Iceberg +Flink+CDH+Trino+Hive
Iceberg +Flink+CDH+Trino+Hive
集群环境
| 名称 | 版本 | 描述 |
|---|---|---|
| flink | 1.3.2 | 开源版本 |
| cdh | 6.3.2 | 开源版本 |
| hive | 2.1.1-cdh6.3.2 | cdh6.3.2中版本 |
| hadoop | 3.0.0-cdh6.3.2 | cdh6.3.2中版本 |
| presto | 2.591 | 开源版本 |
| trino | 360 | 开源版本 |
| Iceberg | 0.13 | master分支编译 |
| kafka | 2.2.1-cdh6.3.2 | cdh6.3.2中版本 |
编译环境
| 名称 | 版本 | 描述 |
|---|---|---|
| Maven | 3.6.3 | 开源版本 |
| jdk | 1.8.0_231 | 开源版本 |
maven setting.xml配置
<profile>
<id>aliid>
<repositories>
<repository>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
repositories>
<pluginRepositories>
<pluginRepository>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
pluginRepository>
pluginRepositories>
profile>
Iceberg编译
Iceberg 包拉取
git clone [email protected]:apache/iceberg.git
cd iceberg
gradlew 清理
./gradlew clean
gradlew 打包
./gradlew build
跳过所有测试打包(常用选项)
第一次编译相对慢一点,因为需要下载依赖,后面编译很快,大概两三分钟即可
./gradlew clean build -x test -x integrationTest
gradlew命令里面的几个选项:
- -x test :
- 表示跳过所有的单元测试;
- -x integrationTest:
- 表示跳过所有的相关集成测试;
测试前准备
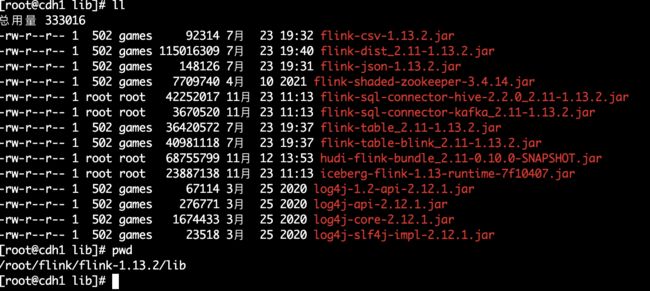
依赖包列表
| 名称 | 来源 | 来源地址 | 需放置位置 | 描述 |
|---|---|---|---|---|
| flink-sql-connector-kafka_2.11-1.13.2.jar | maven下载 | https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.13.2/flink-sql-connector-kafka_2.11-1.13.2.jar | FLINK_HOME/lib | flink读kafka |
| flink-sql-connector-hive-2.2.0_2.11-1.13.2.jar | maven下载 | https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-2.2.0_2.11/1.13.2/flink-sql-connector-hive-2.2.0_2.11-1.13.2.jar | FLINK_HOME/lib | iceberg sync hive catalog |
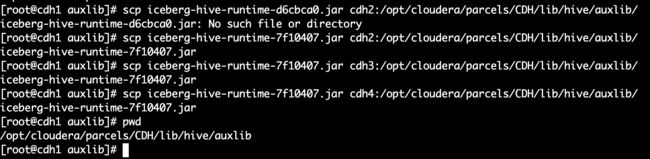
| iceberg-hive-runtime-2d102f5.jar | 编译Iceberg | hive-runtime/build/libs/iceberg-hive-runtime-2d102f5.jar | HIVE_HOME/auxlib | hive读iceberg表 |
| iceberg-flink-1.13-runtime-7f10407.jar | 编译Iceberg | flink/v1.13/flink-runtime/build/libs/iceberg-flink-1.13-runtime-7f10407.jar | FLINK_HOME/lib | flink读写iceberg表 |
Flink开启checkpointing
在sql-client-defaults.yaml 添加以下
configuration:
execution.checkpointing.interval: 60000
state.checkpoints.num-retained: 10
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.checkpoints.dir: hdfs:///user/flink/checkpoints
state.savepoints.dir: hdfs:///user/flink/checkpoints
添加环境变量
vim /etc/profile
export HADOOP_CLASSPATH=`hadoop classpath`
重启hive
重启Flink
测试字段类型
官方支持类型https://iceberg.apache.org/#schemas/#_top
| 类型 | 备注 |
|---|---|
| tinyint | 1字节 整数值 |
| smallint | 2字节 整数值 |
| int | 4字节 整数值 |
| bigint | 8字节 整数值 |
| decimal(precision, scale) | 精确数值,精度precision,小数点后位数scale precision取值1~38,缺省默认为9 scale不能大于precision,缺省默认为0 |
| float | 4字节 浮点型 |
| double | 8字节 浮点型 |
| boolean | true/false |
| char(length) | 固定长度字符,length必填(1~255) |
| varchar(max_length) | 可变长度字符,max_length必填(1~65535) |
| string | 字符串 |
| timestamp | 时间值 |
测试数据参考
- 查询Topic
kafka-topics --list --zookeeper cdh2:2181,cdh3:2181
- 创建Topic
kafka-topics --create --topic all_type --partitions 1 --replication-factor 1 --zookeeper cdh3:2181
- 往Topic 生产消息
kafka-console-producer --broker-list cdh2:9092 --topic all_type
{"tinyint0": 6, "smallint1": 223, "int2": 42999, "bigint3": 429450, "float4": 95.47324181659323, "double5": 340.5755392968011,"decimal6": 111.1111, "boolean7": true, "char8": "dddddd", "varchar9": "buy0", "string10": "buy1", "timestamp11": "2021-09-13 03:08:50.810"}
![]()
- 从Topic 消费消息
#加了--from-beginning 重头消费所有的消息
kafka-console-consumer --bootstrap-server cdh2:9092 --topic all_type --from-beginning

开始数据湖测试
进入Flink-sql- client
cd $FLINK_HOME
## 因为所有依赖包已经放入Flink/lib下,所以不需要指定即可加载
./bin/sql-clent.sh
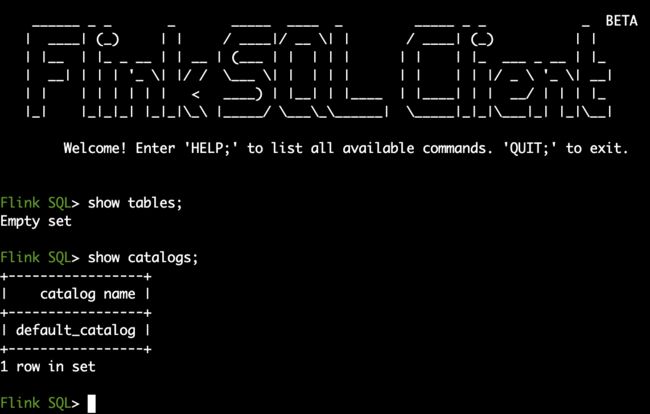
当前环境内无任何表与catalog
创建kafka表
CREATE TABLE k (
tinyint0 TINYINT
,smallint1 SMALLINT
,int2 INT
,bigint3 BIGINT
,float4 FLOAT
,double5 DOUBLE
,decimal6 DECIMAL(38,8)
,boolean7 BOOLEAN
,char8 STRING
,varchar9 STRING
,string10 STRING
,timestamp11 STRING
) WITH (
'connector' = 'kafka' -- 使用 kafka connector
, 'topic' = 'all_type' -- kafka topic名称
, 'scan.startup.mode' = 'earliest-offset' -- 从起始 offset 开始读取
, 'properties.bootstrap.servers' = 'cdh4:9092' -- kafka broker 地址
, 'properties.group.id' = 'testgroup1'
, 'value.format' = 'json'
, 'value.json.fail-on-missing-field' = 'true'
, 'value.fields-include' = 'ALL'
);

Flink sql 操作 iceberg 表
Iceberg V1
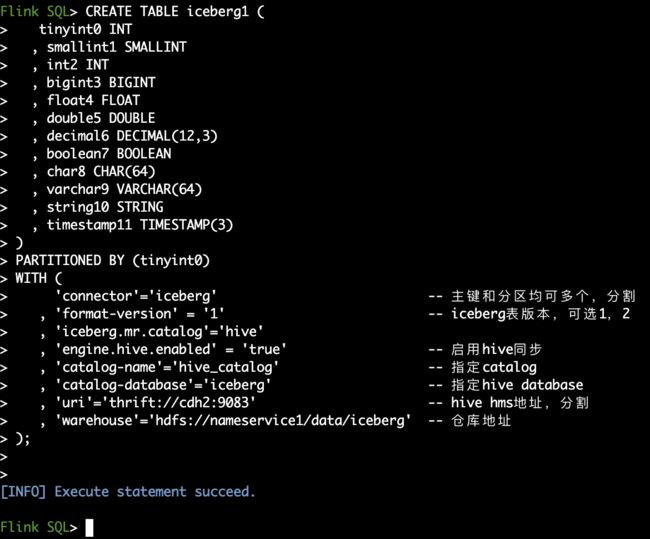
创建v1表
CREATE TABLE iceberg1 (
tinyint0 INT
, smallint1 SMALLINT
, int2 INT
, bigint3 BIGINT
, float4 FLOAT
, double5 DOUBLE
, decimal6 DECIMAL(12,3)
, boolean7 BOOLEAN
, char8 CHAR(64)
, varchar9 VARCHAR(64)
, string10 STRING
, timestamp11 TIMESTAMP(3)
)
PARTITIONED BY (tinyint0)
WITH (
'connector'='iceberg' -- 主键和分区均可多个,分割
, 'format-version' = '1' -- iceberg表版本,可选1,2
, 'iceberg.mr.catalog'='hive'
, 'engine.hive.enabled' = 'true' -- 启用hive同步
, 'catalog-name'='hive_catalog' -- 指定catalog
, 'catalog-database'='iceberg' -- 指定hive database
, 'uri'='thrift://cdh2:9083' -- hive hms地址,分割
, 'warehouse'='hdfs://nameservice1/data/iceberg' -- 仓库地址
);
插入v1表
insert into iceberg1
select
cast(tinyint0 as TINYINT)
, cast(smallint1 as SMALLINT)
, cast(int2 as INT)
, cast(bigint3 as BIGINT)
, cast(float4 as FLOAT)
, cast(double5 as DOUBLE)
, cast(decimal6 as DECIMAL(38,18))
, cast(boolean7 as BOOLEAN)
, cast(char8 as CHAR(64))
, cast(varchar9 as VARCHAR(64))
, cast(string10 as STRING)
, cast(timestamp11 as TIMESTAMP(3))
from k;
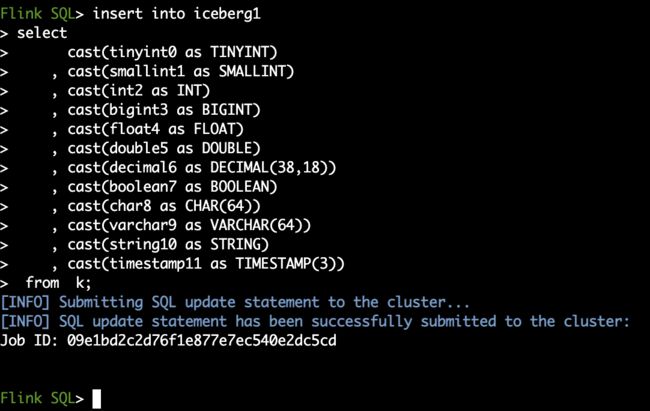
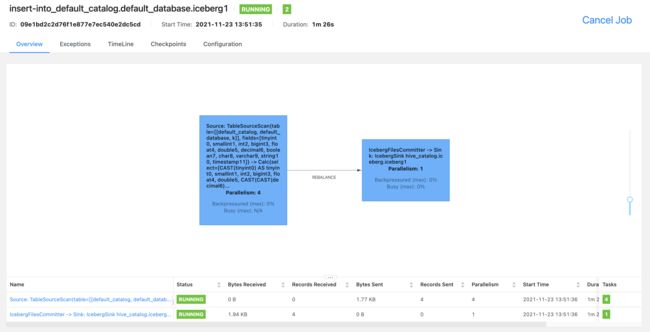
观察Flink-Web
查询v1表
SET sql-client.execution.result-mode=tableau;
## Flink 不支持iceberg TINYINT,SMALLINT数据类型查询
select int2,bigint3,float4,double5,decimal6,boolean7,char8,varchar9,string10,timestamp11 from iceberg1

