论文-《MUREL: Multimodal Relational Reasoning for Visual Question Answering Remi》笔记
重点翻译拓展
摘要:
如今在涉及真是图像的VQA任务中,多模态注意力网络时性能最好的,但是这种简单的机制不足以对复杂的推理特征或者高层次的任务进行建模。因此,我们提出了MuRel,一个能在真实图像中学习端到端推理的多模态关系网络。我们的贡献主要有两个:一是引入了MuRel单元,一种通过丰富的向量表示来对问题和图像区域间的交互进行自动推理,和对成对结合区域关系进行建模的结构;二是合并MuRel单元到MuRel网络,,该网络逐渐细化了图像和文本的交互。
背景:
1.深度学习最近处理问题:
最近,深度学习开始处理一些复杂的视觉推理问题,例如:关系检测(relationship detection)、目标识别(objection recognition)、多模态检索(multimodal retrieval)、抽象推理(abstract reasoning)、视觉因果(visual causality)、是绝对话(visual dialog)。
2.视觉推理:
关于视觉推理这个研究主要是通过CLEVR数据集,这个数据集提供了一些需要推理的简单问题。其中处理CLEVR数据集比较好的模型有FiLM,MAC network。
3.真实数据的VQA:
VQA研究最重要的一部分就是对两个空间向量的高层次关系进行表示,在目前的多模态融合机制里,最受欢迎的是二阶交互(second order interaction)或者是张量分解(tensor decomposion)。在VQA关系推理中,最常使用的推理框架是软注意力机制(soft attention),给定一个问题,模型可以标注每个区域的重要程度分数,并使用它们进行权重求和和池化来视觉表示。多重注意力可以并行或者顺序计算,这其中的代表算法是结构注意力(Structured Attention)。
4.MuRel的贡献:
移除了传统的注意力框架,采用了向量化表示方法,对每个区域的视觉内容和问题进行建模。此外,还在表示中加入了空间和语义环境的概念,即通过视觉嵌入和空间坐标的交互来表示成对的图像区域。
模型方法:
该模型如下图所示:

输入一个图像v和一个问题q,需要获得一个符合真实答案a*的预测答案 。,传统VQA模型通常看作一个分类问题:
。,传统VQA模型通常看作一个分类问题:
![]()
而在该文章提出的方法里,图像表示为一组向量{vi},每个vi对应于图像中的一个目标,在引入空间坐标bi=[x,y,w,h],其中[x,y]表示边界框走上教的位置,[w,h]表示边界框的宽和高。对于问题,则需要门控循环单元(gated recurrent unit)提供一个句子嵌入q。
1.MuRel cell:
MuRel cell首先以N个可视特征作为输入,这些特征都带着坐标bi。它有两个模块做成,第一个是双线性混合模型,可以合并问题和区域特征向量提供的局部多模态嵌入,第二个是成对的建模组件。
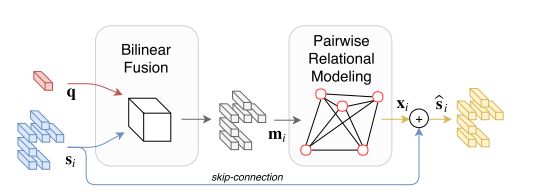
Multimodal fusion:
我们想要将问题信息包含到可视化表示si中,最近刚提出许多策略,其中最高效的是基于三阶张量(third-order tensors)的Tucker 分解(Tucker decomposition),这是一种双线性融合方法。
![]()
传统的注意力模型中,对图像和问题特征s和q的混合是使用encoder方法。而在MulRel cell中,局部多模态信息用mi表示,它可以对模态间更复杂的关系进行编码。
Pairwise interactions:
为了获得多个目标之间的相互关系,根据文献,选择了成对交互模型(pairwise relationship modeling),一个区域对应于K个相似邻域,也就是说MuRel cell的邻域由图像中的每个区域构成。另外作者合并空间和语义表示建立关系向量的方法来代替文献中使用标量成对注意力和高斯核卷积的方法。
2.MuRel netWork:
MuRel网络通过利用双线性融合的能力,将视觉信息迭代地合并到上下文感知视觉嵌入中,从而模仿了一种简单的迭代推理的形式。MuRel network不仅表示和问题相关的区域,也是用自己的视觉上下文,这种表示是通过MuRel cell的多步迭代完成的,每个cell的权值共享,这种残差特性可以使它不受梯度消失的影响,这些都是的该网络具有较好的泛化性和紧密的参数化。
Visualizing MuRel network:
该模型利用可视化方案,强调图像和特定回答间的重要关系。在MuRel网络的最后,视觉特征{si}使用最大化操作进行整合,生成维度为dv的向量s,最后通过测量每个区域对最后向量的贡献程度计算出一个贡献图,并且这个过程是在每一个MuRel Cell之后而不是只在最后一个后边。
同样地,也可以用MuRel Cell对预测结果中的成对关系进行可视化。
Connection to previous work:
将MuRel 网络和之前的FiLM网络进行比较,FiLM网络是为了处理合成数据集CLEVR而建立的,而MuRel网络是为了处理真实数据集,但是两者还存在一些联系。在FiLM网络中,将图像传入一个多步残差单元,而MuRel网络中,是将图像传入一个迭代单元;在多模态交互中,FiLM网络使用的是仿射变换(affine modulation),而MuRel网络使用的是双线性融合(bilinear fusion);最后,FiLM网络和MuRel网络都利用图像表示的空间结构来对区域间的关系进行建模,FiLM网络中,图像用全卷积网络表示,MuRel网络中,图像使用一系列局部特征表示。
实验:
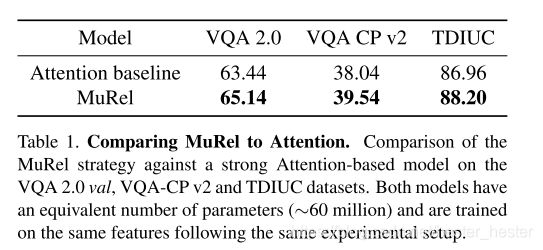
首先将MuRel模型和作为baseline的attention进行比较,验证模型的是否合理:
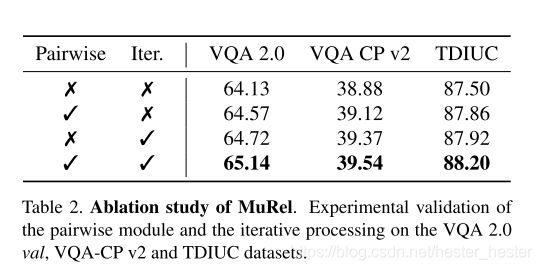
在模型中分别测试成对(Pairwise)和迭代(Iterative)对准确率的影响,发现两个都加入时准确率最高,可见这两个时互补的:
探究对于不同类型的问题迭代次数的影响:

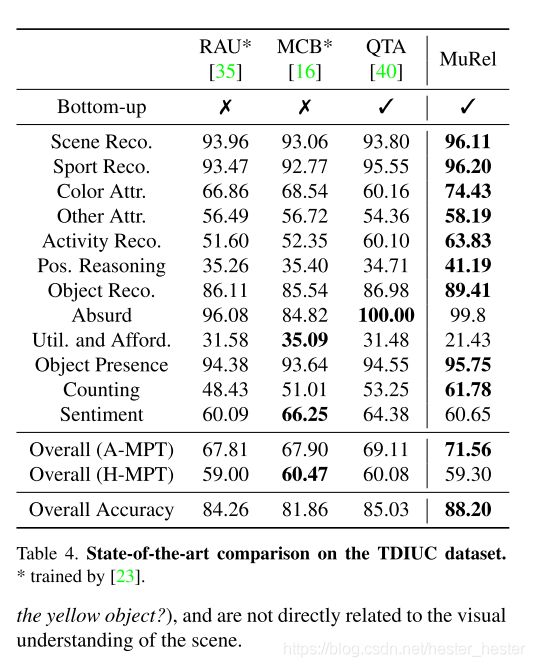
不同的模型在不同数据集的比较:


模型实例:
