【百面成神】消息中间件基础7问,你能撑到第几问
前 言
作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
☕专栏简介:纯手打总结面试题,自用备用
文章简介:消息中间件最基础、重要的9道面试题
文章目录
-
-
- 1. 你怎么理解消息中间件
- 2. 如何保证使用消息中间件时,消息不会丢失?
- 3. 消息队列如何保证消息的顺序性。
- 4.如何幂等处理重复消息呢?
- 5.如何处理消息队列的消息积压问题
- 6. 消息中间件如何做到高可用
- 7.如何保证数据一致性,事务消息如何实现
-
1. 你怎么理解消息中间件
其实就是一个以队列作为消息通信的组件,本质上是一个消息转发器。可以对消息进行接收、存储和消费。当前业界比较流行的消息中间件有rabbitmq,rocketmq和Kafka。我用的比较多的是rabbitmq。
之所以使用消息中间件,主要是基于以下原因:
(1) 应用解耦
假设现在有一个订单系统,一个库存系统,他们之间可以进行交互,那么就是订单完成会削减库存。但此时如果引入一个积分系统,他们也存在交互关系,订单完成则用户需要进行积分计算。这时候就需要改变订单系统的源代码,来实现与库存系统的交互。此时各个应用子系统之间是直接耦合的。引入消息中间件就是为了解决这样的问题。订单下单后,将消息生产存储到中间件,而其他的积分系统、库存系统都只需要在消息中间件中进行消息的消费即可。
(2) 削谷平峰
如在秒杀活动中,为了避免流量暴涨,从而击垮应用,就可以将消息暂存在消息中间件中,慢慢对其中的消息进行处理。
(3) 异步处理
一个业务上经常有的案例是,在用户注册后,需要将注册信息进行入库,同时还需要进行短信通知与邮件通知。如果串行执行,每个操作许愿30ms,一共就需要90ms时间。如果引入消息队列,可以入库后写入消息中间件,写入操作一般很快,预计3ms,然后异步发送邮件和短信,耗时就只需要62ms了。
(4) 消息通信
消息队列中内置了高效的消息通信机制,可以实现点对点通信,聊天室等
(5) 远程调用
可以基于消息队列,自研远程调用框架。
2. 如何保证使用消息中间件时,消息不会丢失?
以rabbitmq为例,消息从生产端到消费端需要经过三个步骤:
(1) 生产端将消息发送到rabbitmq
(2) Rabbitmq将消息发送给消费者
(3) 消费者对消息进行消费
因此,保证消息不会丢失的关键在于:确保生产端和消费端的消息的可靠性
消费端可靠性机制有以下几种:
(1) 事务消息机制,消息发送后,生产端阻塞等待消费者的响应,得到响应后发送下一个消息。这种机制是同步机制,会严重降低性能,不建议使用。
(2) confirm消息确认机制:顾名思义,消费者在接收到消息后会发送确认消息给生产者,如果生产者没有收到确认消息,可以进行消息重发。实际上,因为生产者丢失消息的可能性很小,监听重发的代价会影响性能。一般我们在生产中记录日志,顺便发个邮件给相关人员,方便进行问题回溯即可。如果确实属于消息生产者丢失消息的罕见情况,可以由开发在数据库执行补数据的操作即可。
(3) 消息持久化:rabbitmq中的数据是存储到内存中的,为了避免由于rabbitmq宕机导致消息丢失,就需要采用持久化策略将其存储到磁盘中。Springboot会默认对消息进行持久化
(4)将消息存储到数据库中,并且设置状态变量status。当status=0时,说明消息没有被消费,一定时间后,消息还未被消费,需要进行消息重发。为了避免一直进行消息重发,需要设置重发次数,当超过重发次数,则做另外的处理。
生产端可靠性机制有以下几种:
(1) Springboot重试机制
SpringBoot 给我们提供了一种重试机制,当消费者执行的业务方法报错时会重试执行消费者业务方法。
(2)ACK机制改为手动
RabbitMQ的自动ack机制默认在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完。
我们需要进行手动消费
3. 消息队列如何保证消息的顺序性。
比如一个订单要先下单、再付款。如果生产者生产了两个消息,第一条消息需要发给下单系统,第二条消息需要发送给付款系统,我们需要维护这两条消息按照顺序消费。
什么情况会导致顺序性问题呢?
第一个是一个生产者对应多个消费者。
第二个场景是一个生产者的消息由一个消费者进行消费,但是消费者是多线程并发消费。
如何避免出现顺序性问题呢?
以rabbitmq为例。
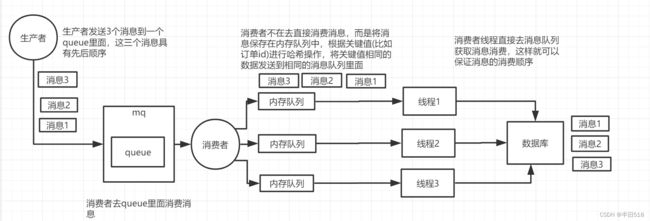
(1)第一种场景 可以拆分为多个queue,一个queue对应一个消费者。也就是说具有顺序性要求的消息放在同一个queue里,由同一个消费者消费。这样略繁琐,同时也可能造成吞吐量下降。

(2) 第二种场景可以一个queue对应一个cumsumer,consumer内部以内存队列形式进行排队,底层分发给不同的worker执行,具有顺序要求的消息由同一个worker处理。
4.如何幂等处理重复消息呢?
幂等性在计算机科学中指的是一次请求和多次请求执行的影响效果相同。
为何需要幂等?
比如一个转账操作,如果转账请求执行后,没有返回结果。可能是转账请求没有送到,也可能是请求送到了,返回结果丢了。这个时候我们需要重试,但必须能够确保这样的重试不会多转一笔钱。
其解决方法有:
(1) 设计一个本地表,通过唯一的主键或者其他业务标识,每一次处理请求进行一次校验。
(2) 也可以使用redis缓存业务标记,每次看下是否已经处理过了。
5.如何处理消息队列的消息积压问题
消息挤压是由于生产者生产消息的速度比消费者消费消息的速度更快。
出现消息挤压得情况,首先需要排除下是不是由于bug导致的。
如果不是由代码bug导致的,消息是一条一条处理时,可以考虑是否可以进行批处理。也可以进行水平扩容在,增加对应topic的消费者机器数量。
如果是bug导致几百万消息持续积压几小时。有如何处理呢? 需要解决bug,临时紧急扩容。扩容后等问题解决后再恢复原来的部署架构。
6. 消息中间件如何做到高可用
以rabbitmq为例,实现高可用是基于镜像集群模式。无论queue的元数据还是queue中的消息都会同时存在与多个实例上. 这种方式的好处就在于, 任何一个服务宕机了,都不会影响整个集群数据的完整性, 因为其他服务中都有queue的完整数据, 当进行消息消费的时候,连接其他的服务器节点一样也能获取到数据.

缺点:
1: 性能开销大: 因为需要进行整个集群内部所有实例的数据同步
2:无法线性扩容: 因为每一个服务器中都包含整个集群服务节点中的所有数据, 这样如果一旦单个服务器节点的容量无法容纳了怎么办?.
7.如何保证数据一致性,事务消息如何实现
可以使用事务消息。
生产者产生消息,发送一条半事务消息到MQ服务器
MQ收到消息后,将消息持久化到存储系统,这条消息的状态是待发送状态。
MQ服务器返回ACK确认到生产者,此时MQ不会触发消息推送事件
生产者执行本地事务
如果本地事务执行成功,即commit执行结果到MQ服务器;如果执行失败,发送rollback。
如果是正常的commit,MQ服务器更新消息状态为可发送;如果是rollback,即删除消息。
如果消息状态更新为可发送,则MQ服务器会push消息给消费者。消费者消费完就回ACK。
如果MQ服务器长时间没有收到生产者的commit或者rollback,它会反查生产者,然后根据查询到的结果执行最终状态。