在Cloudera Hadoop CDH上安装R及RHadoop(rhdfs、rmr2、rhbase、RHive)
RHadoop是由Revolution Analytics发起的一个开源项目,它可以将统计语言R与Hadoop结合起来。目前该项目包括三个R packages,分别为支持用R来编写MapReduce应用的rmr、用于R语言访问HDFS的rhdfs以及用于R语言访问HBASE的rhbase。
一、系统及所需软件版本
服务器操作系统:CentOS 6.4 只下载DVD1即可,DVD2是选择安装的软件包
下载地址:http://mirror.stanford.edu/yum/pub/centos/6.4/isos/x86_64/CentOS-6.4-x86_64-bin-DVD1.iso
R语言版本:R-2.15.3 (本人安装的时候,发现新版本存在各种不兼容的问题)
下载地址:http://ftp.ctex.org/mirrors/CRAN/src/base/R-2/R-2.15.3.tar.gz
Cloudera Hadoop CDH版本:4.3.0
JDK版本:1.6.0_31
使用Cloudera Manager 免费版的安装包cloudera-manager-installer.bin,即可完成CDH和JDK的安装,具体详见CDH的安装
下载地址:https://ccp.cloudera.com/display/SUPPORT/Cloudera+Manager+Free+Edition+Download
rJava(是java可以调用R)版本:rJava_0.9-5
下载地址:http://www.rforge.net/src/contrib/rJava_0.9-5.tar.gz
RHadoop版本,为官方最新版本,具体如下:
下载地址:https://github.com/RevolutionAnalytics/RHadoop/wiki/Downloads
二、依赖安装(R语言包、rJava包)
在安装之前需要在集群各个主机上逐个安装R语言包、rJava包,然后再进行Rhadoop的安装。具体安装步骤如下:
1、安装R语言包
在编译R之前,需要通过yum安装以下几个程序:
yum install gcc-gfortran
否则报”configure: error: No F77 compiler found”错误
# yum install gcc gcc-c++
否则报”configure: error: C++ preprocessor “/lib/cpp” fails sanity check”错误
# yum install readline-devel
否则报”--with-readline=yes (default) and headers/libs are not available”错误
# yum install libXt-devel
否则报”configure: error: --with-x=yes (default) and X11 headers/libs are not available”错误
然后下载源代码,编译
# cd /home/admin # wget http://cran.rstudio.com/src/base/R-2/R-2.15.3.tar.gz # tar -zxvf R-2.15.3.tar.gz # cd R-2.15.3 # ./configure --prefix=/usr --disable-nls --enable-R-shlib/** (后面两个选项--disable-nls --enable-R-shlib是为RHive的安装座准备,如果不安装RHive可以省去)*/ # make # make install
安装完毕后查看,得到R的安装路径为/usr/lib64/R ,即后来要设置的R_HOME所在的目录。
2、安装rJava包:
版本:rJava_0.9-5.tar.gz
在联网的情况下,可以进入R命令,安装rJava包:
> install.packages("rJava")
如果待安装机器不能上网,可以将源文件下载到本地,然后通过shell命令R CMD INSTALL ‘package_name’来安装:
R CMD INSTALL "rJava_0.9-5.tar.gz"
本教程的包,大部分都是都是本地安装的,只有Rserve等个别包。
然后设置Java、Hadoop、R、Hive等相关环境变量(如果在搭建Cloudera Hadoop集群时已经设置好,做一下检查就OK)
下面是RHadoop及RHive安装成功时/etc/profile中的环境变量配置情况
#Java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#Hadoop environment set
export HADOOP_HOME=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_CMD=/usr/bin/hadoop
export HADOOP_STREAMING=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.3.0.jar
export JAVA_LIBRARY_PATH=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop/lib/native
#Hive Home and RHive_data
export RHIVE_DATA=/usr/lib64/R/rhive/data
export HIVE_HOME=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hive
#set R_HOME
export R_HOME=/usr/lib64/R
export CLASSPATH=.:/usr/lib64/R/library/rJava/jri
export LD_LIBRARY_PATH=/usr/lib64/R/library/rJava/jri
export PATH=$PATH:$R_HOME/bin
export RServe_HOME=/usr/lib64/R/library/RServe
