程序猿三部曲之青铜时代
之前在某篇公众号文章中,看到工资10K、15K、20K的Java程序员应该掌握的技术。大致对应着初、中、高级开发人员,所以我打算针对这三个阶段,写三篇文章,一边学习,一边总结。
曾经读过王小波的时代三部曲,分别是《青铜时代》、《白银时代》、《黄金时代》,遂借用来类比程序员的三个阶段。
1 接口和抽象类的关系和区别
1.1 理解接口和抽象类
这个问题之前有了解过,也看过一些文章,但是好长时间不复习,也总是会忘记。因为工作中其实也不会很严谨的按照规则去使用接口和抽象类,总是按照controller、interface、mapper这样的通用格式,实现功能。借此机会,再次学习一下。
接口关心的是对象可以做什么,抽象类主要是描述对象是什么。定义一个狗狗的抽象类,这个类可以被藏獒继承、也可以被哈士奇、柯基继承,但是不能被人类继承。一个活动的接口,定义一个奔跑的方法,这个接口就不局限于藏獒和人类了,只要对象具有奔跑的能力,就可以实现这个接口,拥有奔跑的能力(方法)。所以在java中,类的单继承多实现就很好理解了。在应用场景中,抽象类用于同类事物,而接口多是可以横跨很多个类。
1.2 接口和抽象类的区别
- 抽象类则可以包含普通方法,接口中的普通方法默认为抽象方法。
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的,并且必须赋值,否则通不过编译。
- 接口不能包含构造器,抽象类可以包含构造器,抽象类里的构造器并不是用于创建对象,而是让其子类调用这些构造器来完成属于抽象类的初始化操作。
- 接口里不能包含初始化块,但抽象类里完全可以包含初始化块。
- 就是我们所说的单继承多实现了。
1.3 什么时候应该使用接口而不用抽象类
- 需要实现多态
- 要实现的方法(功能)不是当前类族的必要(属性).
- 要为不同类族的多个类实现同样的方法(功能).
参考资料:搞了这么多年终于知道接口和抽象类的应用场景了
2 反射机制和动态代理
2.1 反射机制
反射(Reflection)是Java程序开发语言的特征之一它允许运行中的Java程序获取自身的信息,并且可以操作类或对象的内部属性。通过反射机制,可以在运行时访问Java对象的属性,方法,构造方法等。
2.1.1 反射的应用场景
反射的主要应用场景有:
- 开发通用框架 - 反射最重要的用途就是开发各种通用框架。很多框架(比如 Spring)都是配置化的(比如通过 XML 文件配置 JavaBean、Filter 等),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射——运行时动态加载需要加载的对象。
- 动态代理 - 在切面编程(AOP)中,需要拦截特定的方法,通常,会选择动态代理方式。这时,就需要反射技术来实现了。
- 注解 - 注解本身仅仅是起到标记作用,它需要利用反射机制,根据注解标记去调用注解解释器,执行行为。如果没有反射机制,注解并不比注释更有用。
- 可扩展性功能 - 应用程序可以通过使用完全限定名称创建可扩展性对象实例来使用外部的用户定义类。
2.1.2 反射的缺点
- 性能开销 - 由于反射涉及动态解析的类型,因此无法执行某些 Java 虚拟机优化。因此,反射操作的性能要比非反射操作的性能要差,应该在性能敏感的应用程序中频繁调用的代码段中避免。
- 破坏封装性 - 反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
- 内部曝光 - 由于反射允许代码执行在非反射代码中非法的操作,例如访问私有字段和方法,所以反射的使用可能会导致意想不到的副作用,这可能会导致代码功能失常并可能破坏可移植性。反射代码打破了抽象,因此可能会随着平台的升级而改变行为。
2.2 动态代理
代理模式是为了提供额外或不同的操作,而插入的用来替代“实际”对象的对象,这些操作涉及到与“实际”对象的通信,因此代理通常充当中间人角色。Java的动态代理比代理的思想更前进了一步,它可以动态地创建并代理并动态地处理对所代理方法的调用。在动态代理上所做的所有调用都会被重定向到单一的调用处理器上,它的工作是揭示调用的类型并确定相应的策略。
学习Spring的时候,我们知道Spring主要有两大思想,一个是IoC,另一个就是AOP,对于IoC,它利用的是反射机制,依赖注入就不用多说了,而对于Spring的核心AOP来说,使用了动态代理,其实底层也是反射。我们不但要知道怎么通过AOP来满足的我们的功能,我们更需要学习的是其底层是怎么样的一个原理,而AOP的原理就是java的动态代理机制。
参考资料:
深入理解Java反射和动态代理
深入理解Java反射+动态代理
3 项目中事务的使用
事务的四个特征:原子性、一致性、隔离性、持久性
3.1 事务传播属性
- Propagation.REQUIRED:支持当前事务,如果当前没有事务,则新建一个事务,默认使用这种,也是最常见的.
