Pyts入门之时间序列的分类---SAX-VSM算法详解(三)
简介
相信不少人会被这个标题唬住,什么叫SAX-VSM算法,其实并不难,容我细细道来。
首先它来自2013年的"SAX-VSM: Interpretable Time Series Classification Using SAX and Vector Space Model"这篇论文,全称为Symbolic Aggregate approXimation in Vector Space Model(在向量空间模型中进行符号聚合近似),其实就是先进行符号聚合近似(SAX),再进行词向量的转换(VSM),细心的朋友应该会发现第一节中简单介绍过SAX。
看到这里,你们可能会想这和时间序列的分类有什么关系呢?
实际上,这是一种把时间序列转换为字母的特征表达,然后使用自然语言处理(NLP)的方法来进行分类的方法。
在Pyts中呢,对于SAX的实现使用了词袋模型,对于词向量的转换则使用了tf-idf模型,所以它的本质就是数字-词转换+Tf-idf。那么如何进行分类的任务呢?只要计算余弦相似度就可以了。
(余弦相似度的百度百科)
所以,它的算法步骤分为以下五步(假设分类有两类):
1.对训练集中每一个时间序列进行窗口滑动抽取子序列。
2.对每一个子序列进行词转换为字母序列。
3.对字母序列进行tf-idf的向量转换,得到两类tf-idf向量。
4.对新的时间序列进行同样的转换,分别计算和两类tf-idf向量的余弦相似度。
5.两个相似度哪个更高,则把新的时间序列分为哪一类。
那么我们接下来先讲两个基本概念:
滑动窗口
可能有些朋友对滑动窗口没什么概念。。它长下面这样子:

比如目前窗口大小为4,步长为1,就是以1个数字为单位,里面有4个数字一起往右滑动,所以对上面这个序列进行抽取子序列的结果是:
主序列1:(0,1,2,3),(1,2,3,4),(2,3,4,5)
主序列2:(6,7,8,9),(7,8,9,10),(8,9,10,11)
抽取出了2x3总共六个子序列。
词转换
这里的词袋(bagofwords)其实更形象的说法是把数字变成字母(在0.11版本中将变成word_extractor,即文字提取),直接上代码,依旧以上面这两行序列作例子:
import numpy as np
from pyts.bag_of_words import BagOfWords
X = np.arange(12).reshape(2, 6) #0-11步长为1,2行6列
bow = BagOfWords(window_size=4, word_size=4,n_bins=4,numerosity_reduction=False)
bow.transform(X)
#array(['abcd abcd abcd', 'abcd abcd abcd'], dtype='
可以看到转换后得到了六个abcd。
window_size就是滑动窗口的长度,我们设置为4,这里没有设置步长,默认步长为1,和上面一致。
word_size即转换后词的长度。
n_bins即分成几类,比如我们这里是1234,所以正好分成abcd,如果我设成3,那么就成了aabc了。
这里还有个比较特别的参数是numerosity_reduction,默认是开着的,现在是把它关了,它有什么作用呢?它会把重复的词删掉,就像下面这样:
X[1][4] = 9
bow = BagOfWords(window_size=4, word_size=4,n_bins=4,numerosity_reduction=True)
bow.fit_transform(X)
#array(['abcd', 'abcd abdd abbd'], dtype='
注意我们把第二行的10换成了9,第一行没动。
所以第一行重复的被删了,只留下了一个abcd。
但是第二行没有重复的,留下了三个。
所以其实转换后的结果可能不是等长的,如果你需要等长的,请把这个参数关掉。
实践
接下来我们使用和上节一样的数据集进行操作,先上最简单的示例:
from pyts.classification import SAXVSM
from pyts.datasets import load_gunpoint
X_train, X_test, y_train, y_test = load_gunpoint(return_X_y=True)
clf = SAXVSM(window_size=0.5, word_size=0.5, n_bins=4, strategy='normal', numerosity_reduction=True)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
