时间序列数据的采样和画图
时间序列数据的采样和画图
- 时间序列数据的采样和画图
-
- 引入相关库
- 时间序列数据的采样
- 时间序列数据的画图
时间序列数据的采样和画图
引入相关库
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
时间序列数据的采样
使用date_range创建一个datetime对象,从2016-01-01开始,以天为间隔,一共366天
t_range=pd.date_range('2016-01-01','2016-12-31')
t_range
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06', '2016-01-07', '2016-01-08',
'2016-01-09', '2016-01-10',
...
'2016-12-22', '2016-12-23', '2016-12-24', '2016-12-25',
'2016-12-26', '2016-12-27', '2016-12-28', '2016-12-29',
'2016-12-30', '2016-12-31'],
dtype='datetime64[ns]', length=366, freq='D')
以该datetime对象作为index,创建一个Series,长度也为366
s1=Series(np.random.randn(len(t_range)),index=t_range)
s1
2016-01-01 1.406461
2016-01-02 0.447931
2016-01-03 1.699394
2016-01-04 0.788757
2016-01-05 -0.232023
...
2016-12-27 -0.247121
2016-12-28 0.673201
2016-12-29 0.091558
2016-12-30 -1.163763
2016-12-31 0.482879
Freq: D, Length: 366, dtype: float64
s1
2016-01-01 1.406461
2016-01-02 0.447931
2016-01-03 1.699394
2016-01-04 0.788757
2016-01-05 -0.232023
...
2016-12-27 -0.247121
2016-12-28 0.673201
2016-12-29 0.091558
2016-12-30 -1.163763
2016-12-31 0.482879
Freq: D, Length: 366, dtype: float64
s1['2016-01']
2016-01-01 1.406461
2016-01-02 0.447931
2016-01-03 1.699394
2016-01-04 0.788757
2016-01-05 -0.232023
2016-01-06 0.348905
2016-01-07 -0.236980
2016-01-08 0.161807
2016-01-09 0.218637
2016-01-10 1.672460
2016-01-11 0.983214
2016-01-12 0.044190
2016-01-13 -0.620090
2016-01-14 0.101304
2016-01-15 1.801919
2016-01-16 1.624366
2016-01-17 0.672093
2016-01-18 1.475754
2016-01-19 0.582916
2016-01-20 -0.284506
2016-01-21 -1.634910
2016-01-22 0.000536
2016-01-23 -2.254585
2016-01-24 0.261707
2016-01-25 -0.320744
2016-01-26 -0.173244
2016-01-27 0.544120
2016-01-28 0.059852
2016-01-29 0.479251
2016-01-30 0.857616
2016-01-31 -0.815376
Freq: D, dtype: float64
s1['2016-01'].mean()
0.3116365177410832
把该Series采样,变成十二个月的数据,可以通过mean来算取每个月的评估值,一共十二个月,得到采样Series的大小为12,采样方法可以使用resample方法为按月进行采样。
s1_month=s1.resample('M').mean()
s1_month
2016-01-31 0.311637
2016-02-29 -0.055687
2016-03-31 0.152305
2016-04-30 0.058371
2016-05-31 -0.102482
2016-06-30 -0.164970
2016-07-31 -0.298555
2016-08-31 0.041087
2016-09-30 0.216605
2016-10-31 0.137500
2016-11-30 -0.269811
2016-12-31 -0.038291
Freq: M, dtype: float64
s1_month.index
DatetimeIndex(['2016-01-31', '2016-02-29', '2016-03-31', '2016-04-30',
'2016-05-31', '2016-06-30', '2016-07-31', '2016-08-31',
'2016-09-30', '2016-10-31', '2016-11-30', '2016-12-31'],
dtype='datetime64[ns]', freq='M')
把resample方法改成按小时采样,由于原始数据一天只有一个数据点,所以变成按小时采样需要填充数据填满24个小时,ffill填充方法为使用一天的这个数据点往前填充,填充24小时
s1.resample('H').ffill()
2016-01-01 00:00:00 1.406461
2016-01-01 01:00:00 1.406461
2016-01-01 02:00:00 1.406461
2016-01-01 03:00:00 1.406461
2016-01-01 04:00:00 1.406461
...
2016-12-30 20:00:00 -1.163763
2016-12-30 21:00:00 -1.163763
2016-12-30 22:00:00 -1.163763
2016-12-30 23:00:00 -1.163763
2016-12-31 00:00:00 0.482879
Freq: H, Length: 8761, dtype: float64
bfill方法的填充数据来自下一天即2016-01-02的数据
s1.resample('H').bfill()
2016-01-01 00:00:00 1.406461
2016-01-01 01:00:00 0.447931
2016-01-01 02:00:00 0.447931
2016-01-01 03:00:00 0.447931
2016-01-01 04:00:00 0.447931
...
