pandas:sql能的,我都能!!!
通常我们用sql处理数据库里的数据,其实sql对数据的操作,在pandas中完全可以实现。
接下来,让我们根据sql执行顺序,来依次看看pandas对应的方法。
1. from … join 连表查询
sql中首先是从from table_name开始,单张表就不特地说了,若是多张表连接的时候,有5中连接情况。
table1 (inner) join table2
table1 left (outer) join table2
table1 right (outer) join table2
table1 full (outer) join table2
table1 cross join table2 # 笛卡尔积
在pandas中,有对应的函数能实现将表连接起来这个功能。
- merge
pandas.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
left: 左表表名
right :右表表名
how:连接方式,就有inner,left,right,outer,cross就对应sql中的各个连接方式
on,left_on,right_on,left_index,right_index:表示两张表需要根据什么值连接就可以写在这边。若两边相连的值具有相同的列名就直接用on,若是列名不同则分别用left_on和right_on分别指定列名,若是需要根据index相连,则通过left_index或者right_index=True指定。
suffixes:若是两张表中都有相同列名的字段,他默认是给你用column_x,column_y的方式给你区分开,可以自己定义列名
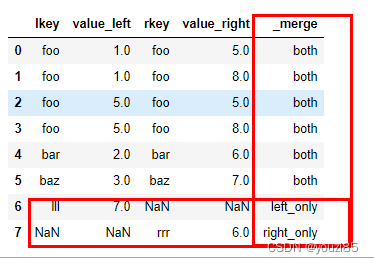
indicator:默认False,若是True,则会添加一列"_merge",这一列会标注合并键数据的存在是因为存在在左表(left_only),存在在右表(right_only)还是这个数据两个表都有(both)。
validate:可以验证合并是否为指定类型:有one_to_one(1:1),one_to_many(1:m),many_to_one(m:1),many_to_many(m:m),若是数据和选择的指定类型不符合,会直接报错。*
举个例子一起看看:
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo','lll'],
'value': [1, 2, 3, 5,7]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo','rrr'],
'value': [5, 6, 7, 8,6]})
# how默认是inner,若是inner连接可以默认不写
pd.merge(df1,df2,left_on='lkey',right_on='rkey');

# how=left,则左表中所有的数据都会显示
pd.merge(df1,df2,how='left',left_on='lkey',right_on='rkey')

# how=right右表的数据完全显示,并且修改重叠列名的后缀
pd.merge(df1,df2,how='right',left_on='lkey',right_on='rkey',suffixes=('_left','_right'))

