
Recall: 0.9005535592891133
F1-score: 0.8767190584424599
太棒了!使用我们的 DBN 实现,我们解决了与使用 MLP 相同的分类问题。尽管如此,与 MLP 相比,我们设法获得了稍微更好的准确率。
现在,如果要解决回归问题,要预测的标签是连续的,则必须使用SupervisedDBNRegression()函数进行此实现。 DBN 文件夹中的回归脚本(即regression_demo.py)也可用于执行回归操作。
但是,使用专门为回归 y 准备的另一个数据集将是更好的主意。您需要做的就是准备数据集,以便基于 TensorFlow 的 DBN 可以使用它。因此,为了最小化演示,我使用房价:高级回归技术数据集来预测房价。
调整超参数和高级 FFNN
神经网络的灵活性也是它们的主要缺点之一:有很多超参数可以调整。即使在简单的 MLP 中,您也可以更改层数,每层神经元的数量以及每层中使用的激活函数的类型。您还可以更改权重初始化逻辑,退出保持概率等。
另外,FFNN 中的一些常见问题,例如梯度消失问题,以及选择最合适的激活函数,学习率和优化器,是最重要的。
调整 FFNN 超参数
超参数是不在估计器中直接学习的参数。有可能并建议您在超参数空间中搜索最佳交叉验证得分。在构造估计器时提供的任何参数可以以这种方式优化。现在,问题是:您如何知道超参数的哪种组合最适合您的任务?当然,您可以使用网格搜索和交叉验证来为线性机器学习模型找到正确的超参数。
但是,对于 DNN,有许多超参数可供调整。由于在大型数据集上训练神经网络需要花费大量时间,因此您只能在合理的时间内探索超参数空间的一小部分。以下是一些可以遵循的见解。
此外,当然,正如我所说,您可以使用网格搜索或随机搜索,通过交叉验证,为线性机器学习模型找到正确的超参数。我们将在本节后面看到一些可能的详尽和随机网格搜索和交叉验证方法。
隐藏层数
对于许多问题,你可以从一个或两个隐藏层开始,这个设置可以很好地使用两个隐藏层,具有相同的神经元总数(见下文以了解一些神经元),训练时间大致相同。现在让我们看一些关于设置隐藏层数的朴素估计:
- 0:仅能表示线性可分离函数或决策
- 1:可以近似包含从一个有限空间到另一个有限空间的连续映射的任何函数
- 2:可以用任意精度表示任意决策边界,具有合理的激活函数,并且可以近似任何平滑映射到任何精度
但是,对于更复杂的问题,您可以逐渐增加隐藏层的数量,直到您开始过拟合训练集。非常复杂的任务,例如大图像分类或语音识别,通常需要具有数十层的网络,并且它们需要大量的训练数据。
不过,您可以尝试逐渐增加神经元的数量,直到网络开始过拟合。这意味着不会导致过拟合的隐藏神经元数量的上限是:
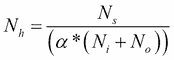
在上面的等式中:
N[i]为输入神经元的数量
N[o]为输出神经元的数量
N[s]为训练数据集中的样本数
α为任意比例因子,通常为 2-10。
请注意,上述等式不是来自任何研究,而是来自我的个人工作经验。但是,对于自动程序,您将以 2 的α值开始,即训练数据的自由度是模型的两倍,如果训练数据的误差明显小于 10,则可以达到 10。用于交叉验证数据集。
每个隐藏层的神经元数量
显然,输入和输出层中神经元的数量取决于您的任务所需的输入和输出类型。例如,如果您的数据集的形状为28x28,则它应该具有大小为 784 的输入神经元,并且输出神经元应该等于要预测的类的数量。
我们将在下一个例子中看到它如何在实践中工作,使用 MLP,其中将有四个具有 256 个神经元的隐藏层(只有一个超参数可以调整,而不是每层一个)。就像层数一样,您可以尝试逐渐增加神经元的数量,直到网络开始过拟合。
有一些经验导出的经验法则,其中最常用的是:“隐藏层的最佳大小通常在输入的大小和输出层的大小之间。”
总之,对于大多数问题,通过仅使用两个规则设置隐藏层配置,您可能可以获得不错的表现(即使没有第二个优化步骤):
- 隐藏层的数量等于一
- 该层中的神经元数量是输入和输出层中神经元的平均值
然而,就像层数一样,你可以尝试逐渐增加神经元的数量,直到网络开始过拟合。
权重和偏置初始化
正如我们将在下一个示例中看到的那样,初始化权重和偏置,隐藏层是一个重要的超参数,需要注意:
- 不要做所有零初始化:一个听起来合理的想法可能是将所有初始权重设置为零,但它在实践中不起作用。这是因为如果网络中的每个神经元计算相同的输出,如果它们的权重被初始化为相同,则神经元之间将不存在不对称的来源。
- 小随机数:也可以将神经元的权重初始化为小数,但不能相同为零。或者,可以使用从均匀分布中抽取的小数字。
- 初始化偏差:通常将偏差初始化为零,因为权重中的小随机数提供不对称性破坏。将偏差设置为一个小的常量值,例如所有偏差的 0.01,确保所有 ReLU 单元都可以传播一些梯度。但是,它既没有表现良好,也没有表现出持续改进因此,建议坚持使用零。
选择最合适的优化器
因为在 FFNN 中, 目标函数之一是最小化评估成本,我们必须定义一个优化器。我们已经看到了如何使用tf.train.AdamOptimizer。Tensorflow tf.train提供了一组有助于训练模型的类和函数。就个人而言,我发现 Adam 优化器在实践中对我很有效,而不必考虑学习率等等。
对于大多数情况,我们可以利用 Adam,但有时我们可以采用实现的RMSPropOptimizer函数,这是梯度下降的高级形式。RMSPropOptimizer函数实现RMSProp算法。
RMSPropOptimizer函数还将学习率除以指数衰减的平方梯度平均值。衰减参数的建议设置值为0.9,而学习率的良好默认值为0.001:
optimizer = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost_op)
使用最常见的优化器 SGD,学习率必须随1/T缩放才能获得收敛,其中T是迭代次数。RMSProp尝试通过调整步长来自动克服此限制,以使步长与梯度的比例相同。
因此,如果您正在训练神经网络,但计算梯度是必需的,使用tf.train.RMSPropOptimizer()将是在小批量设置中学习的更快方式。研究人员还建议在训练 CNN 等深层网络时使用动量优化器。
最后,如果您想通过设置这些优化器来玩游戏,您只需要更改一行。由于时间限制,我没有尝试过所有这些。然而,根据 Sebastian Ruder 最近的一篇研究论文(见此链接),自适应学习率方法的优化者,Adagrad,Adadelta,RMSprop和Adam是最合适的,并为这些情况提供最佳收敛。
网格搜索和随机搜索的超参数调整
采样搜索的两种通用候选方法在其他基于 Python 的机器学习库(如 Scikit-learn)中提供。对于给定值,GridSearchCV详尽考虑所有参数组合,而RandomizedSearchCV可以从具有指定分布的参数空间中对给定数量的候选进行采样。
GridSearchCV是自动测试和优化超参数的好方法。我经常在 Scikit-learn 中使用它。然而,TensorFlowEstimator优化learning_rate,batch_size等等还不是那么简单。而且,正如我所说,我们经常调整这么多超参数以获得最佳结果。不过,我发现这篇文章对于学习如何调整上述超参数非常有用。
随机搜索和网格搜索探索完全相同的参数空间。参数设置的结果非常相似,而随机搜索的运行时间则大大降低。
一些基准测试(例如此链接)已经报告了随机搜索的表现略差,尽管这很可能是一种噪音效应并且不会延续到坚持不懈的测试集。
正则化
有几种方法可以控制 DNN 的训练,以防止在训练阶段过拟合,例如,L2/L1 正则化,最大范数约束和退出:
- L2 正则化:这可能是最常见的正则化形式。使用梯度下降参数更新,L2 正则化表示每个权重将线性地向零衰减。
- L1 正则化:对于每个权重 w,我们将项
λ|w|添加到目标。然而, 也可以组合 L1 和 L2 正则化以实现弹性网络正则化。 - 最大范数约束:这强制了每个隐藏层神经元的权重向量的大小的绝对上限。可以进一步使用投影的梯度下降来强制约束。
消失梯度问题出现在非常深的神经网络(通常是 RNN,它将有一个专门的章节),它使用激活函数,其梯度往往很小(在 0 到 1 的范围内)。
由于这些小梯度在反向传播期间进一步增加,因此它们倾向于在整个层中“消失”,从而阻止网络学习远程依赖性。解决这个问题的常用方法是使用激活函数,如线性单元(又名 ReLU),它不会受到小梯度的影响。我们将看到一种改进的 RNN 变体,称为长短期记忆 (又名 LSTM),它可以解决这个问题。我们将在第 5 章,优化 TensorFlow 自编码器中看到关于该主题的更详细讨论。
尽管如此,我们已经看到最后的架构更改提高了模型的准确率,但我们可以通过使用 ReLU 更改 sigmoid 激活函数来做得更好,如下所示:
图 20:ReLU 函数
ReLU 单元计算函数f(x) = max(0, x)。 ReLU 计算速度快,因为它不需要任何指数计算,例如 sigmoid 或 tanh 激活所需的计算。此外,与 sigmoid/tanh 函数相比,发现它大大加速了随机梯度下降的收敛。要使用 ReLU 函数,我们只需在先前实现的模型中更改前四个层的以下定义:
第一层输出:
Y1 = tf.nn.relu(tf.matmul(XX, W1) + B1) # Output from layer 1
第二层输出:
Y2 = tf.nn.relu(tf.matmul(Y1, W2) + B2) # Output from layer 2
第三层输出:
Y3 = tf.nn.relu(tf.matmul(Y2, W3) + B3) # Output from layer 3
第四层输出:
Y4 = tf.nn.relu(tf.matmul(Y3, W4) + B4) # Output from layer 4
输出层:
Ylogits = tf.matmul(Y4, W5) + B5 # computing the logits
Y = tf.nn.softmax(Ylogits) # output from layer 5
当然,tf.nn.relu是 TensorFlow 的 ReLU 实现。模型的准确率几乎达到 98%,您可以看到运行网络:
>>>
Loading data/train-images-idx3-ubyte.mnist
Loading data/train-labels-idx1-ubyte.mnist Loading data/t10k-images-idx3-ubyte.mnist
Loading data/t10k-labels-idx1-ubyte.mnist
Epoch: 0
Epoch: 1
Epoch: 2
Epoch:
3
Epoch: 4
Epoch: 5
Epoch: 6
Epoch: 7
Epoch: 8
Epoch: 9
Accuracy:0.9789
done
>>>
关注 TensorBoard 分析,从源文件执行的文件夹中,您应该数字:
$> Tensorboard --logdir = 'log_relu' # Don't put space before or after '='
然后在localhost上打开浏览器以显示 TensorBoard 的起始页面。在下图中,我们显示了趋势对训练集示例数量的准确率:
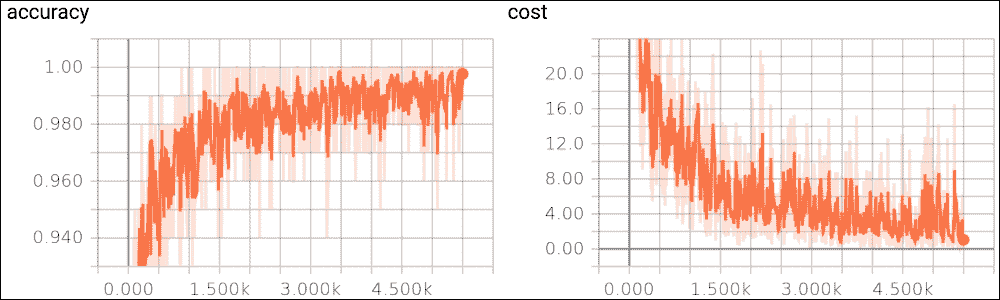
图 21:训练集上的准确率函数
在大约 1000 个示例之后,您可以很容易地看到在不良的初始趋势之后,准确率如何开始快速渐进式改进。
丢弃优化
在使用 DNN 时,我们需要另一个占位符用于丢弃,这是一个需要调整的超参数。它仅通过以某种概率保持神经元活动(比如p > 1.0)或者将其设置为零来实现。这个想法是在测试时使用单个神经网络而不会丢弃。该网络的权重是训练权重的缩小版本。如果在训练期间使用dropout_keep_prob < 1.0保留单元,则在测试时将该单元的输出权重乘以p。
在学习阶段,与下一层的连接可以限于神经元的子集,以减少要更新的权重。这种学习优化技术称为丢弃。因此,丢弃是一种用于减少具有许多层和/或神经元的网络中的过拟合的技术。通常,丢弃层位于具有大量可训练神经元的层之后。
该技术允许将前一层的一定百分比的神经元设置为 0,然后排除激活。神经元激活被设置为 0 的概率由层内的丢弃率参数通过 0 和 1 之间的数字表示。实际上,神经元的激活保持等于丢弃率的概率;否则,它被丢弃,即设置为 0。

图 22:丢弃表示
通过这种方式,对于每个输入,网络拥有与前一个略有不同的架构。即使这些架构具有相同的权重,一些连接也是有效的,有些连接不是每次都以不同的方式。上图显示了丢弃的工作原理:每个隐藏单元都是从网络中随机省略的,概率为p。
但需要注意的是,每个训练实例的选定丢弃单元不同;这就是为什么这更像是一个训练问题。丢弃可以被视为在大量不同的神经网络中执行模型平均的有效方式,其中可以以比架构问题低得多的计算成本来避免过拟合。丢弃降低了神经元依赖于其他神经元存在的可能性。通过这种方式,它被迫更多地了解强大的特征,并且它们与其他不同神经元的联系非常有用。
允许构建丢弃层的 TensorFlow 函数是tf.nn.dropout。此函数的输入是前一层的输出,并且丢弃参数tf.nn.dropout返回与输入张量相同大小的输出张量。该模型的实现遵循与五层网络相同的规则。在这种情况下,我们必须在一层和另一层之间插入丢弃函数:
pkeep = tf.placeholder(tf.float32)
Y1 = tf.nn.relu(tf.matmul(XX, W1) + B1) # Output from layer 1
Y1d = tf.nn.dropout(Y1, pkeep)
Y2 = tf.nn.relu(tf.matmul(Y1, W2) + B2) # Output from layer 2
Y2d = tf.nn.dropout(Y2, pkeep)
Y3 = tf.nn.relu(tf.matmul(Y2, W3) + B3) # Output from layer 3
Y3d = tf.nn.dropout(Y3, pkeep)
Y4 = tf.nn.relu(tf.matmul(Y3, W4) + B4) # Output from layer 4
Y4d = tf.nn.dropout(Y4, pkeep)
Ylogits = tf.matmul(Y4d, W5) + B5 # computing the logits
Y = tf.nn.softmax(Ylogits) # output from layer 5
退出优化产生以下结果:
>>>
Loading data/train-images-idx3-ubyte.mnist Loading data/train-labels-idx1-ubyte.mnist Loading data/t10k-images-idx3-ubyte.mnist Loading data/t10k-labels-idx1-ubyte.mnist Epoch: 0
Epoch: 1
Epoch: 2
Epoch: 3
Epoch: 4
Epoch: 5
Epoch: 6
Epoch:
7
Epoch: 8
Epoch: 9
Accuracy: 0.9666 done
>>>
尽管有这种实现, 之前的 ReLU 网络仍然更好,但您可以尝试更改网络参数以提高模型的准确率。此外,由于这是一个很小的网络,我们处理的是小规模的数据集,当您处理具有更复杂网络的大规模高维数据集时,您会发现丢弃可能非常重要。我们将在下一章中看到一些动手实例。
现在,要了解丢弃优化的效果,让我们开始 TensorBoard 分析。只需键入以下内容:
$> Tensorboard --logdir=' log_softmax_relu_dropout/'
下图显示了作为训练示例函数的精度成本函数:
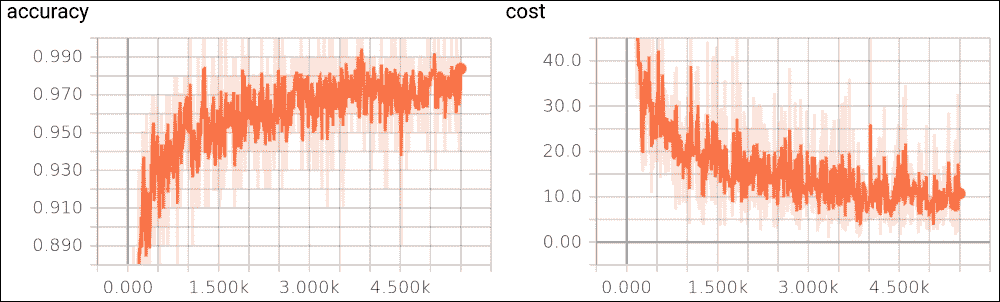
图 23:a)丢弃优化的准确率,b)训练集的成本函数
在上图中,我们显示成本函数作为训练样例的函数。这两种趋势都是我们所期望的:随着训练样例的增加,准确率会提高,而成本函数会随着迭代次数的增加而减
总结
我们已经了解了如何实现 FFNN 架构,其特征在于一组输入单元,一组输出单元以及一个或多个连接该输出的输入级别的隐藏单元。我们已经看到如何组织网络层,以便级别之间的连接是完全的并且在单个方向上:每个单元从前一层的所有单元接收信号并发送其输出值,适当地权衡到所有单元的下一层。
我们还看到了如何为每个层定义激活函数(例如,sigmoid,ReLU,tanh 和 softmax),其中激活函数的选择取决于架构和要解决的问题。
然后,我们实现了四种不同的 FFNN 模型。第一个模型有一个隐藏层,具有 softmax 激活函数。其他三个更复杂的模型总共有五个隐藏层,但具有不同的激活函数。我们还看到了如何使用 TensorFlow 实现深度 MLP 和 DBN,以解决分类任务。使用这些实现,我们设法达到了 90% 以上的准确率。最后,我们讨论了如何调整 DNN 的超参数以获得更好和更优化的表现。
虽然常规的 FFNN(例如 MLP)适用于小图像(例如,MNIST 或 CIFAR-10),但由于需要大量参数,它会因较大的图像而分解。例如,100×100 图像具有 10,000 个像素,并且如果第一层仅具有 1,000 个神经元(其已经严格限制传输到下一层的信息量),则这意味着 1000 万个连接。另外,这仅适用于第一层。
重要的是,DNN 不知道像素的组织方式,因此不知道附近的像素是否接近。 CNN 的架构嵌入了这种先验知识。较低层通常识别图像的单元域中的特征,而较高层将较低层特征组合成较大特征。这适用于大多数自然图像,与 DNN 相比,CNN 具有决定性的先机性。
在下一章中,我们将进一步探讨神经网络模型的复杂性,引入 CNN,这可能对深度学习技术产生重大影响。我们将研究主要功能并查看一些实现示例。
四、CNN 实战
以前面提到的5×5输入矩阵为例,CNN 的输入层由 25 个神经元(5×5)组成,其任务是获取与每个像素对应的输入值并将其转移到下一层。
在多层网络中,输入层中所有神经元的输出将连接到隐藏层(完全连接层)中的每个神经元。然而,在 CNN 网络中,上面定义的连接方案和我们要描述的卷积层是显着不同的。正如您可能猜到的,这是层的主要类型:在 CNN 中使用这些层中的一个或多个是必不可少的。
在卷积层中,每个神经元连接到输入区域的某个区域,称为感受野。例如,使用3×3内核滤波器,每个神经元将具有偏置并且 9 个权重(3×3)连接到单个感受野。为了有效地识别图像,我们需要将各种不同的内核过滤器应用于相同的感受野,因为每个过滤器应该识别来自图像的不同特征。识别相同特征的神经元集定义了单个特征映射。
下图显示了运行中的 CNN 架构:28×28输入图像将由一个由28x28x32特征映射组成的卷积层进行分析。该图还显示了一个感受野和一个3×3内核过滤器:
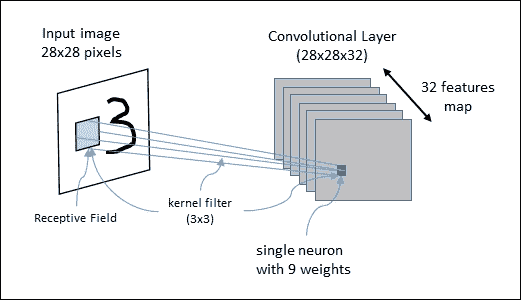
图 5:CNN 正在运行中
CNN 可以由级联连接的若干卷积层组成。每个卷积层的输出是一组特征映射(每个都由单个内核过滤器生成)。这些矩阵中的每一个都定义了将由下一层使用的新输入。
通常,在 CNN 中,每个神经元产生高达激活阈值的输出,该激活阈值与输入成比例并且不受限制。
CNN 还使用位于卷积层之后的池化层。池化层将卷积区域划分为子区域。然后,池化层选择单个代表值(最大池化或平均池化)以减少后续层的计算时间并增加特征相对于其空间位置的稳健性。卷积网络的最后一层通常是完全连接的网络,具有用于输出层的 softmax 激活函数。在接下来的几节中,将详细分析最重要的 CNN 的架构。
LeNet5
LeNet5 CNN 架构由 Yann LeCun 于 1998 年发明,是第一个 CNN。它是一个多层前馈网络,专门用于对手写数字进行分类。它被用于 LeCun 的实验,由七层组成,包含可训练的权重。 LeNet5 架构如下所示:
图 6:LeNet5 网络
LeNet5 架构由三个卷积层和两个交替序列池化层组成。最后两层对应于传统的完全连接的神经网络,即完全连接的层,后面是输出层。输出层的主要功能是计算输入向量和参数向量之间的欧几里德距离。输出函数识别输入模式和我们模型的测量值之间的差异。输出保持最小,以实现最佳模型。因此,完全连接的层被配置为使得输入模式和我们的模型的测量之间的差异最小化。虽然它在 MNIST 数据集上表现良好,但是在具有更高分辨率和更多类别的更多图像的数据集上表现下降。
注意
有关 LeNet 系列模型的基本参考,请参见此链接。
逐步实现 LeNet-5
在本节中,我们将学习如何构建 LeNet-5 架构来对 MNIST 数据集中的图像进行分类。下图显示了数据如何在前两个卷积层中流动:使用滤波器权重在第一个卷积层中处理输入图像。这导致 32 个新图像,一个用于卷积层中的每个滤波器。图像也通过合并操作进行下采样,因此图像分辨率从28×28降低到14×14。然后在第二卷积层中处理这 32 个较小的图像。我们需要为这 32 个图像中的每一个再次使用滤波器权重,并且我们需要该层的每个输出通道的滤波器权重。通过合并操作再次对图像进行下采样,使得图像分辨率从14×14减小到7×7。此卷积层的特征总数为 64。
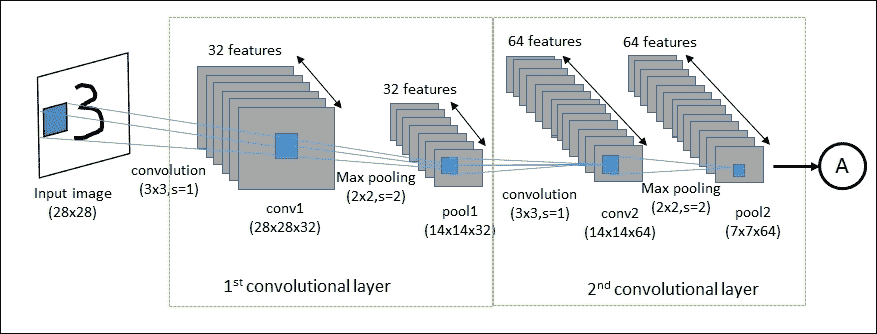
图 7:前两个卷积层的数据流
通过(3×3)第三卷积层再次过滤 64 个结果图像。没有对该层应用池操作。第三卷积层的输出是128×7×7像素图像。然后将这些图像展平为单个向量,长度为4×4×128 = 2048,其用作完全连接层的输入。
LeNet-5 的输出层由 625 个神经元作为输入(即完全连接层的输出)和 10 个神经元作为输出,用于确定图像的类别,该数字在图片。
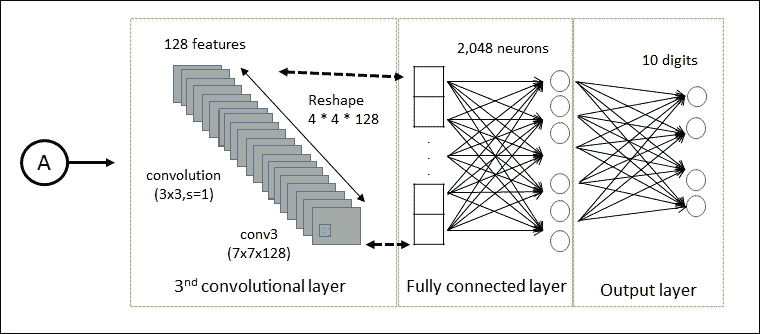
图 8:最后三个卷积层的数据流
卷积滤波器最初是随机选择的。输入图像的预测类和实际类之间的差异被称为成本函数,并且这使我们的网络超出训练数据。然后,优化器会自动通过 CNN 传播此成本函数,并更新过滤器权重以改善分类误差。这反复进行数千次,直到分类误差足够低。
现在让我们详细看看如何编写我们的第一个 CNN。让我们首先导入我们实现所需的 TensorFlow 库:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
设置以下参数。它们表示在训练阶段(128)和测试阶段(256)使用的样本数量:
batch_size = 128
test_size = 256
当我们定义以下参数时,该值为28,因为 MNIST 图像的高度和宽度为28像素:
img_size = 28
对于类的数量,值10意味着我们将为每个 0 到 9 位数设置一个类:
num_classes = 10
为输入图像定义占位符变量X。该张量的数据类型设置为float32,形状设置为[None, img_size, img_size, 1],其中None表示张量可以保存任意数量的图像:
X = tf.placeholder("float", [None, img_size, img_size, 1])
然后我们为占位符变量X中的输入图像正确关联的标签设置另一个占位符变量Y。此占位符变量的形状为[None, num_classes],这意味着它可以包含任意数量的标签。每个标签都是长度为num_classes的向量,在这种情况下为10:
Y = tf.placeholder("float", [None, num_classes])
我们收集MNIST数据,这些数据将被复制到数据文件夹中:
mnist = input_data.read_data_sets("MNIST-data", one_hot=True)
我们构建训练数据集(trX,trY)和测试网络(teX,teY):
trX, trY, teX, teY = mnist.train.images, \
mnist.train.labels, \
mnist.test.images, \
mnist.test.labels
必须重新整形trX和teX图像集以匹配输入形状:
trX = trX.reshape(-1, img_size, img_size, 1)
teX = teX.reshape(-1, img_size, img_size, 1)
我们现在开始定义网络的weights。
init_weights函数在提供的形状中构建新变量,并使用随机值初始化网络权重:
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
第一卷积层的每个神经元被卷积为输入张量的小子集,尺寸为3×3×1。值32只是我们为第一层考虑的特征图的数量。然后定义权重w:
w = init_weights([3, 3, 1, 32])
然后输入的数量增加到32,这意味着第二卷积层中的每个神经元被卷积到第一卷积层的3×3×32个神经元。w2权重如下:
w2 = init_weights([3, 3, 32, 64])
值64表示获得的输出特征的数量。第三个卷积层被卷积为前一层的3x3x64个神经元,而128是结果特征。
w3 = init_weights([3, 3, 64, 128])
第四层完全连接并接收128x4x4输入,而输出等于625:
w4 = init_weights([128 * 4 * 4, 625])
输出层接收625输入,输出是类的数量:
w_o = init_weights([625, num_classes])
请注意,这些初始化实际上并未在此时完成。它们仅在 TensorFlow 图中定义。
p_keep_conv = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
是时候定义网络模型了。就像网络的权重定义一样,它将是一个函数。它接收X张量,权重张量和丢弃参数作为卷积和完全连接层的输入:
def model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden):
tf.nn.conv2d()执行 TensorFlow 操作进行卷积。请注意,所有尺寸的strides都设置为 1。实际上,第一步和最后一步必须始终为 1,因为第一步是图像编号,最后一步是输入通道。padding参数设置为'SAME',这意味着输入图像用零填充,因此输出的大小相同:
conv1 = tf.nn.conv2d(X, w,strides=[1, 1, 1, 1],\
padding='SAME')
然后我们将conv1层传递给 ReLU 层。它为每个输入像素x计算max(x, 0)函数,为公式添加一些非线性,并允许我们学习更复杂的函数:
conv1_a = tf.nn.relu(conv1)
然后由tf.nn.max_pool运算符合并生成的层:
conv1 = tf.nn.max_pool(conv1_a, ksize=[1, 2, 2, 1]\
,strides=[1, 2, 2, 1],\
padding='SAME')
这是一个2×2最大池,这意味着我们正在检查2×2窗口并在每个窗口中选择最大值。然后我们将 2 个像素移动到下一个窗口。我们尝试通过tf.nn.dropout()函数减少过拟合,我们传递conv1层和p_keep_conv概率值:
conv1 = tf.nn.dropout(conv1, p_keep_conv)
如您所见,接下来的两个卷积层conv2和conv3的定义方式与conv1相同:
conv2 = tf.nn.conv2d(conv1, w2,\
strides=[1, 1, 1, 1],\
padding='SAME')
conv2_a = tf.nn.relu(conv2)
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1],\
strides=[1, 2, 2, 1],\
padding='SAME')
conv2 = tf.nn.dropout(conv2, p_keep_conv)
conv3=tf.nn.conv2d(conv2, w3,\
strides=[1, 1, 1, 1]\
,padding='SAME')
conv3 = tf.nn.relu(conv3)
完全连接的层将添加到网络中。第一个FC_layer的输入是前一个卷积的卷积层:
FC_layer = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1],\
strides=[1, 2, 2, 1],\
padding='SAME')
FC_layer = tf.reshape(FC_layer,\
[-1, w4.get_shape().as_list()[0]])
dropout函数再次用于减少过拟合:
FC_layer = tf.nn.dropout(FC_layer, p_keep_conv)
输出层接收FC_layer和w4权重张量作为输入。应用 ReLU 和丢弃运算符:
output_layer = tf.nn.relu(tf.matmul(FC_layer, w4))
output_layer = tf.nn.dropout(output_layer, p_keep_hidden)
结果是一个长度为 10 的向量。这用于确定图像所属的 10 个输入类中的哪一个:
result = tf.matmul(output_layer, w_o)
return result
交叉熵是我们在此分类器中使用的表现指标。交叉熵是一个连续的函数,它总是正的,如果预测的输出与期望的输出完全匹配,则等于零。因此,这种优化的目标是通过改变网络层中的变量来最小化交叉熵,使其尽可能接近零。 TensorFlow 具有用于计算交叉熵的内置函数。请注意,该函数在内部计算 softmax,因此我们必须直接使用py_x的输出:
py_x = model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden)
Y_ = tf.nn.softmax_cross_entropy_with_logits_v2\
(labels=Y,logits=py_x)
现在我们已经为每个分类图像定义了交叉熵,我们可以衡量模型在每个图像上的表现。我们需要一个标量值来使用交叉熵来优化网络变量,因此我们只需要对所有分类图像求平均交叉熵:
cost = tf.reduce_mean(Y_)
为了最小化评估的cost,我们必须定义一个优化器。在这种情况下,我们将使用RMSPropOptimizer,它是 GD 的高级形式。RMSPropOptimizer实现了 RMSProp 算法,这是一种未发表的自适应学习率方法,由 Geoff Hinton 在他的 Coursera 课程的第 6 讲中提出。
注意
您可以在此链接找到 Geoff Hinton 的课程。
RMSPropOptimizer还将学习率除以梯度平方的指数衰减均值。 Hinton 建议将衰减参数设置为0.9,而学习率的良好默认值为0.001:
optimizer = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
基本上,通用 SGD 算法存在一个问题,即学习率必须以1 / T(其中T是迭代次数)进行缩放以实现收敛。 RMSProp 尝试通过自动调整步长来解决这个问题,以使步长与梯度相同。随着平均梯度变小,SGD 更新中的系数变得更大以进行补偿。
注意
有关此算法的有趣参考可在此处找到。
最后,我们定义predict_op,它是模式输出中尺寸最大值的索引:
predict_op = tf.argmax(py_x, 1)
请注意,此时不执行优化。什么都没有计算,因为我们只是将优化器对象添加到 TensorFlow 图中以便以后执行。
我们现在来定义网络的运行会话。训练集中有 55,000 个图像,因此使用所有这些图像计算模型的梯度需要很长时间。因此,我们将在优化器的每次迭代中使用一小批图像。如果您的计算机崩溃或由于 RAM 耗尽而变得非常慢,那么您可以减少此数量,但您可能需要执行更多优化迭代。
现在我们可以继续实现 TensorFlow 会话:
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(100):
我们得到了一批训练样例,training_batch张量现在包含图像的子集和相应的标签:
training_batch = zip(range(0, len(trX), batch_size),\
range(batch_size, \
len(trX)+1, \
batch_size))
将批量放入feed_dict中,并在图中为占位符变量指定相应的名称。我们现在可以使用这批训练数据运行优化器。 TensorFlow 将馈送中的变量分配给占位符变量,然后运行优化程序:
for start, end in training_batch:
sess.run(optimizer, feed_dict={X: trX[start:end],\
Y: trY[start:end],\
p_keep_conv: 0.8,\
p_keep_hidden: 0.5})
同时,我们得到了打乱的一批测试样本:
test_indices = np.arange(len(teX))
np.random.shuffle(test_indices)
test_indices = test_indices[0:test_size]
对于每次迭代,我们显示批次的评估accuracy:
print(i, np.mean(np.argmax(teY[test_indices], axis=1) ==\
sess.run\
(predict_op,\
feed_dict={X: teX[test_indices],\
Y: teY[test_indices], \
p_keep_conv: 1.0,\
p_keep_hidden: 1.0})))
根据所使用的计算资源,训练网络可能需要几个小时。我机器上的结果如下:
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Successfully extracted to train-images-idx3-ubyte.mnist 9912422 bytes.
