如何对数据库进行优化
数据库是什么?
简单来说数据库就是将数据按照一定顺序存储到磁盘上的一个软件,我们平时写的sql语句,就是用数据库软件能识别的语言,对数据进行增删改查。其实数据本质上是不存在表里,而是存在磁盘上,所谓的表只是数据存储空间的名字。
如何优化
数据库优化的底层逻辑,就是优化cpu从磁盘读写数据的时间,一般降低时间有两种方式,一种是提高速度,第二种是缩短路程。
一、提高数据的读写速度:
改变硬件配置:
可以通过更换更加高端的cpu,频率更高的内存,把机械硬盘换成更好的固态硬盘。
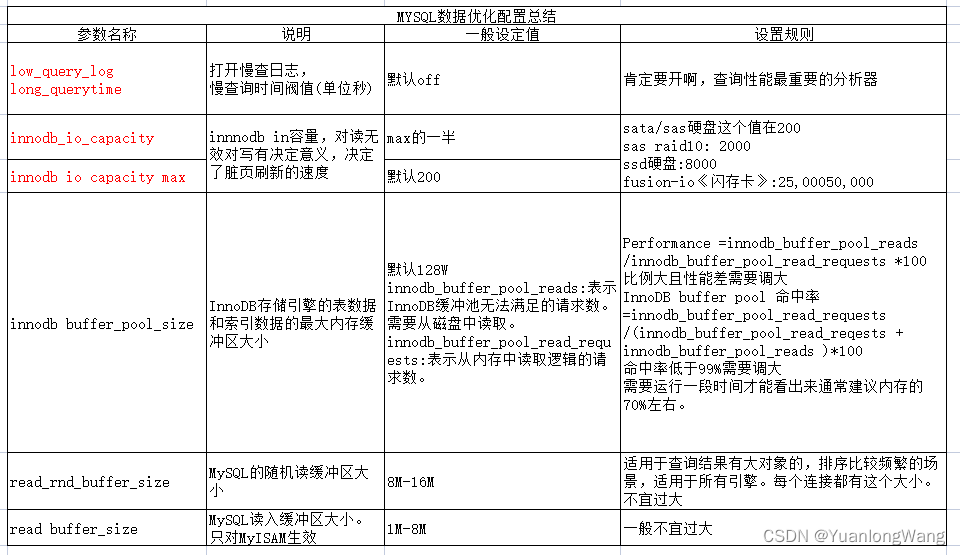
硬件升级后还不够,还需要更改数据库的配置文件,让数据库能体会到硬件的变化,采用更加激进的策略去读取数据,对于mysql来说,可用 innodb 的下面这两个参数来配置:
innodb_io_capacity,innodb_io_capacity_max 控制的是 innodb 刷脏页的能力。
过小会导致 mysql 刷脏页能力不足,影响性能。过大会让 mysql 认为 io 能力很强,会造成 io 尖峰。
nnodb_io_capacity
参数定义了InnoDB后台任务每秒可用的I/O操作数(IOPS),例如用于从buffer pool中刷新脏页和从change buffer中合并数据。
innodb后台进程最大的I/O性能指标,影响刷新赃页和插入缓冲的数量,在高转速磁盘下,尤其是现在SSD盘得到普及,可以根据需要适当提高该参数的值。
在压力下,控制当刷新脏数据时MySQL每秒执行的写IO量
解释一下什么叫“在压力下”,MySQL中称为”紧急情况”,是当MySQL在后台刷新时,它需要刷新一些数据为了让新的写操作进来。然后,MySQL会用到innodb_io_capacity_max。
那么,应该如何设置innodb_io_capacity和innodb_io_capacity_max呢?