- Propagation.SUPPORTS:支持当前事务,如果没有事务,就以非事务的方式执行.
- Propagation.MANDATORY:支持当前事务,如果没有事务,就抛出异常.
- Propagation.REQUIRES_NEW:新建事务,如果当前存在事务,就把当前事务挂起.
- Propagation.NOT_SUPPORTED:以非事务的方式执行操作,如果当前存在事务,就把当前事务挂起.
- Propagation.NEVER:以非事务的方式执行,如果当前存在事务,则会抛出异常.
- Propagation.NESTED:如果当前事务存在,则执行嵌套事务,否则执行类似REQUIRED的操作.
SpringBoot注解@Transactional实现事务
一个事务内部,没有隔离的概念的。打个比方:在同一个事务里,先对一条记录执行更新操作,然后再执行查询操作,整个事务没有完全的执行完毕,那么在执行查询的时候,虽然事务还没结束,但是查询的仍然是最新的更新的值,如果是另外一个事务查询这条记录,因为第一个事务并没有完全结束,所以查询到的就是老值。
3.2 @Transactional事务不生效的场景
spring的事务实现原理为AOP,只有通过代理对象调用方法才能被拦截,事务才能生效。
-
private、final、static方法,事务不生效,入口方法必须是public,spring的AOP特性决定的,spring认为private自己用的方法应该自己控制,不应该用事务切进去
-
Spring的事务管理默认只对出现运行期异常(java.lang.RuntimeException及其子类)进行回滚(至于为什么spring要这么设计:因为spring认为Checked的异常属于业务的,coder需要给出解决方案而不应该直接扔该框架)
-
同类调用不生效(service方法中调用本类中的另一个方法,事务没有生效):
-
如果使用的是rollbakfor的默认,已检查的异常(所有派生自Error和RuntimeException的类,都是未检查异常.其余的是已检查异常, 比如nullPointException是未检查的,IllegalAccessException 是已检查的)不回滚,可设为rollbackFor={Exception.class}
-
最好不要把@Trasaction注解到接口上:在接口上使用 @Transactional 注解,只能当你设置了基于接口的代理时它才生效。因为注解是不能继承的,这就意味着如果正在使用基于类的代理时,那么事务的设置将不能被基于类的代理所识别,而且对象也将不会被事务代理所包装。
-
确认你的类是否被代理了(因为spring的事务实现原理为AOP,只有通过代理对象调用方法才能被拦截,事务才能生效 )。
-
确保你的业务和事务入口在同一个线程里,否则事务也是不生效的 。
参考资料: 《java开发事务篇】之一分钟搞懂事务、使用方式和特定场景》
4 Spring IoC和AOP
4.1 IoC 控制反转
IoC 是 Inversion of Control 的简写,译为“控制反转”,它不是一门技术,而是一种设计思想,是一个重要的面向对象编程法则,能够指导我们如何设计出松耦合、更优良的程序。Spring 通过 IoC 容器来管理所有Java对象的实例化和初始化,控制对象与对象之间的依赖关系。我们将由 IoC 容器管理的 Java 对象称为 Spring Bean,它与使用关键字 new 创建的 Java 对象没有任何区别。
在传统的 Java 应用中,一个类想要调用另一个类中的属性或方法,通常会先在其代码中通过 new Object() 的方式将后者的对象创建出来,然后才能实现属性或方法的调用。为了方便理解和描述,我们可以将前者称为“调用者”,将后者称为“被调用者”。也就是说,调用者掌握着被调用者对象创建的控制权。
但在 Spring 应用中,Java 对象创建的控制权是掌握在 IoC 容器手里的,其大致步骤如下。
- 开发人员通过 XML 配置文件、注解、Java 配置类等方式,对 Java 对象进行定义,例如在 XML 配置文件中使用
