DBSCAN算法
DBSCAN算法
一、基本思想
DBSCAN是一种基于密度的空间聚类算法,是一种无监督的ML聚类算法。它可以替代KMeans和层次聚类等流行的聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
二、算法步骤
- 确认确定两个参数:
epsilon:在一个点周围邻近区域的半径
minPts:邻近区域内至少包含点的个数 - 任意选择一个点(既没有指定到一个类也没有特定为外围点),计算它的NBHD(p,epsilon)判断是否为核点。如果是,在该点周围建立一个类,否则,设定为外围点。
- 遍历其他点,直到建立一个类。把directly-reachable的点加入到类中,接着把density-reachable的点也加进来。如果标记为外围的点被加进来,修改状态为边缘点。
- 重复步骤1和2,直到所有的点满足在类中(核点或边缘点)或者为外围点。
- 利用轮廓函数对算法进行评估,得出最优参数
三、代码
import numpy as np
import pandas as pd
import math as m
import matplotlib.pyplot as plt
import queue
from sklearn.cluster import KMeans
from sklearn import datasets,metrics
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# data_path = "data/iris_data.txt"
data_path = "data/Aggregation_cluster=7.txt"
NOISE = 0
UNASSIGNED = -1
def load_data():
"""
导入数据
:return: 数据
"""
points = np.loadtxt(data_path, delimiter='\t')
return points
def dist(a, b):
"""
计算两个向量的距离
:param a: 向量1
:param b: 向量2
:return: 距离
"""
return m.sqrt(np.power(a-b, 2).sum())
def neighbor_points(data, pointId, radius):
"""
得到邻域内所有样本点的Id
:param data: 样本点
:param pointId: 核心点
:param radius: 半径
:return: 邻域内所用样本Id
"""
points = []
for i in range(len(data)):
if dist(data[i, 0: 2], data[pointId, 0: 2]) < radius:
points.append(i)
return np.asarray(points)
def to_cluster(data, clusterRes, pointId, clusterId, radius, minPts):
"""
判断一个点是否是核心点,若是则将它和它邻域内的所用未分配的样本点分配给一个新类
若邻域内有其他核心点,重复上一个步骤,但只处理邻域内未分配的点,并且仍然是上一个步骤的类。
:param data: 样本集合
:param clusterRes: 聚类结果
:param pointId: 样本Id
:param clusterId: 类Id
:param radius: 半径
:param minPts: 最小局部密度
:return: 返回是否能将点PointId分配给一个类
"""
points = neighbor_points(data, pointId, radius)
points = points.tolist()
q = queue.Queue()
if len(points) < minPts:
clusterRes[pointId] = NOISE
return False
else:
clusterRes[pointId] = clusterId
for point in points:
if clusterRes[point] == UNASSIGNED:
q.put(point)
clusterRes[point] = clusterId
while not q.empty():
neighborRes = neighbor_points(data, q.get(), radius)
if len(neighborRes) >= minPts: # 核心点
for i in range(len(neighborRes)):
resultPoint = neighborRes[i]
if clusterRes[resultPoint] == UNASSIGNED:
q.put(resultPoint)
clusterRes[resultPoint] = clusterId
elif clusterRes[clusterId] == NOISE:
clusterRes[resultPoint] = clusterId
