hive一次加载多个文件_Hive的基本操作
内容提要
l Hive及beeline的命令行操作
l jdbc操作Hive
l Hive函数
3.1 Hive命令操作
3.1.1 Hive的基本操作
我们长久以来习惯于传统的关系型数据库,并且结构化查询语言(SQL)相对来说也比较容易学习,那么能否将类似于关系型数据库的架构应用到Hadoop文件系统,从而可以使用类SQL语言查询和操作数据呢?Hive应运而生。
Hive提供了一个被称为Hive查询语言(HQL)的SQL方言,来查询存储在Hadoop集群中的数据。Hive就相当于是Mysql,Mysql的底层存储引擎是InnoDB,而Hive的引擎就是Hadoop的MapReduce,或者Spark,Hive会将不多数的查询转换成MapReduce任务或者Spark任务,这样就巧妙地将传统SQL语言和Hadoop生态系统结合起来,使仅会SQL的人员就可以轻松编写数据分析任务。
Hive是一个数据仓库,OLAP在线分析处理,用于统计或聚合函数等,不支持行级别的删改。它的数据建立在Hadoop之上,数据存储在HDFS上,但是它的Metastore默认存到Derby数据库当中,也可以存到外部数据库Mysql中。
接下来是对Hive的一些基本操作命令,
(1)desc database(extended)mybase(数据库名称) ; //查看数据库信息(括号内的可加可不加)extended表示扩展信息。
(2)alter database mybase set dbproperties ('created'='xpc'); //修改数据库,增加属性。
(3)create database mybase comment 'this is my first base'; //为数据库增加描述信息。
(4)create database mybase location '/x/x/x/x' ; //指定数据库存放hdfs的位置。
(5)create table default.test1 like mybase.test; //复制表结构,将mybase中test表的结构复制到default中的test1表中。
(6)load data local inpath '/x/x/x' overwrite into table xx ; //上传本地数据到hdfs中。
(7)load data inpath '/x/x/x' into table xx; //移动hdfs文件系统上的数据文件。
(8)insert into mybase.test2 select * from default.test0 where id >1203; //从default.test0中查找id>1203,插入到mybase.test2中。
(9)create table mybase.test3 as select * from default.test0; //复制表(表结构+数据)。
(10)select distinct id,name from xx ; //查询数据时重复的数据不要。
(11)insert into test2(id,name,age) values(5,'kk',22); //向表中插入一组数据。
(12)select all id,name,age from test2; //查询相同字段。
(13)select a.*,b,* from customers a inner join orders b on a.id=b.cid;
select a.*,b,* from customers a , orders b where a.id=b.id; //内连接。
(14)select * from test2 union select * from test2; //join是连接操作,union(纵向),join(横向)。
(15)select id,name from customers union all select id,orderno from orders; //union all是将多个结果合并输出。
3.1.2 Hive视图-索引
本小节主要介绍如何创建和管理视图以及索引,以及一些简单的连接表的操作,比如union、join等。
当使用Hive的表数据作为输入源时,有些情况下,Hive中的表定义和数据并不能满足分析的需求,例如有些列的值需要进行处理,有些列的类型不满足需求,甚至有时候我们在创建Hive表时为了方便快捷,会将Hive表的所有列的字段类型都定义为string,因此很多情况下使用之前需要对Hive上的数据格式等问题进行适当的处理。但是如果在Hive中通过修改原表来解决上面的问题,比如使用alter table 的方式修改原始表的Schema信息未免会对其他依赖Hive的组件有所影响(例如可能导致通过Sqoop等方式导入数据失败),而且也有可能导致之前的作业无法正常运行。于是我们需要考虑在不改变原表的情况下解决这个问题,我们想到的方案是使用Hive的视图。 Hive视图有几个特点:(1)不支持物化视图,物理文件并不存在。虚拟表也是表,但能显示出来。(2)只能查询,不能做加载数据操作。(3)视图的创建,只是保存一份元数据,查询视图时才执行对应的子查询。(4)view定义中若包含了ORDER BY/LIMIT语句,当查询视图时也进行ORDER BY/LIMIT语句操作,视图当中定义的优先级更高。(5)view支持迭代视图
接下来是对视图的一个简单的操作实例。
首先创建一个Hive表:
create table test2(id int,name String,age int)row format delimited fields terminated by ''(lines terminated by '' )stored as textfile;
然后建立一个test.txt文件,使用Hadoop的put命令将该文件上传到HDFS上的/user/hive/warehouse/myhive.db/test2目录下,其内容为:
1 tom 12
2 tomas 13
3 tomaslee 14
在创建好表并且在Hadoop上存储数据之后,可以使用load命令将该数据加载到表中,具体代码如下,
load data inpath ‘/user/hive/warehouse/myhive.db/test2/test.txt’ into table test2;
将数据加载到表中之后,可以使用select查询语句检查以上操作是否成功(此方法是通用方法,也可以在创建Hive表的时候使用location参数来指定HDFS上对应的数据目录,但此方法需要了解Hive的分区操作,关于Hive的分区操作将在3.1.4小节中做详细讲解。)。
如果数据已经可以正常访问到,即Hive的数据插入操作已成功,接下来需要把该Hive表作为两个表,使用自连接方法将两个表连接在一起,具体代码如下,
select a.*,b.* from test2 a,test2 b where a.id=b.id;
运行结果如下:
hive> select a.*,b.* from test2 a,test2 b where a.id=b.id;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181117015844_9f01950b-1f03-425d-9fcf-e721e2027419
Total jobs = 1