Iceberg V2
创建v2表
CREATE TABLE iceberg2 (
tinyint0 INT
, smallint1 INT
, int2 INT
, bigint3 BIGINT
, float4 FLOAT
, double5 DOUBLE
, decimal6 DECIMAL(12,3)
, boolean7 BOOLEAN
, char8 CHAR(64)
, varchar9 VARCHAR(64)
, string10 STRING
, timestamp11 TIMESTAMP(3)
, PRIMARY KEY (char8,tinyint0) NOT ENFORCED -- upsert 分区表主键必须指定分区字段
)
PARTITIONED BY (tinyint0)
WITH (
'connector'='iceberg' -- 主键和分区均可多个,分割
, 'format-version' = '2' -- iceberg表版本,可选1,2
, 'write.upsert.enabled' = 'true' -- 开启upsert
, 'engine.hive.enabled' = 'true' -- 启用hive同步
, 'catalog-name'='hive_catalog' -- 指定catalog
, 'catalog-database'='iceberg' -- 指定hive database
, 'uri'='thrift://cdh2:9083' -- hive hms地址,分割
, 'warehouse'='hdfs://nameservice1/data/iceberg' -- 仓库地址
);

插入v2表
insert into iceberg2
select
cast(tinyint0 as TINYINT)
, cast(smallint1 as SMALLINT)
, cast(int2 as INT)
, cast(bigint3 as BIGINT)
, cast(float4 as FLOAT)
, cast(double5 as DOUBLE)
, cast(decimal6 as DECIMAL(38,18))
, cast(boolean7 as BOOLEAN)
, cast(char8 as CHAR(64))
, cast(varchar9 as VARCHAR(64))
, cast(string10 as STRING)
, cast(timestamp11 as TIMESTAMP(3))
from k;

观察Flink-Web
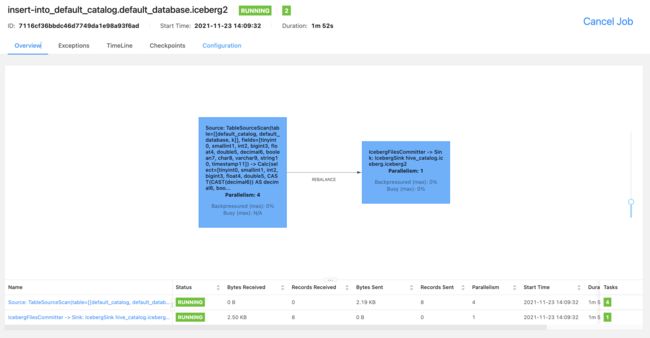
查询v2表
SET sql-client.execution.result-mode=tableau;
## Flink 不支持iceberg TINYINT,SMALLINT数据类型查询
select int2,bigint3,float4,double5,decimal6,boolean7,char8,varchar9,string10,timestamp11 from iceberg2

都可以正常查询
Kafka再次插入数据尝试
插入相同char8的数据尝试,共插入两条数据
{"tinyint0": 6, "smallint1": 123, "int2": 123, "bigint3": 123, "float4": 123.47324181659323, "double5": 340.5755392968011,"decimal6": 111.1111, "boolean7": true, "char8": "dddddd", "varchar9": "buy0", "string10": "buy1", "timestamp11": "2021-09-13 03:08:50.810"}

查询v1 表

查询v1 表

v1表与v2表区别
v1表是appent表,可以插入所有测试类型字段,但是查询TINYINT,SMALLINT数据类型失败,不能设置主键进行upsert
v2表是upsert表,开启upsert时,不可插入TINYINT,SMALLINT,主键必须指定分区字段,因为Delete writer必须知道写入的分区是什么,所以主键才必须包含分区使用的字段,会根据key来修改数据
hive sql 查询 iceberg 表
hive查询iceberg表时,必须将iceberg-hive-runtime-2d102f5.jar放置HIVE_HOME/auxlib下,然后进行重启才可正常查询,hive(iceberg)表通过flinksql 创建iceberg时已经sync至hive中
进入hive sql

查询 v1表

查询v2表

hive where count查询iceberg问题总结
select count(1) from iceberg1 where int2 =123 ;

set hive.optimize.ppd=false;
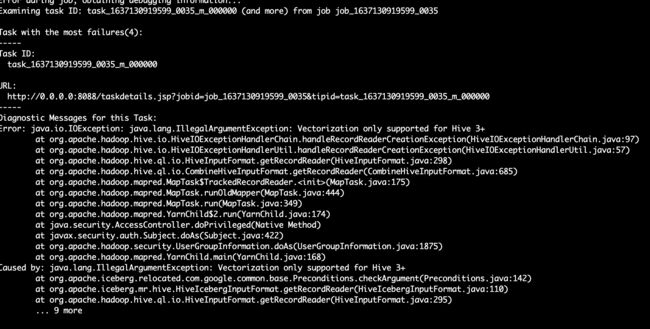
SET hive.vectorized.execution.enabled=false;
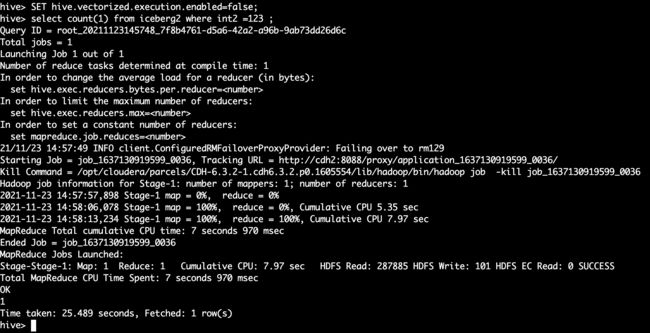
Presto 查询iceberg
presto通过iceberg catalog查询iceberg表
iceberg catalog 配置
connector.name=iceberg
hive.metastore.uri=thrift://cdh2:9083
iceberg.file-format=orc
hive.config.resources=/etc/alternatives/hadoop-conf/core-site.xml,/etc/alternatives/hadoop-conf/hdfs-site.xml
重启后查询iceberg表
本次测试通过dbeaver查询presto测试
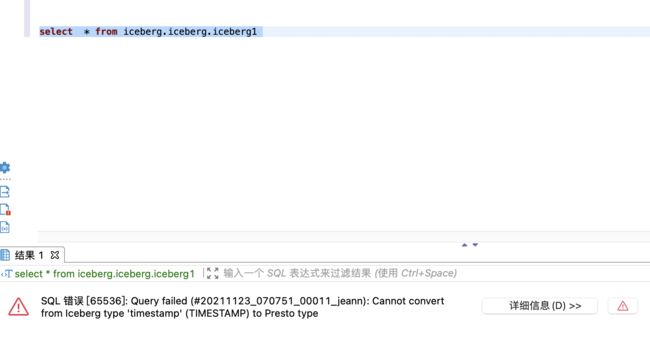
查询v1表
查询v2表
查询超时
presto查询iceberg问题总结
v1表暂时不支持查询TIMESTAMP类型字段,社区正在解决 https://github.com/prestodb/presto/issues/16996
v2表暂时不支持查询。。
Trino查询iceberg
trino通过iceberg catalog查询iceberg表
本次测试通过dbeaver查询Trino测试

查询v1表
查询iceberg

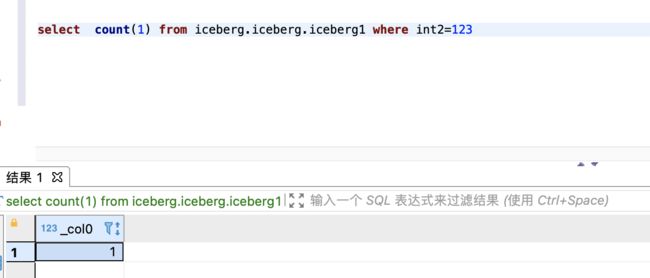
筛选统计
select count(1) from iceberg.iceberg.iceberg1 where int2=123
查看v1表所有快照信息
SELECT * FROM iceberg.iceberg."iceberg1$snapshots" ORDER BY committed_at
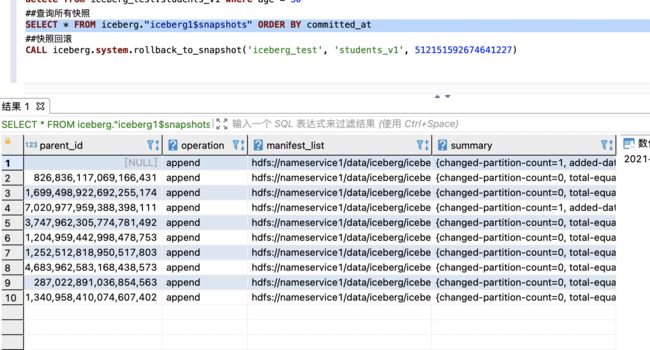
回滚快照后查询
CALL iceberg.system.rollback_to_snapshot('iceberg', 'iceberg1', 1699498922692255174)

查询回滚后数据
select * from iceberg.iceberg.iceberg1

所有命令
v1表查询
##trino 查询所有数据
select * from iceberg.iceberg.iceberg1
##按照分区删除
delete from iceberg.iceberg.iceberg1 where tinyint0 = 6
##查询所有快照
SELECT * FROM iceberg.iceberg."iceberg1$snapshots" ORDER BY committed_at
##快照回滚
CALL iceberg.system.rollback_to_snapshot('iceberg', 'iceberg1', 1699498922692255174)
查询v2表

trino查询iceberg问题总结
v2表暂时不支持查询。。
查询结论
| v1 | v2 | |
|---|---|---|
| Flink | TINYINT,SMALLINT不支持 | TINYINT,SMALLINT不支持 |
| Hive | Y | Y |
| Presto | TIMESTAMP不支持 | N |
| Trino | Y | N |
| 流读 | Y | N |
| upsert | N | Y |
问题总结
hive where count问题
java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.io.sarg.ConvertAstToSearchArg.create(Lorg/apache/hadoop/conf/Configuration;Lorg/apache/hadoop/hive/ql/plan/ExprNodeGenericFuncDesc;)Lorg/apache/hadoop/hive/ql/io/sarg/SearchArgument;
set hive.optimize.ppd=false;
Error: java.io.IOException: java.lang.IllegalArgumentException: Vectorization only supported for Hive 3+
SET hive.vectorized.execution.enabled=false;
presto timestamp
https://github.com/prestodb/presto/issues/16996