瑞吉外卖【笔记】
文章目录
- 一、软件开发整体介绍
-
- 1、软件开发流程
- 2、角色分工
- 3、软件环境
- 二、瑞吉外卖项目开发
-
- 1、分期开发
- 2、技术选型
- 3、功能架构
- 4、角色
- 5、开发环境搭建
- 三、瑞吉外卖代码开发
-
- 1、mybaits-plus
- 2、通用返回类
- 3、登录登出功能
- 4、全局异常处理器
- 5、分页查询
- 6、消息转换器
- 7、公共字段自动填充
- 8、业务异常类
- 9、文件上传下载
- 10、一个分页查询的逻辑
- 11、短信验证
- 12、批量删除
- 13、批量起售\停售
- 14、减少订购量
- 15、结算逻辑
- 16、订单显示逻辑
- 17、linux
-
- 17.1、网路设置
- 17.2、安装jdk
- 17.3、安装tomcat
- 17.4、安装mysql
- 17.5、安装lrzsz
- 18、项目部署
-
- 18.1、手工部署
- 18.2、通过Shell脚本自动部署项目
- 四、redis基础
-
- 1、入门和应用场景
- 2、下载和安装
- 3、Redis服务启动与停止
- 4、设置密码
- 5、远程连接
- 6、Redis数据类型
-
- 6.1、字符串常用命令
- 6.2、哈希hash操作命令
- 6.3、列表list操作命令
- 6.4、集合set操作命令
- 6.5、有序集合sorted set 操作命令
- 6.6、redis常用命令
- 7、Jedis
- 8、Spring Data Redis
-
- 8.1、String类型常用方法
- 8.2、Hash类型常用方法
- 8.3、List类型常用方法
- 8.4、set类型常用方法
- 8.5、Zset类型常用方法
- 8.6、通用方法
- 五、缓存优化
-
- 1、使用git管理项目
- 2、环境搭建
-
- 2.1、maven坐标
- 2.2、配置yml文件
- 2.3、增加一个配置类RedisConfig
- 3、缓存短信验证码
- 4、缓存菜品数据
- 5、清理缓存
- 6、Spring Cache
-
- 6.1、CachePut注解
- 6.2、CacheEvict注解
- 6.3、Cacheable注解
- 6.4、使用Redis作为缓存产品
- 7、缓存套餐数据
- 六、读写分离
-
- 1、MySql主从复制
- 2、配置
- 3、读写分离案例
- 4、项目实现读写分离
- 七、Nginx
-
- 1、概述
- 2、Nginx下载和安装
- 3、Nginx目录结构
- 4、nginx常用命令
- 5、Nginx配置文件结构
- 6、Nginx具体应用
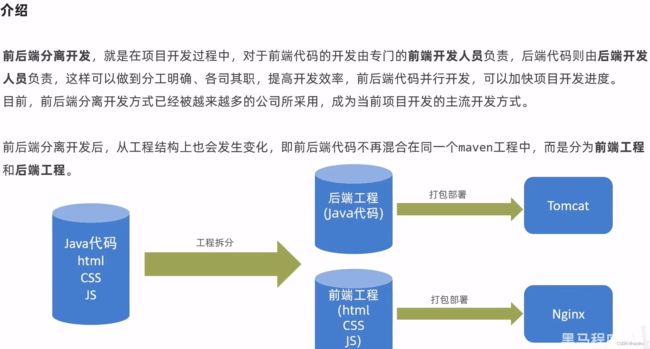
- 八、前后端分离开发
-
- 1、YApi
- 2、Swagger
- 九、项目部署
-
- 1、环境准备
- 2、部署前端项目(服务器A)
- 3、部署后端项目(服务器B)
黑马项目瑞吉外卖,记录一些学习中我遇到的问题和学习到的东西
我的完整代码:https://gitee.com/lzy612/reggie
一、软件开发整体介绍
记录这块的原因是我感觉我找工作的时候,需要知道这些知识,所以记录一下
1、软件开发流程
- 需求分析:产品原型、需求规格说明书
- 设计:产品文档、UI界面设计、概要设计、详细设计、数据库设计
- 编码:项目代码、单元测试
- 测试:测试用例、测试报告
- 上线运维:软件环境安装、配置
我估计找工作就是先找的编码这块的东西
2、角色分工
- 项目经理:对整个项目负责、任务分配、把控进度
- 产品经理:进行需求调研、输出需求调研文档、产品原型
- UI设计师:根据产品原型输出界面效果图
- 架构师:项目整体架构设计、技术选型
- 开发工程师:代码实现
- 测试工程师:编写测试用例,输出测试报告
- 运维工程师:软件环境搭建、项目上线
3、软件环境
- 开发环境(development):开发人员在开发阶段使用的环境,一般外部用户无法访问
- 测试环境(testing):专门给测试人员使用的环境,用于测试项目,一般外部用户无法访问
- 生产环境(production):即线上环境,正式提供对外服务的环境
这块我在做其他项目的时候,遇到过,那个是把一些在不同环境下使用的url写成一些配置文件
二、瑞吉外卖项目开发
1、分期开发
- 第一期:实现基本需求,其中移动端应用通过H5实现,用户可以通过手机浏览器访问
- 第二期:针对移动端应用进行改进,使用微信小程序实现,用户使用起来更加方便
- 第三期:针对系统进行优化升级,提高系统的访问性能
这东西就和我学的东西有关了,我尽量做到
2、技术选型
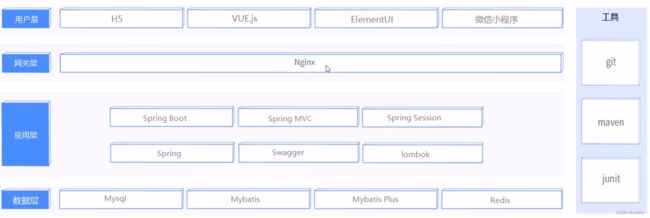
Spring Session 和 Nginx 、Redis不怎么了解,顺便学一下
3、功能架构

4、角色
- 后台系统管理员:登录后台管理系统,拥有后台系统中的所有操作权限
- 后台系统普通员工:登录后台管理系统,对菜品、套餐、订单等进行管理
- C端用户:登录移动端应用,可以浏览菜品、添加购物车、设置地址、在线下单
5、开发环境搭建
数据库
使用图形化界面就直接执行sql文件就可以了,但是使用命令行的时候,最好不要在source sql文件的时候路径中携带中文,否则就会报错