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/software/apache-hive-2.0.0- bin/lib/hive-jdbc-2.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/software/apache-hive-2.0.0- bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/software/hadoop-2.7.3/share/ hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Execution log at: /tmp/lvqianqian/lvqianqian_20181117015844_9f01950b-1f03- 425d-9fcf-e721e2027419.log
2018-11-17 02:19:30 Starting to launch local task to process map join; maximum memory = 518979584
2018-11-17 02:19:43 Dump the side-table for tag: 0 with group count: 3 into file:file:/tmp/lvqianqian/eb51cfa6-0d1c-477d-a813-6d3d85788098/hive_2018-11-17_02-18-57_302_5305750774273816210-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile00--.hashtable
2018-11-17 02:19:44 Uploaded 1 File to: file:/tmp/lvqianqian/eb51cfa6-0d1c-477d-a813-6d3d85788098/hive_2018-11-17_02-18-57_302_5305750774273816210-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile00--.hashtable (334 bytes)
2018-11-17 02:19:44 End of local task; Time Taken: 13.762 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1479375079365_0001, Tracking URL = http://hadoop0:8888/ proxy/application_1479375079365_0001/
Kill Command = /home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479375079365_0001
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2018-11-17 02:27:33,482 Stage-3 map = 0%, reduce = 0%
2018-11-17 02:27:37,017 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 3.25 sec
MapReduce Total cumulative CPU time: 3 seconds 250 msec
Ended Job = job_1479375079365_0001
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 3.25 sec HDFS Read: 6661 HDFS Write: 377210 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 250 msec
OK
1 tom 12 1 tom 12
2 yons 13 2 yons 13
3 yarn 14 3 yarn 14
Time taken: 522.964 seconds, Fetched: 3 row(s)
在执行上面的语句之后,如果输出以上结果,代表语句输入成功,因此可以将该结果保存到一个新表中,用于以后的分析操作,该表命名为res,具体的代码以及运行过程如下所示,
create table res as select a.*,b.* from test2 a,test2 b where a.id=b.id;//会报错,显示id重复,于是create table res as select a.id,b.id from test2 a,test2 b where a.id=b.id;
hive> create table res as select a.id aid,b.id bid from test2 a,test2 b where a.id=b.id;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181117022930_a111967f-e98a-48da-928d-58af0709d23e
Total jobs = 1
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/software/apache-hive-2.0.0- bin/lib/hive-jdbc-2.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/software/apache-hive-2.0.0- bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/software/hadoop-2.7.3/share/ hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Execution log at: /tmp/lvqianqian/lvqianqian_20181117022930_a111967f-e98a-48da-928d-58af0709d23e.log
2018-11-17 02:30:54 Starting to launch local task to process map join; maximum memory = 518979584
2018-11-17 02:30:56 Dump the side-table for tag: 0 with group count: 3 into file:file:/tmp/lvqianqian/f571f325-7611-4212-89e4-4dfe1a974441/hive_2018-11-17_02-30-41_645_7756119684971572457-1/-local-10004/HashTable-Stage-4/MapJoin-mapfile10--.hashtable
2018-11-17 02:30:56 Uploaded 1 File to: file:/tmp/lvqianqian/f571f325-7611- 4212-89e4-4dfe1a974441/hive_2018-11-17_02-30-41_645_7756119684971572457-1/-local-10004/HashTable-Stage-4/MapJoin-mapfile10--.hashtable (314 bytes)
2018-11-17 02:30:56 End of local task; Time Taken: 2.378 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1479375079365_0002, Tracking URL = http://hadoop0:8888/ proxy/application_1479375079365_0002/