#0.9533333333333334
用的都是参数其实和Bagofwords的参数差不多,它总共包含以下参数:
| 参数 | 说明 |
|---|---|
| window_size | 默认0.5,滑动窗口长度,小数的话就是序列长度x小数 |
| word_size | 默认0.5,词的长度,小数的话是窗口长度x小数 |
| n_bins | 默认为4,分箱种类,简单理解:几类字母(a,b,c,d…) |
| strategy | 默认方法为normal,服从标准正态分布 ,若为uniform,则分箱的宽度相同,若为quantile,每个分箱中的数字数目相同 |
| numerosity_reduction | 默认为True,即删除重复的词 |
| window_step | 默认为1,滑动步长,传小数为时间序列长度x小数 |
| threshold_std | 默认0.01,标准差界限,低于这个的不会进行标准化 |
| norm_mean | 默认为True,会进行中心化 |
| use_idf | 默认为True,若为false,就不会进行idf的计算,得到的只是tf |
| smooth_idf | 默认为True,公式里log的分子分母各加一 |
| sublinear_tf | 默认为True,把tf变成1+log(tf) |
| overlapping | 默认为True,一个点可能属于两个分箱来减少序列长度,如为False,那么一个点只属于一个分箱 |
| alphabet | 默认为None,是字母表前N个字母,或者也可以传入自定义数组 |
其实上面的参数就是它的bagofwords的参数加上sklearn的TfidfVectorizer参数,关于TfidfVectorizer的详细介绍,可以看我的这篇文章:
TfidfVectorizer计算复现和细节探究
我们可以通过以下语句来访问它的字典看看细节:
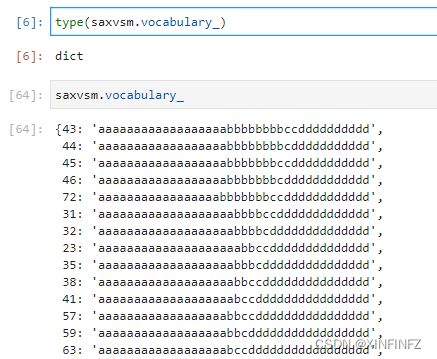
这个东西是怎么得出来的呢?其实这个字典保存的就是不重复的转换后的子序列,看下长度:
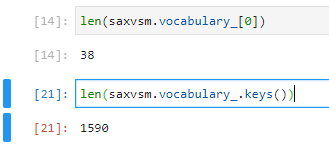
可以发现总共有1590个词,而每一个词的长度是38。为什么是这样呢?
还记得这个数据集的形状吗?(50,150),也就是50个样本,一个样本包含150个时间点的数据,而我们把窗口长度设成了0.5,词的长度也设成了0.5,所以实际上的长度为:
窗口长度=150x0.5=75
词的长度=窗口长度x0.5,约掉=38
之所以如此强调窗口长度和词的长度的计算,是因为这个算法实际上很依赖于选择一个合适的窗口长度和词长(以及分箱分成几类)。
| 参数组合 | 测试集准确率 |
|---|---|
| window_size=0.5, word_size=0.5, n_bins=4 | 0.953 |
| window_size=64, word_size=12, n_bins=5 | 0.993 |
| window_size=34, word_size=5,n_bins=4 | 0.727 |
此外,你也可以用以下代码验证一下1590个词:
bow = BagOfWords(window_size=0.5, word_size=0.5, n_bins=4, strategy='normal')
arr = bow.fit_transform(X_train)
len(np.unique(' '.join(arr).split(),return_counts=True)[0])
#1590
实际上第一行代码就是saxvsm的转换代码,接下来就开始了tf-idf的计算,得到了以下向量:
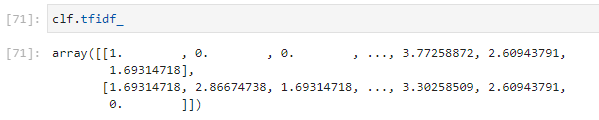
如果我们有新的序列,就用已有的字典把它转化为tf-idf向量,再计算和它们两个的余弦相似度(cosine_similarity),得到以下的结果:
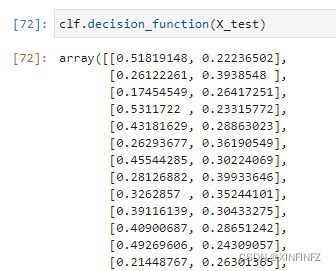
拿第一个样本举例,0.51>0.22,所以它被分类为第一类。
以上我直接使用decision_function函数略过了过程,如果你想复现计算的话可以使用sklearn.metrics.pairwise.cosine_similarity和sklearn.feature_extraction.text.TfidfVectorizer。
总结
这篇写的乱了点,可能读者会觉得有点难受,但鉴于这块算法本身需要一些自然语言处理领域的知识,我已经尽最大的努力让一般人看得懂了,希望大家看完有所收获哈哈,不懂的欢迎留言提问。