最好的方法是测量你的存储设置的随机写吞吐量,然后给innodb_io_capacity_max设置为你的设备能达到的最大IOPS。innodb_io_capacity就设置为它的50-75%,特别是你的系统主要是写操作时。
另外一点就是增加mysql缓冲池的大小,mysql很多时候不会直接读写磁盘的数据,会根据自己的算法,通过缓冲池缓存磁盘的数据到内存中,来提高查询效率,还会根据淘汰算法,来更新缓存中的冷热数据,保证缓存的命中率。
需要注意的一点是缓冲池大小参数不是越高越好,一般要通过不断测试调整来得到一个合适的结果。例如通过调大innodb_io_capacity的参数,虽然脏页刷新的速度得到了提升,但是刷新脏页会阻塞该页的数据访问,过多无意义的刷新也会增加cpu的负担。
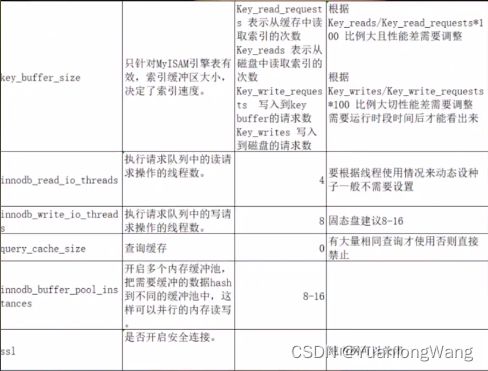
下面列出了mysql数据优化配置常用参数:
二、通过缩短查询路程达到优化的效果:
1、索引
缩短路程的关键点就是索引,建立好合适的索引能显著提高查询速度。
如果不太了解索引的同学可以看下:MySQL索引15连问,你能坚持到第几问?_YuanlongWang的博客-CSDN博客
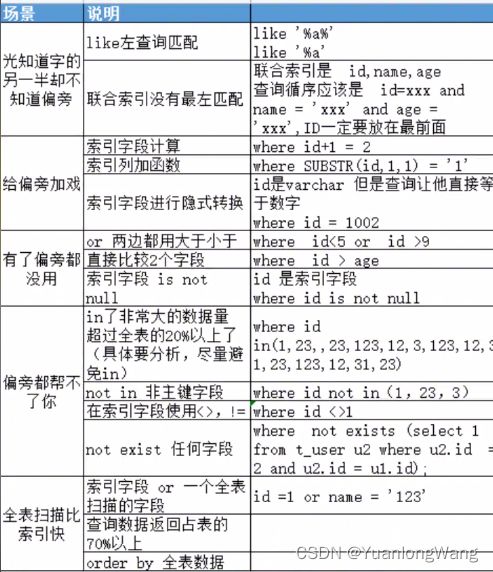
当然在写sql的时候要尽量避免索引失效导致全表扫描,什么情况下会导致索引失效,下面列出了一个表给大家参考:
2、SQL语句优化
1)尽量少 join。MySQL 的优势在于简单,但这在某些方面其实也是其劣势。MySQL优化器效率高,但是由于其统计信息的量有限,优化器工作过程出现偏差的可能性也就更多。对于复杂的多表 Join,一方面由于其优化器受限,再者在Join这方面所下的功夫还不够,所以性能表现离Oracle等关系型数据库前辈还是有一定距离。但如果是简单的单表查询,这一差距就会极小甚至在有些场景下要优于这些数据库前辈。
2)尽量少排序。排序操作会消耗较多的 CPU 资源,所以减少排序可以在缓存命中率高等 IO 能力足够的场景下会较大影响 SQL的响应时间。
3)尽量避免 select *,并尽量用join代替子查询
4)尽量少使用“or”关键字。当 where 子句中存在多个条件以“或”并存的时候,MySQL 的优化器并没有很好的解决其执行计划优化问题,再加上 MySQL 特有的 SQL 与 Storage 分层架构方式,造成了其性能比较低下,很多时候使用 union all 或者是union(必要的时候)的方式来代替“or”会得到更好的效果。
6)尽量用 union all 代替 union。union 和 union all 的差异主要是前者需要将两个(或者多个)结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的 CPU 运算,加大资源消耗及延迟。所以当我们可以确认不可能出现重复结果集或者不在乎重复结果集的时候,尽量使用 union all 而不是 union。
7)避免类型转换
8)能用DISTINCT的就不用GROUP BY
9)尽量不要用SELECT INTO语句
10)从全局出发优化,而不是片面调整。SQL 优化不能是单独针对某一个进行,而应充分考虑系统中所有的 SQL,尤其是在通过调整索引优化 SQL的执行计划的时候,千万不能顾此失彼,因小失大。
3、表结构优化
MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大,那么每次 IO 可访问的行数也就增多了。反过来说,处理相同行数的数据,需要访问的 page 就会减少,也就是 IO 操作次数降低,直接提升性能。
数据类型选择
原则是:数据行的长度不要超过8020字节,如果超过这个长度的话在物理页中这条数据会占用两行从而造成存储碎片,降低查询效率;字段的长度在最大限度的满足可能的需要的前提下,应该尽可能的设得短一些,这样可以提高查询的效率,而且在建立索引的时候也可以减少资源的消耗。 ? ?