Kill Command =/home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479375079365_0002
Hadoop job information for Stage-4: number of mappers: 1; number of reducers: 0
2018-11-17 02:37:21,533 Stage-4 map = 0%, reduce = 0%
2018-11-17 02:37:27,942 Stage-4 map = 100%, reduce = 0%, Cumulative CPU 2.15 sec
MapReduce Total cumulative CPU time: 2 seconds 150 msec
Ended Job = job_1479375079365_0002
Moving data to: hdfs://hadoop0:8020/user/hive/warehouse/myhive.db/res
MapReduce Jobs Launched:
Stage-Stage-4: Map: 1 Cumulative CPU: 2.3 sec HDFS Read: 5778 HDFS Write: 375214 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 300 msec
OK
Time taken: 415.308 seconds
以上存入新表的过程成功之后,可以使用Hadoop的cat命令来查看输出结果,此结果是二进制文件,具体命令以及操作结果如下,
hadoop fs -cat /user/hive/warehouse/myhive.db/res/000000_1000
18/11/17 02:38:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
11
22
33
最后对新建好的表res来创建视图,具体操作命令如下,
create view res_view as select * from res;
创建好视图之后,也可以使用select语句来查询一下视图的创建结果,具体操作如下,
select * from res_view;
删除操作很简单,直接使用drop view res_view即可删除视图。
以上是使用一些简单的命令,可以让我们更熟悉Hive的一些创建表、连接表、查询表等基本操作,而不局限于只创建一个视图,因此通过以上的操作,可以让我们更深入的了解到Hive的功能以及效率、作用等方面。
了解到视图的基本操作之后,可以学习一下关于索引的一些操作。
Hive的索引目的是提高Hive表指定列的查询速度。没有索引时,类似“where tab1.col1=10”的查询,Hive会加载整张表或分区,然后处理所有的rows,但是如果在字段col1上面存在索引时,那么只会加载和处理文件的一部分。与其他传统数据库一样,增加索引在提升查询速度时,会消耗额外资源去创建索引和需要更多的磁盘空间存储索引。在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量。在执行索引字段查询时候,首先额外生成一个MR job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的HDFS文件路径及偏移量,输出到HDFS上的一个文件中,然后根据这些文件中的HDFS路径和偏移量,筛选原始imput文件,生成新的split,作为整个job的split,这样就达到不用全表扫描的目的。关于创建索引(折半查找)的操作如下所示,
create index idx_id on table test2(id);(后面四修饰符)例如:
create index idx on table test2(id) AS 'org.apache.hadoop.hive.ql.index.compact. CompactIndexHandler' WITH DEFERRED REBUILD ;
折半查找法的基本思路(low、high和m分别指向待查元素所在区间的上届、下届和中点,k为要查找数据的关键字值):
(1) 令low-0,high=n-1.
(2) 如果low>high,则查找失败,并结束查找;否则,计算m=(low+high)/2。
(3) 让k与m指向记录的关键字进行比较。
若k=r[m].key,则查找成功,结束查找。
若k
若k>r[m].key,则使low=m+1,回到(2)继续查找。
显示索引信息,具体代码如下,
show formatted index on cusotmers ;
关于创建的索引与检验具体操作代码以及结果如3-1、3-2所示,

图3-1 创建索引与检验具体操作

图3-2 创建索引与检验具体操作(续)
创建索引之后,是用show来显示索引,结果如图3-3所示,
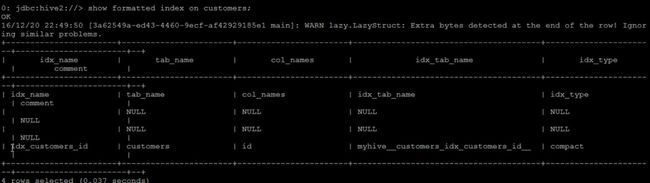
图3-3 显示索引
3.1.3 外部表-内部表
我们在创建表的时候可以指定external关键字创建外部表,外部表对应的文件存储在location指定的目录下,而不是由默认的warehouse决定的,向该目录添加新文件的同时,该表也会读取到该文件(当然文件格式必须跟表定义的一致),删除外部表的同时并不会删除location指定目录下的文件。以下代码是创建外部表,
create external table test(id int,name String,age int)row format delimited fields terminated by '' stored as textfile;
正如以上代码所示,其实创建表和创建外部表的区别只有一个,就是使用external关键字,Hive中默认创建的表是内部表,因此这里不需要再单独创建一个内部表,因为根据前几个小节就可以创建一个表,该表就是内部表,不需要任何的关键字,外部表和内部表最大的区别就是外部表删除之后,原数据表中的数据还在,而默认创建的内部表如果删除该表,它的原数据也将随之被删除。除了这个最大的区别之外,还有几个区别:(1)在导入数据到外部表时,数据并没有移动到自己的数据仓库目录下(如果指定了location的话),也就是说外部表中的数据并不是由它自己来管理的,而内部表则不一样。(2)在创建内部表或外部表时加上location的效果是一样的,只不过表目录的位置不同而已,加上partition用法也一样,只不过表目录下会有分区目录而已,load data local inpath直接把本地文件系统的数据上传到HDFS上,有location的话上传到location指定 的位置上,没有的话上传到Hive默认配置的数据仓库中。
3.1.4 分区-分桶
在Hive select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。分区表指的是在创建表时指定的partition的分区空间。如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。关于Hive的基本操作过程如下,
首先创建分区表,
create table test6(id int,name string,age int) partitioned by (year int,month int) row format delimited fields terminated by '';
由于Hive创建的表是直接存储在hdfs上的,因此可以使用hdfs命令行查看一下该表是否创建成功,
[laura@hadoop0 ~]$ hdfs dfs -lsr /
lsr: DEPRECATED: Please use 'ls -R' instead.
