大语言模型浅探一
目录
1 前言
2 GPT模型解码
3 InstructGPT
4 基于RWKV微调模型
4.1 RWKV简介
4.2 增量预训练
4.3 SFT微调
4.4 RM和PPO
5 测试
6 总结
1 前言
近来,人工智能异常火热,ChatGPT的出现极大的推动了自然语言处理的发展,在推出仅两个月后,月活跃用户已达1亿,成为历史上增长最快的消费应用。OpenAI一直在研究生成式模型,在2018年6月发布了GPT,在2020年5月发布了GPT3,GPT3的模型参数也达到了1750 亿。但是为什么到现在ChatGPT才突然间火起来呢?
众所周知,模型只有达到一定的参数量才会出现涌现能力,但是两年强模型参数已经达到了1750亿,说明单纯的堆模型参数并不能达到想要的效果。或许在OpenAI的一篇论文InstructGPT(Training language models to follow instructions with human feedback)中可以找到答案。接下来本文会简单介绍InstructGPT,然后基于RWKV去复现,之所以选择RWKV是因为其速度快,占用GPU显存低,便于快速实验。
2 GPT模型解码
这里我感觉有必要把生成式模型的解码输出单独拿出来讲一下,只有理解了答案生成的原理才能更好理解InstructGPT所做的工作。
GPT属于生成式预训练语言模型,只采用了Transformers的Decoder结构,并对Decoder进行了一些改动,去掉了第二个Multi-Head Attention。推理解码过程就是利用当前token和前面输入所有token的状态矩阵去预测下一个token的过程,直到输出位终止符。例如输入tokens序列为[u1,u2,u3,u4,u5],词典大小为20000,则输出
![]()
上面公式中,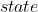 为前面输入所有词的状态矩阵,即保存的是每个词的词向量,
为前面输入所有词的状态矩阵,即保存的是每个词的词向量, 是一个1*20000的矩阵,此时的模型若是没有经过任何微调,此时的分布是比较分散的,如何从20000个词中挑选合适的词有几种方案:
是一个1*20000的矩阵,此时的模型若是没有经过任何微调,此时的分布是比较分散的,如何从20000个词中挑选合适的词有几种方案:
第一种:贪心搜索(greedy search),每次都取概率最大的。贪心搜索是局部最优,但是不能保证全局最优。
第二种:集束搜索(beam search),每次取top-b个得分最高的句子,得分的计算很关键,但是这里不是我要讲的重点,感兴趣的可以自己去了解一下。这种方法比贪心搜索好一点儿。
第三种:随机采用,每次按照概率随机取一个,概率越高越有可能被采到。基于此又有了temperature sampling,top-k sampling和top-p sampling等改进方案。随机采用是目前使用的比较频繁的方式,这里简单说一下。
temperature sampling:设置一个temperature参数来控制概率分布的弥散程度,temperature越接近0,则数值间差异被指数级放大,被采样的数值范围就越小,体现在回答上面就是多次解码结果不会有太大变化。
top-k sampling:取概率最高的top-k个词作为候选采样词,剩余的置为0。
top-p sampling:将词按照概率从大到小排序,从第1个词开始累加,直到累加和大于等于top-p为止,作为候选采样词,剩余的置为0。
随机采用一般是几种方法组合使用,但是有时不管如何组合调整,模型还是会遇到不能生成终止符的情况,即产生一个概率为零的无限长序列,实际上也会添加最长长度限制或者随着输出长度的增加,提高终止符的概率等等。
基于以上问题,学术界一直在探索新的方法可以让正确的答案(人们想要的答案)生成的概率更高,从而更容易被解码出来,而InstructGPT利用人工反馈强化学习进行了探索。
3 InstructGPT
InstructGPT论文的地址:https://arxiv.org/pdf/2203.02155.pdf
总结一下就是:大语言模型可能会生成不真实、有害和对用户没有帮助的简单答案。InstructGPT通过在多种任务上面指令微调以及人类反馈强化学习(RLHF)来降低这种无效输出的概率。
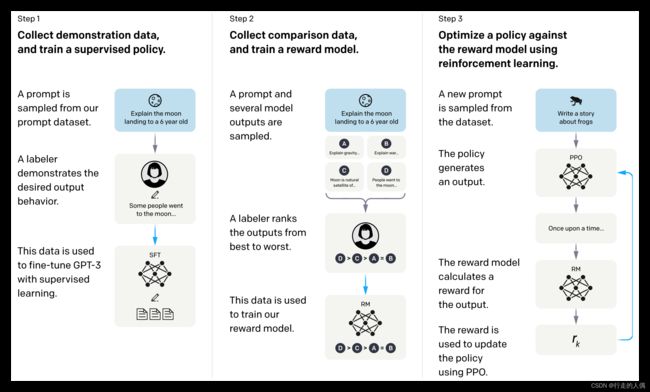
从图中可以看到,两个过程是分三步来进行的。监督微调SFT(supervised fine-tuning),训练reward model(RM)和强化学习(RL)微调。
SFT:也有人把这个阶段叫做指令微调,还有叫做模型精调,不过这都不重要,这个阶段的目的只有一个,就是让模型能识别指令。训练完成后体现在解码上就是指令可能有很多种回答,这些回答的概率都很高,通过多次随机采用解码,每次解码基本上都不一致。若是没有经过微调的模型,只能通过prompt利用语言模型的能力来让模型理解指令,这时答非所问的情况就更容易出现。
RM:训练一个得分模型,即可以对模型的输出打分,便于后面训练PPO。得分模型需要人工标注数据,同一个prompt需要有一条好的回答,一条差的回答构成一条训练语料(也可以理解为一条比另一条好就行)。
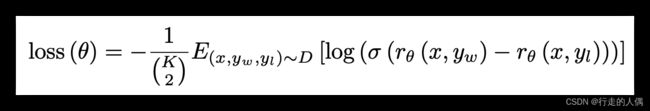
r为打分模型,可以在SFT的模型基础之上添加全连接层改造成一个分类器得到,x为prompt,yw和yl为RM模型的两个输出,一个是好的回答,一个是不好的回答,最小化loss即将二者的得分差扩大。人工标注的数据训练,则会让符合人类回答的答案得分更高。
