DeepSort论文翻译-中英对照
SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC
简单在线和实时跟踪与深度关联度量
目录
目录
摘要:
1.介绍:
2.使用深度关联度量的SORT算法
2.1.航迹处理与状态估计
2.2.分配问题
2.3级联匹配
2.4深度表现描述子(CNN)
3.实验
4.总结
参考文献:
摘要:
Simple Online and Realtime Tracking (SORT) is a pragmatic approach to multiple object tracking with a focus on simple, effective algorithms. In this paper, we integrate appearance information to improve the performance of SORT. Due to this extension we are able to track objects through longer periods of occlusions, effectively reducing the number of identity switches. In spirit of the original framework we place much of the computational complexity into an offline pre-training stage where we learn a deep association metric on a largescale person re-identification dataset. During online application, we establish measurement-to-track associations using nearest neighbor queries in visual appearance space. Experimental evaluation shows that our extensions reduce the number of identity switches by 45%, achieving overall competitive performance at high frame rates.
简单线和实时跟踪(SORT)是一种实用的多目标跟踪方法,重点是简单、有效的算法。在本文中,我们将外观信息集成起来,以提高SORT的性能。由于此扩展,我们能够通过更长的闭塞周期来跟踪对象,从而有效地减少身份切换的数量。本着原有框架的精神,我们将大量的计算复杂性放在一个离线的预训练阶段,该阶段我们在大规模的人重新识别数据集中学习深度关联度量。在线应用中,我们在视觉外观空间中使用最近邻查询建立测量到跟踪关联.实验评估表明,我们的扩展将身份切换次数减少了45%,实现了在高帧速率下的总体有竞争力的性能。

1.介绍:
Due to recent progress in object detection, tracking-bydetection has become the leading paradigm in multiple object tracking. Within this paradigm, object trajectories are usually found in a global optimization problem that processes entire video batches at once. For example, flow network formulations [1, 2, 3] and probabilistic graphical models [4, 5, 6, 7] have become popular frameworks of this type. However, due to batch processing, these methods are not applicable in online scenarios where a target identity must be available at each time step. More traditional methods are Multiple Hypothesis Tracking (MHT) [8] and the Joint Probabilistic Data Association Filter (JPDAF) [9]. These methods perform data association on a frame-by-frame basis. In the JPDAF, a single state hypothesis is generated by weighting individual measurements by their association likelihoods. In MHT, all possible hypotheses are tracked, but pruning schemes must be applied for computational tractability. Both methods have recently been revisited in a tracking-by-detection scenario [10, 11] and shown promising results. However, the performance of these methods comes at increased computational and implementation complexity.
由于最近在目标检测方面的进展,通过检测来跟踪已经成为多目标跟踪的主导范式。在这个范例中,对象轨迹通常出现在全局优化问题中,该问题同时处理整个视频批次。例如,流网络公式[1,2,3]和概率图形模型[4,5,6,7]已成为这方面的流行框架。 但是,由于批处理,这些方法不适用于在每个时间步长必须有目标标识的在线场景中。更传统的方法是多假设跟踪(MHT)[8]和联合概率数据关联滤波器(JPDAF)[9]。这些方法在逐帧的基础上执行数据关联. 在JPACC中,单状态假设是通过加权个体测量的关联概率来产生的。在MHT中,所有可能的假设都会被跟踪,但为了便于计算,必须采用剪枝方案。最近,这两种方法都在检测跟踪场景[10,11]中被重新研究,并显示出了有希望的结果。然而,这些方法的性能需要更多的计算量和实现复杂性。
Simple online and realtime tracking (SORT) [12] is a much simpler framework that performs Kalman filtering in image space and frame-by-frame data association using the Hungarian method with an association metric that measures bounding box overlap. This simple approach achieves favorable performance at high frame rates. On the MOT challenge dataset [13], SORT with a state-of-the-art people detector [14] ranks on average higher than MHT on standard detections.This not only underlines the influence of object detector performance on overall tracking results, but is also an important insight from a practitioners point of view.