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/laura/hadoop-2.7.3/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'.
18/07/26 23:49:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-rw-r--r-- 3 laura supergroup 3 2018-07-22 05:32 /1.txt
drwxr-xr-x - laura supergroup 0 2018-07-23 20:39 /input
-rw-r--r-- 3 laura supergroup 73867 2018-07-23 20:39 /input/1901.gz
-rw-r--r-- 3 laura supergroup 74105 2018-07-23 20:39 /input/1902.gz
drwxrwxrwt - laura supergroup 0 2018-07-18 08:22 /logs
drwxrwx--- - laura supergroup 0 2018-07-18 08:22 /logs/laura
drwxrwx--- - laura supergroup 0 2018-07-26 23:15 /logs/laura/logs
drwxrwx--- - laura supergroup 0 2018-07-18 08:25 /logs/laura/logs/application_1500386743383_0001
-rw-r----- 3 laura supergroup 36896 2018-07-18 08:25 /logs/laura/logs/application_1500386743383_0001/hadoop2_37435
drwxrwx--- - laura supergroup 0 2018-07-23 20:47 /logs/laura/logs/application_1500726223790_0001
-rw-r----- 3 laura supergroup 52215 2018-07-23 20:47 /logs/laura/logs/application_1500726223790_0001/hadoop1_36901
drwxrwx--- - laura supergroup 0 2018-07-23 20:50 /logs/laura/logs/application_1500726223790_0002
-rw-r----- 3 laura supergroup 41963 2018-07-23 20:50 /logs/laura/logs/application_1500726223790_0002/hadoop1_36901
drwxrwx--- - laura supergroup 0 2018-07-25 20:54 /logs/laura/logs/application_1501036601926_0001
-rw-r----- 3 laura supergroup 58718 2018-07-25 20:54 /logs/laura/logs/application_1501036601926_0001/hadoop4_49938
drwxrwx--- - laura supergroup 0 2018-07-25 22:00 /logs/laura/logs/application_1501036601926_0002
-rw-r----- 3 laura supergroup 58546 2018-07-25 22:00 /logs/laura/logs/application_1501036601926_0002/hadoop4_49938
drwxrwx--- - laura supergroup 0 2018-07-26 23:16 /logs/laura/logs/application_1501135590341_0001
-rw-r----- 3 laura supergroup 58468 2018-07-26 23:16 /logs/laura/logs/application_1501135590341_0001/hadoop1_53113
drwxr-xr-x - laura supergroup 0 2018-07-23 20:50 /output
-rw-r--r-- 3 laura supergroup 0 2018-07-23 20:50 /output/_SUCCESS
-rw-r--r-- 3 laura supergroup 18 2018-07-23 20:50 /output/part-r-00000
drwxr-xr-x - laura supergroup 0 2018-07-21 07:06 /system
drwx------ - laura supergroup 0 2018-07-25 02:55 /tmp
drwx------ - laura supergroup 0 2018-07-18 08:21 /tmp/hadoop-yarn
drwx------ - laura supergroup 0 2018-07-18 08:24 /tmp/hadoop-yarn/staging
drwxr-xr-x - laura supergroup 0 2018-07-18 08:24 /tmp/hadoop-yarn/staging/history
drwxrwxrwt - laura supergroup 0 2018-07-18 08:24 /tmp/hadoop-yarn/staging/history/done_intermediate
drwxrwx--- - laura supergroup 0 2018-07-26 23:16 /tmp/hadoop-yarn/staging/history/done_intermediate/laura
-rwxrwx--- 3 laura supergroup 33715 2018-07-18 08:25 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1500386743383_0001-1500391300173-laura-hadoop%2Darchives%2D2.7.3.jar-1500391517100-1-1-SUCCEEDED-default-1500391478352.jhist
-rwxrwx--- 3 laura supergroup 358 2018-07-18 08:25 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1500386743383_0001.summary
-rwxrwx--- 3 laura supergroup 118571 2018-07-18 08:25 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1500386743383_0001_conf.xml
-rwxrwx--- 3 laura supergroup 40302 2018-07-23 20:50 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1500726223790_0002-1500868183737-laura-Max+temperature-1500868216992-2-1-SUCCEEDED-default-1500868206163.jhist