这里用到了关系表,也就是那个中间表,之前遇见过几次,感觉是很有用的
maven项目搭建
主要的还是配置一些坐标,还有springboot的启动,这里还有一点就是对静态资源的放行,之前没有了解过,之前学的是下面这样子的
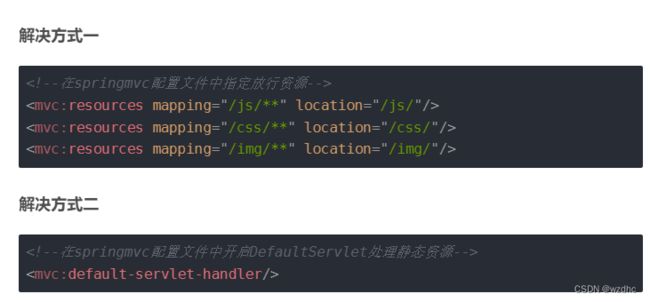
springbootApplication
@Slf4j
@SpringBootApplication
public class ReggieApplication {
public static void main(String[] args) {
SpringApplication.run(ReggieApplication.class, args);
log.info("项目启动成功....");
}
}
WebMvcConfig
@Slf4j
@Configuration
public class WebMvcConfig extends WebMvcConfigurationSupport {
/*
* 设置静态资源映射
* */
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始进行静态资源映射");
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/"); registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
}
}
人家这里是这样子的
我看过的那些视频,无论是javaweb还是是ssm的东西,那些讲师都是先简单的创建一个maven工程,然后加坐标,改造,从来也没有用过idea自动生成的,难道这就是标准吗?我去查了一下,我看到有人推荐的是使用idea快速创建,我感觉也都差不多,反正都了解一下,技多不压身
这里参考的文章`https://blog.csdn.net/Huang_ZX_259/article/details/122105162
三、瑞吉外卖代码开发
我不想去做一些关于源码的笔记了,感觉繁琐,而且没啥大用,我在这里就写一些我自己的一些比较疑惑的东西,学习到的东西
1、mybaits-plus
之前写过一个使用了这个东西的项目,感觉很好用,都不用写sql语句了,都给你弄好了,这次这个我又发现Iservice接口,也是挺神奇的,还是要具体的学习一下这个东西,我发现那个文档也挺不错的,我等的去试试看看,如果不行的话就去看教学视频
欠缺的知识
IServiceLambdaQueryWrapper(之前就见到过QuerryWarpper)公共字段填充还能自定义service方法,来写一些逻辑
2、通用返回类
为了方便与前后端分离程序之间的交互,需要设计一个通用的返回类,我觉的这个东西的实用性应该很高的,留个心眼
参考文章:https://www.cnblogs.com/CF1314/p/13686123.html#_label1
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
3、登录登出功能
- 登录
视频中给出的具体逻辑如下:
1、将页面提交的密码password进行md5加密处理
2、根据页面提交的用户名username查询数据库
3、判断有没有查询到数据
4、密码比对,如果不一致则返回登录失败结果
5、查看员工状态,如果为已禁用状态,则返回员工已禁用结果
6、等录成功,将员工id存入Session并返回登录成功结果
这里前端还把登录成功的用户信息存储到LocalStorage中去了
之前也做过一个用MD5加密的登录方式,那个的逻辑:
- 获取到username然后进行数据库查询
- 判断是否查询到该用户
- 进行密码比对,把查询出的密码和传过来的密码放到一个MD5工具类中的验证方法
- 如果验证成功就将该用户的id和一段用UUID生成的字符串access_token存放到session中
看到这个我又想起来了我之前了解过JWT验证方式,没怎么学,就跟着人家敲了敲代码,感觉这个token和第二种的方式有点相似,这得了解一下,这个登录逻辑中还用到了一些我没有见过的LambdaQueryWrapper和一个DisgestUtis的工具类,也是学习到的点
- 登出
登出逻辑
- 清除掉session中的用户存储的数据
- 删除掉浏览器中在LocalStorage中存储的数据
- 完善登录功能
为了避免不通过登录页面直接进入首页的情况,可以使用过滤器或者拦截器的方式来进行处理
过滤器:
实现步骤:
- 创建自定义过滤器
LoginCheckFilter - 在启动类上加入注解
@ServletComponentScan - 完善过滤器的处理逻辑
实现逻辑
- 获取本次请求的URL
- 判断本次请求是否需要处理
- 如果不需要处理,则直接放行
- 判断登录状态,如果已登录,则直接放行
- 如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据
/*
* 检查用户是否已经完成登录
* */
@WebFilter(filterName = "loginCheckFilter", urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
// 路径匹配器
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest)servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
// 1、获取本次请求的URL
// 定义不需要处理的请求路径
String requestURL = request.getRequestURI();
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
// 2、判断本次请求是否需要处理
boolean check = check(urls, requestURL);
// 3、如果不需要处理,则直接放行
if(check){
filterChain.doFilter(request, response);
return;
}
// 4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee") != null){
filterChain.doFilter(request, response);
return;
}
// 5、如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 路径匹配
* @param urls
* @param requestURL
* @return
*/
public boolean check(String[] urls, String requestURL){
for (String url : urls) {
boolean match = PATH_MATCHER.match(url, requestURL);
if(match){
return true;
}
}
return false;
}
}
这里还了解到了一个专门用于匹配路由的工具类
AntPathMatcher
拦截器
思路:自定义了一个拦截器,然后加上了@Compont注解,内容就是如果session中能判断employee不为空,就不拦截,然后我去注册了拦截器,和那个访问资源的一个类中,然后我拦截了所有的路径,然后将login.html还有那个login和logout和一些样式的资源放行了,然后倒头来,只能访问一下login登录页面,然后退出了再访问就是一些json数据直接打印到屏幕上了,淦
我想尝试使用拦截器来完成登录的优化,可惜水平不够完成不了,遇到下面好几个问题
- 返回json数据错误,直接把json格式的数据打到了屏幕上,它不会通过request.js然后进行页面跳转
- 比如我登录后退出掉了,然后session中的那个session应该是删除掉了,但是我再访问index.html的时候,还是直接可以访问,我感觉这就违反了我使用这个拦截器的初心了
- 还有我调试的时候,发现好像重复的拦截了好几次,不知道这个怎么搞的
因为我没有系统的学过springboot,只知道什么约定大于配置一点点知识,看到了这个我就想自己实现一下,看来还是有好大的坑,等的再说吧,不能老在一棵树上吊死
4、全局异常处理器
问题引出:
对程序进行异常捕获,通常有两种方式,一个是使用try,catch进行异常捕获,一个是使用异常处理类进行全局异常捕获,第一种如果量少的话,还可以,但是量大的话,岂不是要写一堆try、catch语句。所以引出了全局异常处理器,头一次听过这个
// 像是一个通知类型的注解,后面的参数写上要处理异常的部分
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExpcetionHandler {
/**
* 异常处理方法
* @return
*/
// 这个是违反唯一性约束的异常
@ExceptionHandler(SQLIntegrityConstraintViolationException.class)
public R<String> exceptionHandler(SQLIntegrityConstraintViolationException ex){
log.info(ex.getMessage());
if(ex.getMessage().contains("Duplicate entry")){
String[] split = ex.getMessage().split(" ");
String msg = split[2] + "已存在";
return R.error(msg);
}
return null;
}
}
5、分页查询
之前见过一些其他的分页的插件,视频中使用的是一个mybatisplus的一个分页插件
操作步骤
/**
* 配置MP的分页插件
*/
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
// 一个拦截器?
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
先搞一个配置类
@GetMapping ("/page")
public R<Page> page(Integer page, Integer pageSize, String name){
// 打印日志
log.info("page = {}, pageSize = {}, name = {}", page, pageSize, name);
// 构造分页构造器
Page pageInfo = new Page(page, pageSize);
// 构造条件构造器
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
// 添加过滤条件 :: 写法
queryWrapper.like(StringUtils.isNotEmpty(name), Employee::getName, name);
// 添加排序条件
queryWrapper.orderByDesc(Employee::getUpdateTime);
// 执行查询
employeeService.page(pageInfo, queryWrapper);
return R.success(pageInfo);
}
逻辑
- 定义一个分页构造器
- 然后去根据查询条件,去构建多条件的条件构造器
- 最后查询
这个LambdaQueryWrapper,好处有https://blog.csdn.net/fairy1674/article/details/123789066
6、消息转换器
这个东西是在实现禁用员工的账号的时候,发现的原因是服务端响应给前端的员工Long类型的id自动进行了一个舍去,然后在更改的时候,前端传给服务端的Long类型的id是错的(丢失了精度),所以导致,程序没有报错,但是数据库修改对应不上id就没办法进行修改,然后视频中给出的解决方式是使用一个消息转换器
具体实现步骤:
- 提供对象转换器JacksonObjectMapper,基于Jackson进行java对象到json数据的转换
/**
* 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象
* 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
* 从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
*/
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(BigInteger.class, ToStringSerializer.instance)
.addSerializer(Long.class, ToStringSerializer.instance)
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}
- 在WebMvcConfig配置类中扩展Spring MVC的消息转换器,在此消息转换器中使用提供的对象转换器进行java对象到json的转换
/**
* 扩展mvc框架的消息转换器
* @param converters
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
// 创建消息转换器对象
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
// 设置对象转换器,底层使用Jackson将Java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
// 将上面的消息转换器对象追加到mvc框架的转换器集合中
converters.add(0, messageConverter);
}
还是学的不到位,看来做完这个项目还要补一补springboot的知识点
7、公共字段自动填充
Mybatis Plus公共字段自动填充,也就是在插入或者更新的时候为指定字段赋予指定的值,使用它的好处就是可以统一对这些字段进行处理,避免了重复代码
实现步骤:
- 在实体类的属性上加入@TableField注解,指定自动填充的策略
- 按照框架要求编写元数据对象处理器,在此类中统一为公共字段赋值,此类需要实现MetaObjectHandler接口
通过动态的获取createUser和UpdateUser所需要的值,这里的MyMetaObjectHandler是不能获取HttpsSession对象的,所以我们需要通过ThreadLocal类来解决这个问题
补充
在学习threadLocal之前,我们需要先确定一个事情,就是客户端发送的每次https请求,对应的在服务端都会分配一个新的线程来处理,在处理过程中设计到下面类中的方法都属于相同的一个线程
LoginCheckFilter的doFilter方法EmployeeController的update方法MyMetaObjectHandler的updateFill方法
可以在上面的三个方法在那个分别加入
long id = Thread.currentThread().getId();
log.info("线程id为{}", id);

实现步骤
- 编写BaseContext工具类,基于ThreadLocal封装的工具类
/**
* 基于ThreadLocal封装工具类,用户保存和获取当前登录用户id
*/
public class BaseContext {
private static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id){
threadLocal.set(id);
}
public static Long getCurrentId(){
return threadLocal.get();
}
}
- 在LoginCheckFilter的doFilter方法中调用BaseContext来设置当前登录用户的Id
- 在MyMetaObjectHandler的方法中调用BaseContext获取登录用户的id
8、业务异常类
通过自定义业务异常类,通过全局异常处理器,对异常类进行处理
视频中使用这个是因为当删除一个分类的时候,可能关联着菜品和套餐,如果要是直接删除的话,就会产生一个不对等的关系了,所以在删除的时候,去通过关联查询菜单和套餐,通过异常处理来终止删除分类
public class CustomException extends RuntimeException{
public CustomException(String message){
super(message);
}
}
自定义业务异常类

在全局异常处理器中去捕获
9、文件上传下载
概念不用说都也知道,说几个重要的
文件上传时,对页面的form表单有如下要求(三大要素)
- method=“post” 采用post方式提交数据
- enctype=“multipart/form-data” 采用multipart格式上传文件
- type=“file” 使用input的file控件上传

通常会使用到的Apache的两个组件
- commons-fileupload
- commons-io
Spring框架在spring-web包中队文件上传进行了封装,大大简化了服务端的代码,之前我用过那个磁盘工厂啥的去写过,一堆代码,烦的很,但是用了spring通过在Controller方法中声明一个MultipartFile类型的参数就可以直接接受上传的文件

具体实现
/**
* 文件上传
* @param file
* @param request
* @return
*/
@PostMapping("/upload")
public R<String> upload(MultipartFile file, HttpServletRequest request){
log.info(file.toString());
// 原始文件名
String oldFileName = file.getOriginalFilename();
String suffix = oldFileName.substring(oldFileName.lastIndexOf("."));
// 使用UUID重新生成文件名,防止文件名称重复造成文件覆盖
String newFileName = UUID.randomUUID().toString() + suffix;
// 创建一个目录对象
File dir = new File(basePath);
if(!dir.exists()){
// 目录不存在。需要创建
dir.mkdirs();
}
try {
file.transferTo(new File(basePath + newFileName));
} catch (IOException e) {
throw new RuntimeException(e);
}
return R.success(newFileName);
}
这里可以将你要保存的路径写到配置文件中,然后通过@Vaule来获取到
文件下载
我觉的还是IO的知识点多,要不是读要不就是写,之前学过基础,忘的都差不多了。。。
/**
* 文件下载
* @param name
* @param response
*/
@GetMapping("/download")
public void download(String name, HttpServletResponse response){
try {
// 输入流,通过输入流读取文件内容
FileInputStream fileInputStream = new FileInputStream(new File(basePath + name));
// 输出流,通过输出流将文件协会浏览器,在浏览器展示图片
ServletOutputStream outputStream = response.getOutputStream();
// 设置响应回去的类型
response.setContentType("image/jpeg");
int len = 0;
byte[] bytes = new byte[1024];
while ((len = fileInputStream.read(bytes)) != -1){
outputStream.write(bytes, 0, len);
outputStream.flush();
}
// 关闭资源
outputStream.close();
fileInputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
// 输出流,通过输出流将文件写会浏览器,在浏览器展示
}
10、一个分页查询的逻辑