标签、在 Java 类上使用 @Component 注解等。 - Spring 启动时,IoC 容器会自动根据对象定义,将这些对象创建并管理起来。这些被 IoC 容器创建并管理的对象被称为 Spring Bean。
- 当我们想要使用某个 Bean 时,可以直接从 IoC 容器中获取(例如通过 ApplicationContext 的 getBean() 方法),而不需要手动通过代码(例如 new Obejct() 的方式)创建。
IoC 带来的最大改变不是代码层面的,而是从思想层面上发生了“主从换位”的改变。原本调用者是主动的一方,它想要使用什么资源就会主动出击,自己创建;但在 Spring 应用中,IoC 容器掌握着主动权,调用者则变成了被动的一方,被动的等待 IoC 容器创建它所需要的对象(Bean)。
这个过程在职责层面发生了控制权的反转,把原本调用者通过代码实现的对象的创建,反转给 IoC 容器来帮忙实现,因此我们将这个过程称为 Spring 的“控制反转”。
依赖注入(Denpendency Injection,简写为 DI)是 Martin Fowler 在 2004 年在对“控制反转”进行解释时提出的。Martin Fowler 认为“控制反转”一词很晦涩,无法让人很直接的理解“到底是哪里反转了”,因此他建议使用“依赖注入”来代替“控制反转”。控制反转核心思想就是由 Spring负责对象的创建。在对象创建过程中,Spring会自动根据依赖关系,将它依赖的对象注入到当前对象中,这就是所谓的“依赖注入”。
依赖注入本质上是 Spring Bean 属性注入的一种,只不过这个属性是一个对象属性而已。
参考资料:Spring IoC(控制反转)
5 在实际工作中怎样对SQL进行调优
5.1 防止索引失效
索引会提升数据的查询效率,但是会降低“增删改”的效率。尽管如此,索引还是很划算的,因为我们大多数的操作就是查询,查询对于程序的性能影响是很大的。索引分为单值索引、唯一索引、复合索引。
- 在MySQL中不建议使用left join,即使on过滤条件列索引,一些情况也不会走索引,导致大量的数据行被扫描,SQL性能变得很差;
- 使用
!=或者<>会导致索引失效,进而会全表搜索,所以如果数据量大的话,谨慎使用; - 类型不一致也将导致索引失效,比如age的类型是varchar类型,那么查询的时候如果where条件设置age = 12,那么索引就会失效,但是有一种情况不会使索引失效,如果age的类型是int,查询条件age传的是varchar类型的值,是可以走索引的,因为MySQL内部做了隐式类型转换。
- 索引列作为函数的入参,会导致索引失效;
- 如果索引对列进行了四则运算(+,-,*,/,!),都会使索引失效;
- OR导致索引失效,例如where user = ‘zhangsan’ or age = 11。但是也不是所有的OR都使索引失效,如果OR连接的是同一个字段,那么索引不会失效;
- 模糊查询导致索引失效;
- NOT IN、 NOT EXISTS这两种用法都不走索引,但是IN还是走索引的;
- IS NULL不走索引,IS NOT NULL走索引。
在设计字段时,如果字段没有要求没没有值的情况下一定要设置为NULL,那么建议设置为空字符串。
5.2 SELECT检查
- 尽量不使用
select *,需要什么字段就取什么字段; - SQL语句的SELECT后面使用自定义函数,那么SQL查询结果返回多少行,那么UDF函数就会被调用多少次,非常影响性能;
- 如果SELECT出现text类型的字段,就会消耗大量的网络和IO宽带,由于返回的内容过大,超过max_allowed_packet设置会导致程序报错,需要评估谨慎使用。
gorup_concat是一个字符串聚合函数,会影响SQL的响应时间,如果返回的值过大超过了max_allowed_packet设置会导致程序报错。- 在select后面有子查询的情况称为内联子查询,SQL返回多少行,子查询就需要执行过多少次,严重影响SQL性能。
5.3 LIMIT
- 当查询我们知道只会有一条结果或者我们只需要一条结果的时候,加上limit 1可以增加性能,因为mysql数据库引擎会在找到一条数据后停止检索,而不是往后查找下一条符合条件的数据。