简单线和实时跟踪(SORT)[12]是一个更简单的框架,它在图像空间中执行卡尔曼滤波,并使用匈牙利方法逐帧关联数据,使用关联度量度量边界框重叠。这种简单的方法在高帧速率下获得了良好的性能。在MOT挑战数据集[13]中,使用最先进的人员检测器[14],SORT平均排名高于标准检测上的MHT。这不仅强调了目标检测器性能对总体跟踪结果的影响,而且也是从业者的一个重要见解。
While achieving overall good performance in terms of tracking precision and accuracy, SORT returns a relatively high number of identity switches. This is, because the employed association metric is only accurate when state estimation uncertainty is low. Therefore, SORT has a deficiency in tracking through occlusions as they typically appear in frontal-view camera scenes. We overcome this issue by replacing the association metric with a more informed metric that combines motion and appearance information. In particular, we apply a convolutional neural network (CNN) that has been trained to discriminate pedestrians on a large-scale person re-identification dataset. Through integration of this network we increase robustness against misses and occlusions while keeping the system easy to implement, efficient, and applicable to online scenarios. Our code and a pre-trained CNN model are made publicly available to facilitate research experimentation and practical application development.
虽然在跟踪精度和准确性方面取得了总体良好的性能,但SORT返回的身份切换次数相对较多。这是因为所使用的关联度量只有在状态估计不确定度较低时才是准确的。因此,SORT在通过遮挡跟踪方面有缺陷,因为它们通常出现在正面视角的摄像机场景中。我们通过将关联度量替换为结合运动和外观信息的更有见地的度量来克服这一问题。特别是,我们应用了一种卷积神经网络(Cnn),该神经网络已被训练用于在大规模的人的再识别数据集上识别行人。 通过这种网络的集成,我们提高了对错误和遮挡的鲁棒性,同时使系统易于实现、有效和适用于在线场景。我们的代码和预先训练的cnn模型是公开提供的,以促进研究、实验和实际应用开发。
2.使用深度关联度量的SORT算法
We adopt a conventional single hypothesis tracking methodology with recursive Kalman filtering and frame-by-frame data association. In the following section we describe the core components of this system in greater detail.
我们采用传统的单假设跟踪方法,采用递推卡尔曼滤波和逐帧数据关联的方法.在下一节中,我们将更详细地描述本系统的核心组件。
2.1.航迹处理与状态估计

跟踪处理和卡尔曼滤波框架与[12]中的原始公式基本相同。我们假设了一个非常普遍的跟踪场景,在这种情况下,相机是不加标记的,而且没有自我运动信息可用。虽然这些情况对过滤框架构成了挑战,但它是最近多目标跟踪基准[15]中考虑的最常见的设置。因此,我们的跟踪场景在八维状态空间(u,v,r,h,x`,y`r`,h`)上定义,其中包含包围盒中心位置(u,v),纵横比γ,高度h和它们各自在图像坐标中的速度。我们使用了一个常速度运动的标准卡尔曼滤波和线性观测模型,其中我们以边界坐标(u,v,γ,h)为直接值作为对物体状态的观察。
For each track k we count the number of frames since the last successful measurement association ak. This counter is incremented during Kalman filter prediction and reset to 0 when the track has been associated with a measurement.Tracks that exceed a predefined maximum age Amax are considered to have left the scene and are deleted from the track set. New track hypotheses are initiated for each detection that cannot be associated to an existing track. These new tracks are classified as tentative during their first three frames. During this time, we expect a successful measurement association at each time step. Tracks that are not successfully associated to a measurement within their first three frames are deleted.