-rwxrwx--- 3 laura supergroup 347 2018-07-23 20:50 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1500726223790_0002.summary
-rwxrwx--- 3 laura supergroup 117177 2018-07-23 20:50 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1500726223790_0002_conf.xml
-rwxrwx--- 3 laura supergroup 23051 2018-07-25 20:53 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501036601926_0001-1501041123179-laura-insert+into+users%28id%2Cna...values%281%2C%27tom%27%2C12%29%28Stage-1501041234282-1-0-SUCCEEDED-default-1501041225347.jhist
-rwxrwx--- 3 laura supergroup 376 2018-07-25 20:53 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501036601926_0001.summary
-rwxrwx--- 3 laura supergroup 256877 2018-07-25 20:53 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501036601926_0001_conf.xml
-rwxrwx--- 3 laura supergroup 23031 2018-07-25 22:00 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501036601926_0002-1501045166669-laura-insert+into+myhive.t1%28i...values%281%2C%27tom%27%2C12%29%28Stage-1501045217580-1-0-SUCCEEDED-default-1501045207922.jhist
-rwxrwx--- 3 laura supergroup 375 2018-07-25 22:00 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501036601926_0002.summary
-rwxrwx--- 3 laura supergroup 257102 2018-07-25 22:00 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501036601926_0002_conf.xml
-rwxrwx--- 3 laura supergroup 23022 2018-07-26 23:16 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501135590341_0001-1501136045504-laura-insert+into+t3%28id%2Cname%29+values%281%2C%27tom%27%29%28Stage%2D1%29-1501136178929-1-0-SUCCEEDED-default-1501136161600.jhist
-rwxrwx--- 3 laura supergroup 371 2018-07-26 23:16 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501135590341_0001.summary
-rwxrwx--- 3 laura supergroup 256924 2018-07-26 23:16 /tmp/hadoop-yarn/staging/history/done_intermediate/laura/job_1501135590341_0001_conf.xml
drwx------ - laura supergroup 0 2018-07-18 08:21 /tmp/hadoop-yarn/staging/laura
drwx------ - laura supergroup 0 2018-07-26 23:16 /tmp/hadoop-yarn/staging/laura/.staging
drwx-wx-wx - laura supergroup 0 2018-07-25 02:55 /tmp/hive
drwx------ - laura supergroup 0 2018-07-26 23:19 /tmp/hive/laura
drwx------ - laura supergroup 0 2018-07-25 10:15 /tmp/hive/laura/75fcbcee-e25f-40f8-9754-34e998cd0730
drwx------ - laura supergroup 0 2018-07-25 10:15 /tmp/hive/laura/75fcbcee-e25f-40f8-9754-34e998cd0730/_tmp_space.db
drwx------ - laura supergroup 0 2018-07-26 23:20 /tmp/hive/laura/abeb377c-3e5c-4106-9583-b539eb69d611
drwx------ - laura supergroup 0 2018-07-26 23:19 /tmp/hive/laura/abeb377c-3e5c-4106-9583-b539eb69d611/_tmp_space.db
drwxr-xr-x - laura supergroup 0 2018-07-25 20:02 /user
drwxr-xr-x - laura supergroup 0 2018-07-25 20:02 /user/hive
drwxr-xr-x - laura supergroup 0 2018-07-25 20:16 /user/hive/warehouse
drwxr-xr-x - laura supergroup 0 2018-07-26 23:45 /user/hive/warehouse/myhive.db
drwxr-xr-x - laura supergroup 0 2018-07-25 22:00 /user/hive/warehouse/myhive.db/t1
-rwxr-xr-x 3 laura supergroup 9 2018-07-25 22:00 /user/hive/warehouse/myhive.db/t1/000000_0
drwxr-xr-x - laura supergroup 0 2018-07-26 23:16 /user/hive/warehouse/myhive.db/t3
-rwxr-xr-x 3 laura supergroup 6 2018-07-26 23:16 /user/hive/warehouse/myhive.db/t3/000000_0