- 因为这个套餐中没有套餐分类名称的这个字段,只有这个套餐分类的id,视频中的解决办法是引入了一个stemealDto的实体,其中有前端要显示的所有的信息
@GetMapping("/page")
public R<Page> page(Integer page, Integer pageSize, String name){
log.info("page = {} pageSize = {}", page, pageSize);
// 分页构造器
Page<Setmeal> setmealPage = new Page<>(page, pageSize);
// 因为要返回的数据中要有分类的名称所以就要使用SetmealDto当返回数据的类型
Page<SetmealDto> setmealDtoPage = new Page<>();
// 条件构造器
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(name != null, Setmeal::getName, name);
queryWrapper.orderByAsc(Setmeal::getUpdateTime);
// 查询信息
setmealService.page(setmealPage, queryWrapper);
// 拷贝数据,除了records
BeanUtils.copyProperties(setmealPage, setmealDtoPage, "records");
List<Setmeal> records = setmealPage.getRecords();
// 处理分类名称
List<SetmealDto> setmealDtos = records.stream().map((item) ->{
SetmealDto setmealDto = new SetmealDto();
BeanUtils.copyProperties(item, setmealDto);
Long categoryId = item.getCategoryId();
Category category = categoryService.getById(categoryId);
setmealDto.setCategoryName(category.getName());
return setmealDto;
}).collect(Collectors.toList());
setmealDtoPage.setRecords(setmealDtos);
return R.success(setmealDtoPage);
}
这里不做什么赘述了,直接看代码应该就能知道
11、短信验证
视频中使用的是阿里云的短信验证,查看官方使用文档https://help.aliyun.com/document_detail/112148.html
使用步骤
- 导入maven坐标
<dependency>
<groupId>com.aliyungroupId>
<artifactId>aliyun-java-sdk-coreartifactId>
<version>4.5.16version>
dependency>
<dependency>
<groupId>com.aliyungroupId>
<artifactId>aliyun-java-sdk-dysmsapiartifactId>
<version>2.1.0version>
dependency>
- 调用api
import com.aliyuncs.DefaultAcsClient;
import com.aliyuncs.IAcsClient;
import com.aliyuncs.exceptions.ClientException;
import com.aliyuncs.exceptions.ServerException;
import com.aliyuncs.profile.DefaultProfile;
import com.google.gson.Gson;
import java.util.*;
import com.aliyuncs.dysmsapi.model.v20170525.*;
public class SendSms {
public static void main(String[] args) {
DefaultProfile profile = DefaultProfile.getProfile("cn-beijing", "" , "" );
/** use STS Token
DefaultProfile profile = DefaultProfile.getProfile(
"", // The region ID
"", // The AccessKey ID of the RAM account
"", // The AccessKey Secret of the RAM account
""); // STS Token
**/
IAcsClient client = new DefaultAcsClient(profile);
SendSmsRequest request = new SendSmsRequest();
request.setPhoneNumbers("1368846****");//接收短信的手机号码
request.setSignName("阿里云");//短信签名名称
request.setTemplateCode("SMS_20933****");//短信模板CODE
request.setTemplateParam("张三");//短信模板变量对应的实际值
try {
SendSmsResponse response = client.getAcsResponse(request);
System.out.println(new Gson().toJson(response));
} catch (ServerException e) {
e.printStackTrace();
} catch (ClientException e) {
System.out.println("ErrCode:" + e.getErrCode());
System.out.println("ErrMsg:" + e.getErrMsg());
System.out.println("RequestId:" + e.getRequestId());
}
}
}
具体使用步骤https://blog.csdn.net/Qixx_799/article/details/106411765
代码实现步骤:
- 添加实体类、工具类、mapper、service、controller
- 然后修改LoginCheckFilter

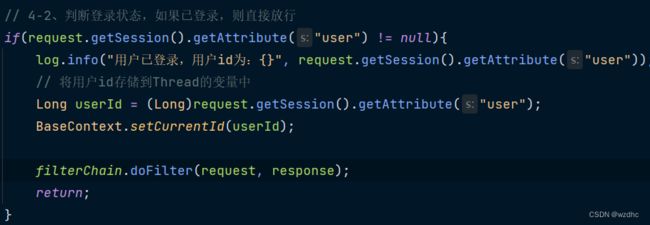
这里再加上一个对移动端登录页面的判断
- controller逻辑
- 获取手机号
- 使用工具类生成随机的4位验证码
- 调用阿里云提供的短信服务API完成发送短信
- 需要将生成的验证那保存到session中,以便后续验证
@PostMapping("/sendMsg")
public R<String> sendMsg(@RequestBody User user, HttpSession session){
// 获取手机号
String phone = user.getPhone();
if(StringUtils.isNotEmpty(phone)){
// 生成随机的4位验证码
String code = ValidateCodeUtils.generateValidateCode(4).toString();
log.info("code = {}", code);
// 调用阿里云提供的短信服务API完成发送短信
//SMSUtils.sendMessage("瑞吉外卖", "", phone, code);
// 需要将生成的验证码保存到Session,以便后续登录验证
session.setAttribute(phone, code);
return R.success("手机验证码短信发送成功");
}
return R.error("错误");
}
因为视频中没有使用那个阿里云来发短信,然后我这里也没有申请成功那个短信服务的签名和模板,,,,所以就先这样吧。。。
12、批量删除
实现逻辑(视频中):
- 在contoller中去接受ids(
因为它可能是删除一个,也可能是批量删除) - 注意有无关联表的信息也需要删除,或者是判断因为有关联信息而无法删除
- 拿删除菜品的逻辑来说因为菜品关联着口味和关联套餐的可能性,
- 还有起售的时候也不能删除,所以在删除逻辑的时候,就要去判断当正在销售或者被其他套餐关联的时候不能删除
- 如果可以删除,也要把口味表中关联的数据删除掉
@Override
public void removeWithDish(List<Long> ids) {
// 查询菜品状态,确定是否可删除
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
// 如果不能删除就抛出业务异常
queryWrapper.in(Dish::getId, ids);
queryWrapper.eq(Dish::getStatus, 1);
int count = this.count(queryWrapper);
if(count > 0){
throw new CustomException("菜品正在售卖中,不能删除");
}
LambdaQueryWrapper<SetmealDish> dishDishQuery = new LambdaQueryWrapper<>();
dishDishQuery.in(SetmealDish::getDishId, ids);
int count1 = setmealDishService.count(dishDishQuery);
if(count1 > 0){
throw new CustomException("菜品已被其他套餐关联,不能删除");
}
// 如果可以删除先删除套餐表中的数据
this.removeByIds(ids);
// 删除关系表中的数据
LambdaQueryWrapper<DishFlavor> dishFlavorLambdaQueryWrapper = new LambdaQueryWrapper<>();
dishFlavorLambdaQueryWrapper.in(DishFlavor::getDishId, ids);
dishFlavorService.remove(dishFlavorLambdaQueryWrapper);
}
13、批量起售\停售
逻辑(自己写的):
- 先是获得传过来的状态和要修改哪些的菜品的ids
- 查询传过来所有id的菜品信息
- 然后通过设置不同菜品的状态,然后再更新一下
@PostMapping("/status/{id}")
public R<String> updateStatus(@PathVariable Integer id, @RequestParam List<Long> ids){
// 条件构造器
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.in(ids != null,Dish::getId, ids);
// 查询一下
List<Dish> list = dishService.list(queryWrapper);
// 枚举一下查询的数据
for (Dish dish : list) {
// 如果菜品不为空的话
if(dish != null){
// 修改状态然后保存
dish.setStatus(id);
dishService.updateById(dish);
}
}
return R.success("批量修改成功!");
}
这里我一开始是想通过一个update xxx set = ?? where ids in (xxxx),但是尝试了好几次都不知道怎么用mybatis-plus中的方法去实现,所以采用上面这种方式
14、减少订购量
@PostMapping("/sub")
public R<ShoppingCart> sub(@RequestBody ShoppingCart shoppingCart){
Long currentId = BaseContext.getCurrentId();
Long dishId = shoppingCart.getDishId();
LambdaQueryWrapper<ShoppingCart> lqw = new LambdaQueryWrapper<>();
lqw.eq(ShoppingCart::getUserId, currentId);
if(dishId != null){
lqw.eq(ShoppingCart::getDishId, dishId);
}else{
lqw.eq(ShoppingCart::getSetmealId, shoppingCart.getSetmealId());
}
ShoppingCart one = shoppingCartService.getOne(lqw);
if(one != null){
// 预测一下
one.setNumber(one.getNumber() - 1);
Integer number = one.getNumber();
if(number > 0) {
// 不为空就减一
shoppingCartService.updateById(one);
}else if(number == 0){
shoppingCartService.removeById(one);
}else if(number < 0){
return R.error("操作异常");
}
}
return R.success(one);
}
记录这里的原因是
- 一开始我是写的那个代码,是减到了1以后就不动了,这个菜品还没有消失,但是数据库中的数据减没了,我一开始是以为前端没有刷新的原因,后面我也不知道怎么搞的。。。
- 然后我修改了一下,成了下面这样子,但是当减到了一后面,既然能到0,然后再减去了才会消失
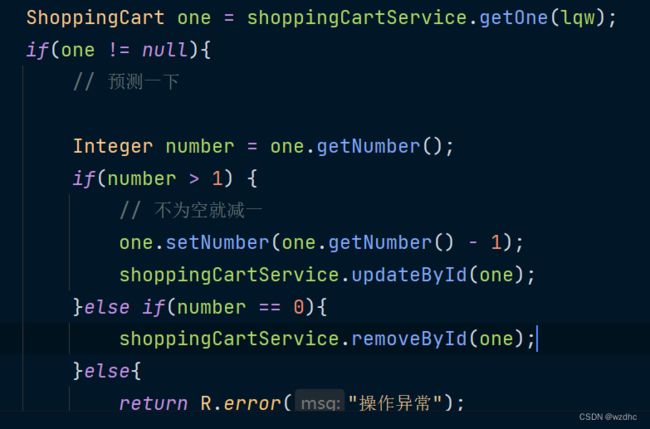
- 后来改成了这个样子,没有问题了,正常显示了(预判法)
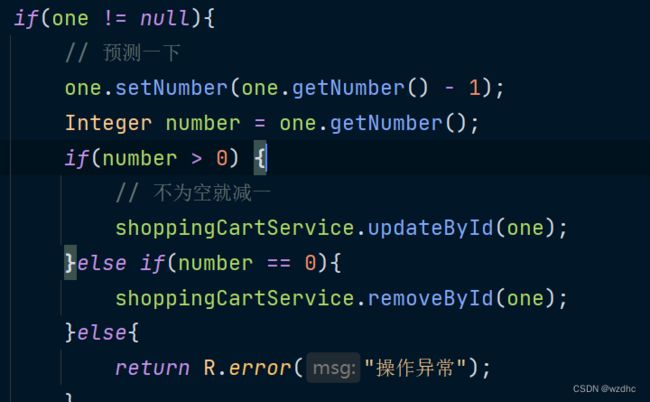
15、结算逻辑
记录一下视频中结算的逻辑,有好多和我想的不一样,就像当点击结算的时候我认为将用户id、购物车里面的数据以及那个Orders里面好多的字段都应该给后端传过去,后来看到视频中就传了几个数据。。。
它里面的用户id从BaseContext那个线程携带中去取出来,购物车中的数据是根据用户id从那个购物车那个表中取出来的,我觉的这很好,我之前一点也没有想到。。。