对于每个跟踪器k,我们计算自上一次成功的测量关联AK以来的帧数。此计数器在kalman滤波预测期间递增,并在跟踪成功时重置为0。其与测量相关联。超过预定义的最大范围Amax的跟踪对象被认为已经离开了场景并且被从轨迹集中删除。对于不能与现有轨道相关联的每个检测,都会启动新的轨道假设。这些新的跟踪器在他们的前三帧被归类为试探性的。在这段时间里,我们期望在每一时间步骤中都有一个成功的测量关联。未成功与其前三帧内的度量相关联的轨道将被删除。
2.2.分配问题
A conventional way to solve the association between the predicted Kalman states and newly arrived measurements is to build an assignment problem that can be solved using the Hungarian algorithm. Into this problem formulation we integrate motion and appearance information through combination of two appropriate metrics.To incorporate motion information we use the (squared) Mahalanobis distance between predicted Kalman states and newly arrived measurements:
传统的解决预测Kalman状态与新到量之间关联的方法是建立一个可以用匈牙利算法求解的分配问题。在这个问题公式中,我们通过两个适当的度量组合来集成运动和外观信息。为了结合运动信息,我们使用预测的卡尔曼状态和新到达的测量之间的(平方)马哈拉诺比斯(Mahalanobis)距离:
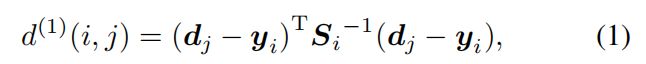
注:

where we denote the projection of the i-th track distribution into measurement space by (yi;Si) and the j-th bounding box detection by dj . The Mahalanobis distance takes state estimation uncertainty into account by measuring how many standard deviations the detection is away from the mean track location. Further, using this metric it is possible to exclude unlikely associations by thresholding the Mahalanobis distance at a 95% confidence interval computed from the inverse 2 distribution. We denote this decision with an indicator
其中,我们用(yi,Si)表示第 i 个跟踪器到度量空间的预测,用dj表示第j个检测框。马氏距离通过测量检测到的距离平均轨迹位置有多少个标准差将状态估计的不确定性考虑在内。此外,利用这一度量,可以通过在95%置信区间上从逆χ2分布中计算出的Mahalanobis距离来排除不可能的关联。我们用一个指标来表示这个决定
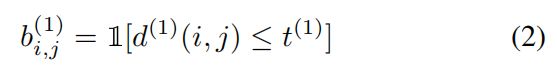
that evaluates to 1 if the association between the i-th track and j-th detection is admissible. For our four dimensional measurement space the corresponding Mahalanobis threshold is t(1) = 9.4877.
如果第i个跟踪器和第j个检测之间的关联是允许的,则结果为1。对于我们的四维测量空间(w,v,r,h),对应的Mahalanobis阈值为t(1)= 9.4877。
While the Mahalanobis distance is a suitable association metric when motion uncertainty is low, in our image-space problem formulation the predicted state distribution obtained from the Kalman filtering framework provides only a rough estimate of the object location. In particular, unaccounted camera motion can introduce rapid displacements in the image plane, making the Mahalanobis distance a rather uninformed metric for tracking through occlusions. Therefore, we integrate a second metric into the assignment problem.
当运动不确定性较低时,马氏距离是一种合适的关联度量,但在我们的图像空间问题公式中,从卡尔曼滤波框架获得的预测状态分布仅提供了对象位置的粗略估计。尤其是,无法解释的摄像机运动可能会在图像平面中引入快速位移,从而使马氏距离成为用于跟踪遮挡的相当不明智的度量。因此,我们将第二个指标集成到分配问题中。

对于每个边界框检测dj,我们计算|| rj || = 1的外观描述符rj。此外,对于每个轨道k,我们保留最后Lk = 100个相关外观描述符的集合{Rk}。然后,我们的第二个度量将测量外观空间中第i个磁道和第j个检测之间的最小余弦距离:
![]()
Again, we introduce a binary variable to indicate if an association is admissible according to this metric
同样的,我们引入一个二进制变量来指示根据该指标是否允许关联

and we find a suitable threshold for this indicator on a separate training dataset. In practice, we apply a pre-trained CNN to compute bounding box appearance descriptors. The architecture of this network is described in Section 2.4.
我们在单独的训练数据集上为此指标找到了合适的阈值。在实践中,我们应用预训练的CNN来计算边界框外观描述符(box appearance descriptors)。该网络的体系结构在2.4节中描述。
In combination, both metrics complement each other by serving different aspects of the assignment problem. On the one hand, the Mahalanobis distance provides information about possible object locations based on motion that are particularly useful for short-term predictions. On the other hand, the cosine distance considers appearance information that are particularly useful to recover identities after longterm occlusions, when motion is less discriminative. To build the association problem we combine both metrics using a weighted sum.