drwxr-xr-x - laura supergroup 0 2018-07-26 23:49 /user/hive/warehouse/myhive.db/t4
drwxr-xr-x - laura supergroup 0 2018-07-26 23:49 /user/hive/warehouse/myhive.db/t4/province=hebei
drwxr-xr-x - laura supergroup 0 2018-07-26 23:49 /user/hive/warehouse/myhive.db/t4/province=hebei/city=baoding
drwxr-xr-x - laura supergroup 0 2018-07-25 20:53 /user/hive/warehouse/myhive.db/users
-rwxr-xr-x 3 laura supergroup 9 2018-07-25 20:53 /user/hive/warehouse/myhive.db/users/000000_0
drwxr-xr-x - laura supergroup 0 2018-07-21 08:25 /user/laura
drwx------ - laura supergroup 0 2018-07-21 08:24 /user/laura/.Trash
drwx------ - laura supergroup 0 2018-07-23 20:49 /user/laura/.Trash/Current
drwxr-xr-x - laura supergroup 0 2018-07-23 20:47 /user/laura/.Trash/Current/output
-rw-r--r-- 3 laura supergroup 0 2018-07-23 20:47 /user/laura/.Trash/Current/output/_SUCCESS
-rw-r--r-- 3 laura supergroup 18 2018-07-23 20:47 /user/laura/.Trash/Current/output/part-r-00000
drwx------ - laura supergroup 0 2018-07-25 20:14 /user/laura/.Trash/Current/user
drwx------ - laura supergroup 0 2018-07-25 20:14 /user/laura/.Trash/Current/user/hive
drwx------ - laura supergroup 0 2018-07-25 20:14 /user/laura/.Trash/Current/user/hive/warehouse
drwxr-xr-x - laura supergroup 0 2018-07-25 21:50 /user/laura/.Trash/Current/user/hive/warehouse/myhive.db
drwxr-xr-x - laura supergroup 0 2018-07-25 20:38 /user/laura/.Trash/Current/user/hive/warehouse/myhive.db/t1
drwx------ - laura supergroup 0 2018-07-21 08:25 /user/laura/.Trash/Current/user/laura
drwxr-xr-x - laura supergroup 0 2018-07-21 06:39 /user/laura/.Trash/Current/user/laura/hadoop
-rw-r--r-- 3 laura supergroup 3 2018-07-21 02:47 /user/laura/.Trash/Current/user/laura/hadoop/1.txt
-rw-r--r-- 3 laura supergroup 1366 2018-07-14 16:00 /user/laura/README.txt
hive>show partitions t4;
OK
province=hebei/city=baoding
Time taken:0.381 seconds,Fetched:1 row(s)
然后使用add关键字对分区表添加多个分区,
alter table partest5 add partition (year=2018,month=11) partition (year=2018, month=12);
给Hive表创建好分区之后,使用show partitions命令查看创建的分区是否成功,
show partitions partest5;
hive> show partitions partest5;
OK
year=2018/month=11
year=2018/month=12
Time taken: 0.149 seconds, Fetched: 2 row(s)
表建成之后,可以向该表中插入一些数据,用于后续的实验使用,
load data local inpath '/x/x/x' overwrite into table partest5 partition (year= 2018,month=12);
在学习到创建分区表以及向分区表中插入数据的一些语法之后,还可以将分区删除,使用drop语法如下所示,
alter table partest5 drop partition (year=2018,month=11);
除了手动的对表进行分区以外,还可以使用动态分区的方法,接下来将一些关于动态分区的操作实验,
首先需要启动动态分区的配置,该配置默认时关闭的,
set hive.exec.dynamic.partition=true;
启动了之后,还需要修改一个配置去设置成分区模式,该配置默认时strict严格模式,修改这个配置时,至少要指定一个分区类,
set hive.exec.dynamic.partition.mode=nonstrict;
了解到基本的分区操作之后,接下来是用一个例子来测试一下动态分区的过程,
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table partest5 partition(year,month) select id,name,age,2018 as year,4 as month from test4;
hive> insert into table partest5 partition(year,month) select id,name,age,2018 as year,4 as month from test4;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181119130613_463819f6-d208-4a24-9215-b8fc3a5909f3
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1479587555371_0001, Tracking URL = http://hadoop0:8888/ proxy/application_1479587555371_0001/
Kill Command = /home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479587555371_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-11-19 13:10:23,452 Stage-1 map = 0%, reduce = 0%