2016-12-30 20:00:00 0.482879
2016-12-30 21:00:00 0.482879
2016-12-30 22:00:00 0.482879
2016-12-30 23:00:00 0.482879
2016-12-31 00:00:00 0.482879
Freq: H, Length: 8761, dtype: float64
时间序列数据的画图
使用date_range再创建一个datetime,从2016-01-01到2016-12-31以每小时为单位,长度为8761
t_range=pd.date_range('2016-01-01','2016-12-31',freq='H')
t_range
DatetimeIndex(['2016-01-01 00:00:00', '2016-01-01 01:00:00',
'2016-01-01 02:00:00', '2016-01-01 03:00:00',
'2016-01-01 04:00:00', '2016-01-01 05:00:00',
'2016-01-01 06:00:00', '2016-01-01 07:00:00',
'2016-01-01 08:00:00', '2016-01-01 09:00:00',
...
'2016-12-30 15:00:00', '2016-12-30 16:00:00',
'2016-12-30 17:00:00', '2016-12-30 18:00:00',
'2016-12-30 19:00:00', '2016-12-30 20:00:00',
'2016-12-30 21:00:00', '2016-12-30 22:00:00',
'2016-12-30 23:00:00', '2016-12-31 00:00:00'],
dtype='datetime64[ns]', length=8761, freq='H')
创建一个空的DataFrame,以datetime作为index
stock_df=DataFrame(index=t_range)
stock_df.head()
| 2016-01-01 00:00:00 |
|---|
| 2016-01-01 01:00:00 |
| 2016-01-01 02:00:00 |
| 2016-01-01 03:00:00 |
| 2016-01-01 04:00:00 |
创建一个columns,作为阿里巴巴的股票,从数值范围为80-160,长度为8761
stock_df['BABA']=np.random.randint(80,160,size=len(t_range))
stock_df.head()
| BABA | |
|---|---|
| 2016-01-01 00:00:00 | 84 |
| 2016-01-01 01:00:00 | 80 |
| 2016-01-01 02:00:00 | 111 |
| 2016-01-01 03:00:00 | 159 |
| 2016-01-01 04:00:00 | 94 |
创建一个腾讯的股票,数值范围为30-50
stock_df['TENCENT']=np.random.randint(30,50,size=len(t_range))
stock_df.head()
| BABA | TENCENT | |
|---|---|---|
| 2016-01-01 00:00:00 | 84 | 33 |
| 2016-01-01 01:00:00 | 80 | 42 |
| 2016-01-01 02:00:00 | 111 | 48 |
| 2016-01-01 03:00:00 | 159 | 39 |
| 2016-01-01 04:00:00 | 94 | 49 |
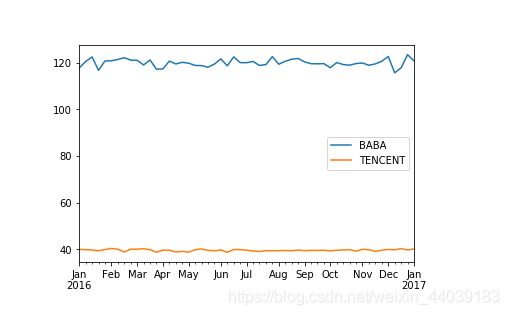
对这个两列的DataFrame画图,创建一个matplotlib里面的图,这个图蓝线表示阿里,黄线表示腾讯,但是由于点太多比较拥挤
stock_df.plot()

如果上述方法显示不出图片的解决方法
import matplotlib.pyplot as plt
plt.show()
对DataFrame重新采样,变成每周一个点
weekly_df=DataFrame()
对阿里巴巴的值按每周重新采样
weekly_df['BABA']=stock_df['BABA'].resample('W').mean()
对腾讯的值按每周重新采样
weekly_df['TENCENT']=stock_df['TENCENT'].resample('W').mean()
weekly_df.head()
| BABA | TENCENT | |
|---|---|---|
| 2016-01-03 | 117.708333 | 39.916667 |
| 2016-01-10 | 120.476190 | 39.767857 |
| 2016-01-17 | 122.428571 | 39.636905 |
| 2016-01-24 | 116.702381 | 39.297619 |
| 2016-01-31 | 120.708333 | 39.839286 |
展示曲线,可以清楚的看到两条线
weekly_df.plot()
上面方法不能显示的解决办法
plt.show()