pd.merge(df1,df2,how='outer',left_on='lkey',right_on='rkey',suffixes=('_left','_right'),indicator=True)
- join
DataFrame.join(other, on=None, how=‘left’, lsuffix=‘’, rsuffix=‘’, sort=False, validate=None)
和merge功能相同,可以连接表。但是这两个函数也有区别。
join默认的连接方式是左连接(left),而merge默认的连接方式是内连接(inner)。
join默认连接两张表的方式是根据两张表的index连接,若是要根据某一列连接,则要通过on指定,这个后面例子会给出。而merge则没有这个默认要求。
join时,如果两张表中有相同的列名,一定要指定lsuffix和rsuffix,否则会直接报错,而merge则没要求,默认会给你的相同列添加上_x,_y来区别来自两个不同的表的数据。
举个例子一起看看,还是那上面的那个数据,用join连接:
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo','lll'],
'value': [1, 2, 3, 5,7]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo','rrr'],
'value': [5, 6, 7, 8,6]})
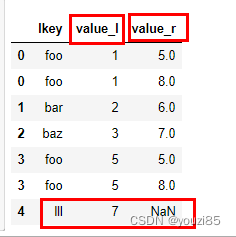
df1.join(df2.set_index('rkey'),on='lkey',lsuffix='_l',rsuffix='_r')
# 因为重设了index,符合index_to_index连接,所以不需要在指定on
df1.set_index('lkey').join(df2.set_index('rkey'),lsuffix='_l',rsuffix='_r')
注意:join默认用的是df1和df2的index去连接。若是需要用某一列去连接,可以用on指定在左表中的列名,但是此时还是用右表中的index去连接,如果on指定左表的多列,那右表必须是符合索引。
df1和df2都是value列,所以必须指定lsuffix和rsuffix,否则直接报错,你可以看看。
# 若是需要根据某两列去匹配表
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo','lll'],
'lcol':['aa','bb','aa','bb','aa'],
'value': [1, 2, 3, 5,7]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo','rrr'],
'rcol':['aa','bb','aa','aa','aa'],
'value': [5, 6, 7, 8,6]})
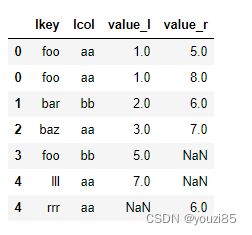
df1.join(df2.set_index(['rkey','rcol']),on=['lkey','lcol'],how='outer',lsuffix='_l',rsuffix='_r')
# 当两个表用复合索引连接时,还是必须用on指定索引名
df1.set_index(['lkey','lcol']).join(df2.set_index(['rkey','rcol']),on=['lkey','lcol'],how='outer',lsuffix='_l',rsuffix='_r')
如此看来,其实join用起来不如merge方便,不需要查看两张表的index是否是连接的键。并且merge对于两个表中相同的列名会自动添加_x,_y帮助识别,而不是直接报错,必须手动指定。
但是join有一个优点的。他可以同时合并多个dataframe。
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo','lll'],
'value': [1, 2, 3, 5,7]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo','rrr'],
'value': [5, 6, 7, 8,6]})
df3 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo','lll','rrr'],
'value': [7,6,3,5,8,5]})
df1.set_index('lkey').join([df2.set_index('rkey'),df3.set_index('rkey')])

# 当合并多个dataframe的时候,此时已经没必要指定lsuffix,rsuffix,哪怕指定也无效
df1.set_index('lkey').join([df2.set_index('rkey'),df3.set_index('rkey')],how='outer',lsuffix='_l',rsuffix='_r')

# 当同时合并多个dataframe时,只支持行索引连接,不能使用参数on。使用on会报错
df1.join([df2.set_index('rkey'),df3.set_index('rkey')],on='lkey')

2. where 条件过滤
select * from table_name where xxx;
在sql中,当需要从表中过滤某些不必要的数据,就是在where这一步。并且可以通过逻辑词and,or连接不同筛选要求。同样在pandas中能实现这个情况。
- 使用布尔索引
# 给个测试数据
date1 = ['星期一','星期二','星期三','星期四','星期五','星期六','星期日']
items = ['白菜','萝卜','土豆','辣椒']
df = pd.DataFrame({'时间':np.random.choice(date1,size=100),
'items':np.random.choice(items,size=100),
'销量':np.random.randint(50,200,size=100)
})
df

# 查看萝卜的销售情况
pd.set_option('display.max_rows',10) # 结果显示页面太长,所以设置只显示10行
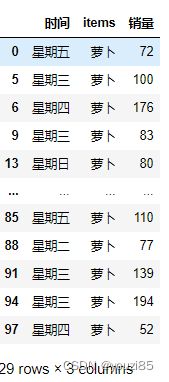
df[df['items']=='萝卜']
# 若是需要多个条件可以实现
# 查看星期五的土豆销售情况
df[(df['items']=='土豆') & (df['时间']=='星期五')]
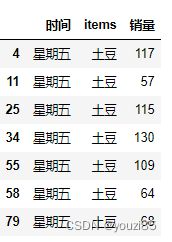
sql中的AND和OR在这里分别是&,|。
- query
DataFrame.query(expr, *, inplace=False, **kwargs)
query中要传入要评估的查询字符串
同样上面两个要求对应的语法如下。
df.query('items=="萝卜"')
df.query('items=="土豆" & 时间=="星期五"')
结果图片和上面一样,不再给出,可以看出用query,语法上会稍微简洁一点。
当列名称有空格或其他特殊情况,可以使用反引号( `` )来引用。
query中不仅支持&,|,还支持and,or上面的语句也可以写成:
df.query('items=="土豆" and 时间=="星期五"')
更多使用情况,还可以看:https://blog.csdn.net/weixin_42596342/article/details/120303484
- filter
DataFrame.filter(items=None, like=None, regex=None, axis=None)
items:保留项目中列的标签
like:保留来自"like in label==True"的轴的标签
regex:正则表达式
axis:0(‘index’),1(‘columns’),默认是dataframe的columns
filter这个函数用户来过滤索引的标签
df1 = pd.DataFrame(np.array(([1, 2, 3,'ett'], [4, 5, 6,'atel'])),
index=['mouse', 'rabbit'],
columns=['one', 'two', 'three','type'])
df1