2018-11-19 13:10:28,936 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.66 sec
MapReduce Total cumulative CPU time: 1 seconds 660 msec
Ended Job = job_1479587555371_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop0:8020/user/hive/warehouse/myhive.db/partest5/. hive-staging_hive_2018-11-19_13-07-16_713_4522739610653491079-1/-ext-10000
Loading data to table myhive.partest5 partition (year=null, month=null)
Time taken to load dynamic partitions: 1.545 seconds
Time taken for adding to write entity : 0.003 seconds
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.66 sec HDFS Read: 4519 HDFS Write: 378500 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 660 msec
OK
Time taken: 198.535 seconds
hive> select * from partest5;
OK
1 tom 12 2015 4
2 yons 13 2015 4
3 yarn 14 2015 4
NULL NULL NULL 2016 12
NULL NULL NULL 2016 12
NULL NULL NULL 2016 12
Time taken: 0.635 seconds, Fetched: 6 row(s)
Hive表的优化操作除了分区,还有一个方法就是分桶操作,分桶则是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀地分发到各个桶文件中。因为分桶操作需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)。因为分桶改变了数据的存储方式,它会把哈希取模相同或者在某一区间的数据行放在同一个桶文件中。如此一来便可提高查询效率,如:我们要对两张在同一列上进行了分桶操作的表进行join操作的时候,只需要对保存相同列值的桶进行join操作即可。同时分桶也能让取样(sampling)更高效。
接下来是关于一个桶表的操作流程,首先创建桶表,
create table test5(id int,name string,age int) clustered by (id) into 2 buckets;
最好把两个blocksize放入一个bucket中,test5是桶表,把没有桶表的test4中数据插入到test5中去,并覆盖test5中数据,如下所示,
insert overwrite table test5 select * from test4;
注:load操作不可以用于bucket表,因此将数据插入事务表之前必须配置打开之前介绍的事务属性的所有配置才可以可以使用insert方法。
由于Hive内部目前使用的是mapreduce架构,因此在处理数据的时候,可以控制reduce的数量,可以设置它的最大值,
set map.reduce.tasks=2;
但是Map的数量是由输入分片的数量决定的,但是分片的数量并不是简单地按照文件的大小和blocksize的大小来切分的,分片的数量其实也是经过一系列的计算得到的,我们常用的Imput Format很多都是继承自FileInputFormat。
因为分桶表在创建的时候只会定义scheme,且写入数据的时候不会自动进行分桶、排序,需要人工先进行分桶、排序后再写入数据。确保目标表中的数据和它定义的分布一致。
目前有两种方式往分桶表中插入数据,
方法一:打开enforce bucketing开关。
set hive.enforce.bucketing=true;
insert (into|overwrite) table select [sort by [asc|desc],[ [asc|desc],…]];
方法二:将Reducer个数设置为目标表的桶数,并在select语句中用distribute by 对查询结果按目标表的分桶键分进Reducer中。相同自定义分区(相同字段值进入同一分区)。等价于MR分区过程,保证具有相同数据的某个字段一定进入同一分区,也就是进入同一Reduce。
set mapred.reduce.tasks=;
insert (into|overwrite) table select distribute by ,[,…] [sort by [asc|desc],[ [asc|desc],…]];
如果分桶表创建时定义了排序键,那么数据不仅要分桶,还要排序;如果分桶键和排序键不同,且降序排列,使用distribute by…sort by分桶排序;如果分桶键和排序键相同,且按升序排列(默认),使用cluster by分桶排序,cluster by的功能就是distribute by个sort by相结合。具体操作代码如下:
set mapred.reduce.tasks=;
insert (into|overwrite) table select cluster by ,[,…];
另外,在Hive(inceptor)中,ORC事物表必须进行分桶(为了提高效率)。每个桶的文件大小应在100~200MB之间(ORC表压缩后的数据)。通常做法是先分区后分桶。
除此之外,桶表还有一个常用的操作,就是对表进行采样。当数据集非常大的时候,我们需要找一个子集来加快数据分析。此时我们需要数据采集工具以获得需要的子集。关于表采样函数的使用如下所示,(1)关闭cbo的优化策略
$>set hive.cbo.enable=false ;
(2)使用百分比随机采样tablesample函数
select * from customers tablesample(0.1 percent);
(3)bucket采样
select * from mybucks tablesample(bucket 1 out of 2 on id) ;
3.1.5 Hive函数
上面讲到了UDAF、转换、连接、聚合、表采样这些函数的概念以及使用方法,但这些函数都是Hive表中自带的一些函数,对于一些有特殊需求的项目,有可能使用这些自带的函数不能够达到想要的要求,因此我们需要使用用户自定义的函数来满足需求,即UDF(user-defined function)。关于UDF的具体操作步骤是:
(1)创建函数类:使用create function即可创建函数类。
(2)导出jar到Hive classpath,
[临时]
$hive>add jar /x/x/x/xxx.jar //该方法时直接在hive shell中输入,是临时生效的方法
[永久]hive-site.xml
hive.aux.jars.path=/shared/ //该方法是在hive的配置文件中配置,是永久生效的方法
