线性回归、Arima和LSTM做单特征预测
一、数据集展示
1.本文只针对单特征的时间序列,这里分别只有时间和牛肉批发价两个特征,一共是三百多条数据
二、模型
1.线性回归
任务:只以当前的牛肉批发价作为特征,预测过后5天的牛肉批发价
(1)线性回归需要有x和y两个维度,这里将原本的牛肉批发价作为x,将第五天开始到最后一天的牛肉批发价作为y,进行训练。
(2)划分训练集和测试集
X_train, X_test,y_train, y_test
对训练集进行fit,最后使用predict 对测试集进行测试,得到y_pred,最后进行预测的后五天与以前的综合在一块,进行比较。
(3)代码
import pandas as pd
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
data = pd.read_csv(r'C:\Users\独为我唱\Desktop\archive\rice_beef_coffee_price_changes.csv')
# 提取特征和目标变量
X = data['Price_beef_kilo'].values.reshape(-1, 1) # 牛肉批发价作为特征,转换成二维数组
y = data['Price_beef_kilo'].shift(-5).dropna().values.reshape(-1, 1) # 预测过后5天的牛肉批发价作为目标变量,转换成二维数组
# 划分训练集和测试集
train_size = int(len(X) * 0.8) # 80%作为训练集
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 在测试集上进行预测并评估模型性能
y_pred = model.predict(X_test) # 360, 1
y_test_1 = np.delete(X_test, range(60,72), axis=0)
y_pred_1 = np.delete(y_pred, range(0,60), axis=0)
y_test_pred = np.concatenate((y_test_1, y_pred_1), axis=0)
# 绘制折线图
plt.rcParams['font.sans-serif']=['SimHei']
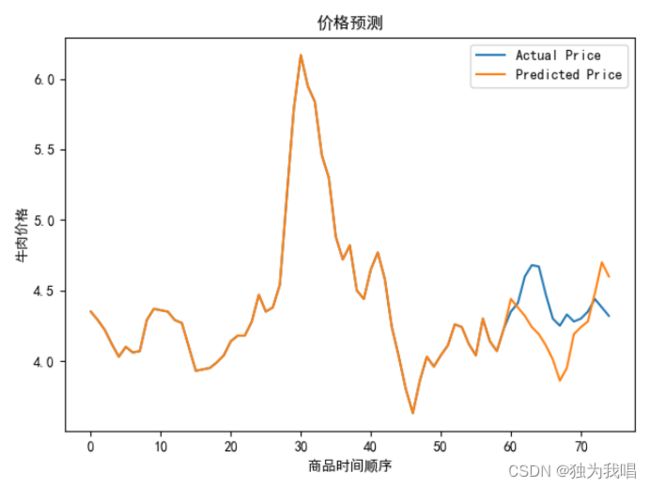
plt.plot(X_test, label='Actual Price') # 绘制实际价格折线图
plt.plot(y_test_pred, label='Predicted Price') # 绘制预测价格折线图
plt.legend()
plt.title('价格预测')
plt.xlabel('商品时间顺序')
plt.ylabel('牛肉价格')
plt.show()(4)结果图
2.LSTM
任务:以rice价格和coffee价格为特征
代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
df = pd.read_csv(r'C:\Users\独为我唱\Desktop\archive\rice_beef_coffee_price_changes.csv')
df = df[['Year', 'Price_beef_kilo', 'Price_rice_kilo', 'Price_coffee_kilo']]
# 将日期转换为时间戳,并将其设置为索引
df['date'] = pd.to_datetime(df['Year'])
df.set_index('date', inplace=True)
# 创建特征矩阵和目标向量
X = df[['Price_beef_kilo', 'Price_rice_kilo']].values
y = df[['Price_coffee_kilo']].values
# 对数据进行归一化处理
scaler = MinMaxScaler(feature_range=(0, 1))
X = scaler.fit_transform(X)
y = scaler.fit_transform(y)
# 分割数据集为训练集和测试集
train_size = int(len(X) * 0.8)
test_size = len(X) - train_size
X_train, X_test = X[0:train_size,:], X[train_size:len(X),:]
y_train, y_test = y[0:train_size,:], y[train_size:len(X),:]
print("分割数据集为训练集和测试集成功!")