Loading ata/train-images-idx3-ubyte.mnist
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Successfully extracted to train-labels-idx1-ubyte.mnist 28881 bytes.
Loading ata/train-labels-idx1-ubyte.mnist
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Successfully extracted to t10k-images-idx3-ubyte.mnist 1648877 bytes.
Loading ata/t10k-images-idx3-ubyte.mnist
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Successfully extracted to t10k-labels-idx1-ubyte.mnist 4542 bytes.
Loading ata/t10k-labels-idx1-ubyte.mnist
(0, 0.95703125)
(1, 0.98046875)
(2, 0.9921875)
(3, 0.99609375)
(4, 0.99609375)
(5, 0.98828125)
(6, 0.99609375)
(7, 0.99609375)
(8, 0.98828125)
(9, 0.98046875)
(10, 0.99609375)
.
.
.
..
.
(90, 1.0)
(91, 0.9921875)
(92, 0.9921875)
(93, 0.99609375)
(94, 1.0)
(95, 0.98828125)
(96, 0.98828125)
(97, 0.99609375)
(98, 1.0)
(99, 0.99609375)
经过 10,000 次迭代后, 模型的准确率为 99.60%,这还不错!
AlexNet
AlexNet 神经网络是首批实现巨大成功的 CNN 之一。作为 2012 年 ILSVRC 的获胜者,这个神经网络是第一个使用 LeNet-5 网络之前定义的神经网络的标准结构在 ImageNet 等非常复杂的数据集上获得良好结果。
注意
ImageNet 项目是一个大型视觉数据库,设计用于视觉对象识别软件研究。截至 2016 年,ImageNet 手工标注了超过一千万个图像 URL,以指示图像中的对象。在至少一百万个图像中,还提供了边界框。第三方图像 URL 的标注数据库可直接从 ImageNet 免费获得。
AlexNet 的架构如下图所示:
图 9:AlexNet 网络
在 AlexNet 架构中,有八层具有可训练参数:一系列五个连续卷积层,后面是三个完全连接的层。每个卷积层之后是 ReLU 层,并且可选地还有最大池层,尤其是在网络的开始处,以便减少网络占用的空间量。
所有池层都有3x3扩展区域,步长率为 2:这意味着您始终使用重叠池。这是因为与没有重叠的普通池相比,这种类型的池提供了稍好的网络表现。在网络的开始,在池化层和下一个卷积层之间,总是使用几个 LRN 标准化层:经过一些测试,可以看出它们倾向于减少网络误差。
前两个完全连接的层拥有 4,096 个神经元,而最后一个拥有 1,000 个单元,对应于 ImageNet 数据集中的类数。考虑到完全连接层中的大量连接,在每对完全连接的层之间添加了比率为 0.5 的丢弃层,即,每次忽略一半的神经元激活。在这种情况下已经注意到,使用丢弃技术不仅加速了单次迭代的处理,而且还很好地防止了过拟合。没有丢弃层,网络制造商声称原始网络过拟合。
迁移学习
迁移学习包括建立已经构建的网络,并对各个层的参数进行适当的更改,以便它可以适应另一个数据集。例如,您可以在大型数据集(如 ImageNet)上使用预先测试的网络,并在较小的数据集上再次训练它。如果我们的数据集在内容上与原始数据集没有明显不同,那么预先训练的模型已经具有与我们自己的分类问题相关的学习特征。
如果我们的数据集与预训练模型训练的数据集没有太大差异,我们可以使用微调技术。 已在大型不同数据集上进行预训练的模型可能会捕捉到早期层中的曲线和边缘等通用特征,这些特征在大多数分类问题中都是相关且有用的。但是,如果我们的数据集来自一个非常特定的域,并且找不到该域中预先训练好的网络,我们应该考虑从头开始训练网络。
预训练的 AlexNet
我们会对预先训练好的 AlexNet 进行微调,以区分狗和猫。 AlexNet 在 ImageNet 数据集上经过预先训练。
要执行这个例子,你还需要安装 scipy(参见此链接)和 PIL(Pillow),这是 scipy 使用的读取图像:pip install Pillow或pip3 install Pillow。
然后,您需要下载以下文件:
myalexnet_forward.py:2017 版 TensorFlow 的 AlexNet 实现和测试代码(Python 3.5)bvlc_alexnet.npy:权重,需要在工作目录中caffe_classes.py:类,与网络输出的顺序相同poodle.png,laska.png,dog.png,dog2.png,quail227.JPEG:测试图像(图像应为227×227×3)
从此链接下载这些文件,或从本书的代码库中下载。
首先,我们将在之前下载的图像上测试网络。为此,只需从 Python GUI 运行myalexnet_forward.py即可。
通过简单地检查源代码可以看到(参见下面的代码片段),将调用预先训练好的网络对以下两个图像进行分类,laska.png和poodle.png,这些图像之前已下载过:
im1 = (imread("laska.png")[:,:,:3]).astype(float32)
im1 = im1 - mean(im1)
im1[:, :, 0], im1[:, :, 2] = im1[:, :, 2], im1[:, :, 0]
im2 = (imread("poodle.png")[:,:,:3]).astype(float32)
im2[:, :, 0], im2[:, :, 2] = im2[:, :, 2], im2[:, :, 0]

图 10:要分类的图像
的权重和偏置由以下语句加载:
net_data = load(open("bvlc_alexnet.npy", "rb"), encoding="latin1").item()
网络是一组卷积和池化层,后面是三个完全连接的状态。该模型的输出是 softmax 函数:
prob = tf.nn.softmax(fc8)
softmax 函数的输出是分类等级,因为它们表示网络认为输入图像属于caffe_classes.py文件中定义的类的强度。
如果我们运行代码,我们应该得到以下结果:
Image 0
weasel 0.503177
black-footed ferret, ferret, Mustela nigripes 0.263265
polecat, fitch, foulmart, foumart, Mustela putorius 0.147746
mink 0.0649517
otter 0.00771955
Image 1
clumber, clumber spaniel 0.258953
komondor 0.165846
miniature poodle 0.149518
toy poodle 0.0984719
kuvasz 0.0848062
0.40007972717285156
>>>
在前面的例子中,AlexNet 给鼬鼠的分数约为 50%。这意味着该模型非常有信心图像显示黄鼠狼,其余分数可视为噪音。
数据集准备
我们的任务是建立一个区分狗和猫的图像分类器。我们从 Kaggle 那里得到一些帮助,我们可以从中轻松下载数据集。
在此数据集中,训练集包含 20,000 个标记图像,测试和验证集包含 2,500 个图像。
要使用数据集,必须将每个图像重新整形为227×227×3。为此,您可以使用prep_images.py中的 Python 代码。否则,您可以使用本书仓库中的trainDir.rar和testDir.rar文件。它们包含 6,000 个用于训练的犬和猫的重塑图像,以及 100 个重新成形的图像用于测试。
以下部分中描述的以下微调实现在alexnet_finetune.py中实现,可以在本书的代码库中下载。
微调的实现
我们的分类任务包含两个类别,因此网络的新 softmax 层将包含 2 个类别而不是 1,000 个类别。这是输入张量,它是一个227×227×3图像,以及等级 2 的输出张量:
n_classes = 2
train_x = zeros((1, 227,227,3)).astype(float32)
train_y = zeros((1, n_classes))
微调实现包括截断预训练网络的最后一层(softmax 层),并将其替换为与我们的问题相关的新 softmax 层。
例如,ImageNet 上预先训练好的网络带有一个包含 1,000 个类别的 softmax 层。
以下代码片段定义了新的 softmax 层fc8:
fc8W = tf.Variable(tf.random_normal\
([4096, n_classes]),\
trainable=True, name="fc8w")
fc8b = tf.Variable(tf.random_normal\
([n_classes]),\
trainable=True, name="fc8b")
fc8 = tf.nn.xw_plus_b(fc7, fc8W, fc8b)
prob = tf.nn.softmax(fc8)
损失是用于分类的表现指标。它是一个始终为正的连续函数,如果模型的预测输出与期望的输出完全匹配,则交叉熵等于零。因此,优化的目标是通过改变模型的权重和偏置来最小化交叉熵,因此它尽可能接近零。
TensorFlow 具有用于计算交叉熵的内置函数。为了使用交叉熵来优化模型的变量,我们需要一个标量值,因此我们只需要对所有图像分类采用交叉熵的平均值:
loss = tf.reduce_mean\
(tf.nn.softmax_cross_entropy_with_logits_v2\
(logits =prob, labels=y))
opt_vars = [v for v in tf.trainable_variables()\
if (v.name.startswith("fc8"))]
既然我们必须最小化成本度量,那么我们可以创建optimizer:
optimizer = tf.train.AdamOptimizer\
(learning_rate=learning_rate).minimize\
(loss, var_list = opt_vars)
correct_pred = tf.equal(tf.argmax(prob, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
在这种情况下,我们使用步长为0.5的AdamOptimizer。请注意,此时不执行优化。事实上,根本没有计算任何东西,我们只需将优化器对象添加到 TensorFlow 图中以便以后执行。然后我们在网络上运行反向传播以微调预训练的权重:
batch_size = 100
training_iters = 6000
display_step = 1
dropout = 0.85 # Dropout, probability to keep units
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 1
继续训练,直到达到最大迭代次数:
while step * batch_size < training_iters:
batch_x, batch_y = \
next(next_batch(batch_size)) #.next()
运行优化操作(反向传播):
sess.run(optimizer, \
feed_dict={x: batch_x, \
y: batch_y, \
keep_prob: dropout})
if step % display_step == 0:
计算批次损失和准确率:
cost, acc = sess.run([loss, accuracy],\
feed_dict={x: batch_x, \
y: batch_y, \
keep_prob: 1.})
print ("Iter " + str(step*batch_size) \
+ ", Minibatch Loss= " + \
"{:.6f}".format(cost) + \
", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print ("Optimization Finished!")
网络训练产生以下结果:
Iter 100, Minibatch Loss= 0.555294, Training Accuracy= 0.76000
Iter 200, Minibatch Loss= 0.584999, Training Accuracy= 0.73000
Iter 300, Minibatch Loss= 0.582527, Training Accuracy= 0.73000
Iter 400, Minibatch Loss= 0.610702, Training Accuracy= 0.70000
Iter 500, Minibatch Loss= 0.583640, Training Accuracy= 0.73000
Iter 600, Minibatch Loss= 0.583523, Training Accuracy= 0.73000
…………………………………………………………………
…………………………………………………………………
Iter 5400, Minibatch Loss= 0.361158, Training Accuracy= 0.95000
Iter 5500, Minibatch Loss= 0.403371, Training Accuracy= 0.91000
Iter 5600, Minibatch Loss= 0.404287, Training Accuracy= 0.91000
Iter 5700, Minibatch Loss= 0.413305, Training Accuracy= 0.90000
Iter 5800, Minibatch Loss= 0.413816, Training Accuracy= 0.89000
Iter 5900, Minibatch Loss= 0.413476, Training Accuracy= 0.90000
Optimization Finished!