过滤出index中包含m的数据
df1.filter(like ='m',axis=0)

过滤出columns中包含o的数据
df1.filter(like ='o')
df1.filter(like ='o',axis=1)

前面布尔索引和query都是针对dataframe中的值进行过滤处理的,而filter是根据行列标签进行过滤处理。
3. group by 分组
在sql中,group by是非常重要的操作,将你的数据分组聚合,可以得到很多有意义的结果。在pandas中,也有对应的groupby用法。
- groupby
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=_NoDefault.no_default, squeeze=_NoDefault.no_default, observed=False, dropna=True)
by:用于指定确定groupby的组。
axis:沿行(0)或者列(1)拆分,默认为0
level:如果index是复合索引,可以通过level指定特定的级别。不要同时指定by和level
as_index:对于聚合结果,以组标签作为索引
sort:排序
group_keys:默认group的键在输出的时候是是不作为结果的index标签输出的。
squeeze:如果需要,减少返回的维度
observed:仅适用于任何groupers是分类的。
dropna:若是True,则聚合结果将会NA值所在行/列删除,若是False,则NA值也会作为组中的键。
在pandas中,也和sql一样,需要分组的数据放在groupby函数中。例如上面,按照时间和items分组:
df.groupby(['时间','items'])
# 得到的是一个groupby对象:
若是想查看结果,可以这样:
list(df.groupby(['时间','items']))

若是想要以index分组,可以通过level指定:
df1 = pd.DataFrame(np.arange(5),index=['wild','sux','sux','wild','wild'],columns=['col'])
list(df1.groupby(level=0))

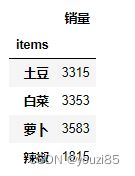
用groupby配合对应的函数,就可以得到对应的分组聚合值。例如,各个items的销量。
df.groupby('items').sum()
4.having 组间数据过滤
having是对group聚合后的组的一个筛选操作。可以把聚合操作后的数据赋值给一张临时表,这样具体处理方法其实和在where条件中一样,不再重复介绍。
5.select 筛选中想要查询的列
select column1,column2,column3,... from table;
当一张表中有特别多的字段,但是我们并不需要所有的字段,只需要取出其中某些查看,就可以通过select后写需要的字段查看。
在pandas中想查看某些列的数据有以下方法:
# 插入测试数据
df = pd.DataFrame(np.random.randint(10,size=(2,7)),columns=['星期一','星期二','星期三','星期四','星期五','星期六','星期日'])
df

单列
- .列名
df.星期三

- []
# 结果和上面一样,不再继续给出
df['星期三']
- loc[]和iloc[]
# 填入的是列标签
df.loc[:,['星期三']]
# 填入的是列索引
df.iloc[:,[2]]
多列
上面的方法取星期三,星期四数据
df[['星期三','星期四']]
df.loc[:,['星期三','星期四']]
df.iloc[:,[2,3]]

另外还可以使用切片的方法。
- 切片
start:stop:step
df.loc[:,'星期三':'星期四']
# 索引是左闭右开
df.iloc[:,2:4]
6.distinct 去重
# postgresql
select distinct id,num from a; -- 根据id,num字段去重
select distinct on (id)id,num from a; -- 根据id字段去重,num随机取值
#mysql
select distinct id,num from a ; -- 根据id,num字段去重
-- 根据id字段去重,mysql没有对应的语法,所以需要其他方法
with a1 as (
select id,num,row_number() over () r from a
)
select id,num from a1 where exists (select id m from (select id,max(r) m from a1 group by id)tmp where a1.id=tmp.id and a1.r=tmp.m)
在sql中,通过distinct字段对数据去重,其中有针对各个字段组合去重,还有就是针对某一个字段去重得到的结果。
在pandas中,有以下去重的方法。
- drop_duplicates
DataFrame.drop_duplicates(subset=None, *, keep=‘first’, inplace=False, ignore_index=False)
subset:传入需要通过哪些列去重数据,默认不传,表示所有列一起去重
keep:first:对于去重的行,保留第一条数据
last:去重数据保留最后一行
False:去重所有重复项
inplace:修改dataframe
ignore_index:忽略index。
举个例子,插入测试数据:
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})

# 对所有列去重
# 相当于 postgresql中的distinct
df.drop_duplicates()

# 针对brand去重显示
# 相当于postgresql中的distinct on
df.drop_duplicates(subset='brand')

# 根据brand,style去重,并且保留最后一条数据
df.drop_duplicates(subset=['brand','style'],keep='last')

- duplicated
DataFrame.duplicated(subset=None, keep=‘first’)
keep:first:将重复项标记为True,第一次出现的除外
last:将重复项标记为True,除最后一次出现的除外
False:将所有重复项标记为True
duplicated函数返回的是表示重复行的布尔系列
df.duplicated()
得到的结果如下图,若是重复出现的行,会返回True,否则返回False

若是想要以brand去重,看每个brand的最后一条数据:
#duplicated中的keep,如果设置last,表示每组重复值中,最后一次出现的为False,其余为True
df[df.duplicated(subset='brand',keep='last')==False]

这个函数用来查看重复项数据有多少比较方便
# 查看以brand去重,重复数据有多少
df.duplicated('brand').sum()

7.order by 排序
select * from a order by id;
select * from a order by id,num desc;
sql中,根据order by关键字指定排序,并通过asc(默认这个,可以不写),desc表示是升序还是降序。
在pandas中,排序有以下方法。
- sort_values
DataFrame.sort_values(by, *, axis=0, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’, ignore_index=False, key=None)
by:跟需要排序的字段名或字段名列表
sort_values表示根据columns上的值排序。
案例:
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col2': [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
'col4': ['a', 'B', 'c', 'D', 'e', 'F']
})
df
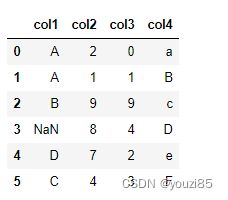
# 根据col1降序排列,若是col1相同,再按照col2升序排序
df.sort_values(['col1','col2'],ascending=[False,True])

# 根据index是4,5这两行对dataframe排序
# 对字母和数据比较大小是通过他们对应的ascii码对应做比较
df.sort_values([4,5],axis=1,ascending=[False,True])

- sort_index
DataFrame.sort_index(*, axis=0, level=None, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’, sort_remaining=True, ignore_index=False, key=None)
这个函数是根据标签排序
df = pd.DataFrame(
np.random.randint(10,size=(5,2)),index=['aa','b','ac','c','bb'],columns=['col2','col1']
)
df

df.sort_index()

df.sort_index(axis=1)

sort_index和sort_values的区别就是,sort_index就是根据index或者columns中的标签来排序,而sort_values则是根据dataframe中的数据进行排序。
8.limit 指定行数显示
# 显示前10条数据
select * from a limit 10;
# 偏移2条数据然后显示4条数据记录
select * from a limit 2,4;
select * from a limit 4 offset 2;
在sql中通过limit关键字指定数据显示条数。
我们一起来看看pandas中怎么处理。
- head
DataFrame.head(n=5)
返回前n行,默认返回前5行。
一起看看案例:
df = pd.DataFrame(
np.random.randint(10,size=(5,2)),index=['aa','b','ac','c','bb'],columns=['col2','col1']
)
df
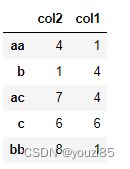
df.head(2)