- 慎用LIMIT m,n分页查询,越往后面翻页,即m值越大的情况下SQL的耗时会越长。
6 Redis是如何实现高可用的?
Redis实现高可用的手段主要有以下四种:
- 数据持久化:保证了数据不丢失;
- Redis主从同步:让Redis从单机变成了多机。它有两种模式:主从模式和从从模式,但当主节点出现问题时,需要人工手动恢复系统;
- Redis哨兵模式:用来监控 Redis 主从模式,并提供了自动容灾恢复的功能。
- Redis 集群:除了可以提供主从和哨兵的功能之外,还提供了多个主从节点的集群功能,这样就可以把数据均匀的存储各个主机主节点上,实现了系统的横向扩展,大大提高了 Redis 的并发处理能力。
6.1 数据持久化
数据持久化保证了系统在发生宕机或者重启之后数据不会丢失,增加了系统的可靠性和减少了系统不可用的时间(省去了手动恢复数据的过程);
在 Redis 4.0 之前数据持久化方式有两种:AOF方式和RDB方式,在 Redis 4.0 推出了混合持久化的功能。
-
RDB(Redis DataBase,快照恢复)是将某一个时刻的内存数据,以二进制的方式写入磁盘。RDB 默认的保存文件为 dump.rdb,优点是以二进制存储的,因此占用的空间更小、数据存储更紧凑,并且与 AOF 相比,RDB 具备更快的重启恢复能力,但有数据丢失的风险。
-
AOF(Append-Only File,只追加文件)是指将所有的操作命令,以文本的形式追加到文件中。AOF 默认的保存文件为 appendonly.aof,它的优点是存储频率更高,因此丢失数据的风险就越低,并且 AOF 并不是以二进制存储的,所以可读性更高。缺点是占用空间大,重启之后的数据恢复速度比较慢。
-
Redis 混合持久化的存储模式指的是 Redis 可以使用 RDB + AOF 两种格式来进行数据持久化,开始的数据以 RDB 的格式进行存储,因此只会占用少量的空间,之后的命令会以 AOF 的方式进行数据追加,这样就可以减低数据丢失的风险,同时可以提高数据恢复的速度这样就可以做到扬长避短物尽其用了。
可以使用config get aof-use-rdb-preamble的命令来查询 Redis 混合持久化的功能是否开启
6.2 Redis主从同步
主从同步是 Redis 多机运行中最基础的功能,有一主节点和多个从节点,多个节点组成一个 Redis 集群,在这个集群主节点用来进行数据的操作,其他从节点用于同步主节点的内容,并且提供给客户端进行数据查询。
Redis 主从同步分为:主从模式和从从模式。
- 主从模式是一个主节点和多个一级从节点
- 从从模式是在主从模式的基础上,一级从节点下面还可以拥有更多的从节点
使用主从模式就可以实现数据的读写分离,把写操作的请求分发到主节点上,把其他的读操作请求分发到从节点上,这样就减轻了 Redis 主节点的运行压力,并且提高了 Redis 的整体运行速度。不但如此使用主从模式还实现了 Redis 的高可用,当主服务器宕机之后,可以很迅速的把从节点提升为主节点,为 Redis 服务器的宕机恢复节省了宝贵的时间。并且主从复制还降低了数据丢失的风险,因为数据是完整拷贝在多台服务器上的,当一个服务器磁盘坏掉之后,可以从其他服务器拿到完整的备份数据。
6.3 哨兵模式
Redis 主从同步有那么多的优点,但是有一个致命的缺点,就是当 Redis 的主节点宕机之后,必须人工介入手动恢复,如果半夜突然发生主节点宕机的问题,此时如果等待人工去处理就会很慢,这个时候我们就需要用到 Redis 的哨兵模式了。
Redis 哨兵模式就是用来监视 Redis 主从服务器的,当 Redis 的主从服务器发生故障之后,Redis 哨兵提供了自动容灾修复的功能。
Redis哨兵模块存储在Redis应用根目录下的 src/redis-sentinel 目录下,我们可以使用命令./src/redis-sentinel sentinel.conf来启动哨兵功能。
工作原理:
哨兵的工作原理是每个哨兵会以每秒钟 1 次的频率,向已知的主服务器和从服务器,发送一个 PING 命令。如果最后一次有效回复 PING 命令的时间,超过了配置的最大下线时间(Down-After-Milliseconds)时,默认是 30s,那么这个实例会被哨兵标记为主观下线。如果一个主服务器被标记为主观下线,那么正在监视这个主服务器的所有哨兵节点,要以每秒 1 次的频率确认主服务器是否进入了主观下线的状态。如果有足够数量(quorum 配置值)的哨兵证实该主服务器为主观下线,那么这个主服务器被标记为客观下线。此时所有的哨兵会按照规则(协商)自动选出新的主节点服务器,并自动完成主服务器的自动切换功能,而整个过程都是无须人工干预的。
6.4 Redis 集群
Redis集群也就是 Redis Cluster,它是 Redis 3.0 版本推出的 Redis 集群方案,有多个主节点同时每个主节点有多个从节点,将数据分布在不同的主服务器上,以此来降低系统对单主节点的依赖,并且可以大大提高 Redis 服务的读写性能。Redis 集群除了拥有主从模式 + 哨兵模式的所有功能之外,还提供了多个主从节点的集群功能,实现了真正意义上的分布式集群服务。
Redis 集群可以实现数据分片服务,也就是说在 Redis 集群中有 16384 个槽位用来存储所有的数据,当我们有 N 个主节点时,可以把 16384 个槽位平均分配到 N 台主服务器上。当有键值存储时,Redis 会使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位,再把此键值存储在对应的服务器上,读取操作也是同样的道理,这样我们就实现了数据分片的功能。
参考资料:Redis是如何实现高可用的?
7 利用JDK,不依赖外部工具,实现一个简单的缓存机制
7.1 存储集合的选择
实现本地缓存,存储容器肯定是 key/value 形式的数据结构,在 Java 中,也就是我们常用的 Map 集合。Map 中有 HashMap、Hashtable、ConcurrentHashMap 几种供我们选择,如果不考虑高并发情况下数据安全问题,我们可以选择HashMap,如果考虑高并发情况下数据安全问题,我们可以选择 Hashtable、ConcurrentHashMap 中的一种集合,但是我们优先选择 ConcurrentHashMap,因为 ConcurrentHashMap 的性能比 Hashtable 要好。
7.2 过期缓存处理
因为缓存直接存储在内存中,如果我们不处理过期缓存,内存将被大量无效缓存占用,这不是我们想要的,所以我们需要清理这些失效的缓存。过期缓存处理可以参考 Redis 的策略来实现,Redis 采用的是定期删除 + 懒惰淘汰策略。
7.2.1 定期删除策略
定期删除策略是每隔一段时间检测已过期的缓存,并且降之删除。这个策略的优点是能够确保过期的缓存都会被删除。同时也存在着缺点,过期的缓存不一定能够及时的被删除,这跟我们设置的定时频率有关系,另一个缺点是如果缓存数据较多时,每次检测也会给 cup 带来不小的压力。
7.2.2 懒惰淘汰策略
懒惰淘汰策略是在使用缓存时,先判断缓存是否过期,如果过期将它删除,并且返回空。这个策略的优点是只有在查找的时候,才判断是否过期,对 CUP 影响较。同时这种策略有致命的缺点,当存入了大量的缓存,这些缓存都没有被使用并且已过期,都将成为无效缓存,这些无效的缓存将占用你大量的内存空间,最后导致服务器内存溢出。
我们简单的了解了一下 Redis 的两种过期缓存处理策略,每种策略都存在自己的优缺点。所以我们在使用过程中,可以将两种策略组合起来,结合效果还是非常理想的。
7.3 缓存淘汰策略
缓存淘汰跟过期缓存处理要区别开来,缓存淘汰是指当我们的缓存个数达到我们指定的缓存个数时,毕竟我们的内存不是无限的。如果我们需要继续添加缓存的话,我们就需要在现有的缓存中根据某种策略淘汰一些缓存,给新添加的缓存腾出位置,下面一起来认识几种常用的缓存淘汰策略。
7.3.1 先进先出策略
最先进入缓存的数据在缓存空间不够的情况下会被优先被清除掉,以腾出新的空间接受新的数据。该策略主要比较缓存元素的创建时间。在一些对数据实效性要求比较高的场景下,可考虑选择该类策略,优先保障最新数据可用。
7.3.2 最少使用策略
无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。该策略主要比较元素的hitCount(命中次数),在保证高频数据有效性场景下,可选择这类策略。
7.3.3 最近最少使用策略
无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。该策略主要比较缓存最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
7.3.4 随机淘汰策略
无论是否过期,随机淘汰某个缓存,如果对缓存数据没有任何要求,可以考虑使用该策略。
7.3.5 不淘汰策略
当缓存达到指定值之后,不淘汰任何缓存,而是不能新增缓存,直到有缓存淘汰时,才能继续添加缓存。
参考资料:实现 Java 本地缓存,该从这几点开始
8 Exception和Error的区别
Exception和Error都继承了Throwable类。
Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理;Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态
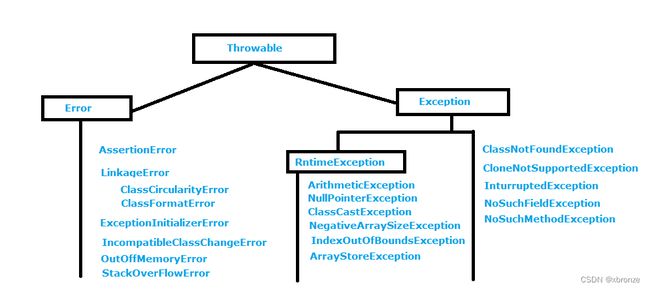
Exception 又分为cheked exception(检查异常) 和 unchecked exception(不检查异常)。
checked exception 指的是在源代码里必须处理的异常。例如:
- IOException
unchecked exception 指的是不用在源代码里处理,为运行时异常。例如:
- NullPointerException
- ClassCastException
绝大数的Error会导致程序处于非正常状态。例如:
- NoClassDefFoundError
- OutOfMemoryError
- StackOverflowError
参考资料:
《谈谈你对Exception 和 Error的理解》
《Exception和Error有什么区别吗》
9 设计模式
23种经典设计模式,设计模式的具逻辑和实现,可移步菜鸟教程了解。
9.1 创建型模式
这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。
- 工厂模式(Factory Pattern)
- 抽象工厂模式(Abstract Factory Pattern)
- 单例模式(Singleton Pattern)
- 建造者模式(Builder Pattern)
- 原型模式(Prototype Pattern)
9.2 结构型模式
这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式。
- 适配器模式(Adapter Pattern)
- 桥接模式(Bridge Pattern)
- 过滤器模式(Filter、Criteria Pattern)
- 组合模式(Composite Pattern)
- 装饰器模式(Decorator Pattern)
- 外观模式(Facade Pattern)
- 享元模式(Flyweight Pattern)
- 代理模式(Proxy Pattern)
9.3 行为型模式
这些设计模式特别关注对象之间的通信。
- 责任链模式(Chain of Responsibility Pattern)
- 命令模式(Command Pattern)
- 解释器模式(Interpreter Pattern)
- 迭代器模式(Iterator Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 观察者模式(Observer Pattern)
- 状态模式(State Pattern)
- 空对象模式(Null Object Pattern)
- 策略模式(Strategy Pattern)
- 模板模式(Template Pattern)
- 访问者模式(Visitor Pattern)
9.4 J2EE 模式
这些设计模式特别关注表示层。这些模式是由 Sun Java Center 鉴定的。
- MVC 模式(MVC Pattern)
- 业务代表模式(Business Delegate Pattern)
- 组合实体模式(Composite Entity Pattern)
- 数据访问对象模式(Data Access Object Pattern)
- 前端控制器模式(Front Controller Pattern)
- 拦截过滤器模式(Intercepting Filter Pattern)
- 服务定位器模式(Service Locator Pattern)
- 传输对象模式(Transfer Object Pattern)
10 一个线程调用两次start()方法会发生什么?简单谈谈线程的几种状态
10.1 调用两次start()
Java的线程是不允许启动两次的,第二次调用必然会抛岀IllegalThreadStateEXception,这是一种运行时异常,多次调用 start 被认为是编程错误。
10.2 线程的生命周期
- 新建(NEW),表示线程被创建出来还没真正启动的状态,可以认为它是个Java内部状态。
- 就绪( RUNNABLE),表示该线程已经在WM中执行,当然由于执行需要计算资源,它可能是正在运行,也可能还在等待系统分配给它cpu片段,在就绪队列里面排队。
- 运行(Running)在其他一些分析中,会额外区分一种状态 RUNNING,但是从 Java API的角度,并不能表示出来。
- 阻塞( BLOCKED),这个状态和我们前面两讲介绍的同步非常相关,阻塞表示线程在等待 Monitor lock。比如,线程试图通过synchronized去获取某个锁,但是其他线程已经独占了,那么当前线程就会处于阻塞状态。
- 等待( WAITING),表示正在等待其他线程釆取某些操作。一个常见的场景是类似生产者消费者模式,发现任务条件尚未满足,就让当前消费者线程等待(wait),另外的生产者线程去准备任务数据,然后通过类似 notify等动作,通知消费线程可以继续工作了。Thread join(也会令线程进入等待状态。
- 计时等待( TIMED_WAIT),其进入条件和等待状态类似,但是调用的是存在超时条件的方法,比如wait或join等方法的指定超时版本,如下面示例
public final native void wait(long timeout) throws InterruptedException;
- 终止( TERMINATED),不管是意外退出还是正常执行结束,线程已经完成使命,终止运行,也有人把这个状态叫作死亡在第二次调用 start()方法的时候,线程可能处于终止或者其他(非NEW)状态,但是不论如何,都是不可以再次启动的。
参考资料:https://cloud.tencent.com/developer/article/1625433
11 RocketMQ
RocketMQ是一个纯Java、分布式队列模型的消息中间件,具有高可用、高可靠、高实时、低延迟的特点。
11.1 消息中间件的通用功能
- 业务解耦:这也是发布订阅的消息模型。生产者发送指令到MQ中,然后下游订阅这类指令的消费者会收到这个指令执行相应的逻辑,整个过程与具体业务无关,抽象成了一个发送指令,存储指令,消费指令的过程。
- 前端削峰:前端发起的请求在短时间内太多后端无法处理,可以堆积在MQ中,后端按照一定的顺序处理,秒杀系统就是这么实现的。
11.2 RocketMQ的特点
- 亿级消息的堆积能力:单个队列中的百万级消息的累积容量。
- 高可用性
- 高可靠性
- 支持分布式事务消息
- 支持顺序消息:消息在Broker中是采用队列的FIFO模式存储的,也就是发送是顺序的,只要保证消费的顺序性即可。
- 支持消息过滤:建议采用消费者业务端的tag过滤。
- 支持定时消息和延迟消息
11.3 RocketMQ消息模型
Message
就是要传输的消息,一个消息必须有一个主题,一条消息也可以有一个可选的Tag(标签)和额外的键值对,可以用来设置一个业务的key,便于开发中在broker服务端查找消息。
Topic
主题,是消息的第一级类型,每条消息都有一个主题,就像信件邮寄的地址一样。主题就是我们具体的业务,比如一个电商系统可以有订单消息,商品消息,采购消息,交易消息等。Topic和生产者和消费者的关系非常松散,生产者和Topic可以是1对多,多对1或者多对多,消费者也是这样。
Tag
标签,是消息的第二级类型,可以作为某一类业务下面的二级业务区分,它的主要用途是在消费端的消息过滤。比如采购消息分为采购创建消息,采购审核消息,采购推送消息,采购入库消息,采购作废消息等,这些消息是同一Topic和不同的Tag,当消费端只需要采购入库消息时就可以用Tag来实现过滤,不是采购入库消息的tag就不处理。
Group