要测试我们的模型,我们将预测与标签集(cat = 0,dog = 1)进行比较:
output = sess.run(prob, feed_dict = {x:imlist, keep_prob: 1.})
result = np.argmax(output,1)
testResult = [1,1,1,1,0,0,0,0,0,0,\
0,1,0,0,0,0,1,1,0,0,\
1,0,1,1,0,1,1,0,0,1,\
1,1,1,0,0,0,0,0,1,0,\
1,1,1,1,0,1,0,1,1,0,\
1,0,0,1,0,0,1,1,1,0,\
1,1,1,1,1,0,0,0,0,0,\
0,1,1,1,0,1,1,1,1,0,\
0,0,1,0,1,1,1,1,0,0,\
0,0,0,1,1,0,1,1,0,0]
count = 0
for i in range(0,99):
if result[i] == testResult[i]:
count=count+1
print("Testing Accuracy = " + str(count) +"%")
最后,我们有我们模型的准确率:
Testing Accuracy = 82%
VGG
VGG 是在 2014 年 ILSVRC 期间发明神经网络的人的名字。我们谈论的是复数网络,因为创建了同一网络的多个版本,每个拥有不同数量的层。根据层数n,这些网络中的一个具有的权重,它们中的每一个通常称为 VGG-n。所有这些网络都比 AlexNet 更深。这意味着它们由多个层组成,其参数比 AlexNet 更多,在这种情况下,总共有 11 到 19 个训练层。通常,只考虑可行的层,因为它们会影响模型的处理和大小,如前一段所示。然而,整体结构仍然非常相似:总是有一系列初始卷积层和最后一系列完全连接的层,后者与 AlexNet 完全相同。因此,使用的卷积层的数量,当然还有它们的参数有什么变化。下表显示了 VGG 团队构建的所有变体。
每一列,从左侧开始,向右侧,显示一个特定的 VGG 网络,从最深到最浅。粗体项表示与先前版本相比,每个版本中添加的内容。 ReLU 层未在表中显示,但在网络中它存在于每个卷积层之后。所有卷积层使用 1 的步幅:
表:VGG 网络架构
请注意, AlexNet 没有具有相当大的感受野的卷积层:这里,所有感受野都是3×3,除了 VGG-16 中有几个具有1×1感受野的卷积层。回想一下,具有 1 步梯度的凸层不会改变输入空间大小,同时修改深度值,该深度值与使用的内核数量相同。因此,VGG 卷积层不会影响输入体积的宽度和高度;只有池化层才能这样做。使用具有较小感受野的一系列卷积层的想法最终总体上模拟具有较大感受野的单个卷积层,这是由于这样的事实,即以这种方式使用多个 ReLU 层而不是单独使用一个,从而增加激活函数的非线性,从而使其更具区别性。它还用于减少使用的参数数量。这些网络被认为是 AlexNet 的演变,因为总体而言,使用相同的数据集,它们的表现优于 AlexNet。 VGG 网络演示的主要概念是拥塞神经网络越来越深刻,其表现也越来越高。但是, 必须拥有越来越强大的硬件,否则网络训练就会成为问题。
对于 VGG,使用了四个 NVIDIA Titan Blacks,每个都有 6 GB 的内存。因此,VGG 具有更好的表现,但需要大量的硬件用于训练,并且还使用大量参数:例如,VGG-19 模型大约为 550MB(是 AlexNet 的两倍)。较小的 VGG 网络仍然具有大约 507MB 的模型。
用 VGG-19 学习艺术风格
在这个项目中,我们使用预训练的 VGG-19 来学习艺术家创建的样式和模式,并将它们转移到图像中(项目文件是style_transfer.py,在本书的 GitHub 仓库中)。这种技术被称为artistic style learning(参见 Gatys 等人的文章 A Art Algorithm of Artistic Style)。根据学术文献,艺术风格学习定义如下:给定两个图像作为输入,合成具有第一图像的语义内容和第二图像的纹理/风格的第三图像。
为了使其正常工作,我们需要训练一个深度卷积神经网络来构建以下内容:
-
用于确定图像 A 内容的内容提取器
-
用于确定图像 B 样式的样式提取器
-
合并器将一些任意内容与另一个任意样式合并,以获得最终结果
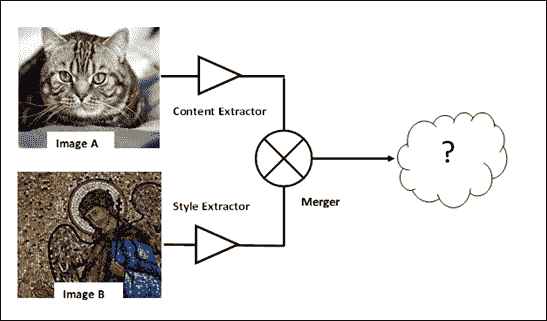
图 11:艺术风格学习操作模式
输入图像
输入图像,每个都是478×478像素,是您在本书的代码库中也可以找到的以下图像(cat.jpg和mosaic.jpg):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K8RNpZcU-1681565849704)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_04_13.jpg)]
图 12:艺术风格学习中的输入图像
为了通过 VGG 模型分析 ,需要对这些图像进行预处理:
-
添加额外的维度
-
从输入图像中减去
MEAN_VALUES:MEAN_VALUES = np.array([123.68, 116.779, 103.939]).reshape((1,1,1,3)) content_image = preprocess('cat.jpg') style_image = preprocess('mosaic.jpg') def preprocess(path): image = plt.imread(path) image = image[np.newaxis] image = image - MEAN_VALUES return image
内容提取器和损失
为了隔离图像的语义内容,我们使用预先训练好的 VGG-19 神经网络,对权重进行了一些微调,以适应这个问题,然后使用其中一个隐藏层的输出作为内容提取器。下图显示了用于此问题的 CNN:
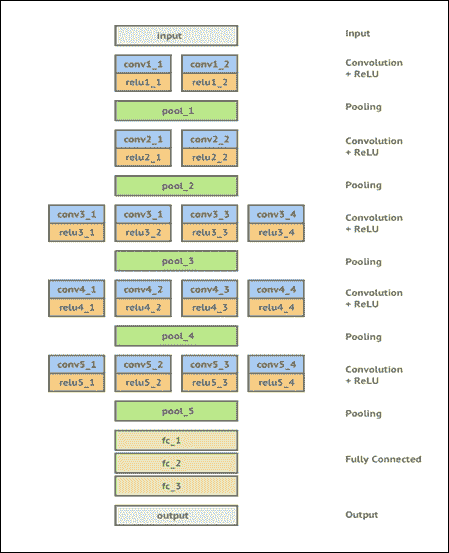
图 13:用于艺术风格学习的 VGG-19
使用以下代码加载预训练的 VGG:
import scipy.io
vgg = scipy.io.loadmat('imagenet-vgg-verydeep-19.mat')
imagenet-vgg-verydeep-19.mat模型应从此链接下载。
该模型有 43 层,其中 19 层是卷积层。其余的是最大池/激活/完全连接的层。
我们可以检查每个卷积层的形状:
[print (vgg_layers[0][i][0][0][2][0][0].shape,\
vgg_layers[0][i][0][0][0][0]) for i in range(43)
if 'conv' in vgg_layers[0][i][0][0][0][0] \
or 'fc' in vgg_layers[0][i][0][0][0][0]]
上述代码的结果如下:
(3, 3, 3, 64) conv1_1
(3, 3, 64, 64) conv1_2
(3, 3, 64, 128) conv2_1
(3, 3, 128, 128) conv2_2
(3, 3, 128, 256) conv3_1
(3, 3, 256, 256) conv3_2
(3, 3, 256, 256) conv3_3
(3, 3, 256, 256) conv3_4
(3, 3, 256, 512) conv4_1
(3, 3, 512, 512) conv4_2
(3, 3, 512, 512) conv4_3
(3, 3, 512, 512) conv4_4
(3, 3, 512, 512) conv5_1
(3, 3, 512, 512) conv5_2
(3, 3, 512, 512) conv5_3
(3, 3, 512, 512) conv5_4
(7, 7, 512, 4096) fc6
(1, 1, 4096, 4096) fc7
(1, 1, 4096, 1000) fc8
每种形状以下列方式表示:[kernel height, kernel width, number of input channels, number of output channels]。
第一层有 3 个输入通道,因为输入是 RGB 图像,而卷积层的输出通道数从 64 到 512,所有内核都是3x3矩阵。
然后我们应用转移学习技术,以使 VGG-19 网络适应我们的问题:
-
不需要完全连接的层,因为它们用于对象识别。
-
最大池层代替平均池层,以获得更好的结果。平均池层的工作方式与卷积层中的内核相同。
IMAGE_WIDTH = 478 IMAGE_HEIGHT = 478 INPUT_CHANNELS = 3 model = {} model['input'] = tf.Variable(np.zeros((1, IMAGE_HEIGHT,\ IMAGE_WIDTH,\ INPUT_CHANNELS)),\ dtype = 'float32') model['conv1_1'] = conv2d_relu(model['input'], 0, 'conv1_1') model['conv1_2'] = conv2d_relu(model['conv1_1'], 2, 'conv1_2') model['avgpool1'] = avgpool(model['conv1_2']) model['conv2_1'] = conv2d_relu(model['avgpool1'], 5, 'conv2_1') model['conv2_2'] = conv2d_relu(model['conv2_1'], 7, 'conv2_2') model['avgpool2'] = avgpool(model['conv2_2']) model['conv3_1'] = conv2d_relu(model['avgpool2'], 10, 'conv3_1') model['conv3_2'] = conv2d_relu(model['conv3_1'], 12, 'conv3_2') model['conv3_3'] = conv2d_relu(model['conv3_2'], 14, 'conv3_3') model['conv3_4'] = conv2d_relu(model['conv3_3'], 16, 'conv3_4') model['avgpool3'] = avgpool(model['conv3_4']) model['conv4_1'] = conv2d_relu(model['avgpool3'], 19,'conv4_1') model['conv4_2'] = conv2d_relu(model['conv4_1'], 21, 'conv4_2') model['conv4_3'] = conv2d_relu(model['conv4_2'], 23, 'conv4_3') model['conv4_4'] = conv2d_relu(model['conv4_3'], 25,'conv4_4') model['avgpool4'] = avgpool(model['conv4_4']) model['conv5_1'] = conv2d_relu(model['avgpool4'], 28, 'conv5_1') model['conv5_2'] = conv2d_relu(model['conv5_1'], 30, 'conv5_2') model['conv5_3'] = conv2d_relu(model['conv5_2'], 32, 'conv5_3') model['conv5_4'] = conv2d_relu(model['conv5_3'], 34, 'conv5_4') model['avgpool5'] = avgpool(model['conv5_4'])
这里我们定义了contentloss函数来测量两个图像p和x之间的内容差异:
def contentloss(p, x):
size = np.prod(p.shape[1:])
loss = (1./(2*size)) * tf.reduce_sum(tf.pow((x - p),2))
return loss
当输入图像在内容方面彼此非常接近并且随着其内容偏离而增长时,该函数倾向于为 0。
我们将在conv5_4层上使用contentloss。这是输出层,其输出将是预测,因此我们需要使用contentloss函数将此预测与实际预测进行比较:
content_loss = contentloss\
(sess.run(model['conv5_4']), model['conv5_4'])
最小化content_loss意味着混合图像在给定层中具有与内容图像的激活非常相似的特征激活。
样式提取器和损失
样式提取器使用过滤器的 Gram 矩阵作为给定的隐藏层。简单来说,使用这个矩阵,我们可以破坏图像的语义,保留其基本组件并使其成为一个好的纹理提取器:
def gram_matrix(F, N, M):
Ft = tf.reshape(F, (M, N))
return tf.matmul(tf.transpose(Ft), Ft)
style_loss测量两个图像彼此之间的接近程度。此函数是样式图像和输入noise_image生成的 Gram 矩阵元素的平方差的总和:
noise_image = np.random.uniform\
(-20, 20,\
(1, IMAGE_HEIGHT, \
IMAGE_WIDTH,\
INPUT_CHANNELS)).astype('float32')
def style_loss(a, x):
N = a.shape[3]
M = a.shape[1] * a.shape[2]
A = gram_matrix(a, N, M)
G = gram_matrix(x, N, M)
result = (1/(4 * N**2 * M**2))* tf.reduce_sum(tf.pow(G-A,2))
return result
style_loss生长 ,因为它的两个输入图像(a和x)倾向于偏离风格。
合并和总损失
我们可以合并内容和样式损失,以便训练输入noise_image来输出(在层中)与样式图像类似的样式,其特征相似于内容图像:
alpha = 1
beta = 100
total_loss = alpha * content_loss + beta * styleloss
训练
最小化网络中的损失,以便样式损失(输出图像的样式和样式图像的样式之间的损失),内容损失(内容图像和输出图像之间的损失),以及总变异损失尽可能低:
train_step = tf.train.AdamOptimizer(1.5).minimize(total_loss)
从这样的网络生成的输出图像应该类似于输入图像并且具有样式图像的造型师属性。
最后,我们可以准备网络进行训练:
sess.run(tf.global_variables_initializer())
sess.run(model['input'].assign(input_noise))
for it in range(2001):
sess.run(train_step)
if it%100 == 0:
mixed_image = sess.run(model['input'])
print('iteration:',it,'cost: ', sess.run(total_loss))
filename = 'out2/%d.png' % (it)
deprocess(filename, mixed_image)
训练时间可能非常耗时,但结果可能非常有趣:
iteration: 0 cost: 8.14037e+11
iteration: 100 cost: 1.65584e+10
iteration: 200 cost: 5.22747e+09
iteration: 300 cost: 2.72995e+09
iteration: 400 cost: 1.8309e+09
iteration: 500 cost: 1.36818e+09
iteration: 600 cost: 1.0804e+09
iteration: 700 cost: 8.83103e+08
iteration: 800 cost: 7.38783e+08
iteration: 900 cost: 6.28652e+08
iteration: 1000 cost: 5.41755e+08
经过 1000 次迭代后,我们创建了一个新的拼接:

图 14:艺术风格学习中的输出图像
真是太棒了!你终于可以训练你的神经网络像毕加索一样画画…玩得开心!
Inception-v3
Szegedy 和其他人在 2014 年的论文“Going Deeper with Convolutions”中首次介绍了 Inception 微架构:

图 15:GoogLeNet 中使用的 Original Inception 模块
初始模块的目标是通过在网络的同一模块内计算1×1,3×3和5×5卷积来充当多级特征提取器 - 这些滤波器的输出然后,在被馈送到网络中的下一层之前,沿着信道维度堆叠。这种架构的原始版本称为 GoogLeNet,但后续形式简称为 InceptionVN,其中 N 表示 Google 推出的版本号。
您可能想知道为什么我们在同一输入上使用不同类型的卷积。答案是,只要仔细研究了它的参数,就不可能总是获得足够的有用特征来用单个卷积进行精确分类。事实上,使用一些输入它可以更好地使用卷积小内核,而其他输入可以使用其他类型的内核获得更好的结果。可能由于这个原因,GoogLeNet 团队想要在他们自己的网络中考虑一些替代方案。如前所述,为此目的,GoogLeNet 在同一网络级别(即它们并行)使用三种类型的卷积层:1×1层,3×3层和5×5层。
这个 3 层并行局部结构的结果是它们所有输出值的组合,链接到单个向量输出,它将是下一层的输入。这是通过使用连接层完成的。除了三个并行卷积层之外,在相同的本地结构中还添加了一个池化层,因为池化操作对于 CNN 的成功至关重要。
使用 TensorFlow 探索初始化
从此链接,你应该能够下载相应的模型库。
然后键入以下命令:
cd models/tutorials/image/imagenet python classify_image.py
当程序第一次运行时,classify_image.py从 tensorflow.org 下载经过训练的模型。您的硬盘上需要大约 200MB 的可用空间。
上面的命令将对提供的熊猫图像进行分类。如果模型正确运行,脚本将生成以下输出:
giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.88493)
indri, indris, Indri indri, Indri brevicaudatus (score = 0.00878)
lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00317)
custard apple (score = 0.00149)
earthstar (score = 0.00127)
如果您想提供其他 JPEG 图像,可以通过编辑来完成:
image_file argument:
python classify_image.py --image=image.jpg
您可以通过从互联网下载图像并查看其产生的结果来测试初始阶段。
例如,您可以尝试从此链接获取以下图像(我们将其重命名为inception_image.jpg):

图 16:使用 Inception-v3 进行分类的输入图像
结果如下:
python classify_image.py --image=inception_example.jpg
strawberry (score = 0.91541)
crayfish, crawfish, crawdad, crawdaddy (score = 0.01208)
chocolate sauce, chocolate syrup (score = 0.00628)
cockroach, roach (score = 0.00572)
grocery store, grocery, food market, market (score = 0.00264)
听起来不错!
CNN 的情感识别
深度学习中难以解决的一个问题与神经网络无关:它是以正确格式获取正确数据。但是,Kaggle 平台提供了新的问题,并且需要研究新的数据集。
Kaggle 成立于 2010 年,作为预测建模和分析竞赛的平台,公司和研究人员发布他们的数据,来自世界各地的统计人员和数据挖掘者竞争生产最佳模型。在本节中,我们将展示如何使用面部图像制作 CNN 以进行情感检测。此示例的训练和测试集可以从此链接下载。
图 17:Kaggle 比赛页面
训练组由 3,761 个灰度图像组成,尺寸为48×48像素,3,761 个标签,每个图像有 7 个元素。
每个元素编码一个情感,0:愤怒,1:厌恶,2:恐惧,3:幸福,4:悲伤,5:惊讶,6:中立。
在经典 Kaggle 比赛中,必须由平台评估从测试集获得的标签集。在这个例子中,我们将训练一个来自训练组的神经网络,之后我们将在单个图像上评估模型。
在开始 CNN 实现之前,我们将通过实现一个简单的过程(文件download_and_display_images.py)来查看下载的数据。
导入库:
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
import EmotionUtils
read_data函数允许构建所有数据集,从下载的数据开始,您可以在本书的代码库中的EmotionUtils库中找到它们:
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_string("data_dir",\
"EmotionDetector/",\
"Path to data files")
images = []
images = EmotionUtils.read_data(FLAGS.data_dir)
train_images = images[0]
train_labels = images[1]
valid_images = images[2]
valid_labels = images[3]
test_images = images[4]
然后打印训练的形状并测试图像:
print ("train images shape = ",train_images.shape)
print ("test labels shape = ",test_images.shape)
显示训练组的第一个图像及其正确的标签:
image_0 = train_images[0]
label_0 = train_labels[0]
print ("image_0 shape = ",image_0.shape)
print ("label set = ",label_0)
image_0 = np.resize(image_0,(48,48))
plt.imshow(image_0, cmap='Greys_r')
plt.show()
有 3,761 个48×48像素的灰度图像:
train images shape = (3761, 48, 48, 1)
有 3,761 个类标签,每个类包含七个元素:
train labels shape = (3761, 7)
测试集由 1,312 个48x48像素灰度图像组成:
test labels shape = (1312, 48, 48, 1)
单个图像具有以下形状:
image_0 shape = (48, 48, 1)
第一张图片的标签设置如下:
label set = [ 0\. 0\. 0\. 1\. 0\. 0\. 0.]