#pkgconfig environment set
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig/
三、安装RHadoop环境(rhdfs、rmr2、rhbase、RHive)
1、安装rhdfs包(仅安装在namenode上):
R CMD INSTALL "rhdfs_1.0.5.tar.gz"
在/etc/profile中设置环境变量HADOOP_HOME、HADOOP_CON_DIR、HADOOP_CMD
export HADOOP_HOME=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_CMD=/usr/bin/hadoop
安装后调用rhdfs,测试安装:
> library("rhdfs") Loading required package: rJava HADOOP_CMD=/usr/bin/hadoop Be sure to run hdfs.init()
当按要求输入hdfs.init()后,如果出现:
> hdfs.init()
13/06/27 09:29:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
需要在/etc/profile中设置环境变量JAVA_LIBRARY_PATH
export JAVA_LIBRARY_PATH=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop/lib/native
如果设置后问题依然没有解决,需要将native下面的libhadoop.so.0 及 libhadoop.so.1.0.0拷贝到 /usr/lib64下面
[root@master native]# pwd /opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop/lib/native [root@master native]# cp libhadoop.so libhadoop.so libhadoop.so.1.0.0 [root@master native]# cp libhadoop.so /usr/lib64 [root@master native]# cp libhadoop.so.1.0.0 /usr/lib64
就会得到解决。
2、安装rmr2包(各个主机上都要安装):
安装rmr2包之前,需要安装其依赖的7个包,他们分别是:
[root@master RHadoop-deps]# ls digest_0.6.3.tar.gz plyr_1.8.tar.gz reshape2_1.2.2.tar.gz stringr_0.6.2.tar.gz functional_0.4.tar.gz Rcpp_0.10.3.tar.gz RJSONIO_1.0-3.tar.gz
执行安装:
[root@master RHadoop-deps]# R CMD INSTALL "digest_0.6.3.tar.gz" [root@master RHadoop-deps]# R CMD INSTALL "plyr_1.8.tar.gz" [root@master RHadoop-deps]# R CMD INSTALL "reshape2_1.2.2.tar.gz" [root@master RHadoop-deps]# R CMD INSTALL "stringr_0.6.2.tar.gz" [root@master RHadoop-deps]# R CMD INSTALL "functional_0.4.tar.gz" [root@master RHadoop-deps]# R CMD INSTALL "Rcpp_0.10.3.tar.gz" [root@master RHadoop-deps]# R CMD INSTALL "RJSONIO_1.0-3.tar.gz"
如果未安装,或者7个包安装不全,安装程序会提示其所依赖的的包要安装。
R CMD INSTALL "rmr2_2.2.0.tar.gz"
需要在/etc/profile中设置环境变量HADOOP_STREAMING
export HADOOP_STREAMING=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.3.0.jar
安装测试:
安装好rhdfs和rmr2两个包后,我们就可以使用R尝试一些Hadoop的操作了。
首先,是基本的hdfs的文件操作。
查看hdfs文件目录
hadoop的命令:hadoop fs -ls /user
R语言函数:hdfs.ls(”/user/“)
查看hadoop数据文件
hadoop的命令:hadoop fs -cat /user/hdfs/o_same_school/part-m-00000
R语言函数:hdfs.cat(”/user/hdfs/o_same_school/part-m-00000″)
接下来,我们执行一个rmr2算法的任务
普通的R语言程序:
> small.ints = 1:10 > sapply(small.ints, function(x) x^2)
MapReduce的R语言程序:
> library("rhdfs") Loading required package: rJava HADOOP_CMD=/usr/bin/hadoop Be sure to run hdfs.init() > hdfs.init() > library("rmr2") Loading required package: Rcpp Loading required package: RJSONIO Loading required package: digest Loading required package: functional Loading required package: stringr Loading required package: plyr Loading required package: reshape2 > small.ints = to.dfs(1:10) 13/06/17 16:11:47 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library 13/06/17 16:11:47 INFO compress.CodecPool: Got brand-new compressor [.deflate] Warning message: In to.dfs(1:10) : Converting to.dfs argument to keyval with a NULL key > mapreduce(input = small.ints, map = function(k, v) cbind(v, v^2)) packageJobJar: [/tmp/RtmprBZ3GE/rmr-local-env6c60369aa6c8, /tmp/RtmprBZ3GE/rmr-global-env6c6044b000b9, /tmp/RtmprBZ3GE/rmr-streaming-map6c6045e81c18, /tmp/hadoop-root/hadoop-unjar8586629798067220662/] [] /tmp/streamjob4620216971843644952.jar tmpDir=null 13/06/17 16:12:07 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 13/06/17 16:12:08 INFO mapred.FileInputFormat: Total input paths to process : 1 13/06/17 16:12:09 INFO streaming.StreamJob: getLocalDirs(): [/tmp/hadoop-root/mapred/local] 13/06/17 16:12:09 INFO streaming.StreamJob: Running job: job_201306162142_0003 13/06/17 16:12:09 INFO streaming.StreamJob: To kill this job, run: 13/06/17 16:12:09 INFO streaming.StreamJob: /opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop/bin/hadoop job -Dmapred.job.tracker=master:8021 -kill job_201306162142_0003 13/06/17 16:12:09 INFO streaming.StreamJob: Tracking URL: http://master:50030/jobdetails.jsp?jobid=job_201306162142_0003 13/06/17 16:12:10 INFO streaming.StreamJob: map 0% reduce 0% 13/06/17 16:12:17 INFO streaming.StreamJob: map 50% reduce 0% 13/06/17 16:12:18 INFO streaming.StreamJob: map 100% reduce 0% 13/06/17 16:12:19 INFO streaming.StreamJob: map 100% reduce 100% 13/06/17 16:12:19 INFO streaming.StreamJob: Job complete: job_201306162142_0003 13/06/17 16:12:19 INFO streaming.StreamJob: Output: /tmp/RtmprBZ3GE/file6c6079b8d37f function () { fname } <environment: 0x3b0b508> > from.dfs("/tmp/RtmprBZ3GE/file6c6079b8d37f") DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. $key NULL $val v [1,] 1 1 [2,] 2 4 [3,] 3 9 [4,] 4 16 [5,] 5 25 [6,] 6 36 [7,] 7 49 [8,] 8 64 [9,] 9 81 [10,] 10 100 >
因为MapReduce只能访问HDFS文件系统,先要用to.dfs把数据存储到HDFS文件系统里。MapReduce的运算结果再用from.dfs函数从HDFS文件系统中取出。
rmr2 WordCount实例:
> input<- '/user/hdfs/sample' > wordcount = function(input, output = NULL, pattern = " "){ wc.map = function(., lines) { keyval(unlist( strsplit( x = lines,split = pattern)),1) } wc.reduce =function(word, counts ) { keyval(word, sum(counts)) } mapreduce(input = input ,output = output, input.format = "text", map = wc.map, reduce = wc.reduce,combine = T) } > wordcount(input)
…………………………………………………………………… > from.dfs("/tmp/RtmprbZ3GE/file7ba96e6aa4a6")
在HDFS中放入了数据文件/user/hdfs/sample。写WordCount的MapReduce函数,执行wordcount函数,最后用from.dfs从HDFS中取得结果。
3、安装rhbase包(仅安装在namenode上):
安装rhbase-1.1.1(参见https://github.com/RevolutionAnalytics/RHadoop/wiki/rhbase)。在安装rhbase之前,还需要安装Thrift库,建议安装版本与rhbase构建及测试选用的版本相同,在rhbase的wiki页面可以看到:
rhbase-1.1.1使用的是Thrift 0.8.0版本,下载网址为 http://archive.apache.org/dist/thrift/0.8.0/thrift-0.8.0.tar.gz
其详细的安装步骤如下:
a、在centos系统下输入shell命令
sudo yum install automake libtool flex bison pkgconfig gcc-c++ boost-devel libevent-devel lib-devel python-devel ruby-devel
安装一些Thrift相关的工具或库。有的时候,还需要安装openssl-devel(在Ubuntu下为libssl-dev),不然会提示libcrypto.so找不到
yum install openssl-devel
b、解压安装Thrift
[root@master admin]# cd thrift-0.8.0 [root@master thrift-0.8.0]# ./configure --with-boost=/usr/include/boost JAVAC=/usr/java/jdk1.6.0_31/bin/javac [root@master thrift-0.8.0]# make [root@master thrift-0.8.0]# make install
在/etc/profile中设置环境变量PKG_CONFIG_PATH:
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig/
验证设置的正确性,在shell下输入pkg-config --cflags thrift如结果如下所示:
[root@master thrift-0.8.0]# pkg-config --cflags thrift -I/usr/local/include/thrift
则说明配置成功。
c、复制library文件到/usr/lib下面(x64位的下面还要复制到/usr/lib64下面,或者仅仅复制到/usr/lib64下面)
cp /usr/local/lib/libthrift.so.0 /usr/lib
有时候仅复制这个还是有问题的,还需要复制libthrift-0.8.0.so :
cp /usr/local/lib/libthrift-0.8.0.so /usr/lib
最好把libthrift相关的都复制进去,如 libthrift.so.0、libthrift.so.0.0.0等。(x64位的下面还要复制到/usr/lib64下面,或者仅仅复制到/usr/lib64下面)
d、安装rhbase
R CMD INSTALL "rhbase_1.1.1.tar.gz"
如果安装的过程中,如果发现libRblas.so、libRlapack.so、libR.so等找不到,需要从$R_HOME/lib将这些library拷贝到/usr/lib64目录下:
[root@slave1 ~]# cp /usr/lib64/R/lib/libRblas.so /usr/lib64/ [root@slave1 ~]# cp /usr/lib64/R/lib/libRlapack.so /usr/lib64/ [root@slave1 ~]# cp /usr/lib64/R/lib/libR.so /usr/lib64/
最终问题可以解决,完成rhbase的安装。
4、安装RHive(各个主机上都要安装):
RHive是一种通过Hive高性能查询来扩展R计算能力的包。它可以在R环境中非常容易的调用HQL, 也允许在Hive中使用R的对象和函数。理论上数据处理量可以无限扩展的Hive平台,搭配上数据挖掘的利器R环境, 堪称是一个完美的大数据分析挖掘的工作环境。
1、Rserve包的安装:
RHive依赖于Rserve,因此在安装R的要按照本文R的安装方式,即附带后面两个选项(--disable-nls --enable-R-shlib)
enable-R-shlib是将R作为动态链接库进行安装,这样像Rserve依赖于R动态库的包就可以安装了,但缺点会有20%左右的性能下降。
Rserve使用的的是在线安装方式:
install.packages("Rserve")
$R_HOME的目录下创建Rserv.conf文件,写入“remote enable''保存并退出。通过scp -r 命令将Master节点上安装好的Rserve包,以及Rserv.conf文件拷贝到所有slave节点下。当然在节点不多的情况下也可以分别安装Rserve包、创建Rserv.conf。
scp -r /usr/lib64/R/library/Rserve slave1:/usr/lib64/R/library/
scp -r /usr/lib64/R/Rserv.conf slave3:/usr/lib64/R/
在所有节点启动Rserve
Rserve --RS-conf /usr/lib64/R/Rserv.conf
在master节点上telnet(如果未安装,通过shell命令yum install telnet安装)所有slave节点:
telnet slave1 6311
显示Rsrv013QAP1则表示连接成功。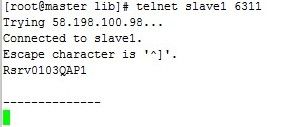
2、RHive包的安装:
安装RHive_0.0-7.tar.gz,并在master和所有slave节点上创建rhive的data目录,并赋予读写权限(最好将$R_HOME赋予777权限)
[root@master admin]# R CMD INSTALL RHive_0.0-7.tar.gz [root@master admin]# cd $R_HOME [root@master R]# mkdir -p rhive/data [root@master R]# chmod 777 -R rhive/data
master和slave中的/etc/profile中配置环境变量RHIVE_DATA=/usr/lib64/R/rhive/data
export RHIVE_DATA=/usr/lib64/R/rhive/data