实现逻辑:
- 获得当前用户的id
- 查询当前用户的购物车数据
- 像订单表插入数据,一条数据
- 向订单表明细插入数据,多条数据
- 清空购物车数据
@Override
public void sumbit(Orders orders) {
// 获得当前用户的id
Long userId = BaseContext.getCurrentId();
// 查询当前用户的购物车数据
LambdaQueryWrapper<ShoppingCart> lqw = new LambdaQueryWrapper<>();
lqw.eq(ShoppingCart::getUserId, userId);
List<ShoppingCart> list = shoppingCartService.list(lqw);
if(list == null || list.size() == 0){
throw new CustomException("购物车为空!无法结账");
}
// 查询用户数据
User user = userService.getById(userId);
// 查询地址数据
AddressBook addressBook = addressBookService.getById(orders.getAddressBookId());
if(addressBook == null){
throw new CustomException("用户地址信息有误!无法结账");
}
// 像订单表插入数据,一条数据
// 补全信息
long orderId = IdWorker.getId();
// 一个原子类型的int数据,在多线程下是一个安全的数
AtomicInteger amount = new AtomicInteger(0);
// 计算总金额和订单明细数据
List<OrderDetail> orderDetails = list.stream().map((item) -> {
OrderDetail orderDetail = new OrderDetail();
orderDetail.setOrderId(orderId);
orderDetail.setNumber(item.getNumber());
orderDetail.setDishFlavor(item.getDishFlavor());
orderDetail.setDishId(item.getDishId());
orderDetail.setSetmealId(item.getSetmealId());
orderDetail.setName(item.getName());
orderDetail.setImage(item.getImage());
orderDetail.setAmount(item.getAmount());
// 每一件商品都加一下
amount.getAndSet(item.getAmount().multiply(new BigDecimal(item.getNumber())).intValue());
return orderDetail;
}).collect(Collectors.toList());
orders.setId(orderId);
orders.setOrderTime(LocalDateTime.now());
orders.setCheckoutTime(LocalDateTime.now());
orders.setStatus(2);
orders.setAmount(new BigDecimal(amount.get()));//总金额
orders.setUserId(userId);
orders.setNumber(String.valueOf(orderId));
orders.setUserName(user.getName());
orders.setConsignee(addressBook.getConsignee());
orders.setPhone(addressBook.getPhone());
orders.setAddress((addressBook.getProvinceName() == null ? "" : addressBook.getProvinceName())
+ (addressBook.getCityName() == null ? "" : addressBook.getCityName())
+ (addressBook.getDistrictName() == null ? "" : addressBook.getDistrictName())
+ (addressBook.getDetail() == null ? "" : addressBook.getDetail()));
this.save(orders);
// 向订单表明细插入数据,多条数据
orderDetailService.saveBatch(orderDetails);
// 清空购物车数据
shoppingCartService.remove(lqw);
}
中间又往开展了一下,补充了表中的信息,比如是用户的一些信息和地址的信息,还有处理明细表中的数据,也是挺复杂的,还用到了一个我从来没见过的
AtomicInteger,通过那个stream迭代的方式,在处理明细表中的数据的时候,也将价钱都算了出来,而且还用到了高精度BigDecimal,以后遇到一些关于线程的和价钱的都可以用这两个东西
16、订单显示逻辑
这个有点复杂了,通过前端给的userId,查询分页,既要找到所有的订单,还有查找出所有订单的所有下单的菜品,也就是
一个id—》多个订单、每个订单—》多个明细
@GetMapping("/userPage")
public R<Page> page(Integer page, Integer pageSize){
// 分页构造器
Page<Orders> ordersPage = new Page<>(page, pageSize);
Page<OrdersDto> ordersDtoPage = new Page<>();
// 条件构造器
LambdaQueryWrapper<Orders> lqw1 = new LambdaQueryWrapper<>();
// 先查询出订单
lqw1.eq(Orders::getUserId, BaseContext.getCurrentId());
lqw1.orderByDesc(Orders::getOrderTime);
// 现在ordersPage中就有许多的订单的 ,但是我们还要其中的购物数据,所以还要进一步的封装orders为ordersDto
orderService.page(ordersPage, lqw1);
// 拷贝分页构造器,除了records数据,这个要自己手动替换成有购物数据的类型
BeanUtils.copyProperties(ordersPage, ordersDtoPage, "records");
// 枚举每一个订单 返回的数据就是要查询的所有的数据
List<Orders> records = ordersPage.getRecords();
List<OrdersDto> ordersDtos = records.stream().map((item) -> {
// 创建OrdersDto对象来准备存储购物数据
OrdersDto ordersDto = new OrdersDto();
// 通过每一个订单的订单号在ordersDetails中去获取购物的数据
Long orderId = item.getId();
// 得到了购物的数据
LambdaQueryWrapper<OrderDetail> lqw2 = new LambdaQueryWrapper<>();
lqw2.eq(OrderDetail::getOrderId, orderId);
List<OrderDetail> orderDetails = orderDetailService.list(lqw2);
// 将每一个订单的信息拷贝到dto上,然后将购物数据也放到dto上
BeanUtils.copyProperties(item, ordersDto);
ordersDto.setOrderDetails(orderDetails);
// 最终返回dto并重新弄成集合
return ordersDto;
}).collect(Collectors.toList());
// 将其放到分页构造器中的records,返回给前端显示
ordersDtoPage.setRecords(ordersDtos);
return R.success(ordersDtoPage);
}
最终是参考了这位佬,一开始思路还挺清晰的,然后越写越不清楚,前端总是不显示明细,死活找不出问题,后来发现是前端要求的那个数据key是固定的,我自己写了一个key,导致匹配不上就读不出数据。。。。之前好像就犯过一次错,这样的分页写过了好几次了,之前那个都是有一些表的id,但是没有名字,所以搞一个dto,然后先查找出原本的数据,通过某个数据然后再查询出另一个表的需要的字段,通过BeaUtils的拷贝最终将数据整合到分页的records,返回给前端显示,这个也是差不多,就是把某个字段又变成了一个集合,和俄罗斯套娃一样,这次这个就花了我好长的时间,希望我下次遇到这种问题可以快速的解决出来
17、linux
17.1、网路设置
使用vm创建一个虚拟机,此步骤略
- 通过命令
ip addr发现ip地址初始化失败 - 编辑
ifcfg-ens33
vim /etc/sysconfig/network-scripts/ifcfg-ens33
- 将
ONBOOT修改为yes - 最后执行
ip addr,下面这个就是ip地址
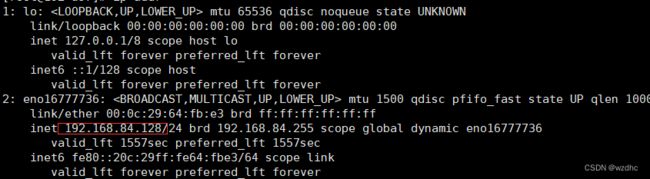
静态网路设置
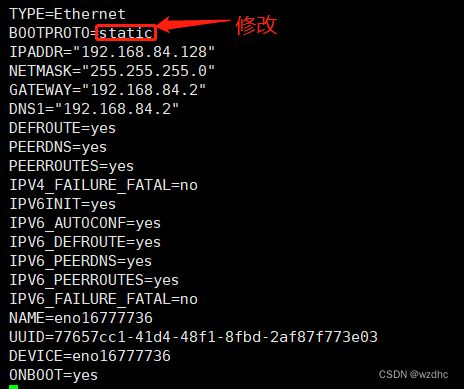
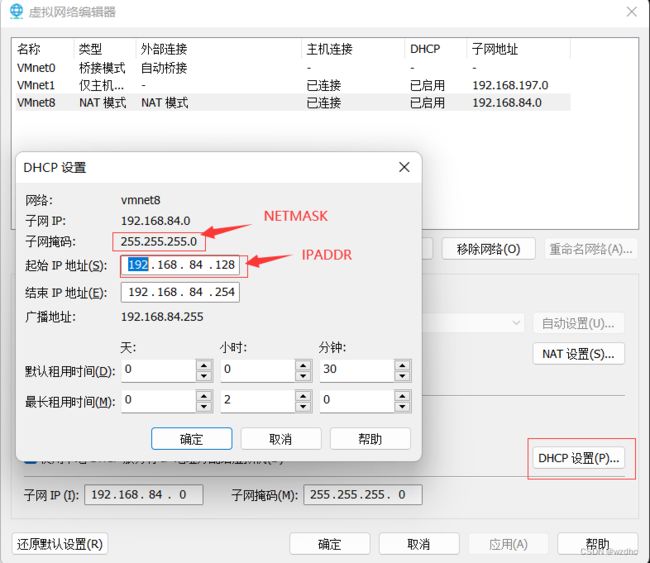
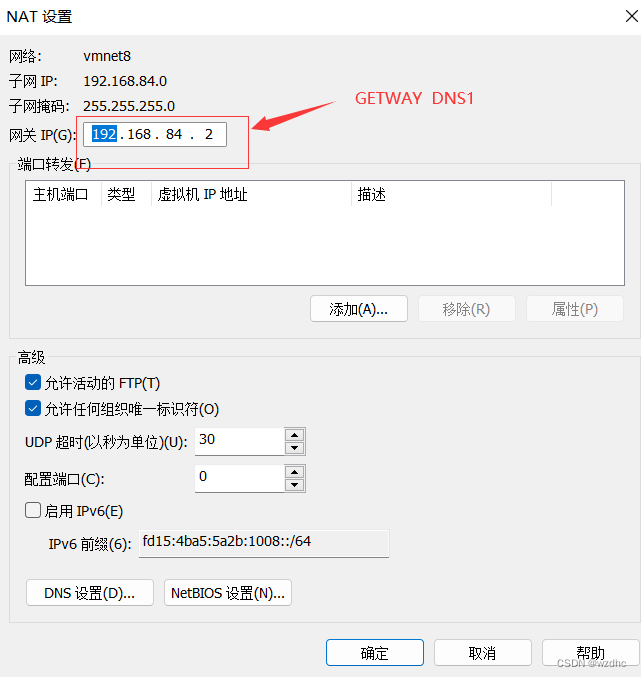
配置完后执行 systemctl restart network
17.2、安装jdk
这里安装的是jdk8全名是
jdk-8u171-linux-×64.tar.gz,下载地址:https://repo.huaweicloud.com/java/jdk/8u171-b11/
安装步骤:
- 将压缩包传到虚拟机中
- 解压命令
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local - 配置环境变量,打开/etc/profile,加入
JAVA_HOME=/usr/local/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
- 执行命令
source /etc/profile,是修改配置生效 - 检查安装是否成功,
java、java -version
17.3、安装tomcat
视频中使用的tomcat版本是(
apache-tomcat-7.0.57.tar.gz)https://archive.apache.org/dist/tomcat/tomcat-7/v7.0.57/bin/
操作步骤
- 将压缩包传到虚拟机中
- 解压安装包
tar -zxvf apache-tomcat-7.0.57.tar.gz -C /usr/local
- 进入tomcat的bin目录下,启动tomcat
./startip.sh