此标签对应于快乐,图像在以下 matplot 图中可视化:
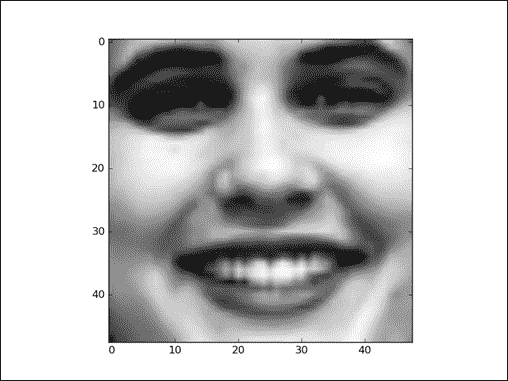
图 18:来自情感检测面部数据集的第一图像
我们现在转向 CNN 架构。
下图显示了数据将如何在 CNN 中流动:
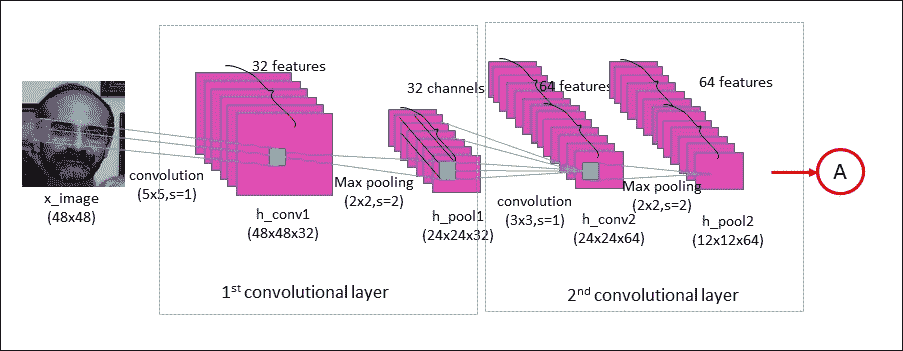
图 19:实现的 CNN 的前两个卷积层
该网络具有两个卷积层,两个完全连接的层,最后是 softmax 分类层。使用5×5卷积核在第一卷积层中处理输入图像(48×48像素)。这导致 32 个图像,每个使用的滤波器一个。通过最大合并操作对图像进行下采样,以将图像从48×48减小到24×24像素。然后,这些 32 个较小的图像由第二卷积层处理;这导致 64 个新图像(见上图)。通过第二次池化操作,将得到的图像再次下采样到12×12像素。
第二合并层的输出是64×12×12像素的图像。然后将它们展平为长度为12×12×64 = 9,126的单个向量,其用作具有 256 个神经元的完全连接层的输入。这将进入另一个具有 10 个神经元的完全连接的层,每个类对应一个类,用于确定图像的类别,即图像中描绘的情感。
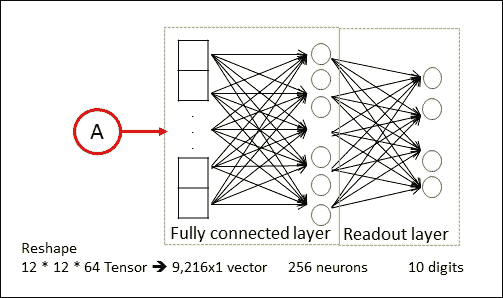
图 20:实现的 CNN 的最后两层
让我们继续讨论权重和偏置定义。以下数据结构表示网络权重的定义,并总结了到目前为止我们所描述的内容:
weights = {
'wc1': weight_variable([5, 5, 1, 32], name="W_conv1"),
'wc2': weight_variable([3, 3, 32, 64],name="W_conv2"),
'wf1': weight_variable([(IMAGE_SIZE // 4) * (IMAGE_SIZE // 4)
\* 64,256],name="W_fc1"),
'wf2': weight_variable([256, NUM_LABELS], name="W_fc2")
}
注意卷积滤波器是随机初始化的,所以分类是随机完成的:
def weight_variable(shape, stddev=0.02, name=None):
initial = tf.truncated_normal(shape, stddev=stddev)
if name is None:
return tf.Variable(initial)
else:
return tf.get_variable(name, initializer=initial)
以相似方式,我们已经定义了偏差:
biases = {
'bc1': bias_variable([32], name="b_conv1"),
'bc2': bias_variable([64], name="b_conv2"),
'bf1': bias_variable([256], name="b_fc1"),
'bf2': bias_variable([NUM_LABELS], name="b_fc2")
}
def bias_variable(shape, name=None):
initial = tf.constant(0.0, shape=shape)
if name is None:
return tf.Variable(initial)
else:
return tf.get_variable(name, initializer=initial)
优化器必须使用区分链规则通过 CNN 传播误差,并更新过滤器权重以改善分类误差。输入图像的预测类和真实类之间的差异由loss函数测量。它将pred模型的预测输出和所需输出label作为输入:
def loss(pred, label):
cross_entropy_loss =\
tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2\
(logits=pred, labels=label))
tf.summary.scalar('Entropy', cross_entropy_loss)
reg_losses = tf.add_n(tf.get_collection("losses"))
tf.summary.scalar('Reg_loss', reg_losses)
return cross_entropy_loss + REGULARIZATION * reg_losses
tf.nn.softmax_cross_entropy_with_logits_v2(pred, label)函数在应用 softmax 函数后计算结果的cross_entropy_loss(但它以数学上仔细的方式一起完成)。这就像是以下结果:
a = tf.nn.softmax(x)
b = cross_entropy(a)
我们计算每个分类图像的cross_entropy_loss,因此我们将测量模型在每个图像上的单独表现。
我们计算分类图像的交叉熵平均值:
cross_entropy_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2 (logits=pred, labels=label))
为了防止过拟合,我们将使用 L2 正则化,其中包括向cross_entropy_loss插入一个附加项:
reg_losses = tf.add_n(tf.get_collection("losses"))
return cross_entropy_loss + REGULARIZATION * reg_losses
哪里:
def add_to_regularization_loss(W, b):
tf.add_to_collection("losses", tf.nn.l2_loss(W))
tf.add_to_collection("losses", tf.nn.l2_loss(b))
注意
有关详细信息,请参阅此链接。
我们已经构建了网络的权重和偏置以及优化过程。但是,与所有已实现的网络一样,我们必须通过导入所有必需的库来启动实现:
import tensorflow as tf
import numpy as np
from datetime import datetime
import EmotionUtils
import os, sys, inspect
from tensorflow.python.framework import ops
import warnings
warnings.filterwarnings("ignore")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
ops.reset_default_graph()
然后,我们在您的计算机上设置存储数据集的路径,以及网络参数:
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_string("data_dir",\
"EmotionDetector/",\
"Path to data files")
tf.flags.DEFINE_string("logs_dir",\
"logs/EmotionDetector_logs/",\
"Path to where log files are to be saved")
tf.flags.DEFINE_string("mode",\
"train",\
"mode: train (Default)/ test")
BATCH_SIZE = 128
LEARNING_RATE = 1e-3
MAX_ITERATIONS = 1001
REGULARIZATION = 1e-2
IMAGE_SIZE = 48
NUM_LABELS = 7
VALIDATION_PERCENT = 0.1
emotion_cnn函数实现我们的模型:
def emotion_cnn(dataset):
with tf.name_scope("conv1") as scope:
tf.summary.histogram("W_conv1", weights['wc1'])
tf.summary.histogram("b_conv1", biases['bc1'])
conv_1 = tf.nn.conv2d(dataset, weights['wc1'],\
strides=[1, 1, 1, 1],\
padding="SAME")
h_conv1 = tf.nn.bias_add(conv_1, biases['bc1'])
h_1 = tf.nn.relu(h_conv1)
h_pool1 = max_pool_2x2(h_1)
add_to_regularization_loss(weights['wc1'], biases['bc1'])
with tf.name_scope("conv2") as scope:
tf.summary.histogram("W_conv2", weights['wc2'])
tf.summary.histogram("b_conv2", biases['bc2'])
conv_2 = tf.nn.conv2d(h_pool1, weights['wc2'],\
strides=[1, 1, 1, 1], \
padding="SAME")
h_conv2 = tf.nn.bias_add(conv_2, biases['bc2'])
h_2 = tf.nn.relu(h_conv2)
h_pool2 = max_pool_2x2(h_2)
add_to_regularization_loss(weights['wc2'], biases['bc2'])
with tf.name_scope("fc_1") as scope:
prob=0.5
image_size = IMAGE_SIZE // 4
h_flat = tf.reshape(h_pool2,[-1,image_size*image_size*64])
tf.summary.histogram("W_fc1", weights['wf1'])
tf.summary.histogram("b_fc1", biases['bf1'])
h_fc1 = tf.nn.relu(tf.matmul\
(h_flat, weights['wf1']) + biases['bf1'])
h_fc1_dropout = tf.nn.dropout(h_fc1, prob)
with tf.name_scope("fc_2") as scope:
tf.summary.histogram("W_fc2", weights['wf2'])
tf.summary.histogram("b_fc2", biases['bf2'])
pred = tf.matmul(h_fc1_dropout, weights['wf2']) +\
biases['bf2']
return pred
然后定义一个main函数,我们将在其中定义数据集,输入和输出占位符变量以及主会话,以便启动训练过程:
def main(argv=None):
此函数中的第一个操作是加载数据集以进行训练和验证。我们将使用训练集来教授分类器识别待预测的标签,我们将使用验证集来评估分类器的表现:
train_images,\
train_labels,\
valid_images,\
valid_labels,\ test_images=EmotionUtils.read_data(FLAGS.data_dir)
print("Train size: %s" % train_images.shape[0])
print('Validation size: %s' % valid_images.shape[0])
print("Test size: %s" % test_images.shape[0])
我们为输入图像定义占位符变量。这允许我们更改输入到 TensorFlow 图的图像。数据类型设置为float32,形状设置为[None, img_size, img_size, 1](其中None表示张量可以保存任意数量的图像,每个图像为img_size像素高和img_size像素宽),和1是颜色通道的数量:
input_dataset = tf.placeholder(tf.float32, \
[None, \
IMAGE_SIZE, \
IMAGE_SIZE, 1],name="input")
接下来,我们为与占位符变量input_dataset中输入的图像正确关联的标签提供占位符变量。这个占位符变量的形状是[None, NUM_LABELS],这意味着它可以包含任意数量的标签,每个标签是长度为NUM_LABELS的向量,在这种情况下为 7:
input_labels = tf.placeholder(tf.float32,\
[None, NUM_LABELS])
global_step保持跟踪到目前为止执行的优化迭代数量。我们希望在检查点中使用所有其他 TensorFlow 变量保存此变量。请注意trainable=False,这意味着 TensorFlow 不会尝试优化此变量:
global_step = tf.Variable(0, trainable=False)
跟随变量dropout_prob,用于丢弃优化:
dropout_prob = tf.placeholder(tf.float32)
现在为测试阶段创建神经网络。emotion_cnn()函数返回input_dataset的预测类标签pred:
pred = emotion_cnn(input_dataset)
output_pred是测试和验证的预测,我们将在运行会话中计算:
output_pred = tf.nn.softmax(pred,name="output")
loss_val包含输入图像的预测类(pred)与实际类别(input_labels)之间的差异:
loss_val = loss(pred, input_labels)
train_op定义用于最小化成本函数的优化器。在这种情况下,我们再次使用AdamOptimizer:
train_op = tf.train.AdamOptimizer\
(LEARNING_RATE).minimize\
(loss_val, global_step)
summary_op是用于 TensorBoard 可视化的 :
summary_op = tf.summary.merge_all()
创建图后,我们必须创建一个 TensorFlow 会话,用于执行图:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter(FLAGS.logs_dir, sess.graph)
我们定义saver来恢复模型:
saver = tf.train.Saver()
ckpt = tf.train.get_checkpoint_state(FLAGS.logs_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print ("Model Restored!")
接下来我们需要获得一批训练示例。batch_image现在拥有一批图像,batch_label包含这些图像的正确标签:
for step in xrange(MAX_ITERATIONS):
batch_image, batch_label = get_next_batch(train_images,\
train_labels,\
step)
我们将批次放入dict中,其中包含 TensorFlow 图中占位符变量的正确名称:
feed_dict = {input_dataset: batch_image, \
input_labels: batch_label}
我们使用这批训练数据运行优化器。 TensorFlow 将feed_dict_train中的变量分配给占位符变量,然后运行优化程序:
sess.run(train_op, feed_dict=feed_dict)
if step % 10 == 0:
train_loss,\
summary_str =\
sess.run([loss_val,summary_op],\
feed_dict=feed_dict)
summary_writer.add_summary(summary_str,\
global_step=step)
print ("Training Loss: %f" % train_loss)
当运行步长是 100 的倍数时,我们在验证集上运行训练模型:
if step % 100 == 0:
valid_loss = \
sess.run(loss_val, \
feed_dict={input_dataset: valid_images, input_labels: valid_labels})
然后我们打印掉损失值:
print ("%s Validation Loss: %f" \
% (datetime.now(), valid_loss))
在训练过程结束时,模型将被保存:
saver.save(sess, FLAGS.logs_dir\
+ 'model.ckpt', \
global_step=step)
if __name__ == "__main__":
tf.app.run()
这是输出。如您所见,在模拟过程中损失函数减少:
Reading train.csv ...
(4178, 48, 48, 1)
(4178, 7)
Reading test.csv ...
Picking ...
Train size: 3761
Validation size: 417
Test size: 1312
2018-02-24 15:17:45.421344 Validation Loss: 1.962773
2018-02-24 15:19:09.568140 Validation Loss: 1.796418
2018-02-24 15:20:35.122450 Validation Loss: 1.328313
2018-02-24 15:21:58.200816 Validation Loss: 1.120482
2018-02-24 15:23:24.024985 Validation Loss: 1.066049
2018-02-24 15:24:38.838554 Validation Loss: 0.965881
2018-02-24 15:25:54.761599 Validation Loss: 0.953470
2018-02-24 15:27:15.592093 Validation Loss: 0.897236
2018-02-24 15:28:39.881676 Validation Loss: 0.838831
2018-02-24 15:29:53.012461 Validation Loss: 0.910777
2018-02-24 15:31:14.416664 Validation Loss: 0.888537
>>>
然而,模型可以通过改变超参数或架构来改进。
在下一节中,我们将了解如何在您自己的图像上有效地测试模型。
在您自己的图像上测试模型
我们使用的数据集是标准化的。所有面部都指向相机,表情在某些情况下被夸大甚至滑稽。现在让我们看看如果我们使用更自然的图像会发生什么。确保脸部没有文字覆盖,情感可识别,脸部主要指向相机。
我从这个 JPEG 图像开始(它是一个彩色图像,你可以从书的代码库下载):

图 21:输入图像
使用 Matplotlib 和其他 NumPy Python 库,我们将输入颜色图像转换为网络的有效输入,即灰度图像:
img = mpimg.imread('author_image.jpg')
gray = rgb2gray(img)
转换函数如下:
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
结果如下图所示:

图 22:灰度输入图像
最后,我们可以使用此图像为网络提供信息,但首先我们必须定义一个正在运行的 TensorFlow 会话:
sess = tf.InteractiveSession()
然后我们可以回想起之前保存的模型:
new_saver = tf.train.\
import_meta_graph('logs/EmotionDetector_logs/model.ckpt-1000.meta')
new_saver.restore(sess,'logs/EmotionDetector_logs/model.ckpt-1000')
tf.get_default_graph().as_graph_def()
x = sess.graph.get_tensor_by_name("input:0")
y_conv = sess.graph.get_tensor_by_name("output:0")
要测试图像,我们必须将其重新整形为网络的有效48×48×1格式:
image_test = np.resize(gray,(1,48,48,1))
我们多次评估相同的图片(1000),以便在输入图像中获得一系列可能的情感:
tResult = testResult()
num_evaluations = 1000
for i in range(0,num_evaluations):
result = sess.run(y_conv, feed_dict={x:image_test})
label = sess.run(tf.argmax(result, 1))
label = label[0]
label = int(label)
tResult.evaluate(label)
tResult.display_result(num_evaluations)
在几秒后,会出现如下结果:
>>>
anger = 0.1%
disgust = 0.1%
fear = 29.1%
happy = 50.3%
sad = 0.1%
surprise = 20.0%
neutral = 0.3%
>>>
最高的百分比证实(happy = 50.3%)我们走在正确的轨道上。当然,这并不意味着我们的模型是准确的。可以通过更多和更多样化的训练集,更改网络参数或修改网络架构来实现可能的改进。
源代码
这里列出了实现的分类器的第二部分:
from scipy import misc
import numpy as np
import matplotlib.cm as cm
import tensorflow as tf
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
import EmotionUtils
from EmotionUtils import testResult
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
img = mpimg.imread('author_image.jpg')
gray = rgb2gray(img)
plt.imshow(gray, cmap = plt.get_cmap('gray'))
plt.show()
sess = tf.InteractiveSession()
new_saver = tf.train.import_meta_graph('logs/model.ckpt-1000.meta')
new_saver.restore(sess, 'logs/model.ckpt-1000')
tf.get_default_graph().as_graph_def()
x = sess.graph.get_tensor_by_name("input:0")
y_conv = sess.graph.get_tensor_by_name("output:0")
image_test = np.resize(gray,(1,48,48,1))
tResult = testResult()
num_evaluations = 1000
for i in range(0,num_evaluations):
result = sess.run(y_conv, feed_dict={x:image_test})
label = sess.run(tf.argmax(result, 1))
label = label[0]
label = int(label)
tResult.evaluate(label)
tResult.display_result(num_evaluations)
我们实现testResult Python 类来显示结果百分比。它可以在EmotionUtils文件中找到。
以下是此类的实现:
class testResult:
def __init__(self):
self.anger = 0
self.disgust = 0
self.fear = 0
self.happy = 0
self.sad = 0
self.surprise = 0
self.neutral = 0
def evaluate(self,label):
if (0 == label):
self.anger = self.anger+1
if (1 == label):
self.disgust = self.disgust+1
if (2 == label):
self.fear = self.fear+1
if (3 == label):
self.happy = self.happy+1
if (4 == label):
self.sad = self.sad+1
if (5 == label):
self.surprise = self.surprise+1
if (6 == label):
self.neutral = self.neutral+1
def display_result(self,evaluations):
print("anger = " +\
str((self.anger/float(evaluations))*100) + "%")
print("disgust = " +\
str((self.disgust/float(evaluations))*100) + "%")
print("fear = " +\
str((self.fear/float(evaluations))*100) + "%")
print("happy = " +\
str((self.happy/float(evaluations))*100) + "%")
print("sad = " +\
str((self.sad/float(evaluations))*100) + "%")
print("surprise = " +\
str((self.surprise/float(evaluations))*100) + "%")
print("neutral = " +\
str((self.neutral/float(evaluations))*100) + "%")
总结
在本章中,我们介绍了 CNN。我们已经看到 CNN 适用于图像分类问题,使训练阶段更快,测试阶段更准确。
最常见的 CNN 架构已经被描述:LeNet-5 模型,专为手写和机器打印字符识别而设计; AlexNet,2012 年参加 ILSVRC; VGG 模型在 ImageNet 中实现了 92.7% 的前 5 个测试精度(属于 1,000 个类别的超过 1400 万个图像的数据集);最后是 Inception-v3 模型,该模型负责在 2014 年 ILSVRC 中设置分类和检测标准。
每个 CNN 架构的描述后面都是一个代码示例。此外,AlexNet 网络和 VGG 示例有助于解释传输和样式学习技术的概念。
最后,我们建立了一个 CNN 来对图像数据集中的情感进行分类;我们在单个图像上测试了网络,并评估了模型的限制和质量。
下一章将介绍自编码器:这些算法可用于降维,分类,回归,协同过滤,特征学习和主题建模。我们将使用自编码器进行进一步的数据分析,并使用图像数据集测量分类表现。
五、使用 TensorFlow 实现自编码器
训练自编码器是一个简单的过程。它是一个 NN,其输出与其输入相同。有一个输入层,后面是几个隐藏层,然后在一定深度之后,隐藏层遵循反向架构,直到我们到达最终层与输入层相同的点。我们将数据传递到我们希望学习嵌入的网络中。
在此示例中,我们使用来自 MNIST 数据集的图像作为输入。我们通过导入所有主库来开始实现:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
然后我们准备 MNIST 数据集。我们使用 TensorFlow 中的内置input_data类来加载和设置数据。此类确保下载和预处理数据以供自编码器使用。因此,基本上,我们根本不需要进行任何特征工程:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
在前面的代码块中,one_hot=True参数确保所有特征都是热编码的。单热编码是一种技术,通过该技术将分类变量转换为可以馈入 ML 算法的形式。
接下来,我们配置网络参数:
learning_rate = 0.01
training_epochs = 20
batch_size = 256
display_step = 1
examples_to_show = 20
输入图像的大小如下:
n_input = 784
隐藏层的大小如下:
n_hidden_1 = 256
n_hidden_2 = 128
最终尺寸对应于28×28 = 784像素。
我们需要为输入图像定义占位符变量。该张量的数据类型设置为float,因为mnist值的比例为[0,1],形状设置为[None, n_input]。定义None参数意味着张量可以包含任意数量的图像:
X = tf.placeholder("float", [None, n_input])
然后我们可以定义网络的权重和偏置。weights数据结构包含编码器和解码器的权重定义。请注意,使用tf.random_normal选择权重,它返回具有正态分布的随机值:
weights = {
'encoder_h1': tf.Variable\
(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable\
(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable\
(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable\
(tf.random_normal([n_hidden_1, n_input])),
}
同样,我们定义了网络的偏置:
biases = {
'encoder_b1': tf.Variable\
(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable\
(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable\
(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable\
(tf.random_normal([n_input])),
}
我们将网络建模分为两个互补的完全连接的网络:编码器和解码器。编码器对数据进行编码;它从 MNIST 数据集中输入图像X,并执行数据编码:
encoder_in = tf.nn.sigmoid(tf.add\
(tf.matmul(X, \
weights['encoder_h1']),\
biases['encoder_b1']))
输入数据编码只是矩阵乘法运算。使用矩阵乘法将维度 784 的输入数据X减少到较低维度 256:
![]()
这里,W是权重张量,encoder_h1,b是偏置张量,encoder_b1。通过这个操作,我们将初始图像编码为自编码器的有用输入。编码过程的第二步包括数据压缩。输入encoder_in张量表示的数据通过第二个矩阵乘法运算减小到较小的大小:
encoder_out = tf.nn.sigmoid(tf.add\
(tf.matmul(encoder_in,\
weights['encoder_h2']),\
biases['encoder_b2']))
然后将尺寸 256 的输入数据encoder_in压缩到 128 的较小张量:
![]()
这里,W代表权重张量encoder_h2,而b代表偏差张量,encoder_b2。请注意,我们使用 sigmoid 作为编码器阶段的激活函数。
解码器执行编码器的逆操作。它解压缩输入以获得相同大小的网络输入的输出。该过程的第一步是将大小为 128 的encoder_out张量转换为 256 大小的中间表示的张量:
decoder_in = tf.nn.sigmoid(tf.add\
(tf.matmul(encoder_out,\
weights['decoder_h1']),\
biases['decoder_b1']))
在公式中,它意味着:
![]()
这里,W是权重张量,decoder_h1,大小256×128,b是偏置张量,decoder_b1,大小 256。最终解码操作是将数据从其中间表示(大小为 256)解压缩到最终表示(维度 784),这是原始数据的大小:
decoder_out = tf.nn.sigmoid(tf.add\
(tf.matmul(decoder_in,\
weights['decoder_h2']),\
biases['decoder_b2']))
y_pred参数设置为decoder_out:
y_pred = decoder_out
网络将了解输入数据X是否等于解码数据,因此我们定义以下内容:
y_true = X
自编码器的要点是创建一个擅长重建原始数据的缩减矩阵。因此,我们希望最小化cost函数。然后我们将cost函数定义为y_true和y_pred之间的均方误差:
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
为了优化cost函数,我们使用以下RMSPropOptimizer类:
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
然后我们准备启动会话:
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
我们需要设置批量图像的大小来训练网络:
total_batch = int(mnist.train.num_examples/batch_size)
从训练周期开始(training_epochs的数量设置为10):
for epoch in range(training_epochs):
循环遍历所有批次:
for i in range(total_batch):
batch_xs, batch_ys =\
mnist.train.next_batch(batch_size)
然后我们运行优化程序,用批量集batch_xs提供执行图:
_, c = sess.run([optimizer, cost],\
feed_dict={X: batch_xs})
接下来,我们显示每个epoch步骤的结果:
if epoch % display_step == 0:
print(„Epoch:", ‚%04d' % (epoch+1),
„cost=", „{:.9f}".format(c))
print("Optimization Finished!")
最后,我们使用编码或解码程序测试模型 。我们为模型提供图像子集,其中example_to_show的值设置为4:
encode_decode = sess.run(
y_pred, feed_dict=\
{X: mnist.test.images[:examples_to_show]})
我们使用 Matplotlib 比较原始图像和它们的重建:
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
f.show()
plt.draw()
plt.show()
当我们运行会话时,我们应该有这样的输出:
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
Epoch: 0001 cost= 0.208461761
Epoch: 0002 cost= 0.172908291
Epoch: 0003 cost= 0.153524384
Epoch: 0004 cost= 0.144243762
Epoch: 0005 cost= 0.137013704
Epoch: 0006 cost= 0.127291277
Epoch: 0007 cost= 0.125370100
Epoch: 0008 cost= 0.121299766
Epoch: 0009 cost= 0.111687921
Epoch: 0010 cost= 0.108801551
Epoch: 0011 cost= 0.105516203
Epoch: 0012 cost= 0.104304880
Epoch: 0013 cost= 0.103362709
Epoch: 0014 cost= 0.101118311
Epoch: 0015 cost= 0.098779991
Epoch: 0016 cost= 0.095374011
Epoch: 0017 cost= 0.095469855
Epoch: 0018 cost= 0.094381645
Epoch: 0019 cost= 0.090281256
Epoch: 0020 cost= 0.092290156
Optimization Finished!
然后我们显示结果。第一行是原始图像,第二行是解码图像:
图 4:原始和解码的 MNIST 图像
如你所见,第二个与原来的不同(它似乎仍然是数字二,就像三个一样)。我们可以增加周期数或更改网络参数以改善结果。
提高自编码器的鲁棒性
我们可以用来改善模型稳健性的成功策略,是在编码阶段引入噪声。我们将去噪自编码器称为自编码器的随机版本;在去噪自编码器中,输入被随机破坏,但相同输入的未破坏版本被用作解码阶段的目标。
直觉上, 去噪自编码器做了两件事:首先,它试图对输入进行编码,保留相关信息;然后,它试图消除应用于同一输入的腐败过程的影响。在下一节中,我们将展示一个去噪自编码器的实现。
实现去噪自编码器
网络架构非常简单。 784 像素的输入图像被随机破坏,然后通过编码网络层进行尺寸缩减。图像尺寸从 784 减少到 256 像素。
在解码阶段,我们准备网络输出,将图像大小返回到 784 像素。像往常一样,我们开始将所有必要的库加载到我们的实现中:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
然后我们设置基本的网络参数:
n_input = 784
n_hidden_1 = 1024
n_hidden_2 = 2048
n_output = 784
我们设置会话的参数:
epochs = 100
batch_size = 100
disp_step = 10
我们构建训练和测试集。我们再次使用从tensorflow.examples.tutorials.mnist导入的input_data函数:
print ("PACKAGES LOADED")
mnist = input_data.read_data_sets('data/', one_hot=True)
trainimg = mnist.train.images
trainlabel = mnist.train.labels
testimg = mnist.test.images
testlabel = mnist.test.labels
print ("MNIST LOADED")
让我们为输入图像定义一个占位符变量。数据类型设置为float,形状设置为[None, n_input]。None参数表示张量可以保持任意数量的图像,每个图像的大小为n_input:
x = tf.placeholder("float", [None, n_input])
接下来,我们有一个占位符变量,用于与在占位符变量x中输入的图像相关联的真实标签。这个占位符变量的形状是[None, n_output],这意味着它可以包含任意数量的标签,并且每个标签都是长度为n_output的向量,在这种情况下为10:
y = tf.placeholder("float", [None, n_output])
为了减少过拟合,我们在编码和解码过程之前应用一个丢弃,因此我们必须定义一个占位符,以便在丢弃期间保持神经元输出的概率:
dropout_keep_prob = tf.placeholder("float")
在这些定义中,我们修正了权重和网络偏差:
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_output]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_output]))
}
使用tf.random_normal选择weights和biases值,它返回具有正态分布的随机值。编码阶段将来自 MNIST 数据集的图像作为输入,然后通过应用矩阵乘法运算来执行数据压缩:
encode_in = tf.nn.sigmoid\
(tf.add(tf.matmul\
(x, weights['h1']),\
biases['b1']))
encode_out = tf.nn.dropout\
(encode_in, dropout_keep_prob)
在解码阶段,我们应用相同的过程:
decode_in = tf.nn.sigmoid\
(tf.add(tf.matmul\
(encode_out, weights['h2']),\
biases['b2']))
过拟合的减少是通过丢弃程序来完成的:
decode_out = tf.nn.dropout(decode_in,\
dropout_keep_prob)
最后,我们准备构建预测张量,y_pred:
y_pred = tf.nn.sigmoid\
(tf.matmul(decode_out,\
weights['out']) +\
biases['out'])
然后我们定义一个成本度量, 用于指导变量优化过程:
cost = tf.reduce_mean(tf.pow(y_pred - y, 2))
我们将使用RMSPropOptimizer类最小化cost函数:
optimizer = tf.train.RMSPropOptimizer(0.01).minimize(cost)
最后,我们可以按如下方式初始化已定义的变量:
init = tf.global_variables_initializer()
然后我们设置 TensorFlow 的运行会话:
with tf.Session() as sess:
sess.run(init)
print ("Start Training")
for epoch in range(epochs):
num_batch = int(mnist.train.num_examples/batch_size)
total_cost = 0.
for i in range(num_batch):
对于每个训练周期,我们从训练数据集中选择一个较小的批次集:
batch_xs, batch_ys = \
mnist.train.next_batch(batch_size)
这是焦点。我们使用之前导入的 NumPy 包中的randn函数随机破坏batch_xs集:
batch_xs_noisy = batch_xs + \
0.3*np.random.randn(batch_size, 784)
我们使用这些集来提供执行图,然后运行会话(sess.run):
feeds = {x: batch_xs_noisy,\
y: batch_xs, \
dropout_keep_prob: 0.8}
sess.run(optimizer, feed_dict=feeds)
total_cost += sess.run(cost, feed_dict=feeds)
每十个周期,将显示平均成本值:
if epoch % disp_step == 0:
print("Epoch %02d/%02d average cost: %.6f"
% (epoch, epochs, total_cost/num_batch))
最后,我们开始测试训练有素的模型:
print("Start Test")
为此,我们从测试集中随机选择一个图像:
randidx = np.random.randint\
(testimg.shape[0], size=1)
orgvec = testimg[randidx, :]
testvec = testimg[randidx, :]
label = np.argmax(testlabel[randidx, :], 1)
print("Test label is %d" % (label))
noisyvec = testvec + 0.3*np.random.randn(1, 784)
然后我们在选定的图像上运行训练模型:
outvec = sess.run(y_pred,\
feed_dict={x: noisyvec,\
dropout_keep_prob: 1})
正如我们将看到的,以下plotresult函数将显示原始图像,噪声图像和预测图像:
plotresult(orgvec,noisyvec,outvec)
print("restart Training")
当我们运行会话时,我们应该看到如下结果:
PACKAGES LOADED
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
MNIST LOADED
Start Training
为简洁起见,我们仅报告了 100 个周期后的结果:
Epoch 100/100 average cost: 0.212313
Start Test
Test label is 6
这些是原始图像和噪声图像(如您所见,数字 6):

图 5:原始图像和噪声图像
这是一个严格重建的图像:
图 6:严重重建的图像
在 100 个周期之后,我们有了更好的结果:
Epoch 100/100 average cost: 0.018221
Start Test
Test label is 5
这是原版和噪声图像:
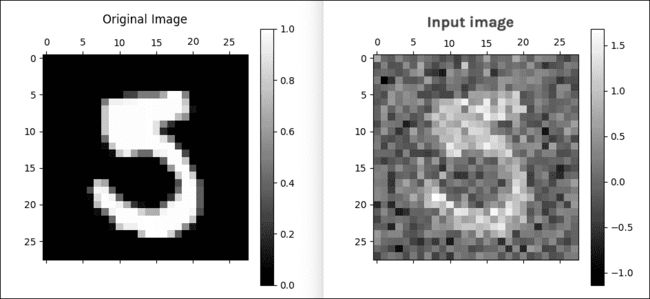
图 7:原始图像和噪声图像
这是一个很好的重建图像:
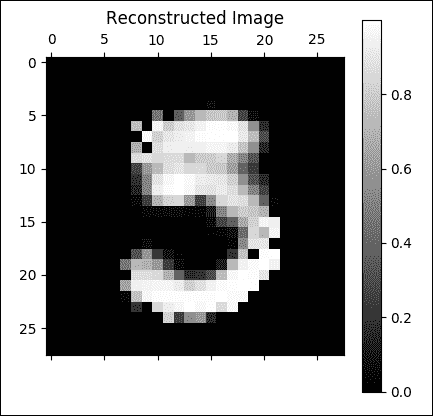
图 8:良好的重建图像
实现卷积自编码器
到目前为止,我们已经看到自编码器输入是图像。因此,有必要问一下卷积架构是否可以在我们之前展示的自编码器架构上更好地工作。我们将分析编码器和解码器在卷积自编码器中的工作原理。
编码器
编码器由三个卷积层组成。特征数量从输入数据 1 变为第一卷积层的 16;然后,第二层从 16 到 32;最后,从最后一个卷积层的 32 到 64。从卷积层移动到另一个层时,形状经历图像压缩:
图 9:编码阶段的数据流
解码器
解码器由三个依次排列的反卷积层组成。对于每个反卷积操作,我们减少特征的数量以获得必须与原始图像大小相同的图像。除了减少特征数量外,反卷积还可以转换图像的形状:
图 10:解码阶段的数据流
我们已经准备好了解如何实现卷积自编码器;第一个实现步骤是加载基本库:
import matplotlib.pyplot as plt
import numpy as np
import math
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
然后我们构建训练和测试集:
mnist = input_data.read_data_sets("data/", one_hot=True)
trainings = mnist.train.images
trainlabels = mnist.train.labels
testings = mnist.test.images
testlabels = mnist.test.labels
ntrain = trainings.shape[0]
ntest = testings.shape[0]
dim = trainings.shape[1]
nout = trainlabels.shape[1]
我们需要为输入图像定义占位符变量:
x = tf.placeholder(tf.float32, [None, dim])
数据类型设置为float32,形状设置为[None, dim],其中None表示张量可以保持任意数量的图像,每个图像是长度为dim的向量。接下来,我们为输出图像提供占位符变量。此变量的形状设置为[None, dim]与输入形状相同:
y = tf.placeholder(tf.float32, [None, dim])
然后我们定义keepprob变量,用于配置在网络训练期间使用的丢弃率:
keepprob = tf.placeholder(tf.float32)
此外,我们必须定义每个网络层中的节点数:
n1 = 16
n2 = 32
n3 = 64
ksize = 5
网络总共包含六层。前三层是卷积的,属于编码阶段,而后三层是解卷积的,是解码阶段的一部分:
weights = {
'ce1': tf.Variable(tf.random_normal\
([ksize, ksize, 1, n1],stddev=0.1)),
'ce2': tf.Variable(tf.random_normal\
([ksize, ksize, n1, n2],stddev=0.1)),
'ce3': tf.Variable(tf.random_normal\
([ksize, ksize, n2, n3],stddev=0.1)),
'cd3': tf.Variable(tf.random_normal\
([ksize, ksize, n2, n3],stddev=0.1)),
'cd2': tf.Variable(tf.random_normal\
([ksize, ksize, n1, n2],stddev=0.1)),
'cd1': tf.Variable(tf.random_normal\
([ksize, ksize, 1, n1],stddev=0.1))
}
biases = {
'be1': tf.Variable\
(tf.random_normal([n1], stddev=0.1)),
'be2': tf.Variable\
(tf.random_normal([n2], stddev=0.1)),
'be3': tf.Variable\
(tf.random_normal([n3], stddev=0.1)),
'bd3': tf.Variable\
(tf.random_normal([n2], stddev=0.1)),
'bd2': tf.Variable\
(tf.random_normal([n1], stddev=0.1)),
'bd1': tf.Variable\
(tf.random_normal([1], stddev=0.1))
}
以下函数cae构建卷积自编码器:传递的输入是图像,_X;数据结构权重和偏置,_W和_b;和_keepprob参数:
def cae(_X, _W, _b, _keepprob):
最初的 784 像素图像必须重新整形为28×28矩阵,随后由下一个卷积层处理:
_input_r = tf.reshape(_X, shape=[-1, 28, 28, 1])
第一个卷积层是_ce1。相对于输入图像,它有_input_r张量作为输入:
_ce1 = tf.nn.sigmoid\
(tf.add(tf.nn.conv2d\
(_input_r, _W['ce1'],\
strides=[1, 2, 2, 1],\
padding='SAME'),\
_b['be1']))
在移动到第二个卷积层之前,我们应用了丢弃操作:
_ce1 = tf.nn.dropout(_ce1, _keepprob)
在下面的两个编码层中,我们应用相同的卷积和丢弃操作:
_ce2 = tf.nn.sigmoid\
(tf.add(tf.nn.conv2d\
(_ce1, _W['ce2'],\
strides=[1, 2, 2, 1],\
padding='SAME'),\
_b['be2']))
_ce2 = tf.nn.dropout(_ce2, _keepprob)
_ce3 = tf.nn.sigmoid\
(tf.add(tf.nn.conv2d\
(_ce2, _W['ce3'],\
strides=[1, 2, 2, 1],\
padding='SAME'),\
_b['be3']))
_ce3 = tf.nn.dropout(_ce3, _keepprob)
特征数量从 1(输入图像)增加到 64,而原始形状图像已减少到28×28到7×7。在解码阶段,压缩(或编码)和重新成形的图像必须为尽可能与原始图像相似。为实现这一目标,我们在接下来的三个层中使用了conv2d_transpose TensorFlow 函数:
tf.nn.conv2d_transpose(value, filter, output_shape, strides, padding='SAME')
这种操作有时是 ,称为反卷积;它只是conv2d的梯度。该函数的参数如下:
value:float型和形状[batch, height, width, in_channels]的 4D 张量。filter:与value和形状[height, width, output_channels, in_channels]具有相同类型的 4D 张量。in_channels维度必须与值匹配。output_shape:表示去卷积操作的输出形状的 1D 张量。strides:整数列表。输入张量的每个维度的滑动窗口的步幅。padding:一个有效的字符串或SAME。
conv2d_transpose函数将返回与value参数类型相同的张量。第一个去卷积层_cd3具有卷积层_ce3作为输入。它返回_cd3张量,其形状为(1,7,7,32):
_cd3 = tf.nn.sigmoid\
(tf.add(tf.nn.conv2d_transpose\
(_ce3, _W['cd3'],\
tf.stack([tf.shape(_X)[0], 7, 7, n2]),\
strides=[1, 2, 2, 1],\
padding='SAME'),\
_b['bd3']))
_cd3 = tf.nn.dropout(_cd3, _keepprob)
对于第二个去卷积层_cd2,我们将反卷积层_cd3作为输入传递。它返回_cd2张量,其形状为(1,14,14,16):
_cd2 = tf.nn.sigmoid\
(tf.add(tf.nn.conv2d_transpose\
(_cd3, _W['cd2'],\
tf.stack([tf.shape(_X)[0], 14, 14, n1]),\
strides=[1, 2, 2, 1],\
padding='SAME'),\
_b['bd2']))
_cd2 = tf.nn.dropout(_cd2, _keepprob)
第三个也是最后一个反卷积层_cd1将_cd2层作为输入传递。它返回结果_out张量,其形状为(1,28,28,1),与输入图像相同:
_cd1 = tf.nn.sigmoid\
(tf.add(tf.nn.conv2d_transpose\
(_cd2, _W['cd1'],\
tf.stack([tf.shape(_X)[0], 28, 28, 1]),\
strides=[1, 2, 2, 1],\
padding='SAME'),\
_b['bd1']))
_cd1 = tf.nn.dropout(_cd1, _keepprob)
_out = _cd1
return _out
然后我们将成本函数定义为y和pred之间的均方误差:
pred = cae(x, weights, biases, keepprob)
cost = tf.reduce_sum\
(tf.square(cae(x, weights, biases, keepprob)\
- tf.reshape(y, shape=[-1, 28, 28, 1])))
learning_rate = 0.001
为了优化成本,我们将使用AdamOptimizer:
optm = tf.train.AdamOptimizer(learning_rate).minimize(cost)
在下一步中,我们配置我们的网络来运行会话:
init = tf.global_variables_initializer()
print ("Functions ready")
sess = tf.Session()
sess.run(init)
mean_img = np.zeros((784))
批次的大小设置为128:
batch_size = 128
周期数是50:
n_epochs = 50
然后我们开始循环会话:
for epoch_i in range(n_epochs):
对于每个周期,我们得到一个批量集trainbatch:
for batch_i in range(mnist.train.num_examples // batch_size):
batch_xs, _ = mnist.train.next_batch(batch_size)
trainbatch = np.array([img - mean_img for img in batch_xs])
我们应用随机噪声,就像去噪自编码器一样,来改善学习:
trainbatch_noisy = trainbatch + 0.3*np.random.randn(\
trainbatch.shape[0], 784)
sess.run(optm, feed_dict={x: trainbatch_noisy \
, y: trainbatch, keepprob: 0.7})
print ("[%02d/%02d] cost: %.4f" % (epoch_i, n_epochs \
, sess.run(cost, feed_dict={x: trainbatch_noisy \
, y: trainbatch, keepprob: 1.})))
对于每个训练周期,我们随机抽取五个训练样例:
if (epoch_i % 10) == 0:
n_examples = 5
test_xs, _ = mnist.test.next_batch(n_examples)
test_xs_noisy = test_xs + 0.3*np.random.randn(
test_xs.shape[0], 784)
然后我们在一个小子集上测试训练模型:
recon = sess.run(pred, feed_dict={x: test_xs_noisy,\
keepprob: 1.})
fig, axs = plt.subplots(2, n_examples, figsize=(15, 4))
for example_i in range(n_examples):
axs[0][example_i].matshow(np.reshape(
test_xs_noisy[example_i, :], (28, 28))
, cmap=plt.get_cmap('gray'))
最后,我们可以使用 Matplotlib 显示输入和学习集:
axs[1][example_i].matshow(np.reshape(
np.reshape(recon[example_i, ...], (784,))
+ mean_img, (28, 28)), cmap=plt.get_cmap('gray'))
plt.show()
执行将产生以下输出:
>>>
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
Packages loaded
Network ready
Functions ready
Start training..
[00/05] cost: 8049.0332
[01/05] cost: 3706.8667
[02/05] cost: 2839.9155
[03/05] cost: 2462.7021
[04/05] cost: 2391.9460
>>>
请注意,对于每个周期,我们将可视化输入集和先前显示的相应学习集。正如您在第一个周期所看到的,我们不知道哪些图像已被学习:
图 11:第一个周期图像
在第二个周期, 的想法变得更加清晰 :

图 12:第二周期图像
这是第三个周期:

图 13:第三周期图像
在第四个周期再好一点:

图 14:第四周期图像
我们可能已经停止在上一个周期,但这是第五个也是最后一个周期:

图 15:第五周期图像
到目前为止,我们已经看到了自编码器的不同实现以及改进版本。但是,将此技术应用于 MNIST 数据集并不能说明其真正的力量。因此,现在是时候看到一个更现实的问题,我们可以应用自编码器技术。
自编码器和欺诈分析
银行,保险公司和信用合作社等金融公司的欺诈检测和预防是一项重要任务。到目前为止,我们已经看到如何以及在何处使用深度神经网络(DNN) 和卷积神经网络(CNN)。
现在是时候使用其他无监督学习算法,如自编码器。在本节中,我们将探索信用卡交易的数据集,并尝试构建一个无监督的机器学习模型,该模型能够判断特定交易是欺诈性的还是真实的。
更具体地说,我们将使用自编码器预先训练分类模型并应用异常检测技术来预测可能的欺诈。在开始之前,我们需要知道数据集。
数据集的描述
对于这个例子,我们将使用来自 Kaggle 的信用卡欺诈检测数据集。数据集可以从此链接下载。由于我使用的是数据集,因此引用以下出版物时,最好是透明的:
Andrea Dal Pozzolo,Olivier Caelen,Reid A. Johnson 和 Gianluca Bontempi。用不平衡分类的欠采样校准概率。在计算智能和数据挖掘研讨会(CIDM),IEEE,2015 年。
该数据集包含 2013 年 9 月欧洲信用卡持有人在两天内进行的交易。共有 285,299 笔交易,只有 492 笔欺诈,这意味着数据集非常不平衡。正类(欺诈)占所有交易的 0.172%。
数据集包含数字输入变量,这些变量是 PCA 转换的结果。遗憾的是,由于机密性问题,我们无法提供有关数据的原始特征和更多背景信息。有 28 个特征,即V1,V2,… V27,它们是使用 PCA 获得的主要成分,除了Time和Amount特征。Class特征是响应变量,在欺诈情况下取值1,否则取0。
还有两个附加特征,Time和Amount。Time列表示每笔交易与第一笔交易之间的时间(以秒为单位),而Amount列表示此交易中转账的金额。那么,让我们看一下输入数据(仅显示V1,V2,V26和V27),如图 16 所示:
图 16:信用卡欺诈检测数据集的快照
问题描述
对于这个例子,我们将使用自编码器作为无监督的特征学习算法,该算法学习和概括训练数据共享的公共模式。在重建阶段,对于具有异常模式的数据点,RMSE 将更高。因此,这些数据点是异常值或异常值。我们的假设是,异常也等于我们所追求的欺诈性交易。
现在,在评估步骤中,我们可以根据验证数据选择 RMSE 的阈值,并将 RMSE 高于阈值的所有数据标记为欺诈。或者,如果我们认为 0.1% 的交易都是欺诈性的,我们也可以根据每个数据点(即 RMSE)的重建误差对数据进行排名,然后选择前 0.1% 为欺诈性交易。
给定类不平衡比,建议使用精确回忆曲线下面积(AUPRC)测量精度 ,因为混淆矩阵精度在不平衡分类中没有意义。在这种情况下,使用线性机器学习模型,例如随机森林,逻辑回归或支持向量机,通过应用上下采样技术,将是一个更好的主意。或者,我们可以尝试查找数据中的异常,因为我们假设数据集中只有少数欺诈案例,即异常。
在处理如此严重的响应标签不平衡时,我们在测量模型表现时也需要小心。只有少数欺诈性实例,因此将一切预测为非欺诈的模型将达到 99% 以上的准确率。然而,尽管它们具有高精度,但线性 ML 模型(甚至是树组合)并不一定能帮助我们找到欺诈性案例。
对于这个例子,我们将构建一个无监督的模型:该模型将接受正面和负面数据(欺诈和非欺诈)的训练,但不提供标签。由于我们有比欺诈更多的正常交易,我们应该期望该模型在训练后学习和记忆正常交易的模式,并且该模型应该能够为任何异常交易给出分数。
这种无监督的训练对于此目的非常有用,因为我们没有足够的标记数据。那么,让我们开始吧。
探索性数据分析
在我们实现模型之前,探索数据集将提供一些见解。我们首先导入所需的包和模块(包括此示例所需的其他包)和模块:
import pandas as pd
import numpy as np
import tensorflow as tf
import os
from datetime import datetime
from sklearn.metrics import roc_auc_score as auc
import seaborn as sns # for statistical data visualization
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
提示
安装 seaborn
您可以通过多种方式安装seaborn,这是一个用于统计数据可视化的 Python 模块:
$ sudo pip install seaborn # for Python 2.7
$ sudo pip3 install seaborn # for Python 3.x
$ sudo conda install seaborn # using conda
# Directly from GitHub (use pip for Python 2.7)
$ pip3 install git+https://github.com/mwaskom/seaborn.git
现在,我假设您已经从上述 URL 下载了数据集。下载附带一个名为creditcard.csv的 CSV 文件。
接下来,让我们阅读数据集并创建一个 pandas DataFrame:
df = pd.read_csv('creditcard.csv')
print(df.shape)
>>>
(284807, 31)
因此,数据集具有关于 300,000 个事务,30 个特征和两个二元标签(即 0/1)。现在让我们看一下列名及其数据类型:
print(df.columns)
>>>
Index(['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8', 'V9', 'V10', 'V11', 'V12', 'V13', 'V14', 'V15', 'V16', 'V17', 'V18', 'V19', 'V20', 'V21', 'V22', 'V23', 'V24', 'V25', 'V26', 'V27', 'V28', 'Amount', 'Class'],
dtype='object')
print(df.dtypes)
>>>
Time float64
V1 float64
V2 float64
V3 float64
…
V25 float64
V26 float64
V27 float64
V28 float64
Amount float64
Class int64
现在让我们来看看数据集:
print(df.head())
>>>
图 17:数据集的快照
现在让我们看看所有交易的时间跨度:
print("Total time spanning: {:.1f} days".format(df['Time'].max() / (3600 * 24.0)))
>>>
Total time spanning: 2.0 days
现在让我们看看这些类的统计信息:
print("{:.3f} % of all transactions are fraud. ".format(np.sum(df['Class']) / df.shape[0] * 100))
>>>
0.173 % of all transactions are fraud.