组,可分为ProducerGroup生产者组合ConsumerGroup消费者组,一个组可以订阅多个Topic。一般来说,某一类相同业务的生产者和消费者放在一个组里。
Message Queue
消息队列,一个Topic可以划分成多个消息队列。Topic只是个逻辑上的概念,消息队列是消息的物理管理单位,当发送消息的时候,Broker会轮询包含该Topic的所有消息队列,然后将消息发出去。有了消息队列,可以使得消息的存储可以分布式集群化,具有了水平的扩展能力。
offset
是指消息队列中的offset,可以认为就是下标,消息队列可看做数组。offset是java long,64位,理论上100年不会溢出,所以可以认为消息队列是一个长度无限的数据结构。
参考资料:RocketMq面试题精选
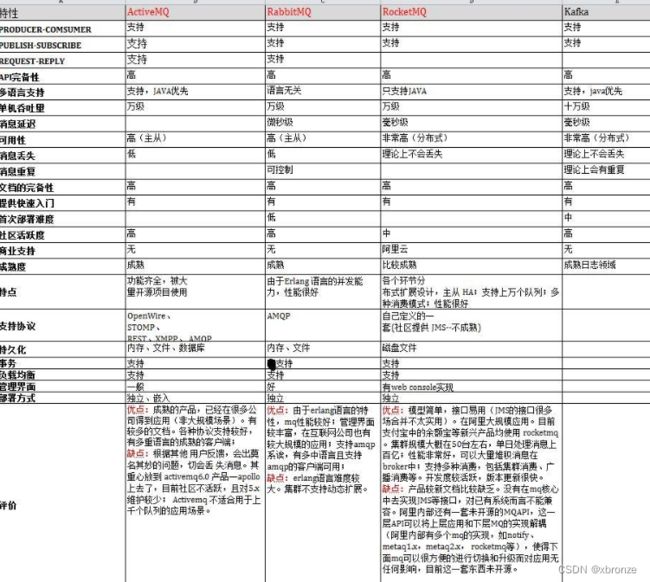
12 RocketMQ和其他消息中间件的区别
13 序列化和反序列化
13.1 什么是序列化和反序列化?
序列化:就是将对象转化成字节序列的过程。
反序列化:就是将字节序列转化成对象的过程。
对象序列化成的字节序列会包含对象的类型信息、对象的数据等,说白了就是包含了描述这个对象的所有信息,能根据这些信息“复刻”出一个和原来一模一样的对象。
13.2 为什么要序列化和反序列化?
- 持久化:对象是存储在JVM中的堆区的,但是如果JVM停止运行了,对象也不存在了。序列化可以将对象转化成字节序列,可以写进硬盘文件中实现持久化。在新开启的JVM中可以读取字节序列进行反序列化成对象。
- 网络传输:网络直接传输数据,但是无法直接传输对象,可在传输前序列化,传输完成后反序列化成对象。所以所有可在网络上传输的对象都必须是可序列化的。
13.3 实现序列化和反序列化的方法
Java为我们提供了对象序列化的机制,规定了要实现序列化对象的类要满足的条件和实现方法。
- 对于要序列化对象的类要去实现Serializable接口或者Externalizable接口。
- 实现方法:JDK提供的ObjectOutputStream和ObjectInputStream来实现序列化和反序列化。
13.4 serialVersionUID的作用
先讲述下序列化的过程:在进行序列化时,会把当前类的serialVersionUID写入到字节序列中(也会写入序列化的文件中),在反序列化时会将字节流中的serialVersionUID同本地对象中的serialVersionUID进行对比,一直的话进行反序列化,不一致则失败报错(报InvalidCastException异常)
serialVersionUID的生成有三种方式(private static final long serialVersionUID= XXXL ):
- 显式声明:默认的1L
- 显式声明:根据包名、类名、继承关系、非私有的方法和属性以及参数、返回值等诸多因素计算出的64位的hash值
- 隐式声明:未显式的声明serialVersionUID时java序列化机制会根据Class自动生成一个serialVersionUID(最好不要这样,因为如果Class发生变化,自动生成的serialVersionUID可能会随之发生变化,导致匹配不上)
序列化类增加属性时,最好不要修改serialVersionUID,避免反序列化失败
参考资料:一文搞懂序列化与反序列化
14 Dubbo和SpringCloud核心组件Feign、Ribbin、Hystrix对比
14.1 协议
Dubbo:支持多传输协议:Dubbo、Rmi、http,可灵活配置。
Feign:基于http传输协议,短连接,性能比Dubbo低。
14.2 与SpringCloud集成
Dubbo:在早期Dubbo是与Spring Cloud 集成有一些脱落,但是在Spring Cloud Alibaba 出现后,spring-cloud-starter-dubbo 与Spring Cloud完美集成
Feign:Spring Cloud 最早支持的RPC框架,兼容性好
14.3 负载均衡
Dubbo内置了如下负载均衡算法,用户可直接配置使用:
| 算法 | 特性 | 备注 |
|---|---|---|
| RandomLandBalance | 加权随机 | 默认算法,默认权重相同 |
| RoundRobinLoadBalance | 加权轮询 | 借鉴与Nginx的平滑加权轮询算法,默认权重相同 |
| LeastActiveLoadBalance | 最少活跃优先+加权随机 | 背后是能者多劳的思想 |
| ShortestResponseLoadBalance | 最短响应优先+加权随机 | 更加关注响应速度 |
| ConsistentHashLoadBalance | 一致性Hash | 确定的入参,确定的提供者,适用于有状态的请求 |
同时支持服务端负载均衡和客户端负载均衡配置,灵活度非常高
Fegin自身是没有负载均衡能力的,之前默认使用Ribbon作为负载均衡的组件,但是Netfix已经不再维护。新版本的Spring Cloud已经将Ribbon替换成Spring Cloud Load Balancer,Ribbon是客户端级别的负载均衡,不像dubbo支持客户端和服务端双向配置
14.4 容错机制
Dubbo支持多种容错策略:
- Failover Cluste:失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数(不含第一次)。默认容错机制
- Failfast Cluster:快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster:失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback Cluster :失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster:并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
- Broadcast Cluster:广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
Feign
Feign默认使用Netfix Hystrix作为服务熔断的组件。Hystix提供了服务降级,服务熔断,依赖隔离,监控(Hystrix Dashboard)等功能。
目前 Hystrix 已经处于维护(maintenance)状态,不再继续开发,这个消息是Netfix 在2018年对外宣布的。Hystrix GitHub页面上也说明了该项目目前处于维护模式
在使用dubbo后续的熔断降级也还可以使用Alibaba Sentinel
14.5 迁移
Dubbo
dubbo为了提供对RestTemplate和OpenFeign客户端端的支持,在Dubbo Spring Cloud提供了@DubboTransported注解,使客户端无需额外处理即可兼容RestTemplate和OpenFeign的调用,换而言之在不调整 Feign 接口以及 RestTemplate URL 的前提下,可以实现无缝迁移
比如在客户端使用OpenFeign调用duboo服务,只需要添加如下注解如下
@FeignClient("order")
@DubboTransported(protocol = "dubbo")
使用RestTemplate或OpenFeign调用Dubbo服务会经历以下过程:
- 根据服务名得到注册中心的Dubbo服务DubboMetadataService。
- 使用DubboMetadataService里提供的getServiceRestMetadata方法获取要使用的Dubbo服务和对应的Rest元数据。
- 基于Dubbo服务和Rest元数据构造GenericService。
- 服务调用过程中使用GenericService发起泛化调用。
Feign
没有提供对dubbo无缝迁移的支持
参考资料:Spring Cloud RPC(Feign VS Dubbo)多维度对比选型
15 线程的创建方式
15.1 继承Thread类
public class App {
public static void main(String[] args){
new ThreadObject().start();
}
static class ThreadObject extends Thread {
@Override
public void run() {
System.out.println("current thread name is :" + Thread.currentThread().getName());
}
}
}
15.2 实现Runnable接口
public class App {
public static void main(String[] args){
Thread thread = new Thread(new RunnableObject());
thread.start();
}
static class RunnableObject implements Runnable {
@Override
public void run() {
System.out.println("current thread name is :" + Thread.currentThread().getName());
}
}
}
15.3 实现Callable接口
public class App {
public static void main(String[] args) {
//执行Callable方式,需要FutureTask实现,用于接收运算结果
FutureTask<Integer> futureTask = new FutureTask<Integer>(new CallableObject());
new Thread(futureTask).start();
try {
// 获取线程执行完毕后的返回值
Integer sum = futureTask.get();
System.out.println("sum is :" + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// Callable泛型定义返回值的类型
static class CallableObject implements Callable<Integer> {
public Integer call() throws Exception {
Integer sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
return sum;
}
}
}
15.4 基于线程池创建
public class App {
public static void main(String[] args) {
//创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
for(int i = 0 ; i < 10 ; i++) {
//调用execute()方法创建线程
//采用匿名内部类的方法,创建Runnable对象,并重写run()方法
threadPool.execute(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
}
// 关闭线程池
threadPool.shutdown();
}
}
未完,待续…