# 将数据集转换为适合LSTM模型的形状 [样本数,时间步数,特征数]
def create_dataset(X, y, time_steps=1):
Xs, ys = [], []
for i in range(len(X) - time_steps):
v = X[i:(i + time_steps)]
Xs.append(v)
ys.append(y[i + time_steps])
return np.array(Xs), np.array(ys)
time_steps = 18
X_train, y_train = create_dataset(X_train, y_train, time_steps)
X_test, y_test = create_dataset(X_test, y_test, time_steps)
# 打印数据集的形状
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# 定义LSTM模型
model = Sequential()
model.add(LSTM(units=64, input_shape=(time_steps, 2)))
model.add(Dropout(0.5))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=16)
# 进行预测
y_pred = model.predict(X_test)
# 将归一化的预测结果反转回原始值
y_test = scaler.inverse_transform(y_test)
y_pred = scaler.inverse_transform(y_pred)
# 预测
y_test_1 = np.delete(y_test, range(42,54), axis=0)
y_pred_1 = np.delete(y_pred, range(0,42), axis=0)
y_test_shiji = np.concatenate((y_test_1, y_pred_1), axis=0)
# 绘制原始结果和预测结果的对比图
plt.rcParams['font.sans-serif']=['SimHei']
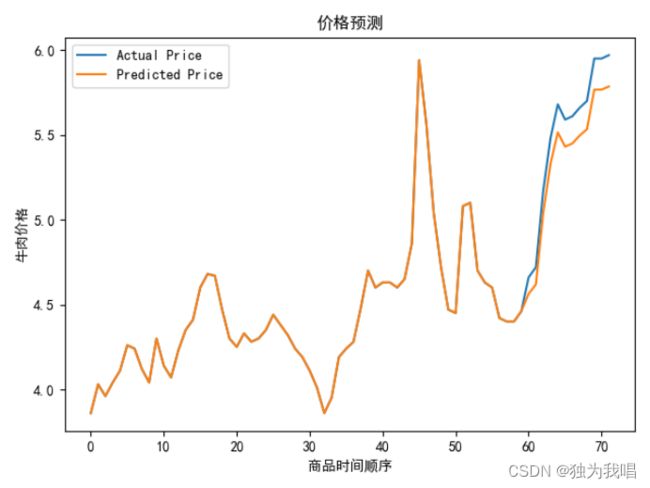
plt.plot(y_test, label='Actual Price')
plt.plot(y_test_shiji, label='Predicted Price')
plt.legend()
plt.title('价格预测')
plt.xlabel('商品时间顺序')
plt.ylabel('牛肉价格')
plt.savefig('C:\\Users\\独为我唱\\Desktop\\archive\\lstm_model_1.pdf', bbox_inches='tight' )
plt.show()结果图:
三、Arima自适应回归
任务:只利用牛肉批发价这一个特征进行预测
代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 读取数据
df = pd.read_csv(r'C:\Users\独为我唱\Desktop\archive\rice_beef_coffee_price_changes.csv')
data = df['Price_beef_kilo'].values
# 拆分训练集和测试集
train_size = int(len(data) * 0.67)
train_data, test_data = data[:train_size], data[train_size:]
# 构建ARIMA模型
p, d, q = 3, 1, 0 # 选择ARIMA的参数
model = ARIMA(train_data, order=(p, d, q))
model_fit = model.fit()
# 进行预测
forecast = model_fit.forecast(steps=len(test_data))
#拼接, 展示时分别展示原始的牛肉价格和包含了对最后十天预测的牛肉价格
y_test_1 = np.delete(test_data, range(60,72), axis=0)
y_pred_1 = np.delete(forecast, range(0,60), axis=0)
y_test_pred = np.concatenate((y_test_1, y_pred_1), axis=0)
test_data = np.delete(test_data, range(75,119), axis=0)
y_test_pred = np.delete(y_test_pred, range(75,166), axis=0)
# 绘制原始结果和预测结果的对比图
plt.rcParams['font.sans-serif']=['SimHei']
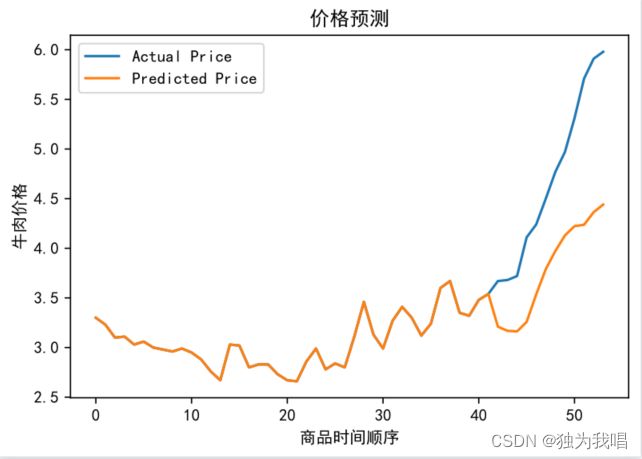
plt.plot(test_data, label='Actual Price')
plt.plot(y_test_pred, label='Predicted Price')
plt.legend()
plt.title('价格预测')
plt.xlabel('商品时间顺序')
plt.ylabel('牛肉价格')
plt.show()
结果图: