【PyTorch】第二节:梯度的求解
作者️♂️:让机器理解语言か
专栏:PyTorch
描述:PyTorch 是一个基于 Torch 的 Python 开源机器学习库。
寄语:没有白走的路,每一步都算数!

介绍
本实验首先讲解了梯度的定义和求解方式,然后引入 PyTorch 中的相关函数,完成了张量的梯度定义、梯度计算、梯度清空以及关闭梯度等操作。
知识点
- 张量的属性
- 计算图
- 梯度的计算
梯度计算
张量的梯度计算
在一元函数中,某点的梯度表示的就是某点的导数。在多元函数中某点的梯度表示的是,由每个自变量所对应的偏导值所组成的向量。如 f(x,y,z) 的梯度向量就是![]() 。
。
梯度的方向就是函数值上升最快的方向。
✅requires_grad=True 对指定变量求取偏导
我们一般可以使用 torch.autograd.backward() 来自动计算变量的梯度,该函数会对指定的变量进行偏导的求取。为了辨别函数中哪些变量需要求偏导,哪些不需要求偏导,我们一般会在定义张量时,加上 requires_grad=True,表示该变量可以求偏导。
import torch
x = torch.randn(1, requires_grad=True)
y = torch.randn(1)
z = torch.randn(1)
f1 = 2*x+y
f2 = y+z
# 查看变量是否存在求梯度函数
print(f1.grad_fn)
print(f2.grad_fn)
#
# None 从结果可以看出, x 被定义成可以求偏导的变量,因此,它所对应的变量 f1 就是可求导的(通过 torch.grad_fn 查看)。
✅background() 获取函数的梯度、x.grad展示偏导的值
接下来让我利用 f1.backward() 求取 f1 的梯度(即所有变量的偏导),然后利用 x.grad 展示 ![]() 的值。
的值。
f1.backward()
print(x.grad) # df1/dx
# tensor([2.])当然除了上面简单的一元函数求偏导外,我们还可以使用上面的方法来求取复合函数的偏导:
x = torch.randn(3, requires_grad=True) # x 中存了三个变量 x1,x2,x3
# tensor([-1.0625, -1.6651, -0.8413], requires_grad=True)
y = x + 2
# tensor([0.9375, 0.3349, 1.1587], grad_fn=)
z = y * y * 3
# tensor([2.6368, 0.3364, 4.0280], grad_fn=)
z = z.mean()
print(z) # tensor(2.3338, grad_fn=)
print(z.grad_fn) #
# 验证:
根据上面代码可知,我们定义了一个 z 关于变量 x 的多元复合函数,如下:
我们手动计算一下 z 关于 x 的偏导数。首先我们将 z 进行展开。
特别的,我们计算 z 对于
的偏导,
,其他的计算类似。
首先计算
:
接着计算
为:
所以最终
为:
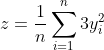
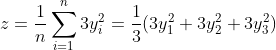
我们也可以使用 z.backward() 求取梯度,该张量的梯度结果会被放在所对应变量的 grad 属性中。下面我们比较一下通过 z.backward() 求取梯度和我们上面推导出的结果是否一样。
z.backward()
print(x.grad) # dz/dx = dz/d(x+2) = dz/dy
# tensor([1.8750, 0.6698, 2.3175])
print(2*(x+2)) # 比较直接计算的结果
# tensor([1.8750, 0.6698, 2.3175], grad_fn=) 上面结果为函数 z 的梯度向量,即函数 z 分别关于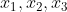 的偏导数。
的偏导数。
✅background( )参数:grad_variables
简单的说, torch.autograd.backward 就是使用链式法则对变量的偏导进行了求解。该函数有一个参数 grad_variables,该参数相当于给原梯度进行了一个加权。
如果使用函数 k.backward(p) 则得到的的变量 x.grad 的值为:
![]()
x = torch.randn(3, requires_grad=True)
k = x * 2
for _ in range(10):
k = k * 2 # 最后得到 k = 2^11 * x = 2048 * x