通过结合使用分配问题的不同方面,两个指标可以相互补充。一方面,马哈拉诺比斯距离基于运动提供有关可能的物体位置的信息,这对于短期预测特别有用。另一方面,当运动的判别力较弱时,余弦距离会考虑外观信息,这些信息对于长时间遮挡后恢复身份特别有用。为了建立关联问题,我们使用加权总和将两个指标结合起来
![]()
where we call an association admissible if it is within the gating region of both metrics:
如果它在两个指标的门控区域之内,我们称其为可接受的关联:
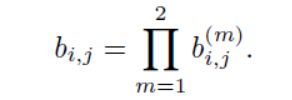
The influence of each metric on the combined association cost can be controlled through hyperparameter λ . During our experiments we found that setting λ= 0 is a reasonable choice when there is substantial camera motion. In this setting, only appearance information are used in the association cost term.However, the Mahalanobis gate is still used to disregarded infeasible assignments based on possible object locations inferred by the Kalman filter.
可以通过超参数λ来控制每个指标对合并成本的影响。在我们的实验过程中,我们发现当摄像机运动较大时,将λ=0是合理的选择。在此设置中,关联费用项中仅使用外观信息。然而,基于由卡尔曼滤波器推断出的可能的物体位置,马氏距离仍然被用来忽略不可行的分配。
注:


2.3级联匹配
Instead of solving for measurement-to-track associations in a global assignment problem, we introduce a cascade that solves a series of subproblems. To motivate this approach, consider the following situation: When an object is occluded for a longer period of time, subsequent Kalman filter predictions increase the uncertainty associated with the object location.Consequently, probability mass spreads out in state space and the observation likelihood becomes less peaked. Intuitively, the association metric should account for this spread of probability mass by increasing the measurement-to-track distance. Counterintuitively, when two tracks compete for the same detection, the Mahalanobis distance favors larger uncertainty, because it effectively reduces the distance in standard deviations of any detection towards the projected track mean.This is an undesired behavior as it can lead to increased track fragmentations and unstable tracks. Therefore, we introduce a matching cascade that gives priority to more frequently seen objects to encode our notion of probability spread in the association likelihood.
为了解决全局分配问题中的测量与跟踪关联,我们引入了一个级联来解决一系列子问题。为了激发这种方法,请考虑以下情况:当物体被长时间遮挡时,后续的卡尔曼滤波器预测会增加与物体位置相关的不确定性,因此,概率质量在状态空间中扩散,观察似然性变得不那么尖锐。直观地,关联度量应通过增加测量到跟踪器的距离来考虑概率质量的这种扩展。违反直觉的是,当两个跟踪器竞争同一检测框时,马氏距离会带来较大的不确定性,因为它有效地减小了任何检测的标准偏差与投影轨道均值之间的距离,这是不希望有的行为,因为它可能导致轨道碎片增加和不稳定的轨道。因此,我们引入了一个级联匹配,该级联将优先级更高的常见对象编码为关联可能性中的概率散布概念。

T是物体跟踪框集合
D是物体检测框集合
1.C矩阵存放所有物体跟踪i与物体检测j之间距离的计算结果(公式5的计算结果,即马氏距离+余弦距离)
2.B矩阵存放所有物体跟踪i与物体检测j之间是否关联的判断(公式6的计算结果,仅为0/1)
3.关联集合M初始化为{}
4.将找不到匹配的物体检测集合初始化为U
5.从刚刚匹配成功的跟踪器循环遍历到最多已经有Amax 次没有匹配的跟踪器
6.选择满足条件的跟踪器集合Tn
7.根据最小成本算法计算出Tn与物体检测j关联成功产生集合[xi,j]
8.更新M为匹配成功的(物体跟踪i,物体检测j) 集合
9.从U中去除已经匹配成功的物体检测j
10.循环
11.返回 M U 两个集合
M是匹配到的(检测框-跟踪框)的集合
U是没匹配到的检测框
Listing 1 outlines our matching algorithm. As input we provide the set of track T and detection D indices as well as the maximum age Amax. In lines 1 and 2 we compute the association cost matrix and the matrix of admissible associations.We then iterate over track age n to solve a linear assignment problem for tracks of increasing age. In line 6 we select the subset of tracks Tn that have not been associated with a detection in the last n frames. In line 7 we solve the linear assignment between tracks in Tn and unmatched detections U.
上表概述了我们的匹配算法。作为输入,我们提供跟踪框T和检测框D的集合以及最大年龄Amax的集合。在第1行和第2行中,我们计算了关联成本矩阵(公式5)和可允许关联的矩阵(公式6),然后对轨道寿命n进行迭代,以解决随着年龄增长的轨道的线性分配问题。在第6行中,我们选择在最近n帧中未与检测框相关联的跟踪框Tn的子集。在第7行中,我们解决了Tn中的跟踪框与不匹配的检测框U之间的线性分配。
In lines 8 and 9 we update the set of matches and unmatched detections, which we return after completion in line 11. Note that this matching cascade gives priority to tracks of smaller age, i.e., tracks that have been seen more recently.
