“基于医疗知识图谱的问答系统”代码解析(一)
“基于医疗知识图谱的问答系统”代码解析(一)
build_medicalgraph.py —建立医疗知识图谱的代码解析
“基于医疗知识图谱的问答系统”代码解析(二)
“基于医疗知识图谱的问答系统”代码解析(三)
“基于医疗知识图谱的问答系统”代码解析(四)
基于医疗知识图谱的问答系统”代码解析(五)
这是我对刘老师所写“基于知识医疗图谱的问答系统”代码的解读。
# 预备知识#!/usr/bin/env python3
# coding: utf-8
# File: MedicalGraph.py
# Author:lhy成功构建后的知识图谱
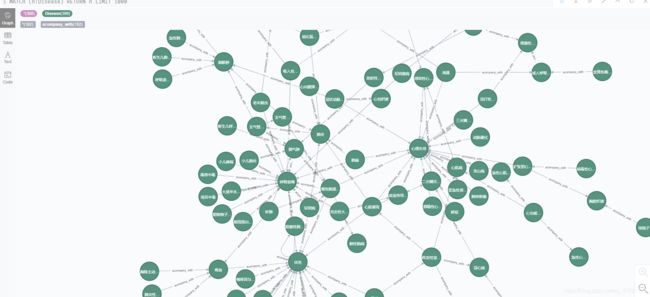

总结
注释有的简单就不写在上面了,欢迎指出不足。
当然代码很重要,但是之前的准备也要做好,比如neo4j的配置,因为我也是初入知识图谱,对这方面不太熟悉,就想着去github网找一个代码跑一下,结果经过了两天时间,我才跑成功,可能是我太笨了,不过笨鸟先飞。neo4j的配置 我就弄了挺久,所以推荐下面的链接给各位看官,希望各位看官多多支持,有疑惑随时提出,https://www.it610.com/article/1289837419532722176.htm
后续我会不断更新,希望各位看官多多指点