return True
def dbscan(data, radius, minPts):
"""
扫描整个数据集,为每个数据集打上核心点,边界点和噪声点标签的同时为
样本集聚类
:param data: 样本集
:param radius: 半径
:param minPts: 最小局部密度
:return: 返回聚类结果, 类id集合
"""
radius = radius
minPts = minPts
clusterId = 1
nPoints = len(data)
clusterRes = [UNASSIGNED] * nPoints
for pointId in range(nPoints):
if clusterRes[pointId] == UNASSIGNED:
if to_cluster(data, clusterRes, pointId, clusterId, radius, minPts):
clusterId = clusterId + 1
return np.asarray(clusterRes), clusterId,radius,minPts
def plotRes(data, clusterRes, clusterNum, radius, minPts):
nPoints = len(data)
scatterColors = ['red', 'green', 'blue', 'orange', 'purple', 'brown']
for i in range(clusterNum):
color = scatterColors[i % len(scatterColors)]
x1 = []; y1 = []
for j in range(nPoints):
if clusterRes[j] == i:
x1.append(data[j, 0])
y1.append(data[j, 1])
plt.scatter(x1, y1, c=color, alpha=1, marker='+')
plt.xlabel('萼片长度')
plt.ylabel('萼片宽度')
plt.title("radius:%s minPts:%d"%(str(radius),minPts))
if __name__ == '__main__':
data = load_data()
# data = datasets.load_iris()
cluster = np.asarray(data[:, 2])
plt.scatter(data[:, 0], data[:, 1], c="red", marker='o', label='原始数据')
plt.legend(loc=2)
plt.show()
res = []
#根据轮廓函数进行评估
for radius in range(1,4):
for minPts in range(2,15):
clusterRes, clusterNum, radius, minPts = dbscan(data,radius, minPts)
try:
#评价dbscan 参数
score = metrics.silhouette_score(data, clusterRes)
except:
score = -99
res.append({'radius':radius,'minPts':minPts,'clusterNum':clusterNum,'score':score})
result = pd.DataFrame(res)
clusterRes, clusterNum, radius, minPts = dbscan(data,2, 9)
print(result)
plotRes(data, clusterRes, clusterNum, radius, minPts)
plt.show()
结果:
1、788个坐标点数据样本(3维):(横坐标,纵坐标),和类别标签(1维,离散值):(1或者2)。
例如,训练样本数据:[15.55 28.65 1],类别:[1]
实验结果:
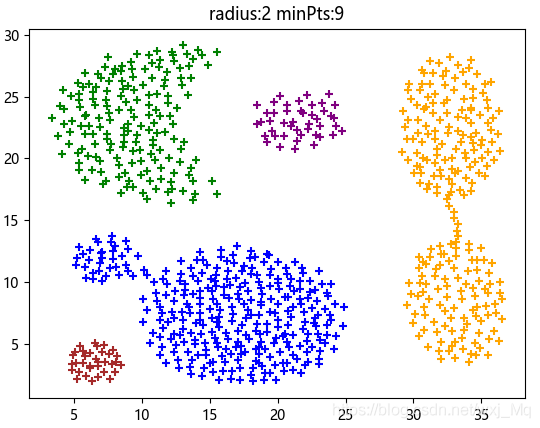
DBSCAN点分类:radius:2 minPts:9(最优参数),如图
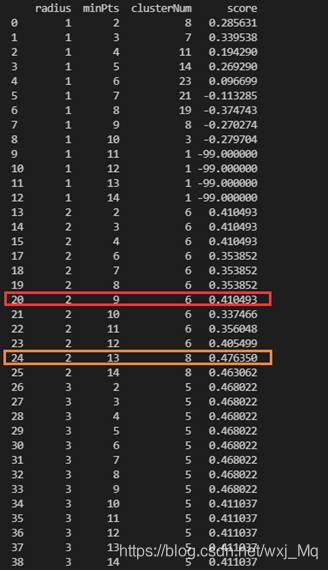
算法评估及不同取值的对应的评估分数、分类数,如图
2、149个鸢尾花数据样本(4维):(萼片长度,萼片宽度,花瓣长度,花瓣宽度)。
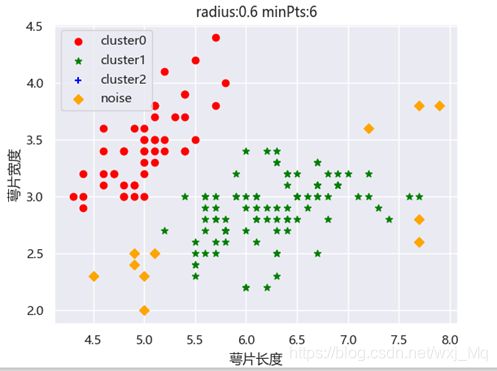
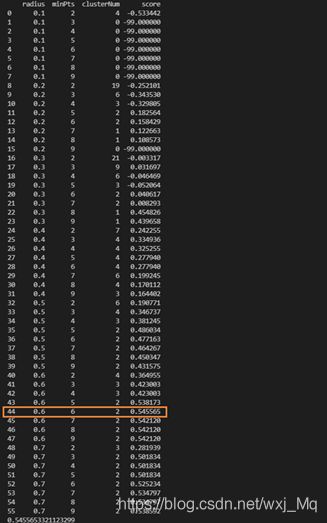
实验结果:花类别分类结果,radius:0.6 minPts:6(一定范围内最优)如图
算法评估及不同取值的对应的评估分数、分类数,如图
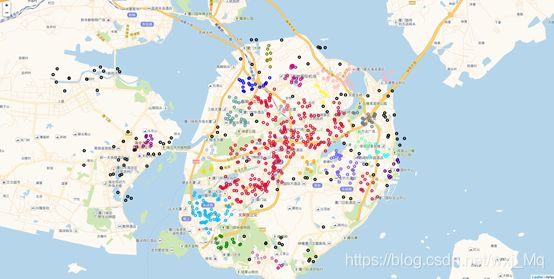
3、对经纬度的聚类(个人学习于大佬博主,详细请看Python实现经纬度空间点DBSCAN聚类_黄钢的博客-CSDN博客!!!!详细!)