在第8行和第9行中,我们更新了匹配项M和未匹配的检测框集合U,并在第11行中完成后返回。请注意,此匹配级联将优先考虑年龄较小的跟踪器,即最近匹配成功的跟踪器。
In a final matching stage, we run intersection over union association as proposed in the original SORT algorithm [12] on the set of unconfirmed and unmatched tracks of age n = 1.This helps to to account for sudden appearance changes, e.g., due to partial occlusion with static scene geometry, and to increase robustness against erroneous initialization.
在最后的匹配阶段,我们对原始的SORT算法[12]中提出的联合关联进行相交,对年龄n = 1的一组未经确认和不匹配的轨道进行处理。这有助于解决突然出现的外观变化,例如由于具有静态场景几何形状的部分遮挡,并提高了针对错误初始化的鲁棒性。
注:
如果一条轨迹被遮挡了一段较长的时间,那么在kalman滤波器的不断预测中就会导致概率弥散。那么假设现在有两条轨迹竞争同一个detection,那么那条遮挡时间长的往往得到马氏距离更小,使detection倾向于匹配给丢失时间更长的轨迹,但是直观上,该detection应该匹配给时间上最近的轨迹。导致这种现象的原因正是由于kalman滤波器连续预测没法更新导致的概率弥散。这么理解吧,假设本来协方差矩阵是一个正态分布,那么连续的预测不更新就会导致这个正态分布的方差越来越大,那么离均值欧氏距离远的点可能和之前分布中离得较近的点获得同样的马氏距离值。
所以文中才引入了级联匹配的策略让'more frequently seen objects'匹配的优先级更高(将遮挡时间按等级分层,遮挡时间越小的匹配等级更高,即更容易被匹配)。这样每次匹配的时候考虑的都是遮挡时间相同的轨迹,就不存在上面说的问题了。
匹配的最后阶段还对unconfirmed和age=1的未匹配轨迹进行基于IoU的匹配。这可以缓解因为表观突变或者部分遮挡导致的较大变化。当然有好处就有坏处,这样做也有可能导致一些新产生的轨迹被连接到了一些旧的轨迹上。但这种情况较少。
2.4深度表现描述子(CNN)
By using simple nearest neighbor queries without additional metric learning, successful application of our method requires a well-discriminating feature embedding to be trained offline, before the actual online tracking application. To this end, we employ a CNN that has been trained on a large-scale person re-identification dataset [21] that contains over 1,100,000 images of 1,261 pedestrians, making it well suited for deep metric learning in a people tracking context.
通过使用简单的最近邻查询而不进行额外的度量学习,我们方法的成功应用要求在实际的在线跟踪应用之前,将具有良好区分性的功能嵌入脱机训练。为此,我们采用了经过大规模人员重新识别数据集[21]训练的CNN,该数据集包含1,261位行人的1,100,000多张图像,使其非常适合在人员跟踪环境中进行深度度量学习。
The CNN architecture of our network is shown in Table 1.In summary, we employ a wide residual network [22] with two convolutional layers followed by six residual blocks. The global feauture map of dimensionality 128 is computed in dense layer 10. A final batch and l2 normalization projects features onto the unit hypersphere to be compatible with our cosine appearance metric.In total, the network has 2,800,864 parameters and one forward pass of 32 bounding boxes takes approximately 30 ms on an Nvidia GeForce GTX 1050 mobile GPU. Thus, this network is well suited for online tracking, provided that a modern GPU is available.While the details of our training procedure are out of the scope of this paper, we provide a pretrained model in our GitHub repository 1 along with a script that can be used to generate features.