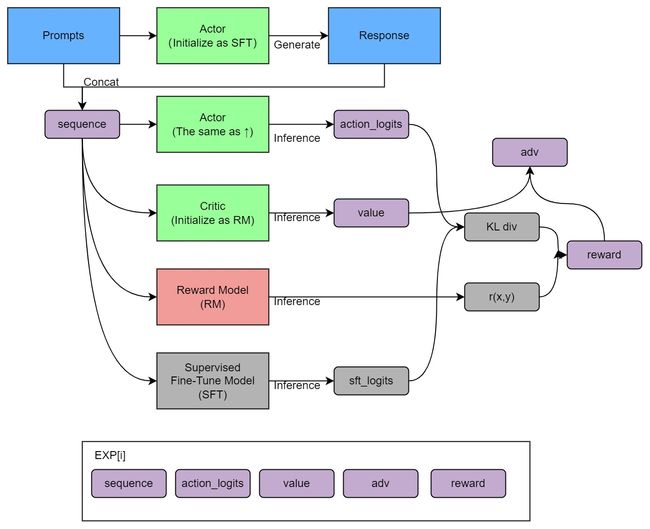
RL:主要采用的是近端策略优化模型( reinforcement learning via proximal policy optimization)。架构图参考ColossalAI。强化学习微调,会让得分高的答案,概率更高,得分低的答案,概率更低,提高差异,采样时即使不怎么调整参数,也会只采样到正确的答案。
4 基于RWKV微调模型
我们基于RWKV1.5B模型作为基模型,使用CSDN博客100W篇和问答30W条数据进行中文垂直领域增量训练,使用BELLE开源的50K指令数据进行指令微调。这里将训练后的命名为ChatCSDN,可以作为入门大模型的Hello World来参考学习使用。
项目地址:https://gitcode.net/csdn/ai/chatcsdn
模型参数地址:zxm2023/ChatCSDN · Hugging Face。
4.1 RWKV简介
RWKV的介绍除了作者的项目外,还可以参考另一篇博文:RWKV:一种鱼和熊掌兼得的线性transformer模型 - 知乎
想了解RWKV必须先看苹果的AFT(An Attention Free Transformer)论文,它和标准的注意力算法结构相同,同样包含QKV结构,K和V首先与一组学习得到的位置偏差(position bias)结合,然后再进行同位元素Q对应相乘(element-wise multiplication)。

从上图可以看出,QKV的计算转换成了线性计算,速度得到了极大提升。但是wt是一个需要训练的矩阵,大小为ctx_len*ctx_len,即模型的参数量随输入长度的增加而指数级增加,模型能处理的句子长度严重受限。
而RWKV就是针对AFT不能训练长文本的特点,进行了改进,主要引入了Position Matrix、Time-shit、TimeMix和ChannelMix 等结构,相较于原始的GPT结构,RWKV将self-attention替换为Position Encoding和TimeMix,将FFN替换为ChannelMix。

RWKV项目地址:RWKV-LM/RWKV-v4neo at main · BlinkDL/RWKV-LM · GitHub
1.5B模型参数地址:BlinkDL/rwkv-4-pile-1b5 · Hugging Face
4.2 增量预训练
RWKV模型基本上都是采用英文进行的训练,这里使用中文的CSDN博客数据和问答数据进行垂直领域增量式训练,同时也会引入部分代码。如果大家也想尝试一下增量式训练,可以参考如下的步骤。
数据预处理。直接参考原作者的数据处理步骤需要按照很多包,这里已经将需要的包都移植到tools里面了。首先使用clean_data.py中的clean_ask_data和clean_blog_data方法可以将从数据仓库中拉取的数据转换成jsonl文件。之后进入tools文件夹下使用如下命令将数据转换成idx和bin文件:
python preprocess_data.py \
--input ../data/data.txt \
--output-prefix ../data/blog \
--vocab ../20B_tokenizer.json \
--dataset-impl mmap \
--tokenizer-type HFTokenizer \
--append-eod增量预训练。使用前面n-1个词预测第n个词。
x = torch.tensor(dix[:-1], dtype=torch.long)
y = torch.tensor(dix[1:], dtype=torch.long)从上面断面可以看出x和y只是错开了一个token,例如:原始句子的tokens为[u1,u2,u3,u4,u5,u6],x为[u1,u2,u3,u4,u5],y为[u2,u3,u4,u5,u6]。
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))使用如上的代码计算loss。
python train.py --load_model "RWKV-4-Pile-1B5-EngChn-test4-20230115.pth" --wandb "" --proj_dir "out" \
--data_file "data/blog_text_document" --data_type "binidx" --vocab_size 50277 \
--ctx_len 1024 --epoch_steps 200 --epoch_count 1000 --epoch_begin 0 --epoch_save 10 \
--micro_bsz 8 --n_layer 24 --n_embd 2048 --pre_ffn 0 --head_qk 0 \
--lr_init 1e-5 --lr_final 1e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.999 --adam_eps 1e-8 \
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_2_offload --grad_cp 1使用上面的命令开始训练。 load_model代表要加载的模型,data_type是数据类型,data_file是训练数据,precision是数据的精度,epoch_save是多久保存一次,ctx_len是窗口长度,每条数据多少个token,micro_bsz是批大小,gpu显存不够的可以设置的小一些。
4.3 SFT微调
构造训练用的指令数据,这里添加了相应的角色指令。
data_list = []
for index, row in pf.iterrows():
input = row["input"]
target = row["target"]
input_instruction = f"Below is an instruction that describes a task. Write a response that appropriately " \
f"completes the request.\n\n### Instruction: {input}\n\n### Response:"
input_tokens = self.tokenizer.tokenizer.encode(input_instruction)
target_tokens = self.tokenizer.tokenizer.encode(target)
if len(input_tokens) + len(target_tokens) > self.args.ctx_len:
continue
data_list.append((input_tokens, target_tokens))“### Instruction”和“### Response”问答对话的两个角色。这里写什么后续推理时最好也要用同样的方式构造prompt。
def __getitem__(self, index):
ctx_len = self.args.ctx_len
req_len = ctx_len + 1
i = np.random.randint(0, len(self.data))
question, answer = self.data[i]
text = question + answer
text = text[:req_len]
text = text + [0] * (req_len - len(text))
x = torch.tensor(text[:-1], dtype=torch.long)
y = torch.tensor(text[1:], dtype=torch.long)
z = [0] * len(question) + [1] * (ctx_len - len(question))
z = torch.tensor(z, dtype=torch.long)构造x,y和z,z代表mask,后面计算loss使用,会将前面的instruction给屏蔽掉。
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), reduction='none')
# loss_raw = loss
loss = torch.sum(loss * mask) / sum_mask4.4 RM和PPO
RM和PPO代码部分已经初步完善,待测试训练。
5 测试
将训练好的模型使用chat.py运行,解码方式采用的是随机采用解码。部分结果如下:
### Instruction: 你好
### Response:Hello! Nice to meet you!
### Instruction: 用java实现冒泡排序
### Response:以下是使用Java实现冒泡排序的代码:
```java
public void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
```
该方法的工作方式是,首先将数组排序,然后比较相邻的两个数字是否相等,如果相等,则交换它们的位置,并重新计算下一个数字的位置
### Instruction: +++
### Response:。
在实际应用中,您可以将此方法替换为任何其他适用的排序算法,例如快速排序、归并排序或基数排序等。
### Instruction: 帮我写一段JavaScript数组去重代码
### Response:```JavaScript
function uniqueArray(arr) {
// 去重
let unique = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i] === arr[i]) {
unique.push(arr[i]);
}
}
return unique;
}
```
此方法将一个数组转化为一个新的数组,在此过程中,会判断每个元素是否已经在原数组中,如果是则不会重复元素,否则则会添加到新数组中去。这样就可以将原始数组转化为新数组,避免重复元素。
### Instruction: How about JOYI Sports Company? 翻译成中文
### Response:科基力学(JOYI)是一个怎样的公司?6 总结
1、rwkv速度已经很快了,单卡可达到500+token/s,但是在亿级甚至更大的tokens面前,也显得有点儿力不从心。
2、没有经过强化学习微调的模型,多次随机采用的结果都会不一致,要想得到理想的回答,可能需要多试几次。
3、1.5B受限于语言模型本身的限制,语言能力较弱,用来做大模型的入门学习还是挺不错的。后续我们会将代码和模型参数开源出来供大家一起学习研究。