print(k) # tensor([-736.0573, 1320.2373, -650.0005], grad_fn=)
print(k.shape) # torch.Size([3])
p = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float32)
k.backward(p)
print(x.grad) # tensor([2.0480e+02, 2.0480e+03, 2.0480e-01])
停止张量的梯度计算
如果我们不需要某些张量的梯度计算,我们就可以使用下面三种方法告诉计算机停止梯度的计算:
x.requires_grad_(False)x.detach()with torch.no_grad():
下面举例展示一下三种方法如何使用:
-
x.requires_grad_(False):就地更改现有标志
a = torch.randn(2, 2, requires_grad=True)
b = ((a * 3) / (a - 1))
print(b.grad_fn) # 此时可偏导,求取梯度的函数存在
a.requires_grad_(False)
b = ((a * 3) / (a - 1))
print(b.grad_fn) # 此时不可偏导了,求取梯度的函数不存在了
#
# None -
x.detach():获取具有相同内容但不能进行梯度计算的新张量
a = torch.randn(2, 2, requires_grad=True)
b = a.detach()
print(a.requires_grad)
print(b.requires_grad)
# True
# False-
with torch.no_grad():在该作用域中定义的都是不进行梯度计算的张量
a = torch.randn(2, 2, requires_grad=True)
print((a ** 2).requires_grad)
with torch.no_grad(): # 该作用域下定义的都是不进行梯度计算的张量
print((a ** 2).requires_grad)
# True
# False梯度的清空
在 PyTorch 中,如果我们利用 torch.autograd.backward 求取张量的梯度时。但是,如果我们多次运行该函数,该函数会将计算得到的梯度累加起来,如下所示:
x = torch.ones(4, requires_grad=True)
y = (2*x+1).sum()
z = (2*x).sum()
y.backward()
print("第一次偏导:", x.grad) # dy/dx
z.backward()
print("第二次偏导:", x.grad) # dy/dx+dz/dx
# 第一次偏导: tensor([2., 2., 2., 2.])
# 第二次偏导: tensor([4., 4., 4., 4.]) 从上面的结果可以看到,如果我们对张量 y 和 z 分别求梯度,那么它们关于 x 的偏导都会被放入 x.grad 中,形成累加的局面。
为了避免这种情况,一般我们在计算完梯度后,都会清空梯度,即清空 x.grad 。在清空梯度后,我们再进行其他张量的梯度求解。
我们可以使用 x.grad.zero_() 清空梯度:
x = torch.ones(4, requires_grad=True)
y = (2*x+1).sum()
z = (2*x).sum()
y.backward()
print("第一次偏导:", x.grad) # dy/dx
x.grad.zero_()
z.backward()
print("第二次偏导:", x.grad) # dz/dx
# 第一次偏导: tensor([2., 2., 2., 2.])
# 第二次偏导: tensor([2., 2., 2., 2.])这个性质是非常重要的,特别是在后面我们将要学到的梯度下降算法之中。
因为我们训练模型时需要循环求梯度,如果这时梯度一直叠加,那么我们求出来的结果就没有意义。因此,可以使用上面方法对张量的偏导进行清空。
除了张量中存在梯度清空函数,优化器中也存在这样的函数:zero_grad()。
optimizer = torch.optim.SGD([x], lr=0.1)
optimizer.step()
optimizer.zero_grad()
optimizer

关于上面代码中的提到的优化器知识,我们将在后面的实验中学到,这里只需要知道优化器也需要进行梯度清空即可。
实验总结
本实验首先讲解了梯度的含义,然后利用 PyTorch 定义了可以自动求偏导的张量,然后对张量进行了梯度求解,最后阐述了梯度清空的重要性和必要性。在下一个实验中,我们会利用梯度求解函数,详细的阐述神经网络中的正向传播和反向传播。