查看tomcat是否启动成功
- 通过查看启动日志
vi apache-tomcat-7.0.57/logs/catalina.out
- 查看进程
ps -ef | grep tomcat
防火墙常用操作
- 查看防火墙状态
systemctl status firewalld 或 firewall-cmd --state
- 暂时关闭防火墙
systemctl stop firewalld
- 永久关闭防火墙
systemcel disable firewalld
- 开启防火墙
systemctl start firewalld
- 开放指定端口
firewall-cmd --zone=public --add-port=8080/tcp --permanent
- 关闭指定端口
firewall-cmd --zone=public --remove=8080/tcp --permanent
- 立即生效
firewall-cmd --reload
- 查看开放的端口
firewall-cmd --zone=public --list-ports
17.4、安装mysql
安装包下载地址https://downloads.mysql.com/archives/community/
安装mysql与centos7中自带的mariadb有冲突,所以要先卸载掉旧的软件
卸载命令rpm -e --nodeps mariadb-libs-5.5.41-2.el7_0.x86_64
安装步骤
- 将压缩包解压到虚拟机中
- 解压
tar -zxvf mysql-5.7.25-1.el7.x86_64.rpm-bundle -C /usr/local/mysql.tar
- 一个一个那安装rpm
rpm -ivh mysql-community-common-5.7.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-devel-5.7.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.25-1.el7.x86_64.rpm
yum install net-tools
rpm -ivh mysql-community-server-5.7.25-1.el7.x86_64.rpm
最后一步还可能遇到的错误:

执行以下命令
yum install -y perl-Module-Install.noarch
启动mysql
- 查看一下mysql服务是否开启
systemctl status mysqld 查看mysql服务状态
systemctl start mysqld 启动mysql服务

2. 设置开启时自动启动mysql服务
systemctl enable mysqld 开机启动mysql服务
netstat -tunlp grep | mysql 查看已经启动的服务
ps -ef | grep mysql 查看进程
- 登录MySQL数据库,查阅临时密码
cat /var/log/mysqld.log | grep 查看密码(那个:后面的
空格不是密码哦!)
- 登录mysql数据库
mysql -uroot -p
- 修改密码
因为这里是练习所用,所以搞的简单点
set global validate_password_length=4;设置密码长度最低位数
set global validate_password_policy=LOW;设置密码安全等级低
set password = password('root');设置密码为root
grant all on *.* to 'root'@'%' identified by 'root';开启访问权限
flush privileges;刷新
- 将3306端口放开,就可以用sql连接工具连接到虚拟中的中mysql了
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --reload 生效一下
17.5、安装lrzsz
这里有两个常用的命令
-
yum list
name搜索安装包 -
yum install
name在线安装
安装步骤:
-
yum list lrzsz
-
yum install lrzsz.x86_64
-
安装完成后输入命令
rz,就可以弹出一个传输文件的窗口了
18、项目部署
18.1、手工部署
先准备一个springboot的程序,我这里准备了一个这样的,视频中的没有加数据库查询,我顺便就试试能不能查数据库的数据,自己新建了一个数据库,还有表啥的
步骤
- 先使用maven的clean和package命令,将程序打成jar包
- 然后再虚拟机上
mkdir /usr/local/app,将jar包传上去 - 在虚拟机中执行
java -jar jar包名称,将springboot项目跑起来 - 检查8080端口是否放开
- 测试(我这里测试的没啥问题)

存在两个问题
- 当你运行起来jar包的时候,那么整个屏幕就不可以操控了,而且当你关闭你的ssh连接工具的话程序就会直接挂掉
- 正规来说我们的日志文件会输出到专门的日志文件中,而不是直接输出在屏幕上
现在来解决这两个问题
通过使用nohup命令:英文全程no hang up(不挂起),用于不断地运行指定命令,退出中断不会影响到程序的运行,并且同时还可以让日志输出到指定的日志文件中

18.2、通过Shell脚本自动部署项目
操作步骤:
- 在linux中安装git
yum list git
yum install git
- 在Linux中安装maven
下载地址https://repo.maven.apache.org/maven2/org/apache/maven/apache-maven/3.5.4/
安装步骤
还是那样把文件解压到usr/local里面就可以,然后就是配置环境变量,配置maven下载的仓库就
export MAVEN_HOME=/usr/local/apache-maven-3.5.4
export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$PATH环境变量
在local下创建一个repo的文件夹,然后添加配置到maven的conf/settings.xml中
/usr/local/repo
再添加一个镜像
aliyunmaven
*
aliyun maven
https://maven.aliyun.com/repository/public
- 编写Shell脚本(拉取代码、编译、打包、启动)
#! /bin/sh
echo ======================
echo 自动化部署脚本启动
echo =====================
echo 停止原来运行中的项目
APP_NAME=helloworld
tipd=`ps -ef | grep $APP_NAME | grep -v grep | grep -v kill | awk '{ print $2 }'`
if [ ${tpid} ]; then
echo 'Stop Process...'
kill -15 $tpid
fi
sleep 2
tpid=`ps -ef | grep $APP_NAME | grep -v grep | grep -v kill | awk '{ print $2 }'`
if [ ${tpid} ]; then
echo 'Kill Process!'
kill -9 $tpid
else
echo 'Stop Success!';
fi
echo 准备从git仓库拉取最新代码
cd /usr/local/helloworld
echo 开始从git仓库拉取最新代码
git pull
echo 代码拉取完成
echo 开始打包
output=`mvn clean package -Dmaven.test.skip=true`
cd /usr/local/helloworld/target
echo 启动项目
nohup java -jar helloworld-1.0-SNAPSHOT.jar &> helloworld.log &
echo 项目启动完成
- 为用户授予执行Shell脚本的权限
chmod 777 bootStart.sh
- 执行Shell脚本
./bootStart.sh

这个是我从未设想过的道路。。。。很有趣
四、redis基础
1、入门和应用场景



2、下载和安装
redis下载和安装(linux)
下载地址:https://download.redis.io/releases/
步骤:
- 将Redis安装包上传到Linux
- 解压安装包(
解压后里面装的是源码,还要现场编译一下)
tar -zxvf xxxxx -C /usr/local
- 安装Redis的依赖环境gcc(
这个就是编译c用的东西)
yum install gcc-c++
- 进入/usr/local/redis-4.0.0,然后
make
- 进入redis的src目录,进行安装
make install
3、Redis服务启动与停止
Linux中redis服务启动,可以使用redis-server,默认端口号为6379
步骤
- 修改redis.conf配置文件,修改为后台运行

- 然后输入命令启动redis,同时要使用redis.conf配置
src/redis-server ./redis.conf

- 然后另外开一个窗口,进入到redis中的src下,然后运行redis
./redis-cli
可以使用keys *,看一看

windows,解压完后,进去直接点就行了
- 点那个redis-server.exe
- 然后再点那个redis-cli.exe

4、设置密码
通过修改配置文件中的requirepass 选项来开始密码验证

然后杀掉服务端和客户端的进程
ps -ef | grep redis
然后再重新启动服务端和客户端,我们发现还可以登进入

但是执行keys *命令的时候,报错,没有认证

此时我们可以通过输入auth 密码,来通过验证

还可以直接在启动客户端的时候使用命令

我发现这样也可以,反正都有一样

5、远程连接
- 修改配置文件

- 然后重新启动一下redis服务
- 开放6379端口号
firewall-cmd --zone=public --add-port=6379/tcp --permanent
firewall-cmd --reload 生效一下
- 在windows下的命令行中输入,即可以远程连接redis了
.\redis-cli.exe -h 192.168.84.128 -p 6379 -a 123456

6、Redis数据类型
更多命令查看官网 https://redis.net.cn


6.1、字符串常用命令

6.2、哈希hash操作命令

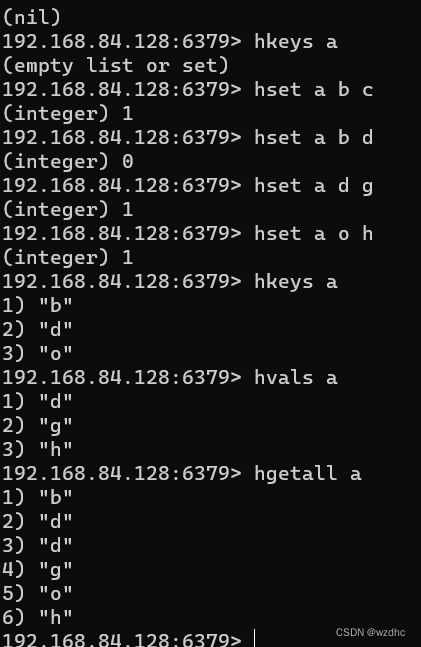
6.3、列表list操作命令

6.4、集合set操作命令
6.5、有序集合sorted set 操作命令

6.6、redis常用命令

7、Jedis

操作步骤:
- 导入坐标jedis
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.8.0version>
dependency>
- 使用
- 获取连接
- 执行具体操作
- 关闭连接
@Test
public void testRedis(){
// 1、获取连接
Jedis jedis = new Jedis("localhost", 6379);
// 2、执行具体的操作
jedis.set("username", "xiaoming");
jedis.setex("age", 10, "18");
String username = jedis.get("username");
String age = jedis.get("age");
System.out.println("username = " + username + " age = " + age);
jedis.hset("a", "b", "c");
jedis.hset("a", "c", "d");
String hget = jedis.hget("a", "b");
String hget1 = jedis.hget("a", "c");
System.out.println("hget = " + hget + " hget1 = " + hget1);
// 3、关闭连接
jedis.close();
}
8、Spring Data Redis

操作步骤
- 导入坐标
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<version>2.4.5version>
dependency>
- 配置文件
spring:
application:
name: springdataredis_demo
#redis相关配置
redis:
host: localhost
port: 6379
database: 0
jedis:
#Redis连接池配置
pool:
max-active: 8 #最大连接数
max-wait: 1ms #连接池最大阻塞等待时间
max-idle: 4 #连接池中的最大空闲等待
min-idle: 0 #连接池中最小空闲连接
- 自定义一下序列化配置
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
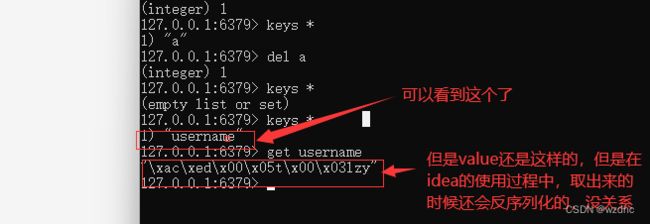
因为如果使用默认的序列化的方式的话,存储的
key值也被序列化了,然后你访问这个key的时候就访问不了,淦!所以要存储key的时候要使用其他的序列化的方式才可以
还有一个注意点使用springboot的test的时候,一定要注意那个目录结构,src里面的和test里面的结构一定要一样,要不然的话就会报错,这应该也就那个约定大于配置的体现了

测试
@SpringBootTest
@RunWith(SpringJUnit4ClassRunner.class)
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testString(){
redisTemplate.opsForValue().set("username", "lzy");
Object username = redisTemplate.opsForValue().get("username");
System.out.println( username);
}
}
8.1、String类型常用方法
@Test
public void testSetAndGetString(){
// 普通set
redisTemplate.opsForValue().set("age", 18);
// 有过期时间的set
redisTemplate.opsForValue().set("username", "lzy", 10, TimeUnit.SECONDS);
// 可以加强转
String username = (String)redisTemplate.opsForValue().get("username");
Object age = redisTemplate.opsForValue().get("age");
System.out.println( username + " " + age);
}
@Test
public void testDeleteKey(){
redisTemplate.delete("age");
}
@Test
public void testLen(){
Long age = redisTemplate.opsForValue().size("age");
//用Spring Data Redis来储存的时候 前面会带有一些特殊字符 因此长度会不符
System.out.println(age);
}
8.2、Hash类型常用方法
Test
public void testHash()
{
// Hash表添加记录
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("002","name","xiaoming");
hashOperations.put("002","age","20");
hashOperations.put("002","address","bj");
// 取值
String age = (String) hashOperations.get("002", "age");
System.out.println(age); // 20
//获得hash结构中的所有字段
Set keys = hashOperations.keys("002");
for (Object key : keys) {
System.out.println(key);
}
// 获取hash结构中的所有值
List values = hashOperations.values("002");
for (Object value : values) {
System.out.println(value);
}
}
8.3、List类型常用方法
@Test
public void testList(){
ListOperations listOperations = redisTemplate.opsForList();
//存值
listOperations.leftPush("mylist","a");
listOperations.leftPushAll("mylist","b","c","d");
//取值
List<String> mylist = listOperations.range("mylist", 0, -1);
for (String value : mylist) {
System.out.println(value);
}
//获得列表长度 llen
Long size = listOperations.size("mylist");
int lSize = size.intValue();
for (int i = 0; i < lSize; i++) {
//出队列
String element = (String) listOperations.rightPop("mylist");
System.out.println(element);
}
}
8.4、set类型常用方法
@Test
public void testSet(){
SetOperations setOperations = redisTemplate.opsForSet();
//存值
setOperations.add("myset","a","b","c","a");
//取值
Set<String> myset = setOperations.members("myset");
for (String o : myset) {
System.out.println(o);
}
//删除成员
setOperations.remove("myset","a","b");
//取值
myset = setOperations.members("myset");
for (String o : myset) {
System.out.println(o);
}
}
8.5、Zset类型常用方法
@Test
public void testZset(){
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
//存值
zSetOperations.add("myZset","a",10.0);
zSetOperations.add("myZset","b",11.0);
zSetOperations.add("myZset","c",12.0);
zSetOperations.add("myZset","a",13.0);
//取值
Set<String> myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
//修改分数
zSetOperations.incrementScore("myZset","b",20.0);
//取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
//删除成员
zSetOperations.remove("myZset","a","b");
//取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
}
8.6、通用方法
@Test
public void testCommon(){
//获取Redis中所有的key
Set<String> keys = redisTemplate.keys("*");
for (String key : keys) {
System.out.println(key);
}
//判断某个key是否存在
Boolean itcast = redisTemplate.hasKey("itcast");
System.out.println(itcast);
//删除指定key
redisTemplate.delete("myZset");
//获取指定key对应的value的数据类型
DataType dataType = redisTemplate.type("myset");
System.out.println(dataType.name());
}
五、缓存优化
1、使用git管理项目
操作步骤
- 在gitee上创建一个仓库
- 在本地项目中初始化
git仓库,配置好.gitignore文件,然后add、commit、push即可
这里可以用两种方式:一是使用git命令行,二是使用idea中的git视图操作,我觉的哪种都可以,哪个用的习惯了就用哪个
- 这时候就可以看到gitee上的项目了
- 然后创建一个新的
分支v1.0,再次提交项目到gitee上,这样我们就拥有了两条分支,一个是master,一个是v1.0,当我们把缓存优化都完成测试好以后,就可以把v1.0这条分支合并到主分支上,之前学的时候没有想这么多,这样看来确实很方便
2、环境搭建
2.1、maven坐标
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
2.2、配置yml文件
2.3、增加一个配置类RedisConfig
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
3、缓存短信验证码
之前我我们实现了移动端手机验证码登录,随机生成的验证我们是保存在HttpSession中的,现在需要改造成为将验证码缓存到Redis中
实现思路
- 在服务端UserContoller中注入RedisTemplate对象,用于操作Redis
- 在服务端UserController的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟
- 在服务端UserController的login方法中,从Redis中获取缓存的验证码,如果登录成功则删除Reids中的验证码
4、缓存菜品数据
前面实现了移动端菜品的查看功能,对应的服务端方法为DishController的list方法,次方法会根据前端提交的查询条件进行数据库查询操作。在
高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长,现在需要对此方法进行缓存优化,提交系统性能
实现思路
- 改造DishController的list方法,先从Redis中获取菜品数据,如果有则直接返回,无需查询数据库;如果没有则查询数据库,并将查询到的菜品数据放到Redis中
- 改造DishController的save和update方法,加入清理缓存的逻辑(
这里要清除的原因是,如果你修改了一个商品的价格或者是新增了一个商品,但是你没有清理缓存,那么你再查询的时候,查询出的数据都是旧的数据,也就是脏数据)
@GetMapping("/list")
public R<List<DishDto>> list(Dish dish){
List<DishDto> dishDtoList = null;
// 动态构造一个key
String key = "dish_" + dish.getCategoryId() + "_" + dish.getStatus();
// 先从redis中获取缓存数据
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
if(dishDtoList != null){
// 如果存在,直接返回,无需查询数据库
log.info(key + "从redis中取出来");
return R.success(dishDtoList);
}
// 条件构造器
LambdaQueryWrapper<Dish> q = new LambdaQueryWrapper<>();
// 输入条件
q.eq(Dish::getStatus, 1);
q.eq(dish.getName() != null, Dish::getName, dish.getName());
q.eq(dish.getCategoryId() != null, Dish::getCategoryId, dish.getCategoryId());
q.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
// 查询
List<Dish> list = dishService.list(q);
dishDtoList = list.stream().map((item)->{
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(item, dishDto);
Category category = categoryService.getById(item.getCategoryId());
if(category != null){
String categoryName = category.getName();
dishDto.setCategoryName(categoryName);
}
LambdaQueryWrapper<DishFlavor> qw = new LambdaQueryWrapper<>();
qw.eq(DishFlavor::getDishId, dishDto.getId());
List<DishFlavor> list1 = dishFlavorService.list(qw);
dishDto.setFlavors(list1);
return dishDto;
}).collect(Collectors.toList());
// 如果不存在,需要查询数据库,将查询到的菜品数据缓存到redis,并设置60分钟
redisTemplate.opsForValue().set(key, dishDtoList, 60, TimeUnit.MINUTES);
return R.success(dishDtoList);
}
5、清理缓存
在使用缓存过程中,要注意保证数据库中的数据和缓存中的数据一致,如果数据库中的数据发生变化,需要及时清理缓存数据
// 清理所有菜品的缓存数据
// Set keys = redisTemplate.keys("dish_*");
// edisTemplate.delete(keys);
// 精确清理缓存
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
6、Spring Cache