因此,我们只有少数欺诈交易。这在文献中也被称为罕见事件检测,并且意味着数据集高度不平衡。现在,让我们绘制前五个特征的直方图:
plt.figure(figsize=(12,5*4))
gs = gridspec.GridSpec(5, 1)
for i, cn in enumerate(df.columns[:5]):
ax = plt.subplot(gs[i])
sns.distplot(df[cn][df.Class == 1], bins=50)
sns.distplot(df[cn][df.Class == 0], bins=50)
ax.set_xlabel('')
ax.set_title('histogram of feature: ' + str(cn))
plt.show()
>>>
图 18:显示前五个特征的直方图
在前面的屏幕截图中,可以看出所有特征都是正偏差或负偏斜。此外,数据集没有很多特征,因此修剪尾部会丢失重要的信息。所以,暂时,让我们尽量不这样做,并使用所有特征。
训练,验证和测试集准备
让我们通过将数据分成训练,开发(也称为验证)和测试集来开始训练。我们首先使用 80% 的数据作为训练和验证集。剩余的 20% 将用作测试集:
TEST_RATIO = 0.20
df.sort_values('Time', inplace = True)
TRA_INDEX = int((1-TEST_RATIO) * df.shape[0])
train_x = df.iloc[:TRA_INDEX, 1:-2].values
train_y = df.iloc[:TRA_INDEX, -1].values
test_x = df.iloc[TRA_INDEX:, 1:-2].values
test_y = df.iloc[TRA_INDEX:, -1].values
现在,让我们对前面的分裂进行统计:
print("Total train examples: {}, total fraud cases: {}, equal to {:.5f} % of total cases. ".format(train_x.shape[0], np.sum(train_y), (np.sum(train_y)/train_x.shape[0])*100))
print("Total test examples: {}, total fraud cases: {}, equal to {:.5f} % of total cases. ".format(test_x.shape[0], np.sum(test_y), (np.sum(test_y)/test_y.shape[0])*100))
>>>
Total train examples: 227845, total fraud cases: 417, equal to 0.18302 % of total cases.
Total test examples: 56962, total fraud cases: 75, equal to 0.13167 % of total cases.
归一化
为了获得更好的预测准确率,我们可以考虑两种类型的标准化:z 得分和 min-max 缩放:
- Z 得分:这将每列归一化为零均值并将其标准化。这特别适用于激活函数,例如 tanh,其输出零两侧的值。其次,这将留下极端值,因此在正常化之后会有一些极端。在这种情况下,这可能对检测异常值很有用。
- 最小 - 最大缩放:这确保所有值都在 0 和 1 之间,即正数。如果我们使用 sigmoid 作为输出激活,这是默认方法。
我们使用验证集来决定数据标准化方法和激活函数。根据实验,我们发现当与 z 得分标准化一起使用时,tanh 的表现略好于 sigmoid。因此,我们选择了 tanh,然后是 z 得分:
cols_mean = []
cols_std = []
for c in range(train_x.shape[1]):
cols_mean.append(train_x[:,c].mean())
cols_std.append(train_x[:,c].std())
train_x[:, c] = (train_x[:, c] - cols_mean[-1]) / cols_std[-1]
test_x[:, c] = (test_x[:, c] - cols_mean[-1]) / cols_std[-1]
作为无监督特征学习算法的自编码器
在本小节中,我们将看到如何使用自编码器作为无监督的特征学习算法。首先,让我们初始化网络超参数:
learning_rate = 0.001
training_epochs = 1000
batch_size = 256
display_step = 10
n_hidden_1 = 15 # number of neurons is the num features
n_input = train_x.shape[1]
由于第一层和第二层分别包含 15 和 5 个神经元,我们正在构建这样的架构网络:28(输入)-> 15 -> 5 -> 15 -> 28(输出)。那么让我们构建我们的自编码器网络。
让我们创建一个 TensorFlow 占位符来保存输入:
X = tf.placeholder("float", [None, n_input])
现在我们必须使用随机初始化创建偏差和权重向量:
weights = {
'encoder_h1': tf.Variable\
(tf.random_normal([n_input, n_hidden_1])),
'decoder_h1': tf.Variable\
(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b1': tf.Variable(tf.random_normal([n_input])),
}
现在,我们构建一个简单的自编码器。这里我们有encoder()函数,它构造了编码器。我们使用tanh函数对隐藏层进行编码,如下所示:
def encoder(x):
layer_1 = tf.nn.tanh(tf.add\
(tf.matmul(x, weights['encoder_h1']),\
biases['encoder_b1']))
return layer_1
这是decoder()函数,它构造了解码器。我们使用tanh函数解码隐藏层,如下所示:
def decoder(x):
layer_1 = tf.nn.tanh(tf.add\
(tf.matmul(x, weights['decoder_h1']),\
biases['decoder_b1']))
return layer_1
之后,我们通过传递输入数据的 TensorFlow 占位符来构建模型。权重和偏置(NN 的W和b)包含我们将学习优化的网络的所有参数,如下所示:
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
一旦我们构建了自编码器网络,就可以进行预测,其中目标是输入数据:
y_pred = decoder_op
y_true = X
现在我们已经进行了预测,现在是时候定义batch_mse来评估表现:
batch_mse = tf.reduce_mean(tf.pow(y_true - y_pred, 2), 1)
注意
未观测值的均方误差(MSE)是平方误差或偏差的平均值。从统计学的角度来看, 它是估计量质量的度量(它总是非负的,接近于零的值更好)。
如果Y^是 n 个预测的向量,并且Y是被预测变量的观测值的向量,则预测变量的样本内 MSE 计算如下:

因此,MSE 是误差平方(Y[i] - Y^[i])^2的平均值(1/n ∑[i])。
我们在这里有另一个batch_mse将返回批量中所有输入数据的 RMSE,这是一个长度等于输入数据中行数的向量。如果您想要输入(无论是训练,验证还是测试数据),这些将是预测值或欺诈分数,我们可以在预测后提取出来。然后我们定义损失和优化器,并最小化平方误差:
cost_op = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost_op)
每层所用的激活函数是tanh。这里的目标函数或成本测量一批中预测和输入数组的总 RMSE,这意味着它是一个标量。然后,每次我们想要进行批量更新时,我们都会运行优化器。
太棒了!我们准备开始训练了。但是,在此之前,让我们定义保存训练模型的路径:
save_model = os.path.join(data_dir, 'autoencoder_model.ckpt')
saver = tf.train.Saver()
到目前为止,我们已经定义了许多变量以及超参数,因此我们必须初始化变量:
init_op = tf.global_variables_initializer()
最后,我们开始训练。我们在训练周期中循环所有批次。然后我们运行优化操作和成本操作来获得损失值。然后我们显示每个周期步骤的日志。最后,我们保存训练有素的模型:
epoch_list = []
loss_list = []
train_auc_list = []
data_dir = 'Training_logs/'
with tf.Session() as sess:
now = datetime.now()
sess.run(init_op)
total_batch = int(train_x.shape[0]/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_idx = np.random.choice(train_x.shape[0],\
batch_size)
batch_xs = train_x[batch_idx]
# Run optimization op (backprop) and
# cost op (to get loss value)
_, c = sess.run([optimizer, cost_op],\
feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
train_batch_mse = sess.run(batch_mse,\
feed_dict={X: train_x})
epoch_list.append(epoch+1)
loss_list.append(c)
train_auc_list.append(auc(train_y, train_batch_mse))
print("Epoch:", '%04d,' % (epoch+1),
"cost=", "{:.9f},".format(c),
"Train auc=", "{:.6f},".format(auc(train_y, \
train_batch_mse)),
print("Optimization Finished!")
save_path = saver.save(sess, save_model)
print("Model saved in: %s" % save_path)
save_model = os.path.join(data_dir, autoencoder_model_1L.ckpt')
saver = tf.train.Saver()
前面的代码段很简单。每次,我们从train_x中随机抽取 256 个小批量的小批量,作为X的输入将其输入模型,并运行优化器通过随机梯度下降更新参数 SGD):
>>>
Epoch: 0001, cost= 0.938937187, Train auc= 0.951383
Epoch: 0011, cost= 0.491790086, Train auc= 0.954131
…
Epoch: 0981, cost= 0.323749095, Train auc= 0.953185
Epoch: 0991, cost= 0.255667418, Train auc= 0.953107
Optimization Finished!
Model saved in: Training_logs/autoencoder_model.ckpt
Test auc score: 0.947296
我们在train_x上的估值得出的 AUC 得分约为 0.95。然而,从前面的日志中,很难理解训练的进展情况:
# Plot Training AUC over time
plt.plot(epoch_list, train_auc_list, 'k--', label='Training AUC', linewidth=1.0)
plt.title('Training AUC per iteration')
plt.xlabel('Iteration')
plt.ylabel('Training AUC')
plt.legend(loc='upper right')
plt.grid(True)
# Plot train loss over time
plt.plot(epoch_list, loss_list, 'r--', label='Training loss', linewidth=1.0)
plt.title('Training loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
>>>

图 19:每次迭代的训练损失和 AUC
在上图中,我们可以看到训练误差有点颠簸,但训练 AUC 几乎保持稳定,约为 95%。这可能听起来很可疑。您还可以看到我们使用相同的数据进行训练和验证。这可能听起来很混乱,但等等!
由于我们正在进行无监督的训练,并且模型在训练期间从未看到标签,因此不会导致过拟合。此附加验证用于监视早期停止以及超参数调整。
评估模型
在训练完我们的自编码器模型和超参数后,我们可以在 20% 测试数据集上评估其表现,如下所示:
save_model = os.path.join(data_dir, autoencoder_model.ckpt')
saver = tf.train.Saver()
# Initializing the variables
init = tf.global_variables_initializer()
with tf.Session() as sess:
now = datetime.now()
saver.restore(sess, save_model)
test_batch_mse = sess.run(batch_mse, feed_dict={X: test_x})
print("Test auc score: {:.6f}".format(auc(test_y, \
test_batch_mse)))
在此代码中,我们重用了之前制作的训练模型。test_batch_mse是我们测试数据的欺诈分数:
>>>
Test auc score: 0.948843
太棒了!我们训练有素的模型被证明是一个高度准确的模型,显示 AUC 约为 95%。现在我们已经看到了评估,一些可视化分析会很棒。你们觉得怎么样?让我们绘制非欺诈案件的欺诈分数(MSE)分布图。以下代码段执行此操作:
plt.hist(test_batch_mse[test_y == 0.0], bins = 100)
plt.title("Fraud score (mse) distribution for non-fraud cases")
plt.xlabel("Fraud score (mse)")
plt.show()
>>>
图 20:非欺诈案件的 MSE 欺诈评分
前面的屏幕截图是不可理解的,所以让我们将其缩放到(0, 30)范围并再次绘制图形:
# Zoom into (0, 30) range
plt.hist(test_batch_mse[(test_y == 0.0) & (test_batch_mse < 30)], bins = 100)
plt.title("Fraud score (mse) distribution for non-fraud cases")
plt.xlabel("Fraud score (mse)")
plt.show()
>>>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4YQOSeAB-1681565849711)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/dl-tf-2e-zh/img/B09698_05_21.jpg)]
图 21:非欺诈案件的 MSE 欺诈评分,放大到(0, 30)范围
现在让我们只显示欺诈类:
# Display only fraud classes
plt.hist(test_batch_mse[test_y == 1.0], bins = 100)plt.title("Fraud score (mse) distribution for fraud cases")
plt.xlabel("Fraud score (mse)")
plt.show()
>>>
图 22:欺诈案件的 MSE 欺诈评分
最后,让我们看一下一些相关统计数据。例如,我们使用10作为检测阈值。现在我们可以计算高于阈值的检测到的病例数,高于阈值的阳性病例数,高于阈值的准确率百分比(即精确度),并将其与测试集中欺诈的平均百分比进行比较:
threshold = 10
print("Number of detected cases above threshold: {}, \n\
Number of pos cases only above threshold: {}, \n\
The percentage of accuracy above threshold (Precision): {:0.2f}%. \n\
Compared to the average percentage of fraud in test set: 0.132%".format( \
np.sum(test_batch_mse > threshold), \
np.sum(test_y[test_batch_mse > threshold]), \
np.sum(test_y[test_batch_mse > threshold]) / np.sum(test_batch_mse > threshold) * 100))
>>>
Number of detected cases above threshold: 198,
Number of positive cases only above threshold: 18,
The percentage of accuracy above threshold (Precision): 9.09%.
Compared to the average percentage of fraud in test set: 0.132%
总而言之,对于我们的案例,只有一个隐藏层的自编码器足够(至少用于训练)。但是,您仍然可以尝试采用其他变体,例如解卷积自编码器和去噪自编码器来解决同样的问题。
总结
在本章中,我们实现了一些称为自编码器的优化网络。自编码器基本上是数据压缩网络模型。它用于将给定输入编码为较小维度的表示,然后可以使用解码器从编码版本重建输入。我们实现的所有自编码器都包含编码和解码部分。
我们还看到了如何通过在网络训练期间引入噪声和构建去噪自编码器来提高自编码器的表现。最后,我们应用第 4 章中介绍的 CNN 概念,卷积神经网络上的 TensorFlow 和卷积自编码器的实现。
即使隐藏单元的数量很大,我们仍然可以通过在网络上施加其他约束来使用自编码器发现数据集的有趣和隐藏结构。换句话说,如果我们对隐藏单元施加稀疏约束,那么即使隐藏单元的数量很大,自编码器仍将在数据中发现有趣的结构。为了证明这一观点,我们看到了一个真实的例子,即信用卡欺诈分析,我们成功应用了自编码器。
循环神经网络(RNN)是一类人工神经网络,其中单元之间的连接形成有向循环。 RNN 利用过去的信息,如时间序列预测。这样,他们就可以对具有高时间依赖性的数据进行预测。这创建了网络的内部状态,允许它展示动态时间行为。
在下一章中,我们将研究 RNN。我们将首先描述这些网络的基本原理,然后我们将实现这些架构的一些有趣示例。