- tail
DataFrame.tail(n=5)
返回最后n条数据,默认n是5
df.tail(2)

# 返回第二行、第三行数据
# head(2)+tail(-1)刚好的等于整个dataframe
df.tail(-1).head(2)

此外,sql的其他操作在pandas中同样能够处理。
9.union all 数据拼接
select id,name from a1
union all
select id,name from a2
sql中通过union all 关键字,可以将多张表结构一样的表拼接在一起。若是union,则表示合并表并删除重复项只保留去重项。
在pandas中,我们以下方法合并表。
- concat
pandas.concat(objs, *, axis=0, join=‘outer’, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
axis:表示按index方向还是columns方向拼接数据。
join:{‘inner’,‘outer’},默认outer,处理其他轴上的索引
ignore_index:默认false,若是true,则合并数据的index将会标记为0,1,…,n-1。
keys:如果有多个级别,通过传递的键作为最外层索引
levels:用于构建 MultiIndex 的特定级别(唯一值)
names:生成复合索引中的级别名称
# 插入测试数据
df1 = pd.DataFrame(data=[[1,3,2],[4,5,6]],columns=['col1','col2','col3'])
df2 = pd.DataFrame({'col1':np.random.randint(10,size=3),
'col2':np.random.randint(10,size=3),
'col3':np.random.randint(10,size=3)})
print(df1)
print(df2)

pd.concat([df1,df2])

concat除了沿着index方向拼接,还可以沿着columns方向拼接,这样拼接和merge和join一样。
# 默认拼接方式是outer,所以当某张表的数据比较多的时候,另一张表会用NAN补齐
pd.concat([df1,df2],axis=1)
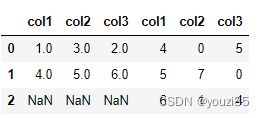
pd.concat([df1,df2],axis=1,join='inner',keys=['df1','df2'],names=['i1','i2'])

- append
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=False)
ignore_index:默认false,若是true,则合并数据的index将会标记为0,1,…,n-1。
verify_integrity:默认false,若是true,则在创建具有重复项的索引时会引发ValueError。
df1.append(df2)
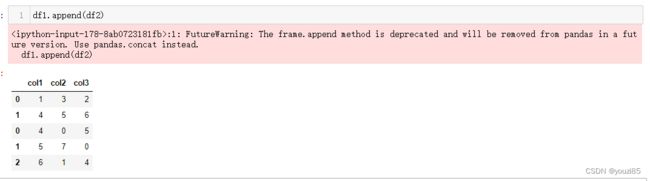
append这个方法还能使用,但是已经不推荐使用这种方法了,所以就使用concat比较好。
10.update 修改表中数据
update a set id=xxx where num=aaa;
- 利用索引修改(loc和iloc)
df = pd.DataFrame(np.arange(5))
df

df.iloc[2,0]=10
df

可以通过直接赋值的方法修改dataframe的值,同理loc也一样,不再举例。
- where
DataFrame.where(cond, other=_NoDefault.no_default, *, inplace=False, axis=None, level=None, errors=‘raise’, try_cast=_NoDefault.no_default)
当输入的条件时False时,将会替换value
# 插入测试数据:
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df
# 查看brand是Indomie,style是cup的数据
df.where((df['brand']=='Indomie')&(df['style']=='cup'))
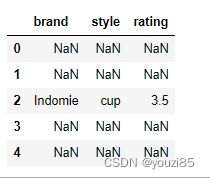
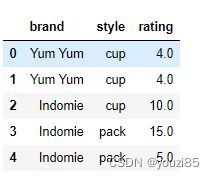
# 把brand是Indomie,style是cup的rating值改成10
# 这里要稍微变一下,where是将符合条件的数据保留原值,替换不符合条件的数据
df['rating'].where((df['brand']=='Yum Yum')|(df['style']=='pack'),10,inplace=True)
df
- mask
DataFrame.mask(cond, other=nan, *, inplace=False, axis=None, level=None, errors=‘raise’, try_cast=_NoDefault.no_default)
当条件为真时,替换value。这个函数和where刚好相反。
df.mask((df['brand']=='Indomie')&(df['style']=='cup'))
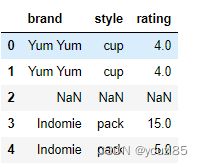
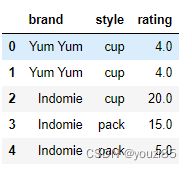
# 把brand是Indomie,style是cup的rating值改成20
df['rating'].mask((df['brand']=='Indomie')&(df['style']=='cup'),20,inplace=True)
df
因为,若是是为了查看数据时,用where函数比较好,可以顺着自己的思路直接写过滤条件。若是需要修改数据,用mask比较好,可以顺着自己的过滤要求写条件,否则写的条件就要反推,容易出错。
- update
DataFrame.update(other, join=‘left’, overwrite=True, filter_func=None, errors=‘ignore’)
other:DataFrame,至少有一个匹配的索引/列标签;Series必设name属性
join:{‘left’}仅实现左连接,保留原始对象的索引和列
overwrite =True:处理重叠键(行索引)非NA值: (True:覆盖原始df值,False:仅更新原始df中na的值)
filter_func:callable(1d-array) - > boolean 1d-array
可替换NA以外值。返回True表示值应该更新。函数参数作用于df
raise_conflict=False:为True,则会在df和other同一位置都是非na值时引发ValueError
# 插入测试数据
df = pd.DataFrame({'A': [11, 12, 13],'B': [14, 15, 16]})
new_df = pd.DataFrame({'B': [21, 22,23],'C': [24, 25, 26]})
print(df)
print(new_column)

# 只修改具有相同index和columns的值
df.update(new_column)
df

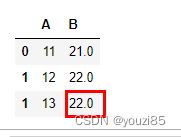
# 若是原dataframe相同的index有两个,overwrite=True表示都覆盖
df = pd.DataFrame({'A': [11, 12, 13],'B': [14, np.nan, 16]},index=[0,1,1])
new_df = pd.DataFrame({'B': [21, 22,23],'C': [24, 25, 26]})
df.update(new_df)
df
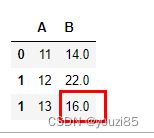
df = pd.DataFrame({'A': [11, 12, 13],'B': [14, np.nan, 16]},index=[0,1,1])
new_df = pd.DataFrame({'B': [21, 22,23],'C': [24, 25, 26]})
df.update(new_df,overwrite=False)
df
# 添加过滤条件filter_func
df = pd.DataFrame([[2.5, 2.1, 1.],
[2, np.nan, 3.],
[1.5, np.nan, 3],
[1.5, np.nan, 3]])
other = pd.DataFrame([[3.6, 2., np.nan],
[np.nan, np.nan, 7]])
df.update(other, filter_func=lambda x: x > 2)
df
# 根据index和columns名,other是修改df前两行数据。
# filter_func判断df前两行的数据,当该位置的元素大于2将会被替换
# 其中df.iloc[0,2]位置上的1没被替换是因为other.iloc[0,2]这个位置的数是np.nan,空值不做替换

# other的index设定,是other只替换df中相同index处的数据
df = pd.DataFrame([[2.5, 2.1, 1.],
[2, np.nan, 3.],
[1.5, np.nan, 3],
[1.5, np.nan, 3]])
other = pd.DataFrame([[3.6, 2., np.nan],
[np.nan, np.nan, 7]], index=[1, 3])
df.update(other, filter_func=lambda x: x > 2)
df

更多update案例,可查看(点这里)。
11.insert 插入数据
insert into a values (xxx,yyy);
insert into a select id,name from b;
在pandas中的插入数据怎么处理。
插入行:
# 测试数据
df = pd.DataFrame(np.arange(9).reshape(3,-1))
df

- loc[]
df.loc[3,:]=[10,10,10]
df

注意这里能通过loc来添加一行数据,但是不适用于iloc,iloc会报错。
添加一列:
df.loc[0,3]=20
df
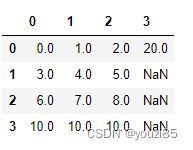
这里同样没有办法通过iloc来来增加一列,可以通过loc增加,若是只添加了一个数,那这列其余的值都会用NaN填充。
- dataframe.[‘列名’]
同理可以用dataframe[‘column’]新增一列。
df[4]=50

- insert
DataFrame.insert(loc, column, value, allow_duplicates=_NoDefault.no_default)
loc:插入的index
column:插入列名的标签
value:插入的value值
allow_duplicates:是否允许dataframe已存在一样的column标签
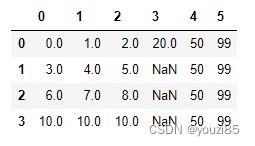
# 表示插入在列索引是5的位置,该列的索引标签是5,这一列中插入的数据是99
df.insert(5,5,99)
df
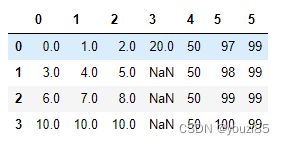
# 因为df中已经有列标签名是5的列,这个时候要插入相同的列名,需要allow_duplicates
df.insert(5,5,[97,98,99,100],allow_duplicates=True)
df
此外,若是想将另一张表的数据插入到表中,这就是前面讲的union all中的拼接表就一样,这里就不再继续说了。
12.delete 删除数据
# 删除整张表
delete from a;
# 删除满足条件的部分数据
delete from a where id=xxx;
# 删除列
alter table a drop column id;
删除列:
- del dataframe[‘column_name’]
del df[2]
df

- pop
DataFrame.pop(item)
传入的是column的标签
# 这个是有返回值的,返回的就是那列被删除的结果
df.pop(1)

下面这个函数不仅可以删除列,也可以删除行:
- drop
DataFrame.drop(labels=None, *, axis=0, index=None, columns=None, level=None, inplace=False, errors=‘raise’)
labels:要删除的index或者column标签,可以是单个标签,也可以是一个列表
axis:表示要删除行还是列
index:指定要删除的索引标签:index=label_name 等同于labels=label_name,axis=0。可以是单标签也可以是标签列表
columns:指定要删除的列标签:columns=label_name等同于labels=label_name,axis=1。可以是单标签也可以是标签列表
level:int或level name(针对复合索引)
inplace:是创建副本还是直接修改原dataframe
errors:{‘ignore’,‘raise’}
drop可以通过标签删掉行或者列
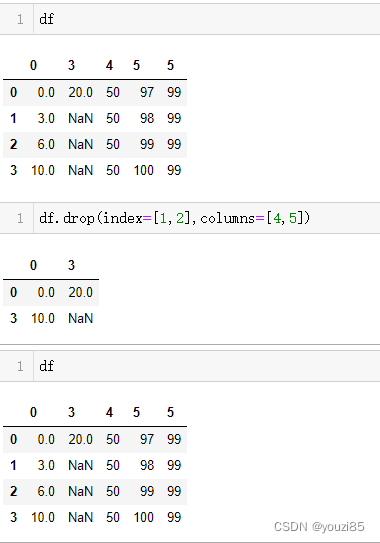
df
df.drop(index=[1,2],columns=[4,5])
df
# 若是只删除行或者只删除列,可以通过labels和axis指定
# inplace=False所以对原dataframe不做修改,会返回一个删除后的dataframe
本文到这里就结束了,感觉您的阅读~