1)数字类型:非万不得已不要使用DOUBLE,不仅仅只是存储长度的问题,同时还会存在精确性的问题。同样,固定精度的小数,也不建议使用DECIMAL,建议乘以固定倍数转换成整数存储,可以大大节省存储空间,且不会带来任何附加维护成本。
2)字符类型:定长字段,建议使用 CHAR 类型(char查询快,但是耗存储空间,可用于用户名、密码等长度变化不大的字段),不定长字段尽量使用 VARCHAR(varchar查询相对慢一些但是节省存储空间,可用于评论等长度变化大的字段),且仅仅设定适当的最大长度,而不是非常随意的给一个很大的最大长度限定,因为不同的长度范围,MySQL也会有不一样的存储处理。
3)时间类型:尽量使用TIMESTAMP类型,因为其存储空间只需要DATETIME 类型的一半。对于只需要精确到某一天的数据类型,建议使用DATE类型,因为他的存储空间只需要3个字节,比TIMESTAMP还少。不建议通过INT类型类存储一个unix timestamp 的值,因为这太不直观,会给维护带来不必要的麻烦,同时还不会带来任何好处。
4)ENUM &SET:对于状态字段,可以尝试使用 ENUM 来存放,因为可以极大的降低存储空间,而且即使需要增加新的类型,只要增加于末尾,修改结构也不需要重建表数据。
字符编码
字符集直接决定了数据在MySQL中的存储编码方式,由于同样的内容使用不同字符集表示所占用的空间大小会有较大的差异,所以通过使用合适的字符集,可以帮助我们尽可能减少数据量,进而减少IO操作次数。
尽量使用 NOT NULL
NULL 类型比较特殊,SQL 难优化。虽然 MySQL NULL类型和 Oracle 的NULL有差异,会进入索引中,但如果是一个组合索引,那么这个NULL 类型的字段会极大影响整个索引的效率。虽然 NULL空间上可能确实有一定节省,倒是带来了很多其他的优化问题,不但没有将IO量省下来,反而加大了SQL的IO量。所以尽量确保 DEFAULT 值不是 NULL,也是一个很好的表结构设计优化习惯。
4.数据库架构优化
分布式和集群化
1)负载均衡。负载均衡集群是由一组相互独立的计算机系统构成,通过常规网络或专用网络进行连接,由路由器衔接在一起,各节点相互协作、共同负载、均衡压力,对客户端来说,整个群集可以视为一台具有超高性能的独立服务器。MySQL一般部署的是高可用性负载均衡集群,具备读写分离,一般只对读进行负载均衡。
2)读写分离。读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提供读操作,其实在很多系统中,主要是读的操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。
3)数据切分。通过某种特定的条件,将存放在同一个数据库中的数据分散存放到多个数据库上,实现分布存储,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。