(3)添加函数声明,
[临时函数]
CREATE TEMPORARY FUNCTION add AS 'com.it18zhang.myhive210.udf.UDFAdd';
[永久函数]
CREATE FUNCTION add AS 'com.it18zhang.myhive210.udf.UDFAdd' USING JAR 'file:///shared/bigdata/data/myhive210-0.0.1-SNAPSHOT.jar';(本地模式不可用,必须上传到hdfs上,然后不能用file,用hdfs8020端口执行)
临时函数和永久函数最大的区别是是否包含TEMPORARY关键字。
(4)使用add函数,可以实现两个参数相加,具体代码如下,
$>select add(1,2) ;
(5)使用DROP关键字可以删除函数,其他语法相同。具体代码如下,
DROP TEMPORARY FUNCTION IF EXISTS toUpper;
除了使用Hive-Cli操作自定义函数以外,还有一种方法就是之前提到过的,使用jdbc来操作Hive的自定义函数。首先导入一些关于Hive的库,然后开始定义函数并且定义一个UDFAdd类,该类继承UDF父类,类中定义三个方法。具体代码如下,
package com.lvqianqian.myhive210.udf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
/**
* 定义函数
*/
@Description(
name = "add",
value = "this is a add function.",
extended = "add() => 0 add(1,2) => 3 add(1,2,3) => 6")
@UDFType(deterministic =true, stateful = false)
public class UDFAdd extends UDF {
public int evaluate() {
return 0;
}
public int evaluate(int a , int b) {
return a + b;
}
public int evaluate(int a ,int b ,int c) {
return a + b + c;
}
}
代码编译通过后,导出jar包到Hive类路径下,具体代码如下,
[临时]
$hive>add jar /x/x/x/xxx.jar //该方法是临时打jar包
[永久]hive-site.xml
hive.aux.jars.path=/x/x/x/xxx.jar //该方法是永久地导出jar包
结果如下所示,
以上就是实现了一个自定义函数的过程。其实函数就是方法,面向对象的语言叫方法,面向过程的语言叫函数。
关于函数的创建,删除等操作熟悉之后,可以通过show方法来显示出该数据库中包含的所有函数。具体代码以及结果如下,
hive> show functions;
OK
!
!=
$sum0
%
&
*
+
-
/
<
<=
<=>
<>
=
==
>
>=
^
abs
acos
add_months
aes_decrypt
aes_encrypt
and
array
array_contains
ascii
asin
assert_true
atan
avg
base64
between
bin
bround
case
cbrt
ceil
ceiling
chr
coalesce
collect_list
collect_set
compute_stats
concat
concat_ws
context_ngrams
conv
corr
cos
count
covar_pop
covar_samp
crc32
create_union
cume_dist
current_database
current_date
current_timestamp
current_user
date_add
date_format
date_sub
datediff
day
dayofmonth
decode
degrees
dense_rank
div
e
elt
encode
ewah_bitmap
ewah_bitmap_and
ewah_bitmap_empty
ewah_bitmap_or
exp
explode
factorial
field
find_in_set
first_value
floor
format_number
from_unixtime
from_utc_timestamp
get_json_object
get_splits
greatest
hash
hex
histogram_numeric
hour
if
in
in_file
index
initcap
inline
instr
isnotnull
isnull
java_method
json_tuple
lag
last_day
last_value
lcase
lead
least
length
levenshtein
like
ln
locate
log
log10
log2
lower
lpad
ltrim
map
map_keys
map_values
mask
mask_first_n
mask_hash
mask_last_n
mask_show_first_n
mask_show_last_n
matchpath
max
md5
min
minute
month
months_between
named_struct
negative
next_day
ngrams
noop
noopstreaming
noopwithmap
noopwithmapstreaming
not
ntile
nvl
or
parse_url
parse_url_tuple
percent_rank
percentile
percentile_approx
pi
pmod
posexplode
positive
pow
power
printf
quarter
radians
rand
rank
reflect
reflect2
regexp
regexp_extract
regexp_replace
repeat
replace
reverse
rlike
round
row_number
rpad
rtrim
second
sentences
sha
sha1
sha2
shiftleft
shiftright
shiftrightunsigned
sign
sin
size
sort_array
soundex
space
split
sqrt
stack
std
stddev
stddev_pop
stddev_samp
str_to_map
struct
substr
substring
substring_index
sum
tan
to_date
to_unix_timestamp
to_utc_timestamp
translate
trim
trunc
ucase
unbase64
unhex
unix_timestamp
upper
var_pop
var_samp
variance
version
weekofyear
when
windowingtablefunction
xpath
xpath_boolean
xpath_double
xpath_float
xpath_int
xpath_long
xpath_number
xpath_short
xpath_string
year
|
~
Time taken: 0.66 seconds, Fetched: 237 row(s)