6.1、CachePut注解
/**
* CachePut将方法返回值放入缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
* @param user
* @return
*/
@CachePut(value = "userCache", key = "#user.id")
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
这个里还学到一个注解这里
key支持的一种写法#user.id,可以动态的获取到某些对象的某个字段或者是方法
在debug的过程中可以看到这里的缓存其实是存储到了chacheManager里面了,当你重新启动这个项目的时候,它就会全部更新掉,但是后面使用redis就不会出现这种问题了
6.2、CacheEvict注解
/**
* 清理指定缓存
* value:缓存的名称
* @param id
*/
@CacheEvict(value = "userCache", key = "#id")
// 多种写法一个意思
//@CacheEvict(value = "userCache", key = "#root.args[0]")
//@CacheEvict(value = "userCache", key = "#p0")
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}
@CacheEvict(value = "userCache", key = "#user.id")
@PutMapping
public User update(User user){
userService.updateById(user);
return user;
}
这里适用于更新和删除的时候要使用这个注解清除缓存,防止脏数据
@CacheEvict(value = “xxx”, allEntries = true)这个可以将这个value下的所有的缓存都删除掉
6.3、Cacheable注解
/**
* Cacheable:在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据
* 若没有数据,就缓存数据
* value: 缓存的名称:每个缓存名称下面可以有多个key
* key:缓存的key
* condition:条件,满足条件才会缓存数据
* unless:不满足条件才会缓存数据
* @param id
* @return
*/
@Cacheable(value = "userCache", key = "#id", unless = "#result == null")
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
@Cacheable(value = "userCache", key = "#user.id + '_' + #user.name")
@GetMapping("/list")
public List<User> list(User user){
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(user.getId() != null,User::getId,user.getId());
queryWrapper.eq(user.getName() != null,User::getName,user.getName());
List<User> list = userService.list(queryWrapper);
return list;
}
偏向于查询语句,byId或者是list
6.4、使用Redis作为缓存产品
操作步骤
- 导入maven坐标
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-cacheartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
- 配置application.yaml文件
cache:
redis:
time-to-live: 1800000 #设置缓存过期时间,可选
- 在启动类上加入@EnableCaching注解,开启缓存注解功能

4. 在Controller的方法上加入@Cacheable、@CacheEvict等注解进行缓存操作
7、缓存套餐数据
前面实现了移动端套餐查看功能,对应的服务端方法为SetmealController的list方法,此方法会根据前提提交的查询条件进行数据库查询操作,在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应事件增长。需要对此方法进行缓存优化,提高系统的性能
实现思路
- 导入Spring Cache和Redis相关maven坐标
- 在application.yaml中配置缓存数据的过期时间
- 在启动类上加入@EnableCaching注解,开启缓存注解功能
- 在SetmealController的list方法上加入@Cacheable注解
- 在SetmealCntroller的save和delete方法上加入CacheEvict注解
@PostMapping
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> save(@RequestBody SetmealDto setmealDto){
log.info("套餐信息:{}", setmealDto);
setmealService.saveWithDish(setmealDto);
return R.success("保存成功");
}
@GetMapping("/list")
@Cacheable(value = "setmealCache", key = "#setmeal.categoryId + '_' + #setmeal.status")
public R<List<Setmeal>> list(Setmeal setmeal){
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(setmeal.getCategoryId() != null, Setmeal::getCategoryId, setmeal.getCategoryId());
queryWrapper.eq(setmeal.getStatus() != null, Setmeal::getStatus, setmeal.getStatus());
queryWrapper.orderByDesc(Setmeal::getUpdateTime);
List<Setmeal> list = setmealService.list(queryWrapper);
return R.success(list);
}
这里最终还是简单的了解一下,做完这个项目后再系统的了解一下redis
这里还要让common中的R实现一下序列化的接口,要不然无法直接将R数据进行序列化操作存储或者从redis取出数据
六、读写分离

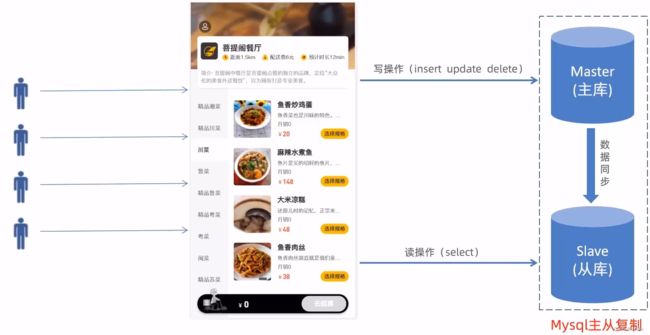
1、MySql主从复制
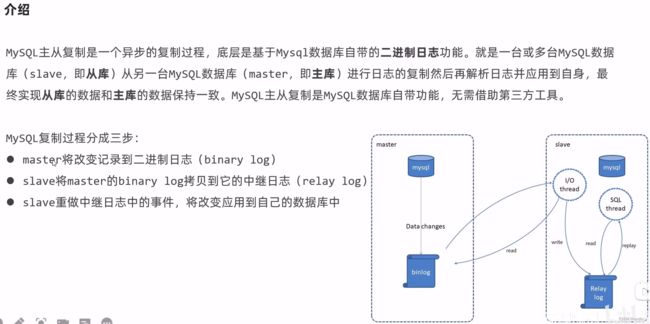
实际生产中,从库可能有很多个
2、配置
准备
:首先你要拥有两个数据库,可以通过创建两个虚拟机,使用docker,或者一个本地一个虚拟机都可以,要求都安装了mysql数据库,并且正常运行,我这里是使用了创建一个数据库然后克隆了一下
配置步骤(主库):
- 修改mysql数据库的配置文件 /etc/my.cnf
[mysqld]
log-bin=mysql-bin
server-id=100
- 重启数据库
systemctl restart mysqld
- 登录mysql数据库,指定一下sql
grant replication slave on *.* to 'xiaoming'@'%'identified by 'Root@123456';
注:上面SQL的作用是创建一个用户xiaoming,密码是Roor@123456,并且给xiaoming用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是salve必须被master授权具有该权限的用户,才能通过该用户复制
- 执行以下sql,记录结果中file和position的值
show master status;

配置步骤(从库)
- 修改mysql数据库的配置文件 /etc/my.cnf
[mysqld]
server-id=101
- 重启数据库
systemctl restart mysqld
- 登录mysql数据库,执行下面sql
change master to master_host='192.168.84.129', master_user='xiaoming', master_password='Root@123456', master_log_file='mysql-bin.000002', master_log_pos=154;
start slave;
如果遇到下面这种问题。可能是克隆虚拟机的时候,有着相同的id,解决办法https://blog.csdn.net/mingknow/article/details/98061196

- 执行
show slave status;
这时候我们可以测试一下,同步一致!!!very good!!!

3、读写分离案例

入门案例
使用Sharding-JDBC实现读写分离步骤:
- 导入maven坐标
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
- 在配置文件中配置读写分离规则
- 在配置文件中配置允许bean定义覆盖配置项
server:
port: 8080
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.84.129:3306/rw?characterEncoding=utf-8
username: root
password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.84.130:3306/rw?characterEncoding=utf-8
username: root
password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true # 自定义覆盖配置项
4、项目实现读写分离
我这里使用的就是案例中用的那两个数据库
实现步骤
- 导入坐标
- 配置文件
server:
port: 8080
spring:
application:
name: reggie_take_out
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.84.129:3306/reggie?characterEncoding=utf-8&useSSL=false
username: root
password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.84.130:3306/reggie?characterEncoding=utf-8&useSSL=false
username: root
password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true
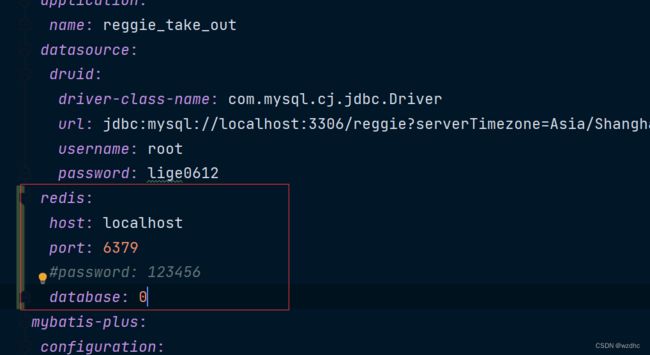
redis:
host: localhost
port: 6379
#password: 123456
database: 0
cache:
redis:
time-to-live: 1800000
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
#标准输出日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
reggie:
path: D:\img\
这个我觉得要十分注意那个缩进一定要规规整整的,要不然会有很多意想不到的错误,别问,问就是错过了
七、Nginx
1、概述

2、Nginx下载和安装
安装过程
- 安装依赖包
yum -y install gcc pcre-devel zlib-devel openssl openssl-devel
- 下载Nginx安装包
wget https://nginx.org/download/nginx-1.16.1.tar.gz --no-check-certificate
- 解压
tar -zxvf nginx-1.16.1.tar.gz
- 进入文件夹
nginx-1.16.1
./configure --prefix=/usr/local/nginx
- 然后执行
make && mkdir install
3、Nginx目录结构