代码:
import pandas as pd
import numpy as np
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import seaborn as sns
import folium
from sklearn import metrics
from math import radians
from math import tan,atan,acos,sin,cos,asin,sqrt
from scipy.spatial.distance import pdist, squareform
sns.set()
def haversine(lonlat1, lonlat2):
lat1, lon1 = lonlat1
lat2, lon2 = lonlat2
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2
c = 2 * asin(sqrt(a))
r = 6371 # Radius of earth in kilometers. Use 3956 for miles
return c * r * 1000
## 第一部分
df = pd.read_csv('data/route.csv')
df = df[['lat_Amap', 'lng_Amap']].dropna(axis=0,how='all')
data = np.array(df)
distance_matrix = squareform(pdist(df, (lambda u, v: haversine(u, v))))
radius = 500
minPts = 5
# #这里的metric='precomputed’不再是欧式距离,后面也不再是fit函数,而是fit_predict函数,用这种方法呢,就将原来的欧式距离换成了实际的距离
db = DBSCAN(eps=radius, min_samples=minPts, metric='precomputed').fit_predict(distance_matrix)
labels = db
raito = len(labels[labels[:] == -1]) / len(labels) # 计算噪声点个数占总数的比例
n_clusters = len(set(labels)) - (1 if -1 in labels else 0) # 获取分簇的数目
score = metrics.silhouette_score(data, labels)
#进行聚类 并分析
res = []
for radius in range(500,1000):
for minPts in range(10,15):
db = DBSCAN(eps=radius, min_samples=minPts, metric='precomputed').fit_predict(distance_matrix)
labels = db
raito = len(labels[labels[:] == -1]) / len(labels) # 计算噪声点个数占总数的比例
n_clusters = len(set(labels)) - (1 if -1 in labels else 0) # 获取分簇的数目
try:
#评价dbscan 参数
score = metrics.silhouette_score(data, labels)
except:
score = -99
res.append({'radius':radius,'minPts':minPts,'clusterNum':n_clusters,'score':score,'raito_noise':raito})
result = pd.DataFrame(res)
print(result)
print(result['score'].max())
print(result['raito_noise'].min())
print(result['clusterNum'].max())
## 第二部分
map_ = folium.Map(location=[24.50463, 118.145933], zoom_start=12,
tiles='http://webrd02.is.autonavi.com/appmaptile?lang=zh_cn&size=1&scale=1&style=7&x={x}&y={y}&z={z}',
attr='default')
colors = ['#DC143C', '#FFB6C1', '#DB7093', '#C71585', '#8B008B', '#4B0082', '#7B68EE',
'#0000FF', '#B0C4DE', '#708090', '#00BFFF', '#5F9EA0', '#00FFFF', '#7FFFAA',
'#008000', '#FFFF00', '#808000', '#FFD700', '#FFA500', '#FF6347','#DC143C',
'#FFB6C1', '#DB7093', '#C71585', '#8B008B', '#4B0082', '#7B68EE',
'#0000FF', '#B0C4DE', '#708090', '#00BFFF', '#5F9EA0', '#00FFFF', '#7FFFAA',
'#008000', '#FFFF00', '#808000', '#FFD700', '#FFA500', '#FF6347',
'#DC143C', '#FFB6C1', '#DB7093', '#C71585', '#8B008B', '#4B0082', '#7B68EE',
'#0000FF', '#B0C4DE', '#708090', '#00BFFF', '#5F9EA0', '#00FFFF', '#7FFFAA',
'#008000', '#FFFF00', '#808000', '#FFD700', '#FFA500', '#FF6347',
'#DC143C', '#FFB6C1', '#DB7093', '#C71585', '#8B008B', '#4B0082', '#7B68EE',
'#0000FF', '#B0C4DE', '#708090', '#00BFFF', '#5F9EA0', '#00FFFF', '#7FFFAA',
'#008000', '#FFFF00', '#808000', '#FFD700', '#FFA500', '#FF6347','#DC143C',
'#FFB6C1', '#DB7093', '#C71585', '#8B008B', '#4B0082', '#7B68EE',
'#0000FF', '#B0C4DE', '#708090', '#00BFFF', '#5F9EA0', '#00FFFF', '#7FFFAA',
'#008000', '#FFFF00', '#808000', '#FFD700', '#FFA500', '#FF6347',
'#DC143C', '#FFB6C1', '#DB7093', '#C71585', '#8B008B', '#4B0082', '#7B68EE',
'#0000FF', '#B0C4DE', '#708090', '#00BFFF', '#5F9EA0', '#00FFFF', '#7FFFAA',
'#008000', '#FFFF00', '#808000', '#FFD700', '#FFA500', '#FF6347','#000000']
for i in range(len(data)):
folium.CircleMarker(location=[data[i][0], data[i][1]],
radius=4, popup='popup',
color=colors[labels[i]], fill=True,
fill_color=colors[labels[i]]).add_to(map_)
map_.save('all_cluster.html')
实验数据: 1、774个不同经纬度数据(2维):(经度,纬度)。
实验结果:经纬度聚类结果,radius:800 minPts:10(一定范围内最优)如图