表1给出了我们网络的CNN体系结构。总之,我们使用了一个宽残差网络[22],该网络具有两个卷积层和六个残差块。维度128的全局特征图是在全链接层10中计算的。最后一批和l2归一化将特征投影到单位超球面上,以与我们的余弦外观度量兼容。该网络总共具有2,800,864个参数和一个32边界的正向传递Nvidia GeForce GTX 1050移动GPU上大约需要30毫秒。因此,只要有可用的现代GPU,此网络非常适合在线跟踪。尽管我们的培训过程的详细信息不在本文讨论范围之内,但我们在GitHub存储库1中提供了一个经过预训练的模型,以及一个可用于生成功能的脚本。

3.实验
(基本为机翻)
We assess the performance of our tracker on the MOT16 benchmark [15]. This benchmark evaluates tracking performance on seven challenging test sequences, including frontal-view scenes with moving camera as well as top-down surveillance setups. As input to our tracker we rely on detections provided by Yu et al. [16]. They have trained a Faster RCNN on a collection of public and private datasets to provide excellent performance. For a fair comparison, we have re-run SORT on the same detections.
我们根据MOT16基准[15]评估跟踪器的性能。该基准评估了七个挑战性测试序列的跟踪性能,包括具有移动摄像机的前视场景以及自上而下的监视设置。作为对跟踪器的输入,我们依靠Yu等人提供的检测结果。[16]。他们已经在一组公共和私有数据集上训练了Faster RCNN,以提供出色的性能。为了进行公平的比较,我们对相同的检测重新运行了SORT。
Evaluation on test sequences were carried out using λ = 0 and Amax = 30 frames. As in [16], detections have been thresholded at a confidence score of 0:3. The remaining parameters of our method have been found on separate training sequences which are provided by the benchmark. Evaluation is carried out according to the following metrics:
使用λ= 0和Amax = 30帧对测试序列进行评估。如[16]中所述,检测阈值的置信度为0.3。我们的方法的其余参数已在基准提供的单独训练序列中找到。评估是根据以下指标进行的:
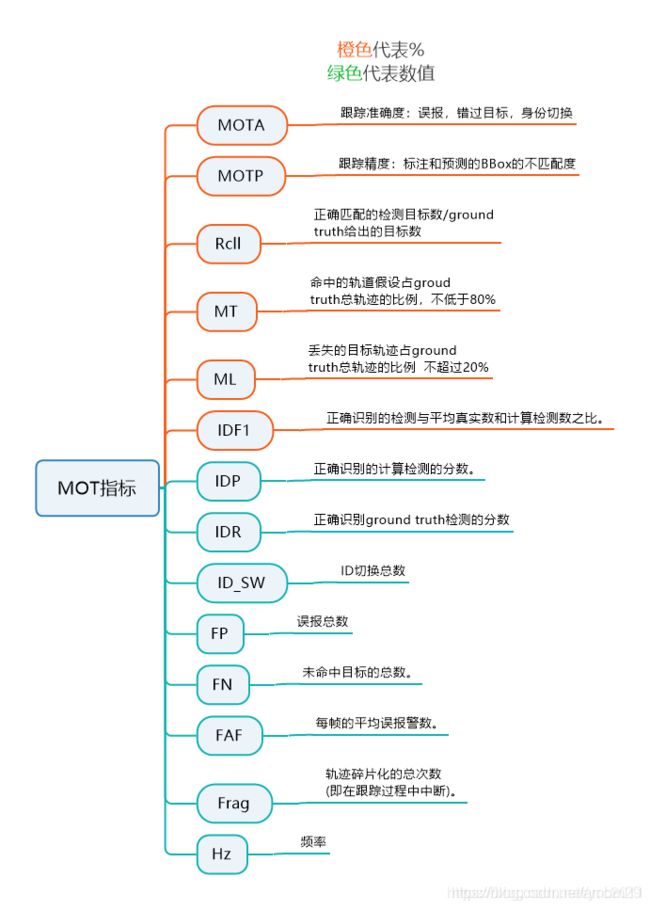
1.Multi-object tracking accuracy (MOTA): Summary of overall tracking accuracy in terms of false positives, false negatives and identity switches [23].
2.Multi-object tracking precision (MOTP): Summary of overall tracking precision in terms of bounding box overlap between ground-truth and reported location [23].
3.Mostly tracked (MT): Percentage of ground-truth tracks that have the same label for at least 80% of their life span.
4.Mostly lost(ML): Percentage of ground-truth tracks that are tracked for at most 20% of their life span.
5.dentity switches (ID): Number of times the reported identity of a ground-truth track changes.
6.Fragmentation (FM): Number of times a track is interrupted by a missing detection.
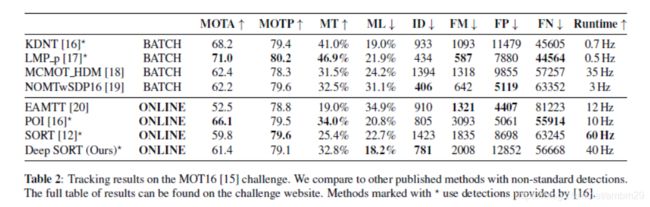
The results of our evaluation are shown in Table 2. Our adaptions successfully reduce the number of identity switches. In comparison to SORT, ID switches reduce from 1423 to 781.This is a decrease of approximately 45%
我们的评估结果显示在表2中。我们的调整成功地减少了 ID switches的数量。与SORT相比, ID switches从1423减少到781,减少了约45%
track fragmentation increase slightly due to maintaining object identities through occlusions and misses. We also see a significant increase in number of mostly tracked objects and a decrease of mostly lost objects. Overall, due to integration of appearance information we successfully maintain identities through longer occlusions. This can also be seen by qualitative analysis of the tracking output that we provide in the supplementary material. An exemplary output of our tracker is shown in Figure 1.
由于通过遮挡和遗漏来保持对象的身份,轨道碎片会稍微增加。我们还看到,大多数跟踪对象的数量显着增加,而大多数丢失对象的数量则减少了。总体而言,由于外观信息的整合,我们通过更长的遮挡成功地保持了身份。通过对补充材料中提供的跟踪输出进行定性分析,也可以看出这一点。我们的跟踪器的示例输出如图1所示。
Our method is also a strong competitor to other online tracking frameworks. In particular, our approach returns the fewest number of identity switches of all online methods while maintaining competitive MOTA scores, track fragmentations, and false negatives. The reported tracking accuracy is mostly impaired by a larger number of false positives.Given their overall impact on the MOTA score, applying a larger confidence threshold to the detections can potentially increase the reported performance of our algorithm by a large margin. However, visual inspection of the tracking output shows that these false positives are mostly generated from sporadic detector responses at static scene geometry. Due to our relatively large maximum allowed track age, these are more commonly joined to object trajectories. At the same time, we did not observe tracks jumping between false alarms frequently. Instead, the tracker commonly generated relatively stable, stationary tracks at the reported object location.
我们的方法也是其他在线跟踪框架的有力竞争者。特别是,我们的方法返回了所有在线方法中最少的身份切换次数,同时保持了竞争性的MOTA分数,跟踪碎片和假阴性。报告的跟踪准确性主要受到大量误报的损害,鉴于它们对MOTA分数的总体影响,对检测应用较大的置信度阈值可能会大大提高我们算法的报告性能。但是,对跟踪输出的视觉检查表明,这些误报主要是由静态场景几何中的零星检测器响应产生的。由于我们的最大允许跟踪年龄比较大,这些通常会与对象轨迹结合在一起。同时,我们没有观察到在错误警报之间频繁跳跃的轨迹。相反,跟踪器通常在报告的对象位置生成相对稳定的固定轨道。
Our implementation runs at approximately 20 Hz with roughly half of the time spent on feature generation. Therefore, given a modern GPU, the system remains computationally efficient and operates at real time.
我们的实现以大约20 Hz的频率运行,其中大约一半的时间花在了特征生成上。因此,在使用现代GPU的情况下,该系统保持了计算效率,并可以实时运行。
4.总结
(基本为机翻)
We have presented an extension to SORT that incorporates appearance information through a pre-trained association metric.Due to this extension, we are able to track through longer periods of occlusion, making SORT a strong competitor to state-of-the-art online tracking algorithms. Yet, the algorithm remains simple to implement and runs in real time.
我们提供了SORT的扩展功能,该功能通过预先训练的关联指标整合了外观信息,由于该扩展功能,我们能够跟踪更长的遮挡时间,从而使SORT成为最新在线跟踪的强大竞争对手算法。但是,该算法仍然易于实现并且可以实时运行。
参考文献:
1.匈牙利算法(简单易懂)
https://blog.csdn.net/sunny_hun/article/details/80627351
2.【算法分析】SORT/Deep SORT 物体跟踪算法解析
https://blog.csdn.net/HaoBBNuanMM/article/details/85555547