通过scp命令将master节点上安装的RHive包拷贝到所有的slave节点下:
scp -r /usr/lib64/R/library/RHive slave1:/usr/lib64/R/library/
查看hdfs文件下的jar是否有读写权限
hadoop fs -ls /rhive/lib
安装rhive后,hdfs的根目录并没有rhive及其子目录lib,这就需要自己建立,并将/usr/lib64/R/library/RHive/java下的rhive_udf.jar复制到该目录
hadoop fs -put /usr/lib64/R/library/RHive/java/rhive_udf.jar /rhive/lib
否则在测试rhive.connect()的时候会报没有/rhive/lib/rhive_udf.jar目录或文件的错误。
最后,在hive客户端启(master、各slave均可)动hive远程服务(rhive是通过thrift连接hiveserver的,需要要启动后台thrift服务):
nohup hive --service hiveserver &
3、RHive的使用及测试:
1、RHive API
从HIVE中获得表信息的函数,比如
- rhive.list.tables:获得表名列表,支持pattern参数(正则表达式),类似于HIVE的show table
- rhive.desc.table:表的描述,HIVE中的desc table
- rhive.exist.table:
2、测试
> library("RHive") Loading required package: Rserve This is RHive 0.0-7. For overview type ?.RHive?. HIVE_HOME=/opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hive [1] "there is no slaves file of HADOOP. so you should pass hosts argument when you call rhive.connect()." call rhive.init() because HIVE_HOME is set. Warning message: In file(file, "rt") : cannot open file '/etc/hadoop/conf/slaves': No such file or directory > rhive.connect() 13/06/17 20:32:33 WARN conf.Configuration: fs.default.name is deprecated. Instead, use fs.defaultFS 13/06/17 20:32:33 WARN conf.Configuration: fs.default.name is deprecated. Instead, use fs.defaultFS >
表明安装成功,只是conf下面的slaves没有配置,在/etc/hadoop/conf中新建slaves文件,并写入各个slave的名称即可解决该警告。
RHive的运行环境如下:
> rhive.env() Hive Home Directory : /opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hive Hadoop Home Directory : /opt/cloudera/parcels/CDH-4.3.0-1.cdh4.3.0.p0.22/lib/hadoop Hadoop Conf Directory : /etc/hadoop/conf No RServe Connected HiveServer : 127.0.0.1:10000 Connected HDFS : hdfs://master:8020 >
3、RHive简单应用
载入RHive包,令连接Hive,获取数据:
> library(RHive)
> rhive.connect(host = 'host_ip')
> d <- rhive.query('select * from emp limit 1000')
> class(d)
> m <- rhive.block.sample(data_sku, percent = 0.0001, seed = 0)
> rhive.close()
一般在系统中已经配置了host,因此可以直接rhive.connect()进行连接,记得最后要有rhive.close()操作。 通过HIVE查询语句,将HIVE中的目标数据加载至R环境下,返回的 d 是一个dataframe。
实际上,rhive.query的实际用途有很多,一般HIVE操作都可以使用,比如变更scheme等操作:
> rhive.query('use scheme1') > rhive.query('show tables') > rhive.query('drop table emp')
但需要注意的是,数据量较大的情况需要使用rhive.big.query,并设置memlimit参数。
将R中的对象通过构建表的方式存储到HIVE中需要使用
> rhive.write.table(dat, tablename = 'usertable', sep = ',')
而后使用join等HIVE语句获得相关建模数据。其实写到这儿,有需求的看官就应该明白了,这几项 RHive 的功能就足够 折腾些有趣的事情了。
- 注1:其他关于在HIVE中调用R函数,暂时还没有应用,未来更新。
-
注2:
rhive.block.sample这个函数需要在HIVE 0.8版本以上才能执行。
安徽隆兴禽业(www.58lxqy.com)全年大量供应状元红鸡苗(红玉鸡苗)、固始鸡土鸡苗、淮南王土鸡苗,散养鸡苗,大红公鸡苗及各类土鸡种蛋。批发订购:13075005200 QQ:1170693418 地址:阜阳市太和县倪邱镇孙庙105国道东侧。
安徽鸡苗,阜阳鸡苗,安徽土鸡苗,阜阳土鸡苗,鸡苗孵化,河南鸡苗,山东鸡苗,河南土鸡苗,山东土鸡苗,固始鸡,淮南王,纯红肉杂,纯红公鸡。