4、nginx常用命令
- 查看Nginx版本可以使用命令
./nginx -v
![]()
- 检查配置文件正确性
./nginx -t

- 启动nginx
./nginx
启动完以后,关闭了防火墙就可以访问你虚拟机的ip地址了,出现下面这个就是成功了

- 停止Nginx
./nginx -s stop
- 重新加载配置文件
./nginx -s reload
- 修改/etc/profile

然后source /etc/profile,之后就可以在任何目录下使用nginx的命令了
5、Nginx配置文件结构

6、Nginx具体应用
部署静态资源

反向代理

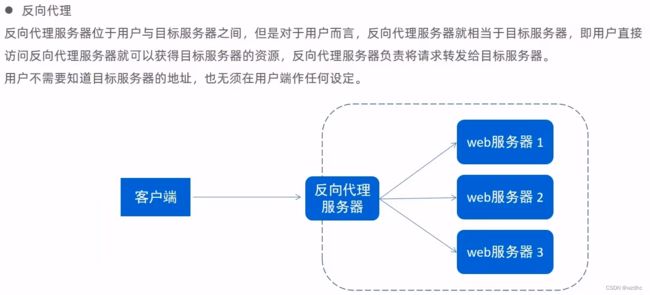

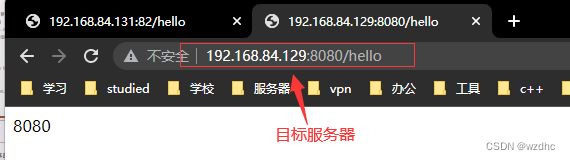
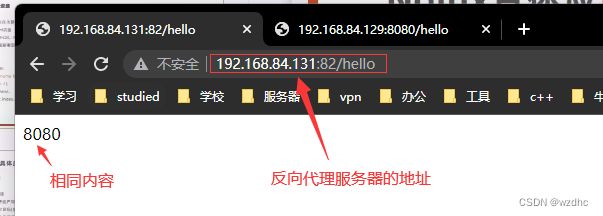
通过直接访问反向代理服务器的地址加端口号,就可以直接跳到目标服务器,搜嘎

负载均衡
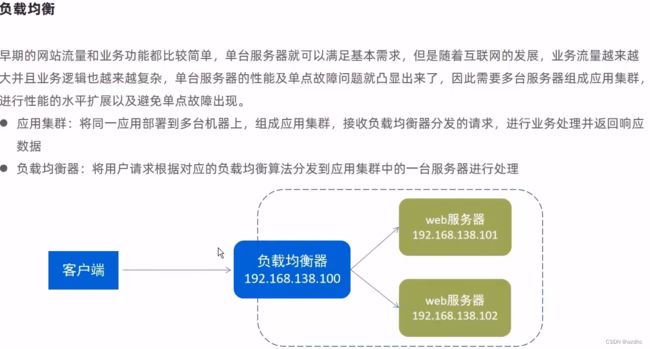


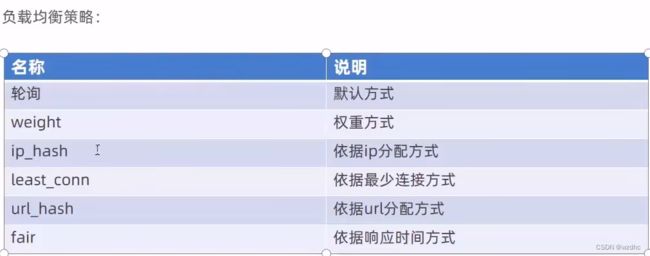
这里用两个不同的端口号来模拟两个服务器,默认采取的是轮询算法,就是两个端口号会轮流着访问
八、前后端分离开发


1、YApi

部署
- 下载源码https://github.com/YMFE/yapi
- 检查环境
nodejs(7.6+)
mongodb(2.6+)教程https://blog.csdn.net/weixin_41466575/article/details/105326230
git
- 我看的教程https://zhuanlan.zhihu.com/p/488933573
- mkdir yapi
- cd yapi
- //或者下载 zip 包解压到 vendors 目录(clone 整个仓库大概 140+ M,可以通过
git clone --depth=1 https://github.com/YMFE/yapi.git vendors命令减少,大概 10+ M)- git clone https://github.com/YMFE/yapi.git vendors
//复制完成后请修改相关配置- cp vendors/config_example.json ./config.json
- cd vendors
- npm install --production --registry https://registry.npm.taobao.org
- npm run install-server //安装程序会初始化数据库索引和管理员账号,管理员账号名可在 config.json 配置
- node server/app.js //启动服务器后,请访问 127.0.0.1:{config.json配置的端口},初次运行会有个编译的过程,请耐心等候
这个弄好了以后就可以直接使用了,而且还可以把接口文档导出,还可以把postman和swagger中生成的接口文档导入,之前见过接口文档,原来是这么做的
2、Swagger


操作步骤
- 导入坐标
<dependency>
<groupId>com.github.xiaoymingroupId>
<artifactId>knife4j-spring-boot-starterartifactId>
<version>3.0.3version>
dependency>
- 导入knife4j相关配置(WebMvcConfig)
@Slf4j
@Configuration
@EnableSwagger2
@EnableKnife4j
public class WebMvcConfig extends WebMvcConfigurationSupport {
/*
* 设置静态资源映射
* */
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始进行静态资源映射");
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/");
registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
}
/**
* 扩展mvc框架的消息转换器
* @param converters
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器...");
// 创建消息转换器对象
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
// 设置对象转换器,底层使用Jackson将Java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
// 将上面的消息转换器对象追加到mvc框架的转换器集合中
converters.add(0, messageConverter);
}
@Bean
public Docket createRestApi() {
// 文档类型
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.lzy.reggie.controller"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("瑞吉外卖")
.version("1.0")
.description("瑞吉外卖接口文档")
.build();
}
}
- 设置静态资源映射(WebMvcConfig类中的addResourceHandlers方法),否则接口文档页面无法访问
registry.addResourceHandler("doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
- 在LoginCheckFilter中设置不需要处理的请求路径
"/doc.html",
"/webjars/**",
"/swagger-resources",
"/v2/api-docs"
- 然后访问

常用注解

九、项目部署
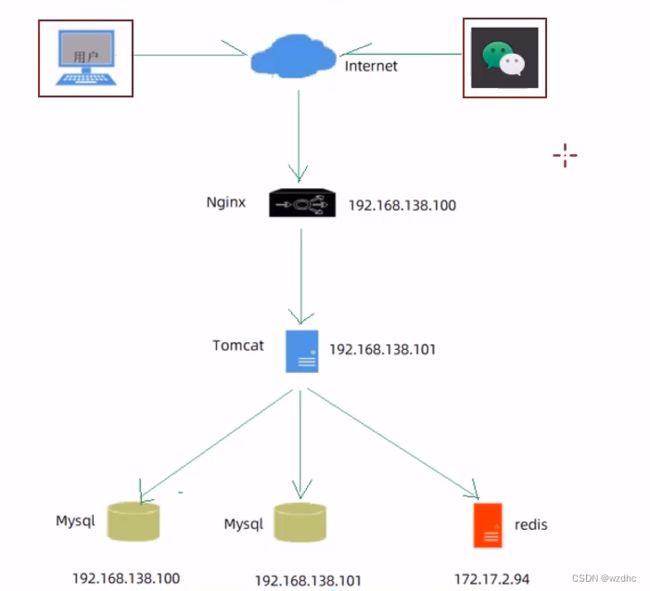
1、环境准备

自己又部署了一遍,感觉不错没啥问题
2、部署前端项目(服务器A)
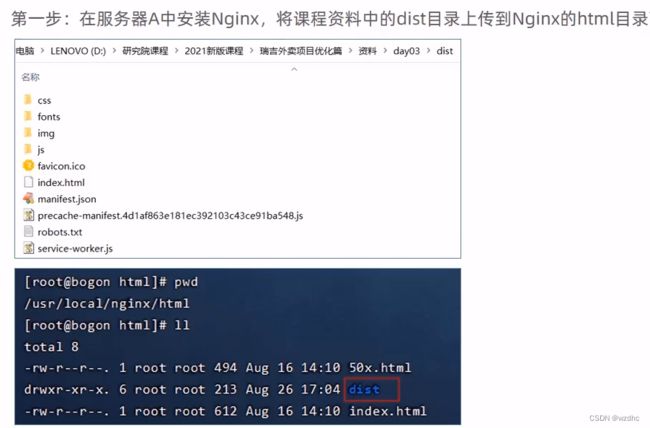
第二步,修改一下nginx的配置文件

然后重启一下nginx,再次访问nginx首页
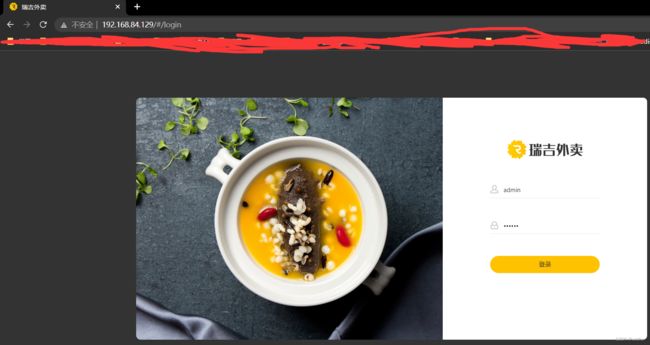

先用rewite对路径进行一下重写(处理掉了api),然后再通过反向代理到其他的服务器上,我觉得好神奇啊,好厉害!!!
3、部署后端项目(服务器B)
创建一个文件夹javaapp,通过git将代码拉取到里面

将资料中提供的reggieStart.sh文件上传到服务器B上
#!/bin/sh
echo =================================
echo 自动化部署脚本启动
echo =================================
echo 停止原来运行中的工程
APP_NAME=reggie_take_out
tpid=`ps -ef|grep $APP_NAME|grep -v grep|grep -v kill|awk '{print $2}'`
if [ ${tpid} ]; then
echo 'Stop Process...'
kill -15 $tpid
fi
sleep 2
tpid=`ps -ef|grep $APP_NAME|grep -v grep|grep -v kill|awk '{print $2}'`
if [ ${tpid} ]; then
echo 'Kill Process!'
kill -9 $tpid
else
echo 'Stop Success!'
fi
echo 准备从Git仓库拉取最新代码
cd /usr/local/javaapp/reggie_take_out
echo 开始从Git仓库拉取最新代码
git pull
echo 代码拉取完成
echo 开始打包
output=`mvn clean package -Dmaven.test.skip=true`
cd target
echo 启动项目
nohup java -jar reggie_take_out-1.0-SNAPSHOT.jar &> reggie_take_out.log &
echo 项目启动完成
根据你自己的情况,修改shell脚本
最后需要修改一下后端application.yml中的那个图片的路径,然后在对应虚拟机的位置将图片放进去就可以了正常的看到图片了,完结撒花花!!!